From the creators of Indexisto - "Search for Habr II"
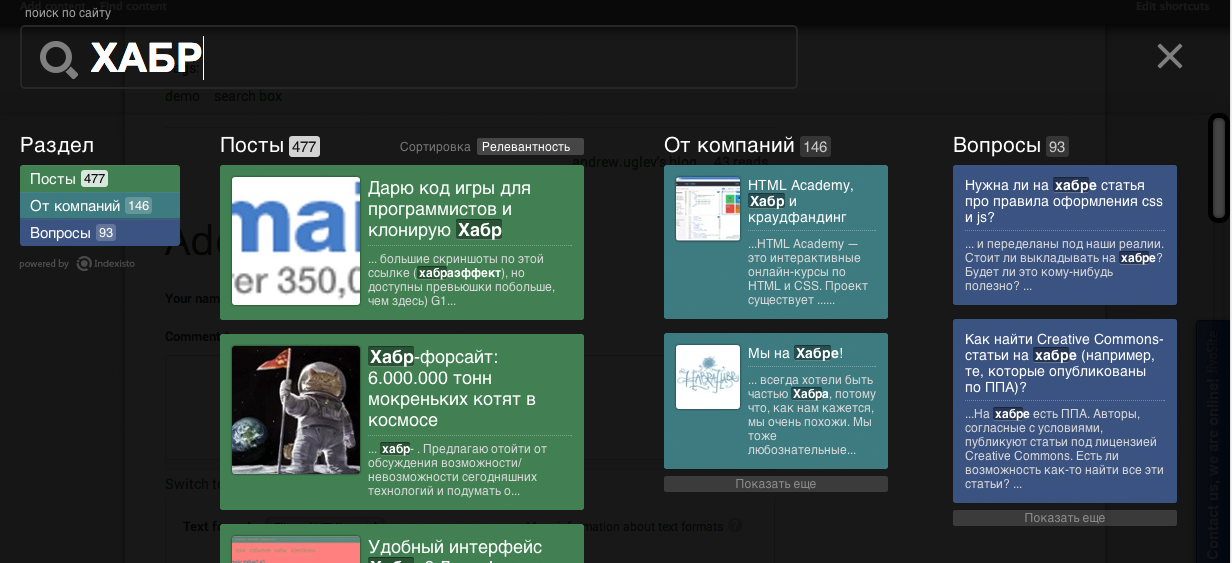
On a gloomy autumn morning, as an experiment, we washed down our search for Habr with structure and speed. It took about 10 minutes to all the work. Those who are too lazy to read tyk to view a new search (search input right in the body of a blog entry)
To obtain such a search, we did not ask for access to the database, or uploading articles through our API. Everything is done very simply through a regular crawler. For example, we scrawled about 5,000 articles.
Background
Hello. Let me remind you that we do a quick structured search for Indexisto sites (+ our post on the hub ). For a long time nothing was heard from us, and now we finally come out with the release.
After the first publication, many liked what we were doing and many wanted to implement. I am very grateful to the first people who connected - we saw a lot of “subtleties” that we would not have found. We quickly repaired everything, and at the same time we never dropped a single “live” index. However, there was a structural problem:
- A very high entry threshold. Sophisticated database connection, sophisticated settings for templates, search query, analyzers, etc.
We solved this problem by manually configuring client configs (for example, you can see our output on maximonline.ru ), and with explanations that we need early adopters. At the same time, development (in addition to bugs) almost got up, and we realized that we were either becoming an integrator, or we had to change something in order to remain an Internet project.
Development of events
Today we want to present a radical solution to the problem with the connection - you just need to enter the site URL, and get ready search results. That's it. Everything else is done automatically. Many complex settings are taken from the finished template and applied to your index. At the same time, the admin panel has shrunk completely - to checkboxes and drop-down lists. For fans of hardcore, we left the opportunity to switch to advanced mode.
Crawler and parser
And so, now we have a crawler and a content parser. Crawler gives relatively reasonable pages: we more or less learned to discard paginations, various feeds, changes in presentation (like? Sort = date.asc). But even if the crawler works perfectly, we will have pages with articles in which there is a ton of superfluous: menus, blocks in the right and left column. Let's face it, I would not really like to see all this in the search results, if we adhere to our positioning.
Here we go to the Uber system without a doubt: a parser that allows you to extract any data from the page.
Conceptually, the system combines two approaches:
- Automatically retrieving content based on algorithms such as this Boilerplate Detection using Shallow Text Features . About it will be a separate post.
- Extraction of data "in the forehead" using xpath . Let me remind you, if in a simple way - xpath allows you to search for text in specific tags, for example
//span[contains(@class, 'post_title')]- pull out the header from the span tag with the post_title class .
The system can work both without additional settings, or using manual settings for a specific site.
Parser masks for extracting content
We store all the xpath settings in masks.
The parser receives a page as an input and starts to run it in different masks, passing from one to another. Each mask tries to isolate something from the html page and append to the received document: title, picture, article text. For example, there is a mask that extracts Open Graph tags and appends their contents to the document:
//meta[contains(@property, 'og:url')]/@content //meta[contains(@property, 'og:type')]/@content //meta[contains(@property, 'og:image')]/@content //meta[contains(@property, 'og:title')]/@content //meta[contains(@property, 'og:description')]/@content //meta[contains(@property, 'og:site_name')]/@content As we already understand, we describe masks in XML. The code does not require special explanations)
We have quite a lot of such masks - for OG, microdata, discarding pages with noindex, etc.
Thus, you can, in principle, enter the address of the site, and get an acceptable return.
However, many want not just acceptable, but perfect. And here we give you the opportunity to write xpath yourself.
Custom masks
Without extra water, let's see how we extracted data from Habr
/company/ /events/ /post/ /qa/ //div[contains(@class, 'html_format')] //span[contains(@class, 'post_title')] The code doesn’t need explanation) In fact, we told this mask: work only on the pages of posts, companies, events and questions, take the body of the article from a div with the html_format class , a header from span with the post_title class The picture is
extracted at the system (built-in) level masks by the Open Graph tag, so we didn’t remember anything about the picture in our mask.
In the future, we will try to make this process even easier, like Google has in the webmaster panel ( Video )