Introduction to Algorithm Complexity Analysis (Part 3)
- Transfer
- Tutorial
From the translator: this text is given with minor abbreviations due to places of excessive "chewed up" material. The author absolutely rightly warns that certain topics may seem too simple or well-known to the reader. Nevertheless, to me personally this text helped to streamline the existing knowledge on the analysis of the complexity of algorithms. I hope that it will be useful to someone else.
Due to the large volume of the original article, I broke it into parts, of which there will be a total of four.
I (as always) will be extremely grateful for any comments in PM on improving the quality of translation.
Published earlier:
Part 1
Part 2

If you know what logarithms are, then you can safely skip this section. The chapter is intended for those who are unfamiliar with this concept or use it so rarely that they have already forgotten what's what. Logarithms are important because they are very common in complexity analysis. A logarithm is an operation that, when applied to a number, makes it much smaller (like taking the square root). So, the first thing you should remember: the logarithm returns a number less than the original. In the figure to the right, the green graph is a linear function
I will explain with an example. Consider the equation
To find from it
Practical recommendation: in competitions, algorithms are often implemented in C ++. Once you have analyzed the complexity of your algorithm, you can immediately get a rough estimate of how fast it will work, assuming that 1,000,000 instructions are executed per second. Their number is calculated from the asymptotic estimation function that you received that describes the algorithm. For example, a calculation using the algorithm with Θ (n) will take about a second for n = 1,000,000.
Now let's turn to recursive functions. A recursive function is a function that calls itself. Can we analyze its complexity? The following function, written in Python, calculates the factorial of a given number. The factorial of a positive integer is found as the product of all previous positive integers. For example, factorial 5 is this
Let's analyze this feature. It does not contain cycles, but its complexity is still not constant. Well, you have to do the counting of instructions again. Obviously, if we apply this function to some
If you are still not sure about this, then you can always find the exact complexity by counting the number of instructions. Apply this method to this function to find its f (n), and make sure it is linear (recall that linear means
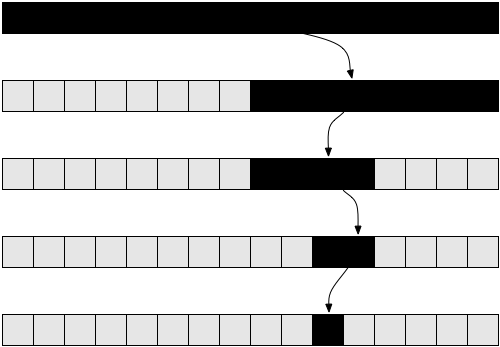
One of the most famous tasks in computer science is to search for values in an array. We already solved it earlier for the general case. The task becomes more interesting if we have a sorted array in which we want to find the given value. One way to do this is binary search . We take the middle element from our array: if it matches what we were looking for, then the problem is solved. Otherwise, if the given value is greater than this element, then we know that it must lie on the right side of the array. And if less - then in the left. We will break these subarrays until we get the desired one.
Here is the implementation of such a method in pseudocode:
The given pseudo code is a simplification of the real implementation. In practice, this method is easier to describe than to implement, since the programmer needs to solve some additional issues. For example, error protection by one position ( off-by-one error, OBOE ), and division by two may not always give an integer, so you need to use the functions
If you are not sure that the method works in principle, then get distracted and manually solve some simple example.
Now let's try to analyze this algorithm. Once again, in this case we have a recursive algorithm. Let's assume for simplicity that the array is always split exactly in half, ignoring the +1 and -1 parts in the recursive call. At this point, you should be sure that such a small change as ignoring +1 and -1 will not affect the final result of the complexity assessment. In principle, it is usually necessary to prove this fact if we want to be careful from a mathematical point of view. But in practice, this is obvious at the level of intuition. Also, for simplicity, let's assume that our array has the size of one of the powers of two. Again, this assumption will in no way affect the final result of calculating the complexity of the algorithm. The worst-case scenario for this task would be the option when the array basically does not contain the desired value. In this case, we start with an array of size
0th iteration:
1st iteration:
2nd iteration:
3rd iteration:
...
i-iteration:
...
last iteration:
Notice that at the i-th iteration has
Equality will be true only when we reach the final function call
If you read the section on the logarithms above, then this expression will be familiar to you. Solving it, we get:
This answer tells us that the number of iterations required for a binary search equals
If you think a little, it makes sense. For example, take
The last result allows us to compare binary search with linear search (our previous method). Undoubtedly,
Practical recommendation: improving the asymptotic execution time of a program often greatly increases its productivity. Much stronger than a small "technical" optimization in the form of using a faster programming language.
Due to the large volume of the original article, I broke it into parts, of which there will be a total of four.
I (as always) will be extremely grateful for any comments in PM on improving the quality of translation.
Published earlier:
Part 1
Part 2
Logarithms
If you know what logarithms are, then you can safely skip this section. The chapter is intended for those who are unfamiliar with this concept or use it so rarely that they have already forgotten what's what. Logarithms are important because they are very common in complexity analysis. A logarithm is an operation that, when applied to a number, makes it much smaller (like taking the square root). So, the first thing you should remember: the logarithm returns a number less than the original. In the figure to the right, the green graph is a linear function
f(n) = n, the red is f(n) = sqrt(n), and the least rapidly increasing is f(n) = log(n). Further: just as taking the square root is the operation inverse of squaring, the logarithm is the inverse operation of raising something to a power.I will explain with an example. Consider the equation
2x. = 1024To find from it
x, we ask ourselves: to what degree do you need to raise 2 to get 1024? Answer: in the tenth. In fact, 210 = 1024 is easy to verify. Logarithms help us describe this problem using a new notation. In this case, 10 is the logarithm of 1024 and is written as log (1024). It reads: "Logarithm 1024". Since we used 2 as the base, such logarithms are called “base 2”. The base can be any number, but in this article we will use only a deuce. If you are an olympiad student and are not familiar with the logarithms, then I recommend that you practiceafter you finish reading this article. In computer science, the base 2 logarithms are more common than any other, since often we have only two entities: 0 and 1. There is also a tendency to split volumetric tasks in half, and, as you know, there are only two. Therefore, for further reading of the article, you only need to have an idea of the base 2 logarithms.Exercise 7
Solve the equations below by writing down the logarithms you are looking for. Use base 2 logarithms only.
- 2 x = 64
- (2 2 ) x = 64
- 4 x = 4
- 2 x = 1
- 2 x + 2 x = 32
- (2 x) * (2 x ) = 64
Decision
Nothing beyond the ideas set forth above is needed here.
- By trial and error, we find that
x = 6. Thus,log( 64 ) = 6 - By the property of degrees (2 2 ) x can be written as 2 2 x . Thus, we obtain that
2x = 6(becauselog( 64 ) = 6from the previous example) and, therefore,x = 3 - Using the knowledge gained in solving the previous example, we write 4 as 2 2 . Then our equation will turn into (2 2 ) x = 4, which is equivalent to 2 2 x . Note that log (4) = 2 (since 2 2 = 4), so that we get
2x = 2wherex = 1. This is easy to see from the original equation, since degree 1 provides the basis for the result - Recalling that degree 0 gives the result 1 (i.e.
log( 1 ) = 0), we getx = 0 - Here we are dealing with the sum, so we can’t directly take the logarithm. However, we notice that
2x+ 2x is the same as2 * (2x). Multiplying by 2 gives2x + 1 , and we get the equation2x + 1= 32. We find thatlog( 32 ) = 5, wherex + 1 = 5andx = 4. - We multiply two powers of two, therefore, we can combine them in 2 2x . It remains to simply solve the
22x equation= 64, which we already did above. Answer:x = 3
Practical recommendation: in competitions, algorithms are often implemented in C ++. Once you have analyzed the complexity of your algorithm, you can immediately get a rough estimate of how fast it will work, assuming that 1,000,000 instructions are executed per second. Their number is calculated from the asymptotic estimation function that you received that describes the algorithm. For example, a calculation using the algorithm with Θ (n) will take about a second for n = 1,000,000.
Recursive complexity
Now let's turn to recursive functions. A recursive function is a function that calls itself. Can we analyze its complexity? The following function, written in Python, calculates the factorial of a given number. The factorial of a positive integer is found as the product of all previous positive integers. For example, factorial 5 is this
5 * 4 * 3 * 2 * 1. It is designated as “5!” And pronounced “factorial of five” (however, some prefer “FIVE !!! 11”).def factorial( n ):
if n == 1:
return 1
return n * factorial( n - 1 )
Let's analyze this feature. It does not contain cycles, but its complexity is still not constant. Well, you have to do the counting of instructions again. Obviously, if we apply this function to some
n, then it will be calculated nonce. (If you are not sure about this, you can manually schedule the calculation of when n = 5to determine how it actually works.) Thus, we see what this function is Θ( n ). If you are still not sure about this, then you can always find the exact complexity by counting the number of instructions. Apply this method to this function to find its f (n), and make sure it is linear (recall that linear means
Θ( n )).Logarithmic complexity
One of the most famous tasks in computer science is to search for values in an array. We already solved it earlier for the general case. The task becomes more interesting if we have a sorted array in which we want to find the given value. One way to do this is binary search . We take the middle element from our array: if it matches what we were looking for, then the problem is solved. Otherwise, if the given value is greater than this element, then we know that it must lie on the right side of the array. And if less - then in the left. We will break these subarrays until we get the desired one.
Here is the implementation of such a method in pseudocode:
def binarySearch( A, n, value ):
if n = 1:
if A[ 0 ] = value:
return true
else:
return false
if value < A[ n / 2 ]:
return binarySearch( A[ 0...( n / 2 - 1 ) ], n / 2 - 1, value )
else if value > A[ n / 2 ]:
return binarySearch( A[ ( n / 2 + 1 )...n ], n / 2 - 1, value )
else:
return true
The given pseudo code is a simplification of the real implementation. In practice, this method is easier to describe than to implement, since the programmer needs to solve some additional issues. For example, error protection by one position ( off-by-one error, OBOE ), and division by two may not always give an integer, so you need to use the functions
floor()or ceil(). However, suppose that in our case, the division will always be successful, our code is protected from off-by-one errors, and all we want to do is analyze the complexity of this method. If you have never implemented binary search before, you can do it in your favorite programming language. Such a task is truly instructive.If you are not sure that the method works in principle, then get distracted and manually solve some simple example.
Now let's try to analyze this algorithm. Once again, in this case we have a recursive algorithm. Let's assume for simplicity that the array is always split exactly in half, ignoring the +1 and -1 parts in the recursive call. At this point, you should be sure that such a small change as ignoring +1 and -1 will not affect the final result of the complexity assessment. In principle, it is usually necessary to prove this fact if we want to be careful from a mathematical point of view. But in practice, this is obvious at the level of intuition. Also, for simplicity, let's assume that our array has the size of one of the powers of two. Again, this assumption will in no way affect the final result of calculating the complexity of the algorithm. The worst-case scenario for this task would be the option when the array basically does not contain the desired value. In this case, we start with an array of size
non the first recursive call, n / 2on the second, n / 4on the third and so on. In general, our array is split in half on each call until we reach unity. Let's write down the number of elements in the array on each call: 0th iteration:
n1st iteration:
n / 22nd iteration:
n / 43rd iteration:
n / 8...
i-iteration:
n / 2i...
last iteration:
1Notice that at the i-th iteration has
n / 2i elements. Each time we split it in half, which means dividing the number of elements by two (equivalent to multiplying the denominator by two). Having done this ionce, we get n / 2i . The process will continue, and out of every bigiwe will get fewer items until we reach one. If we want to know at what iteration this happened, we will just need to solve the following equation: 1 = n / 2iEquality will be true only when we reach the final function call
binarySearch(), so that having learned from it i, we will know the number of the last recursive iteration. Multiplying both parts by 2i , we get: 2i = nIf you read the section on the logarithms above, then this expression will be familiar to you. Solving it, we get:
i = log( n )This answer tells us that the number of iterations required for a binary search equals
log( n ), where nis the size of the original array.If you think a little, it makes sense. For example, take
n = 32(an array of 32 elements). How many times will we need to split it to get one item? We consider: 32 → 16 → 8 → 4 → 2 → 1 - a total of 5 times, which is the logarithm of 32. Thus, the complexity of the binary search is equal Θ( log( n ) ). The last result allows us to compare binary search with linear search (our previous method). Undoubtedly,
log( n )much less n, from which it is legitimate to conclude that the first is much faster than the second. So it makes sense to store arrays in sorted form if we are going to often look for values in them.Practical recommendation: improving the asymptotic execution time of a program often greatly increases its productivity. Much stronger than a small "technical" optimization in the form of using a faster programming language.