Mini ai cup 2 or almost AgarIO - what could be done to win
Hello! This time I want to write about how I managed to win the competition Mini AI Cup 2 . As in my previous article , there will be almost no implementation details. This time the task was less voluminous, but still there were a lot of nuances and trifles affecting the behavior of the bot. As a result, even after almost three weeks of active work on the bot, there were still ideas on how to improve the strategy.
Under the cat a lot of gifs and traffic.
Persistent will understand, the rest will run away in horror (from the comments to thebrief condensed part).
Those who are too lazy to read a lot can go to the penultimate spoiler of the article to view abrief, concise description of the algorithm , and then you can start reading from the beginning .
Link to github sources .
Like last time, it took me quite a lot of thinking time, where to start. The choice was also between two languages: Java, which I used to be familiar to me, and C ++ that has already been forgotten since student days. But since from the very beginning it seemed to me that the main obstacle for writing a good bot would be not so much the speed of development as the performance of the final solution, the choice still fell on C ++.
After the successful experience of using my own visualizer to debug a bot in previous competitions, I didn’t want to do without one again. But the visualizer that I wrote for myself on Qt for CodeWars did not look like an ideal solution for me, and I decided to use thisvisualizer. It was also made for CodeWars, but did not require serious processing for use in this competition. Relative simplicity in connection and convenience of a draw call anywhere in the code played in his favor.
As before, I really wanted to debug any tick in the game - having the opportunity to launch a strategy on an arbitrary moment of the tested game. Since this task could not be solved by the connected visualizer, then using the #ifdef pair (in which I also wrapped pieces of code responsible for drawing), I added a Context class in each tick, which contained all the necessary values of variables from the previous tick. At its core, the solution was similar to what I used in Code Wizards, but this time the approach was formed not so spontaneously. After the simulation of the entire game, it was requested to enter the number of the game tick, which must be re-run. From the array, I got information about the state of the variables in front of this tick, as well as the string obtained by the input strategy, which allowed me to play the moves of my strategy in any necessary order.
On the opening day of the rules, I did not pass by and on the very first evening I looked at what was waiting for us. I didn’t stop to be perturbed by the json input format (yes, it’s convenient, but some participants are starting to learn new or long forgotten old PLs at such competitions, and starting with parsing json isn’t the most pleasant thing), looked at the strange motion formula and somehow proceeded to form a future framework strategy (for understanding the article in the future it is useful to read the rules ). For 2 days I wrote a bunch of classes like Ejection, Virus, Player and others, reading json'a, connecting a single-file library for logging ... And on the evening of the opening of the non-rating sandbox I already had a strategy in terms of strength and almost completely repeating the basic C ++, but Significantly, significantly larger code size.
And then ... I began to figure out the options, how to develop it. Thoughts at the time:
Accurately determined one thing: you need to do a simulation of the world. After all, approximate calculations cannot “beat” cold and accurate calculations? Such considerations, of course, prompted me to look into the code that was responsible for simulating the world on the server, because this time it was laid out in open access along with the rules. After all, there is nothing better than a code that should accurately describe the rules of the world?
So I thought exactly until I started studying the code that was supposed to test our bots on the server and locally. Initially, in terms of clarity and correctness of the code, everything was not very good, and the organizers, together with the participants, began to actively recycle it. During the beta test (capturing a couple of days after it), the changes in the game engine were very serious, and many did not start participating until the testing engine stabilized. But in the end, in my opinion, we got a good working engine to a very suitable game for the competition format. I also did not begin to implement any serious approaches until the locale of the runner stabilized, and for the first week I didn’t do anything sensible about my bot except the bolted visualizer.
On the eve of the first weekend in the evening, a separate group was created in the telegram by the organizers, in which it was assumed that people would be able to help fix and improve the locale runner. I also took part in the work on the engine of the world. After discussions in this chat, I made 2 pull requests to the local runner as a sample: adjusting to the rules of the eating formula (and minor edits in the order of eating), and merging several parts into one agarik with preservation of inertia and center of mass). Then I began to think about how to insert inclined collision physics into this code, because the physics present in the game world at that time was very illogical. Since the collisions between the two agarics in the rules were not described, I asked the organizers for the criteria according to which my implementation of such logic would be acceptable. The answer was this: agarics in a collision should be “soft” (that is, they could move a little on each other), while the logic of the collision with the walls should not be touched (that is, the walls should just stop the agarics, but not repel them). And my next pull request was a serious alteration of physics.
Separately, I would like to highlight this pool request, which quite significantly reduced the intricate code with the analysis of states and a large number of found (and potential) bugs into something much more intelligible.
After bringing the locale runner code into a sane view, I gradually began to transfer the world simulation code from the runner locale to my bot. First of all, it was, of course, the code for simulating the motion of agarics, and at the same time the code for computing the physics of collisions. It took a couple of evenings to get rid of the rewritten code from rewriting bugs (the transfer of logic did not take place at all by copying the code) and approximate estimations of how deeply the calculations needed to be carried out.
The evaluation function for each tick at this point was +1 for the food I ate and -1 for the food eaten by the enemy, as well as slightly higher values for eating each other’s agarics. In constants for eating other agarics, there was initially a difference between eating my opponent, my opponent (and of course a very large penalty for eating my last agarik's opponent), as well as two different rivals of each other (after a couple of days, the last coefficient was 0). In addition, the total fast for all previous ticks of the simulation, each tick was multiplied by 1 + 1e-5, in order to encourage my bot to perform more useful actions even a little earlier, and at the end of the simulation it was added a bonus for the speed of movement in the last tick, also very small . To simulate the movement of agarics, points were chosen at the edge of the map with a step of 15 degrees from the arithmetic mean coordinates of all my agarics, and a point was chosen, when simulating movement to which the evaluation function assumed the greatest value. And already with such a seemingly primitive simulation and simple assessment at that time, the bot quite firmly established itself in the top 10.
On Friday and Saturday evening, a simulator of mergers of agarics was added, a simulation of “undermining” on viruses, and a guessing of the opponent's TTF. The opponent's TTF was quite an interesting calculated value, and to understand at what point the opponent made a split or hit the virus, you could only catch a moment of uncontrolled flight, which could last from a very small number of ticks with a large viscosity and to flight through the entire map. Since the collisions of agarists could lead to a slight excess of their maximum speed, to calculate the opponent's TTF, I made a check that its speed two ticks in a row really corresponds to the speed that can be obtained in free flight two ticks in a row (in free flight the agarics flew strictly straight and with deceleration every tick, strictly equal viscosity). This almost completely eliminated the possibility of a false positive. Also in the process of testing this logic, I noticed that a larger TTF always corresponds to a larger id of the agaric (which I later became convinced of when transferring the codeexplosion on the virus and splitting ), which also cost to use.
Watching the permanent splits in the top 3 (which allowed them to significantly collect food on the map), I added a constant command split to the bot if there was no enemy within sight, and on Sunday morning I found my bot on the second line of the rating. Managing a handful of small agarics greatly increased the rating, but it was much easier for them to lose if it was unsuccessful to stumble upon an opponent. And since the fear of being eaten my agarics had a very conditional (the penalty was only for being devoured in the simulation, but not for approaching an opponent who could eat), the first thing added was the penalty for crossing with an opponent who could eat. And the same score mirror worked as a bonus for the pursuit of an opponent. After checking the CPU consumption with my strategy, I decided to add another simulation circle, when split was done on the first tick (this logic, of course, also needed to be transferred to itself into the code from the locale runner), and then the simulation went exactly the same way as before. Such a variant of logic was not very suitable for “shooting” at the enemy (although sometimes it did by chance split at the very right moment), but it was very good for faster picking up food, which the whole top did at that time. Such modifications allowed to enter the next week on the first line of the rating, although the gap was insignificant. what the top was doing at that time. Such modifications allowed to enter the next week on the first line of the rating, although the gap was insignificant. what the top was doing at that time. Such modifications allowed to enter the next week on the first line of the rating, although the gap was insignificant.
At that time, this was quite enough, the “backbone” of the strategy was developed, the strategy looked rather primitive and expandable. But what I really noticed is the CPU consumption and overall code stability. Therefore, mainly the evenings of the next working part of the week were devoted to improving the accuracy of simulations (what the visualizer helped a lot with), code stabilization (valgrind) and some work speed optimizations.
My next posted strategy, which showed significantly better results and went into separation from rivals (at that time), contained two significant changes: adding a potential field for collecting food and doubling the number of simulations if there is an opponent with an unknown TTF nearby.
The potential field for collecting food in the first version was quite simple and its whole essence was to memorize food that disappeared from the zone of visibility, reducing the potential in those places where the enemy's bot was located and zeroing in my area of visibility (with subsequent recovery every n ticks according to the rules). This seemed to be a useful improvement, but in practice, in my subjective opinion, the difference was either small or not at all. For example, on maps with large inertia and speed, the bot often skipped past food and then tried to return to it, while losing much speed. However, if he decided to maintain speed and simply ignored the missed food, he would eat significantly more.
Quite different in subjective utility was the double simulation of the enemy with different TTF - the minimum and maximum possible (if I do not know the TTF for all visible agarics on the map). And if earlier my bot thought that the enemy handful of agarics would become a single tick for the next tick and move slowly, now he chose the worst scenario of the two and did not risk being close to the enemy, about which he knows less than he would like.
After obtaining a significant advantage, I tried to increase it by adding a definition of the point at which the opponent commanded his agarics to move, and although such a point could be calculated in most cases quite accurately, by itself this did not bring an improvement in the bot's results. According to my observations, it became even worse than the variant, when the agarics of the opponent simply moved in the same direction and with the same speed as if the opponent did nothing, so these edits were saved in a separate git branch until better times.
There were also attempts to transfer the evaluation function to the evaluation of the resulting mass, attempts to change the evaluation function of the danger of the opponent ... But again, all such changes made even worse by the sensations. The only thing that was done was useful with the function of assessing the danger of being close to the enemy - the next performance optimization along with the extension of this assessment to a much larger radius than the radius of intersection with the enemy (essentially the entire map, but with a quadratic decrease, if slightly simplified - making a presence in five or more radii from the opponent in the region of 1/25 of the maximum danger of being eaten). The last change also unplanned led to the fact that my agarics began to be very afraid of approaching a noticeably larger enemy, as well as in the case of their greatly superior sizes, they were more inclined to move towards the opponent. Thus, it turned out a successful and not resource-intensive replacement of the code planned for the future, which was to be responsible for the fear of attacking an opponent through split (and little help in such an attack to me afterwards).
After long and relatively fruitless attempts to improve something, I once again returned to predicting the direction of movement of the opponent. I decided to try, since it is not easy to replace dummy opponents, then do what I did with the minimum and maximum TTF options - simulate twice and choose the best option. But for this, the CPU could not be enough, and in many games my bot could simply be disconnected from the system due to insatiable appetite. Therefore, before implementing such an option, I added an approximate definition of the time spent and, in the case of exceeding the limits, I began to reduce the number of simulation moves. Having added a double simulation of the enemy for the case when I know the place where he is going, I again received a fairly serious increase in most of the game settings,
Before starting the games for 25k ticks, two more useful improvements were made: the penalty for ending the simulation far from the center of the map, as well as memorizing the previous position of the opponent if he left the zone of visibility (as well as simulating his movement at that time). The implementation of the penalty for the final position of the bot in the simulation was the pre-calculated static hazard field with zero hazard in a radius slightly larger than half the length of the playing field and gradually increasing as the distance from the playing field increased. The application of the penalty of this field at the end points of the simulation almost did not require a CPU and prevented unnecessary running into corners, sometimes saving it from enemy attacks. And memorization with subsequent simulation of rivals for the most part allowed to avoid two sometimes manifested problems. The first problem is presented in the gif below.
Also, additional points of motion simulation were added to points on the edge of the map: to each agarik of rivals and in a radius of the arithmetic mean of my agarics every 45 degrees. The radius was set to avgDistance from the arithmetic mean coordinates of my agarics.
At the time of the opening of games for 25k ticks and passing to the final I had a solid lead, but I did not plan to relax.
Along with the new game duration of 25k, news came as well: games during the final will also be 25k duration, and the strategy time limit per tick was slightly longer. Having estimated the time that my strategy spends on the game in the new conditions, I decided to add another simulation option: we do everything as usual, but during the simulation on the move n we split. This, in particular, required for subsequent moves as a basic fast for all simulations to use the simulation found in the previous step, but with a shift of 1 turn (i.e., if we found that the ideal variant would be split 7 times from the current one, then The next move is the same, but we’ll do the split already on move 6). This significantly added aggressive attacks on opponents, but ate a little more time for the strategy.
All further refinements were related solely to the efficiency of simulations in the event of a TL shortage: optimizing the order of shutting down certain parts of the logic depending on the CPU consumed. For most of the games, this shouldn’t have changed anything, but something more correct wouldn’t have come out then.
In general, the start of this competition turned out to be quite blurry, but for the first week and a half, the task was brought into a fairly playable form with the help of the participants. Initially, the task was very variable, and choosing the right approach to its solution did not seem to be a trivial task. It was even more interesting to come up with ways to improve the algorithm without flying out of the limits of CPU consumption. Many thanks to the organizers for the competition held and for sharing the source of the world in open access. The latter, of course, greatly added to their problems at the start, but it greatly facilitated (if not to say what made it possible in principle) the participants understanding the world simulator device. Special thanks for choosing the prize! So the prize came out much more useful :-)Why do I need another macbook?
Under the cat a lot of gifs and traffic.
Persistent will understand, the rest will run away in horror (from the comments to the
Those who are too lazy to read a lot can go to the penultimate spoiler of the article to view a
Link to github sources .
Selection of tools
Like last time, it took me quite a lot of thinking time, where to start. The choice was also between two languages: Java, which I used to be familiar to me, and C ++ that has already been forgotten since student days. But since from the very beginning it seemed to me that the main obstacle for writing a good bot would be not so much the speed of development as the performance of the final solution, the choice still fell on C ++.
After the successful experience of using my own visualizer to debug a bot in previous competitions, I didn’t want to do without one again. But the visualizer that I wrote for myself on Qt for CodeWars did not look like an ideal solution for me, and I decided to use thisvisualizer. It was also made for CodeWars, but did not require serious processing for use in this competition. Relative simplicity in connection and convenience of a draw call anywhere in the code played in his favor.
As before, I really wanted to debug any tick in the game - having the opportunity to launch a strategy on an arbitrary moment of the tested game. Since this task could not be solved by the connected visualizer, then using the #ifdef pair (in which I also wrapped pieces of code responsible for drawing), I added a Context class in each tick, which contained all the necessary values of variables from the previous tick. At its core, the solution was similar to what I used in Code Wizards, but this time the approach was formed not so spontaneously. After the simulation of the entire game, it was requested to enter the number of the game tick, which must be re-run. From the array, I got information about the state of the variables in front of this tick, as well as the string obtained by the input strategy, which allowed me to play the moves of my strategy in any necessary order.
Start
On the opening day of the rules, I did not pass by and on the very first evening I looked at what was waiting for us. I didn’t stop to be perturbed by the json input format (yes, it’s convenient, but some participants are starting to learn new or long forgotten old PLs at such competitions, and starting with parsing json isn’t the most pleasant thing), looked at the strange motion formula and somehow proceeded to form a future framework strategy (for understanding the article in the future it is useful to read the rules ). For 2 days I wrote a bunch of classes like Ejection, Virus, Player and others, reading json'a, connecting a single-file library for logging ... And on the evening of the opening of the non-rating sandbox I already had a strategy in terms of strength and almost completely repeating the basic C ++, but Significantly, significantly larger code size.
And then ... I began to figure out the options, how to develop it. Thoughts at the time:
- Busting through the states of the world does not reduce to those values that can overpower the minimax and modifications;
- Potential fields are good, but they do not respond well to the question of how the world will change next n ticks;
- Genetics and similar algorithms will work, but only 20 msec is given per course, and the depth of calculation is desirable, at first glance, more than the sensations can be processed with the help of GA. Yes, and play with the selection of mutation parameters can be “happily ever after.”
Accurately determined one thing: you need to do a simulation of the world. After all, approximate calculations cannot “beat” cold and accurate calculations? Such considerations, of course, prompted me to look into the code that was responsible for simulating the world on the server, because this time it was laid out in open access along with the rules. After all, there is nothing better than a code that should accurately describe the rules of the world?
So I thought exactly until I started studying the code that was supposed to test our bots on the server and locally. Initially, in terms of clarity and correctness of the code, everything was not very good, and the organizers, together with the participants, began to actively recycle it. During the beta test (capturing a couple of days after it), the changes in the game engine were very serious, and many did not start participating until the testing engine stabilized. But in the end, in my opinion, we got a good working engine to a very suitable game for the competition format. I also did not begin to implement any serious approaches until the locale of the runner stabilized, and for the first week I didn’t do anything sensible about my bot except the bolted visualizer.
On the eve of the first weekend in the evening, a separate group was created in the telegram by the organizers, in which it was assumed that people would be able to help fix and improve the locale runner. I also took part in the work on the engine of the world. After discussions in this chat, I made 2 pull requests to the local runner as a sample: adjusting to the rules of the eating formula (and minor edits in the order of eating), and merging several parts into one agarik with preservation of inertia and center of mass). Then I began to think about how to insert inclined collision physics into this code, because the physics present in the game world at that time was very illogical. Since the collisions between the two agarics in the rules were not described, I asked the organizers for the criteria according to which my implementation of such logic would be acceptable. The answer was this: agarics in a collision should be “soft” (that is, they could move a little on each other), while the logic of the collision with the walls should not be touched (that is, the walls should just stop the agarics, but not repel them). And my next pull request was a serious alteration of physics.
Before and after reworking physics
Such a physics of collisions was:
And it became such after the updates:
And it became such after the updates:
Separately, I would like to highlight this pool request, which quite significantly reduced the intricate code with the analysis of states and a large number of found (and potential) bugs into something much more intelligible.
We write a simulation
After bringing the locale runner code into a sane view, I gradually began to transfer the world simulation code from the runner locale to my bot. First of all, it was, of course, the code for simulating the motion of agarics, and at the same time the code for computing the physics of collisions. It took a couple of evenings to get rid of the rewritten code from rewriting bugs (the transfer of logic did not take place at all by copying the code) and approximate estimations of how deeply the calculations needed to be carried out.
The evaluation function for each tick at this point was +1 for the food I ate and -1 for the food eaten by the enemy, as well as slightly higher values for eating each other’s agarics. In constants for eating other agarics, there was initially a difference between eating my opponent, my opponent (and of course a very large penalty for eating my last agarik's opponent), as well as two different rivals of each other (after a couple of days, the last coefficient was 0). In addition, the total fast for all previous ticks of the simulation, each tick was multiplied by 1 + 1e-5, in order to encourage my bot to perform more useful actions even a little earlier, and at the end of the simulation it was added a bonus for the speed of movement in the last tick, also very small . To simulate the movement of agarics, points were chosen at the edge of the map with a step of 15 degrees from the arithmetic mean coordinates of all my agarics, and a point was chosen, when simulating movement to which the evaluation function assumed the greatest value. And already with such a seemingly primitive simulation and simple assessment at that time, the bot quite firmly established itself in the top 10.
Demonstration of points, the command of movement to which the algorithm was originally simulated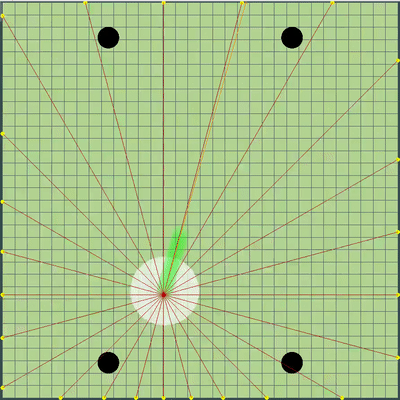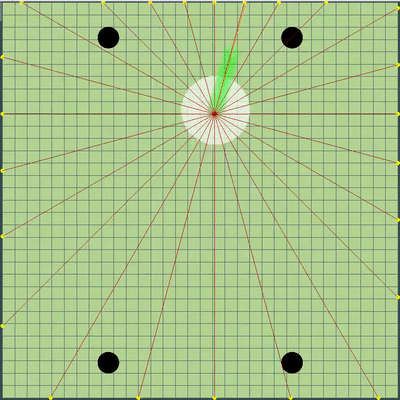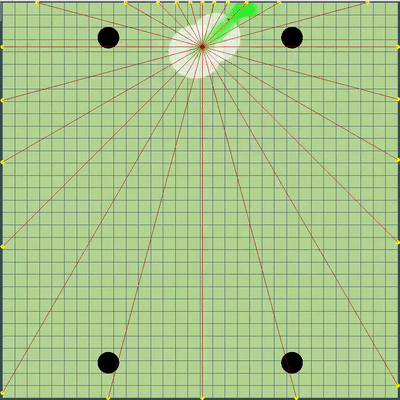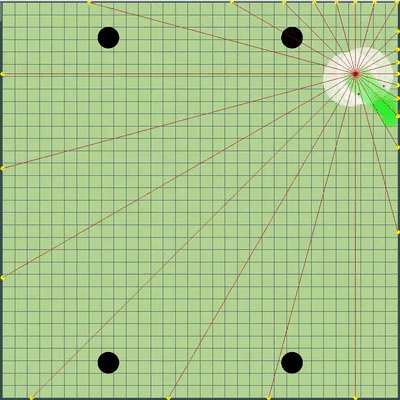
Points, the command of the movement to which was given at different simulations. If you look closely - the final command given is sometimes shifted relative to the enumerated points, but these are consequences of future alterations.
Points, the command of the movement to which was given at different simulations. If you look closely - the final command given is sometimes shifted relative to the enumerated points, but these are consequences of future alterations.
On Friday and Saturday evening, a simulator of mergers of agarics was added, a simulation of “undermining” on viruses, and a guessing of the opponent's TTF. The opponent's TTF was quite an interesting calculated value, and to understand at what point the opponent made a split or hit the virus, you could only catch a moment of uncontrolled flight, which could last from a very small number of ticks with a large viscosity and to flight through the entire map. Since the collisions of agarists could lead to a slight excess of their maximum speed, to calculate the opponent's TTF, I made a check that its speed two ticks in a row really corresponds to the speed that can be obtained in free flight two ticks in a row (in free flight the agarics flew strictly straight and with deceleration every tick, strictly equal viscosity). This almost completely eliminated the possibility of a false positive. Also in the process of testing this logic, I noticed that a larger TTF always corresponds to a larger id of the agaric (which I later became convinced of when transferring the codeexplosion on the virus and splitting ), which also cost to use.
Watching the permanent splits in the top 3 (which allowed them to significantly collect food on the map), I added a constant command split to the bot if there was no enemy within sight, and on Sunday morning I found my bot on the second line of the rating. Managing a handful of small agarics greatly increased the rating, but it was much easier for them to lose if it was unsuccessful to stumble upon an opponent. And since the fear of being eaten my agarics had a very conditional (the penalty was only for being devoured in the simulation, but not for approaching an opponent who could eat), the first thing added was the penalty for crossing with an opponent who could eat. And the same score mirror worked as a bonus for the pursuit of an opponent. After checking the CPU consumption with my strategy, I decided to add another simulation circle, when split was done on the first tick (this logic, of course, also needed to be transferred to itself into the code from the locale runner), and then the simulation went exactly the same way as before. Such a variant of logic was not very suitable for “shooting” at the enemy (although sometimes it did by chance split at the very right moment), but it was very good for faster picking up food, which the whole top did at that time. Such modifications allowed to enter the next week on the first line of the rating, although the gap was insignificant. what the top was doing at that time. Such modifications allowed to enter the next week on the first line of the rating, although the gap was insignificant. what the top was doing at that time. Such modifications allowed to enter the next week on the first line of the rating, although the gap was insignificant.
At that time, this was quite enough, the “backbone” of the strategy was developed, the strategy looked rather primitive and expandable. But what I really noticed is the CPU consumption and overall code stability. Therefore, mainly the evenings of the next working part of the week were devoted to improving the accuracy of simulations (what the visualizer helped a lot with), code stabilization (valgrind) and some work speed optimizations.
We go to the gap
My next posted strategy, which showed significantly better results and went into separation from rivals (at that time), contained two significant changes: adding a potential field for collecting food and doubling the number of simulations if there is an opponent with an unknown TTF nearby.
The potential field for collecting food in the first version was quite simple and its whole essence was to memorize food that disappeared from the zone of visibility, reducing the potential in those places where the enemy's bot was located and zeroing in my area of visibility (with subsequent recovery every n ticks according to the rules). This seemed to be a useful improvement, but in practice, in my subjective opinion, the difference was either small or not at all. For example, on maps with large inertia and speed, the bot often skipped past food and then tried to return to it, while losing much speed. However, if he decided to maintain speed and simply ignored the missed food, he would eat significantly more.
Potential food collection field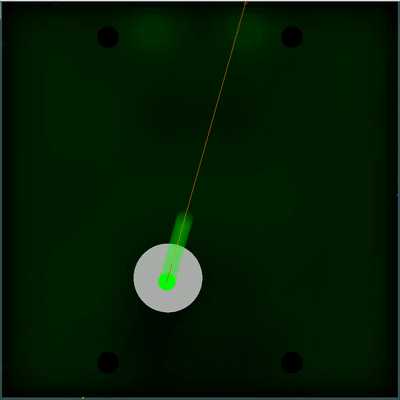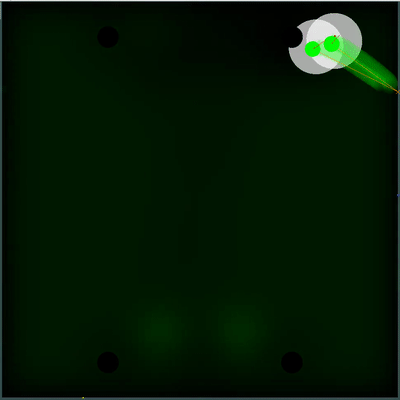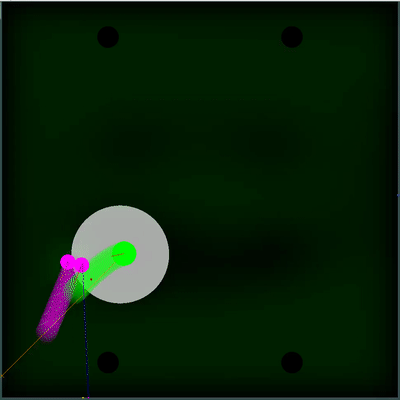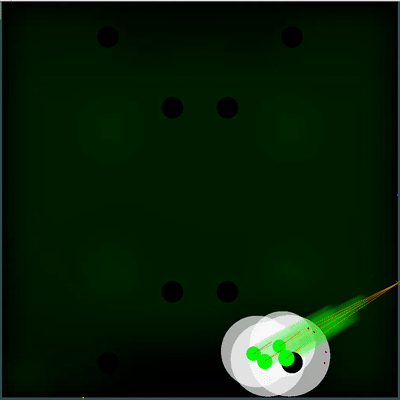
Можно обратить внимание, как каждые 40 тиков поле становится чуть ярче. Каждые 40 тиков поле обновляется в соответствии с тем, как добавляется еда по карте, и вероятность появление еды равномерно «размазывается» по полю. Если на этом тике мы видим, что появилась еда, которую мы видели бы на предыдущем тике — вероятность появление этой еды не «размазывается» вместе с остальными, а задаётся конкретными точками (еда появляется каждые 40 тиков строго симметрично).
Можно обратить внимание, как каждые 40 тиков поле становится чуть ярче. Каждые 40 тиков поле обновляется в соответствии с тем, как добавляется еда по карте, и вероятность появление еды равномерно «размазывается» по полю. Если на этом тике мы видим, что появилась еда, которую мы видели бы на предыдущем тике — вероятность появление этой еды не «размазывается» вместе с остальными, а задаётся конкретными точками (еда появляется каждые 40 тиков строго симметрично).
Quite different in subjective utility was the double simulation of the enemy with different TTF - the minimum and maximum possible (if I do not know the TTF for all visible agarics on the map). And if earlier my bot thought that the enemy handful of agarics would become a single tick for the next tick and move slowly, now he chose the worst scenario of the two and did not risk being close to the enemy, about which he knows less than he would like.
After obtaining a significant advantage, I tried to increase it by adding a definition of the point at which the opponent commanded his agarics to move, and although such a point could be calculated in most cases quite accurately, by itself this did not bring an improvement in the bot's results. According to my observations, it became even worse than the variant, when the agarics of the opponent simply moved in the same direction and with the same speed as if the opponent did nothing, so these edits were saved in a separate git branch until better times.
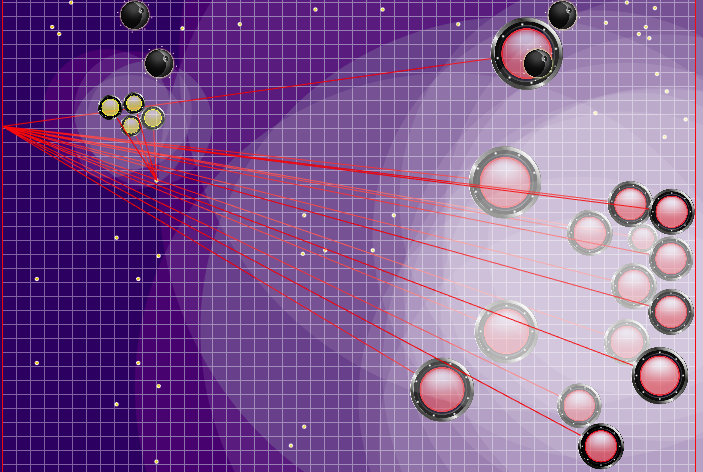
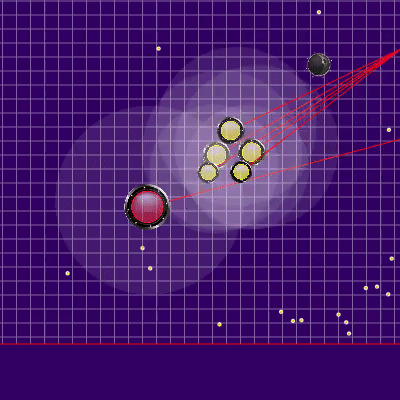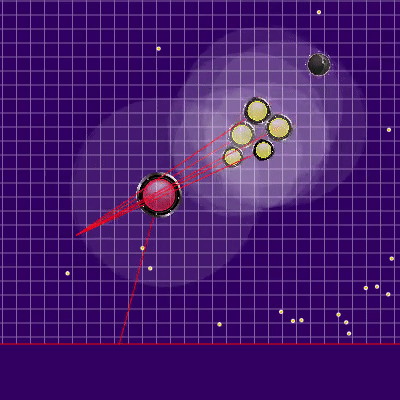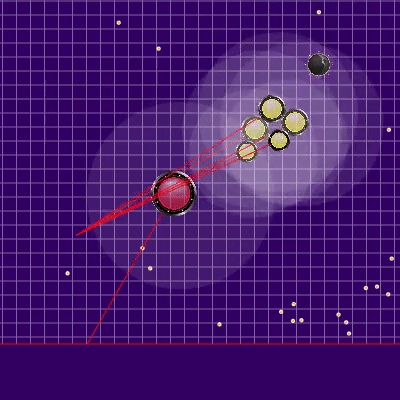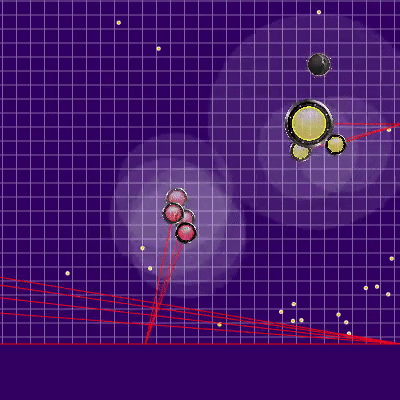
The definition of the enemy team that was used later
Лучами из агариков соперника показана предполагаемая команда, которую соперник отдавал своим агарикам на предыдущем тике. Синие лучи — точное направление, в котором агарик менял направление на прошлом тике. Чёрные — предполагаемое. Более точно определить направление команды можно было только в случае, если агарик полностью в зоне нашей видимости (можно было просчитать влияние коллизий на изменение его скорости). Место пересечения лучей и есть предполагаемая команда соперника. Гифка сделана на базе игры aicups.ru/session/200710, около 3000 тика.
Лучами из агариков соперника показана предполагаемая команда, которую соперник отдавал своим агарикам на предыдущем тике. Синие лучи — точное направление, в котором агарик менял направление на прошлом тике. Чёрные — предполагаемое. Более точно определить направление команды можно было только в случае, если агарик полностью в зоне нашей видимости (можно было просчитать влияние коллизий на изменение его скорости). Место пересечения лучей и есть предполагаемая команда соперника. Гифка сделана на базе игры aicups.ru/session/200710, около 3000 тика.
There were also attempts to transfer the evaluation function to the evaluation of the resulting mass, attempts to change the evaluation function of the danger of the opponent ... But again, all such changes made even worse by the sensations. The only thing that was done was useful with the function of assessing the danger of being close to the enemy - the next performance optimization along with the extension of this assessment to a much larger radius than the radius of intersection with the enemy (essentially the entire map, but with a quadratic decrease, if slightly simplified - making a presence in five or more radii from the opponent in the region of 1/25 of the maximum danger of being eaten). The last change also unplanned led to the fact that my agarics began to be very afraid of approaching a noticeably larger enemy, as well as in the case of their greatly superior sizes, they were more inclined to move towards the opponent. Thus, it turned out a successful and not resource-intensive replacement of the code planned for the future, which was to be responsible for the fear of attacking an opponent through split (and little help in such an attack to me afterwards).
After long and relatively fruitless attempts to improve something, I once again returned to predicting the direction of movement of the opponent. I decided to try, since it is not easy to replace dummy opponents, then do what I did with the minimum and maximum TTF options - simulate twice and choose the best option. But for this, the CPU could not be enough, and in many games my bot could simply be disconnected from the system due to insatiable appetite. Therefore, before implementing such an option, I added an approximate definition of the time spent and, in the case of exceeding the limits, I began to reduce the number of simulation moves. Having added a double simulation of the enemy for the case when I know the place where he is going, I again received a fairly serious increase in most of the game settings,
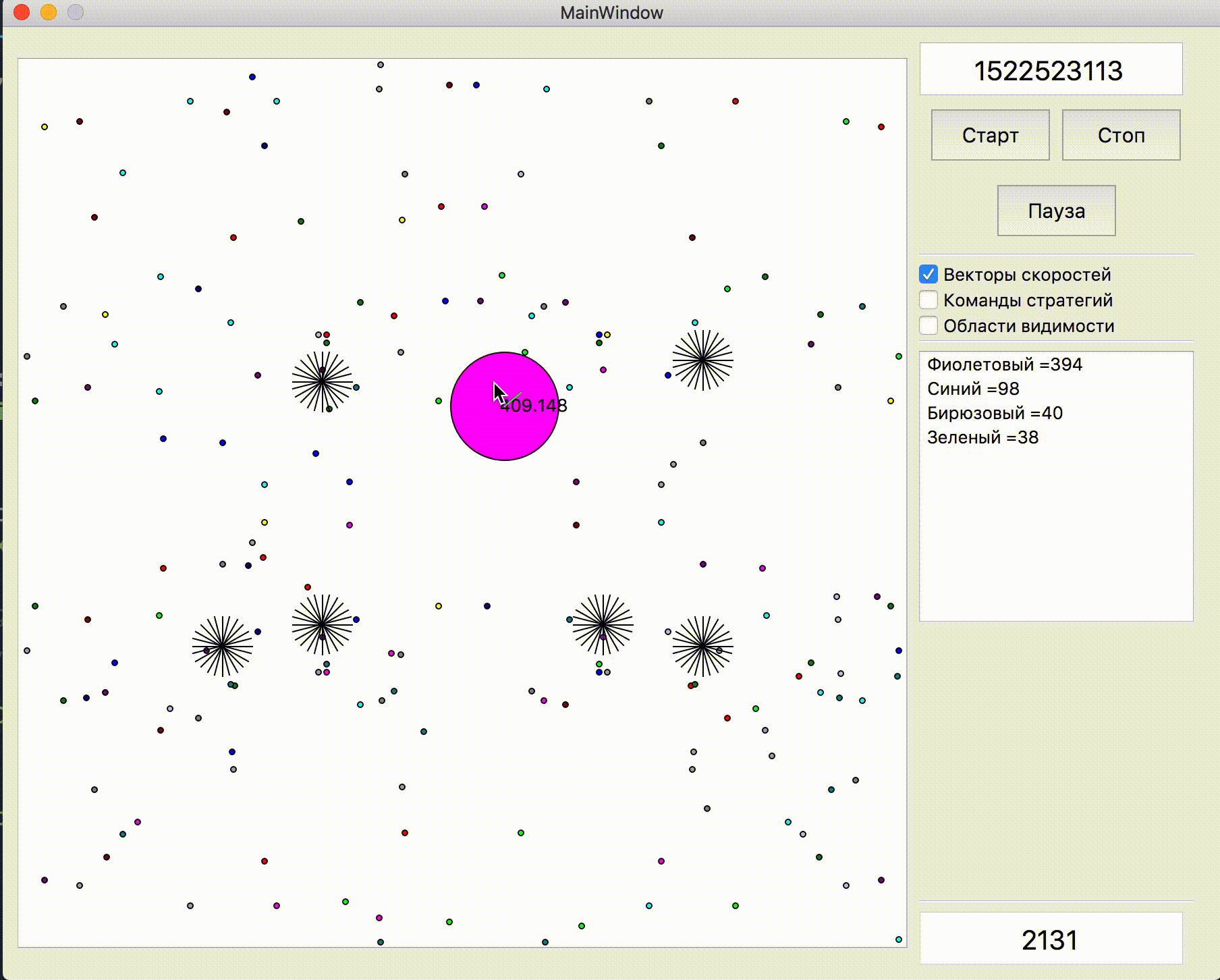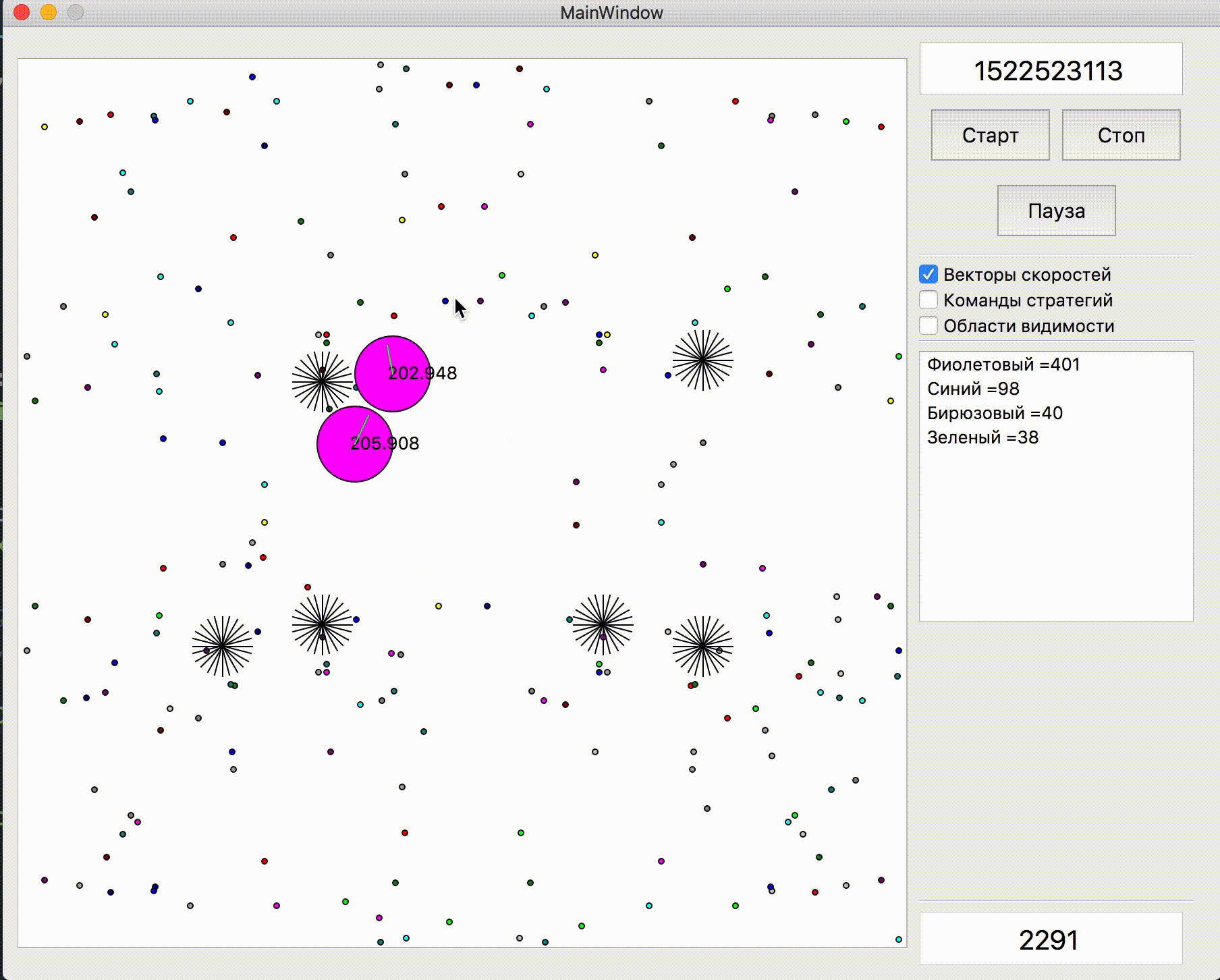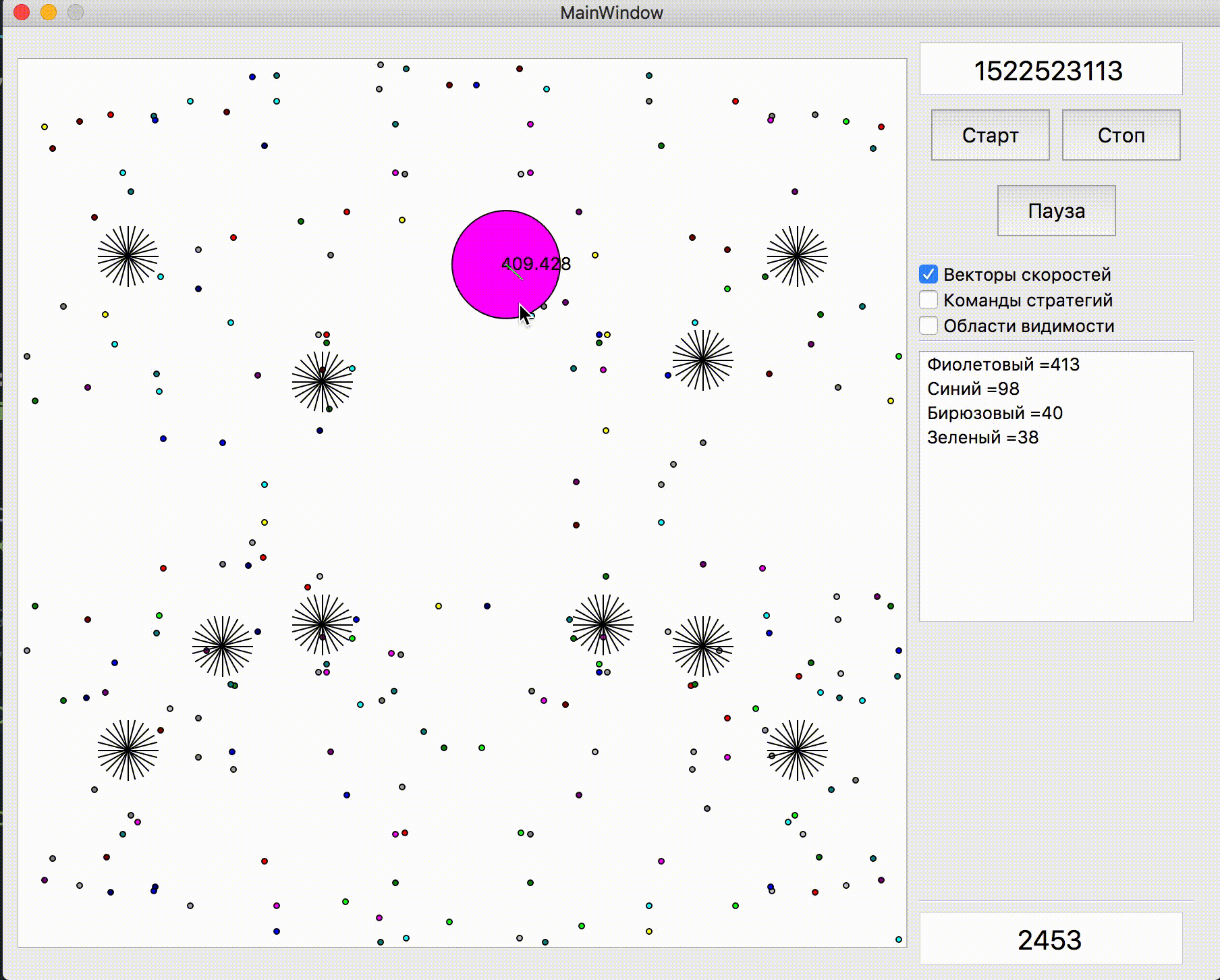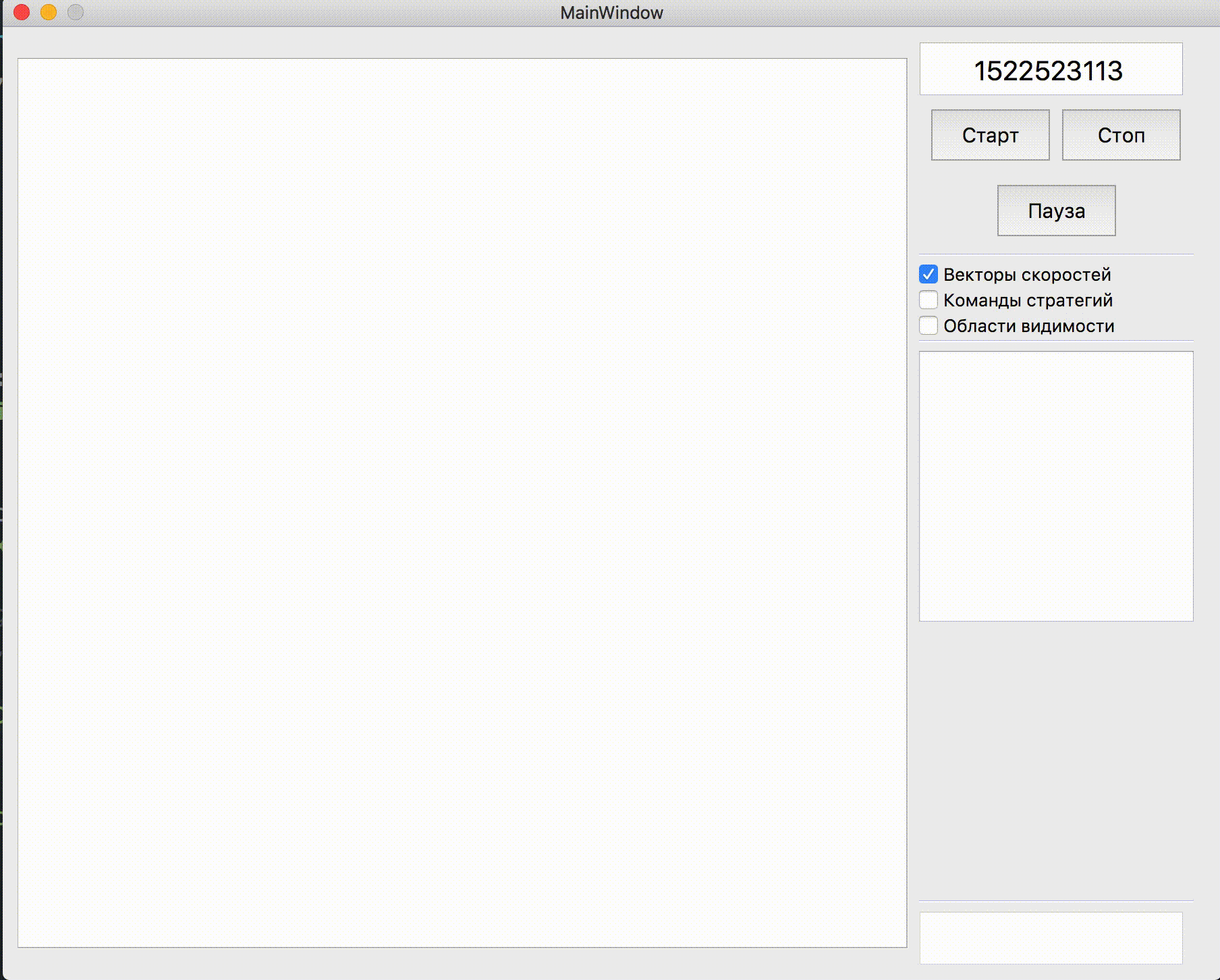
Before starting the games for 25k ticks, two more useful improvements were made: the penalty for ending the simulation far from the center of the map, as well as memorizing the previous position of the opponent if he left the zone of visibility (as well as simulating his movement at that time). The implementation of the penalty for the final position of the bot in the simulation was the pre-calculated static hazard field with zero hazard in a radius slightly larger than half the length of the playing field and gradually increasing as the distance from the playing field increased. The application of the penalty of this field at the end points of the simulation almost did not require a CPU and prevented unnecessary running into corners, sometimes saving it from enemy attacks. And memorization with subsequent simulation of rivals for the most part allowed to avoid two sometimes manifested problems. The first problem is presented in the gif below.
An example of a hazard field for ending a turn in a corner and wasting ticks in vain
Изначально планировались штрафы и рядом со стенами, но в итоге они были добавлены только в углах
Что может происходить, если совсем не помнить предыдущего расположения противника. В данном случае застревание было недолгим, но встречались и куда более серьёзные.
Изначально планировались штрафы и рядом со стенами, но в итоге они были добавлены только в углах
Что может происходить, если совсем не помнить предыдущего расположения противника. В данном случае застревание было недолгим, но встречались и куда более серьёзные.
Also, additional points of motion simulation were added to points on the edge of the map: to each agarik of rivals and in a radius of the arithmetic mean of my agarics every 45 degrees. The radius was set to avgDistance from the arithmetic mean coordinates of my agarics.
New simulation points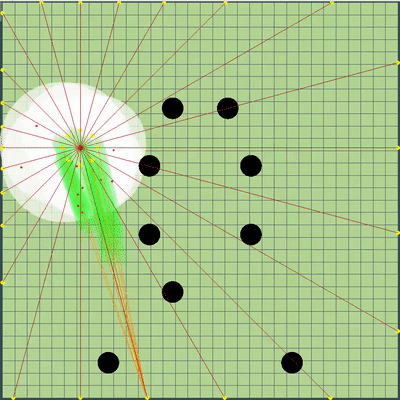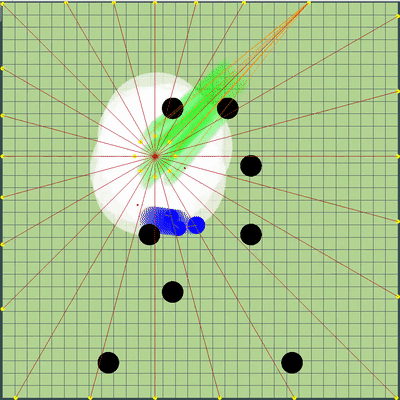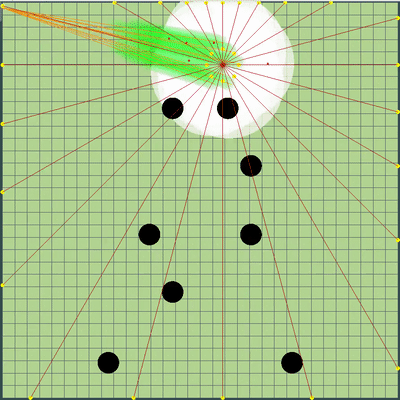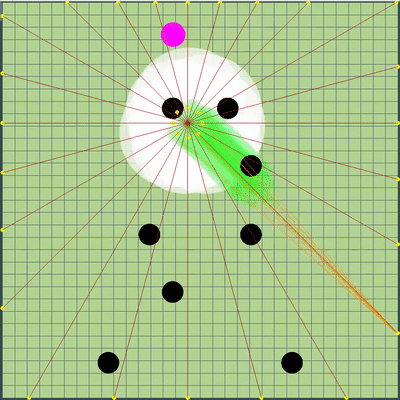
Вокруг центральной точки моих агариков добавились дополнительные точки симуляции. Они только иногда помогали агарикам скорее «собраться» в правильном месте, чтобы съесть соперников. В остальное же время были практически бесполезны.
Вокруг центральной точки моих агариков добавились дополнительные точки симуляции. Они только иногда помогали агарикам скорее «собраться» в правильном месте, чтобы съесть соперников. В остальное же время были практически бесполезны.
Preparation for the final
At the time of the opening of games for 25k ticks and passing to the final I had a solid lead, but I did not plan to relax.
Along with the new game duration of 25k, news came as well: games during the final will also be 25k duration, and the strategy time limit per tick was slightly longer. Having estimated the time that my strategy spends on the game in the new conditions, I decided to add another simulation option: we do everything as usual, but during the simulation on the move n we split. This, in particular, required for subsequent moves as a basic fast for all simulations to use the simulation found in the previous step, but with a shift of 1 turn (i.e., if we found that the ideal variant would be split 7 times from the current one, then The next move is the same, but we’ll do the split already on move 6). This significantly added aggressive attacks on opponents, but ate a little more time for the strategy.
There should have been a concise description of the algorithm.
А получилось вот так
Оценка симуляции:
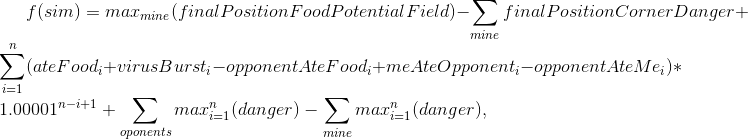
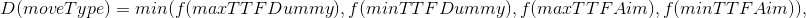
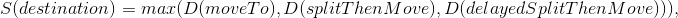
За базовый набор команд брался выбранный на предыдущем тике со сдвигом на 1 тик. Т.е. вызов splitThenMove превращался в вызов moveTo, delayedSplitThenMove менял задержку на сплит с 7 до 6 тиков, а на следующий ход с 6 до 5 и т.д. Дополнительно оценивались два набора команд, сделанных на основе базового — если мы добавим команду сплит на следующем тике и если мы добавим сплит на 7 тике. Выбрав лучшую оценку для трёх наборов команд начинали работать над поиском новых направлений с большей оценкой.
В destination подставлялась:
Каждый следующий оцененный destination сравнивался с текущим набором команд, который набрал максимальную оценку и в случае нахождения новой лучшей оценки заменял предыдущую найденную.
Оценка симуляции:
- f — функция, которая оценивает промежуточные и конечное состояние мира при симуляции с заданными параметрами;
- sim — заранее заданный набор команд и параметры симуляции (моё направление движения, направления соперников, TTF соперников, на каком тике делаем сплит);
- finalPositionFoodPotentialField — очки конкретного агарика, полученный из ПП, отвечающего за близость еды;
- finalPositionCornerDanger — мера опасности нахождения данного агарика в конкретной точке. ПП рассчитано на основе расстояния от цента карты, опасность отлична от нуля только ближе к краям карты;
- n — величина, рассчитываемая исходя из потреблённого стратегией времени и конфигурации мира. Ограничена 10 снизу и 50 сверху;
- ateFood — очки за съеденную моими агариками еду на тике i;
- virusBurst — очки за взрыв одного из моих агариков на вирусе на тике i;
- opponentAteFood — очки за съеденную соперником еду на тике i;
- meAteOpponent — очки за съедение моими агариками соперников;
- opponentAteMe — очки за съедение соперниками моих агариков;
- mine/opponents — оставшиеся в конце симуляции агарики. Т.е. если агарик был съеден или слился во время симуляции — в данной оценке он не участвует;
- danger — оценка риска, которому подвергался агарик, находясь рядом большим агариком соперника.
- moveType — заранее заданный набор команд, куда двигаться и на каком тике делать сплит;
- max/min TTF — симулируем противника считая, что у его агариков минимальный и максимальный TTF из возможных (основано на алгоритме определения TTF соперника);
- dummy/aim — симулируем всех агариков противника как Dummy или на основании определённой с предыдущего тика команды (основано на алгоритме определения точки, команда движения к которой была отдана соперником на предыдущем шаге).
- destination — точка, движение к которой мы хотим симулировать с разными параметрами;
- moveTo — набор команд, где все n тиков отдаётся команда “движемся в заданную точку” без дополнительных параметров;
- splitThenMove — дополнительно к простому движению добавляем команду split на первом тике;
- delayedSplitThenMove — аналогично предыдущему, но split добавляется на седьмом тике.
За базовый набор команд брался выбранный на предыдущем тике со сдвигом на 1 тик. Т.е. вызов splitThenMove превращался в вызов moveTo, delayedSplitThenMove менял задержку на сплит с 7 до 6 тиков, а на следующий ход с 6 до 5 и т.д. Дополнительно оценивались два набора команд, сделанных на основе базового — если мы добавим команду сплит на следующем тике и если мы добавим сплит на 7 тике. Выбрав лучшую оценку для трёх наборов команд начинали работать над поиском новых направлений с большей оценкой.
В destination подставлялась:
- Все направления с шагом в 15 градусов от среднеарифметического координат моих агариков (далее — центральная точка). По 24 направлениям брались точки на краю карты;
- Центральная точка, совпадающая со среднеарифметическим координат моих агариков (даже если агарик был один);
- Если мы не приближались к таймлимитам в текущей игре:
- “преследующее” один из вражеских агариков направление, которое во время симуляции соперника также менялось;
- дополнительные 8 точек вокруг центральной. Расстояние от центральной точки до целевых зависело от удалённости моих агариков от центра.
Каждый следующий оцененный destination сравнивался с текущим набором команд, который набрал максимальную оценку и в случае нахождения новой лучшей оценки заменял предыдущую найденную.
All further refinements were related solely to the efficiency of simulations in the event of a TL shortage: optimizing the order of shutting down certain parts of the logic depending on the CPU consumed. For most of the games, this shouldn’t have changed anything, but something more correct wouldn’t have come out then.
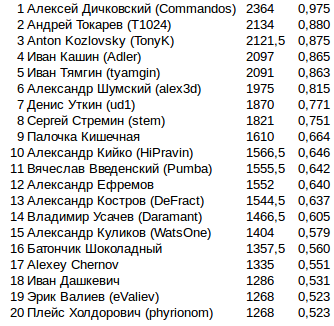
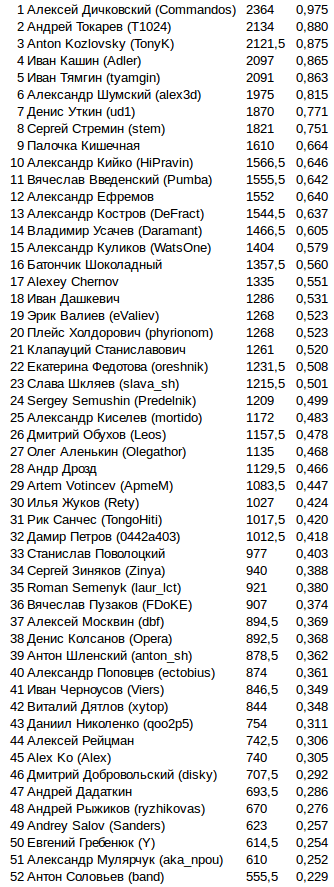
Final points in the final
Последней колонкой добавил какую долю из максимально возможных очков набрал бот. За 808 можно было максимум набрать 2424 очка, если победить во всех играх. Так просто красивее смотрится.
Instead of conclusion
In general, the start of this competition turned out to be quite blurry, but for the first week and a half, the task was brought into a fairly playable form with the help of the participants. Initially, the task was very variable, and choosing the right approach to its solution did not seem to be a trivial task. It was even more interesting to come up with ways to improve the algorithm without flying out of the limits of CPU consumption. Many thanks to the organizers for the competition held and for sharing the source of the world in open access. The latter, of course, greatly added to their problems at the start, but it greatly facilitated (if not to say what made it possible in principle) the participants understanding the world simulator device. Special thanks for choosing the prize! So the prize came out much more useful :-)