How GIL works in Ruby. Part 1
- Transfer
Five out of four developers admit that multi-threaded programming is not easy to understand.
 Most of the time I spent in the Ruby community, the infamous GIL remained a dark horse for me. In this article I will talk about how I finally got to know GIL better.
Most of the time I spent in the Ruby community, the infamous GIL remained a dark horse for me. In this article I will talk about how I finally got to know GIL better.
The first thing I heard about GIL was in no way related to how it works or what it is for. All I heard is that the GIL is bad because it limits concurrency, or that it is good because it makes the code thread safe. The time has come, I got used to multithreaded programming and realized that everything is actually more complicated.
I wanted to know how GIL works from a technical point of view. There is no specification or documentation on GIL. This is essentially a feature of MRI (Matz's Ruby Implementation). The MRI development team says nothing about how GIL works and what guarantees.
However, I am getting ahead of myself.
From the 2008 Parallelism is a Myth in Ruby article by Ilya Grigorik, I got a general understanding of GIL. That's just a common understanding will not help to deal with technical issues. In particular, I want to know if the GIL guarantees the thread safety of certain operations in Ruby. I will give an example.
In Ruby, little is thread safe at all. Take for example adding an element to an array
In this example, each of the five threads adds a thousand times
= (
Even in such a simple example, we are faced with non-thread-safe operations. We will figure out what is happening.
Note that running the code using MRI gives the correct ( perhaps in this context you will like the word “expected” more - approx. Per. ) Result and JRuby and Rubinius do not .. If you run the code again, the situation will happen again, and JRuby and Rubinius will give other (still incorrect) results.
The difference in results is due to the existence of the GIL. Since the MRI has a GIL, despite the fact that five threads work in parallel, only one of them is active at any given time. In other words, true parallelism is not observed here. JRuby and Rubinius do not have a GIL, so when five threads work in parallel, they really parallelize between the available kernels and, if they run non-thread-safe code, can violate data integrity.
How can this be? Thought Ruby wouldn't allow this? Let's see how it is technically possible.
Whether MRI, JRuby or Rubinius, Ruby is implemented in another language: MRI is written in C, JRuby in Java, and Rubinius in Ruby and C ++. Therefore, when performing a single operation in Ruby, for example,
Note that there are at least four different operations:
Each of them refers to other functions. I draw attention to these details in order to show how parallel streams can disrupt data integrity. We are used to linear step-by-step code execution - in a single-threaded environment, you can take a look at a short function in C and easily track the code execution order.
But if we are dealing with multiple threads, this cannot be done. If we have two threads, they can execute different parts of the function code and you have to follow two chains of code execution.
In addition, since threads use shared memory, they can simultaneously modify data. One of the threads can interrupt another, change the general data, after which the other thread will continue execution, being not aware that the data has changed. This is the reason why some Ruby implementations produce unexpected results when simply added
Initially, the system is in the following state:

We have two threads, each of which is about to begin to execute a function. Let steps 1-4 be the pseudo-code of the implementation
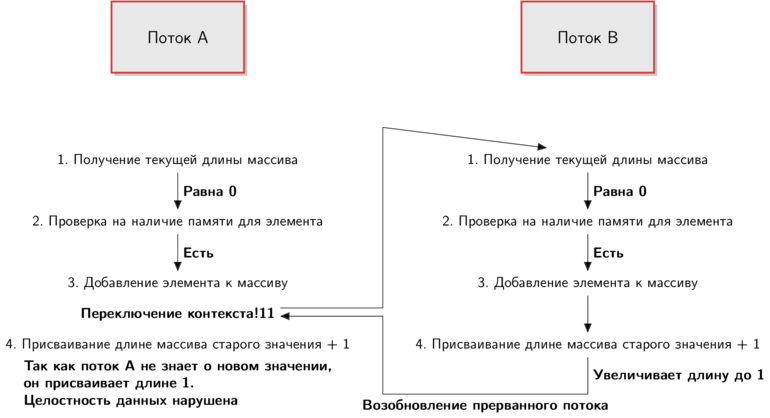
To understand what is happening, just follow the arrows. I added inscriptions reflecting the state of things in terms of each stream.
This is just one of the possible scenarios:
Stream A starts to execute the function code, but when the queue reaches step 3, the context switches. Stream A pauses and it is the turn of stream B, which executes all the function code, adding an element and increasing the length of the array.
After that, thread A resumes exactly from the point at which it was stopped, and this happened just before increasing the length of the array. Thread A sets the length of the array to
Once again: stream B sets the length of the array to
The scenario described above may lead to incorrect results, as we saw in the case of JRuby and Rubinius. But with JRuby and Rubinius it’s still more complicated, since in these implementations the threads can actually work in parallel. In the figure, one thread pauses when the other is running, while in the case of true concurrency, both threads can run simultaneously.
If you run the example above several times using JRuby or Rubinius, you will see that the result is always different. Context switching is unpredictable. It may happen sooner or later, or not at all. I will touch on this topic in the next section.
Why doesn't Ruby protect us from this madness? For the same reason that underlying data structures in other languages are not thread safe: this is too expensive. Ruby implementations might have thread-safe data structures, but this would require an overhead that would make the code even slower. Therefore, the burden of thread safety has been shifted to the programmer.
I have not yet touched on the technical details of the implementation of GIL, and the main question still remains unanswered: why does running the code on MRI still give the correct result?
This question was the reason I wrote this article. A general understanding of the GIL does not give an answer: it is clear that only one thread can execute Ruby code at any given time. But can context switching still happen in the middle of a function?
But first...
Context switching is the task of the OS scheduler. In all the mentioned implementations, one native thread corresponds to one Ruby thread. The OS must ensure that no thread captures all available resources (CPU time, for example), so it implements a schedule so that each thread gets access to resources.
For a stream, this means that it will pause and resume. Each thread receives processor time, after which it is suspended, and the next thread receives access to resources. When the time comes, the flow resumes, and so on.
This is effective from the point of view of the OS, but introduces some randomness and motivates to reconsider the view on the correctness of the program. For example, when doing
If you want to be sure that the thread will not be interrupted in the wrong place, use atomic operations, which ensure that there are no interruptions to completion. Due to this, in our example, the stream will not be interrupted in step 3 and ultimately will not violate the integrity of the data in step 4.
The simplest way to use the atomic operation is to resort to blocking. The following code will produce the same predictable result with MRI, JRuby, and Rubinius thanks to the mutex.
If a thread starts executing a block
We saw how you can use locking to create an atomic operation and ensure thread safety. GIL is also a lock, but does it make the code thread safe? Does GIL turn
Soon the fairy tale affects, but not soon the thing is doneThe article is too large to be read at one time, so I split it into two parts. In the second part, we will look at the implementation of GIL in MRI to answer the questions posed.
The translator will be happy to hear comments and constructive criticism.
Most of the time I spent in the Ruby community, the infamous GIL remained a dark horse for me. In this article I will talk about how I finally got to know GIL better. The first thing I heard about GIL was in no way related to how it works or what it is for. All I heard is that the GIL is bad because it limits concurrency, or that it is good because it makes the code thread safe. The time has come, I got used to multithreaded programming and realized that everything is actually more complicated.
I wanted to know how GIL works from a technical point of view. There is no specification or documentation on GIL. This is essentially a feature of MRI (Matz's Ruby Implementation). The MRI development team says nothing about how GIL works and what guarantees.
However, I am getting ahead of myself.
If you don't know anything about GIL at all, here is a brief description:
There is something called MRI in the MRI (global interpreter lock). Thanks to it, in a multi-threaded environment at some point in time, Ruby-code can be executed in only one thread.
For example, if you have eight threads running on an eight-core processor, only one thread can run at a time. GIL is designed to prevent a race of conditions that could compromise data integrity. There are some subtleties, but the essence is as follows.
From the 2008 Parallelism is a Myth in Ruby article by Ilya Grigorik, I got a general understanding of GIL. That's just a common understanding will not help to deal with technical issues. In particular, I want to know if the GIL guarantees the thread safety of certain operations in Ruby. I will give an example.
Adding an item to an array is not thread safe
In Ruby, little is thread safe at all. Take for example adding an element to an array
array = []
5.times.map do
Thread.new do
1000.times do
array << nil
end
end
end.each(&:join)
puts array.size
In this example, each of the five threads adds a thousand times
nilto the same array. As a result, the array should have five thousand elements, right?$ ruby pushing_nil.rb
5000
$ jruby pushing_nil.rb
4446
$ rbx pushing_nil.rb
3088
= (
Even in such a simple example, we are faced with non-thread-safe operations. We will figure out what is happening.
Note that running the code using MRI gives the correct ( perhaps in this context you will like the word “expected” more - approx. Per. ) Result and JRuby and Rubinius do not .. If you run the code again, the situation will happen again, and JRuby and Rubinius will give other (still incorrect) results.
The difference in results is due to the existence of the GIL. Since the MRI has a GIL, despite the fact that five threads work in parallel, only one of them is active at any given time. In other words, true parallelism is not observed here. JRuby and Rubinius do not have a GIL, so when five threads work in parallel, they really parallelize between the available kernels and, if they run non-thread-safe code, can violate data integrity.
Why concurrent threads can compromise data integrity
How can this be? Thought Ruby wouldn't allow this? Let's see how it is technically possible.
Whether MRI, JRuby or Rubinius, Ruby is implemented in another language: MRI is written in C, JRuby in Java, and Rubinius in Ruby and C ++. Therefore, when performing a single operation in Ruby, for example,
array << nilit may turn out that its implementation consists of tens or even hundreds of lines of code. Here is the implementation Array#<<in MRI:VALUE
rb_ary_push(VALUE ary, VALUE item)
{
long idx = RARRAY_LEN(ary);
ary_ensure_room_for_push(ary, 1);
RARRAY_ASET(ary, idx, item);
ARY_SET_LEN(ary, idx + 1);
return ary;
}
Note that there are at least four different operations:
- Getting current array length
- Check for memory for another item
- Adding an item to an array
- Assigning the length of the array to the old value + 1
Each of them refers to other functions. I draw attention to these details in order to show how parallel streams can disrupt data integrity. We are used to linear step-by-step code execution - in a single-threaded environment, you can take a look at a short function in C and easily track the code execution order.
But if we are dealing with multiple threads, this cannot be done. If we have two threads, they can execute different parts of the function code and you have to follow two chains of code execution.
In addition, since threads use shared memory, they can simultaneously modify data. One of the threads can interrupt another, change the general data, after which the other thread will continue execution, being not aware that the data has changed. This is the reason why some Ruby implementations produce unexpected results when simply added
nilto an array. The situation is similar to that described below. Initially, the system is in the following state:
We have two threads, each of which is about to begin to execute a function. Let steps 1-4 be the pseudo-code of the implementation
Array#<<in the MRI above. The following is a possible development of events (at the initial moment of time, flow A is active):To understand what is happening, just follow the arrows. I added inscriptions reflecting the state of things in terms of each stream.
This is just one of the possible scenarios:
Stream A starts to execute the function code, but when the queue reaches step 3, the context switches. Stream A pauses and it is the turn of stream B, which executes all the function code, adding an element and increasing the length of the array.
After that, thread A resumes exactly from the point at which it was stopped, and this happened just before increasing the length of the array. Thread A sets the length of the array to
1. But stream B has already managed to change the data. Once again: stream B sets the length of the array to
1, after which thread A also assigns it 1, despite the fact that both threads added elements to the array. Data integrity is broken.And I relied on Ruby
The scenario described above may lead to incorrect results, as we saw in the case of JRuby and Rubinius. But with JRuby and Rubinius it’s still more complicated, since in these implementations the threads can actually work in parallel. In the figure, one thread pauses when the other is running, while in the case of true concurrency, both threads can run simultaneously.
If you run the example above several times using JRuby or Rubinius, you will see that the result is always different. Context switching is unpredictable. It may happen sooner or later, or not at all. I will touch on this topic in the next section.
Why doesn't Ruby protect us from this madness? For the same reason that underlying data structures in other languages are not thread safe: this is too expensive. Ruby implementations might have thread-safe data structures, but this would require an overhead that would make the code even slower. Therefore, the burden of thread safety has been shifted to the programmer.
I have not yet touched on the technical details of the implementation of GIL, and the main question still remains unanswered: why does running the code on MRI still give the correct result?
This question was the reason I wrote this article. A general understanding of the GIL does not give an answer: it is clear that only one thread can execute Ruby code at any given time. But can context switching still happen in the middle of a function?
But first...
Blame the planner
Context switching is the task of the OS scheduler. In all the mentioned implementations, one native thread corresponds to one Ruby thread. The OS must ensure that no thread captures all available resources (CPU time, for example), so it implements a schedule so that each thread gets access to resources.
For a stream, this means that it will pause and resume. Each thread receives processor time, after which it is suspended, and the next thread receives access to resources. When the time comes, the flow resumes, and so on.
This is effective from the point of view of the OS, but introduces some randomness and motivates to reconsider the view on the correctness of the program. For example, when doing
Array#<< it should be borne in mind that the thread can be stopped at any time and another thread can execute the same code in parallel, changing the general data.Decision? Use atomic operations
If you want to be sure that the thread will not be interrupted in the wrong place, use atomic operations, which ensure that there are no interruptions to completion. Due to this, in our example, the stream will not be interrupted in step 3 and ultimately will not violate the integrity of the data in step 4.
The simplest way to use the atomic operation is to resort to blocking. The following code will produce the same predictable result with MRI, JRuby, and Rubinius thanks to the mutex.
array = []
mutex = Mutex.new
5.times.map do
Thread.new do
mutex.synchronize do
1000.times do
array << nil
end
end
end
end.each(&:join)
puts array.size
If a thread starts executing a block
mutex.synchronize, other threads are forced to wait for it to complete before starting to execute the same code. Using atomic operations, you get a guarantee that if the context switch happens inside the block, other threads will still not be able to enter it and change the general data. The scheduler will notice this and switch the flow again. Now the code is thread safe.GIL is also a lock
We saw how you can use locking to create an atomic operation and ensure thread safety. GIL is also a lock, but does it make the code thread safe? Does GIL turn
array << nilinto an atomic operation?The translator will be happy to hear comments and constructive criticism.