How to drop 10 million packets per second
- Transfer
In the company, our team for resisting DDoS attacks is called “packet packet droppers”. While all the other teams are doing cool things with traffic passing through our network, we have fun finding new ways to get rid of it.

Photo: Brian Evans , CC BY-SA 2.0 The
ability to quickly drop packets is very important in resisting DDoS attacks.
Dropping packets reaching our servers can be done at several levels. Each method has its pros and cons. Under the cut, we look at everything we tried.
For ease of comparison, we will give you some numbers, however, you should not take them too literally, due to the artificiality of the tests. We will use one of our Intel-servers with a 10Gbit / s network card. The remaining characteristics of the server are not so important, because we want to focus on the limitations of the operating system, not the hardware.
Our tests will look like this:
Artificial traffic is generated in such a way as to create maximum load: a random IP address and port of the sender are used. Here’s something like this in tcpdump:
On the selected server, all packets will be in one RX queue and, therefore, processed by one core. We achieve this with hardware flow control:
Performance testing is a complex process. When we were preparing tests, we noticed that the presence of active raw sockets has a negative effect on performance, so you need to make sure that none of them are running before running the tests
Finally, we disable Intel Turbo Boost on our server:
Despite the fact that Turbo Boost is a great thing and increases throughput by at least 20%, it significantly spoils the standard deviation in our tests. With turbo enabled, the deviation reaches ± 1.5%, while without it only 0.25%.
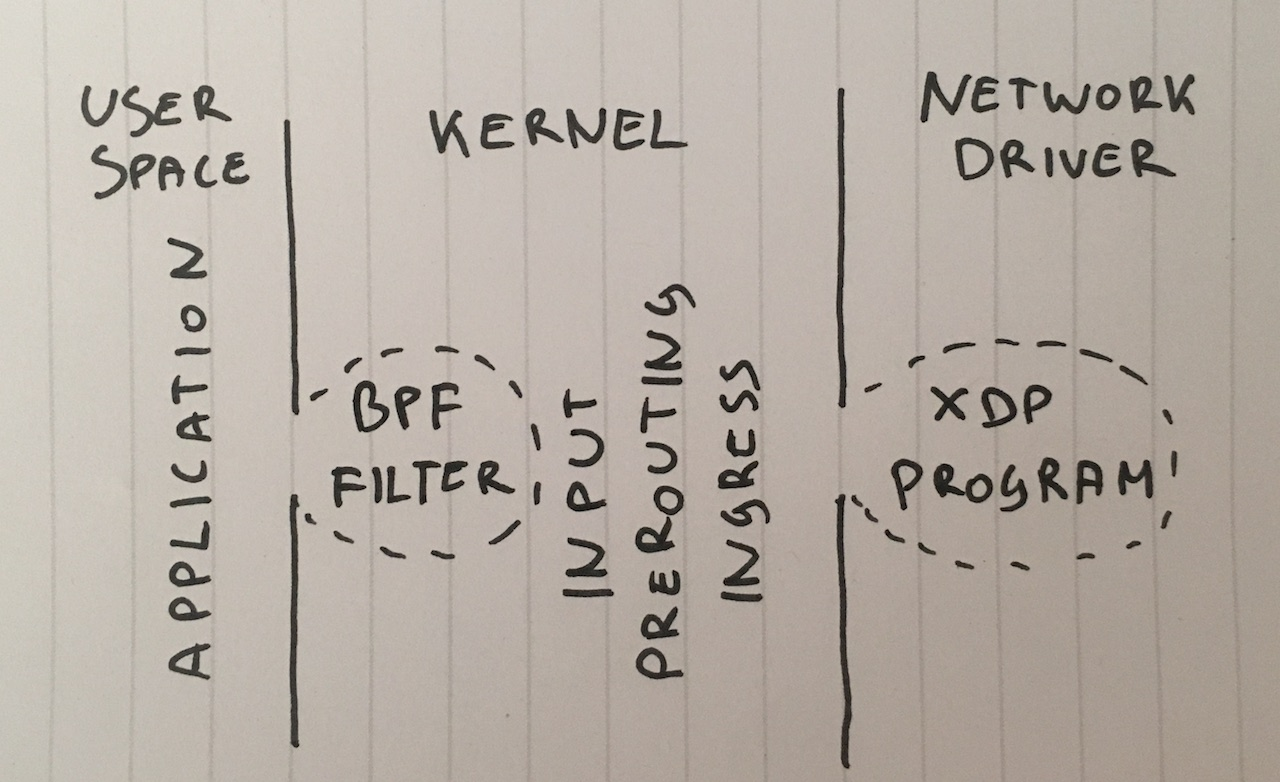
Let's start with the idea of delivering all the packages to the application and ignoring them there. For the integrity of the experiment, make sure that iptables does not affect the performance:
An application is a simple loop in which incoming data is immediately dropped:
We have already prepared the code , run:
This solution allows the kernel to take only 175 thousand packets from the hardware queue, as was measured by the utilities
Technically, the server receives 14 million packets per second, however, one processor core cannot cope with such a volume.
As we can see, the application is not a bottleneck: CPU # 1 is used at 27.17% + 2.17%, while interrupt handling takes 100% on CPU # 2.
Use
We specifically made such a load with different IP and port of the sender in order to load the conntrack as much as possible. The number of entries in the conntrack during the test strives for the maximum possible and we can verify this:
Moreover,
So let's turn it off:
And restart the tests:
This allowed us to reach the level of 333 thousand packets per second. Hooray!
PS With the use of SO_BUSY_POLL we can reach as much as 470 thousand per second, however, this is a topic for a separate post.
Go ahead. Why do we need to deliver packages to the application? Although this is not a common solution, we can tie a classic Berkeley packet filter to a socket by calling
Prepare the code , run:
Using a packet filter (the classic and advanced Berkeley filters give roughly the same performance) we get to about 512,000 packets per second. Moreover, dropping a packet during an interrupt frees the processor from having to wake up the application.
Now we can drop packets by adding the following rule to iptables in the INPUT chain:
Let me remind you that we have already disabled conntrack rule
Look at the numbers in iptables:
Well, not bad, but we can do better.
Faster technology is to drop packets before routing using this rule:
This allows us to discard a solid 1.688 million packets per second.
In fact, this is a slightly surprising jump in performance. I did not understand the reasons, perhaps our routing is difficult, or maybe just a bug in the server configuration.
In any case, raw iptables work much faster.
Now the iptables utility is a bit old. It was replaced by nftables. Check out this video explaining why nftables are top. Nftables promise to be faster than gray iptables for a variety of reasons, including the rumor that retpoline slows down iptables a lot.
But our article is still not about comparing iptables and nftables, so let's just try the quickest thing I could do:
Counters can be seen as:
The nftables input hook showed values of about 1.53 million packets. This is a little less than the prefix chain in iptables. But there is a mystery in it: theoretically, the nftables hook comes earlier than PREROUTING iptables and, therefore, should be processed faster.
In our test, nftables are a bit slower than iptables, but still, nftables are cooler. : P
Somewhat unexpectedly, the tc (traffic control) hook occurs earlier than iptables PREROUTING. tc allows us to select packets according to simple criteria and, of course, discard them. The syntax is a bit unusual, so for the customization we suggest using this script . And we need a rather complicated rule that looks like this:
And we can check it in action:
The tc hook allowed us to drop up to 1.8 million packets per second on a single core. It's fine!
But we can even faster ...
And finally, our strongest weapon: XDP - eXpress Data Path . With XDP, we can run Berkeley’s extended Berkley Packet Filter (eBPF) code directly in the context of the network driver and, most importantly, before allocating memory under
Usually an XDP project consists of two parts:
Writing your bootloader is a difficult task, so just use the new iproute2 chip and load the code with a simple command:
Ta-dam!
The source code for the downloadable eBPF program is available here . The program looks at such characteristics of IP packets as the UDP protocol, the sender's subnet and destination port:
An XDP program must be built using modern clang, which can generate BPF bytecode. After that we can download and test the functionality of the BFP program:
And then see the statistics in
Yu-hoo! With XDP, we can drop up to 10 million packets per second!

Photography: Andrew Filer , CC BY-SA 2.0
We repeated the experiment for IPv4 and for IPv6 and prepared this diagram:
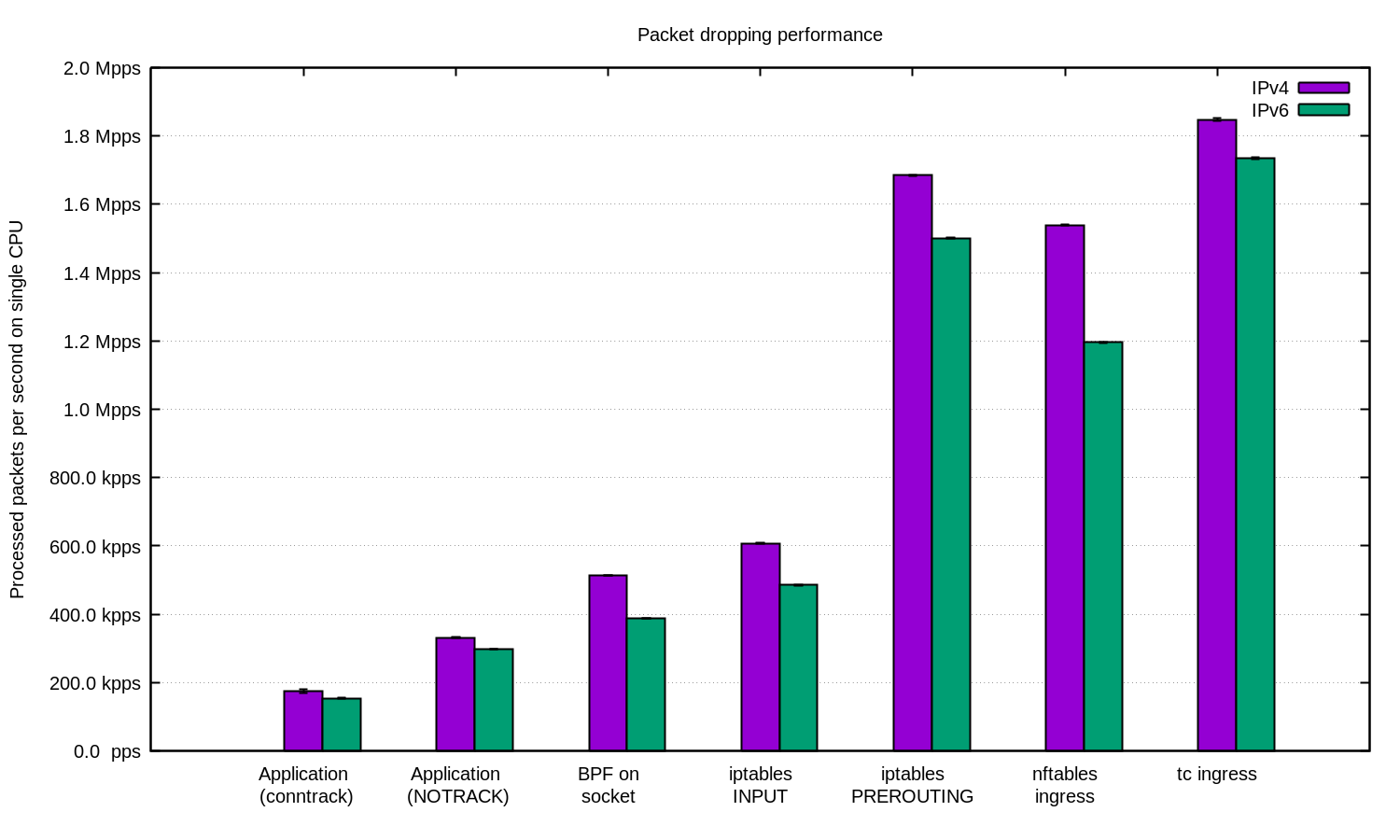
In general, it can be argued that our configuration for IPv6 is a bit slower. But since IPv6 packets are somewhat larger, the difference in speed is expected.
In Linux, there are many ways to filter packets, each with its own speed and complexity of configuration.
To protect against DDoS, it is quite reasonable to give packets to the application and process them there. A well-tuned application can perform well.
For DDoS attacks with random or spoofed IPs, it may be useful to disable conntrack to get a small increase in speed, but beware: there are attacks against which conntrack is very useful.
In other cases, it makes sense to add a Linux firewall as one of the ways to mitigate a DDoS attack. In some cases it is better to use the table "-t raw PREROUTING", since it is much faster than the table filter.
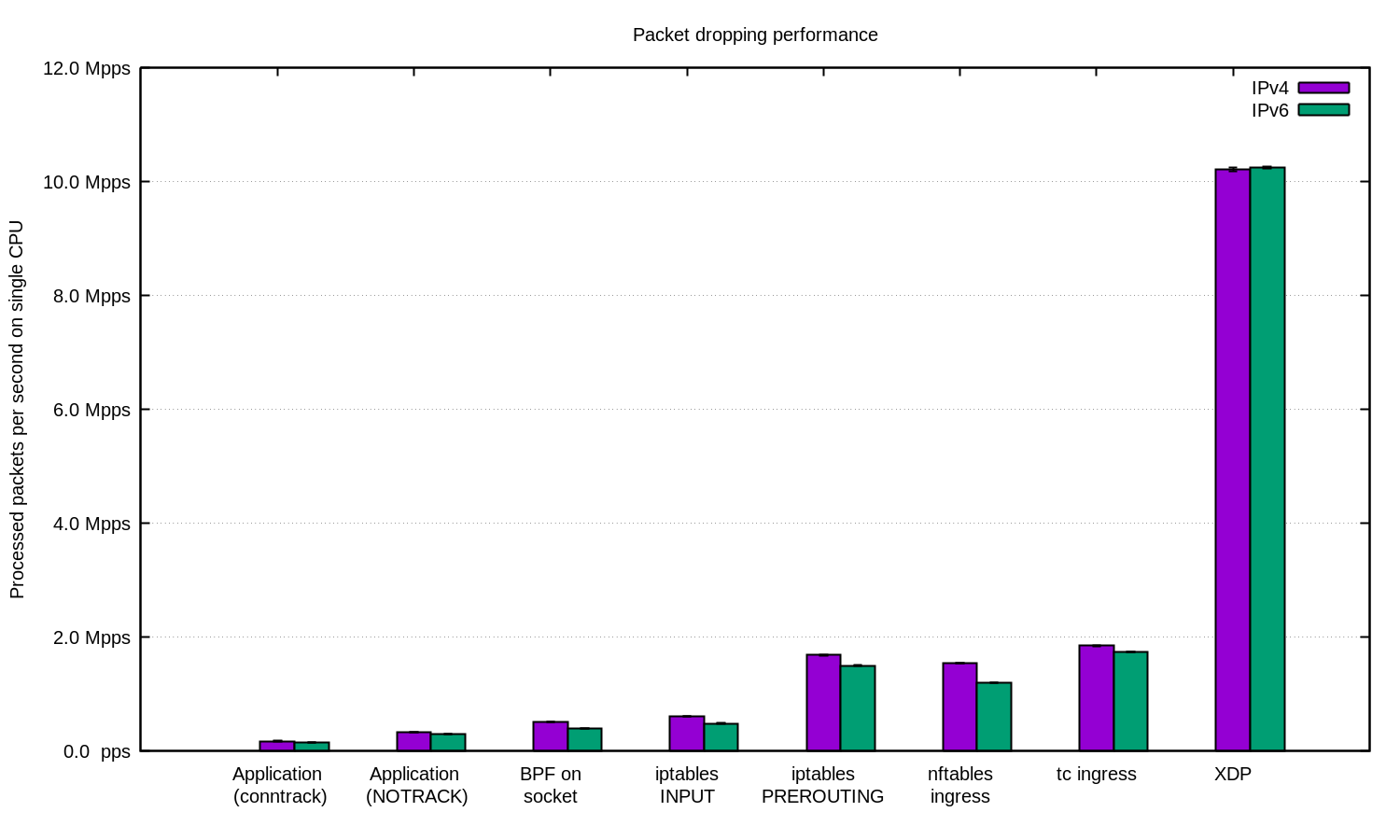
For the most neglected cases, we always use XDP. And yes, this is a very powerful thing. Here is the chart as above, only with XDP:
If you want to repeat the experiment, here is the README, in which we have documented everything .
We use CloudFlare ... almost all of these techniques. Some user space tricks are integrated into our applications. The technique with iptables is found in our Gatebot . Finally, we replace our own core solution with XDP.
Many thanks to Jesper Dangaard Brouer for the help in work.
Photo: Brian Evans , CC BY-SA 2.0 The
ability to quickly drop packets is very important in resisting DDoS attacks.
Dropping packets reaching our servers can be done at several levels. Each method has its pros and cons. Under the cut, we look at everything we tried.
Translator's note: in the output of some of the commands presented, extra spaces have been removed to preserve readability.
Test pad
For ease of comparison, we will give you some numbers, however, you should not take them too literally, due to the artificiality of the tests. We will use one of our Intel-servers with a 10Gbit / s network card. The remaining characteristics of the server are not so important, because we want to focus on the limitations of the operating system, not the hardware.
Our tests will look like this:
- We create a load of a huge number of small UDP packets, reaching a value of 14 million packets per second;
- All this traffic is directed to one processor core of the selected server;
- We measure the number of packets processed by the core on one core processor.
Artificial traffic is generated in such a way as to create maximum load: a random IP address and port of the sender are used. Here’s something like this in tcpdump:
$ tcpdump -ni vlan100 -c 10 -t udp and dst port 1234
IP 198.18.40.55.32059 > 198.18.0.12.1234: UDP, length 16
IP 198.18.51.16.30852 > 198.18.0.12.1234: UDP, length 16
IP 198.18.35.51.61823 > 198.18.0.12.1234: UDP, length 16
IP 198.18.44.42.30344 > 198.18.0.12.1234: UDP, length 16
IP 198.18.106.227.38592 > 198.18.0.12.1234: UDP, length 16
IP 198.18.48.67.19533 > 198.18.0.12.1234: UDP, length 16
IP 198.18.49.38.40566 > 198.18.0.12.1234: UDP, length 16
IP 198.18.50.73.22989 > 198.18.0.12.1234: UDP, length 16
IP 198.18.43.204.37895 > 198.18.0.12.1234: UDP, length 16
IP 198.18.104.128.1543 > 198.18.0.12.1234: UDP, length 16
On the selected server, all packets will be in one RX queue and, therefore, processed by one core. We achieve this with hardware flow control:
ethtool -N ext0 flow-type udp4 dst-ip 198.18.0.12 dst-port 1234 action 2
Performance testing is a complex process. When we were preparing tests, we noticed that the presence of active raw sockets has a negative effect on performance, so you need to make sure that none of them are running before running the tests
tcpdump. There is an easy way to check for bad processes:$ ss -A raw,packet_raw -l -p|cat
Netid State Recv-Q Send-Q Local Address:Port
p_raw UNCONN 525157 0 *:vlan100 users:(("tcpdump",pid=23683,fd=3))
Finally, we disable Intel Turbo Boost on our server:
echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turboDespite the fact that Turbo Boost is a great thing and increases throughput by at least 20%, it significantly spoils the standard deviation in our tests. With turbo enabled, the deviation reaches ± 1.5%, while without it only 0.25%.
Step 1. Dropping packets in the application
Let's start with the idea of delivering all the packages to the application and ignoring them there. For the integrity of the experiment, make sure that iptables does not affect the performance:
iptables -I PREROUTING -t mangle -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
iptables -I INPUT -t filter -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
An application is a simple loop in which incoming data is immediately dropped:
s = socket.socket(AF_INET, SOCK_DGRAM)
s.bind(("0.0.0.0", 1234))
whileTrue:
s.recvmmsg([...])
We have already prepared the code , run:
$ ./dropping-packets/recvmmsg-loop
packets=171261 bytes=1940176
This solution allows the kernel to take only 175 thousand packets from the hardware queue, as was measured by the utilities
ethtooland oursmmwatch :$ mmwatch 'ethtool -S ext0|grep rx_2'
rx2_packets: 174.0k/s
Technically, the server receives 14 million packets per second, however, one processor core cannot cope with such a volume.
mpstatconfirms this:$ watch 'mpstat -u -I SUM -P ALL 1 1|egrep -v Aver'
01:32:05 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
01:32:06 PM 0 0.00 0.00 0.00 2.94 0.00 3.92 0.00 0.00 0.00 93.14
01:32:06 PM 1 2.17 0.00 27.17 0.00 0.00 0.00 0.00 0.00 0.00 70.65
01:32:06 PM 2 0.00 0.00 0.00 0.00 0.00 100.00 0.00 0.00 0.00 0.00
01:32:06 PM 3 0.95 0.00 1.90 0.95 0.00 3.81 0.00 0.00 0.00 92.38
As we can see, the application is not a bottleneck: CPU # 1 is used at 27.17% + 2.17%, while interrupt handling takes 100% on CPU # 2.
Use
recvmessagge(2)is important. After Specter’s vulnerability was discovered, system calls became even more expensive due to the KPTI and retpoline used in the kernel .$ tail -n +1 /sys/devices/system/cpu/vulnerabilities/*
==> /sys/devices/system/cpu/vulnerabilities/meltdown <==
Mitigation: PTI
==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <==
Mitigation: __user pointer sanitization
==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <==
Mitigation: Full generic retpoline, IBPB, IBRS_FW
Step 2. Killing conntrack
We specifically made such a load with different IP and port of the sender in order to load the conntrack as much as possible. The number of entries in the conntrack during the test strives for the maximum possible and we can verify this:
$ conntrack -C
2095202
$ sysctl net.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max = 2097152
Moreover,
dmesgyou can also see conntrack shouts:[4029612.456673] nf_conntrack: nf_conntrack: table full, dropping packet
[4029612.465787] nf_conntrack: nf_conntrack: table full, dropping packet
[4029617.175957] net_ratelimit: 5731 callbacks suppressed
So let's turn it off:
iptables -t raw -I PREROUTING -d 198.18.0.12 -p udp -m udp --dport 1234 -j NOTRACK
And restart the tests:
$ ./dropping-packets/recvmmsg-loop
packets=331008 bytes=5296128
This allowed us to reach the level of 333 thousand packets per second. Hooray!
PS With the use of SO_BUSY_POLL we can reach as much as 470 thousand per second, however, this is a topic for a separate post.
Step 3. Berkeley packet filter
Go ahead. Why do we need to deliver packages to the application? Although this is not a common solution, we can tie a classic Berkeley packet filter to a socket by calling
setsockopt(SO_ATTACH_FILTER)and configure the filter to drop packets while it is still in the kernel. Prepare the code , run:
$ ./bpf-drop
packets=0 bytes=0
Using a packet filter (the classic and advanced Berkeley filters give roughly the same performance) we get to about 512,000 packets per second. Moreover, dropping a packet during an interrupt frees the processor from having to wake up the application.
Step 4. iptables DROP after routing
Now we can drop packets by adding the following rule to iptables in the INPUT chain:
iptables -I INPUT -d 198.18.0.12 -p udp --dport 1234 -j DROP
Let me remind you that we have already disabled conntrack rule
-j NOTRACK. These two rules give us 608 thousand packets per second. Look at the numbers in iptables:
$ mmwatch 'iptables -L -v -n -x | head'
Chain INPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
605.9k/s 26.7m/s DROP udp -- * * 0.0.0.0/0 198.18.0.12 udp dpt:1234
Well, not bad, but we can do better.
Step 5. iptabes DROP to PREROUTING
Faster technology is to drop packets before routing using this rule:
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j DROPThis allows us to discard a solid 1.688 million packets per second.
In fact, this is a slightly surprising jump in performance. I did not understand the reasons, perhaps our routing is difficult, or maybe just a bug in the server configuration.
In any case, raw iptables work much faster.
Step 6. nftables DROP
Now the iptables utility is a bit old. It was replaced by nftables. Check out this video explaining why nftables are top. Nftables promise to be faster than gray iptables for a variety of reasons, including the rumor that retpoline slows down iptables a lot.
But our article is still not about comparing iptables and nftables, so let's just try the quickest thing I could do:
nft add table netdev filter
nft -- add chain netdev filter input { type filter hook ingress device vlan100 priority -500 \; policy accept \; }
nft add rule netdev filter input ip daddr 198.18.0.0/24 udp dport 1234 counter drop
nft add rule netdev filter input ip6 daddr fd00::/64 udp dport 1234 counter drop
Counters can be seen as:
$ mmwatch 'nft --handle list chain netdev filter input'
table netdev filter {
chain input {
type filter hook ingress device vlan100 priority -500; policy accept;
ip daddr 198.18.0.0/24 udp dport 1234 counter packets 1.6m/s bytes 69.6m/s drop # handle 2
ip6 daddr fd00::/64 udp dport 1234 counter packets 0 bytes 0 drop # handle 3
}
}
The nftables input hook showed values of about 1.53 million packets. This is a little less than the prefix chain in iptables. But there is a mystery in it: theoretically, the nftables hook comes earlier than PREROUTING iptables and, therefore, should be processed faster.
In our test, nftables are a bit slower than iptables, but still, nftables are cooler. : P
Step 7. tc DROP
Somewhat unexpectedly, the tc (traffic control) hook occurs earlier than iptables PREROUTING. tc allows us to select packets according to simple criteria and, of course, discard them. The syntax is a bit unusual, so for the customization we suggest using this script . And we need a rather complicated rule that looks like this:
tc qdisc add dev vlan100 ingress
tc filter add dev vlan100 parent ffff: prio 4 protocol ip u32 match ip protocol 17 0xff match ip dport 1234 0xffff match ip dst 198.18.0.0/24 flowid 1:1 action drop
tc filter add dev vlan100 parent ffff: protocol ipv6 u32 match ip6 dport 1234 0xffff match ip6 dst fd00::/64 flowid 1:1 action drop
And we can check it in action:
$ mmwatch 'tc -s filter show dev vlan100 ingress'
filter parent ffff: protocol ip pref 4 u32
filter parent ffff: protocol ip pref 4 u32 fh 800: ht divisor 1
filter parent ffff: protocol ip pref 4 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:1 (rule hit 1.8m/s success 1.8m/s)
match 00110000/00ff0000 at 8 (success 1.8m/s )
match 000004d2/0000ffff at 20 (success 1.8m/s )
match c612000c/ffffffff at 16 (success 1.8m/s )
action order 1: gact action drop
random type none pass val 0
index 1 ref 1 bind 1 installed 1.0/s sec
Action statistics:
Sent 79.7m/s bytes 1.8m/s pkt (dropped 1.8m/s, overlimits 0 requeues 0)
The tc hook allowed us to drop up to 1.8 million packets per second on a single core. It's fine!
But we can even faster ...
Step 8. XDP_DROP
And finally, our strongest weapon: XDP - eXpress Data Path . With XDP, we can run Berkeley’s extended Berkley Packet Filter (eBPF) code directly in the context of the network driver and, most importantly, before allocating memory under
skbuffwhat promises us a speed boost. Usually an XDP project consists of two parts:
- eBPF downloadable code
- bootloader that puts code in the correct network interface
Writing your bootloader is a difficult task, so just use the new iproute2 chip and load the code with a simple command:
ip link set dev ext0 xdp obj xdp-drop-ebpf.o
Ta-dam!
The source code for the downloadable eBPF program is available here . The program looks at such characteristics of IP packets as the UDP protocol, the sender's subnet and destination port:
if (h_proto == htons(ETH_P_IP)) {
if (iph->protocol == IPPROTO_UDP
&& (htonl(iph->daddr) & 0xFFFFFF00) == 0xC6120000// 198.18.0.0/24
&& udph->dest == htons(1234)) {
return XDP_DROP;
}
}
An XDP program must be built using modern clang, which can generate BPF bytecode. After that we can download and test the functionality of the BFP program:
$ ip link show dev ext0
4: ext0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp qdisc fq state UP mode DEFAULT group default qlen 1000
link/ether 24:8a:07:8a:59:8e brd ff:ff:ff:ff:ff:ff
prog/xdp id 5 tag aedc195cc0471f51 jited
And then see the statistics in
ethtool:$ mmwatch 'ethtool -S ext0|egrep "rx"|egrep -v ": 0"|egrep -v "cache|csum"'
rx_out_of_buffer: 4.4m/s
rx_xdp_drop: 10.1m/s
rx2_xdp_drop: 10.1m/s
Yu-hoo! With XDP, we can drop up to 10 million packets per second!
Photography: Andrew Filer , CC BY-SA 2.0
findings
We repeated the experiment for IPv4 and for IPv6 and prepared this diagram:
In general, it can be argued that our configuration for IPv6 is a bit slower. But since IPv6 packets are somewhat larger, the difference in speed is expected.
In Linux, there are many ways to filter packets, each with its own speed and complexity of configuration.
To protect against DDoS, it is quite reasonable to give packets to the application and process them there. A well-tuned application can perform well.
For DDoS attacks with random or spoofed IPs, it may be useful to disable conntrack to get a small increase in speed, but beware: there are attacks against which conntrack is very useful.
In other cases, it makes sense to add a Linux firewall as one of the ways to mitigate a DDoS attack. In some cases it is better to use the table "-t raw PREROUTING", since it is much faster than the table filter.
For the most neglected cases, we always use XDP. And yes, this is a very powerful thing. Here is the chart as above, only with XDP:
If you want to repeat the experiment, here is the README, in which we have documented everything .
We use CloudFlare ... almost all of these techniques. Some user space tricks are integrated into our applications. The technique with iptables is found in our Gatebot . Finally, we replace our own core solution with XDP.
Many thanks to Jesper Dangaard Brouer for the help in work.