ISO 15926 vs Semantics: comparative analysis of semantic models
The idea of using semantic models in corporate information systems has existed for a long time, but a sustainable practice for their use has not yet been formed. Semantic models can be used for data integration, analytics, knowledge management; however, there is still no generally accepted opinion on how to approach the assessment of their usefulness, and by what methods such models should be built.
The objective of the article is to compare, on a practical example, the analytical potential of models built according to the rules of the integration standard ISO 15926, which prescribes the use of OWL and SPARQL for expressing models and working with them, and “ordinary” semantic models built without using this standard. The solution to this issue will allow us to choose a range of tasks, for the solution of which it is advisable to apply such high-level paradigms of semantic modeling as ISO 15926.
It is necessary to briefly highlight the history of the issue, and the essence of the relationship between ISO 15926 and “ordinary” semantics. ISO 15926 is an information exchange standard intended for use in industry (primarily oil and gas). Historically, the emphasis in the development of the standard was on the exchange of data between various organizations, i.e. between different information infrastructures. Its main features are a specific approach to the classification of objects and their relationships, taking into account the time component of objects (4D modeling), the ability to simulate the life cycle of systems (and not just the current state of a system). The standard contains the ontological core, and implies the use of common reference data libraries to create applied information models.
The development of the standard was started back in the 1990s. With the advent of the Semantic Web technologies in the mid-2000s, they were approved as the technological basis for expressing data in accordance with ISO 15926. Thus, the basic concepts of the standard were laid before the emergence of the Semantic Web, but only the appearance of these technologies provided the necessary technological basis for creating a way of expressing data in accordance with a standard that has the potential for truly widespread dissemination. Some ideological proximity, but not the identity of these technologies, laid the foundation for the “contradiction” that we want to resolve. Since the principles by which modeling is performed in accordance with ISO 15926 do not fully comply with the principles of representing objects and the relationships between them, for example, in the OWL language, The combination of these two technologies turned out to be somewhat synthetic. The data constructed in accordance with ISO 15926 can be decomposed into elementary elements - RDF triplets, but the analysis of the relations between the information objects of the model presented in this form by means of SPARQL will be difficult.
So, the essence of the contradiction, which we are going to shed light on, is as follows: it is argued that semantic models built in accordance with ISO 15926 have qualitative differences from semantic models built without such a high-level manual, only by means of the "usual" Semantic Web technologies . Thus, these models have a fundamentally different nature (at least ideological). It is argued that there can be competition between these two types of semantic models, and there can only be one argument in favor of “ordinary” models - relative simplicity; for all other indicators, the ISO 15926 models are more correct and useful.
Below we will consider these statements in detail, based on a practical example designed to clearly indicate the relationship, similarities and differences between ISO 15926 and “ordinary” semantic models. In the meantime, we turn to the ideology of the creation and application of semantic data models (“ordinary” semantics we will refer to models built not in accordance with ISO 15926).
The main driving idea in creating semantic technologies was the need to ensure the "understanding" of the meaning (semantics) of data by computer algorithms. Thus, the initial task of these technologies was analytics: providing opportunities to extract knowledge from related sets of information.
With the development of these technologies, experiments on their application in various fields, it turned out that they are extremely convenient for combining (linking) data from sources of different structure. From this came the second direction of the development of tools based on the ideas of semantic networks - the integration of information systems.
There is no contradiction between the analytical and integration application of semantics; on the contrary, they are in inextricable unity. After all, the goal of integration, as a rule, is to extract some new knowledge from the combined set - such knowledge that could not be obtained from each source individually. The task of simplifying the transfer of information from one information system to another can also be solved with the help of semantic technologies, but is rather an additional bonus from their development.
In a number of areas of application, significant breakthroughs were achieved using semantic information analysis technologies. Particularly convincing are these advances in medicine and biotechnology. For example, on semantic technologies, bases are built that combine information about medicines and their effects, clinical histories, and genetic information. An analysis of such databases helps researchers create new drugs. This is a great example of a situation where relational databases are not able to adequately reflect the diversity of relationships between information objects, and provide tools for analyzing these relationships - and semantic technologies can. Semantic databases are also used in healthcare (to analyze the spread of diseases), and in many other applications.
Tools for analyzing information using semantic technologies are also included in everyday life. For example, the developers of Facebook Graph Search came up with an excellent example that allows demonstrating at a routine level the fundamental novelty of semantic search (analysis): it is obvious that not one of the existing search engines built on the principle of searching in the text can answer the question “What restaurants did you like?” to my friends? ”, or“ In what cities do my relatives live? ”. A graph search, using a formalized set of information objects (people, restaurants, cities) and the relationships between them (like, lives in), is able to give the right answer quickly and exactly. At the same time, the query conditions can be varied within the limits allowed by the ontology (a set of the very types of information objects and the relationships between them): similar questions can be asked not about restaurants, but about films, not about relatives, but about classmates. It is clear that the entire content of the social network Facebook is a huge single information graph, with billions of nodes and connections. The ability to analyze and use these relationships is all its value, which is well understood by the owners of the resource.
Based on the foregoing, we can determine the criteria that should be presented to information models built on the principles of semantic technology. Some of these criteria follow from the general requirements for models, and some from the specifics of technologies related to the conditions of their practical usefulness. We list them.
1. The result of any action in the real system and in the model must match (the similarity relations between the model and the system in the initial and final state are described by the same rules). This requirement provides the predictive potential of the model: if it is fulfilled, we can simulate the development of the system and implement the simulation results.
2. The model should reflect the properties of objects and the relationships between them in a way that makes it possible to extract knowledge from the model using existing technologies (such as SPARQL). This is a purely practical requirement, ensuring the suitability of the model for analysis. In fact, it declares the ability to perform calculations on the model.
3. The model should provide the possibility of expansion and scaling (enlargement and detailing), without revising its ontological core. This requirement imposes restrictions on the selection of methods for classifying objects, distinguishing between objects and their properties; this requirement can be seriously detailed.
We now consider two “conflicting” methods of constructing models, and evaluate their practical usefulness, based on the above criteria. We will take an example from the field of industry, “native” for the standard under discussion.
Let us describe in the form of a semantic model information about the event - the installation of the pump in the pipeline. Our model should contain the following information:
First, we model this information structure without relying on ISO 15926 (of course, you can create it in many different ways, we will arbitrarily choose one).
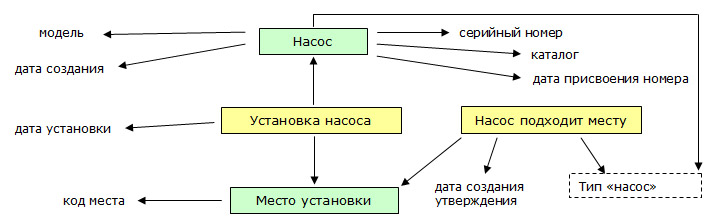
Objects corresponding to events are shown in yellow, material objects in green, and literals without a frame. A class definition is circled in a dotted box, which, in principle, refers to reference data, and not to a specific model. Arrows indicate the relationship of objects with each other, and objects with literals (properties) - edges of the graph.
As a result of importing this ontology into SPARQL, we get a set of 16 triplets (edges of the graph). They correspond to the lines shown in the diagram, plus one triplet for the type of each object. Of course, the scheme is simplified - for example, the “model” should not be a literal, but a reference to the corresponding object.
ByThis link allows you to download the RDF-representation of this model, as well as a set of triplets into which it turns after import into a SPARQL access point.
Consider the analysis of this model. For example, let us want to know in which place the pump with the serial number known to us was installed. To do this, we need the following sequence of simple queries:
This query returns the identifier of the object containing information about the pump. Now we find the object "pump installation":
It remains to find out the installation location:
We looked at three edges of the graph; Of course, these queries can be combined into one.
In accordance with ISO 15926, our event - the installation of the pump - should be described by the InstallationOfTemporalPartMaterializedPhysicalObjectInFunctionPlace template. In a simplified form, the role structure of this template, which allows expressing information that is approximately equivalent to that shown in the example above, can be represented as follows:
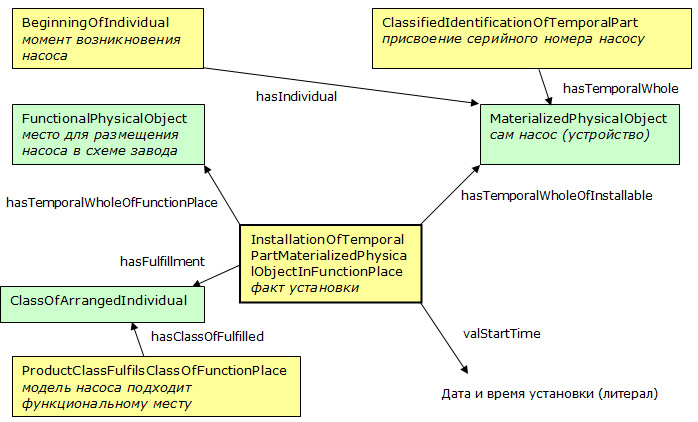
In this diagram, the instances of the templates are colored in yellow, the instances of objects in green.
Such a structure, filled with the minimum necessary data (without annotations), when imported into SPARQL, the access point turns into 36 triplets (you can download OWL and the resulting triplet set from this link) Note that the structure of this data in triplets is quite reasonable, and not so different from the structure of the model without using the standard. The increase in the number of triplets in comparison with the “ordinary” semantic model is more than double due to the addition of new information objects, as well as links to the definitions of the basic types contained in many of them. However, converting reference data into triplets, especially template definitions, will yield much worse results in terms of optimizing the structure of the graph. So, the definition of only one InstallationOfTemporalPartMaterializedPhysicalObjectInFunctionPlace template is 148 triplets, many of which include blank nodes (graph nodes that do not have their own identifiers). Including, many triplets connect two blank nodes among themselves. Working with such structures using SPARQL is very difficult. In practice, this will result in a serious increase in the complexity of software that implements the ability to create or view templates. For comparison, the “ordinary” semantic model of the same data fits into only 38 triplets, that is, it is an order of magnitude more compact than the ISO 15926 model (do not forget that the above 148 triplets describe only one template, and there are four of them in our example, plus definitions of the required standard types). Another important difference is that the ISO model contains links to external elements that are outside the access point where the current ontology is located - in particular, in the RDL (Reference Data Library, reference data directory; below we will return to these directories). In practice, this will result in a serious increase in the complexity of software that implements the ability to create or view templates. For comparison, the “ordinary” semantic model of the same data fits into only 38 triplets, that is, it is an order of magnitude more compact than the ISO 15926 model (do not forget that the 148 triplets mentioned above describe only one template, and there are four of them in our example, plus definitions of the required standard types). Another important difference is that the ISO model contains links to external elements that are outside the access point where the current ontology is located - in particular, in the RDL (Reference Data Library, reference data directory; below we will return to these directories). In practice, this will result in a serious increase in the complexity of software that implements the ability to create or view templates. For comparison, the “ordinary” semantic model of the same data fits into only 38 triplets, that is, it is an order of magnitude more compact than the ISO 15926 model (do not forget that the 148 triplets mentioned above describe only one template, and there are four of them in our example, plus definitions of the required standard types). Another important difference is that the ISO model contains links to external elements that are outside the access point where the current ontology is located - in particular, in the RDL (Reference Data Library, reference data directory; below we will return to these directories). implements the ability to create or view templates. For comparison, the “ordinary” semantic model of the same data fits into only 38 triplets, that is, it is an order of magnitude more compact than the ISO 15926 model (do not forget that the 148 triplets mentioned above describe only one template, and there are four of them in our example, plus definitions of the required standard types). Another important difference is that the ISO model contains links to external elements that are outside the access point where the current ontology is located - in particular, in the RDL (Reference Data Library, reference data directory; below we will return to these directories). implements the ability to create or view templates. For comparison, the “ordinary” semantic model of the same data fits into only 38 triplets, that is, it is an order of magnitude more compact than the ISO 15926 model (do not forget that the 148 triplets mentioned above describe only one template, and there are four of them in our example, plus definitions of the required standard types). Another important difference is that the ISO model contains links to external elements that are outside the access point where the current ontology is located - in particular, in the RDL (Reference Data Library, reference data directory; below we will return to these directories). that the above 148 triplets describe only one template, and there are four of them in our example, plus the definitions of the necessary standard types). Another important difference is that the ISO model contains links to external elements that are outside the access point where the current ontology is located - in particular, in the RDL (Reference Data Library, reference data directory; below we will return to these directories). that the above 148 triplets describe only one template, and there are four of them in our example, plus the definitions of the necessary standard types). Another important difference is that the ISO model contains links to external elements that are outside the access point where the current ontology is located - in particular, in the RDL (Reference Data Library, reference data directory; below we will return to these directories).
Let us consider the possibilities of analyzing a model built according to the rules of ISO 15926. We will perform the same tasks that are described above for the “ordinary” semantic model. Let us want to know in which place the pump with the serial number known to us was installed. In the ISO model, we need the following sequence of simple queries:
The result is an instance ID of the ClassifiedIdentificationOfTemporalPart template. Now we ask what physical object “pump” this template is associated with:
We get the pump identifier (an object of type MaterializedPhysicalObject). Now we can get a list of instances of the template that describes the installation of the pump:
Got the instance ID of the InstallationOfTemporalPartMaterializedPhysicalObjectInFunctionPlace template instance. We now find out what functional place the installation was made:
So, we needed to go through four edges of the graph. It is very important that in order to compose these requests, the programmer must be familiar with the principles of ISO 15926 in detail, and have an annotated library of templates (which, in fact, is not in the public domain).
Another interesting aspect of the analysis of this graph is related to time (taking into account the temporal aspect is one of the strengths of ISO 15926). If we want to find out which pump was installed in a certain functional place at a certain time, we will have to do this using not very convenient means of working with SPARQL dates. We construct the necessary request.
We get the pump installation episodes, knowing the identifier of the functional place:
Now we get the pump identifier - for the sake of a variety of examples, we will do this in the same query:
From the pump, there will most likely be a link to its type in RDL - with its help we can find out which pump it is; but we left this part of the model outside our example. It remains to add the condition for the installation dates to the request:
The combination of using the FILTER condition by installation date, sorting ORDER BY and limiting the number of output results LIMIT gives us only one desired result - it allows you to select the episode of the pump installation that precedes the specified date.
On a “regular” semantic model, this query will have exactly the same structure, and exactly the same number of elements:
Another interesting aspect of using models built in accordance with ISO 15926 is related to the use of RDL - reference data libraries. They store definitions of device types, their functions, etc. These libraries are available at external SPARQL access points, usually owned by industry associations. There is one link to RDL in our column - this is the definition of the type of a functional object that tells us that it should be a device with a pump function. If we request information about the type of the FunctionalPhysicalObject we have,
then we get a link to RDL: < rdl.example.org/sampleReferenceData#R4598459832 > (and at the same time we find out that our function object belongs to the WholeLifeIndividual class, and several other ISO 15926 root classes are not very useful information for us). If now we want to know what this definition means, we will have to query another access point where this RDL is stored:
Such a request will return to us all the information that is available in the RDL for this type of device. As RDL, reference libraries (catalogs) maintained by industry associations and regulators, as well as private catalogs, for example, suppliers of certain equipment, can be used.
In “regular” semantic models, we can also use federated queries. We can create a common catalog, for example, equipment, and place it in an open access point. The whole question is only whose "authority" will be supported by such a repository of information. Giving authority to directories is a function of various associations. At the same time, if you do not cheat, the correspondence or non-compliance of the guidebook with one or another standard does not add practically anything to its "authority". If the catalog of a certain company, for example, a supplier of equipment, is used as RDL, then the question of the presence of “authority” is completely meaningless.
The conclusions from the considered examples of the use of semantic models are quite obvious:
1. From a technological point of view, “ordinary” semantic models are quite symmetrical to the ISO 15926 models, if we talk about design data (expressing information about specific systems and processes). ISO models are more complex, and this gap, in comparison with “ordinary” models, grows depending on the volume of the model according to a linear law. This is due to the presence of separate entities for expressing the temporal parts of objects, as well as the need to classify objects in accordance with the classifier of top-level types.
2. From the point of view of the computational potential of these models, calculations on them are also somewhat more complicated than in the “ordinary” semantics, but the difference is not radical. More importantly, to build queries, you need not only familiarity with the model, but also knowledge of the concepts of ISO 15926, as well as the presence of a template navigator (which, as far as we know, is not publicly available; a set of templates and the procedure for their approval, as far as we know are also far from desired).
3. The system of reference data and high-level entities ISO 15926 is very complicated in comparison with the “usual” semantics (if we take as an indicator the number of triplets required to express the model - 10 times or more). This is especially true for libraries of higher-level entities, such as templates. Work with definitions (not instances!) Of these entities by means of semantic technologies is significantly complicated. However, any application that provides the user with the ability to work with templates, and “hiding” their low-level representation from him, must have wide capabilities for such work (search and viewing, creating and editing template definitions, filling them out). A partial solution to the problem may be working with templates that are not expressed as triplets in RDF storage, but as OWL files.
4. The ISO 15926 concepts, considered to be its know-how, and providing the special value of this standard — the use of federated access and RDL libraries, the consideration of temporal parts — are also available in “ordinary” semantics. It all depends on how the data model is built, and how the separation of data into design and reference data is implemented. By the way, we note that there are no practical obstacles to using the RDL libraries built in accordance with ISO 15926 in applications using data models that do not correspond to it.
5. The true value of a standard is, first of all, its status as a standard; generally accepted classification methods and the classifiers themselves (as well as methods of their administration) provide the potential for using the standard for integration between different enterprises, but somewhat complicate the performance of computational tasks on models. This is a natural situation: for any versatility you have to pay for speed.
Thus, the ISO 15926 standard is one of the methods for constructing semantic models, which has certain advantages and disadvantages compared to other methods that contain less than a high-level formalism. From the point of view of practical implementation and potential use, there is no fundamental difference between the standard and other methods that would allow them to be contrasted as different technologies. Declaring the existence of such a difference could be considered a marketing device for propagating the standard if it did not play a daunting role for specialists already familiar with “ordinary” semantic technologies (as is happening now in practice). In addition, to explain the difference between ISO 15926 and “ordinary” semantics at the technological level to people who are not IT specialists,
Creating high-quality models of systems is possible both with the use of this standard, and without it; the decision on its use should be made based on the context of the application of the developed information system, first of all, from the point of view of the possible inclusion of the model in the integration processes, and from the point of view of the requirements for performing calculations on the model. Following the standard can be stated as a general recommendation, but under certain circumstances the need for fast computations on the model may require the implementation of a more rational ontology. Solving the problem of optimizing computing only with hardware is usually irrational.
The main obstacles to the dissemination of the standard should be considered:
It is with these problems that we must fight by spreading the standard as best practice. Its artificial opposition to “ordinary” semantic technologies can play only a negative role in this process.
ps Thanks to Victor Agroskin for clarifying the example model ISO 15926.
The objective of the article is to compare, on a practical example, the analytical potential of models built according to the rules of the integration standard ISO 15926, which prescribes the use of OWL and SPARQL for expressing models and working with them, and “ordinary” semantic models built without using this standard. The solution to this issue will allow us to choose a range of tasks, for the solution of which it is advisable to apply such high-level paradigms of semantic modeling as ISO 15926.
Formulation of the problem
It is necessary to briefly highlight the history of the issue, and the essence of the relationship between ISO 15926 and “ordinary” semantics. ISO 15926 is an information exchange standard intended for use in industry (primarily oil and gas). Historically, the emphasis in the development of the standard was on the exchange of data between various organizations, i.e. between different information infrastructures. Its main features are a specific approach to the classification of objects and their relationships, taking into account the time component of objects (4D modeling), the ability to simulate the life cycle of systems (and not just the current state of a system). The standard contains the ontological core, and implies the use of common reference data libraries to create applied information models.
The development of the standard was started back in the 1990s. With the advent of the Semantic Web technologies in the mid-2000s, they were approved as the technological basis for expressing data in accordance with ISO 15926. Thus, the basic concepts of the standard were laid before the emergence of the Semantic Web, but only the appearance of these technologies provided the necessary technological basis for creating a way of expressing data in accordance with a standard that has the potential for truly widespread dissemination. Some ideological proximity, but not the identity of these technologies, laid the foundation for the “contradiction” that we want to resolve. Since the principles by which modeling is performed in accordance with ISO 15926 do not fully comply with the principles of representing objects and the relationships between them, for example, in the OWL language, The combination of these two technologies turned out to be somewhat synthetic. The data constructed in accordance with ISO 15926 can be decomposed into elementary elements - RDF triplets, but the analysis of the relations between the information objects of the model presented in this form by means of SPARQL will be difficult.
So, the essence of the contradiction, which we are going to shed light on, is as follows: it is argued that semantic models built in accordance with ISO 15926 have qualitative differences from semantic models built without such a high-level manual, only by means of the "usual" Semantic Web technologies . Thus, these models have a fundamentally different nature (at least ideological). It is argued that there can be competition between these two types of semantic models, and there can only be one argument in favor of “ordinary” models - relative simplicity; for all other indicators, the ISO 15926 models are more correct and useful.
Below we will consider these statements in detail, based on a practical example designed to clearly indicate the relationship, similarities and differences between ISO 15926 and “ordinary” semantic models. In the meantime, we turn to the ideology of the creation and application of semantic data models (“ordinary” semantics we will refer to models built not in accordance with ISO 15926).
Semantic models and their applications
The main driving idea in creating semantic technologies was the need to ensure the "understanding" of the meaning (semantics) of data by computer algorithms. Thus, the initial task of these technologies was analytics: providing opportunities to extract knowledge from related sets of information.
With the development of these technologies, experiments on their application in various fields, it turned out that they are extremely convenient for combining (linking) data from sources of different structure. From this came the second direction of the development of tools based on the ideas of semantic networks - the integration of information systems.
There is no contradiction between the analytical and integration application of semantics; on the contrary, they are in inextricable unity. After all, the goal of integration, as a rule, is to extract some new knowledge from the combined set - such knowledge that could not be obtained from each source individually. The task of simplifying the transfer of information from one information system to another can also be solved with the help of semantic technologies, but is rather an additional bonus from their development.
In a number of areas of application, significant breakthroughs were achieved using semantic information analysis technologies. Particularly convincing are these advances in medicine and biotechnology. For example, on semantic technologies, bases are built that combine information about medicines and their effects, clinical histories, and genetic information. An analysis of such databases helps researchers create new drugs. This is a great example of a situation where relational databases are not able to adequately reflect the diversity of relationships between information objects, and provide tools for analyzing these relationships - and semantic technologies can. Semantic databases are also used in healthcare (to analyze the spread of diseases), and in many other applications.
Tools for analyzing information using semantic technologies are also included in everyday life. For example, the developers of Facebook Graph Search came up with an excellent example that allows demonstrating at a routine level the fundamental novelty of semantic search (analysis): it is obvious that not one of the existing search engines built on the principle of searching in the text can answer the question “What restaurants did you like?” to my friends? ”, or“ In what cities do my relatives live? ”. A graph search, using a formalized set of information objects (people, restaurants, cities) and the relationships between them (like, lives in), is able to give the right answer quickly and exactly. At the same time, the query conditions can be varied within the limits allowed by the ontology (a set of the very types of information objects and the relationships between them): similar questions can be asked not about restaurants, but about films, not about relatives, but about classmates. It is clear that the entire content of the social network Facebook is a huge single information graph, with billions of nodes and connections. The ability to analyze and use these relationships is all its value, which is well understood by the owners of the resource.
Based on the foregoing, we can determine the criteria that should be presented to information models built on the principles of semantic technology. Some of these criteria follow from the general requirements for models, and some from the specifics of technologies related to the conditions of their practical usefulness. We list them.
1. The result of any action in the real system and in the model must match (the similarity relations between the model and the system in the initial and final state are described by the same rules). This requirement provides the predictive potential of the model: if it is fulfilled, we can simulate the development of the system and implement the simulation results.
2. The model should reflect the properties of objects and the relationships between them in a way that makes it possible to extract knowledge from the model using existing technologies (such as SPARQL). This is a purely practical requirement, ensuring the suitability of the model for analysis. In fact, it declares the ability to perform calculations on the model.
3. The model should provide the possibility of expansion and scaling (enlargement and detailing), without revising its ontological core. This requirement imposes restrictions on the selection of methods for classifying objects, distinguishing between objects and their properties; this requirement can be seriously detailed.
Example: creating and analyzing a “regular” semantic model
We now consider two “conflicting” methods of constructing models, and evaluate their practical usefulness, based on the above criteria. We will take an example from the field of industry, “native” for the standard under discussion.
Let us describe in the form of a semantic model information about the event - the installation of the pump in the pipeline. Our model should contain the following information:
- The place of installation of the pump (indicated by a specific identifier on the plant diagram; hereinafter, we will call it the “functional location”, in accordance with the terminology of ISO 15926)
- The pump itself, as a physical object of a certain type with a specific serial number assigned to it at a certain point in time;
- Information that this pump is suitable for this place (can be installed in it);
- Date and time of installation.
First, we model this information structure without relying on ISO 15926 (of course, you can create it in many different ways, we will arbitrarily choose one).
Objects corresponding to events are shown in yellow, material objects in green, and literals without a frame. A class definition is circled in a dotted box, which, in principle, refers to reference data, and not to a specific model. Arrows indicate the relationship of objects with each other, and objects with literals (properties) - edges of the graph.
As a result of importing this ontology into SPARQL, we get a set of 16 triplets (edges of the graph). They correspond to the lines shown in the diagram, plus one triplet for the type of each object. Of course, the scheme is simplified - for example, the “model” should not be a literal, but a reference to the corresponding object.
ByThis link allows you to download the RDF-representation of this model, as well as a set of triplets into which it turns after import into a SPARQL access point.
Consider the analysis of this model. For example, let us want to know in which place the pump with the serial number known to us was installed. To do this, we need the following sequence of simple queries:
SELECT * WHERE { ?pump "Centrifugal Pump Model AB-123C"^^ }
This query returns the identifier of the object containing information about the pump. Now we find the object "pump installation":
SELECT * WHERE { ?installation }
It remains to find out the installation location:
SELECT * WHERE { ?place }
We looked at three edges of the graph; Of course, these queries can be combined into one.
Example: creating and analyzing a model according to ISO 15926
In accordance with ISO 15926, our event - the installation of the pump - should be described by the InstallationOfTemporalPartMaterializedPhysicalObjectInFunctionPlace template. In a simplified form, the role structure of this template, which allows expressing information that is approximately equivalent to that shown in the example above, can be represented as follows:
In this diagram, the instances of the templates are colored in yellow, the instances of objects in green.
Such a structure, filled with the minimum necessary data (without annotations), when imported into SPARQL, the access point turns into 36 triplets (you can download OWL and the resulting triplet set from this link) Note that the structure of this data in triplets is quite reasonable, and not so different from the structure of the model without using the standard. The increase in the number of triplets in comparison with the “ordinary” semantic model is more than double due to the addition of new information objects, as well as links to the definitions of the basic types contained in many of them. However, converting reference data into triplets, especially template definitions, will yield much worse results in terms of optimizing the structure of the graph. So, the definition of only one InstallationOfTemporalPartMaterializedPhysicalObjectInFunctionPlace template is 148 triplets, many of which include blank nodes (graph nodes that do not have their own identifiers). Including, many triplets connect two blank nodes among themselves. Working with such structures using SPARQL is very difficult. In practice, this will result in a serious increase in the complexity of software that implements the ability to create or view templates. For comparison, the “ordinary” semantic model of the same data fits into only 38 triplets, that is, it is an order of magnitude more compact than the ISO 15926 model (do not forget that the above 148 triplets describe only one template, and there are four of them in our example, plus definitions of the required standard types). Another important difference is that the ISO model contains links to external elements that are outside the access point where the current ontology is located - in particular, in the RDL (Reference Data Library, reference data directory; below we will return to these directories). In practice, this will result in a serious increase in the complexity of software that implements the ability to create or view templates. For comparison, the “ordinary” semantic model of the same data fits into only 38 triplets, that is, it is an order of magnitude more compact than the ISO 15926 model (do not forget that the 148 triplets mentioned above describe only one template, and there are four of them in our example, plus definitions of the required standard types). Another important difference is that the ISO model contains links to external elements that are outside the access point where the current ontology is located - in particular, in the RDL (Reference Data Library, reference data directory; below we will return to these directories). In practice, this will result in a serious increase in the complexity of software that implements the ability to create or view templates. For comparison, the “ordinary” semantic model of the same data fits into only 38 triplets, that is, it is an order of magnitude more compact than the ISO 15926 model (do not forget that the 148 triplets mentioned above describe only one template, and there are four of them in our example, plus definitions of the required standard types). Another important difference is that the ISO model contains links to external elements that are outside the access point where the current ontology is located - in particular, in the RDL (Reference Data Library, reference data directory; below we will return to these directories). implements the ability to create or view templates. For comparison, the “ordinary” semantic model of the same data fits into only 38 triplets, that is, it is an order of magnitude more compact than the ISO 15926 model (do not forget that the 148 triplets mentioned above describe only one template, and there are four of them in our example, plus definitions of the required standard types). Another important difference is that the ISO model contains links to external elements that are outside the access point where the current ontology is located - in particular, in the RDL (Reference Data Library, reference data directory; below we will return to these directories). implements the ability to create or view templates. For comparison, the “ordinary” semantic model of the same data fits into only 38 triplets, that is, it is an order of magnitude more compact than the ISO 15926 model (do not forget that the 148 triplets mentioned above describe only one template, and there are four of them in our example, plus definitions of the required standard types). Another important difference is that the ISO model contains links to external elements that are outside the access point where the current ontology is located - in particular, in the RDL (Reference Data Library, reference data directory; below we will return to these directories). that the above 148 triplets describe only one template, and there are four of them in our example, plus the definitions of the necessary standard types). Another important difference is that the ISO model contains links to external elements that are outside the access point where the current ontology is located - in particular, in the RDL (Reference Data Library, reference data directory; below we will return to these directories). that the above 148 triplets describe only one template, and there are four of them in our example, plus the definitions of the necessary standard types). Another important difference is that the ISO model contains links to external elements that are outside the access point where the current ontology is located - in particular, in the RDL (Reference Data Library, reference data directory; below we will return to these directories).
Let us consider the possibilities of analyzing a model built according to the rules of ISO 15926. We will perform the same tasks that are described above for the “ordinary” semantic model. Let us want to know in which place the pump with the serial number known to us was installed. In the ISO model, we need the following sequence of simple queries:
SELECT * WHERE { ?temporalpart "S/N DE-1234F"^^ }
The result is an instance ID of the ClassifiedIdentificationOfTemporalPart template. Now we ask what physical object “pump” this template is associated with:
SELECT * WHERE { ?pump }
We get the pump identifier (an object of type MaterializedPhysicalObject). Now we can get a list of instances of the template that describes the installation of the pump:
SELECT * WHERE { ?installation }
Got the instance ID of the InstallationOfTemporalPartMaterializedPhysicalObjectInFunctionPlace template instance. We now find out what functional place the installation was made:
SELECT * WHERE { ?place }
So, we needed to go through four edges of the graph. It is very important that in order to compose these requests, the programmer must be familiar with the principles of ISO 15926 in detail, and have an annotated library of templates (which, in fact, is not in the public domain).
Comparison of the analytical potential of models
Another interesting aspect of the analysis of this graph is related to time (taking into account the temporal aspect is one of the strengths of ISO 15926). If we want to find out which pump was installed in a certain functional place at a certain time, we will have to do this using not very convenient means of working with SPARQL dates. We construct the necessary request.
We get the pump installation episodes, knowing the identifier of the functional place:
SELECT * WHERE { ?inst . }
Now we get the pump identifier - for the sake of a variety of examples, we will do this in the same query:
SELECT * WHERE { ?inst .
?inst ?pump. }
From the pump, there will most likely be a link to its type in RDL - with its help we can find out which pump it is; but we left this part of the model outside our example. It remains to add the condition for the installation dates to the request:
SELECT ?pump WHERE { ?inst .
?inst ?pump.
?inst ?time.
FILTER (?time < "2013-05-09T12:00:00Z"^^)
}
ORDER BY DESC (?time)
LIMIT 1
The combination of using the FILTER condition by installation date, sorting ORDER BY and limiting the number of output results LIMIT gives us only one desired result - it allows you to select the episode of the pump installation that precedes the specified date.
On a “regular” semantic model, this query will have exactly the same structure, and exactly the same number of elements:
SELECT ?pump WHERE { ?inst .
?inst ?pump.
?inst ?time.
FILTER (?time < "2013-05-09T12:00:00Z"^^)
}
ORDER BY DESC (?time)
LIMIT 1
Another interesting aspect of using models built in accordance with ISO 15926 is related to the use of RDL - reference data libraries. They store definitions of device types, their functions, etc. These libraries are available at external SPARQL access points, usually owned by industry associations. There is one link to RDL in our column - this is the definition of the type of a functional object that tells us that it should be a device with a pump function. If we request information about the type of the FunctionalPhysicalObject we have,
SELECT * WHERE { ?rdl }
then we get a link to RDL: < rdl.example.org/sampleReferenceData#R4598459832 > (and at the same time we find out that our function object belongs to the WholeLifeIndividual class, and several other ISO 15926 root classes are not very useful information for us). If now we want to know what this definition means, we will have to query another access point where this RDL is stored:
SELECT * WHERE {
?a.
SERVICE { ?a ?b ?c. }.
}
Such a request will return to us all the information that is available in the RDL for this type of device. As RDL, reference libraries (catalogs) maintained by industry associations and regulators, as well as private catalogs, for example, suppliers of certain equipment, can be used.
In “regular” semantic models, we can also use federated queries. We can create a common catalog, for example, equipment, and place it in an open access point. The whole question is only whose "authority" will be supported by such a repository of information. Giving authority to directories is a function of various associations. At the same time, if you do not cheat, the correspondence or non-compliance of the guidebook with one or another standard does not add practically anything to its "authority". If the catalog of a certain company, for example, a supplier of equipment, is used as RDL, then the question of the presence of “authority” is completely meaningless.
Similarities and differences between “regular” semantics and ISO 15926
The conclusions from the considered examples of the use of semantic models are quite obvious:
1. From a technological point of view, “ordinary” semantic models are quite symmetrical to the ISO 15926 models, if we talk about design data (expressing information about specific systems and processes). ISO models are more complex, and this gap, in comparison with “ordinary” models, grows depending on the volume of the model according to a linear law. This is due to the presence of separate entities for expressing the temporal parts of objects, as well as the need to classify objects in accordance with the classifier of top-level types.
2. From the point of view of the computational potential of these models, calculations on them are also somewhat more complicated than in the “ordinary” semantics, but the difference is not radical. More importantly, to build queries, you need not only familiarity with the model, but also knowledge of the concepts of ISO 15926, as well as the presence of a template navigator (which, as far as we know, is not publicly available; a set of templates and the procedure for their approval, as far as we know are also far from desired).
3. The system of reference data and high-level entities ISO 15926 is very complicated in comparison with the “usual” semantics (if we take as an indicator the number of triplets required to express the model - 10 times or more). This is especially true for libraries of higher-level entities, such as templates. Work with definitions (not instances!) Of these entities by means of semantic technologies is significantly complicated. However, any application that provides the user with the ability to work with templates, and “hiding” their low-level representation from him, must have wide capabilities for such work (search and viewing, creating and editing template definitions, filling them out). A partial solution to the problem may be working with templates that are not expressed as triplets in RDF storage, but as OWL files.
4. The ISO 15926 concepts, considered to be its know-how, and providing the special value of this standard — the use of federated access and RDL libraries, the consideration of temporal parts — are also available in “ordinary” semantics. It all depends on how the data model is built, and how the separation of data into design and reference data is implemented. By the way, we note that there are no practical obstacles to using the RDL libraries built in accordance with ISO 15926 in applications using data models that do not correspond to it.
5. The true value of a standard is, first of all, its status as a standard; generally accepted classification methods and the classifiers themselves (as well as methods of their administration) provide the potential for using the standard for integration between different enterprises, but somewhat complicate the performance of computational tasks on models. This is a natural situation: for any versatility you have to pay for speed.
Thus, the ISO 15926 standard is one of the methods for constructing semantic models, which has certain advantages and disadvantages compared to other methods that contain less than a high-level formalism. From the point of view of practical implementation and potential use, there is no fundamental difference between the standard and other methods that would allow them to be contrasted as different technologies. Declaring the existence of such a difference could be considered a marketing device for propagating the standard if it did not play a daunting role for specialists already familiar with “ordinary” semantic technologies (as is happening now in practice). In addition, to explain the difference between ISO 15926 and “ordinary” semantics at the technological level to people who are not IT specialists,
Creating high-quality models of systems is possible both with the use of this standard, and without it; the decision on its use should be made based on the context of the application of the developed information system, first of all, from the point of view of the possible inclusion of the model in the integration processes, and from the point of view of the requirements for performing calculations on the model. Following the standard can be stated as a general recommendation, but under certain circumstances the need for fast computations on the model may require the implementation of a more rational ontology. Solving the problem of optimizing computing only with hardware is usually irrational.
The main obstacles to the dissemination of the standard should be considered:
- high “entry threshold” - the amount of knowledge necessary for the successful use of this technology;
- lack of a full-fledged methodological base, documentation, developed support communities, collections of examples of use;
- the lack of software available to a wide range of users that provides the ability to work with data models built in accordance with the standard;
- lack of convincing and open examples of the successful use of the standard (beyond the scope of a simple declaration that such and such companies use it for such and such purposes).
It is with these problems that we must fight by spreading the standard as best practice. Its artificial opposition to “ordinary” semantic technologies can play only a negative role in this process.
ps Thanks to Victor Agroskin for clarifying the example model ISO 15926.