HPC Technology Basics
Definition of highly loaded systems and methods of their construction
Server load is an important indicator of server hardware utilization. A hit is a client request to a server for information. Server load is defined as the ratio of the number of client requests (hits) to time, expressed in hits per second. According to Microsoft research in 2010, a server with a load of 100-150 hits per second can be considered a high-loaded server.In the literature, there are such concepts as an HPC system, a highly loaded system, a highly loaded cluster, a Highload system, a supercomputer, which are sometimes used as synonyms. We will understand a site with a load of at least 150 hits per second.
A cluster is a group of computers that work together to form a single unified computing resource. Each node is running its own copy of the operating system, which is most commonly used Linux and BSD.
To understand how the tasks performed by a cluster are distributed among its nodes, it is necessary to define scalability. Scalability - the ability of a system to cope with an increase in workload (increase its productivity) when adding resources. A system is called scalable if it is able to increase performance in proportion to additional resources. Scalability can be estimated through the ratio of the increase in system performance to the increase in resources used. The closer this relationship is to unity, the better. Also, scalability refers to the possibility of increasing additional resources without structural changes to the central node of the system. Scaling the architecture of a heavily loaded system can be horizontal and vertical. Vertical scaling is to increase system performance by increasing server capacity. The main disadvantage of vertical scaling is that it is limited to a certain limit. The parameters of iron cannot be increased indefinitely. However, in fact, the vertical component is almost always present, and universal horizontal scaling as such does not exist. Horizontal scaling is to increase system performance by connecting additional servers. It is horizontal scaling that is now actually the standard. Also known is the term diagonal scaling. It involves the simultaneous use of two approaches. The main disadvantage of vertical scaling is that it is limited to a certain limit. The parameters of iron cannot be increased indefinitely. However, in fact, the vertical component is almost always present, and universal horizontal scaling as such does not exist. Horizontal scaling is to increase system performance by connecting additional servers. It is horizontal scaling that is now actually the standard. Also known is the term diagonal scaling. It involves the simultaneous use of two approaches. The main disadvantage of vertical scaling is that it is limited to a certain limit. The parameters of iron cannot be increased indefinitely. However, in fact, the vertical component is almost always present, and universal horizontal scaling as such does not exist. Horizontal scaling is to increase system performance by connecting additional servers. It is horizontal scaling that is now actually the standard. Also known is the term diagonal scaling. It involves the simultaneous use of two approaches. and universal horizontal scaling as such does not exist. Horizontal scaling is to increase system performance by connecting additional servers. It is horizontal scaling that is now actually the standard. Also known is the term diagonal scaling. It involves the simultaneous use of two approaches. and universal horizontal scaling as such does not exist. Horizontal scaling is to increase system performance by connecting additional servers. It is horizontal scaling that is now actually the standard. Also known is the term diagonal scaling. It involves the simultaneous use of two approaches.
And finally, it is necessary to determine the basic principle used in the construction of any cluster architecture. This is the three-link structure of the system (Fig. 1). The three links are the frontend, backend, and data warehouse. Each link performs its functions, is responsible for the various stages in processing requests, and scales differently. Initially, the request comes to the front end. Frontends are usually responsible for the return of static files, the initial processing of the request and transferring it further. The second link where the request comes, already pre-processed by the front-end, is the backend. The backend is engaged in computing. On the backend side, as a rule, the business logic of the project is implemented. The next layer that goes into query processing is the data warehouse that is processed by the backend. It can be a database or file system.
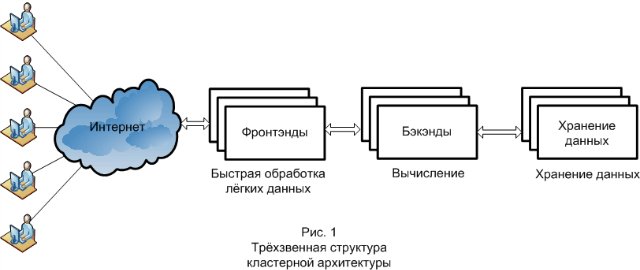
Overview of hardware and software for building a cluster HPC-system
When building a cluster, the task arises of how to distribute the load between servers. For this, load balancing is used, which, in addition to the distribution itself, performs a number of other tasks, for example: increasing fault tolerance (if one of the servers fails, the system will continue to work) and protection against some types of attacks (for example, SYN-flood).Front-end balancing and protection
One of the balancing methods is “DNS Round Robin”, used to scale the front-ends. Its essence is that several DNS records of type A are created on the DNS server to record the domain of the system. The DNS server issues these records in alternating cyclical order. In the simplest case, DNS Round Robin works by responding to requests not only with a single IP address, but with a list of several server addresses that provide the same service. With each response, the sequence of ip addresses changes. As a rule, simple clients try to establish connections with the first address from the list, so different clients will be given addresses of different servers, which will distribute the total load between the servers. To implement the method, any DNS server, for example, bind, is suitable. The disadvantage of this method is that there are DNS servers for some providers,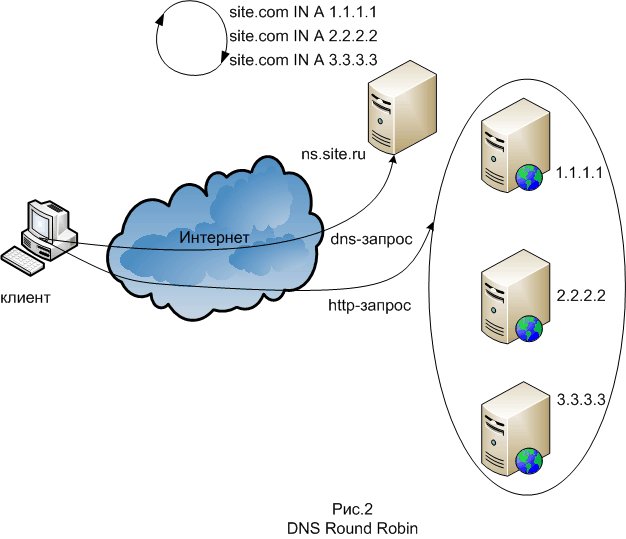 The next balancing method is balancing at the second level of the protocol stack. Balancing is done using a router so that the front-ends accept connections coming to the IP address of the system and respond to them, but do not respond to ARP requests related to this address. Of the software tools of this method, the most common is LVS (Linux Virtual Server), which is a module of the Linux kernel, also this balancing method is called Direct Routing. The main terminology here is as follows: Director - the actual node that performs routing; Realserver - server farm node VIP or Virtual IP - just the IP of our virtual (collected from a bunch of real) server; DIP and RIP - IP directors and real servers. The director includes this IPVS (IP Virtual Server) module, packet forwarding rules are configured and VIP rises - usually as an alias to the external interface. Users will go through VIP. Packets arriving at the VIP are forwarded by the selected method to one of the Realserver's and are already being processed there normally. It seems to the client that he is working with one machine.
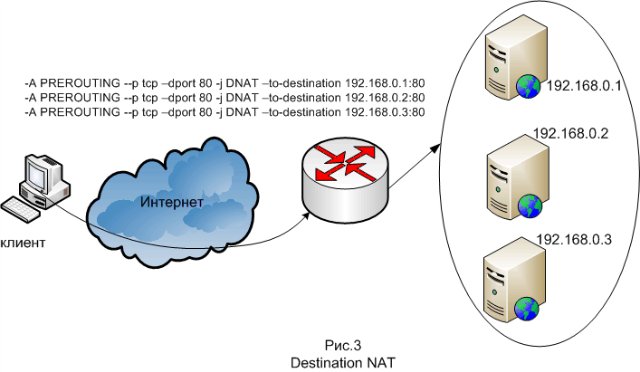
The next balancing method is balancing at the second level of the protocol stack. Balancing is done using a router so that the front-ends accept connections coming to the IP address of the system and respond to them, but do not respond to ARP requests related to this address. Of the software tools of this method, the most common is LVS (Linux Virtual Server), which is a module of the Linux kernel, also this balancing method is called Direct Routing. The main terminology here is as follows: Director - the actual node that performs routing; Realserver - server farm node VIP or Virtual IP - just the IP of our virtual (collected from a bunch of real) server; DIP and RIP - IP directors and real servers. The director includes this IPVS (IP Virtual Server) module, packet forwarding rules are configured and VIP rises - usually as an alias to the external interface. Users will go through VIP. Packets arriving at the VIP are forwarded by the selected method to one of the Realserver's and are already being processed there normally. It seems to the client that he is working with one machine.Another method is balancing at the third level of the protocol stack, that is, at the IP level. This method works in such a way that when a connection is made to the IP address of the system, Destination NAT is done on the balancer, that is, in packets the destination IP addresses are replaced by the IP addresses of the frances. For responses, packet headers are modified back. This is done using netfilter, which is part of the Linux kernel.
 As far as the front-ends receive requests from users, the main task of protecting the cluster lies precisely with the front-ends (or the front-end balancer, depending on the architecture). It is necessary to provide protection against all kinds of hacker attacks (for example, such as SYN flood and DDOS). Mostly, a firewall (firewall - fire wall) is used for protection, its other name is a firewall (brandmauer - fire wall), another name is a firewall. The firewall blocks malicious traffic using packet filtering rules, and can also perform actions such as caching, address translation, and forwarding on the traffic. GNU / Linux has a built-in netfilter firewall, which is part of the Linux kernel.
As far as the front-ends receive requests from users, the main task of protecting the cluster lies precisely with the front-ends (or the front-end balancer, depending on the architecture). It is necessary to provide protection against all kinds of hacker attacks (for example, such as SYN flood and DDOS). Mostly, a firewall (firewall - fire wall) is used for protection, its other name is a firewall (brandmauer - fire wall), another name is a firewall. The firewall blocks malicious traffic using packet filtering rules, and can also perform actions such as caching, address translation, and forwarding on the traffic. GNU / Linux has a built-in netfilter firewall, which is part of the Linux kernel.Backend Scaling
When building highly loaded websites, light and heavy http requests are distinguished. Light requests are requests for static web pages and images. Heavy queries are an appeal to a certain program that generates content dynamically. Dynamic web pages are generated by a program or script written in a high-level language: most often PHP, ASP.net, Perl and Java. The combination of these programs is called business logic. Business logic is a set of rules, principles, dependencies of the behavior of objects of the subject area, the implementation of the rules and restrictions of automated operations. The business logic is on the backends. Two schemes are used: the first - the front-end web server will process light requests, and heavy proxies it to backends; the second - the frontend acts purely as a proxy,Apache is often used as the web server used on backends. Apache is the most popular HTTP server. Apache has a built-in virtual host mechanism. Apache provides various multiprocessor models (MPMs) for use in a variety of work environments. The prefork model - the most popular on Linux - creates a certain number of Apache processes when it starts and manages them in the pool. An alternative model is worker, which uses multiple threads instead of processes. Although threads are lighter than processes, they cannot be used until your entire server is thread safe. And the prefork model has its own problems: each process takes up a lot of memory. Highly loaded sites process thousands of files in parallel, while being limited in memory and by the maximum number of threads or processes. In 2003, German developer Jan Kneschke became interested in this problem and decided that he could write a web server that would be faster than Apache, focusing on the right techniques. He designed the Lighttpd server as a single process with a single thread and non-blocking I / O. To perform the scaling task, you can use Lighttpd + Apache, so that Lighttpd will give all the static to the client, and requests ending, for example, with .cgi and .php will be transferred to Apache. Another popular server for solving the scaling problem is Nginx. Nginx is an HTTP server and reverse proxy server, as well as a mail proxy server. As a proxy server, Nginx is put on the frontends. There may be several backends, then Nginx works as a load balancer. This model saves system resources due to the fact that requests are accepted by Nginx, Nginx sends an Apache request and quickly receives a response, after which Apache frees up memory and Nginx interacts with the client (responds to simple requests), which is written to distribute static content , a large number of customers, with little consumption of system resources. Under Microsoft Server, IIS is used as the backend web server, and business logic is written on ASP.net. which is written to distribute static content to a large number of clients, with little consumption of system resources. Under Microsoft Server, IIS is used as the backend web server, and business logic is written on ASP.net. which is written to distribute static content to a large number of clients, with little consumption of system resources. Under Microsoft Server, IIS is used as the backend web server, and business logic is written on ASP.net.
Another way to scale backends is a scalable application server. Applicable if the business logic is written in Java, namely on its server version. These applications are called servlets, and the server is called the servlet container or application server. There are many open source servlet containers: Apache Tomcat, Jetty, JBoss Application Server, GlassFish and proprietary: Oracle Application Server, Borland Application Server. Many application servers support clustering, provided that the application is designed and developed according to clearly defined levels. In addition, to solve critical problems with applications, Oracle Application Server supports “cluster islands” - sets of servers at the J2EE level,
DBMS scaling
And finally, in the description of software tools used to create cluster HPC-systems, it is necessary to mention the means of scaling data warehouses. As a data warehouse for the web, general-purpose databases are used, the most common of which are MySQL and PostgreSQL.The main technique for DBMS scaling is sharding, or rather it would be more correct to call sharding not scaling, but splitting data into machines. The essence of the method is that with an increase in the amount of data, new shard servers are added, which are added when the existing shards are filled to a certain limit.
When scaling a DBMS, the replication technique comes to the rescue. Replication is a means of communication between database servers. Using replication, you can transfer data from one server to another or duplicate data on two servers. Replication is used in the “virtual shard” scaling technique - using replication, the data is distributed so that each backend server works with its own virtual shard, information about where the physical shard is physically located is stored in the matching table. Also, the replication technique in the scaling method, based on the features of database queries: rare update operations and frequent read requests. Each backend server works with its own database server, they are called SLAVE, read operations from the table (SELECT function) occur on these servers.
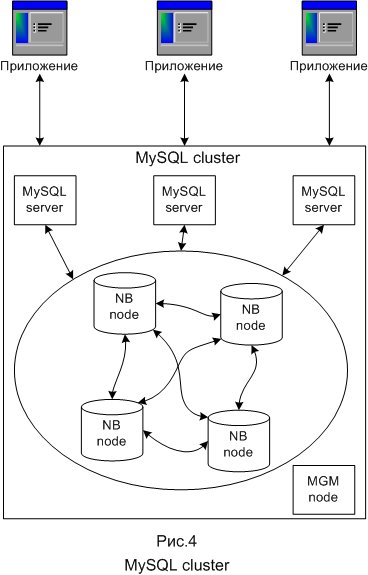
MySQL uses different storage systems. Most often these are MyISAM and InnoDB. There is also an NDB storage system that is used in a special MySQL scaling tool called MySQL cluster. The clustered part of MySQL Cluster is currently configured independently of MySQL servers. In MySQL Cluster, each part of the cluster is called a node, and the nodes are actually processes. There can be any number of nodes on one computer. In the minimum configuration of a MySQL cluster, there will be at least three nodes: the manager (MGM node) - its role: manage other nodes inside MySQL Cluster, such as providing configuration data, starting and stopping nodes, performing backups, etc .; database node (DB node) - manages and saves the database directly, there are so many DB nodes, how many fragments are available for replications, for example, with two replications, two fragments each, you need four DB nodes; client node (API) - a user node that will access the cluster, in the case of a MySQL cluster, the user node is a traditional MySQL server that uses the NDB Cluster storage type, allowing access to clustered tables.
Distributed computing as an alternative solution
Sometimes, instead of building your own highly loaded system based on cluster architecture, it is easier and more profitable for a client to use the Internet services of distributed computing. Distributed computing is a way to solve time-consuming computing tasks using several computers, most often combined into a parallel computing system. The history of distributed computing dates back to 1999, when freshman at Northeastern United States University, Sean Fanning, wrote a system for exchanging MP3 files between users. This project is called Napster. Following the example of Napster, a whole class of P2P (or peer-to-peer) networks of a new, decentralized type has developed, P2P file sharing is that the user does not download files from the server, but from the computers of other users of the file sharing network, The IP addresses that he receives from a specialized server called a tracker or hub. Downloading files occurs simultaneously from all peers (members of the peer-to-peer network) and is accompanied by simultaneous upload, so the peer-to-peer network is a kind of distributed file storage.The technology of distributed computing developed, and the P2P principles began to be used not only to create distributed file storages, distributed databases, streams, processors appeared.
Grid computing (grid - lattice, network) is a form of distributed computing in which a “virtual supercomputer” is presented in the form of clusters connected by a network, working together to perform a huge number of tasks. Grid is a system that coordinates distributed resources through standard, open, universal protocols and interfaces to ensure non-trivial quality of service. The main idea underlying the concept of grid computing is the centralized remote provision of resources necessary for solving various kinds of computing problems. The user can run any task from any computer to the calculation, the resources for this calculation should be automatically provided on the remote high-performance servers, regardless of the type of task. Resource allocation in which grid developers are interested, this is not file sharing, but direct access to computers, software, data and other resources that are required for jointly solving tasks and resource management strategies. The following levels of grid architecture are distinguished: basic (contains various resources, such as computers, storage devices, networks, sensors, etc.); binding (defines communication protocols and authentication protocols); resource (implements protocols for interaction with the resources of the RVS and their management); collective (resource catalog management, diagnostics, monitoring); applied (tools for working with grids and user applications). which are required for jointly solving tasks and resource management strategies. The following levels of grid architecture are distinguished: basic (contains various resources, such as computers, storage devices, networks, sensors, etc.); binding (defines communication protocols and authentication protocols); resource (implements protocols for interaction with the resources of the RVS and their management); collective (resource catalog management, diagnostics, monitoring); applied (tools for working with grids and user applications). which are required for jointly solving tasks and resource management strategies. The following levels of grid architecture are distinguished: basic (contains various resources, such as computers, storage devices, networks, sensors, etc.); binding (defines communication protocols and authentication protocols); resource (implements protocols for interaction with the resources of the RVS and their management); collective (resource catalog management, diagnostics, monitoring); applied (tools for working with grids and user applications). resource (implements protocols for interaction with the resources of the RVS and their management); collective (resource catalog management, diagnostics, monitoring); applied (tools for working with grids and user applications). resource (implements protocols for interaction with the resources of the RVS and their management); collective (resource catalog management, diagnostics, monitoring); applied (tools for working with grids and user applications).

The next step in the evolution of distributed computing is cloud computing. Berkeley’s lab gives the following definition: “Cloud computing is not only applications delivered as services over the Internet, but also hardware and software systems in data centers that provide these services.” Cloud computing is a technology in which distributed resources are provided to the user as an Internet service.
Thanks to cloud computing, companies can provide end users with remote dynamic access to services, computing resources and applications (including operating systems and infrastructure) via the Internet. Computing clouds consist of thousands of servers located in physical and virtual data centers, providing tens of thousands of applications that millions of users use simultaneously.
All possible methods for classifying clouds can be reduced to a three-layer architecture of cloud systems, consisting of the following levels:
- Infrastructure as a Service: IaaS
- platform as a service (Platform as a Service: PaaS)
- software as a service (Software as a Service: SaaS)
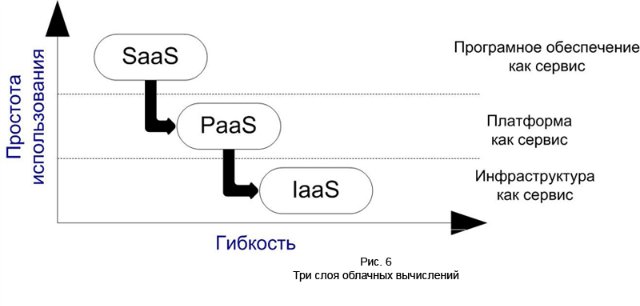
SaaS is a web-based software deployment model that makes software completely accessible through a web browser. For users of the SaaS system, it does not matter where the software is installed, what operating system it uses, and in which language it is written: PHP, Java or. NET And, most importantly, the user does not need to install anything anywhere. For example, Gmail is an email program accessible through a browser. At the same time, Gmail itself is distributed in a cloud of servers located around the world, that is, it uses SaaS technology.
PaaS presents the user with an infrastructure and functionally complete service and application development environments for deploying custom web applications. For example, a Google App Engine user can write their own Python application using the Google APIs.
Iaas offers information resources, such as computational cycles or information storage resources, as a service. Instead of providing access to raw computing and storage devices, IaaS providers typically provide a virtualized structure as a service.
The largest cloud providers at the end of 2012 are: Amazon Web Services, Windows Azure and Google App Engine.
Amazon Web Services (AWS) - A comprehensive description of Amazon for all of its cloud services, it covers a wide range of services. Amazon Elastic Cloud Compute (Amazon EC2) is the heart of the Amazon cloud. This service provides web services APIs for provisioning, managing and releasing virtual servers after they become unnecessary with the release of freed resources to the Amazon cloud. EC2 is a user virtual network, which includes virtual servers. The primary means of accessing amazon EC2 is through the web services application programming interface (API). Amazon provides a number of interactive tools that work with the API, such as the Amazon Web Services Console, the Firefox ElasticFox plugin,
Windows Azure is a cloud platform developed by Microsoft. Windows Azure provides storage, use and modification of data on Microsoft data center computers. From the user's point of view, there are two categories of applications: internal, executable on the user's computer, and cloud, actually executable in the Windows Azure environment on the data center computers. The core component of Windows Azure for managing applications in the cloud is the Windows Azure AppFabric, which is a mid-tier cloud platform for developing, deploying, and managing applications on the Windows Azure platform. According to Windows classification, Azure refers to a PaaS-type cloud platform, i.e.
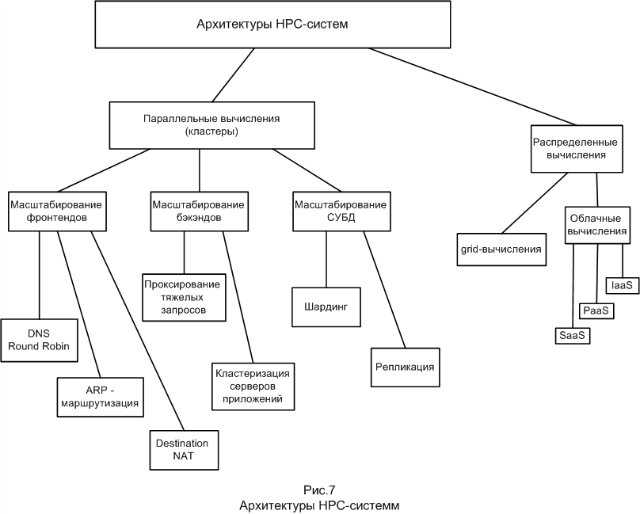
Summarizing, all considered architectures of HPC-systems can be represented as such a block diagram:
Used sources
- High load textbook - journal “Hacker: a magazine from computer hooligans” - No. 7-11 2012
- Collection of the best materials of the conference of developers of high-loaded systems HighLoad ++ for 2010 and 2011 [Electronic resource] - Moscow, 2012.
- Radchenko G.I. Distributed Computing Systems - Chelyabinsk: Photographer, 2012. - 182s.
- Reese J. Cloud Computing: Per. - St. Petersburg: BHV-Petersburg, 2011. -288 pp .: ill.
- Safonov V. O. Cloud computing platform Microsoft Windows Azure - M.: National Open University INTUIT, 2013 - 234 pp., Ill.