Streamline Template Processing
In practice, I had to deal with some not obvious features of template processing performance. The study of the issue gave rise to a small study, the results of which I hasten to share.
I am currently developing a fairly large project on Django. The project is large, I’m actually developing it alone, so the optimization question arises only when it’s completely hot. General technical information on the project:
Project size: about 70k lines
Django: 1.4.3
Environment: apache2 + mod_wsgi + virtualenv, python2.6, mysql, dedicated server. The project on the server is not the only one.
I am a fan of the invention of bicycles, so the decorator collected performance time, module name, function name, user name and key parameter from the view and saved everything in the database.
The result - the average runtime of one of the main performances was 1200ms, which is extremely sad.
The first thing that comes to mind is of course the ineffective work with the database. A fairly large amount of work was carried out, which halved the number of database queries, their complexity (and execution time) by half. It was supposed that this would correct the situation, but the result was not at all impressive. The execution time fell “only” by 100ms and amounted to 1100ms, which did not make the weather. The database optimization margin still remained, and there are many other ways, but it became clear that the problem was clearly not in working with the database. A more detailed profiling of the presentation function showed that about 80-90% of the time, a line is executed that you get used to not noticing:
The project uses hamlpy as a template engine, which in itself is not fast. The patterns themselves are quite complex - they include double inheritance, several include, loops, a lot of logic associated with the mapping. However, 950ms for rendering is too much.
Upgrading hamlpy to the latest version won about 50ms more. Rendering a template still takes an average of 900ms.
A more detailed study of the issue allowed us to learn about the fact that django can cache templates, and this must be configured separately:
The processing time of the template fell markedly, to 500-600ms, but still remained significant. At the same time, an unpleasant effect appeared - changes in the templates, which is logical, stopped clinging on the fly. So under DEBUG it is better to refuse caching.
Looking in more detail at the statistics, I noticed that the results are heterogeneous. If I had a distribution graph, then probably there would be not one Gaussian curve on it, but two. Curiosity overcame laziness, and graphs were bolted to statistics. Coming back a little, this is how the distribution of the processing time of the template without caching looks like:

The graph does not have a pronounced curve, since the statistics are collected in one view without specification. The volume of HTML output of this view depends on a large number of different parameters, and processing its template takes different times. The peaks in the graph are presumably the result of overlapping curves from several key factors. Probably if we take the samples not only according to the representation, but also to its parameters, then classical curves would be obtained. But this is somewhat beyond the scope of the study.
Returning to caching, his distribution chart looks like this:

Indeed, there are two peaks on it. The nature of the peak on the left is understandable - this is the result of the caching action. But the peak on the right obviously arises from the lack thereof. Apache regularly kills threads to protect against memory leaks. I don’t know how often he does this, but judging by the schedule, he kills them after every third request, which makes caching not very effective.
We go into the configuration of the Apache host and do the following: This translates the life cycle of threads from maintaining Apache to mod_wsgi and sets the life time of the stream to 5 requests. We get the following chart:

As you can see, the peak on the right has become smaller. Streams began to die less often, caching efficiency increased, average execution time fell. The path is clearly the right one, but the graph of well-functioning caching should obviously not look like this. We increase the lifetime to 10 requests:

Already not bad. Execution time has fallen noticeably to an acceptable value of 230ms. The best is the enemy of the good, and the life span of the stream is not bullshit. Studying memory consumption through top did not reveal any tangible problems, so we increase the lifespan to 15:
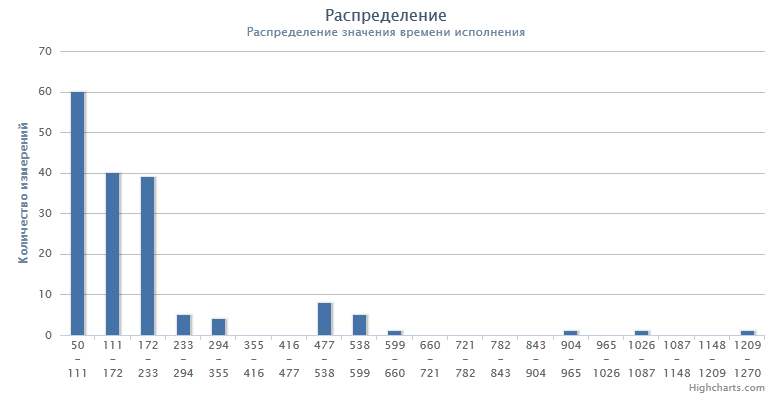
Such a schedule looks plausible - non-cached requests have ceased to be statistically significant, which means that a further increase in the life of the threads will not give a tangible result. The total achieved execution time is 190ms. The performance time of the performance itself fell from 900 to 290ms, which is already much better.
When optimizing the application code, one should also pay attention not only to the presentation itself, but also to the template processing process. A key factor in the fight for processing speed may be the lifetime of the threads running your application. In my case, the optimal lifetime of the threads was 15 queries, but most likely for different projects this may be a different number that needs to be selected, looking back at memory consumption.
Background
I am currently developing a fairly large project on Django. The project is large, I’m actually developing it alone, so the optimization question arises only when it’s completely hot. General technical information on the project:
Project size: about 70k lines
Django: 1.4.3
Environment: apache2 + mod_wsgi + virtualenv, python2.6, mysql, dedicated server. The project on the server is not the only one.
Problem assessment
I am a fan of the invention of bicycles, so the decorator collected performance time, module name, function name, user name and key parameter from the view and saved everything in the database.
The result - the average runtime of one of the main performances was 1200ms, which is extremely sad.
Database Optimization
The first thing that comes to mind is of course the ineffective work with the database. A fairly large amount of work was carried out, which halved the number of database queries, their complexity (and execution time) by half. It was supposed that this would correct the situation, but the result was not at all impressive. The execution time fell “only” by 100ms and amounted to 1100ms, which did not make the weather. The database optimization margin still remained, and there are many other ways, but it became clear that the problem was clearly not in working with the database. A more detailed profiling of the presentation function showed that about 80-90% of the time, a line is executed that you get used to not noticing:
return direct_to_template(request, template_name, locals())
The project uses hamlpy as a template engine, which in itself is not fast. The patterns themselves are quite complex - they include double inheritance, several include, loops, a lot of logic associated with the mapping. However, 950ms for rendering is too much.
Upgrading hamlpy to the latest version won about 50ms more. Rendering a template still takes an average of 900ms.
A more detailed study of the issue allowed us to learn about the fact that django can cache templates, and this must be configured separately:
TEMPLATE_LOADERS = (
('django.template.loaders.cached.Loader', (
'hamlpy.template.loaders.HamlPyFilesystemLoader',
'hamlpy.template.loaders.HamlPyAppDirectoriesLoader',
'django.template.loaders.filesystem.Loader',
'django.template.loaders.app_directories.Loader',
)),
)
The processing time of the template fell markedly, to 500-600ms, but still remained significant. At the same time, an unpleasant effect appeared - changes in the templates, which is logical, stopped clinging on the fly. So under DEBUG it is better to refuse caching.
Looking in more detail at the statistics, I noticed that the results are heterogeneous. If I had a distribution graph, then probably there would be not one Gaussian curve on it, but two. Curiosity overcame laziness, and graphs were bolted to statistics. Coming back a little, this is how the distribution of the processing time of the template without caching looks like:
The graph does not have a pronounced curve, since the statistics are collected in one view without specification. The volume of HTML output of this view depends on a large number of different parameters, and processing its template takes different times. The peaks in the graph are presumably the result of overlapping curves from several key factors. Probably if we take the samples not only according to the representation, but also to its parameters, then classical curves would be obtained. But this is somewhat beyond the scope of the study.
Returning to caching, his distribution chart looks like this:
Indeed, there are two peaks on it. The nature of the peak on the left is understandable - this is the result of the caching action. But the peak on the right obviously arises from the lack thereof. Apache regularly kills threads to protect against memory leaks. I don’t know how often he does this, but judging by the schedule, he kills them after every third request, which makes caching not very effective.
We go into the configuration of the Apache host and do the following: This translates the life cycle of threads from maintaining Apache to mod_wsgi and sets the life time of the stream to 5 requests. We get the following chart:
WSGIDaemonProcess mysite threads=5 maximum-requests=5
As you can see, the peak on the right has become smaller. Streams began to die less often, caching efficiency increased, average execution time fell. The path is clearly the right one, but the graph of well-functioning caching should obviously not look like this. We increase the lifetime to 10 requests:
Already not bad. Execution time has fallen noticeably to an acceptable value of 230ms. The best is the enemy of the good, and the life span of the stream is not bullshit. Studying memory consumption through top did not reveal any tangible problems, so we increase the lifespan to 15:
Such a schedule looks plausible - non-cached requests have ceased to be statistically significant, which means that a further increase in the life of the threads will not give a tangible result. The total achieved execution time is 190ms. The performance time of the performance itself fell from 900 to 290ms, which is already much better.
conclusions
When optimizing the application code, one should also pay attention not only to the presentation itself, but also to the template processing process. A key factor in the fight for processing speed may be the lifetime of the threads running your application. In my case, the optimal lifetime of the threads was 15 queries, but most likely for different projects this may be a different number that needs to be selected, looking back at memory consumption.