Storage systems: how slowly, but surely they get rid of iron
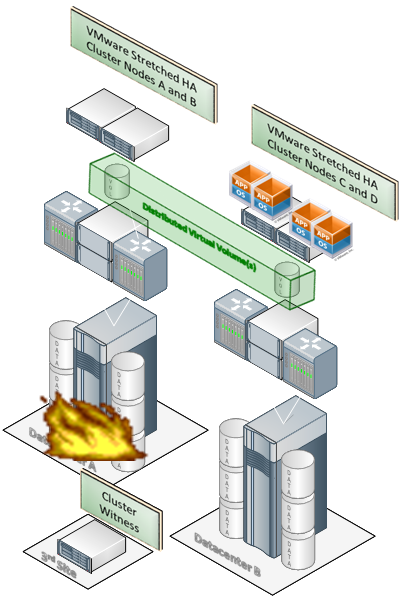
An accident in the first data center and automatic restart of services in another
Virtualization is one of my favorite topics. The fact is that now you can almost completely forget about the hardware used and organize, for example, a data storage system in the form of a “logical” unit that can interact with information according to simple rules. Moreover, all the processes between the virtual unit and the real hardware in different data centers lie on the virtualization system and are not visible to applications.
This gives a bunch of advantages, but it also poses a number of new problems: for example, there is a question of ensuring data consistency in synchronous replication, which imposes restrictions on the distance between nodes.
For example, the speed of light becomes a real physical barrier., which does not allow the customer to put the second data center beyond 40-50, or even less, kilometers from the first.
But let's start from the very beginning - how storage virtualization works, why it is needed, and what tasks are being addressed. And most importantly - where exactly can you win and how.
A bit of history
At first there were servers with internal disks on which all information was stored. This rather simple and logical solution quickly became not the most optimal, and over time we began to use external storage. At first, simple, but gradually required special systems that allow you to store incredibly much data and give them very quick access. Storage systems differed from each other in volume, reliability and speed. Depending on specific technologies (for example, magnetic tape, hard drives or even SSDs, which now, of course, will not surprise anyone), these parameters could be varied over a rather wide range - the main thing is that there is money.
For CIOs, one of the most important storage criteria right now is reliability. For example, an hour of downtime for a bank may well cost as much as 10-20 such cabinets with iron, not to mention reputation losses - therefore, geographically distributed fault-tolerant solutions have become the main paradigm. Simply put - glands that duplicate each other, which are in two different data centers.
Evolution:

I stage: Two servers with integrated disks.

II stage: storage and two machines in one data center.

Stage III: Different data centers and the replication between them (the most common option)

Stage IV: Virtualization of this economy. By the way, in a bunch in the middle you can stick, for example, an additional backup.

V stage: Virtualization of storage (EMC VPLEX)
One of the tools for solving this problem is EMC VPLEX, on the example of which you can clearly understand the advantages of this virtualization.
System comparison
So what's the point?
Before VPLE X: there are two servers, each sees its own volume, replication between volumes. One always stands and waits, the second always works. The backup server does not have write permissions until the primary data center fails.
After implementing VPLEX : replication is not needed. Both servers see only one virtual volume as directly connected to itself. Each server works with its own volume, and everyone thinks that it is a local volume. In reality, everyone works with their storage.
Before : to transfer data to another storage (physical storage), you need to reconfigure the servers, clusters, and so on. This reduces fault tolerance and can cause errors: during reconfiguration, the cluster may part, for example.
After: without loss of fault tolerance and transparent for servers, you can transfer data (all storage systems are hidden under VPLEX and the servers do not even know about hardware). The mechanics are as follows: add a new storage system, connect it under VPLEX, mirror it without removing the old one, then switch it over and the server does not even notice.
Before : there are problems with different vendors, for example, you cannot configure HP replication with an EMC array.
After : you can connect an array of HP and EMC (or other manufacturers) and calmly assemble a volume from two hundredorages. This is especially cool, because large customers often have a heterogeneous “zoo” that integrates tightly and is easily upgraded. This means that any critical system can be easily and simply transferred to a new hardware without an accompanying headache.
Before: It takes time to switch replication and cluster.
After : only the application in the cluster is restarted, it is always either on one node or on the second, but it is transparently and quickly transferred.
Before : architecture is a geocluster with all limitations.
After : architecture - local cluster. More precisely, the server thinks so, and therefore there is no difficulty in working with it.
Before : you need replication management software.
After : VPLEX monitors replication at the system level. And indeed, there is essentially no replication - there is a “mirror”.
Before : SRM imposes its limitations on restarting the VM in the backup data center.
After: standard VMotion works when moving VMs to a backup site (preceding the question about the channel: yes, we have a wide channel between the sites, since we are talking about a serious Disaster Recovery solution).
How to move without downtime?
It is necessary to move from one piece of iron to another quite often: approximately every two to three years, highly loaded systems require modernization. In Russia, the reality is that many customers are simply afraid to touch their systems and produce “crutches” instead of transferring - and often quite justified, because there are many examples of errors when moving. It’s easy to move with VPLEX - the main thing is to know about this opportunity.
Another interesting point is the transfer of systems for which performance is incomprehensible. For example, a bank launches a new service, and its availability in six months becomes an important competitive advantage. The load on iron is growing, you need to make a difficult and painful move (banks are afraid of even one lost transaction, and even 5 milliseconds of a miss is a problem). In this case, VPLEX-like systems become the only more or less reasonable alternative. Otherwise, quickly and transparently replacing the storage system will not be easy.
Let's say the system is old and rigidly attached to the hardware. When moving to another hardware, you need an environment that will help carry out the transfer without affecting the work of users and services. By placing such a system under VPLEX, it can be easily transferred between vendors - applications will not even notice. There are no problems with OS support either. In the list of compatibility all the major OSes that are found at the customer. In exotic cases, you can check the compatibility with the vendor or partner and get confirmation.

We take the current storage system (left) and mirror it with EMC VPLEX tools invisibly to the server and applications (right). In terms of VPLEX, this is called Distributed volume. The server continues to think that it works with one store and one volume.

In fact, the first storage system becomes something like a piece of mirror. We turn it off - and the move is ready.
About sync
There are three configurations - Local (1 data center), Metro (synchronous replication) and Geo (2 asynchronous data centers). A type of synchronous replication with x-connection - Campus. Synchronous replication is most in demand (this is 99% of deployments in Russia). Here the heartless speed of light comes into play, which sets the maximum distance between the data centers - it should be enough 5 milliseconds to pass the signal. You can configure it with 10 milliseconds, but the closer the data centers are, the better. Usually it is 30-40 kilometers maximum.

Schema Options for Synchronous Replication
VPLEX gives servers read-write access. Servers see one data volume each on its site, but in reality it is a virtual distributed VPLEX volume. Metro allows for long delays, Campus gives greater reliability. In Campus, it looks like this:

The best part is that there is no problem switching replication when moving virtual machines.

When using Campus, failure of all disk subsystems and the local part of VPLEX will result in the loss of only half the paths for the disk. The drives themselves will remain available to the servers - only through the x-connection and the remote part of VPLEX. Here's how it works for Oracle.
There are still situations like data centers in Moscow and Novosibirsk, they are solved by asynchronous replication. Her VPLEX also knows how, but already in the configuration of Geo.
And if the accident?

Here VPLEX Metro and VMware HA (but maybe Hyper-V) - and an accident in one of the data centers.
Services are restarted in another data center without the participation of an administrator, as for Vmware, it is a single HA cluster.
In the middle, there is Witness, a virtual machine that monitors the state of both clusters and ensures that when the connection between them is broken, both of them do not start processing data. That is, it protects against machine "schizophrenia." Witness allows only one cluster to work with the most up-to-date copy in the event of an accident - and after fixing the problem, the second simply receives a more recent version of the data and continues to work.
Witness is deployed either on the third platform or at a cloud provider. It communicates with EMC VPLEX over IP via VPN. She does not need anything else to work.
Remote site data
Obtaining data physically located in another data center is also not a question. What for? For example, if there is not enough space in the main data center. Then you can take it to the backup.
Heterogeneous iron

Ecosystem VPLEX & Partners
We have built such a solution in the CROC solutions center based on EMC technologies. On one site EMC storage, a Cisco server (for many, the news is that Cisco produces very good servers), on another site Hitachi is virtualized, and an IBM server. But as you can see, all other vendors are also quietly supported. That week, we conducted a demonstration of the system for one of the banks, for which a stand was assembled, and their specialists themselves were convinced that there were no jambs, and the integration was really smooth. During the demonstration, we imitated various accidents and failures that we prepared, or the customer suggested them during the meeting. The next step is a pilot project on several small systems. Despite the experience of operating these pieces of iron, each customer wants to make sure himself that everything works. The solution center is made just for this,
More bonuses
- When working in one data center, VPLEX also solves the problem of mirroring inside this data center. In addition, VPLEX is much softer about miscalculations in the required performance - you can move to a more powerful storage system during the course of the play.
- Having the capacities in the remote data center, I want to use them - you can use the "backup" data center for storage in some cases, while keeping the server on your site.
How does data access work?
Surely you are already wondering how it works a level lower. So, earlier, when writing on one site and reading from another, there was a chance to get on irrelevant data. VPLEX has a directory system that shows which node has the most recent data, so cache can be considered shared across the entire system.

When reading a section just recorded by another machine, such a bunch works.
Configuration

You can start small, for example, put a block that contains 2 controllers (that is, it is already a fault-tolerant configuration, up to 500,000 iops) - then you can go to the middle configuration or achieve the maximum 4-node configuration in the rack in each data center. That is, up to 2,000,000 iops, which is not always necessary, but quite achievable. You can go further and create VPLEX domains, but before that, I think, no one has matured in our market yet.
Pros and cons
Minuses:
- Need implementation costs and licenses
- It is necessary to make a decision on the transition to a new philosophy and train staff
- Most likely, the transition process will be phased (but remember how we virtualized our servers!)
Pros:
- You can get rid of iron and not worry about the failure of parts of the system, getting reliability of five nines.
- Easy scaling and moving.
- Simple manipulations with virtual machines and applications.
- No multi-vendor problem.
- A system from a certain level is cheaper than a bunch of software for solving local storage problems in data centers.
- Due to the simplicity and transparency of all actions, the use of VPLEX significantly reduces the number of human errors.
- Forgives inaccurate performance forecasts.
- VPLEX allows you not to think about sharpening iron for a specific task, but to use it the way you want.
- Moving From Failover to Mobility
- Server administrators configure clusters as before, using the same tools.
Implementation
If you want to try or see how it all works live - write to vbolotnov@croc.ru. And I will answer any questions in the comments.