Organization of safe testing in production. Part 1
- Transfer
This article discusses the different types of testing in production and the conditions under which each of them is most useful, and also describes how to organize safe testing of various services in production.
It is worth noting that the content of this article applies only to those services , the development of which is controlled by the developers. In addition, you should immediately warn that the use of any of the types of testing described here is a difficult task, which often requires major changes to the systems design, development and testing processes. And, despite the title of the article, I do not consider that any of the types of testing in production is absolutely reliable. There is only an opinion that such testing can significantly reduce the level of risks in the future, and the investment costs will be reasonable.
(Approx. Lane .: since the original article is a longrid, for the convenience of readers, it is divided into two parts).
Why do you need testing in production if it can be performed on staging?
The meaning of a staging cluster (or staging environment) is perceived differently by different people. For many companies, deploying and testing a product on rating is an essential step prior to its final release.
Many well-known organizations perceive stying as a miniature copy of the work environment. In such cases, it is necessary to ensure their maximum synchronization. In this case, it is usually necessary to ensure the operation of differing instances of stateful systems, such as databases, and to regularly synchronize data from the production environment with the staging. The only exception is confidential information that allows you to identify the user (this is necessary to comply with the requirements of GDPR , PCI , HIPAAand other regulations).
The problem with this approach (in my experience) is that the difference lies not only in the use of a separate database instance containing the actual production-environment data. Often the difference extends to the following aspects:
- Staging cluster size (if it can be called a “cluster” - sometimes it’s just one server under the guise of a cluster);
- The fact that staging usually uses a cluster of a much smaller scale also means that the configuration parameters for almost every service will differ. This applies to load balancers, databases, and queues, for example, the number of open file descriptors, the number of open connections to the database, the size of the thread pool, etc. If the configuration is stored in a database or a key-value data repository (for example, Zookeeper or Consul), these support systems must also be present in the staging environment;
- The number of real-time connections handled by a stateless service, or the way the proxy server reuses TCP connections (if this procedure is performed at all);
- Lack of monitoring on pricing. But even if it is monitored, some signals may be completely inaccurate, since an environment other than the working environment is monitored. For example, even if you are monitoring the delay of a MySQL query or response time, it is difficult to determine whether a new code contains a query that can initiate a full table scan in MySQL, since it is much faster (and sometimes even preferable) to perform a full scan of a small table used in the test database, rather than a production database, where the query may have a completely different performance profile.
Although it is fair to assume that all the above differences are not serious arguments against the use of styling as such, unlike antipatterns, which should be avoided. At the same time, the desire to do everything correctly often requires huge labor costs for engineers in an attempt to ensure compliance with the environments. Production is constantly changing and influenced by various factors, so an attempt to achieve the specified match is like going nowhere.
Moreover, even if the conditions on pricing are as similar to the working environment as possible, there are other types of testing that are better applied based on real production information. A good example would be soak testing, in which the reliability and stability of a service is checked over an extended period of time with actual levels of multitasking and workload. It is used to detect memory leaks, determine the duration of pauses in the GC, the CPU load and other indicators for a certain period of time.
None of the above suggests that staging is absolutelyuseless (this will become apparent after reading the section on shadow data duplication when testing services). This only indicates that quite often relying on rankings is more than necessary, and in many organizations it remains the only type of testing performed before the full product release.
The Art of Testing in Production
So historically, the concept of “testing in production” is associated with certain stereotypes and negative connotations (“partisan programming”, lack or absence of unit and integration testing, carelessness or inattention to the perception of the product by the end user).
Testing prodakshene certainly be deserving of this reputation, if it is done carelessly and poorly. It in no way replaces testing at the pre-production stage and under no circumstances is it a simple task . Moreover, I contend that for a successful and secureProduction testing requires a significant level of automation, a good understanding of current practices, and the design of systems with an initial focus on this type of testing.
To organize a comprehensive and secure process for effectively testing services in production, it is important not to regard it as a generic term for a set of different tools and techniques. This mistake, unfortunately, was made by me - in my previous article I presented not quite a scientific classification of testing methods, and in the section “Testing in production” there were grouped a variety of methodologies and tools.

From the Testing Microservices note, the sane way (“A reasonable approach to testing microservices”)
From the moment of the publication of the note at the end of December 2017, I discussed its content and generally the topic of testing in production with several people.
During these discussions, as well as after a series of separate conversations, it became clear to me that the topic of testing in production cannot be reduced to several points listed above.
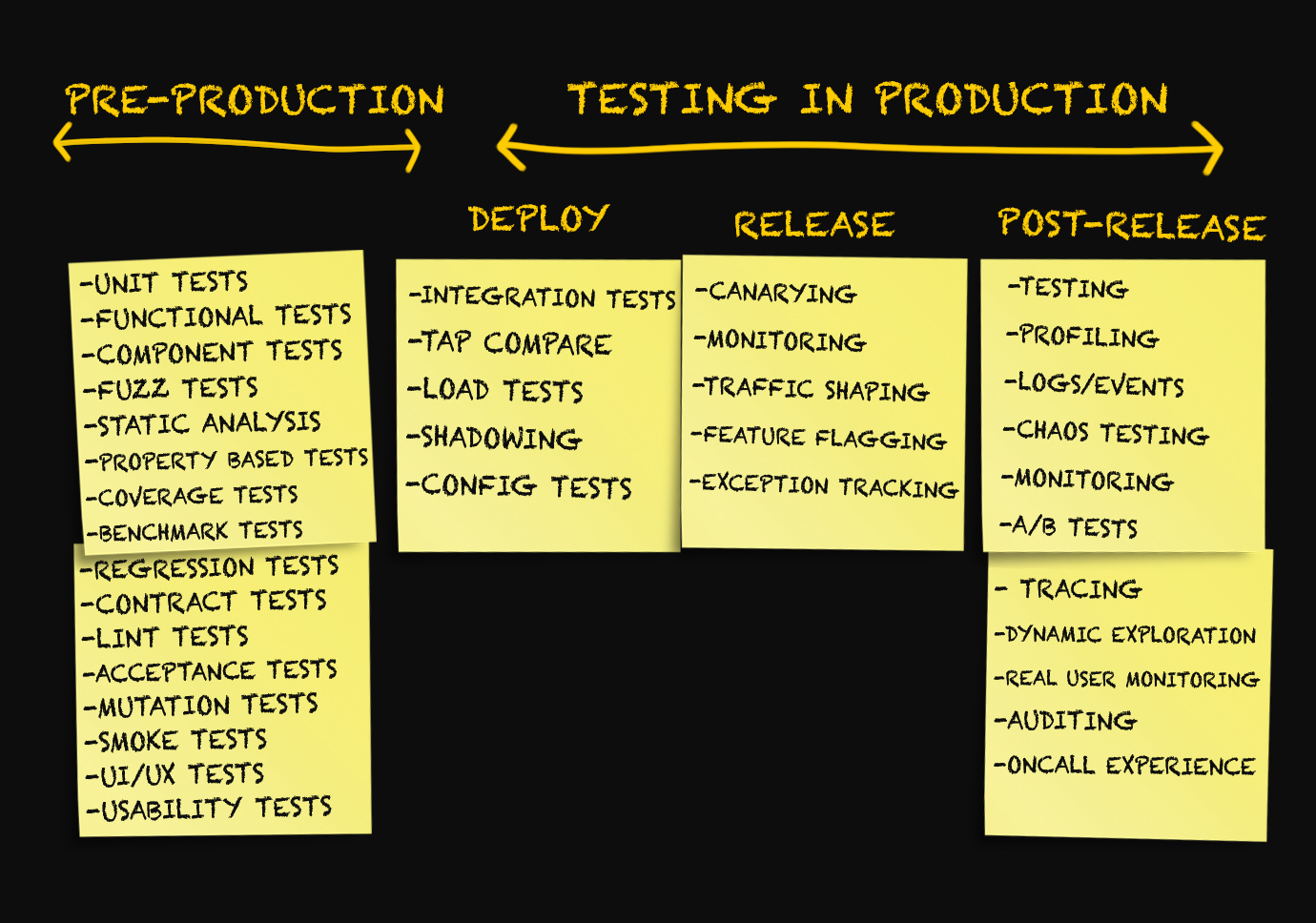
The concept of "testing in production" includes a whole range of techniques used in three different stages . What exactly - let's understand.
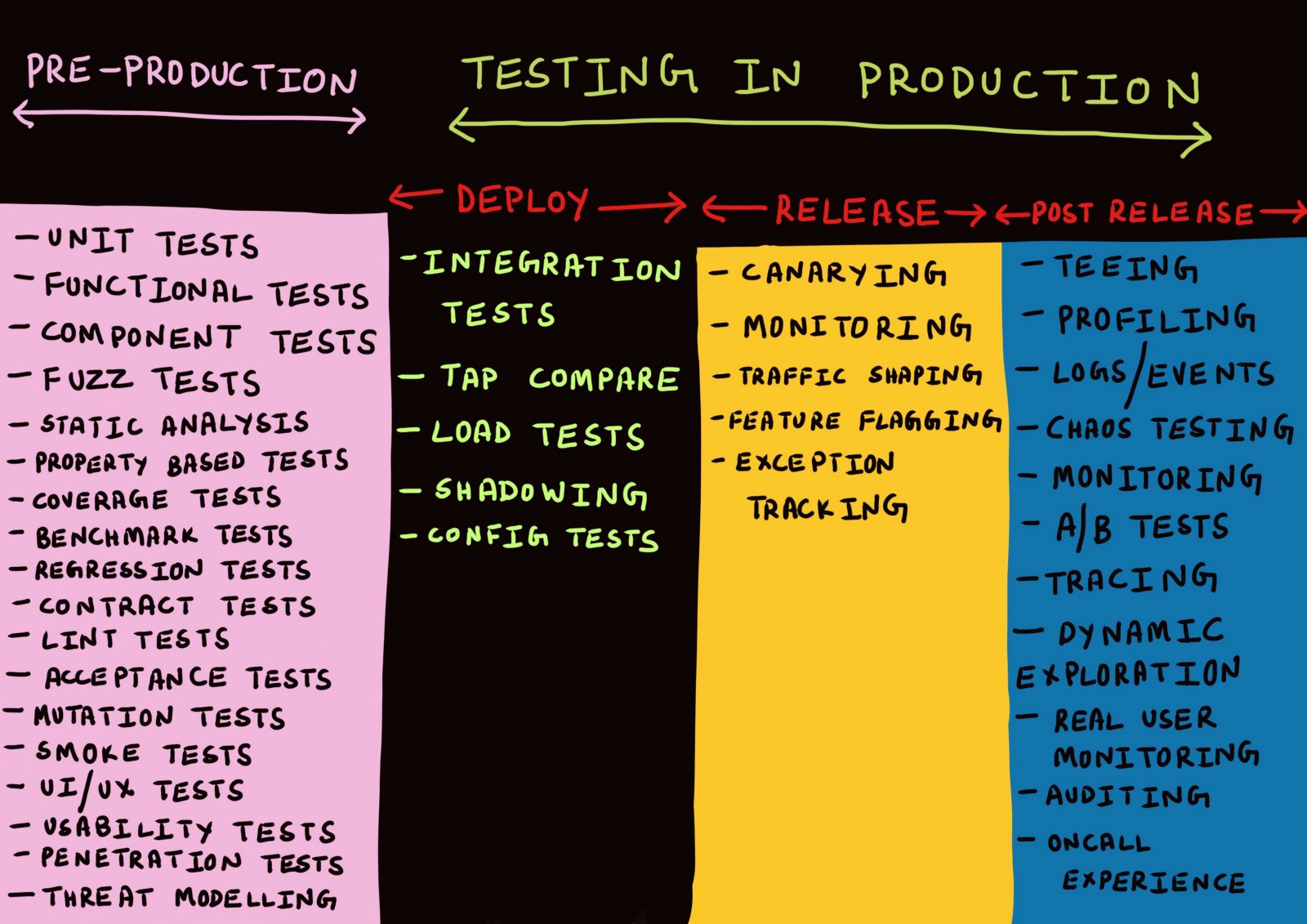
Three stages of production
Usually, discussions about production are conducted only in the context of deploying code to production, monitoring, or emergency situations, when something has gone wrong.
I myself have so far used as synonyms terms such as "deployment", "release", "delivery", etc., thinking little about their meaning. A few months ago, all attempts to distinguish between these terms would be rejected by me as something unimportant.
After thinking about it, I came up with the idea that there is a real need to distinguish between the various stages of production.
Stage 1. Deployment
When testing (even in production) is a test to achieve the best possible performance , the accuracy of testing (and indeed any checks) is ensured only if the method of performing the tests is as close as possible to the actual use of the service in production.
In other words, tests must be performed in an environment that best imitates the working environment .
And the best imitation of the work environment is ... the work environment itself. To perform as many tests as possible in a production environment, it is necessary that the failure of any one of them does not affect the end user.
This, in turn, is possible only ifwhen deploying a service in a work environment, users do not directly access this service .
In this article, I decided to use the terminology from the article Deploy! = Release (“Deployment - not release”), written by Turbine Labs . In it, the term “deployment” gives the following definition:
“Deployment is the installation by the working group of a new version of the service code in the production infrastructure. When we say that a new version of software is deployed, we mean that it runs somewhere within the framework of the working infrastructure. This may be a new EC2 instance in AWS or a Docker container running in a pod in the Kubernetes cluster. The service started successfully, passed the performance check and is ready (you hope!) To process the production environment, but it may not receive any data in reality. This is an important point, I will emphasize it once again: for deployment, it is not necessary that users get access to a new version of your service . Given this definition, deployment can be called a process with an almost zero risk. ”
The words “zero-risk process” are simply a balm for the soul of many people who have suffered from unsuccessful deployments. Ability to install software in a real environmentwithout user access to it has several advantages when it comes to testing.
Firstly, the need to maintain separate environments for development, testing and staging, which inevitably have to be synchronized with production, is minimized (and may disappear altogether).
In addition, at the design stage of services, it becomes necessary to isolate them from each other in such a way that the unsuccessful testing of a specific service instance in production does not lead to cascading or affecting users to failures of other services. One of the solutions to ensure this may be the design of the data model and database schema, in which nonidempotent queries (mainly write operations ) can:
- Run on the production environment database for any test service launch in production (I prefer this approach);
- Be safely rejected at the application level until they reach the write or save level;
- Be selected or isolated at the record or save level in some way (for example, by saving additional metadata).
Stage 2. Release
In the Deploy! = Release note, the term “release” is defined as follows:
“When we say that a service version has been released , we mean that it provides data processing in a production environment. In other words, release is a process that directs production data to a new version of software. Given this definition, all the risks that we associate with sending new data streams (disruptions, customer dissatisfaction, poisonous notes in The Register ) relate to the release of new software, rather than its deployment (in some companies this stage is also called release . In this article, we will use the term release ) ".
In Google’s SRE book, the term “release” is used in the chapter on software release organization to describe it .
“A release is a logical piece of work consisting of one or more separate tasks. Our goal is to align the deployment process with the risk profile of this service .
In development or pre-production environments, we can build every hour and automatically distribute releases after passing all the tests. For large user-oriented services, we can start the release from a single cluster and then scale it up until we upgrade all the clusters. For important elements of the infrastructure, we can extend the implementation period by several days and carry it out in turn in different geographic regions. ”
In this terminology, the words “release” and “release” refer to what is generally understood as “deployment”, and terms often used to describe various deployment strategies (for example, blue-green deployment or canary deployment) refer to the release of a new software.
Moreover, an unsuccessful release of applications can cause partial or significant interruptions. At this stage, rollback or hotfix is also performed , if it turns out that the released new version of the service is unstable.
The release process works best when it is automated and running.incrementally . Similarly, a rollback or hotfix service provides more benefit when the frequency of occurrence of errors and the frequency of requests are automatically correlated with the baseline.
Stage 3. After release
If the release went smoothly and the new version of the service processes the production environment data without obvious problems, we can consider it successful. A successful release is followed by a stage that can be called “post-release”.
Any rather complex system will always be in a state of gradual loss of productivity. This does not mean that a rollback or hotfix is necessarily required . Instead, it is necessary to monitor such deterioration (for various operating and work purposes) and, if necessary, to debug. For this reason, testing after the release is more like not the usual procedures, but debugging or analytical data collection.
In general, I believe that every component of the system should be created taking into account the fact that not a single large system works 100% flawlessly and that failures must be recognized and taken into account during the design, development, testing, deployment and monitoring stages security.
Now that we have defined the three stages of production, let's look at the different testing mechanisms available in each of them. Not everyone has the opportunity to work on new projects or rewrite code from scratch. In this article, I tried to clearly identify the techniques that would best show themselves in the development of new projects, and also tell about what else we can do to take advantage of the proposed techniques, without making significant changes to existing projects.
Testing in production at the deployment stage
We have separated the deployment and release stages from each other, and now we will consider some types of testing that can be applied after the code is deployed in a production environment.
Integration testing
Typically, integration testing is performed by the continuous integration server in an isolated test environment for each branch of Git. A copy of the entire service topology (including databases, queues, proxy servers, etc.) is deployed for test suites of all services that will work together.
I believe that it is not particularly effective for several reasons. First of all, the test environment, like staging, cannot be deployed so that it is identical to the real production environment, even if the tests are run in the same Docker container that will be used in production. This is especially true when the only thing that runs in a test environment is the tests themselves.
Regardless of whether the test runs as a Docker container or a POSIX process, it most likely makes one or more connections to an upstream service, database, or cache, which is rare if the service is in a production environment where it can process multiple concurrent connections, often reusing inactive TCP connections (this is called HTTP connection reuse).
Also, the problems are caused by the fact that most tests create a new database table or cache key space on the same node every timewhere this test is performed (thus tests are isolated from network failures). At best, this type of testing can show that the system works correctly with a very specific request. It is rarely effective at imitating serious, well-established types of failures, not to mention the various types of partial failures. Exhaustive studies exist that confirm that distributed systems often exhibit unpredictable behavior that cannot be foreseen using analysis performed differently than for the entire system.
But this does not mean that integration testing is basically useless. We can only say that the implementation of integration tests inartificial, completely isolated environment , as a rule, does not make sense. Integration testing should still be performed to verify that the new version of the service:
- Does not break interaction with higher or lower services;
- Does not have a negative impact on the goals and objectives of the higher or lower services.
The first can be provided to some extent with the help of contract testing. Thanks only to ensuring the correct operation of interfaces between services, contract testing is an effective method of developing and testing individual services at the pre-production stage , which does not require the deployment of the entire service topology.
Client-oriented contract testing platforms, such as Pact , currently support interaction between services only through RESTful JSON RPC, although, most likely, work is also under way to support asynchronous communication through web sockets, off-server applications and message queues. In the future, support for the gRPC and GraphQL protocols will probably be added, but now it is not yet available.
However, before the release of the new version, it may be necessary to check not only the correct operation of the interfaces . And, for example, make sure that the duration of an RPC call between two services is within the allowable limit when the interface between them changes. It is also necessary to check that the cache hit ratio remains constant, for example, when adding an additional parameter to an incoming request.
As it turned out, integration testing is not optional , its goal is to ensure that the tested change does not lead to serious, widespreadtypes of system failure (usually those for which alerts are assigned).
In this regard, the question arises: how to safely conduct integration testing in production?
To do this, consider the following example. The figure below shows the architecture I worked with a couple of years ago: our mobile and web clients connected to a web server (service C) based on MySQL (service D) with a client part in the form of a memcache cluster (service B).
Despite the fact that this is a rather traditional architecture (and you will not call it microservice), the combination of stateful and stateless services makes this system a good example for my article.
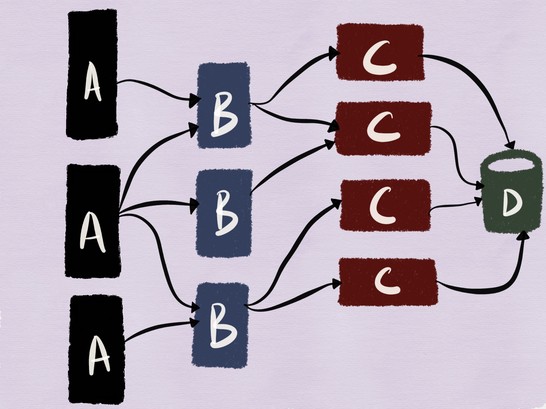
Separating the release from deployment means that we can safely deploy a new instance of the service in a production environment.
Modern service discovery utilities allow services with the same name to receive tags (or tags), with which you can distinguish the released and deployed version of the service with the same name. Thanks to this feature, customers can only connect to the released version of the desired service.
Suppose we are deploying a new version of service C in production.
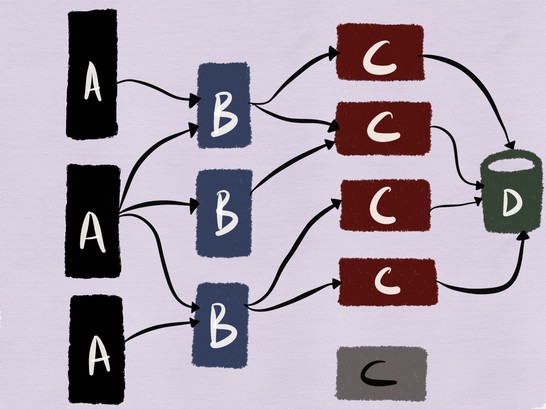
To verify that the deployed version is working correctly, we must be able to run it and make sure that none of the contracts is violated. The main advantage of loosely coupled services is that they allow working groups to develop, deploy and scale independently. In addition, it is possible to independently perform testing , which paradoxically applies to integration testing.
Google’s blog has an article called “ Just Say No to More End-to-End Tests ”, where integration tests are described as follows:
“During the integration test, a small set of modules (usually two) is tested for consistency in their work. If the two modules do not integrate properly, why write a pass-through test? You can write a much smaller in volume and more narrowly integrated integration test, which can reveal the same errors . Although in general it is necessary to think more broadly, there is no need to pursue the scale when it comes only to checking the joint work of the modules. ”
It is further stated that integration testing in production should follow the same philosophy: it should be sufficient and obviously useful.Only for comprehensive verification of small groups of modules. With proper design, all upstream dependencies should be sufficiently isolated from the service being tested so that a poorly formed request from service A would not lead to a cascade failure in the architecture.
For our example, this means that testing of the deployed version of the C service and its interaction with MySQL should be performed , as shown in the figure below.
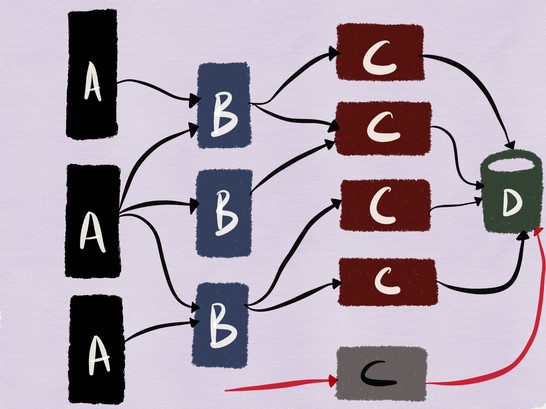
Testing read operations in most cases should be straightforward (unless the stream of data read by the service being tested does not fill the cache with its subsequent “poisoning” with the data used by the released services). In this case, testing the interaction of deployed code with MySQL becomes more complex if nonidempotent queries are used, which can lead to changes in data.
My choice is to perform integration testing using a production environment database. Previously, I kept a white list of clients who were allowed to send requests to the service being tested. Some workgroups support a special set of user accounts to perform tests in the production system so that any accompanying data change is limited to a small, experienced series.
But if it is absolutely necessary that the production environment data under no circumstances be changed during the execution of the test, then the write / change operations:
- You must reject requests at the C application level or write to another table / collection in the database;
- It is necessary to register in the database as a new record marked as “created” during the test.
If in the second case it is necessary to select test write operations at the database level, then to support this type of testing, the database schema should be designed in advance (for example, adding an additional field).
In the first case, the rejection of write operations at the application level can occur if the application is able to determine that the request should not be processed. This is possible either by checking the IP address of the client sending the test request, or by the user ID contained in the incoming request, or by checking the request for a header that is expected to be specified by the client working in test mode.
What I propose is similar to mock or stub, but at the level of service, and this is not too far from the truth. This approach is accompanied by a fair number of problems. Kraken’s Facebook brochure says:
“ An alternative design solution is to use the shadow data stream when an incoming request is recorded and played in a test environment. In the case of a web server, most of the operations have side effects that extend deep into the system. Shadow tests should not activate these side effects, as this may entail changes for the user.The use of stubs for side effects in shadow testing is not only impractical due to frequent changes in the logic of the server, but also reduces the accuracy of the test, since dependencies that would otherwise be affected are not loaded. ”
Although new projects can be designed so that side effects are minimized, prevented, or even completely eliminated, the use of stubs in a ready-made infrastructure can bring more problems than benefits.
The mesh architecture of the service can in some way help with this. When using the service mesh architecture, services know nothing about the network topology and wait for connections on the local node. All interaction between services is carried out through an additional proxy server. If each transition between nodes is carried out through a proxy server, then the architecture described above will look like this:
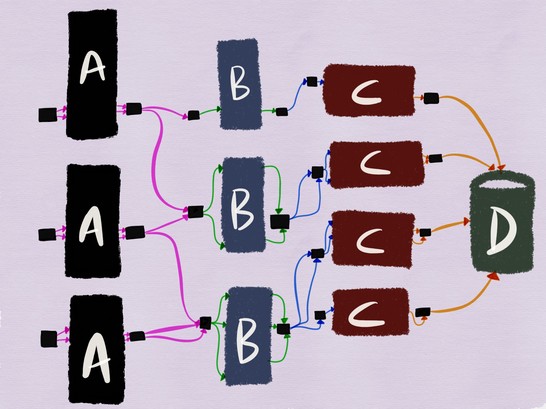
If we test service B, its outgoing proxy server can be configured to add a special header
X-ServiceB-Testto each test request. At the same time, the incoming proxy server of the upstream service C can:- Detect this header and send a standard response to service B;
- Report service C that the request is a test .
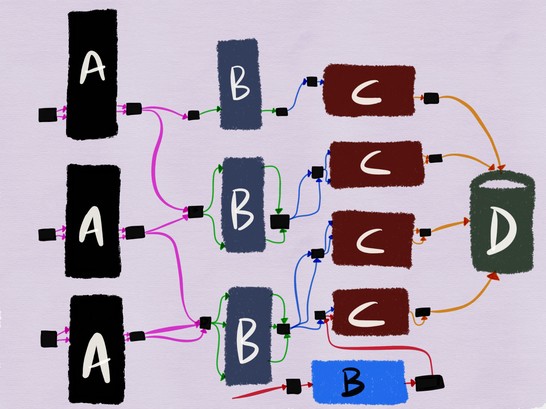
Integration testing of the interaction of the deployed version of service B with the released version of service C, where write operations never reach the database
Performing integration testing in this way also provides testing of the interaction of service B with higher-level services when they process normal production-environment data — probably more close imitation of how Service B will behave when released in production.
It would also be nice if each service in this architecture supported real API calls in test or layout mode, allowing you to test the execution of service contracts with downstream services without changing the actual data. This would be equivalent to contract testing, but at the network level.
Shadow data duplication (dark data flow testing or mirroring)
Shadow duplication (in an article from a Google blog, it is called a dark launch , and Istio uses the term mirroring ) in many cases has more advantages than integration testing.
The Principles of Chaos Design ( Principles of Chaos Engineering ) states the following:
“ Systems behave differently depending on the environment and the data transfer scheme. Since the usage mode can change at any time , sampling real data is the only reliable way to fix the query path. ”
Shadow data duplication is a method by which the data stream of the production environment that enters this service is captured and reproduced in the new deployed version of the service. This process can be performed either in real time, when the incoming data stream is divided and sent to both the released and the deployed version of the service, or asynchronously, when a copy of the previously captured data is played in the deployed service.
When I worked in imgix(a startup with a staff of 7 engineers, of whom only four were system engineers), dark data streams were actively used to test changes in our imaging infrastructure. We recorded a certain percentage of all incoming requests and sent them to the Kafka cluster — we transferred the HAProxy access logs to the heka pipeline , which in turn passed the analyzed request flow to the Kafka cluster. Before the release stage , a new version of our image processing application was tested on a captured dark data stream - this made sure that requests are being processed correctly. However, our imaging system was, by and large, a stateless service that was particularly well suited for this type of testing.
Some companies prefer not to capture a part of the data stream, but to transfer a new version of the application a full copy of this stream. Facebook's McRouter router (memcached proxy server) supports this kind of shadow duplication of the memcache data stream.
“ During testing of a new installation for the cache, we found it very convenient to be able to redirect a complete copy of the data stream from clients. McRouter supports flexible shadow shadowing. You can perform shadow duplication of a pool of various sizes (by re-caching the key space), copy only a part of the key space, or dynamically change the parameters in the process . ”
The negative aspect of shadow duplication of the entire data stream for a deployed service in a production environment is that if it is running at the time of maximum data transfer rate, then it may need twice as much power.
Proxy servers such as Envoy support shadow duplication of data flow to another cluster in fire-and-forget mode. His documentation says:
"The router can perform shadow data duplication from one cluster to another. Fire-and-forget mode is currently implemented, in which the Envoy proxy does not wait for a response from the shadow cluster before returning a response from the main cluster. For the shadow cluster, all the usual statistics are collected, which is useful for testing purposes. With shadow duplication, a parameter is added to the host / authority header
-shadow. This is useful for logging. For example, it cluster1turns intocluster1-shadow ". However, it is often impractical or impossible to create a cluster replica synchronized with production for testing (for the same reason that it is problematic to organize synchronized aging cluster). If shadow duplication is used to test the newdeployed service that has many dependencies, it can initiate unintended changes in the status of the parent services in relation to the test. Shadow duplication of the daily volume of user registrations in the deployed version of the service with a record in the production database can lead to an increase in error rate up to 100% due to the fact that the shadow data stream will be perceived as repeated registration attempts and be rejected.
My personal experience suggests that shadow duplication is best suited for testing nonidempotent queries or stateless services with server-side stubs. In this case, shadow data duplication is more commonly used to test load, resilience, and configurations. In this case, using integration testing or styling, you can test how a service interacts with a stateful server when working with non-idempotent queries.
Tap comparison
The only mention of this term is in an article from the Twitter blog dedicated to the launch of services with a high level of service quality.
“To check the correctness of the new implementation of the existing system, we used a method called tap-comparison . Our tap-comparison tool reproduces sample production data in the new system and compares the received answers with the results of the old one. The results obtained helped us find and correct errors in the system before the end users encountered them. ”
Another article from the Twitter blog gives the following definition of a tap comparison:
“Sending requests to service instances in both production and aging environments with validation of resultsand performance evaluation. ”
The difference between tap-comparison and shadow duplication is that in the first case the answer returned by the released version is compared with the answer returned by the deployed version, and in the second case, the request is duplicated into the deployed version in autonomous mode, like fire-and-forget.
Another tool for working in this area is the scientist library , available on GitHub. This tool was developed to test Ruby code, but was then ported to several other languages.. It is useful for some types of testing, but has a number of unsolved problems. Here is what the developer wrote with GitHub in one professional Slack community:
“This tool simply performs two branches of code and compares the results. Be careful with the code for these branches. Care should be taken not to duplicate database queries if this leads to problems. I think that this applies not only to a scientist, but also to any situation in which you do something twice, and then compare the results. The scientist tool was created to verify that the new permissions system works the same way as the old one, and at certain times was used to compare data that is characteristic of virtually every Rails request. I think that the process will take more time, since the processing is performed sequentially, but this is a Ruby problem that does not use threads.
In most cases I’ve known, the scientist tool was used to work with read operations rather than write, for example, to find out whether new improved requests and permissions schemes receive the same answer as the old ones. Both options are performed in a production environment (on replicas). If the tested resources have side effects, I suppose the testing will have to be done at the application level. ”
Diffy is an open source tool written in Scala that Twitter introduced in 2015. An article from a Twitter blog called Testing without Writing Tests is probably the best resource for understanding how a tap comparison works in practice.
“Diffy detects potential errors in the service, simultaneously launching a new and old version of the code. This tool works as a proxy server and sends all received requests to each of the running instances. It then compares the responses of the instances and reports all deviations detected during the comparison. Diffy is based on the following idea: if two service implementations return the same answers with a sufficiently large and diverse set of requests, then these two implementations can be considered equivalent, and the newer one - without any impairments in performance. Diffy’s innovative interference mitigation technique sets it apart from other comparative regression analysis tools. ”
Tap-comparison is great when you need to check whether the two versions give the same results. According to Mark McBride ( Mark McBride ),
“the Diffy tool was often used when redesigning systems. In our case, we divided the Rails source code base into several services created using Scala, and a large number of API clients did not use the functions as we expected. Functions like date formatting were especially dangerous. ”
Tap-comparison is not the best option for testing user activity or identity of the behavior of two versions of the service at maximum load. As with shadow duplication, side effects remain an unsolved problem, especially when both the deployed version and the production version write data to the same database. As in the case of integration testing, one of the ways to get around this problem is to use tap comparisons with only a limited set of accounts.
Stress Testing
For those not familiar with load testing, this article can serve as a good starting point. There is no shortage of tools and open source load testing platforms. The most popular of them are Apache Bench , Gatling , wrk2 , Tsung , written in Erlang, Siege , Iago from Twitter, written in Scala (which reproduces the HTTP server, proxy server or network packet sniffer logs in a test instance). Some experts believe that the best tool for generating load - mzbenchwhich supports a variety of protocols, including MySQL, Postgres, Cassandra, MongoDB, TCP, etc. Netflix NDBench is another open source tool for load testing data warehouses that supports most of the known protocols.
The official Twitter blog dedicated to Iago describes in more detail what characteristics a good load generator should have:
“Non-blocking requests are generated with a specified frequency based on an internal custom statistical distribution ( the Poisson process is modeled by default ). The request rate can be changed as needed, for example, to prepare the cache before working at full load.
In general, the focus is on the frequency of requests in accordance with Little's law , rather than the number of concurrent users, which can vary depending on the amount of delay inherent in this service. Due to this, new opportunities appear to compare the results of several tests and prevent deterioration in the service, slowing down the work of the load generator.
In other words, the Iago tool seeks to simulate a system in which requests arrive regardless of the ability of your service to process them. This is different from the load generators that simulate closed systems in which users will patiently work with the existing delay. This difference allows us to quite accurately simulate the failure modes that can be encountered in production. ”
Another type of load testing is stress testing by redistributing the data stream. Its essence is as follows: the entire data stream of the production environment is sent to a smaller cluster than the one prepared for the service; if this causes problems, the data stream is transferred back to the larger cluster. This technique is used by Facebook, as described in one of its official blog articles :
“We specifically redirect a larger data stream to individual clusters or nodes, measure resource consumption at these nodes, and determine the limits of service sustainability. This type of testing is particularly useful for determining the CPU resources needed to support the maximum number of simultaneous Facebook Live broadcasts. ”
Here is what the former LinkedIn engineer writes in the professional Slack community:
“LinkedIn also used redline tests in production — servers were removed from the load balancer until the load reached thresholds or errors started to occur.”
Indeed, Google search provides a link to a full technical document and an article on the LinkedIn blog on this topic:
“The Redliner solution for measurements uses a real stream of production data from the environment, thus avoiding errors that prevent accurate measurement of performance in the laboratory.
Redliner redirects part of the data stream to the service being tested and analyzes its performance in real time. This solution was implemented in hundreds of LinkedIn internal services and is used daily for various types of performance analysis.
Redliner supports parallel test execution for canary and working instances. This allows engineers to transfer the same amount of data to two different instances of the service: 1) a service instance that contains innovations, such as new configurations, properties, or new code; 2) an instance of the service of the current working version.
The results of load testing are taken into account when making decisions and prevent the code from being deployed, which can lead to poor performance. ”
Facebook brought load testing using real-world data streams to a whole new level thanks to the Kraken system, and its description is also worth reading.
Testing is implemented by redistributing the data flow when the weights change (read from the distributed configuration storage) for the edge devices and clusters in the Proxygen configuration (Facebook load balancer). These values determine the volumes of real data sent respectively to each cluster and region at a given point of presence.

Data from the Kraken technical document
The monitoring system ( Gorilla ) displays the performance of various services (as shown in the table above). Based on the monitoring data and threshold values, it is decided whether to further send data in accordance with the weights, or whether it is necessary to reduce or even completely stop the transfer of data to a specific cluster.
Configuration Tests
The new wave of open source infrastructure tools has made fixing all changes in the infrastructure in the form of code not only possible, but also relatively easy . It has also become possible to test these changes to varying degrees , although most infrastructure-as-code tests at the pre-production stage can only confirm the correctness of the specifications and syntax.
At the same time, the refusal to test the new configuration before the release of the code caused a significant number of interruptions .
For complete testing of configuration changes, it is important to distinguish between different types of configurations. Fred Hebert ( of Fred Hebert ) once proposed to use the following quadrant:

This option, of course, is not universal, but this distinction makes it possible to decide how best to test each of the configurations and at what stage to do it. The build time configuration makes sense if you can ensure real repeatability of the builds. Not all configurations are static, and on modern platforms a dynamic configuration change is inevitable (even if we are dealing with a “permanent infrastructure”).
By testing configuration changes using methods such as integration testing, shadow duplication of peak data flow, and blue-green deployment, you can significantly reduce the risks associated with deploying new configurations. Jamie Wilkinson ( by Jamie Wilkinson ), the Google engineer grade, writes :
"By updating the configuration needs to be treated with no less attention than the code, mainly because the unit test configuration is difficult to carry out without the compiler. It is necessary to carry out integration tests.It is necessary to perform canarying and styling deployments of configuration changes, because the only suitable place to test them is the production stage, when real users initiate the execution of code branches activated by your configuration. A global synchronized configuration change is equivalent to a failure.
For this reason, functions should be deployed in a disconnected form and gradually release configurations that include them. The configuration must be packaged in the same way as binary files - in a compact sealed shell. "
A two-year-old Facebook article provides useful information about risk management when deploying configuration changes:
“Configuration systems are designed to quickly replicate changes globally. Quick configuration change is a powerful tool by which engineers can quickly manage the launch of new products and adjust their settings. However, a quick configuration change also means a quick failure in case of deployment with errors. A number of practical techniques help to prevent errors and failures that may be caused by a configuration change.
- Using a common configuration system
When using a common configuration system, procedures and tools apply to all types of configuration. Facebook staff found that in some cases, experts prefer to handle different configurations separately. The desire to avoid such temptation and implement a unified configuration management led to the creation of a system that helped to increase the reliability of the site. - Static check of configuration changes
Many configuration systems support configurations with weak typing (for example, JSON structures). In these cases, the developer can easily make a typo in the field name, apply a string data type instead of an integer, or make another simple mistake. To find errors of this type, it is best to use static validation.
A structured format (for example, Thrift is used on Facebook) provides basic capabilities for its implementation. However, it makes sense to write additional programs for validating more detailed requirements. - Canary Deployment
It is recommended to first deploy the configuration in isolation on a small part of the service in order to prevent the ubiquitous distribution of errors that may occur due to changes. Canary deployment can be implemented in several ways. The most obvious is A / B testing, such as launching a new configuration for only 1% of users. You can simultaneously conduct multiple A / B tests, as well as use dynamic data to track indicators. However, in terms of improving reliability, A / B tests do not solve all problems. Obviously, a change deployed for a small number of users and caused a failure on the servers involved or occupying their entire memory does not only affect those users who directly participate in the test. In addition, A / B tests take too much time. Engineers often want to apply minor changes without resorting to A / B tests. For this reason, the Facebook infrastructure automatically tests new configurations on a small set of servers.
For example, if you want to deploy a new A / B test for 1% of users, then this 1% of users will be chosen so that as few servers as possible can be used to service them (this technique is called “fixed canary deployment”). We monitor these servers for a short period of time to ensure there are no failures or other obvious problems. This mechanism allows you to perform a basic health check for all changes and ensure that they do not cause a global failure. - Saving the correct configurations
The Facebook configuration system is focused on saving the correct configurations in the event of a failure in the process of updating them. Developers typically tend to create configuration systems that stop working when they receive invalid updated configurations. We prefer systems that, in a similar situation, keep the previous efficient version and notify the system operator that the configuration could not be updated. Using an outdated configuration is usually more preferable compared to displaying an error message to users. - Simple and convenient cancellation of changes
In some cases, despite all the preventive measures, an unworkable configuration is deployed. Quickly finding and reversing changes is critical to solving a similar problem. In our configuration system, version control tools are available that make it much easier to undo changes. ”
To be continued!
UPD: continued here .