Accidents "do not watch the clock": a statistical justification for the mode of technical support 24/7
- Transfer

According to the results of numerous operational assessments of data centers around the world, the Uptime Institute noted that the staffing level in data centers varies greatly from place to place. This observation is somewhat puzzling, but this is not surprising. While staffing is an important aspect of data center operations that try to maintain operational excellence, many other factors influence the organization’s decision on the required level of staffing.
Among the factors that can affect the overall staffing level, we can highlight the complexity of the data processing center, staff turnover, the number of hours of technical support work required, the number of contracts with contractors, and the business goal of ensuring accessibility. The costs are also worrying, since each employee is a direct cost to the data center. Because of these many factors, the level of data center staffing needs to be constantly reviewed to ensure effective support at a reasonable price.
Uptime Institute often get the question: "What is the proper level of staffing for my data center?". Unfortunately, there is no concise answer that would be universal for each data center. Proper staffing depends on a number of variables.
The time required to complete maintenance tasks, and ensuring that the technical support shifts are complete, are two main variables. Staffing to meet maintenance requirements is a relatively fixed factor, but depends on what actions are performed by data center personnel and which functions are assigned to contractors. Maintenance shifts are defined as staffing for monitoring the data center and for responding to any incidents and events. The recruitment of personnel for technical support can be determined in various ways. Each way of staffing has a potential impact on operations, depending on which processes are covered by technical support.
Shifts trends
The main purpose of permanently finding qualified personnel in the field is to minimize the risk of failures caused by abnormal events by preventing incident, deterring or isolating it, and preventing its spread or affecting other systems. Many data centers still maintain the constant presence of a team of qualified electricians, mechanical engineers and other technicians who provide 24x7 operation. However, remote monitoring technologies, a particular arrangement of buildings in the form of a complex, a desire to balance costs, and other reasons may encourage organizations to staff personnel in different ways.
Managing the mode of providing technical support without the availability of qualified personnel at the site at any time may increase the risks due to the delayed response to abnormal incidents. Ultimately, the company must come to a solution with an acceptable level of risk.
Other full-coverage technical support delivery models include:
- Training security personnel to respond to alarms and perform procedures to solve problems;
- Monitoring the data center through a local or regional building condition monitoring system (BMS) and engaging on-call technicians;
- Availability of staff on site during normal business hours and on call at night and on weekends;
- The work of several data centers in the form of a special complex of buildings, whose team provides support for several data centers without having to be in place in each individual data center at any given time.
These and other methods should be evaluated in terms of effectiveness individually. In order to assess the model of technical support, the data center must determine the potential risks of incidents in the data center and their potential impact on the business.
Over the past 20 years, the Uptime Institute has collected an abnormal incident database (Abnormal Incident Reports, AIRs) using information from members of the Uptime Institute Network. The Uptime Institute analyzes data annually and presents its results to members of the Network. The AIRs database contains interesting information regarding personnel problems and effective data center staffing models.
Incidents occur outside working hours
In 2013, a small majority of incidents (out of 277 cases) occurred during business hours. However, 44% of incidents occurred between midnight and 8:00 am, which underscores the potential need for 24x7 technical support (see Figure 1).

Figure 1. Approximately half of the anomalous incidents that occurred in 2013 took place between 8 am and noon, the other half from midnight to 8 am.
Incidents can occur at any time of the year. Focusing staff activity for a certain time of year in priority over others would not be productive (for example, a ban on vacation). The occurrence of incidents is fairly evenly distributed throughout the year.
Figure 2 shows the distribution of incidents by day of the week. The diagram shows that each day of the week has an almost equal share, which means that the staffing level should be the same for each day of the week. This is an important conclusion, because some data centers have concentrated their technical support manpower for the period from Monday to Friday and leave the weekend for remote monitoring (see Figure 2).
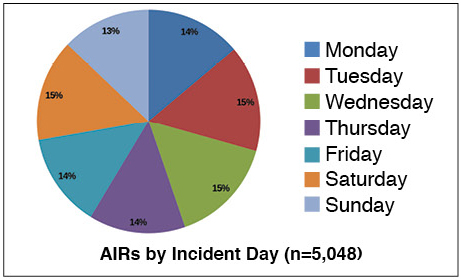
Figure 2. Data center personnel must be ready every day of the week.
Incidents by industry
Figure 3 further illustrates industry incidents and does not show a significant difference in trends between industries. The chart shows that the financial services industry reported a much larger number of incidents than in other industries, but this rather reflects the composition of the sample.

Figure 3. Incidents in data centers take place all year round.
Causes of failure and methods of detection
Knowing when incidents occur, there is little that can be said about which personnel should be in place. Understanding which incidents occur most often will help shape the composition of the shift, as well as learn how incidents occur most often. Figure 4 shows that most of the incidents affect electrical systems, followed by mechanical systems. In contrast, a critical IT load causes a relatively small number of incidents.
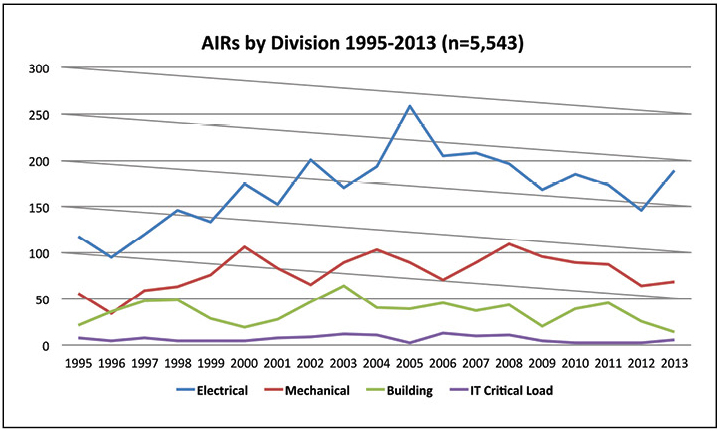
Figure 4. More than half of the abnormal incidents reported in 2013 are related to the electrical system.
As a result, it makes sense that teams from all shifts have enough experience to respond to the most common incidents in electrical systems. The support team should also respond to other types of incidents. Cross-training of electrical engineers in mechanical and building systems can provide adequate coverage, and on-call attendants can cover relatively rare IT incidents.
The AIRs database also sheds light on how incidents are detected. Figure 5 shows that more than half of the primary information about all incidents detected in 2013 were obtained from alarm systems, and more than 40% of incidents are detected by technical experts on the spot, which totals about 95% of cases. The biggest change over the years, shown in the diagram, is the slow growth of incidents detected by an alarm.
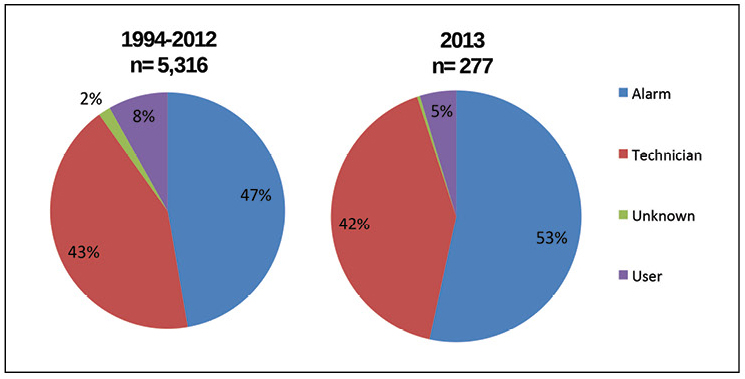
Figure 5. Alarms are now a way to detect most incidents; however, accessibility problems are more often detected by technicians.
However, alarms cannot respond to incidents or mitigate consequences. The Uptime Institute has witnessed a number of methods that allow data centers to avoid disruptions and reduce their impact. These methods require personnel to respond to the incident, create redundancy in critical systems, and effective predictive maintenance programs to predict potential failures before they occur. Figure 6 shows how often each of these methods “saves” data centers.

Figure 6. Equipment redundancy in 2013 contributed to the number of “rescue” more than in previous years.
The diagram also shows that in recent years, equipment redundancy and preventive maintenance become more efficient and save data centers more money. There are several possible explanations for this, including increased system reliability, increased use of proactive services and budget cuts, which lead to a reduction in the number of personnel or moving it beyond the data center.
Failures in the context of the main cause
The data shows that all accessibility problems in 2013 were caused by electrical system incidents. Most failures occurred because the maintenance procedures were not performed properly. This finding emphasizes the importance of having proper procedures and well-trained staff.
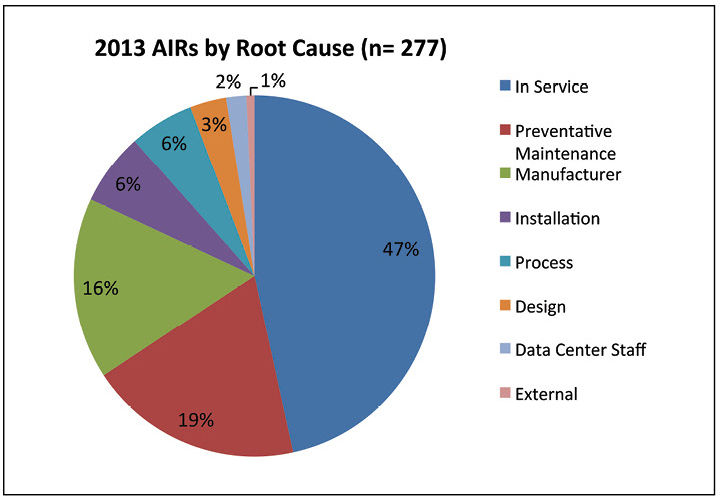
Figure 7. Almost half of the failures reported in 2013 were due to maintenance problems.
In fig. 7 further discusses the causes of incidents in 2013. Approximately half of the incidents were described as “In Service”, which is defined as inadequate maintenance, improper equipment setup, failure to work, or lack of a specific root cause. Cases of “preventive maintenance” are actually related to preventive maintenance that was improperly performed. Data center personnel caused only 2% of incidents, showing that the interaction of personnel and equipment is not the main cause of incidents and failures.
Conclusion
The increasing complexity of managing data center infrastructure (DCIM), building management systems (BMS) and building automation systems (BAS) makes it difficult to find an answer to the question of whether it is possible to reduce the number of personnel in data processing centers. Advances in the improvement of these systems are significant. They can improve the performance of your data center; however, data shows that on-site personnel are often required to prevent incidents. That is why it is still a full-time equivalent of full-time (FTE) staffed with qualified staff that is a directive for certified Tier III and Tier IV data centers.
The main objective is to provide a quick response time to mitigate the effects of any incidents and events. The data show that there are no temporary patterns when incidents occur. Their appearance is fairly well distributed over all 24 hours and all 7 days of the week.
The primary concern is risk prevention. Data centers continue to evolve, leveraging control through remote access and increasing hardware redundancy. Each data center is unique and has its own set of inherent risks. Technical support mode is just one factor, but quite important. Deciding how much staff to use on each shift and with what qualifications can have a major impact on risk prevention and data center availability. Make a smart choice.
Other Cloud4Y blog articles:
→ What is the true cost of IT infrastructure downtime for small and medium enterprises? (external link)
→ The rise of cloud computing in the automation of industrial enterprises (external link)
→ What happens with the prices of cloud computing in recent years (Habr)
→ How to create samples for the Unified biometric system and why it can be dangerous (Habr)