Who uses Node.js: Trello (Part 1)
Quite often I come across questions like: “And who of the large / well-known / notable IT companies generally uses Node.js in production?” On January 19, 2012, the blog of Fog Creek, founded by the notorious Joel Spolsky , published the article “The Trello Tech Stack” . It is strange that on Habr it somehow ignored. Therefore, in order to correct this shortcoming, and at the same time to show an example of using Node.js in a large project, I translated this article.
The article itself is quite voluminous, therefore it is divided into two parts:
Part 1
Part 2
Trello's development began with an HTML layout that Justin and Bobby , the Trello team designers, had assembled in a week. I was struck by how cool he looked and felt. After Daniel and I joined the project to develop the prototype and working version of Trello, the real challenge was to keep the amazing impressions of the original layout while creating the server and client.
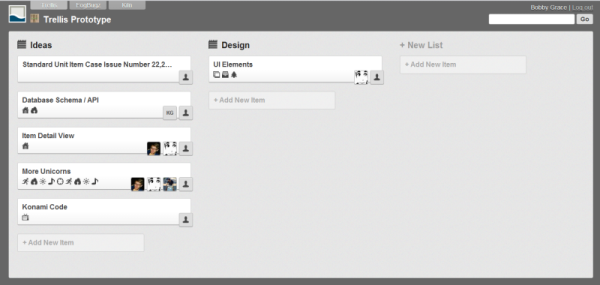
The original layout of Trello.
The layout led us to a one-page web application that creates a client-side user interface and receives data updates over the north. This was significantly different from any work that we had previously done at Fog Creek. So, from a technical point of view, the development of Trello was an adventure.
At first, we were surprised how interesting and diverse the structure of the [application] could be, before the [project] management became worried, our problems were solved at the initial meeting with Joel , when he said: “Use solutions that will work perfectly for two years ".
So we did. We have consistently selected promising (and often problematic) technologies that will provide a terrific experience compared to more mature alternatives. We have been doing this for about a year, and we like it.
Trello development started on pure JavaScript both on the client side and on the server side, and adhered to this path until the month of May, when we experimentally rewrote a couple of files on CoffeeScript to see if we liked it. We really liked it, and very soon we rewrote the rest of the code and continued development entirely on CoffeeScript.
CoffeeScript is a language that compiles to be easy to read.Javascript It already existed when we started developing Trello, but I was worried about the additional complexity caused by debugging the compiled code, instead of directly debugging the source files. When we tried this, however, the conversion turned out to be so high-quality that it took a little mental effort to render the final code to the source files during debugging in Chrome. And the gain from code brevity and ease of reading when using CoffeeScript was obvious and convincing.
JavaScript is a cool language. Well-written CoffeeScript smooths and shortens JavaScript, while maintaining the same semantics, and does not introduce a significant problem into debugging.
Trello servers, in essence, do not work with HTML. In fact, they do not execute much client code. The Trello page is a lightweight (2KiB) thin shell that downloads the client application from the server in the form of one minimized and compressed JS file (including third-party libraries and our compiled CoffeeScript files and Mustache templates) and one CSS file (compiled from our LESS files and including embedded (inlined) images). All it takes is less than 250KiB, and we are sharing it with Amazon's CloudFrontCDN This way we get low-latency downloads for most users. In the case of a fairly high-speed connection (high-bandwidth) we get the download and launch of the application in the browser window in about half a second. We also benefit from caching, and so on subsequent visits to Trello that part [download] is skipped.
At the same time, we removed the loading of data via AJAX from the start page and try to establish a WebSocket connection to the server.
When a response with data arrives, Backbone.js starts acting. The idea with Backbone is to display each model received from the server using a View, and Backbone provides easy ways to:
Gracefully! Using this approach, we get a normal, understandable and supported client application. We specifically build client-side model caches to handle updates and simplify client-side reuse of the model.
Now that we have the entire client application loaded into the browser window, we do not want to waste time navigating between pages. We use the HTML 5 History.pushState interface method to navigate between pages. In this way, we provide the correct and consistent links in the location bar [browser element], and upon transition we simply load the data and transfer it to the appropriate controller based on Backbone.
We use Mustache - a template language with minimal use of logical constructs - to display our models in HTML. While “using the full power of [substitute_ here_your_name] templates” sounds good, in practice it turns out that this requires serious discipline from developers to maintain clear code. We were very happy with Mustache's “brevity is the sister of talent” approach, which allows us to reuse template code without mixing it with client logic and causing confusion.
Real-time updates (realtime) is not a new thing, but it is an important part when creating a collaboration tool, so we spent some time on this part of Trello.
For those browsers that support this, we used WebSocket connections so that the server pushes changes made by other people into browsers listening to the corresponding channels. We use modified (*) Socket.io client and server libraries, which allow us to keep many thousands of WebSocket connections open on each of our servers with minimal costs in terms of CPU and memory usage. Thus, when some action occurs on the board [Trello element] that you are observing, this action is transferred to the process on our server and distributed to the browser with a minimum delay, usually much less than a second.
(*) Currently, the Socket.io server has some problems with scaling up to more than 10K concurrent connections with clients when using several processes and Redis storage. And the client has some problems that can lead to the opening of multiple connections to the same server or to the fact that the client will not be able to determine that its connection is served. There are some problems with making our changes (hacks!) Back to the project - in many cases they only work with WebSockets (the only Socket.io transport we use). We are working on those changes that are suitable for general use, for making back to the project.
They are not intricate, but they work.
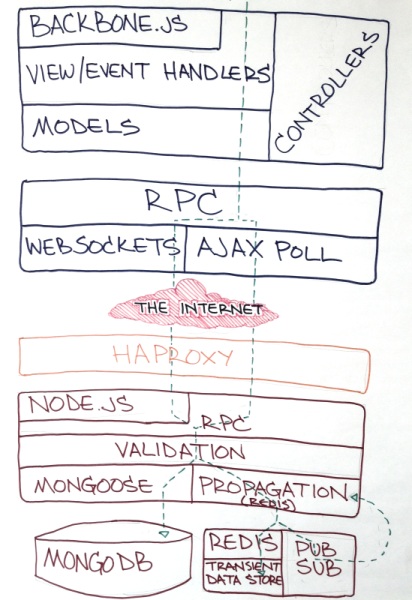
Initial sketch of architecture.
When the browser does not support WebSockets (hi, IE), we just make tiny AJAX change requests every couple of seconds while the user is active, and reduce the interval to ten seconds when the user goes into idle. Since our server settings allow us to serve HTTPS requests with minimal overhead and keep TCP connections open, we are able to share good experience in using simple requests when necessary.
We tried Comet through low-level transports for Socket.io, and all of them were unstable at that time, anyway. In addition, it seems risky to use Comet and WebSockets as the basis for the main feature of the application. We wanted to be able to return to the simplest and most established technologies if we stumble upon a problem.
We stumbled upon a problem right after launch. Our WebSocket server implementation began to behave strangely under the sudden and massive loads caused by TechCrancheffect, and we were glad that we were able to return to simple requests, and adjust the server performance by adjusting the intervals of requests during activity and during inactivity. This allowed us to smoothly reduce performance when our number of users grew from 300 to 50,000 in a week. Now we are back to using WebSockets, but we have a working short-request system, which still seems to be a very prudent reserve.
To be continued...
The article itself is quite voluminous, therefore it is divided into two parts:
Part 1
- CoffeeScript
- Client
* Backbone.js
* HTML5 History API
* Mustache - Pushing and Polling
* Socket.io and WebSockets
* AJAX Requests
Part 2
- Server
* node.js
* HAProxy
* Redis
* MongoDB - So, do we like it?
The trello tech stack
Trello's development began with an HTML layout that Justin and Bobby , the Trello team designers, had assembled in a week. I was struck by how cool he looked and felt. After Daniel and I joined the project to develop the prototype and working version of Trello, the real challenge was to keep the amazing impressions of the original layout while creating the server and client.
The original layout of Trello.
The layout led us to a one-page web application that creates a client-side user interface and receives data updates over the north. This was significantly different from any work that we had previously done at Fog Creek. So, from a technical point of view, the development of Trello was an adventure.
At first, we were surprised how interesting and diverse the structure of the [application] could be, before the [project] management became worried, our problems were solved at the initial meeting with Joel , when he said: “Use solutions that will work perfectly for two years ".
So we did. We have consistently selected promising (and often problematic) technologies that will provide a terrific experience compared to more mature alternatives. We have been doing this for about a year, and we like it.
CoffeeScript
Trello development started on pure JavaScript both on the client side and on the server side, and adhered to this path until the month of May, when we experimentally rewrote a couple of files on CoffeeScript to see if we liked it. We really liked it, and very soon we rewrote the rest of the code and continued development entirely on CoffeeScript.
CoffeeScript is a language that compiles to be easy to read.Javascript It already existed when we started developing Trello, but I was worried about the additional complexity caused by debugging the compiled code, instead of directly debugging the source files. When we tried this, however, the conversion turned out to be so high-quality that it took a little mental effort to render the final code to the source files during debugging in Chrome. And the gain from code brevity and ease of reading when using CoffeeScript was obvious and convincing.
JavaScript is a cool language. Well-written CoffeeScript smooths and shortens JavaScript, while maintaining the same semantics, and does not introduce a significant problem into debugging.
Client
- Backbone.js (MVC framework)
- HTML 5 (History API: pushState)
- Mustache (templates)
Trello servers, in essence, do not work with HTML. In fact, they do not execute much client code. The Trello page is a lightweight (2KiB) thin shell that downloads the client application from the server in the form of one minimized and compressed JS file (including third-party libraries and our compiled CoffeeScript files and Mustache templates) and one CSS file (compiled from our LESS files and including embedded (inlined) images). All it takes is less than 250KiB, and we are sharing it with Amazon's CloudFrontCDN This way we get low-latency downloads for most users. In the case of a fairly high-speed connection (high-bandwidth) we get the download and launch of the application in the browser window in about half a second. We also benefit from caching, and so on subsequent visits to Trello that part [download] is skipped.
At the same time, we removed the loading of data via AJAX from the start page and try to establish a WebSocket connection to the server.
Backbone.js
When a response with data arrives, Backbone.js starts acting. The idea with Backbone is to display each model received from the server using a View, and Backbone provides easy ways to:
- tracking DOM events in HTML that was created by the view and binding them to handlers in a model that synchronizes with the server;
- tracking model changes and displaying changed HTML blocks.
Gracefully! Using this approach, we get a normal, understandable and supported client application. We specifically build client-side model caches to handle updates and simplify client-side reuse of the model.
History.pushState
Now that we have the entire client application loaded into the browser window, we do not want to waste time navigating between pages. We use the HTML 5 History.pushState interface method to navigate between pages. In this way, we provide the correct and consistent links in the location bar [browser element], and upon transition we simply load the data and transfer it to the appropriate controller based on Backbone.
Mustache
We use Mustache - a template language with minimal use of logical constructs - to display our models in HTML. While “using the full power of [substitute_ here_your_name] templates” sounds good, in practice it turns out that this requires serious discipline from developers to maintain clear code. We were very happy with Mustache's “brevity is the sister of talent” approach, which allows us to reuse template code without mixing it with client logic and causing confusion.
Pushing and polling
Real-time updates (realtime) is not a new thing, but it is an important part when creating a collaboration tool, so we spent some time on this part of Trello.
Socket.io and WebSockets
For those browsers that support this, we used WebSocket connections so that the server pushes changes made by other people into browsers listening to the corresponding channels. We use modified (*) Socket.io client and server libraries, which allow us to keep many thousands of WebSocket connections open on each of our servers with minimal costs in terms of CPU and memory usage. Thus, when some action occurs on the board [Trello element] that you are observing, this action is transferred to the process on our server and distributed to the browser with a minimum delay, usually much less than a second.
(*) Currently, the Socket.io server has some problems with scaling up to more than 10K concurrent connections with clients when using several processes and Redis storage. And the client has some problems that can lead to the opening of multiple connections to the same server or to the fact that the client will not be able to determine that its connection is served. There are some problems with making our changes (hacks!) Back to the project - in many cases they only work with WebSockets (the only Socket.io transport we use). We are working on those changes that are suitable for general use, for making back to the project.
AJAX requests
They are not intricate, but they work.
Initial sketch of architecture.
When the browser does not support WebSockets (hi, IE), we just make tiny AJAX change requests every couple of seconds while the user is active, and reduce the interval to ten seconds when the user goes into idle. Since our server settings allow us to serve HTTPS requests with minimal overhead and keep TCP connections open, we are able to share good experience in using simple requests when necessary.
We tried Comet through low-level transports for Socket.io, and all of them were unstable at that time, anyway. In addition, it seems risky to use Comet and WebSockets as the basis for the main feature of the application. We wanted to be able to return to the simplest and most established technologies if we stumble upon a problem.
We stumbled upon a problem right after launch. Our WebSocket server implementation began to behave strangely under the sudden and massive loads caused by TechCrancheffect, and we were glad that we were able to return to simple requests, and adjust the server performance by adjusting the intervals of requests during activity and during inactivity. This allowed us to smoothly reduce performance when our number of users grew from 300 to 50,000 in a week. Now we are back to using WebSockets, but we have a working short-request system, which still seems to be a very prudent reserve.
To be continued...