History of the struggle for IOPS in a self-assembled SAN
Hello!
One of my projects uses something a bit like a private cloud. These are several servers for data storage and several - diskless, responsible for virtualization. The other day I seem to have finally put an end to the issue of squeezing the maximum performance of the disk subsystem of this solution. It was quite interesting, and even at some points - quite unexpectedly. Therefore, I want to share my story with the habrasociety, which began back in 2008, even before the advent of the "First Cloud Provider in Russia" and the campaign for sending free water meters.
Virtual hard disks are exported through a separate gigabit network using the AoE protocol . In short - this is the brainchild of Coraid, which proposed to implement the transfer of ATA commands over the network directly. The protocol specification takes only a dozen pages! The main feature is the lack of TCP / IP. When transferring data, a minimal overhead is obtained, but as a fee for simplicity, impossibility of routing.
Why such a choice? If you omit the reprinting of official sources - including and commonplace lowcost.
Accordingly, in storages we used ordinary SATA disks with 7200 rpm. Their flaw is known to everyone - low IOPS.
The very first, popular and obvious way to solve the problem of random access speed. They took mdadm into their hands, drove a couple of appropriate commands into the console, raised LVM on top (we are going to distribute block devices for virtual machines as a result) and launched several naive tests.
To be honest, checking IOPS was scary, there were no options for solving the problem besides switching to SCSI or writing your own crutches.
Although the network was gigabit, the read speed from diskless servers did not reach the expected ~ 100MiB / sec. Naturally, the drivers of the network cards were to blame (hi, Debian). Using fresh drivers from the manufacturer’s website seems to have partially fixed the problem ...
In all AoE speed optimization manuals, the first item indicates setting the maximum MTU. At that moment it was 4200. Now it seems ridiculous, but compared to the standard 1500, the linear read speed really reached ~ 120MiB / sec, cool! And even with a small load on the disk subsystem by all virtual servers, local caches corrected the situation and within each virtual machine the linear read speed was kept at least 50MiB / sec. Actually, pretty good! Over time, we changed the network cards, the switch, and raised the MTU to a maximum of 9K.
Yes, some of the projects 24/7 pulled MySQL, both for writing and reading. It looked something like this:
Harmless? No matter how. A huge stream of small requests, 70% io wait on the virtual server, 20% load on each of the hard disks (according to atop) on the storage and such a dull picture on the other virtual machines:
And it's fast! Often the linear read speed was no more than 1-2 MiB / sec.
I think everyone has already guessed what we ran into. Low IOPS SATA drives, even though RAID10.
How on time these guys appeared! This is salvation, this is the same! Life is getting better, we will be saved!
Urgent purchase of Intel SSDs, inclusion of the module and flashcache utilities in the live-image of storage servers, write-back cache setting and fire in the eyes. Yeah, all the counters are zeros. Well, the features of LVM + Flashcache are easy to google, the problem was quickly resolved.
On a virtual server with MySQL, loadavg dropped from 20 to 10. Linear reading on other virtual machines increased to stable 15-20 MiB / sec. Do not be fooled!
After some time, I collected the following statistics:
read hit percent: 13, write hit percent: 3. A huge amount of uncached reads / writes. It turns out that flashcache worked, but not at full strength. There were a couple of dozen virtual machines, the total volume of virtual disks did not exceed a terabyte, disk activity was small. Those. such a low percentage of cache hits - not because of neighbor activity.
For the hundredth time looking at this:
I decided to open my favoriteExcel LibreOffice Calc:

The diagram is built on the last line, a histogram of the distribution of queries by block sizes.
We all know that
hard drives usually operate in 512-byte blocks. Exactly like AoE. Linux kernel - 4096 bytes each. Data block size in flascache is also 4096.
Having summed up the number of requests with block sizes different from 4096, it is evident that the resulting number suspiciously matches the number of uncached reads + uncached writes from the flashcache statistics. Only 4K blocks are cached! Remember that initially MTU we had 4200? If we subtract from this the size of the AoE packet header, we get the size of the data block at 3584. This means that any request to the disk subsystem will be divided into at least 2 AoE packets: 3584 bytes and 512 bytes. Which just was clearly visible in the original diagram, which I saw. Even in the diagram from the article, the predominance of 512 byte packets is noticeable. And the MTK recommended at each corner in 9K also has a similar problem: the size of the data block is 8704 bytes, these are 2 4K blocks and one per 512 bytes (which is exactly what is seen in the diagram from the article). Goofy! The solution, I think, is obvious to everyone.
The diagram is made a few days after updating the configuration on one of the diskless nodes. After updating MTU on the others, the situation will become even better. And loadavg on a virtual server with MySQL dropped to 3!
Not being system administrators with 20 years of experience, we solved problems using the “standard” and most popular approaches known to the community at the appropriate time. But in the real world there is always room for imperfections, crutches and assumptions. On which we, in fact, ran into.
Here is such a story.
One of my projects uses something a bit like a private cloud. These are several servers for data storage and several - diskless, responsible for virtualization. The other day I seem to have finally put an end to the issue of squeezing the maximum performance of the disk subsystem of this solution. It was quite interesting, and even at some points - quite unexpectedly. Therefore, I want to share my story with the habrasociety, which began back in 2008, even before the advent of the "First Cloud Provider in Russia" and the campaign for sending free water meters.
Architecture
Virtual hard disks are exported through a separate gigabit network using the AoE protocol . In short - this is the brainchild of Coraid, which proposed to implement the transfer of ATA commands over the network directly. The protocol specification takes only a dozen pages! The main feature is the lack of TCP / IP. When transferring data, a minimal overhead is obtained, but as a fee for simplicity, impossibility of routing.
Why such a choice? If you omit the reprinting of official sources - including and commonplace lowcost.
Accordingly, in storages we used ordinary SATA disks with 7200 rpm. Their flaw is known to everyone - low IOPS.
RAID10
The very first, popular and obvious way to solve the problem of random access speed. They took mdadm into their hands, drove a couple of appropriate commands into the console, raised LVM on top (we are going to distribute block devices for virtual machines as a result) and launched several naive tests.
root@storage:~# hdparm -tT /dev/md127
/dev/md127:
Timing cached reads: 9636 MB in 2.00 seconds = 4820.51 MB/sec
Timing buffered disk reads: 1544 MB in 3.03 seconds = 509.52 MB/sec
To be honest, checking IOPS was scary, there were no options for solving the problem besides switching to SCSI or writing your own crutches.
Network and MTU
Although the network was gigabit, the read speed from diskless servers did not reach the expected ~ 100MiB / sec. Naturally, the drivers of the network cards were to blame (hi, Debian). Using fresh drivers from the manufacturer’s website seems to have partially fixed the problem ...
In all AoE speed optimization manuals, the first item indicates setting the maximum MTU. At that moment it was 4200. Now it seems ridiculous, but compared to the standard 1500, the linear read speed really reached ~ 120MiB / sec, cool! And even with a small load on the disk subsystem by all virtual servers, local caches corrected the situation and within each virtual machine the linear read speed was kept at least 50MiB / sec. Actually, pretty good! Over time, we changed the network cards, the switch, and raised the MTU to a maximum of 9K.
Until MySQL Comes
Yes, some of the projects 24/7 pulled MySQL, both for writing and reading. It looked something like this:
Total DISK READ: 506.61 K/s | Total DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
30312 be/4 mysql 247.41 K/s 11.78 K/s 0.00 % 11.10 % mysqld
30308 be/4 mysql 113.89 K/s 19.64 K/s 0.00 % 7.30 % mysqld
30306 be/4 mysql 23.56 K/s 23.56 K/s 0.00 % 5.36 % mysqld
30420 be/4 mysql 62.83 K/s 11.78 K/s 0.00 % 5.03 % mysqld
30322 be/4 mysql 23.56 K/s 23.56 K/s 0.00 % 2.58 % mysqld
30445 be/4 mysql 19.64 K/s 19.64 K/s 0.00 % 1.75 % mysqld
30183 be/4 mysql 7.85 K/s 7.85 K/s 0.00 % 1.15 % mysqld
30417 be/4 mysql 7.85 K/s 3.93 K/s 0.00 % 0.36 % mysqld
Harmless? No matter how. A huge stream of small requests, 70% io wait on the virtual server, 20% load on each of the hard disks (according to atop) on the storage and such a dull picture on the other virtual machines:
root@mail:~# hdparm -tT /dev/xvda
/dev/xvda:
Timing cached reads: 10436 MB in 1.99 seconds = 5239.07 MB/sec
Timing buffered disk reads: 46 MB in 3.07 seconds = 14.99 MB/sec
And it's fast! Often the linear read speed was no more than 1-2 MiB / sec.
I think everyone has already guessed what we ran into. Low IOPS SATA drives, even though RAID10.
Flashcache
How on time these guys appeared! This is salvation, this is the same! Life is getting better, we will be saved!
Urgent purchase of Intel SSDs, inclusion of the module and flashcache utilities in the live-image of storage servers, write-back cache setting and fire in the eyes. Yeah, all the counters are zeros. Well, the features of LVM + Flashcache are easy to google, the problem was quickly resolved.
On a virtual server with MySQL, loadavg dropped from 20 to 10. Linear reading on other virtual machines increased to stable 15-20 MiB / sec. Do not be fooled!
After some time, I collected the following statistics:
root@storage:~# dmsetup status cachedev
0 2930294784 flashcache stats:
reads(85485411), writes(379006540)
read hits(12699803), read hit percent(14)
write hits(11805678) write hit percent(3)
dirty write hits(4984319) dirty write hit percent(1)
replacement(144261), write replacement(111410)
write invalidates(2928039), read invalidates(8099007)
pending enqueues(2688311), pending inval(1374832)
metadata dirties(11227058), metadata cleans(11238715)
metadata batch(3317915) metadata ssd writes(19147858)
cleanings(11238715) fallow cleanings(6258765)
no room(27) front merge(1919923) back merge(1058070)
disk reads(72786438), disk writes(374046436) ssd reads(23938518) ssd writes(42752696)
uncached reads(65392976), uncached writes(362807723), uncached IO requeue(13388)
uncached sequential reads(0), uncached sequential writes(0)
pid_adds(0), pid_dels(0), pid_drops(0) pid_expiry(0)
read hit percent: 13, write hit percent: 3. A huge amount of uncached reads / writes. It turns out that flashcache worked, but not at full strength. There were a couple of dozen virtual machines, the total volume of virtual disks did not exceed a terabyte, disk activity was small. Those. such a low percentage of cache hits - not because of neighbor activity.
Insight!
For the hundredth time looking at this:
root@storage:~# dmsetup table cachedev
0 2930294784 flashcache conf:
ssd dev (/dev/sda), disk dev (/dev/md2) cache mode(WRITE_BACK)
capacity(57018M), associativity(512), data block size(4K) metadata block size(4096b)
skip sequential thresh(0K)
total blocks(14596608), cached blocks(3642185), cache percent(24)
dirty blocks(36601), dirty percent(0)
nr_queued(0)
Size Hist: 512:117531108 1024:61124866 1536:83563623 2048:89738119 2560:43968876 3072:51713913 3584:83726471 4096:41667452
I decided to open my favorite
The diagram is built on the last line, a histogram of the distribution of queries by block sizes.
We all know that
hard drives usually operate in 512-byte blocks. Exactly like AoE. Linux kernel - 4096 bytes each. Data block size in flascache is also 4096.
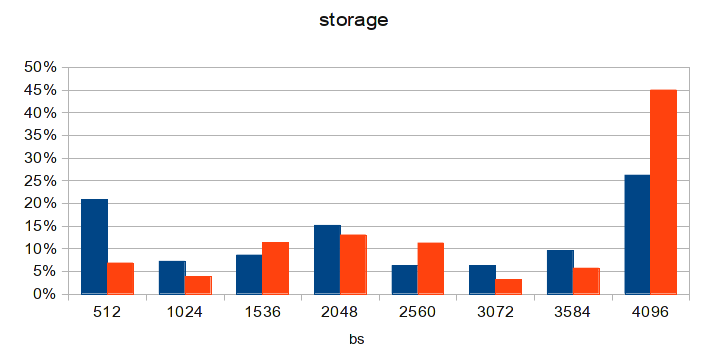
Having summed up the number of requests with block sizes different from 4096, it is evident that the resulting number suspiciously matches the number of uncached reads + uncached writes from the flashcache statistics. Only 4K blocks are cached! Remember that initially MTU we had 4200? If we subtract from this the size of the AoE packet header, we get the size of the data block at 3584. This means that any request to the disk subsystem will be divided into at least 2 AoE packets: 3584 bytes and 512 bytes. Which just was clearly visible in the original diagram, which I saw. Even in the diagram from the article, the predominance of 512 byte packets is noticeable. And the MTK recommended at each corner in 9K also has a similar problem: the size of the data block is 8704 bytes, these are 2 4K blocks and one per 512 bytes (which is exactly what is seen in the diagram from the article). Goofy! The solution, I think, is obvious to everyone.
MTU 8700
The diagram is made a few days after updating the configuration on one of the diskless nodes. After updating MTU on the others, the situation will become even better. And loadavg on a virtual server with MySQL dropped to 3!
Conclusion
Not being system administrators with 20 years of experience, we solved problems using the “standard” and most popular approaches known to the community at the appropriate time. But in the real world there is always room for imperfections, crutches and assumptions. On which we, in fact, ran into.
Here is such a story.