Cassandra for storing metadata: successes and failures
What requirements must be met by a metadata store for a cloud service? But not the most usual, but for enterprises with support for geographically distributed data centers and Active-Active. Obviously, the system must scale well, be fault tolerant and would like to be able to implement custom consistency of operations.
Under all these requirements only Cassandra fits, and nothing else fits. It should be noted, Cassandra is really cool, but working with it resembles a roller coaster.
In a report on Highload ++ 2017 Andrey Smirnov ( smira) I decided that it was not interesting to talk about good things, but I spoke in detail about every problem I had to face: data loss and data corruption, zombies and performance loss. These stories really resemble a roller coaster ride, but for all the problems there is a solution, for which you are welcome to the cat.
About the speaker: Andrey Smirnov works in the company Virtustream, implementing cloud storage for the enterprise. The idea is that conditionally, Amazon makes a cloud for everyone, and Virtustream does the specific things that a large company needs.
We work in a completely remote small team, and we are working on one of the Virtustream cloud solutions. This is a cloud data storage.

Speaking very simply, it is an S3-compatible API in which you can store objects. For those who don’t know what S3 is, it’s just the HTTP API that allows you to upload objects to the cloud somewhere, get them back, delete them, get a list of objects, etc. Further - already more complex features based on these simple operations.
We have some distinctive features that Amazon doesn't have. One of them is the so-called geo-regions. In a typical situation, when you create a repository and say that you will be storing objects in the cloud, you must select a region. A region is essentially a data center, and your objects will never leave this data center. If something happens to it, then your objects will no longer be available.
We offer geo-regions in which data is located simultaneously in several data centers (DC), at least in two, as in the picture. The client can contact any data center, for him it is transparent. The data between them is replicated, that is, we are working in the “Active-Active” mode, and all the time. This provides the customer with additional features, including:
This is an interesting opportunity - even if these DCs are far from each other geographically, then one of them may be closer to the client at different points in time. And access the data in the nearest DC just faster.
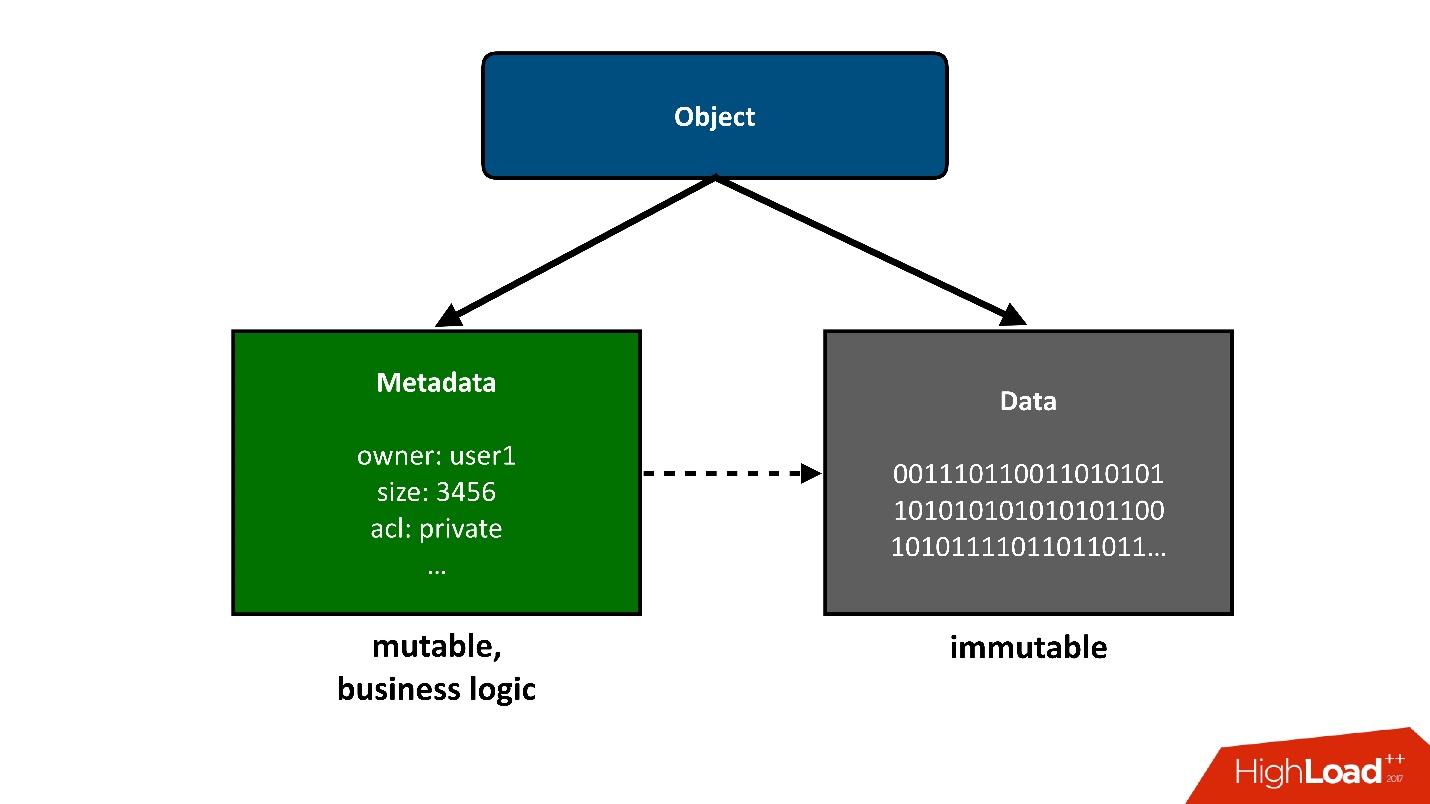
In order for the construction that we will talk about to be divided into parts, I will present those objects that are stored in the cloud as two large pieces:
1. The first simple piece of an object is data . They are the same, they were downloaded once and that's it. The only thing that can happen to them later is that we can remove them if they are no longer needed.
The previous project was related to the storage of the data exabyte, so we did not have any problems with data storage. This for us was already a solved task.
2. Metadata. All business logic, all the most interesting, related to competitiveness: circulation, writing, rewriting - in the area of metadata.
Metadata about the object takes away the greatest complexity of the project, the metadata stores a pointer to the block of the saved data of the object.
From the user's point of view, this is a single object, but we can divide it into two parts. Today I will only talk about metadata .
Numbers
If you look at these indicators carefully, the first thing that catches your eye is the very small average size of the stored object. We have a lot of metadata per unit volume of basic data. For us it was no less surprise than perhaps for you now.
We planned that we would have at least an order of magnitude, if not 2, more than metadata. That is, each object will be much larger, and the volume of metadata will be less. Because data is cheaper to store, there are fewer operations with them, and metadata is much more expensive both in terms of hardware and in terms of maintaining and performing various operations on them.
At the same time, these data change with a fairly high speed. I gave here the peak value, non-peak is not much less, but, nevertheless, quite a large load can be obtained at specific points in time.
These figures were obtained from the operating system, but let's go back a bit, by the time the cloud storage is designed.
When we faced the challenge that we want to have geo-regions, Active-Active, and we need to store metadata somewhere, we thought, what could it be?
Obviously, the storage (database) must have the following properties:
We would very much like our product to be wildly popular, and we don’t know how it will grow in this case, so the system must scale.
Metadata must be stored securely, because if we lose them, and there is a link to the data, we will lose the entire object.
Due to the fact that we work in several DCs and admit the possibility that DCs may be unavailable, moreover, DCs are far from each other, we cannot during the execution of most operations through the API require that this operation be performed simultaneously in two DCs. It will be just too slow and impossible if the second DC is unavailable. Therefore, part of the operations should work locally in one DC.
But, obviously, some convergence should take place once, and after all conflicts have been resolved, the data should be visible in both data centers. Therefore, the consistency of operations must be adjusted.
From my point of view, Cassandra fits these requirements.
I would be very happy if we did not have to use Cassandra, because for us it was a kind of new experience. But nothing else fits. It seems to me that the saddest situation on the market for such storage systems is that there is no alternative .

What is Cassandra?
This is a distributed key-value database. From the point of view of architecture and the ideas that are embedded in it, it seems to me, everything is cool. If I did, I would do the same. When we first started, we thought about writing our own metadata storage system. But the further, the more and more we understood that we would have to do something very similar to Cassandra, and the efforts that we will spend on it are not worth it. For the whole development we had only one and a half months . It would be strange to spend them on writing your database.
If Cassandra is divided into layers, like a layer cake, I would select 3 layers:
1. Local KV storage on each node.
This is a cluster of nodes, each of which is able to store key-value data locally.
2Sharding data on nodes (consistent hashing).
Cassandra is able to distribute data across cluster nodes, including replication, and does this in such a way that the cluster can grow or shrink in size, and the data will be redistributed.
3. Coordinator for redirecting requests to other nodes.
When we access data from any application from our application, Cassandra can distribute our request among nodes so that we get the data we want and with the level of consistency that we need - we want to read them just quorum, or we want quorum with two DCs, etc.
For us, two years with Cassandra are roller coasters or Russian as you wish to call. It all started deep down, we had zero experience with Cassandra. We were scared. We started and everything was fine. But then there are constant ups and downs: the problem, everything is bad, we don’t know what to do, we have mistakes, then we solve the problem, etc.
These roller coasters, in principle, do not end to this day.
The first and last chapter, where I will say that Cassandra is cool. It is really cool, a great system, but if I continue to say how good it is, I think you will not be interested. Therefore, the bad pay more attention, but later.
Cassandra is really good.
Again, Cassandra is good, it works for us, but I will tell five stories about the bad. I think this is what you read it for. I will cite stories in chronological order, although they are not very connected with each other.

This story was the saddest for us. Since we store user data, the worst possible thing is to lose them, and lose them irretrievably , as happened in this situation. We had ways to recover data if we lost it in Cassandra, but we lost it so that we really could not recover it.
In order to explain how this happens, I have a little bit to tell you about how everything is arranged inside us.
From an S3 point of view, there are a few basic things:
In our situation, active-active, operations can occur, including competitive in different DC, not only in one. Therefore, we need some kind of preservation scheme that will allow to implement this logic. In the end, we chose a simple policy: the latest recorded version wins. Sometimes there are several competitive operations, but it is not necessary that our customers specifically do this. It may just be a request that started, but the client did not wait for an answer, something else happened, tried again, etc.
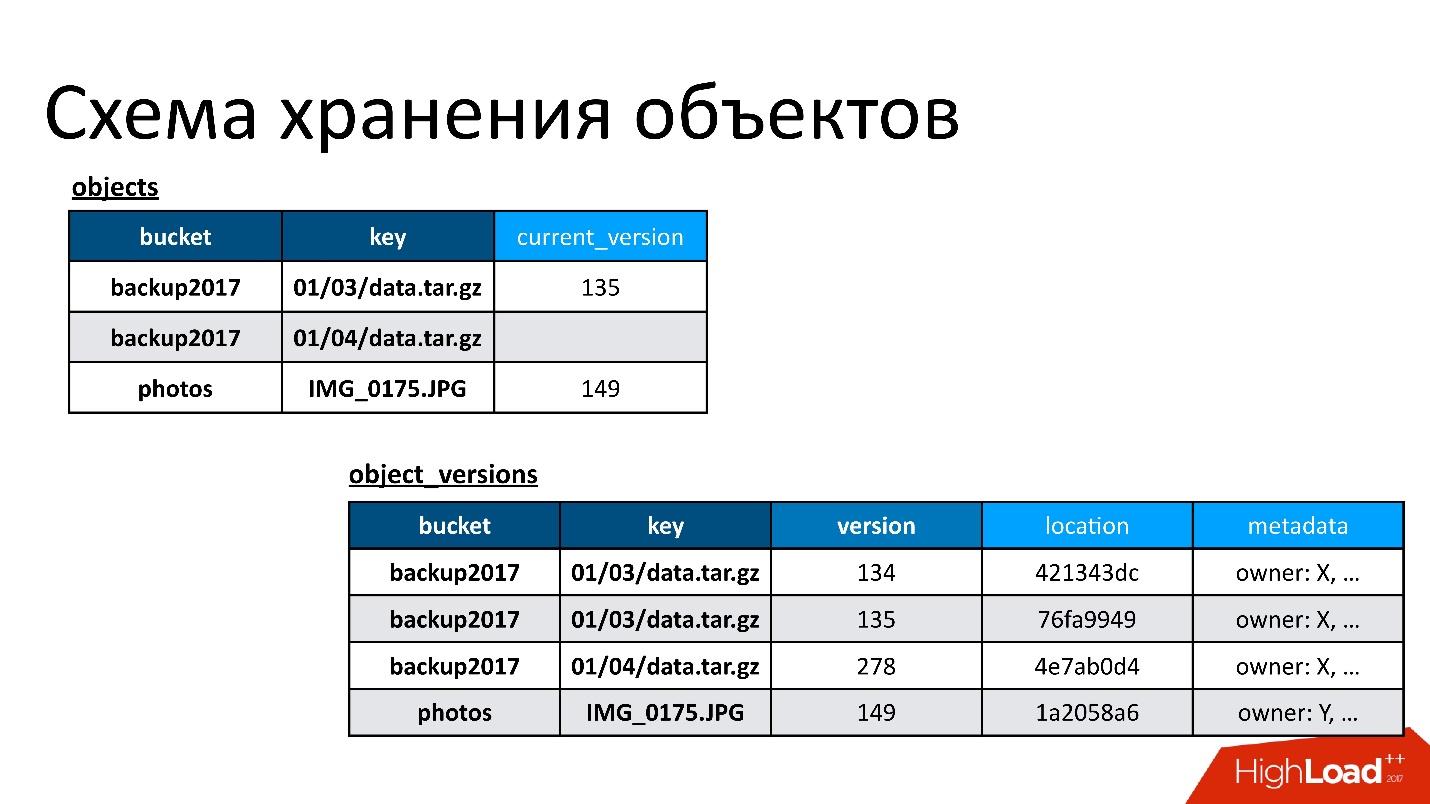
Therefore, we have two base tables:
The figure is an example of how object tables and object versions are related.

Here there is an object that has two versions - one current and one old, there is an object that has already been deleted, and its version is still there. We need to clean up unnecessary versions from time to time, that is, to delete something that nobody already refers to. And we don’t need to delete immediately, we can do it in the deferred mode. This is our internal cleaning, we simply remove what is no longer needed.
There was a problem.
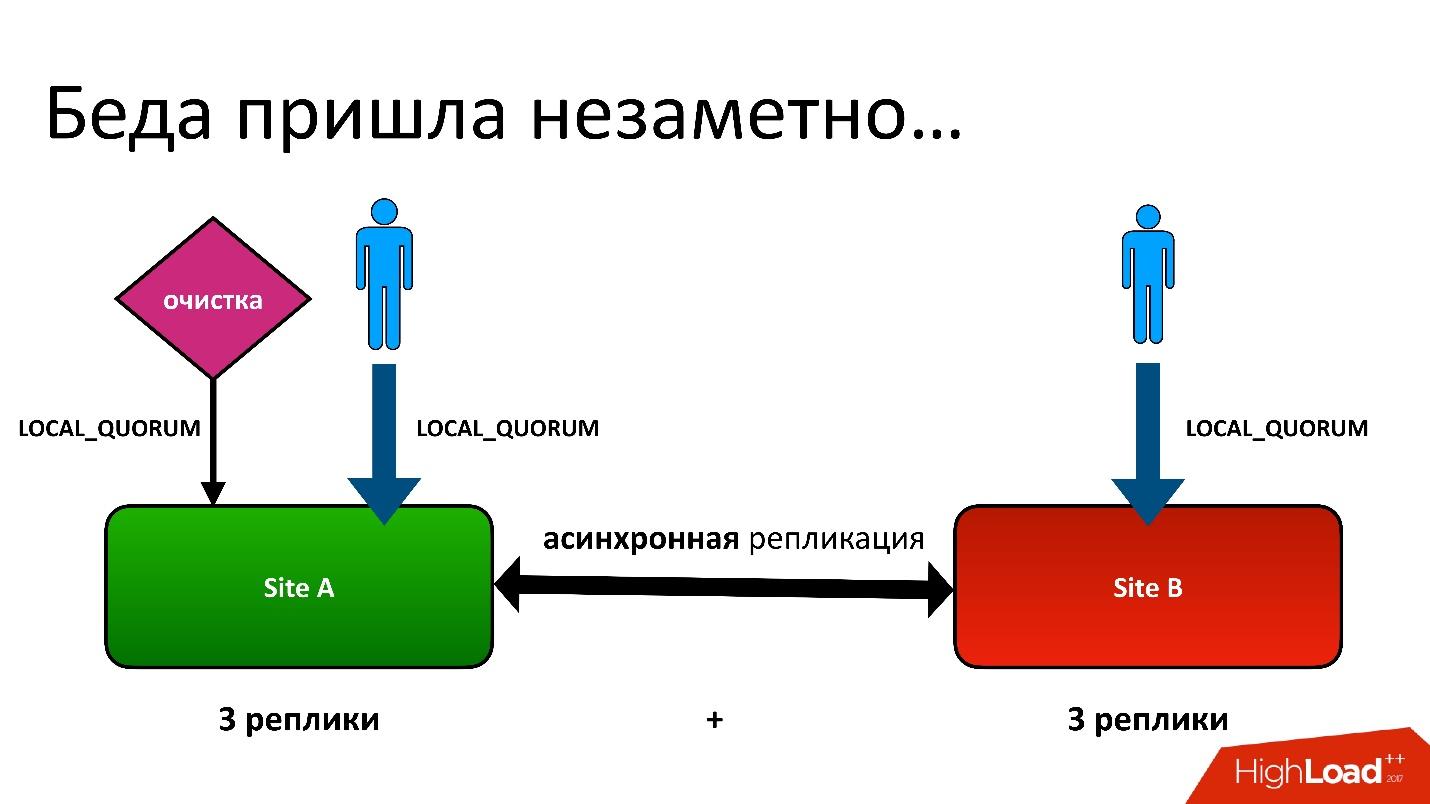
The problem was this: we have an active-active, two DCs. In each DC, the metadata is stored in three copies, that is, we have 3 + 3 - only 6 replicas. When clients turn to us, we perform operations with consistency (from the point of view of Cassandra is called LOCAL_QUORUM). That is, it is guaranteed that the write (or read) occurred in 2 replicas in the local DC. This is a guarantee - otherwise the operation will fail.
Cassandra will always try to write in all 6 replicas - 99% of the time everything will be fine. In fact, all 6 replicas will be the same, but guaranteed to us 2.
We had a difficult situation, although it was not even a geo-region. Even for ordinary regions, which are in one DC, we still kept a second copy of the metadata in another DC. This is a long story, I will not give all the details. But ultimately we had a cleaning process that removed unnecessary versions.
And then that problem arose. The cleaning process also worked with the consistency of the local quorum in one data center, because there is no two ways to run it - they will fight with each other.
Everything was good, until it turned out that our users still sometimes write to another data center, which we did not suspect. Everything was set up just in case for a faylover, but it turned out that they were already using it.
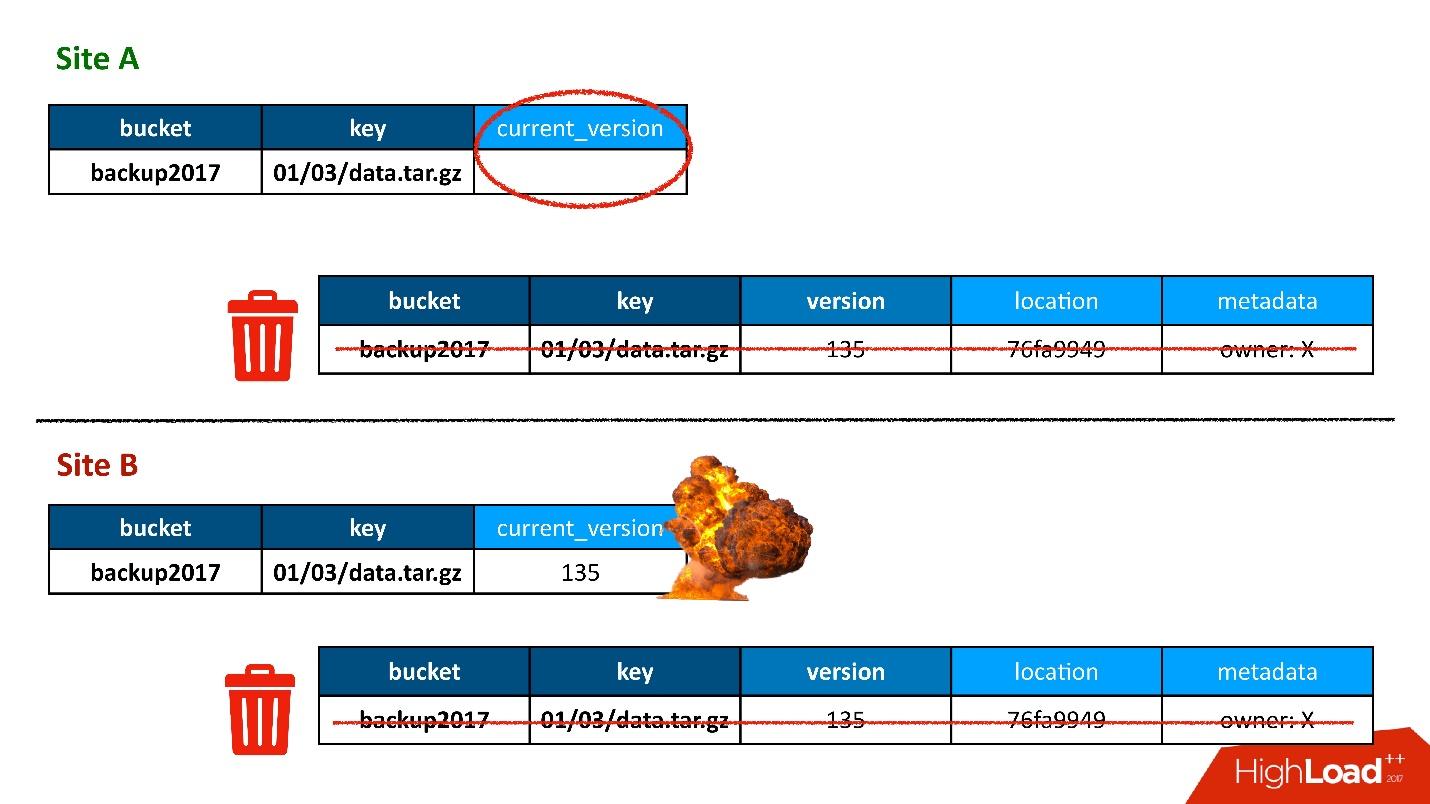
Most of the time, everything was fine, until one day a situation arose when a record in the version table was replicated in both DCs, but the entry in the table of objects was only in one DC, and the second did not hit. Accordingly, the cleaning procedure launched in the first (upper) DC, saw that there is a version to which no one refers, and deleted it. Moreover, it deleted not only the version, but, of course, the data - all completely, because it is just an unnecessary object. And this removal is irrevocable.
Of course, the “boom” happens further, because we have a record in the object table that refers to a version that no longer exists.
So the first time we lost the data, and lost them really irrevocably - the good, a little.
What to do? In our situation, everything is simple.
Since our data is stored in two business centers, the cleaning process is a process of some kind of convergence and synchronization. We must read the data from both DCs. This process will work only when both DCs are available. Since I said that this is a delayed process that does not occur during the processing of the API, it is not a problem.
ALL consistency is a feature of Cassandra 2. In Cassandra 3, everything is slightly better — there is a level of consistency, which is called quorum in each DC. But in any case, there is the problem of the fact that it is slow , because, first, we have to contact a remote DC. Secondly, in the case of the consistency of all 6 nodes, this means that it operates at the speed of the worst of these 6 nodes.
But at the same time there is a process of the so-called read-repair , when not all replicas are synchronous. That is, when somewhere the recording failed, this process repairs them at the same time. That's the way Cassandra is.
When this happened, we received a complaint from the client that the object was unavailable. We figured out, understood why, and the first thing we wanted to do was find out how many such objects we still have. We ran a script that tried to find a construct similar to this one when there is a record in one table, but there is no record in another.
Suddenly, we discovered that we have 10% of such records . Nothing worse, probably, could not be, if we had not guessed that this was not the case. The problem was different.

Zombies sneaked into our database. This is the semi-official title of the problem. In order to understand what it is, you need to talk about how the removal works in Cassandra.
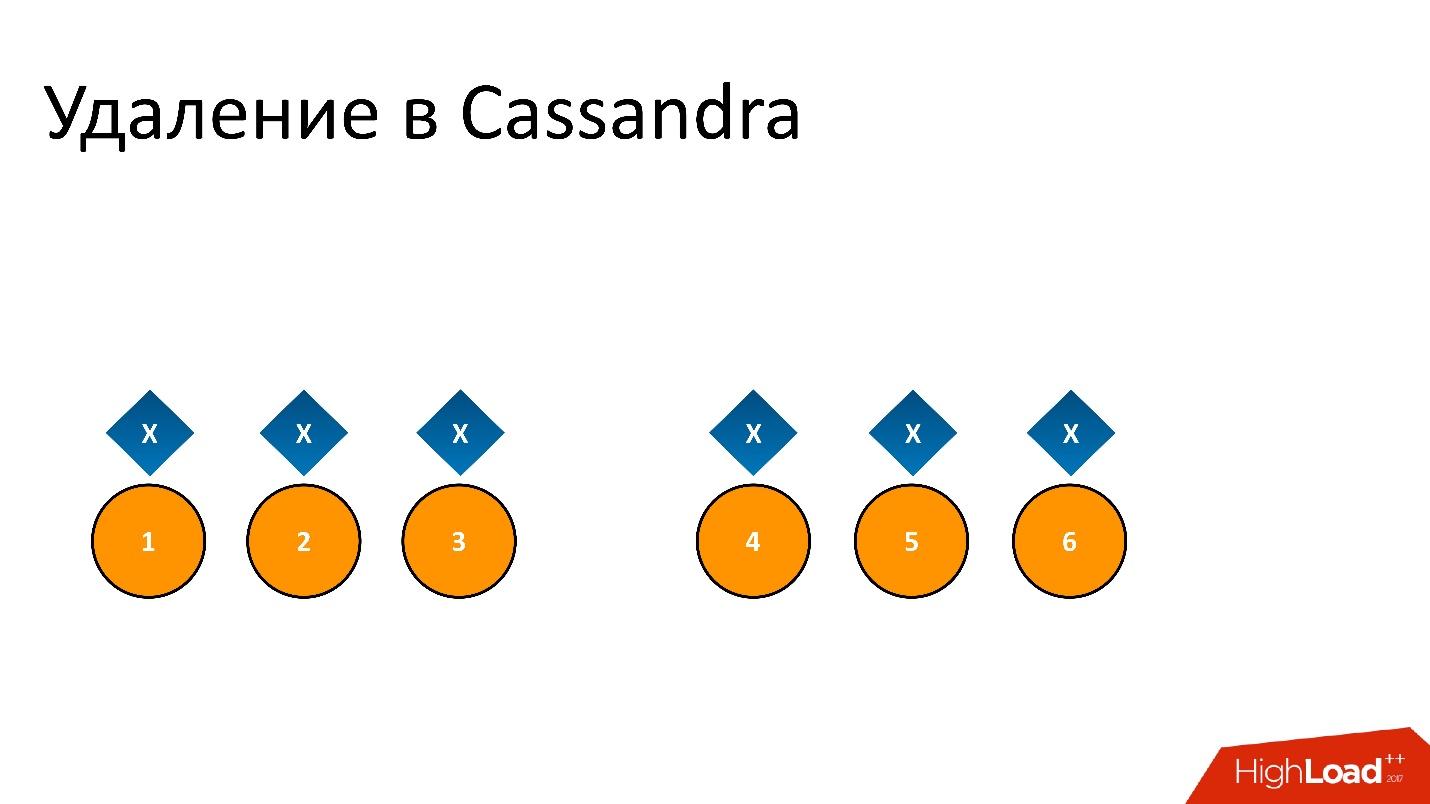
For example, we have some kind of data x , which is recorded and perfectly replicated to all 6 replicas. If we want to remove it, deletion, like any operation in Cassandra, may not be performed on all nodes.
For example, we wanted to guarantee the consistency of 2 of 3 in one DC. Let the delete operation be performed on five nodes, and one record remained, for example, because the node was unavailable at that moment.
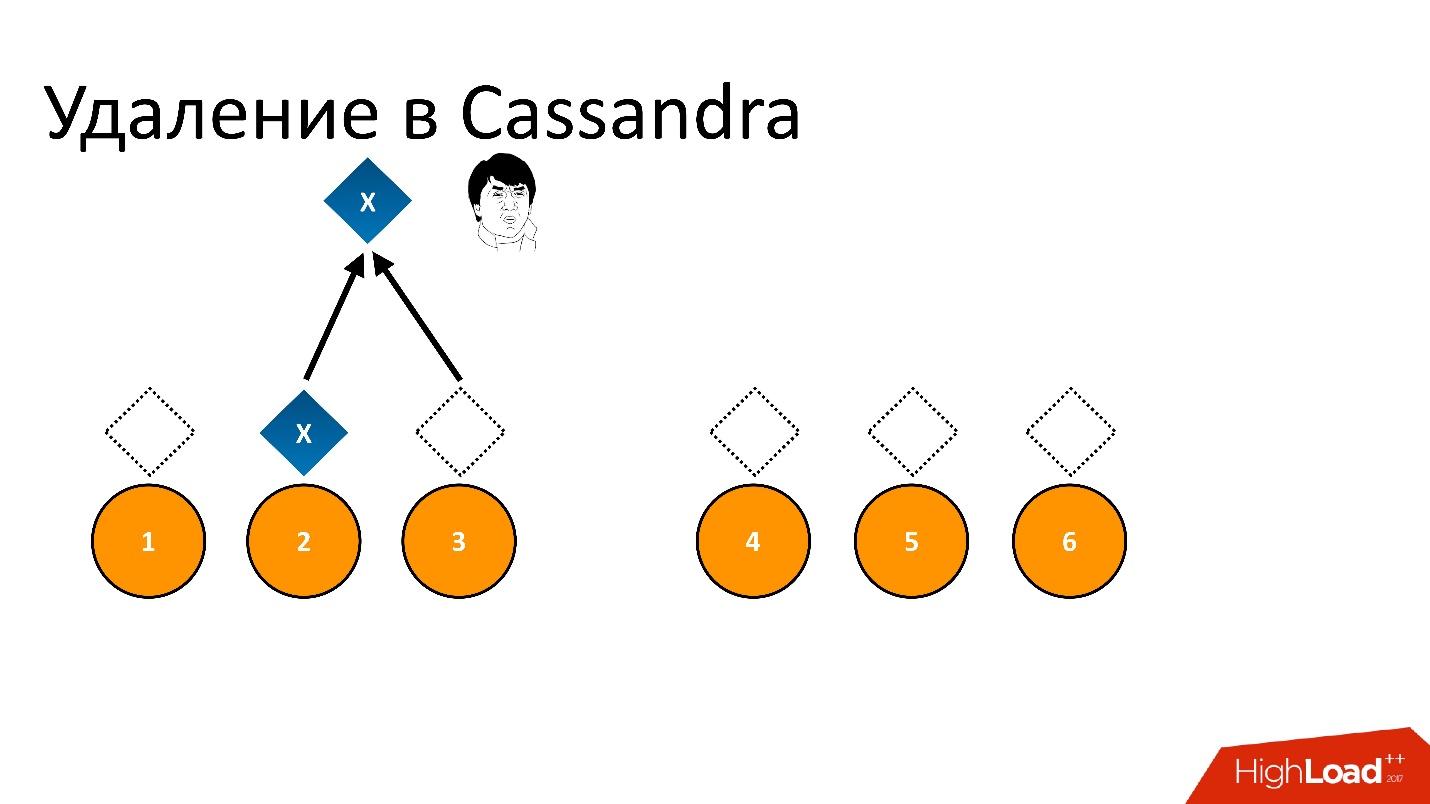
If we delete this way and then try to read “I want 2 of 3” with the same consistency, then Cassandra, seeing the value and its absence, interprets this as the availability of data. That is, when reading back, she will say: “Oh, there is data!”, Although we deleted them. Therefore, it cannot be deleted in this way.

Cassandra removes differently. Deletion is actually a record . When we delete data, Cassandra writes a small marker of a small size called Tombstone (tombstone). It marks that the data has been deleted. So, if we read both the deletion marker and the data at the same time, Cassandra always prefers the deletion marker in this situation and says that there really is no data. This is what you need.
Although Tombstone is a small markerit is clear that if we delete and delete data, we also need to delete these markers, otherwise they will accumulate endlessly. Therefore, Tombstone has some configurable lifetime. That is, Tombstone is removed in gc_grace_period seconds . When there is no marker, the situation is equivalent to the situation when there is no data.
What can happen?
Repair
Cassandra has a process called Repair (fix). His task - to make sure that all the replicas were synchronous. We may have different operations in the cluster, maybe not all the nodes have executed them, or we changed the cluster size, added / dropped replicas, maybe some node once fell, hard drives, etc. Replicas may not be consistent. Repair makes them consistent.

We deleted the data, somewhere there were deletion markers, somewhere the data itself remained. But we have not done Repair yet, and it is able, as in the picture above. Some time passed and the deletion markers disappeared - their lifespan just went out. Instead, they left an empty space, as if there is no data.

If after this you start Repair, which should bring the replicas to a consistent state, it will see that there is data on some nodes, there is no data on others - it means that they need to be restored. Accordingly, all 6 nodes will again be with data. These are the very Zombies - the data that we deleted, but which returned to the cluster.

Usually we don’t see them, if we don’t access them - perhaps these are some random keys. If nothing refers to it, we will not see it. But if we try to scan the entire database, trying to find something, as we were then looking for, how many records we have with deleted objects, these Zombies are very disturbing.
Decision
The solution is very simple, but rather important:
But there are different situations when we do not have time to do repair. It takes a very long time, because it is one of the most difficult operations for a cluster, which is related to comparing data on nodes.
The repair interval is the time for repair. For example, we know that we have time to repair this cluster in 10-20 days, a week, 3 days. But the period of Tombstone removal should be above this value, which is comprehended only from practice. If we repress too aggressively, it turns out that the cluster responds poorly to frontend queries.

Another classic problem for Cassandra that developers often come across. In fact, this is difficult to fight.
In S3 there is a bakt. As I said, it can be any size - 10 keys, 100 billion keys. One of the APIs we need to support is to give the list of keys in the bucket. Moreover, the list should be sorted, given, of course, page by page, it can be scrolled through, and it should always be consistent with current operations. That is, if I wrote down an object, deleted an object, take a list of keys - and it is the same as after my operation. I can not postpone it rebuilt.
How to implement such an API?

There is a table of objects that I showed earlier - bake, key, the current version - it seems to be exactly the one that is needed in order to build a list of keys. But there is a small problem. I absolutely correctly selected a pair of bucket - key for this table as a primary key. The primary key determines where this string will be located, on which node. This is the very thing why an object is hashed when it is stored in Cassandra. But at the same time it means that the keys of one bake are stored on different nodes - generally speaking, at all, if there are enough of them, because they are all evenly spread.
From the point of view of storing this table, this is cool, because my buckets can be completely different in size, and I cannot guess in advance how big and how small. If the data of one batch were stored on one node, then there would be a problem with scaling. But, on the other hand, I cannot in any way build a list of objects in a cluster from such a table. So, we need some other way by which this very list of objects could be obtained.
Cassandra says that she has more complex structures. You can create another table specifically for the list of keys in the bucket, which will store exactly the information you need, namely, the bucket, the key, and the minimum amount of metadata about the object in order to build a response to the query.
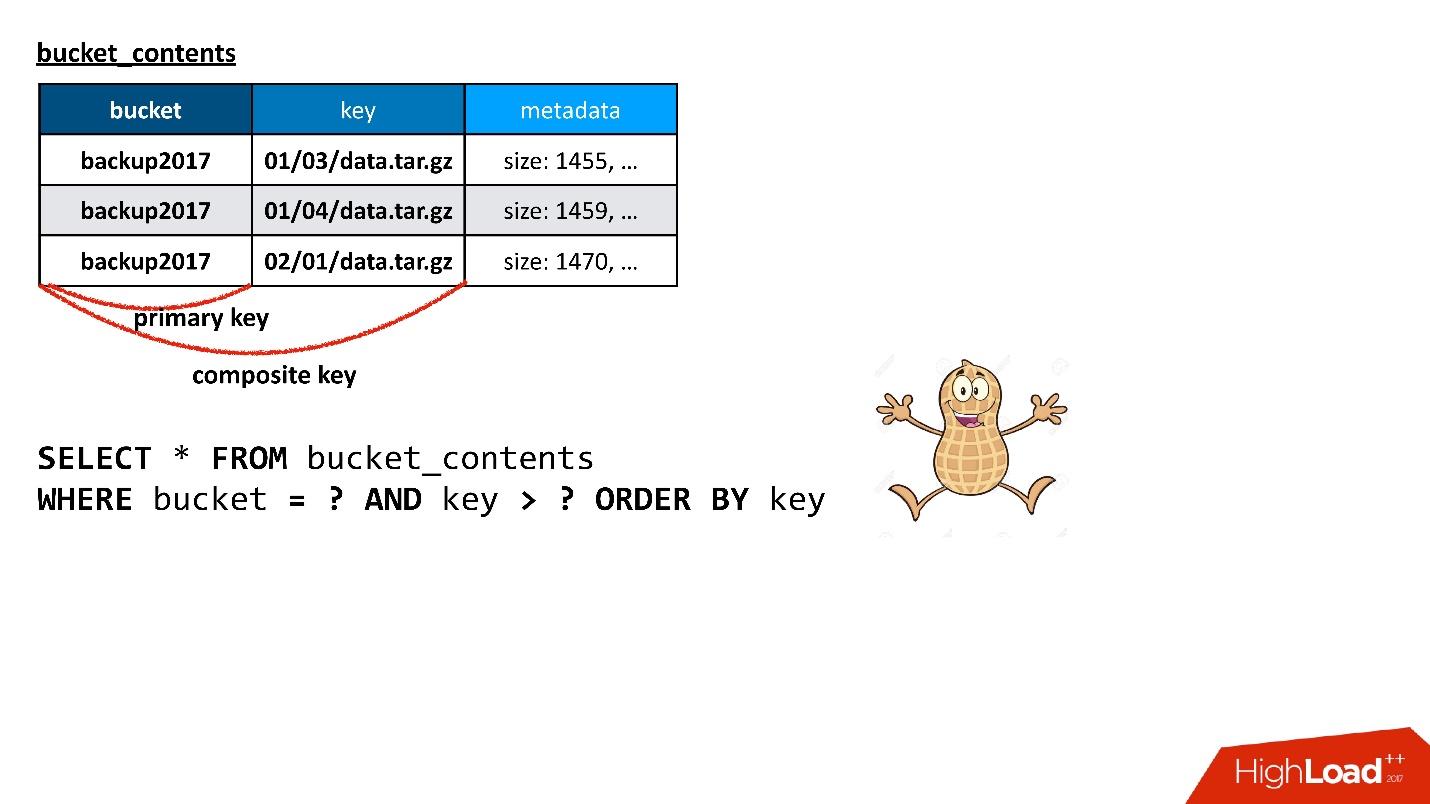
Here I use what's called a composite key in Cassandra . If I build a query to this table that I need - select data from the batch, starting with some key, and so that they are sorted - the query works. He does exactly what I need. Am i happy Yes, I'm glad of course, I did it all!
But if you carefully read what was said before, then remember that if the primary key is from the baketa, this means that all data is put on the same node.
In fact, the problem is worse. There is some schizophrenia in Cassandra, because different layers of Cassandra essentially speak different languages.. The layer with which we interact today most often represents Cassandra as something remotely similar to a relational database: with tables, with queries similar to SQL, etc. It seems to be all right!

But there is also an internal data layer. How does Cassandra really keep it? Historically, it was primary, and to it was its own, completely different API. This construction, which I described, is actually stored inside, as a long line, in which each key (in this situation, the key in the bucket) is a separate column. The larger the bucket size, the larger the columns in this table.
When I make a request, I don’t see it and can’t find out about it. If I try to climb a level or read how it works, yes, I can find out. This means that the width of such a line — the number of columns — is equal in my situation to the size of my baketa. This, by the way, works well because the columns at the physical level are stored sorted by name.
But in Cassandra there are a lot of operations in which it operates with the entire value of a string. Even if I ask: “Give me 100 keys”, and a million of them are stored there, depending on the version, in order to build an answer to my question, she has to literally read the entire line of a million, from there choose 100, and throw everything else away.
Imagine that this data is still distributed across several nodes (the same multiple replicas), and any request is not really a request to a specific replica, but in fact a request that tries to build a consistent representation across several nodes at the same time. If I have a million columns in one node, a million in another, a million in the third, formally in order to build an answer to a query, it is impossible to do something simple. If I ask for 100 keys that are greater than such a value, and all nodes match perfectly, it is simple. If the nodes do not quite coincide, then this query with a limit from the point of view of SQL becomes not trivial at all.
Cassandra is trying to extend such a broad line into memory, and when it does it, and it is written in Java, it becomes very bad. This design, calledLarge Partition , arises imperceptibly. So far there is little data - tens, hundreds, thousands, tens of thousands, even hundreds of thousands of keys - all is well. But then an exponential crash begins in terms of performance, nodes begin to fall, garbage collection fails, etc. The result is a cascade effect.
Plus, the wide string is replicated, and not only one node drops, but many at once , because they all have the same problem.
Of course, we immediately knew about this problem and thought that we need to do something in advance.

Therefore, in the table that is used for listing objects, we have foreseen the possibility of scattering the data of one baket across several columns. I will call them conditionally partitions. That is, partition the table so that we do not have a Large Partition.
We have two requirements:
When we started, we never figured out how to distribute the data, and always used 0 as the key_hash column. As always, features go ahead of any improvements that do not bring direct profit in terms of the product . Therefore, of course, we missed the moment when the partitions became large. We had some very fun months when we screwed the solution to a system that was almost in a state of agony.
Let's discuss how this could be done.

We immediately thought - well, we have a bake, he has a bunch of keys, let's run all the keys through some hash function and thus distribute them into partitions.
The first problem - how big should this hash be, what should N choose? If you choose too small, there will be a Large Partition, too large - too many partitions will be created. At the same time, we do not know anything about the size of the bake in advance. It may change: grow or shrink. Most importantly, if it is just hashing, then it turns out that the sort property is gone, and there will be some random keys in each partition. To get a sorted list, you must query all partitions and combine the results from them. Extremely inconvenient and inefficient, especially if there will be a lot of these partitions.

The second solution is quite obvious - since we wanted the sort property to be preserved, let's use some kind of key prefix. If we take some characters to the left, and the keys are well distributed across the buckets, then we can distribute the buckets by partitions. Each partition will be a prefix, each will have keys, and they will be sorted. If we know which keys we need, we know which partition to turn to, etc.
But here again the same problem arises - how to guess how the keys are named? We do not name the keys, but our clients. What do they call them? Someone calls them as a result of md5 hashing - this is ideally suited for such a scheme, and for someone the first 30 characters are a constant for all keys, or something else. We can not guess. This scheme would work well only if we knew what the key looks like.

As a result, we came to the scheme, when we dynamically guess, more precisely, we analyze how the keys are distributed. This distribution may change over time - the bucket may grow, the key structure may change. We adapt to this, and dynamically distribute them using a table. The table indicates that the keys for such and such are in such and such a partition, with such and such for such and such - in such. This is a conditional solution with a prefix, only the prefix is complex and dynamic. Yes, and not quite a prefix.
To make dynamic hashing, we had to tinker a lot, because there are a lot of interesting, quite scientific tasks.
We have some kind of baket state now, it is somehow divided into partitions. Then we understand that some partitions are too big or too small. We need to find a new partition, which, on the one hand, will be optimal, that is, the size of each partition will be less than some of our limits, and they will be more or less uniform. In this case, the transition from the current state to the new should require a minimum number of actions. It is clear that any transition requires the movement of keys between partitions, but the less we move them, the better.
We did it. Probably, the part that deals with the selection of distribution is the most difficult piece of the entire service, if we talk about working with metadata as a whole. We rewrote it, reworked it, and we are still doing it, because some customers or certain key creation patterns are always being discovered that beat the weak point of this scheme.
For example, we assumed that the bakt would grow more or less evenly. That is, we picked up some distribution, and hoped that all the partitions will grow according to this distribution. But we had a client who always writes to the end, in the sense that he always has the keys in a sorted order. He always hits the most recent partition, which is growing at such a rate that in a minute it can be 100 thousand keys. And 100 thousand is approximately the value that fits into one partition.
We simply would not have time to process such an addition of keys with our algorithm, and we had to introduce a special preliminary distribution for this client. Since we know what his keys look like, if we see that it is him, we simply start creating empty partitions at the end for him so that he can write there quietly, and we would rest for a while until the next iteration, when we again have to redistribute everything.
All this happens online in the sense that we do not stop the operation. There may be reads, writes, at any time you can request a list of keys. It will always be consistent, even if we are in the process of repartitioning.
This is quite interesting, and it works out with Cassandra. Here you can play with tricks related to the fact that Cassandra is able to resolve conflicts. If we in the same line recorded two different values, then wins the value, which has more timestamp.
Usually the timestamp is the current timestamp, but you can pass it manually. For example, we want to write a value in a string, which in any case must be ground, if the client writes something himself. That is, we copy some data, but we want the client, if suddenly he writes with us at the same time, to overwrite it. Then we can just copy our data from the timestamp a little bit from the past. Then any current recording will deliberately grind them, regardless of the order in which the recording was made.
Such tricks allow you to do it online.
If something similar to a large partition is planned in the data scheme, you should immediately try to do something about it - think of how to break it and how to get away from it. Sooner or later it arises, because any inverted index sooner or later arises in almost any task. I have already told you about this story - we have a bake key to the object, and we need to get a list of keys from the baket - in fact, this is an index.
Moreover, the partition can be large not only from the data, but also from the Tombstones (deletion markers). The deletion markers, in the same way from the point of view of Cassandra internals (we never see them from the outside) are data, and the partition can be large if it deletes a lot of things, because the deletion is a record. This is also not to be forgotten.

Another story that is actually constant — something goes wrong from beginning to end. For example, you see that the response time from Cassandra has grown, it responds slowly. How to understand and understand what the problem is? There is never an external signal that the problem is there.

For example, here is a graph - this is the average response time of the cluster as a whole. It shows that we have a problem - the maximum response time rested on 12 s - this is the internal timeout of Cassandra. This means that it time out by itself. If the timeout is longer than 12 seconds, it most likely means that the garbage collector is working, and Cassandra does not even have time to respond at the right time. It answers itself on timeout, but the response time to most requests, as I said, should be on average within 10 ms.
On the graph, the average has already exceeded hundreds of milliseconds - something went wrong. But looking at this picture, it is impossible to understand the reason.

But if the same statistics are deployed over the Cassandra nodes, then it is clear that in principle all the nodes are more or less nothing, but at one node the response time differs by orders of magnitude. Most likely, with him some kind of problem.
Statistics on nodes changes the image completely. This statistic is from the side of the app. But here too it is actually very often difficult to understand what the problem is. When an application accesses Cassandra, it accesses a node, using it as a coordinator. That is, the application gives a request, and the coordinator redirects it to the replicas with data. Those already answer, and the coordinator forms the final answer back.
But why does the coordinator respond slowly? Maybe the problem is with him, as with such, that is, he slows down and responds slowly? Or maybe he slows down, because replicas respond slowly to him? If the replicas respond slowly, from the point of view of the application it will look like a slow response from the coordinator, although he has nothing to do with it.
Here is a happy situation - it is clear that only one node responds slowly, and most likely the problem lies precisely in it.
It is always difficult to understand what is wrong. You just need a lot of statistics and monitoring , both from the application and Cassandra itself, because if she is really bad, from Cassandra can not see anything. You can also look at the level of individual queries, at the level of each specific table, on each specific node.
It may be, for example, a situation where one table of what is called in Cassandra SSTables (separate files) is too much. To read Cassandra, it is necessary, roughly speaking, to sort through all the SSTables. If there are too many of them, then simply the process of this sorting takes too much time, and the reading begins to subside.
The solution is compaction, which reduces the number of these SSTables, but it should be noted that it can only be on one node for one particular table. Since Cassandra is, unfortunately, written in Java and works on the JVM, it may be that the garbage collector has paused so much that it simply does not have time to respond. When the garbage collector pauses, not only do your queries slow down, but the interaction within the Cassandra cluster between the nodes begins to slow down . The nodes of each other begin to be considered dead, that is, fallen, dead.
An even more fun situation begins, because when a node considers that another node is down, it, firstly, does not send requests to it, secondly, it starts trying to save data that it would need to replicate to another node himself locally, so he starts killing himself, and so on.
There are situations where this problem can be solved simply by using the correct settings. For example, there may be enough resources, everything is fine and good, but just the Thread Pool, the number of which is of a fixed size, needs to be increased.
Finally, maybe we need to limit competition on the part of the driver. Sometimes it happens that too many competitive requests are sent, and like any database, Cassandra cannot cope with them and goes into the clinch when the response time grows exponentially, and we try to give more and more work.
There is always some kind of context for the problem - what is happening in the cluster, whether Repair now works, on which node, in which key spaces, in which table.
We, for example, had rather ridiculous problems with iron. We have seen that part of the nodes is slow. Later it turned out that the reason was that in the BIOS their processors were in power saving mode. For some reason, during the initial installation of iron, this happened, and approximately 50% of the CPU resources were used compared to other nodes.
To understand this problem can be difficult, in fact. The symptom is this - it seems that the node does compaction, but it does it slowly. Sometimes it is associated with iron, sometimes not, but this is just another Cassandra bug.
Therefore, monitoring is mandatory and it needs a lot. The more complex the feature in Cassandra, the farther it is from simple writing and reading, the more problems with it, and the faster it can kill the database with a sufficient number of queries. Therefore, if there is an opportunity, do not look at some "tasty" chips and try to use them, it is better to avoid them as far as possible. Not always possible - of course, sooner or later you have to.

The last story is about how Cassandra corrupted the data. In this situation, it happened inside Cassandra. It was interesting.
We saw that about dozens of broken lines appear in our database about once a week - they are literally littered with garbage. And Cassandra validates the data that comes to her at the entrance. For example, if it is a string, then it must be in utf8. But in these lines there was garbage, not utf8, and Cassandra did not even do anything with it. When I try to delete (or do something else), I cannot delete a value that is not utf8, because, in particular, I cannot enter in WHERE, because the key must be utf8.
Corrupt lines appear as a flash, at some point, and then they are not there again in a few days or weeks.
We started looking for a problem. We thought maybe there was a problem in a certain node with which we were busy, doing something with data, SSTables copied. Maybe, after all, this data can be seen their replicas? Maybe these replicas have a common node, the least common divisor? Maybe some node fails? No, nothing like that.
Maybe something with a disk? Is the data corrupted on the disk? Again, no.
Maybe a memory? Not! Scattered across the cluster.
Maybe this is some kind of replication problem? Did one node spoil everything and then replicate a bad value? - Not.
Finally, maybe this is an application problem?
And at some point the broken lines began to appear in two clusters of Cassandra. One worked on version 2.1, the second on the third. It seems that Cassandra is different, but the problem is the same. Maybe our service sends bad data? But it was hard to believe. Cassandra validates the input data, it could not write garbage. But suddenly?
Nothing fits.
We fought long and hard until we found a small problem: why do we have some crash dumps from the JVM on the nodes that we didn’t pay special attention to? And somehow suspiciously looks in the stack trace garbage collector ... And for some reason, some of the stack trace is also clogged with garbage.
In the end, we understood - oh, we somehow use the old 2015 version of JVM . This was the only common thing that united the Cassandra clusters on different versions of Cassandra.
I still don’t know what the problem was, because nothing is written about it in the official release notes of the JVM. But after the update everything disappeared, the problem no longer arose. Moreover, it appeared in the cluster not from the first day, but from a certain moment, although it worked on the same JVM for quite a long time.
What lesson we learned from this:
● Backup is useless.
The data, as we found out, was corrupted at the same second as they were recorded. At the moment when the data entered the coordinator, they were already corrupted.
● Partial restoration of intact speakers is possible.
Some columns were not damaged, we could read this data, partially restore it.
● In the end, we had to do a recovery from various sources.
We had backup metadata in the object, but in the data itself. To reconnect with the object, we used logs, etc.
● Logs - it's priceless!
We were able to recover all the data that was corrupted, but in the end it’s very hard to trust the database if it loses your data even without some kind of action on your part.
● Low quality of testing releases
When you start working with Cassandra, there is a constant feeling (especially if you switch, conditionally speaking, from “good” databases, for example, PostgreSQL), that if you fixed the previous bug in the release, you will definitely add a new . And the bug is not some nonsense, it is usually corrupted data or other incorrect behavior.
● Persistent problems with complex features.
The more complex the feature, the more problems with it, bugs, etc.
● Do not use incremental repair in 2.1
The famous repair I was talking about, which fixes the consistency of data, in standard mode, when it polls all nodes, works well. But not in the so-called incremental mode (when repair skips data that has not changed since the previous repair, which is quite logical). It was announced long ago, formally, as a feature exists, but everyone says: “No, in version 2.1, do not use it ever! He is sure to miss something. We will fix it in 3 ”
● But do not use incremental repair and in 3.x
When the third version came out, after a few days they said:“ No, you cannot use it in the 3rd version. There is a list of 15 bugs, so do not use incremental repair. In the 4th we will do better! ”
I do not believe them. And this is a big problem, especially with increasing cluster size. Therefore, you need to constantly monitor their bugtracker and watch what happens. Without this, unfortunately, it is impossible to live with them.
● Must follow JIRA


I wish you to find other rakes and attack them, because, from my point of view, in spite of everything, Сassandra is good and undoubtedly boring. Just remember the bumps on the road!
Under all these requirements only Cassandra fits, and nothing else fits. It should be noted, Cassandra is really cool, but working with it resembles a roller coaster.
In a report on Highload ++ 2017 Andrey Smirnov ( smira) I decided that it was not interesting to talk about good things, but I spoke in detail about every problem I had to face: data loss and data corruption, zombies and performance loss. These stories really resemble a roller coaster ride, but for all the problems there is a solution, for which you are welcome to the cat.
About the speaker: Andrey Smirnov works in the company Virtustream, implementing cloud storage for the enterprise. The idea is that conditionally, Amazon makes a cloud for everyone, and Virtustream does the specific things that a large company needs.
Couple of words about virtustream
We work in a completely remote small team, and we are working on one of the Virtustream cloud solutions. This is a cloud data storage.
Speaking very simply, it is an S3-compatible API in which you can store objects. For those who don’t know what S3 is, it’s just the HTTP API that allows you to upload objects to the cloud somewhere, get them back, delete them, get a list of objects, etc. Further - already more complex features based on these simple operations.
We have some distinctive features that Amazon doesn't have. One of them is the so-called geo-regions. In a typical situation, when you create a repository and say that you will be storing objects in the cloud, you must select a region. A region is essentially a data center, and your objects will never leave this data center. If something happens to it, then your objects will no longer be available.
We offer geo-regions in which data is located simultaneously in several data centers (DC), at least in two, as in the picture. The client can contact any data center, for him it is transparent. The data between them is replicated, that is, we are working in the “Active-Active” mode, and all the time. This provides the customer with additional features, including:
- high reliability of storage, reading and writing in case of DC failure or loss of connectivity;
- availability of data even if one of the DCs fails;
- redirection of operations to the “nearest” DC.
This is an interesting opportunity - even if these DCs are far from each other geographically, then one of them may be closer to the client at different points in time. And access the data in the nearest DC just faster.
In order for the construction that we will talk about to be divided into parts, I will present those objects that are stored in the cloud as two large pieces:
1. The first simple piece of an object is data . They are the same, they were downloaded once and that's it. The only thing that can happen to them later is that we can remove them if they are no longer needed.
The previous project was related to the storage of the data exabyte, so we did not have any problems with data storage. This for us was already a solved task.
2. Metadata. All business logic, all the most interesting, related to competitiveness: circulation, writing, rewriting - in the area of metadata.
Metadata about the object takes away the greatest complexity of the project, the metadata stores a pointer to the block of the saved data of the object.
From the user's point of view, this is a single object, but we can divide it into two parts. Today I will only talk about metadata .
Numbers
- Data : 4 PB.
- Metadata clusters : 3.
- Objects : 40 billion.
- The volume of metadata : 160 TB (including replication).
- Rate of change (metadata): 3000 objects / s.
If you look at these indicators carefully, the first thing that catches your eye is the very small average size of the stored object. We have a lot of metadata per unit volume of basic data. For us it was no less surprise than perhaps for you now.
We planned that we would have at least an order of magnitude, if not 2, more than metadata. That is, each object will be much larger, and the volume of metadata will be less. Because data is cheaper to store, there are fewer operations with them, and metadata is much more expensive both in terms of hardware and in terms of maintaining and performing various operations on them.
At the same time, these data change with a fairly high speed. I gave here the peak value, non-peak is not much less, but, nevertheless, quite a large load can be obtained at specific points in time.
These figures were obtained from the operating system, but let's go back a bit, by the time the cloud storage is designed.
Metadata storage selection
When we faced the challenge that we want to have geo-regions, Active-Active, and we need to store metadata somewhere, we thought, what could it be?
Obviously, the storage (database) must have the following properties:
- Active-Active support ;
- Scalable.
We would very much like our product to be wildly popular, and we don’t know how it will grow in this case, so the system must scale.
- Balance failover and reliability of storage.
Metadata must be stored securely, because if we lose them, and there is a link to the data, we will lose the entire object.
- Configurable consistency of operations.
Due to the fact that we work in several DCs and admit the possibility that DCs may be unavailable, moreover, DCs are far from each other, we cannot during the execution of most operations through the API require that this operation be performed simultaneously in two DCs. It will be just too slow and impossible if the second DC is unavailable. Therefore, part of the operations should work locally in one DC.
But, obviously, some convergence should take place once, and after all conflicts have been resolved, the data should be visible in both data centers. Therefore, the consistency of operations must be adjusted.
From my point of view, Cassandra fits these requirements.
Cassandra
I would be very happy if we did not have to use Cassandra, because for us it was a kind of new experience. But nothing else fits. It seems to me that the saddest situation on the market for such storage systems is that there is no alternative .
What is Cassandra?
This is a distributed key-value database. From the point of view of architecture and the ideas that are embedded in it, it seems to me, everything is cool. If I did, I would do the same. When we first started, we thought about writing our own metadata storage system. But the further, the more and more we understood that we would have to do something very similar to Cassandra, and the efforts that we will spend on it are not worth it. For the whole development we had only one and a half months . It would be strange to spend them on writing your database.
If Cassandra is divided into layers, like a layer cake, I would select 3 layers:
1. Local KV storage on each node.
This is a cluster of nodes, each of which is able to store key-value data locally.
2Sharding data on nodes (consistent hashing).
Cassandra is able to distribute data across cluster nodes, including replication, and does this in such a way that the cluster can grow or shrink in size, and the data will be redistributed.
3. Coordinator for redirecting requests to other nodes.
When we access data from any application from our application, Cassandra can distribute our request among nodes so that we get the data we want and with the level of consistency that we need - we want to read them just quorum, or we want quorum with two DCs, etc.
For us, two years with Cassandra are roller coasters or Russian as you wish to call. It all started deep down, we had zero experience with Cassandra. We were scared. We started and everything was fine. But then there are constant ups and downs: the problem, everything is bad, we don’t know what to do, we have mistakes, then we solve the problem, etc.
These roller coasters, in principle, do not end to this day.
Good
The first and last chapter, where I will say that Cassandra is cool. It is really cool, a great system, but if I continue to say how good it is, I think you will not be interested. Therefore, the bad pay more attention, but later.
Cassandra is really good.
- This is one of the systems that allows us to have a response time in milliseconds , that is, obviously less than 10 ms. This is good for us because the response time in general is important for us. The metadata operation for us is only a part of any operation related to the storage of an object, be it a receipt or a record.
- From a recording point of view, high scalability is achieved . In Cassandra, you can write with a crazy speed, and in some situations this is necessary, for example, when we move large amounts of data between records.
- Cassandra is really fault tolerant . The fall of a single node does not lead to problems at the same second, although sooner or later they will begin. Cassandra declares that there is no single point of failure in it, but, in fact, there are points of failure everywhere. In fact, the one who worked with the database, knows that even the fall of a node is not something that usually suffers until the morning. Usually, this situation needs to be fixed faster.
- Simplicity. Still, compared to other standard relational databases, Cassandra is easier to understand what is happening. Very often something goes wrong, and we need to understand what is happening. With Cassandra, there are more chances to figure out how to get to the smallest screw, probably, than from another database.
Five stories about bad
Again, Cassandra is good, it works for us, but I will tell five stories about the bad. I think this is what you read it for. I will cite stories in chronological order, although they are not very connected with each other.
This story was the saddest for us. Since we store user data, the worst possible thing is to lose them, and lose them irretrievably , as happened in this situation. We had ways to recover data if we lost it in Cassandra, but we lost it so that we really could not recover it.
In order to explain how this happens, I have a little bit to tell you about how everything is arranged inside us.
From an S3 point of view, there are a few basic things:
- Bucket - it can be thought of as a huge directory into which the user uploads an object (hereinafter referred to as bakt)
- Each object has a name (key) and associated metadata: size, content type, and a pointer to the object data. At the same time, the size of the bucket is unlimited. That is, it may be 10 keys, maybe 100 billion keys - there is no difference.
- Any competitive operations are possible, that is, there may be several competitive fills in the same key, there may be competitive deletion, etc.
In our situation, active-active, operations can occur, including competitive in different DC, not only in one. Therefore, we need some kind of preservation scheme that will allow to implement this logic. In the end, we chose a simple policy: the latest recorded version wins. Sometimes there are several competitive operations, but it is not necessary that our customers specifically do this. It may just be a request that started, but the client did not wait for an answer, something else happened, tried again, etc.
Therefore, we have two base tables:
- Table objects . In it, the pair — the name of the bucket and the name of the key — is associated with its current version. If the object is deleted, there is nothing in this version. If the object exists, there is its current version. In fact, in this table we only change the field of the current version.
- Object version table . In this table we just insert new versions. Every time a new object is loaded, we insert a new version into the version table, give it a unique number, save all the information about it, and at the end update the link to it in the object table.
The figure is an example of how object tables and object versions are related.
Here there is an object that has two versions - one current and one old, there is an object that has already been deleted, and its version is still there. We need to clean up unnecessary versions from time to time, that is, to delete something that nobody already refers to. And we don’t need to delete immediately, we can do it in the deferred mode. This is our internal cleaning, we simply remove what is no longer needed.
There was a problem.
The problem was this: we have an active-active, two DCs. In each DC, the metadata is stored in three copies, that is, we have 3 + 3 - only 6 replicas. When clients turn to us, we perform operations with consistency (from the point of view of Cassandra is called LOCAL_QUORUM). That is, it is guaranteed that the write (or read) occurred in 2 replicas in the local DC. This is a guarantee - otherwise the operation will fail.
Cassandra will always try to write in all 6 replicas - 99% of the time everything will be fine. In fact, all 6 replicas will be the same, but guaranteed to us 2.
We had a difficult situation, although it was not even a geo-region. Even for ordinary regions, which are in one DC, we still kept a second copy of the metadata in another DC. This is a long story, I will not give all the details. But ultimately we had a cleaning process that removed unnecessary versions.
And then that problem arose. The cleaning process also worked with the consistency of the local quorum in one data center, because there is no two ways to run it - they will fight with each other.
Everything was good, until it turned out that our users still sometimes write to another data center, which we did not suspect. Everything was set up just in case for a faylover, but it turned out that they were already using it.
Most of the time, everything was fine, until one day a situation arose when a record in the version table was replicated in both DCs, but the entry in the table of objects was only in one DC, and the second did not hit. Accordingly, the cleaning procedure launched in the first (upper) DC, saw that there is a version to which no one refers, and deleted it. Moreover, it deleted not only the version, but, of course, the data - all completely, because it is just an unnecessary object. And this removal is irrevocable.
Of course, the “boom” happens further, because we have a record in the object table that refers to a version that no longer exists.
So the first time we lost the data, and lost them really irrevocably - the good, a little.
Decision
What to do? In our situation, everything is simple.
Since our data is stored in two business centers, the cleaning process is a process of some kind of convergence and synchronization. We must read the data from both DCs. This process will work only when both DCs are available. Since I said that this is a delayed process that does not occur during the processing of the API, it is not a problem.
ALL consistency is a feature of Cassandra 2. In Cassandra 3, everything is slightly better — there is a level of consistency, which is called quorum in each DC. But in any case, there is the problem of the fact that it is slow , because, first, we have to contact a remote DC. Secondly, in the case of the consistency of all 6 nodes, this means that it operates at the speed of the worst of these 6 nodes.
But at the same time there is a process of the so-called read-repair , when not all replicas are synchronous. That is, when somewhere the recording failed, this process repairs them at the same time. That's the way Cassandra is.
When this happened, we received a complaint from the client that the object was unavailable. We figured out, understood why, and the first thing we wanted to do was find out how many such objects we still have. We ran a script that tried to find a construct similar to this one when there is a record in one table, but there is no record in another.
Suddenly, we discovered that we have 10% of such records . Nothing worse, probably, could not be, if we had not guessed that this was not the case. The problem was different.
Zombies sneaked into our database. This is the semi-official title of the problem. In order to understand what it is, you need to talk about how the removal works in Cassandra.
For example, we have some kind of data x , which is recorded and perfectly replicated to all 6 replicas. If we want to remove it, deletion, like any operation in Cassandra, may not be performed on all nodes.
For example, we wanted to guarantee the consistency of 2 of 3 in one DC. Let the delete operation be performed on five nodes, and one record remained, for example, because the node was unavailable at that moment.
If we delete this way and then try to read “I want 2 of 3” with the same consistency, then Cassandra, seeing the value and its absence, interprets this as the availability of data. That is, when reading back, she will say: “Oh, there is data!”, Although we deleted them. Therefore, it cannot be deleted in this way.
Cassandra removes differently. Deletion is actually a record . When we delete data, Cassandra writes a small marker of a small size called Tombstone (tombstone). It marks that the data has been deleted. So, if we read both the deletion marker and the data at the same time, Cassandra always prefers the deletion marker in this situation and says that there really is no data. This is what you need.
Although Tombstone is a small markerit is clear that if we delete and delete data, we also need to delete these markers, otherwise they will accumulate endlessly. Therefore, Tombstone has some configurable lifetime. That is, Tombstone is removed in gc_grace_period seconds . When there is no marker, the situation is equivalent to the situation when there is no data.
What can happen?
Repair
Cassandra has a process called Repair (fix). His task - to make sure that all the replicas were synchronous. We may have different operations in the cluster, maybe not all the nodes have executed them, or we changed the cluster size, added / dropped replicas, maybe some node once fell, hard drives, etc. Replicas may not be consistent. Repair makes them consistent.
We deleted the data, somewhere there were deletion markers, somewhere the data itself remained. But we have not done Repair yet, and it is able, as in the picture above. Some time passed and the deletion markers disappeared - their lifespan just went out. Instead, they left an empty space, as if there is no data.
If after this you start Repair, which should bring the replicas to a consistent state, it will see that there is data on some nodes, there is no data on others - it means that they need to be restored. Accordingly, all 6 nodes will again be with data. These are the very Zombies - the data that we deleted, but which returned to the cluster.
Usually we don’t see them, if we don’t access them - perhaps these are some random keys. If nothing refers to it, we will not see it. But if we try to scan the entire database, trying to find something, as we were then looking for, how many records we have with deleted objects, these Zombies are very disturbing.
Decision
The solution is very simple, but rather important:
- Repair in a cluster needs to be done anyway .
But there are different situations when we do not have time to do repair. It takes a very long time, because it is one of the most difficult operations for a cluster, which is related to comparing data on nodes.
- But in any case, the period after which the Tombstones are removed must be longer than the repair interval.
The repair interval is the time for repair. For example, we know that we have time to repair this cluster in 10-20 days, a week, 3 days. But the period of Tombstone removal should be above this value, which is comprehended only from practice. If we repress too aggressively, it turns out that the cluster responds poorly to frontend queries.
Another classic problem for Cassandra that developers often come across. In fact, this is difficult to fight.
In S3 there is a bakt. As I said, it can be any size - 10 keys, 100 billion keys. One of the APIs we need to support is to give the list of keys in the bucket. Moreover, the list should be sorted, given, of course, page by page, it can be scrolled through, and it should always be consistent with current operations. That is, if I wrote down an object, deleted an object, take a list of keys - and it is the same as after my operation. I can not postpone it rebuilt.
How to implement such an API?
There is a table of objects that I showed earlier - bake, key, the current version - it seems to be exactly the one that is needed in order to build a list of keys. But there is a small problem. I absolutely correctly selected a pair of bucket - key for this table as a primary key. The primary key determines where this string will be located, on which node. This is the very thing why an object is hashed when it is stored in Cassandra. But at the same time it means that the keys of one bake are stored on different nodes - generally speaking, at all, if there are enough of them, because they are all evenly spread.
From the point of view of storing this table, this is cool, because my buckets can be completely different in size, and I cannot guess in advance how big and how small. If the data of one batch were stored on one node, then there would be a problem with scaling. But, on the other hand, I cannot in any way build a list of objects in a cluster from such a table. So, we need some other way by which this very list of objects could be obtained.
Cassandra says that she has more complex structures. You can create another table specifically for the list of keys in the bucket, which will store exactly the information you need, namely, the bucket, the key, and the minimum amount of metadata about the object in order to build a response to the query.
Here I use what's called a composite key in Cassandra . If I build a query to this table that I need - select data from the batch, starting with some key, and so that they are sorted - the query works. He does exactly what I need. Am i happy Yes, I'm glad of course, I did it all!
But if you carefully read what was said before, then remember that if the primary key is from the baketa, this means that all data is put on the same node.
In fact, the problem is worse. There is some schizophrenia in Cassandra, because different layers of Cassandra essentially speak different languages.. The layer with which we interact today most often represents Cassandra as something remotely similar to a relational database: with tables, with queries similar to SQL, etc. It seems to be all right!
But there is also an internal data layer. How does Cassandra really keep it? Historically, it was primary, and to it was its own, completely different API. This construction, which I described, is actually stored inside, as a long line, in which each key (in this situation, the key in the bucket) is a separate column. The larger the bucket size, the larger the columns in this table.
When I make a request, I don’t see it and can’t find out about it. If I try to climb a level or read how it works, yes, I can find out. This means that the width of such a line — the number of columns — is equal in my situation to the size of my baketa. This, by the way, works well because the columns at the physical level are stored sorted by name.
But in Cassandra there are a lot of operations in which it operates with the entire value of a string. Even if I ask: “Give me 100 keys”, and a million of them are stored there, depending on the version, in order to build an answer to my question, she has to literally read the entire line of a million, from there choose 100, and throw everything else away.
Imagine that this data is still distributed across several nodes (the same multiple replicas), and any request is not really a request to a specific replica, but in fact a request that tries to build a consistent representation across several nodes at the same time. If I have a million columns in one node, a million in another, a million in the third, formally in order to build an answer to a query, it is impossible to do something simple. If I ask for 100 keys that are greater than such a value, and all nodes match perfectly, it is simple. If the nodes do not quite coincide, then this query with a limit from the point of view of SQL becomes not trivial at all.
Cassandra is trying to extend such a broad line into memory, and when it does it, and it is written in Java, it becomes very bad. This design, calledLarge Partition , arises imperceptibly. So far there is little data - tens, hundreds, thousands, tens of thousands, even hundreds of thousands of keys - all is well. But then an exponential crash begins in terms of performance, nodes begin to fall, garbage collection fails, etc. The result is a cascade effect.
Plus, the wide string is replicated, and not only one node drops, but many at once , because they all have the same problem.
Of course, we immediately knew about this problem and thought that we need to do something in advance.
Therefore, in the table that is used for listing objects, we have foreseen the possibility of scattering the data of one baket across several columns. I will call them conditionally partitions. That is, partition the table so that we do not have a Large Partition.
We have two requirements:
- so that each partition is limited in size (no more than some keys);
- even though we distribute the data, we want to get a sorted list of keys quickly. It was our initial task, for the sake of it everything was started.
When we started, we never figured out how to distribute the data, and always used 0 as the key_hash column. As always, features go ahead of any improvements that do not bring direct profit in terms of the product . Therefore, of course, we missed the moment when the partitions became large. We had some very fun months when we screwed the solution to a system that was almost in a state of agony.
Let's discuss how this could be done.
We immediately thought - well, we have a bake, he has a bunch of keys, let's run all the keys through some hash function and thus distribute them into partitions.
The first problem - how big should this hash be, what should N choose? If you choose too small, there will be a Large Partition, too large - too many partitions will be created. At the same time, we do not know anything about the size of the bake in advance. It may change: grow or shrink. Most importantly, if it is just hashing, then it turns out that the sort property is gone, and there will be some random keys in each partition. To get a sorted list, you must query all partitions and combine the results from them. Extremely inconvenient and inefficient, especially if there will be a lot of these partitions.
The second solution is quite obvious - since we wanted the sort property to be preserved, let's use some kind of key prefix. If we take some characters to the left, and the keys are well distributed across the buckets, then we can distribute the buckets by partitions. Each partition will be a prefix, each will have keys, and they will be sorted. If we know which keys we need, we know which partition to turn to, etc.
But here again the same problem arises - how to guess how the keys are named? We do not name the keys, but our clients. What do they call them? Someone calls them as a result of md5 hashing - this is ideally suited for such a scheme, and for someone the first 30 characters are a constant for all keys, or something else. We can not guess. This scheme would work well only if we knew what the key looks like.
As a result, we came to the scheme, when we dynamically guess, more precisely, we analyze how the keys are distributed. This distribution may change over time - the bucket may grow, the key structure may change. We adapt to this, and dynamically distribute them using a table. The table indicates that the keys for such and such are in such and such a partition, with such and such for such and such - in such. This is a conditional solution with a prefix, only the prefix is complex and dynamic. Yes, and not quite a prefix.
Dynamic hash
To make dynamic hashing, we had to tinker a lot, because there are a lot of interesting, quite scientific tasks.
- Dynamic distribution table.
- Genetic algorithm for finding the perfect distribution and perfect redistribution.
- Counting the size of a patrician outside of Cassandra.
- Online redistribution (without stopping operations and loss of consistency).
We have some kind of baket state now, it is somehow divided into partitions. Then we understand that some partitions are too big or too small. We need to find a new partition, which, on the one hand, will be optimal, that is, the size of each partition will be less than some of our limits, and they will be more or less uniform. In this case, the transition from the current state to the new should require a minimum number of actions. It is clear that any transition requires the movement of keys between partitions, but the less we move them, the better.
We did it. Probably, the part that deals with the selection of distribution is the most difficult piece of the entire service, if we talk about working with metadata as a whole. We rewrote it, reworked it, and we are still doing it, because some customers or certain key creation patterns are always being discovered that beat the weak point of this scheme.
For example, we assumed that the bakt would grow more or less evenly. That is, we picked up some distribution, and hoped that all the partitions will grow according to this distribution. But we had a client who always writes to the end, in the sense that he always has the keys in a sorted order. He always hits the most recent partition, which is growing at such a rate that in a minute it can be 100 thousand keys. And 100 thousand is approximately the value that fits into one partition.
We simply would not have time to process such an addition of keys with our algorithm, and we had to introduce a special preliminary distribution for this client. Since we know what his keys look like, if we see that it is him, we simply start creating empty partitions at the end for him so that he can write there quietly, and we would rest for a while until the next iteration, when we again have to redistribute everything.
All this happens online in the sense that we do not stop the operation. There may be reads, writes, at any time you can request a list of keys. It will always be consistent, even if we are in the process of repartitioning.
This is quite interesting, and it works out with Cassandra. Here you can play with tricks related to the fact that Cassandra is able to resolve conflicts. If we in the same line recorded two different values, then wins the value, which has more timestamp.
Usually the timestamp is the current timestamp, but you can pass it manually. For example, we want to write a value in a string, which in any case must be ground, if the client writes something himself. That is, we copy some data, but we want the client, if suddenly he writes with us at the same time, to overwrite it. Then we can just copy our data from the timestamp a little bit from the past. Then any current recording will deliberately grind them, regardless of the order in which the recording was made.
Such tricks allow you to do it online.
Decision
- Never, never allow a large partition .
- Split the data by primary key depending on the task.
If something similar to a large partition is planned in the data scheme, you should immediately try to do something about it - think of how to break it and how to get away from it. Sooner or later it arises, because any inverted index sooner or later arises in almost any task. I have already told you about this story - we have a bake key to the object, and we need to get a list of keys from the baket - in fact, this is an index.
Moreover, the partition can be large not only from the data, but also from the Tombstones (deletion markers). The deletion markers, in the same way from the point of view of Cassandra internals (we never see them from the outside) are data, and the partition can be large if it deletes a lot of things, because the deletion is a record. This is also not to be forgotten.
Another story that is actually constant — something goes wrong from beginning to end. For example, you see that the response time from Cassandra has grown, it responds slowly. How to understand and understand what the problem is? There is never an external signal that the problem is there.
For example, here is a graph - this is the average response time of the cluster as a whole. It shows that we have a problem - the maximum response time rested on 12 s - this is the internal timeout of Cassandra. This means that it time out by itself. If the timeout is longer than 12 seconds, it most likely means that the garbage collector is working, and Cassandra does not even have time to respond at the right time. It answers itself on timeout, but the response time to most requests, as I said, should be on average within 10 ms.
On the graph, the average has already exceeded hundreds of milliseconds - something went wrong. But looking at this picture, it is impossible to understand the reason.
But if the same statistics are deployed over the Cassandra nodes, then it is clear that in principle all the nodes are more or less nothing, but at one node the response time differs by orders of magnitude. Most likely, with him some kind of problem.
Statistics on nodes changes the image completely. This statistic is from the side of the app. But here too it is actually very often difficult to understand what the problem is. When an application accesses Cassandra, it accesses a node, using it as a coordinator. That is, the application gives a request, and the coordinator redirects it to the replicas with data. Those already answer, and the coordinator forms the final answer back.
But why does the coordinator respond slowly? Maybe the problem is with him, as with such, that is, he slows down and responds slowly? Or maybe he slows down, because replicas respond slowly to him? If the replicas respond slowly, from the point of view of the application it will look like a slow response from the coordinator, although he has nothing to do with it.
Here is a happy situation - it is clear that only one node responds slowly, and most likely the problem lies precisely in it.
Difficulty interpreting
- The response time of the coordinator (the node itself vs. the replicas).
- Specific table or entire node?
- GC Pause? Not enough thread pool?
- Too many uncompacted sstables?
It is always difficult to understand what is wrong. You just need a lot of statistics and monitoring , both from the application and Cassandra itself, because if she is really bad, from Cassandra can not see anything. You can also look at the level of individual queries, at the level of each specific table, on each specific node.
It may be, for example, a situation where one table of what is called in Cassandra SSTables (separate files) is too much. To read Cassandra, it is necessary, roughly speaking, to sort through all the SSTables. If there are too many of them, then simply the process of this sorting takes too much time, and the reading begins to subside.
The solution is compaction, which reduces the number of these SSTables, but it should be noted that it can only be on one node for one particular table. Since Cassandra is, unfortunately, written in Java and works on the JVM, it may be that the garbage collector has paused so much that it simply does not have time to respond. When the garbage collector pauses, not only do your queries slow down, but the interaction within the Cassandra cluster between the nodes begins to slow down . The nodes of each other begin to be considered dead, that is, fallen, dead.
An even more fun situation begins, because when a node considers that another node is down, it, firstly, does not send requests to it, secondly, it starts trying to save data that it would need to replicate to another node himself locally, so he starts killing himself, and so on.
There are situations where this problem can be solved simply by using the correct settings. For example, there may be enough resources, everything is fine and good, but just the Thread Pool, the number of which is of a fixed size, needs to be increased.
Finally, maybe we need to limit competition on the part of the driver. Sometimes it happens that too many competitive requests are sent, and like any database, Cassandra cannot cope with them and goes into the clinch when the response time grows exponentially, and we try to give more and more work.
Understanding the context
There is always some kind of context for the problem - what is happening in the cluster, whether Repair now works, on which node, in which key spaces, in which table.
We, for example, had rather ridiculous problems with iron. We have seen that part of the nodes is slow. Later it turned out that the reason was that in the BIOS their processors were in power saving mode. For some reason, during the initial installation of iron, this happened, and approximately 50% of the CPU resources were used compared to other nodes.
To understand this problem can be difficult, in fact. The symptom is this - it seems that the node does compaction, but it does it slowly. Sometimes it is associated with iron, sometimes not, but this is just another Cassandra bug.
Therefore, monitoring is mandatory and it needs a lot. The more complex the feature in Cassandra, the farther it is from simple writing and reading, the more problems with it, and the faster it can kill the database with a sufficient number of queries. Therefore, if there is an opportunity, do not look at some "tasty" chips and try to use them, it is better to avoid them as far as possible. Not always possible - of course, sooner or later you have to.
The last story is about how Cassandra corrupted the data. In this situation, it happened inside Cassandra. It was interesting.
We saw that about dozens of broken lines appear in our database about once a week - they are literally littered with garbage. And Cassandra validates the data that comes to her at the entrance. For example, if it is a string, then it must be in utf8. But in these lines there was garbage, not utf8, and Cassandra did not even do anything with it. When I try to delete (or do something else), I cannot delete a value that is not utf8, because, in particular, I cannot enter in WHERE, because the key must be utf8.
Corrupt lines appear as a flash, at some point, and then they are not there again in a few days or weeks.
We started looking for a problem. We thought maybe there was a problem in a certain node with which we were busy, doing something with data, SSTables copied. Maybe, after all, this data can be seen their replicas? Maybe these replicas have a common node, the least common divisor? Maybe some node fails? No, nothing like that.
Maybe something with a disk? Is the data corrupted on the disk? Again, no.
Maybe a memory? Not! Scattered across the cluster.
Maybe this is some kind of replication problem? Did one node spoil everything and then replicate a bad value? - Not.
Finally, maybe this is an application problem?
And at some point the broken lines began to appear in two clusters of Cassandra. One worked on version 2.1, the second on the third. It seems that Cassandra is different, but the problem is the same. Maybe our service sends bad data? But it was hard to believe. Cassandra validates the input data, it could not write garbage. But suddenly?
Nothing fits.
Needle found!
We fought long and hard until we found a small problem: why do we have some crash dumps from the JVM on the nodes that we didn’t pay special attention to? And somehow suspiciously looks in the stack trace garbage collector ... And for some reason, some of the stack trace is also clogged with garbage.
In the end, we understood - oh, we somehow use the old 2015 version of JVM . This was the only common thing that united the Cassandra clusters on different versions of Cassandra.
I still don’t know what the problem was, because nothing is written about it in the official release notes of the JVM. But after the update everything disappeared, the problem no longer arose. Moreover, it appeared in the cluster not from the first day, but from a certain moment, although it worked on the same JVM for quite a long time.
Data recovery
What lesson we learned from this:
● Backup is useless.
The data, as we found out, was corrupted at the same second as they were recorded. At the moment when the data entered the coordinator, they were already corrupted.
● Partial restoration of intact speakers is possible.
Some columns were not damaged, we could read this data, partially restore it.
● In the end, we had to do a recovery from various sources.
We had backup metadata in the object, but in the data itself. To reconnect with the object, we used logs, etc.
● Logs - it's priceless!
We were able to recover all the data that was corrupted, but in the end it’s very hard to trust the database if it loses your data even without some kind of action on your part.
Decision
- Update your JVM after a long test.
- Monitoring JVM crash.
- Have a copy of the data independent of Cassandra.
As a tip: Try to have some kind of Cassandra-independent copy of the data from which you can recover if necessary. This may be the last level solution. Let it take a lot of time, resources, but that was some option that will allow you to return the data.
Bugs
● Low quality of testing releases
When you start working with Cassandra, there is a constant feeling (especially if you switch, conditionally speaking, from “good” databases, for example, PostgreSQL), that if you fixed the previous bug in the release, you will definitely add a new . And the bug is not some nonsense, it is usually corrupted data or other incorrect behavior.
● Persistent problems with complex features.
The more complex the feature, the more problems with it, bugs, etc.
● Do not use incremental repair in 2.1
The famous repair I was talking about, which fixes the consistency of data, in standard mode, when it polls all nodes, works well. But not in the so-called incremental mode (when repair skips data that has not changed since the previous repair, which is quite logical). It was announced long ago, formally, as a feature exists, but everyone says: “No, in version 2.1, do not use it ever! He is sure to miss something. We will fix it in 3 ”
● But do not use incremental repair and in 3.x
When the third version came out, after a few days they said:“ No, you cannot use it in the 3rd version. There is a list of 15 bugs, so do not use incremental repair. In the 4th we will do better! ”
I do not believe them. And this is a big problem, especially with increasing cluster size. Therefore, you need to constantly monitor their bugtracker and watch what happens. Without this, unfortunately, it is impossible to live with them.
● Must follow JIRA
If you scatter all the databases on the predictability spectrum, for me Cassandra is on the left in the red area. This does not mean that it is bad, you just have to be prepared for the fact that Cassandra is unpredictable in any sense of the word: in the way it works, and in that something can happen.
I wish you to find other rakes and attack them, because, from my point of view, in spite of everything, Сassandra is good and undoubtedly boring. Just remember the bumps on the road!
Open meeting of HighLoad ++ activists
on July 31 in Moscow, at 19:00, a meeting of speakers, Program Committee and activists of the conference of developers of high-loaded systems HighLoad ++ 2018 will take place . Let's organize a little brainstorming about this year’s program so as not to miss anything new and important. The meeting is open, but you need to register .
Call for Papers
Actively accepting applications for reports on Highload ++ 2018. The program committee is waiting for your abstract until the end of summer.