Research of formats of game resources on the example of Dr.Riptide game
I once set out to port this game to more modern platforms. But of course, the game is far from open source, and once back in 1994, developers took as much as 25 bucks for it, and therefore all game resources had to be redrawn or a single game archive gutted. What I did.
A game archive named RIPTIDE.DAT is a binary file of its own format. By the way, it is not an archive, but a so-called pseudo-archive. Those. files are stored in a single container without compression, and there is some primitive file system that tells how to access files inside the container.
If we open this file in any hex editor, we will see that the records about the files inside the container go at the very beginning, and then the binary data itself. Actually, you need to find out how many files the container contains and the recording format itself. The first thing we pay attention to is a fixed record length, i.e. from the beginning of the file name in one record, to the beginning in the next, for all records, it is the same and equal to 0x19 (25) bytes.
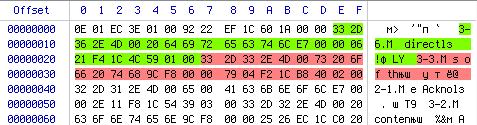
However, the file name of the first record is slightly offset from the beginning of the file, so we will see what is in front of it. Because usually compilers use standard data of 1 (byte), 2 (word), 4 (dword), 8 (qword) bytes in size, then we will divide the data in the mind into approximately blocks of this size. Our attention is drawn to two dword'a

In principle, this is already enough to get all the files from the container, but let's see what the rest of the fields are for. The numbers between the offset and the size are much larger than the size of the pseudo-archive itself, and therefore can not be either an address or a size. The first thing that comes to mind is the checksum, because it would be logical to check the data in case the file turns out to be broken. However, in this case, the developers acted differently. These fields contain a time stamp of files. Why this is needed remains a mystery. Using the example of the first file record, it
The last unsolved value remains only word 0x010E at the very beginning of the file. It is most logical to assume that it contains the number of files in the container. This is easy to verify. We take the offset to the first file from the first file record,
As a result, this can be written as structures in C as follows:
After unpacking, we get 270 files with the extensions CMF, L, M, PCS, PCX, TXT, VOC.
Of these extensions, there is no need to analyze TXT, PCX, which are quite common formats. After a short search, the analysis of CMF and VOC, which are sound files, has disappeared. Remain L, M and PCS. Honestly, why PCS is used, I still haven't figured out, and there was no need for that.
Analyzing the file names, it can be assumed that the L-format files contain graphics, and the M-format contain information about game level cards.
Analyzing the graphics, we rely on the fact that somewhere in any format the image sizes and the information itself displayed as graphics should be indicated somewhere. For animation, at least another number of frames and possibly time intervals between frames are added.
Again, open the file (or rather a few) in the hex editor. What immediately catches your eye is that all the graphics that are displayed statically in the game by the first byte have the value 0x01, and those that are animated have more than one. Thus, we make the assumption that this number indicates the number of frames in the file. Next are two bytes, after which in most cases there are zeros. Suppose it is width and height. Check - we multiply the first by the second and we get just almost the length of the file minus just those same three bytes at the beginning.
Since only one byte per color is used to describe the color, then the colors are indicated by the indices in the palette, and the maximum number of colors used simultaneously is 256, which is consistent with the graphic modes of the time. In 256-color modes, the following palette is used:

For files in which the number of frames is more than one, the sizes of each frame go immediately after the graphic data of the previous one.
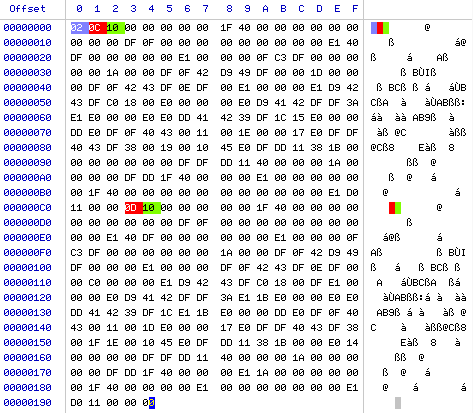
In this figure, you can easily find the offset to the second frame. We take the offset to the first frame 0x00000001 and first add 2 bytes allocated for the size, and then 0x0C * 0x10 for the schedule. We get just
What is noteworthy, to save space, the sizes of the described frames may vary. For transparent color, the value 0 is used.
If before this, the formats were simple, and not difficult, and we roughly knew what to look for, now we have to act extremely intuitively.
Again, open several M-files at once in a hex editor and try to identify similar regions in them.
After a short analysis, we notice several main blocks in the file:
The first thing that was noticed is that the third block in all files is 0x8000 bytes in size. The second thing that was noticed was that the second block is similar to an array of DWORDs, and its length is a multiple of the words from the first four bytes. It was logical to assume that these two words set the dimensions of a two-dimensional array of dwords, and then the array itself.
We start to look at the values of this array. The low byte of any dword is non-zero in most cases, but the closer to the high-order bits, the less frequently are non-zero values.
It was decided to display this two-dimensional array as an image in which 2 bytes of the dword would indicate whether to paint the point or not.
The following picture turned out:

Which approximately resembles the silhouettes of a map, and at first I thought that this byte describes a map for checking for collisions with walls.
Then I decided to display in pixels the color for which the high bytes of the dword are nonzero. The third is red, the fourth is yellow.
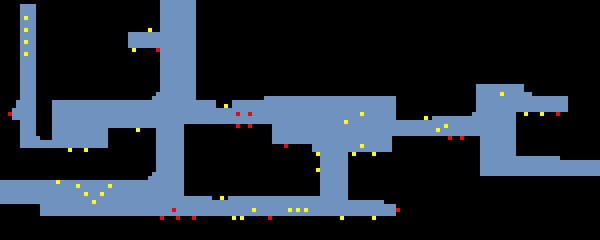
The picture begins to clear up. These values describe static and dynamic game objects for which there is a separate graphic in L-files.
It became clear that the first byte of the dword was storing the index number of the image in the tile map, which was supposed to be displayed at this place. But since tile maps were not stored anywhere in the graphic files, an attempt was made to display that data block as 0x8000 bytes in size. Since I did not know the width of the image, a long strip of 1 pixel thickness was originally obtained. Gradually reducing the width of the image, silhouettes of some map images began to appear. With an image width of 8 pixels, I got a clear image with a pronounced square cut into tiles. The result was an image with a width of 8 and a height of 4096 pixels.
I will present some fragments in the picture below. The byte value was used as the RGB color component, so the image turned out in shades of gray.
By the way, in most cases, everything you see in the pictures is a screenshot of the rendered HTML pages with huge tables, the cells of which were painted in their own color. The parsing of binary files was carried out by means of PHP. Not that I was a pervert, I was just too lazy to look towards graphically libraries.

If we divide the height of the tile map of 4096 pixels by 8, we get 512, not 256 pictures. Thus, what I thought was a mask for checking collisions with walls turned out to be the same image index in the map. That's how the developers killed two birds with one stone in one shot. Those. the younger 256 images for objects through which it is impossible to swim, the older ones through which it is possible. And 2 bytes are allocated for the index, not one.
The rendered overlay map now looks like this:

This is now the whole map fits easily on one screen, and in the days of graphics with a resolution of 320x200 pixels, the background in the game smoothly scrolled.
Why the last two blocks in the format are intended to be found out intuitively failed.
A game archive named RIPTIDE.DAT is a binary file of its own format. By the way, it is not an archive, but a so-called pseudo-archive. Those. files are stored in a single container without compression, and there is some primitive file system that tells how to access files inside the container.
If we open this file in any hex editor, we will see that the records about the files inside the container go at the very beginning, and then the binary data itself. Actually, you need to find out how many files the container contains and the recording format itself. The first thing we pay attention to is a fixed record length, i.e. from the beginning of the file name in one record, to the beginning in the next, for all records, it is the same and equal to 0x19 (25) bytes.
However, the file name of the first record is slightly offset from the beginning of the file, so we will see what is in front of it. Because usually compilers use standard data of 1 (byte), 2 (word), 4 (dword), 8 (qword) bytes in size, then we will divide the data in the mind into approximately blocks of this size. Our attention is drawn to two dword'a
0x00001A60and 0x00013EECand word0x010E, because they can indicate the beginning of the data or the size of the data because it is smaller than the size of the file itself. Displacement 0x00013EECand 0x000001EСare of no interest. The first points to the middle of some binary data, the second falls into the middle of file records. And here it 0x00001A60points out evenly to the binary data located immediately after the last file entry. Since this field refers to a file record, we look at the same field for the next record. To this is added to the offset number 0x19, which got higher and that is a file record length: 0x0000000A+0x19=0x00000023. The dword has a number at this offset 0x0001594C, which is also within the file size. We notice that the number 0x00013EECfrom the first file record is less than this number. Check it out.0x00001A60+0x00013EEC=0x0001594C. We check this on other records and come to the conclusion that this field contains the size of the file located in the container. In principle, this is already enough to get all the files from the container, but let's see what the rest of the fields are for. The numbers between the offset and the size are much larger than the size of the pseudo-archive itself, and therefore can not be either an address or a size. The first thing that comes to mind is the checksum, because it would be logical to check the data in case the file turns out to be broken. However, in this case, the developers acted differently. These fields contain a time stamp of files. Why this is needed remains a mystery. Using the example of the first file record, it
0x1CEF2292turns into a DOS format on 07/15/1994 04:20:36.The last unsolved value remains only word 0x010E at the very beginning of the file. It is most logical to assume that it contains the number of files in the container. This is easy to verify. We take the offset to the first file from the first file record,
0x00001A60subtract 2 bytes by the word itself, and divide by the length of the file record in 0x19 bytes and we get exactly (00001A60-2)/19 = 010Ewhat was required to prove. As a result, this can be written as structures in C as follows:
typedef _FILE_ITEM {
uint32_t Size;
uint32_t TimeStamp;
uint32_t Offset;
char Name[13];
} FILE_ITEM, *PFILE_ITEM;
typedef _HEADER {
uint16_t Count;
FILE_ITEM Files[0];
} HEADER, *PHEADER;
After unpacking, we get 270 files with the extensions CMF, L, M, PCS, PCX, TXT, VOC.
Of these extensions, there is no need to analyze TXT, PCX, which are quite common formats. After a short search, the analysis of CMF and VOC, which are sound files, has disappeared. Remain L, M and PCS. Honestly, why PCS is used, I still haven't figured out, and there was no need for that.
Analyzing the file names, it can be assumed that the L-format files contain graphics, and the M-format contain information about game level cards.
L format
Analyzing the graphics, we rely on the fact that somewhere in any format the image sizes and the information itself displayed as graphics should be indicated somewhere. For animation, at least another number of frames and possibly time intervals between frames are added.
Again, open the file (or rather a few) in the hex editor. What immediately catches your eye is that all the graphics that are displayed statically in the game by the first byte have the value 0x01, and those that are animated have more than one. Thus, we make the assumption that this number indicates the number of frames in the file. Next are two bytes, after which in most cases there are zeros. Suppose it is width and height. Check - we multiply the first by the second and we get just almost the length of the file minus just those same three bytes at the beginning.
Since only one byte per color is used to describe the color, then the colors are indicated by the indices in the palette, and the maximum number of colors used simultaneously is 256, which is consistent with the graphic modes of the time. In 256-color modes, the following palette is used:
For files in which the number of frames is more than one, the sizes of each frame go immediately after the graphic data of the previous one.
In this figure, you can easily find the offset to the second frame. We take the offset to the first frame 0x00000001 and first add 2 bytes allocated for the size, and then 0x0C * 0x10 for the schedule. We get just
0x000000C3. What is noteworthy, to save space, the sizes of the described frames may vary. For transparent color, the value 0 is used.
M format
If before this, the formats were simple, and not difficult, and we roughly knew what to look for, now we have to act extremely intuitively.
Again, open several M-files at once in a hex editor and try to identify similar regions in them.
After a short analysis, we notice several main blocks in the file:
- 4 bytes at the very beginning of the file
- large block of data sparse zeros
- a data block of always 0x8000 bytes in size with chains of repeating data, but almost zero bytes
- small block of data sparse with zeros at the end of the file
- 4 bytes at the very end of the file
The first thing that was noticed is that the third block in all files is 0x8000 bytes in size. The second thing that was noticed was that the second block is similar to an array of DWORDs, and its length is a multiple of the words from the first four bytes. It was logical to assume that these two words set the dimensions of a two-dimensional array of dwords, and then the array itself.
We start to look at the values of this array. The low byte of any dword is non-zero in most cases, but the closer to the high-order bits, the less frequently are non-zero values.
It was decided to display this two-dimensional array as an image in which 2 bytes of the dword would indicate whether to paint the point or not.
The following picture turned out:
Which approximately resembles the silhouettes of a map, and at first I thought that this byte describes a map for checking for collisions with walls.
Then I decided to display in pixels the color for which the high bytes of the dword are nonzero. The third is red, the fourth is yellow.
The picture begins to clear up. These values describe static and dynamic game objects for which there is a separate graphic in L-files.
It became clear that the first byte of the dword was storing the index number of the image in the tile map, which was supposed to be displayed at this place. But since tile maps were not stored anywhere in the graphic files, an attempt was made to display that data block as 0x8000 bytes in size. Since I did not know the width of the image, a long strip of 1 pixel thickness was originally obtained. Gradually reducing the width of the image, silhouettes of some map images began to appear. With an image width of 8 pixels, I got a clear image with a pronounced square cut into tiles. The result was an image with a width of 8 and a height of 4096 pixels.
I will present some fragments in the picture below. The byte value was used as the RGB color component, so the image turned out in shades of gray.
By the way, in most cases, everything you see in the pictures is a screenshot of the rendered HTML pages with huge tables, the cells of which were painted in their own color. The parsing of binary files was carried out by means of PHP. Not that I was a pervert, I was just too lazy to look towards graphically libraries.
If we divide the height of the tile map of 4096 pixels by 8, we get 512, not 256 pictures. Thus, what I thought was a mask for checking collisions with walls turned out to be the same image index in the map. That's how the developers killed two birds with one stone in one shot. Those. the younger 256 images for objects through which it is impossible to swim, the older ones through which it is possible. And 2 bytes are allocated for the index, not one.
The rendered overlay map now looks like this:
This is now the whole map fits easily on one screen, and in the days of graphics with a resolution of 320x200 pixels, the background in the game smoothly scrolled.
Why the last two blocks in the format are intended to be found out intuitively failed.