Know your JIT: closer to the car
Before the code we write is executed, it goes a long way. Andrei Melikhov, in his report on RHS ++ 2018, analyzed every step along the way using the example of the V8 engine. Come under the cat to find out what gives us a deep understanding of the principles of the compiler and how to make JavaScript code more productive.

Find out whether WASM is a silver bullet to improve code performance, and whether optimization is always justified.
Spoiler: "Premature optimization is the root of all ills," Donald Knut.

About the speaker: Andrei Melikhov works for Yandex.Money, actively writes on Node.js, and less in the browser, therefore server JavaScript is closer to him. Andrew supports and develops the devShacht community, go to meetGitHub or Medium .
Today we will talk about JIT compilation. I think you are interested, since you are reading this. Nevertheless, let's clarify why you need to know what JIT is and how V8 works, and why it’s not enough to write to React in a browser.
Wikipedia says that JavaScript is a high-level interpreted programming language with dynamic typing. We will deal with these terms.
Compilation and interpretation
Compilation - when the program is delivered in binary code, and initially optimized for the environment in which it will work.
Interpretation - when we deliver the code as is.
JavaScript comes as it is - it is an interpreted language, as it is written on Wikipedia.
Dynamic and static typing
Static and dynamic typing is often confused with weak and strong typing. For example, C is a language with static weak typing. JavaScript has weak dynamic typing.
What is the best of it? If the program is compiled, it is sharpened to the environment in which it will be executed, which means it will work better. Static typing allows you to make this code more efficient. In JavaScript, the opposite is true.
But at the same time, our application becomes more and more complicated: huge clusters on Node.js appear on both the client and the server, which work fine and come to replace Java-based applications.
But how does all this work, if initially it seems that it is the loser.
We have a JIT (Just In Time Compilation) that occurs during program execution. We will talk about it.
You can write your own engine, but if you move to an effective implementation, you will come up with about the same scheme, which I will show further.
Today we will talk about the V8, and yes, it is named after the 8-cylinder engine.
How is javascript executed?
Parsing turns the code into an abstract syntax tree . AST is a display of the syntactic structure of a code in the form of a tree. In fact, it is convenient for the program, although it is hard to read.
Obtaining an element of an array with index 1 in the form of a tree is represented as an operator and two operands: load the property by key and these keys.
AST is not only in engines. Using AST, extensions are written in many utilities, including:
For example, the cool thing Jscodeshift, about which not everyone knows, allows you to write transformations. If you change the API of a function, you can set these transformations on it and make changes in the whole project.

Moving on. The processor does not understand the abstract syntax tree, it needs machine code . Therefore, further transformation occurs through the interpreter, because the language is interpretable.
So it was, while browsers had a little javascript - highlight the line, open something, close. But now we have applications - SPA, Node.js, and the interpreter becomes a bottleneck .
Instead of the interpreter, an optimizing JIT compiler appears, that is, a Just-in-time compiler. Ahead-of-time compilers work before the application is executed, and JIT - during. In the optimization question, the JIT compiler tries to guess how the code will be executed, what types will be used, and optimize the code so that it works better.
Such optimization is called speculative , because it speculates on knowledge of what happened to the code before. That is, if something with the number type was called 10 times, the compiler thinks that it will be this way all the time and optimizes for this type.
Naturally, if Boolean gets to the input, deoptimization occurs. Consider a function that adds numbers.
Folded once, the second time. The compiler builds a prediction: “These are numbers, I have a cool solution for adding numbers!” And you write
At this point, de-optimization occurs.
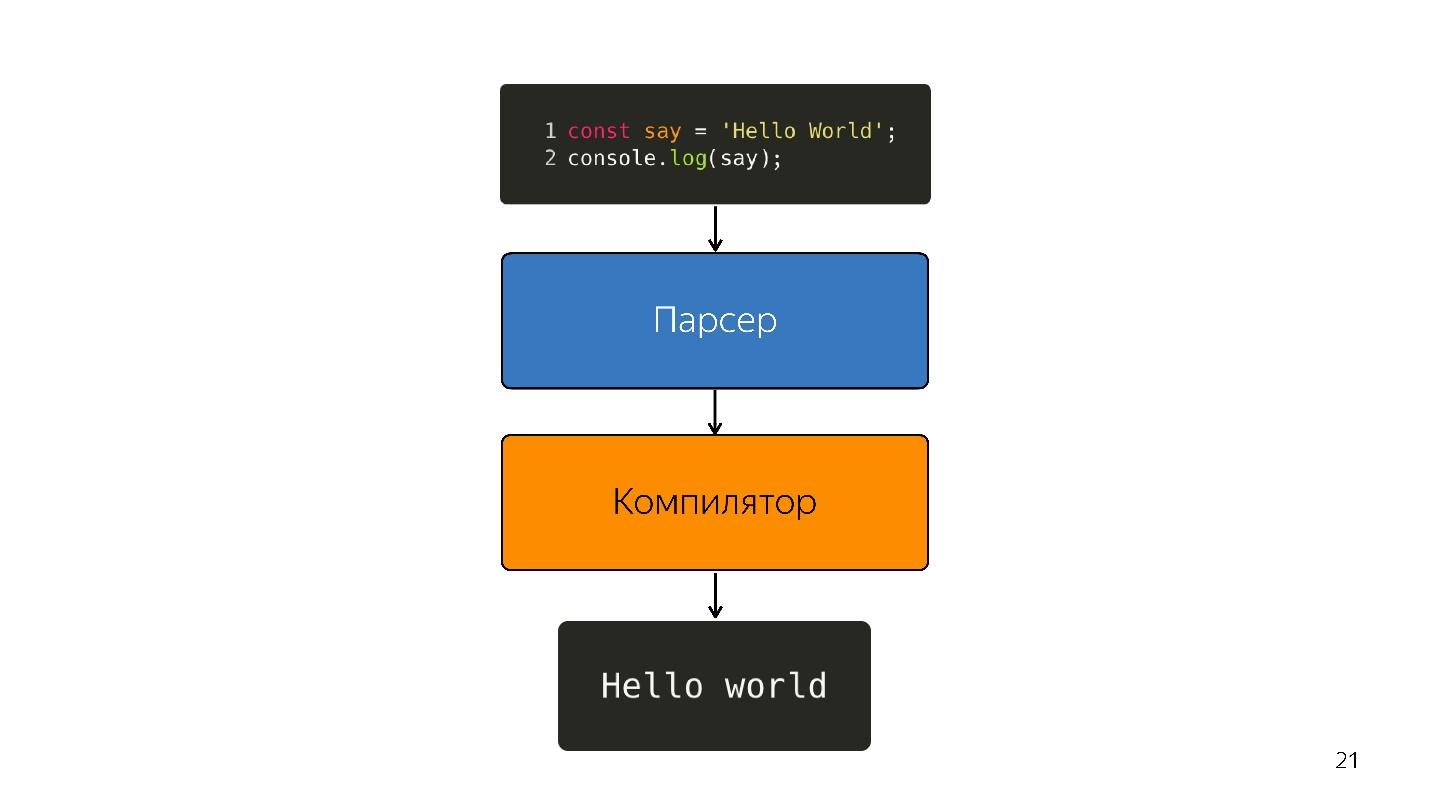
So, the interpreter was replaced by the compiler. It seems that the diagram above is a very simple pipeline. In reality, everything is a little different.
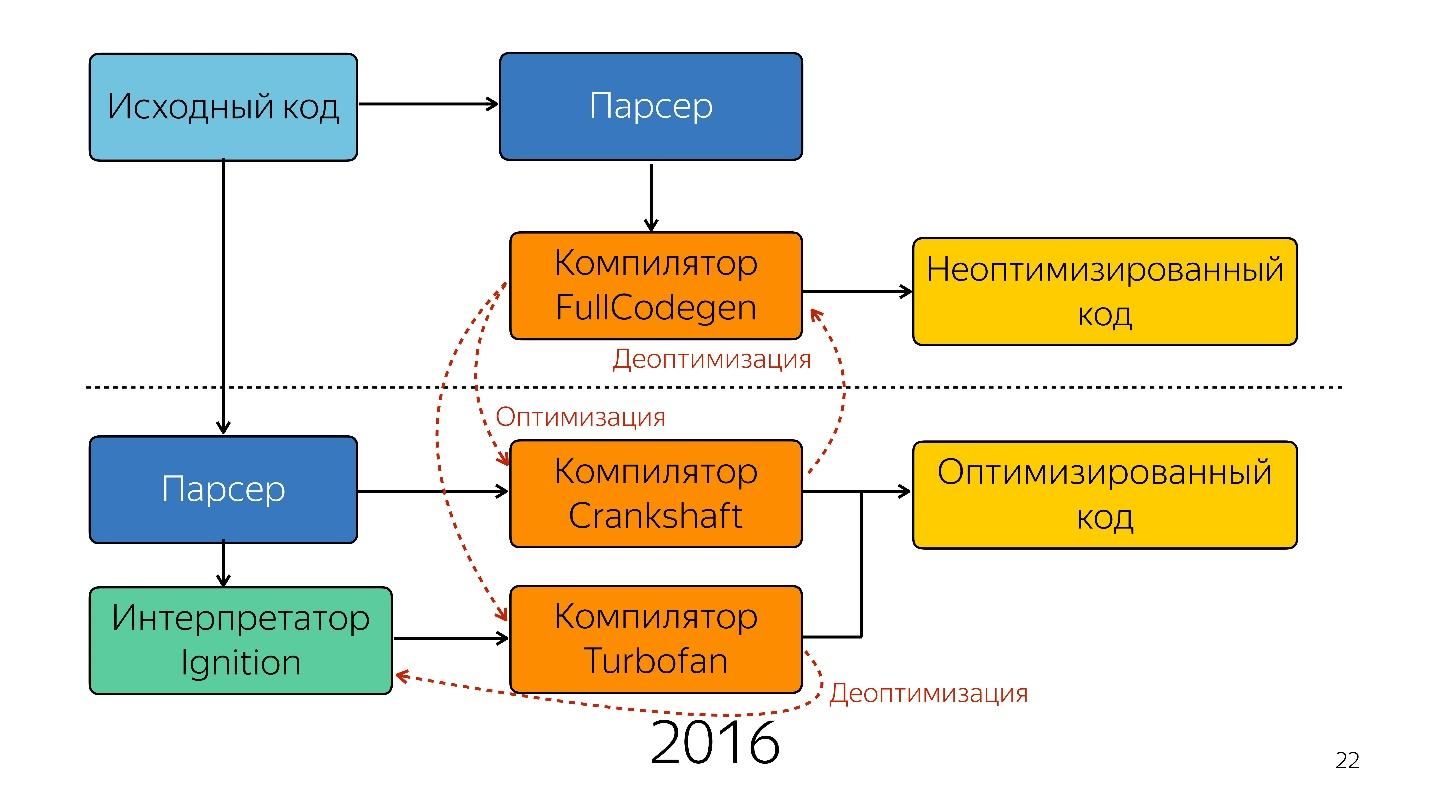
That was until last year. Last year you could hear a lot of reports from Google that they launched a new pipeline with TurboFan and now the scheme looks simpler.
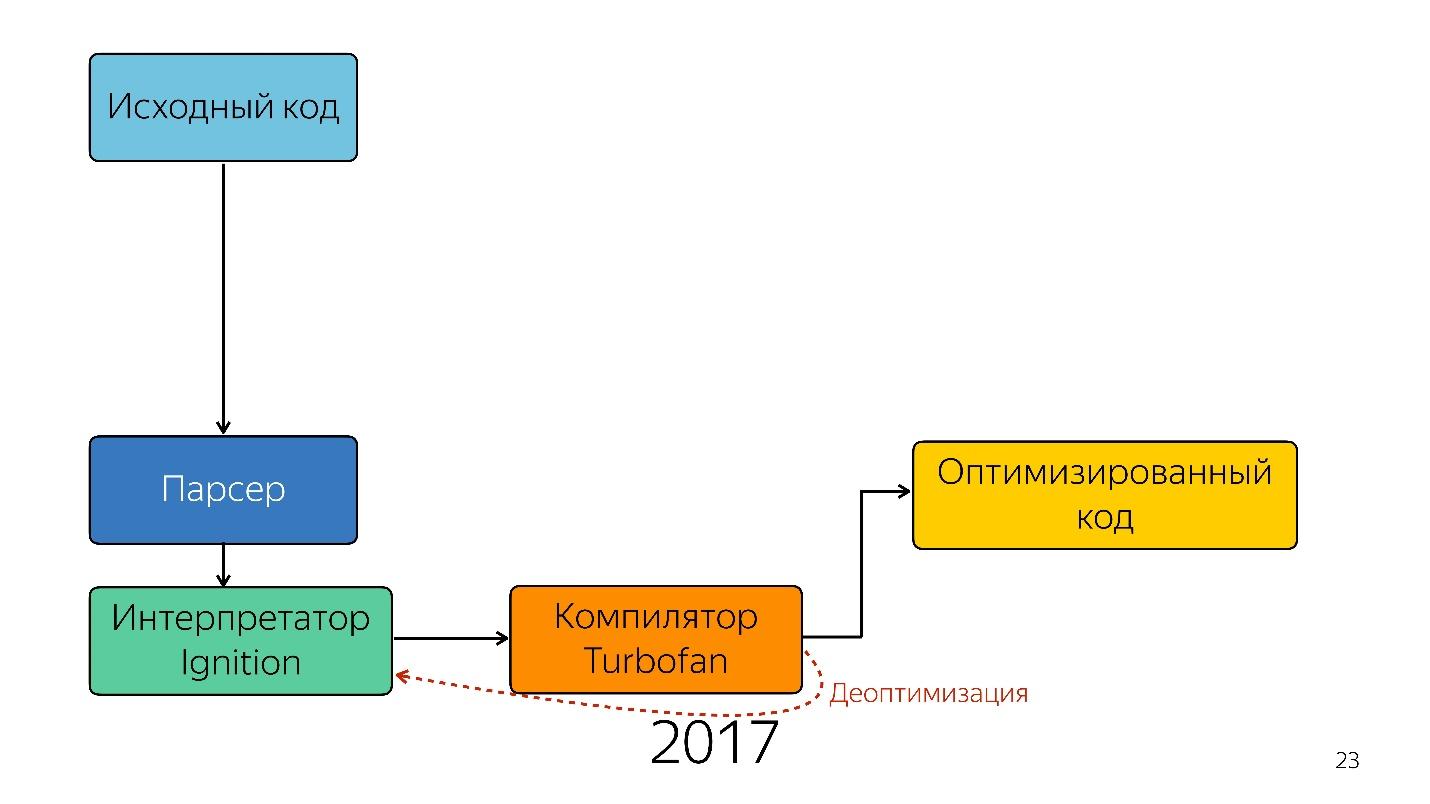
Interestingly, an interpreter appeared here.
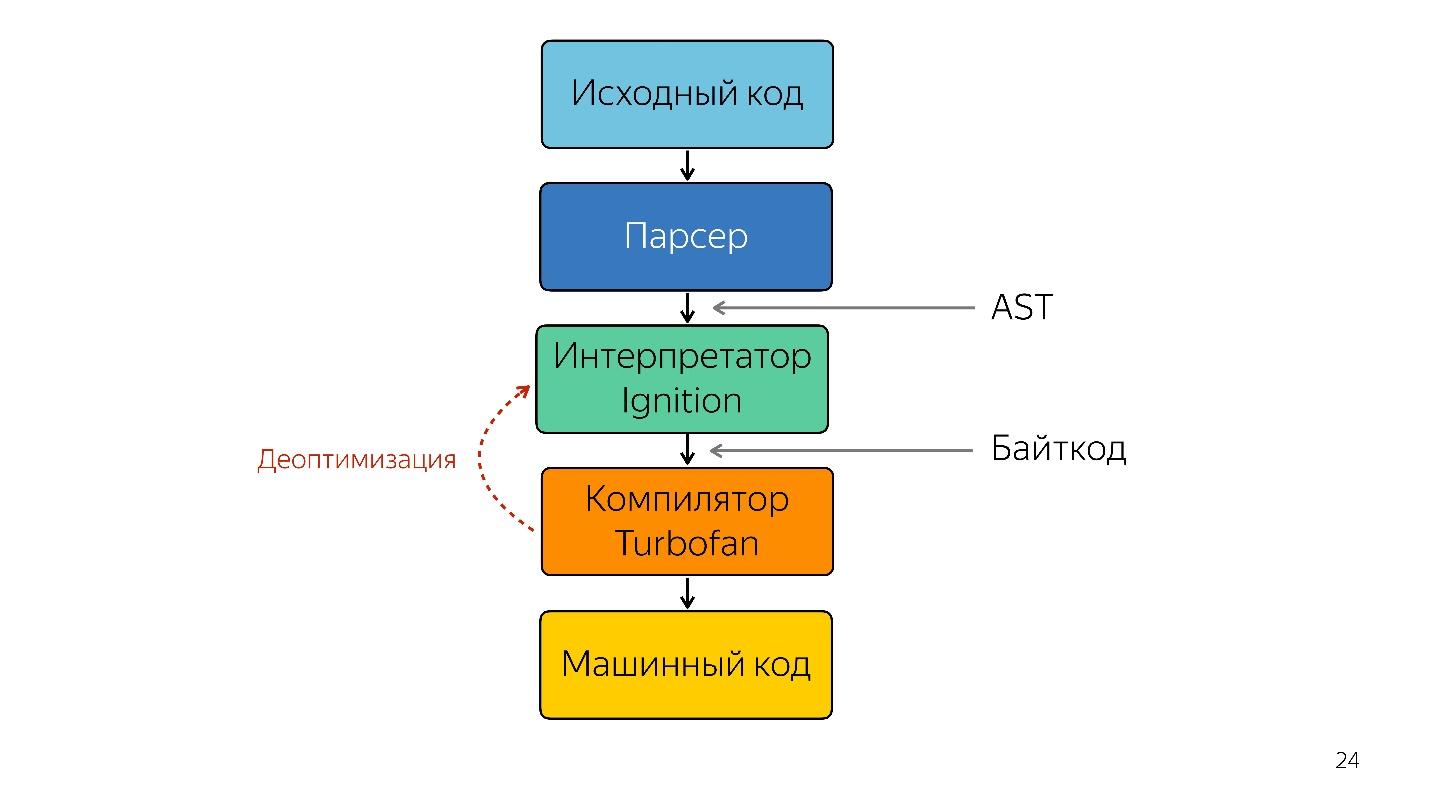
An interpreter is needed to turn an abstract syntax tree into bytecode, and turn the bytecode into a compiler. In case of de-optimization, he again goes to the interpreter.
Previously, the Ignition interpreter scheme was not. Google initially said that the interpreter is not needed - JavaScript is already quite compact and interpretable - we won’t win anything.
But the team that worked on mobile apps faced the following problem.

In 2013-2014, people began to use mobile devices more often to access the Internet than desktop. Basically, this is not an iPhone, but from devices simpler - they have little memory and a weak processor.
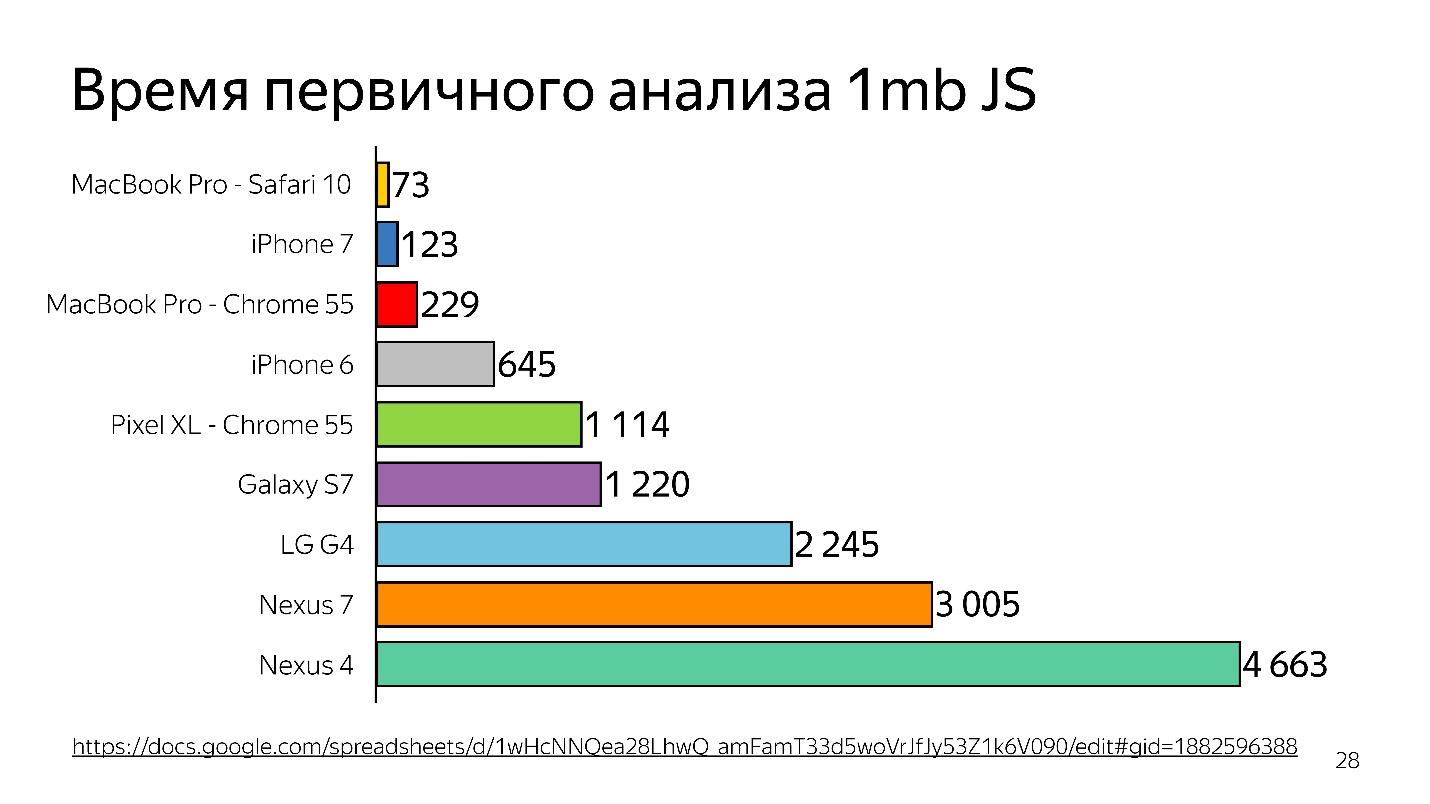
Above is the primary analysis graph of 1 MB of code before the interpreter runs. It can be seen that the desktop wins very much. The iPhone is also good, but it has a different engine, and now we are talking about the V8, which works in Chrome.
Thus, time is wasted - and this is only analysis, not execution - your file has been loaded, and it is trying to understand what is written in it.
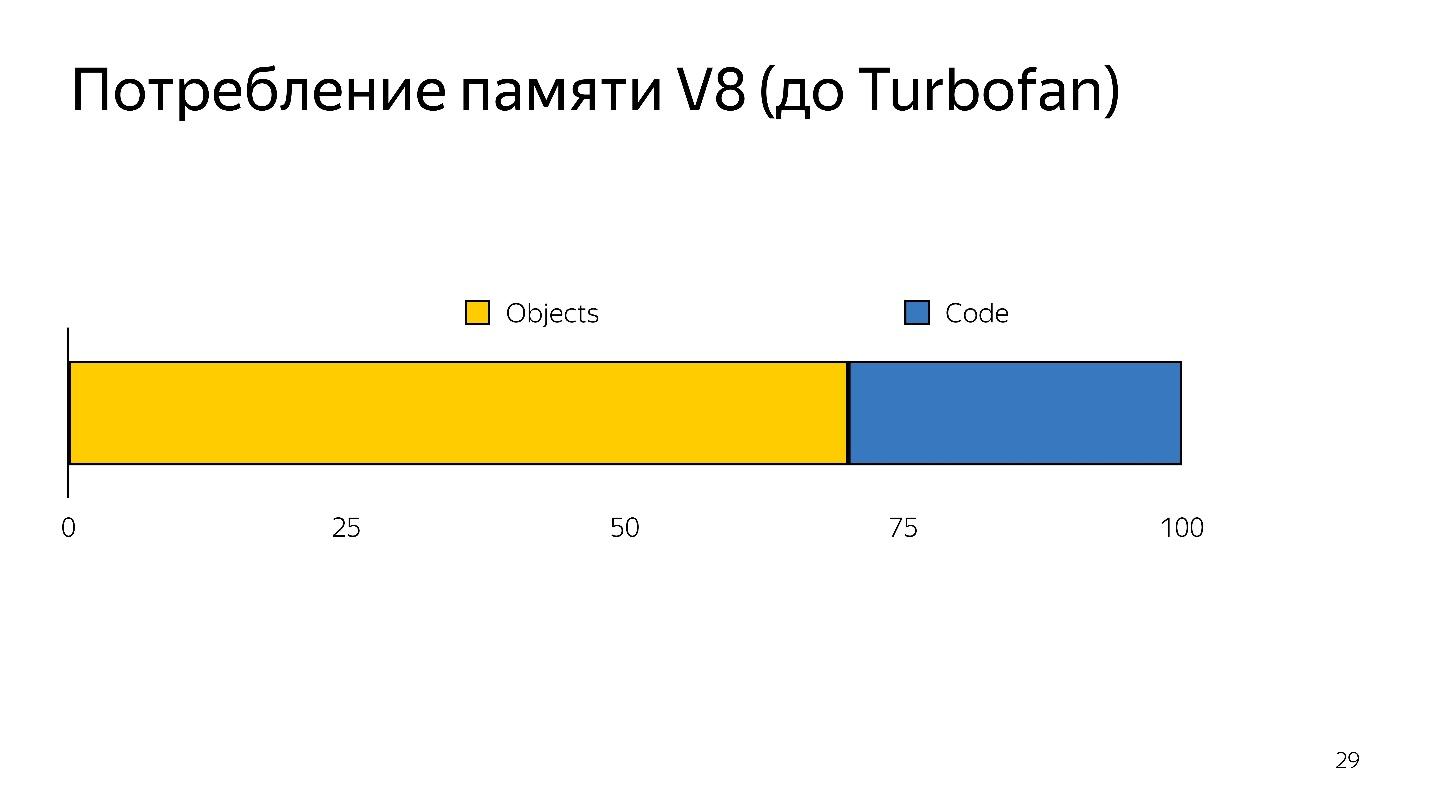
When de-optimization occurs, you need to take the source code again, i.e. it must be stored somewhere. It took a lot of memory.
Thus, the interpreter had two tasks:
The tasks were solved by switching to the bytecode interpreter.
Bytecode in Chrome is a register machine with a battery . In SpiderMonkey, the stack machine, there all the data are on the stack, but there are no registers. Here they are.
We will not fully understand how this works, just look at the code snippet.

It says: take the value that lies in the battery, and add to the value that lies in the register a0 , that is, in the variable a . There is still no information about types. If this were a real assembly code, then it would be written with an understanding of what shifts in memory are, what is in it. Here is just an instruction - take what lies in the register a0 and add to the value lying in the battery.
Of course, the interpreter does not just take an abstract syntax tree and translate it into bytecode.
There are also optimizations, for example, dead code elimination.
If a piece of code is not called, it is discarded and no longer stored. If Ignition sees the addition of two numbers, he will add them up and leave them in such a way as not to store excess information. Only after that it turns out baytkod.
This is the simplest topic.
Cold functions are those that were called once or not called at all, hot functions are those that were called several times. How many times, it is impossible to say - at any time it can be remade. But at some point the function becomes hot, and the engine understands that it needs to be optimized.

Scheme of work.
This is a normal cycle that happens all the time, but it is not infinite. At some point, the engine says: “No, it’s impossible to optimize,” and starts performing without optimization. It is important to understand that it is necessary to observe monomorphism.
Monomorphism is when the same types always come to the input of your function. That is, if you have a string all the time, you do not need to pass a boolean there.
But what to do with objects? Objects are all object. We have classes, but they are not real - it’s just sugar over the prototype model. But inside the engine there are so-called hidden classes.
Hidden classes are in all engines, not only in V8. Everywhere they are called differently, in terms of V8 is Map.
All objects you create have hidden classes. If you
look at the memory profiler, you will see that there are elements where the list of elements is stored, properties where the property is stored, and map (usually the first parameter), where the link to its hidden class is indicated.
Map describes the structure of objects, because, in principle, in JavaScript, typing is possible only structural, not nominal. We can describe how our object looks like, what is behind it.
When deleting / adding properties of Hidden classes objects, the object is changed, a new one is assigned. Let's look at the code.
We have a constructor that creates a new object of type Point.
How can I check Hidden classes?
In Node.js, you can run node —allow-natives-syntax. Then you will be able to write commands in a special syntax, which, of course, cannot be used in production. It looks like this:
No one guarantees that tomorrow these commands will work, they are not in the ECMAScript specification, this is all for debugging.
What do you think will be the result of calling the% HaveSameMap function for two objects? The correct answer is false, because one has a field called a , and the second one has b . These are different objects. This knowledge can be used for Inline Caches.
Call a very simple function that returns a field from an object. It seems to return the unit is very simple. But if you look at the ECMAScript specification, you will see that there is a huge list of what needs to be done to get the field from the object. Because if the field is not in the object, it may be in its prototype. Maybe it's setter, getter, and so on. All this needs to be checked.

In this case, the object has a link to the map, which says: to get the field x , you need to make an offset by one, and we get x . No need to climb anywhere, in any prototypes, everything is close by. Inline Caches uses this.
It seems that 4 polymorphic states are now allowed, but tomorrow there may be eight of them. This is decided by the developers of the engine. We'd better stay in monomorphic, in extreme cases, in a polymorphic state. The transition between monomorphic and polymorphic states is expensive, because you will need to go to the interpreter, get the code again and optimize it again.
In JavaScript, aside from the specific Typed Arrays, there is one type of
array. In the V8 engine, they are 6:
1. [1, 2, 3, 4] // PACKED_SMI_ELEMENTS is simply a packed small integer array. For him there is optimization.
2. [1.2, 2.3, 3.4, 4.6] // PACKED_DOUBLE_ELEMENTS is a packed array of double elements, for it there are also optimizations, but slower ones.
3. [1, 2, 3, 4, 'X'] // PACKED_ELEMENTS - packed array in which there are objects, strings and everything else. For him, too, there is optimization.
The following three types are arrays of the same type as the first three, but with holes:
4. [1, / * hole * /, 2, / * hole * /, 3, 4] // HOLEY_SMI_ELEMENT
5. [1.2, / * hole * /, 2, / * hole * /, 3, 4] // HOLEY_DOUBLE_ELEMENTS
6. [1, / * hole * /, 'X'] // HOLEY_ELEMENTS
When holes appear in your arrays, optimizations become less efficient. They start to work badly, because it is impossible to go through this array in a row, sorting through its iterations. Each subsequent type is worse optimized.
In the diagram, everything above is faster optimized. That is, all your native methods — map, reduce, sort — are well optimized inside. But with each type of optimization it gets worse.
For example, a simple array arrived at the input [ 1 , 2 , 3] (type - packed small integer). Slightly changed this array by adding a double to it - switched to the PACKED_DOUBLE_ELEMENTS state. Add an object to it - moved to the next state, the green rectangle PACKED_ELEMENTS. Add holes to it - go to the HOLEY_ELEMENTS state. We want to restore it to its previous state, so that it becomes “good” again - we delete everything that we have written, and we remain in the same condition ... with holes! That is, HOLEY_ELEMENTS at the bottom right in the diagram. Back it doesn't work. Your arrays can only get worse, but not vice versa.
We often encounter Array-Like Object - these are objects that look like arrays, because they have a sign of length. In fact, they are like a pirate cat, that is, they seem to be similar, but in the efficiency of rum consumption, the cat will be worse than the pirate. Similarly, an Array-Like Object is similar to an array, but not efficient.

Our two favorite Array-Like Objects are arguments and document.querySelectorAII. There are such beautiful functional pieces.
We have a map - we tore it from the prototype and we can seem to use it. But if the array did not come to its input, there will be no optimization. Our engine does not know how to optimize objects.
What should be done?
With querySelectorAll, the same thing - due to the spread, we can turn it into a full-fledged array and work with all the optimizations.
The correct answer: depends on.
What's the Difference?
That is, in the first case we write quickly — we are slowly working; in the second we write slowly - we work quickly.
The garbage collector also eats a little time and resources. Without plunging deeply, I will give the most common base.

In our generative model there is a space of young and old objects . The created object falls into the space of young objects. After some time, the cleaning starts. If the object cannot be reached by links from the root, then it can be collected in the trash. If the object is still in use, it moves to the space of old objects, which is cleaned less often. However, at some point old objects are also deleted.

This is how the automatic garbage collector works - it cleans up objects itself, based on the fact that there are no links to them. These are two different algorithms.
If you start memory consumption profiling in Node.js, you’ll get something like this.

At first it grows abruptly - this is the work of the Scavenge algorithm. Then there is a sharp drop - this Mark-Sweep algorithm collected garbage in the space of old objects. At this point, everything starts to slow down a bit. You cannot control it because you do not know when it will happen. You can only customize the sizes.
Therefore, in the pipeline there is a stage of garbage collection, which consumes time.
Let's look into the future. What to do next, how to be faster?
On this lineup, block sizes are roughly related to the time it takes.
The first thing that comes to mind to people who have heard about baytkod is to immediately feed baytkod to the input and decode it, and not to parse - it will be faster!

The problem is that the bytecode is different now. As I said: in Safari one, in FireFox the other, in Chrome the third. Nevertheless, developers from Mozilla, Bloomberg and Facebook have launched such a Proposal , but this is the future.
There is another problem - compilation, optimization, and re-optimization, if the compiler did not guess. Imagine that there is a statically typed input language that produces an efficient code, and therefore no re-optimization is needed, because what we have received is already effective. Such an input can only be compiled and optimized once. The resulting code will be more efficient and faster.
What else can you do? Imagine that there is manual memory management in this language. Then do not need a garbage collector. The line has become shorter and faster.

Guess what it looks like? WebAssembly about
and work: manual memory management, statically typed
languages and faster execution.

Is WebAssembly a silver bullet?

No, because it is behind JavaScript. WASM cannot do anything by itself. It does not have access to the DOM API. It is inside the engine for javascript - inside the same engine! It does everything through JavaScript, so WASM will not speed up your code . It can speed up individual computations, but your exchange between JavaScript and WASM will be a bottleneck.
Therefore, so far our language is JavaScript and only it, and some help from the black box.
There are three types of optimization.
● Algorithmic optimizations
There is an article " Perhaps you do not need Rust to speed up your JS " by Vyacheslav Egorov, who once developed V8, and now develops Dart. Briefly retell her story.
There was a javascript library that didn't work very fast. Some guys copied it to Rust, compiled it and got WebAssembly, and the application started to work faster. Vyacheslav Egorov as an experienced JS-developer decided to answer them. He applied algorithmic optimizations, and the JavaScript solution became much faster than the Rust solution. In turn, those guys saw it, did the same optimizations, and won again, but not much - it depends on the engine: they won in Mozilla, in Chrome they did not.
Today we didn’t talk about algorithmic optimizations, and front-endiers usually don’t talk about them. This is very bad, because the algorithms also allow the code to run faster . You simply remove unnecessary cycles.
● Language-specific optimizations
This is what we talked about today: our language is interpreted dynamically typed. Understanding how arrays, objects work, monomorphism allows you to write efficient code . It is necessary to know and write correctly.
● Engine-specific optimizations
These are the most dangerous optimizations. If your very smart, but not very sociable, developer who applied a lot of such optimizations, and did not tell anyone about them, did not write the documentation, then if you open the code, you will see not JavaScript, but, for example, Crankshaft Script. That is, JavaScript, written with a deep understanding of how the Crankshaft engine worked two years ago. It all works, but now is no longer needed.
Therefore, such optimizations must be documented, covered with tests proving their effectiveness at the moment. They need to follow. You need to go to them only at the moment when you really slowed down somewhere - you just can’t do without the knowledge of such deep devices. Therefore, the famous phrase of Donald Knut seems logical.

No need to try to introduce some kind of tough optimization just because you have read positive reviews about them.
Such optimizations should be feared, be sure to document and leave the metrics. In general, always collect metrics. Metrics are important!
Useful links:
Find out whether WASM is a silver bullet to improve code performance, and whether optimization is always justified.
Spoiler: "Premature optimization is the root of all ills," Donald Knut.
About the speaker: Andrei Melikhov works for Yandex.Money, actively writes on Node.js, and less in the browser, therefore server JavaScript is closer to him. Andrew supports and develops the devShacht community, go to meetGitHub or Medium .
Motivation and glossary
Today we will talk about JIT compilation. I think you are interested, since you are reading this. Nevertheless, let's clarify why you need to know what JIT is and how V8 works, and why it’s not enough to write to React in a browser.
- Allows you to write more efficient code , because we have a specific language.
- Reveals riddles why in foreign libraries the code is written this way and not otherwise. Sometimes we come across old libraries and see what is written there in a strange way, but it’s necessary, it’s not necessary — it’s not clear. When you know how it works, you understand why it was done.
- This is just interesting . In addition, it makes it possible to understand what is tweeted by Axel Rauschmaier, Benedict Meurer and Dan Abramov.
Wikipedia says that JavaScript is a high-level interpreted programming language with dynamic typing. We will deal with these terms.
Compilation and interpretation
Compilation - when the program is delivered in binary code, and initially optimized for the environment in which it will work.
Interpretation - when we deliver the code as is.
JavaScript comes as it is - it is an interpreted language, as it is written on Wikipedia.
Dynamic and static typing
Static and dynamic typing is often confused with weak and strong typing. For example, C is a language with static weak typing. JavaScript has weak dynamic typing.
What is the best of it? If the program is compiled, it is sharpened to the environment in which it will be executed, which means it will work better. Static typing allows you to make this code more efficient. In JavaScript, the opposite is true.
But at the same time, our application becomes more and more complicated: huge clusters on Node.js appear on both the client and the server, which work fine and come to replace Java-based applications.
But how does all this work, if initially it seems that it is the loser.
JIT all reconcile! Or at least try.
We have a JIT (Just In Time Compilation) that occurs during program execution. We will talk about it.
JS engines
- All unloved Chakra, which is in Internet Explorer. It even works not with JavaScript, but with Jscript - there is such a subset.
- Modern Chakra and ChakraCore, who work in the Edge;
- SpiderMonkey in FireFox;
- JavaScriptCore in WebKit. It is also used in React Native. If you have an RN-application for Android, then it is also executed on JavaScriptCore - the engine comes bundled with the application.
- V8 - my favorite. It is not the best, I just work with Node.js, in which it is the main engine, as in all Chrome Based browsers.
- Rhino and Nashorn are engines that are used in Java. With their help, JavaScript can also be executed there.
- JerryScript - for embedded devices;
- other...
You can write your own engine, but if you move to an effective implementation, you will come up with about the same scheme, which I will show further.
Today we will talk about the V8, and yes, it is named after the 8-cylinder engine.
We climb under the hood
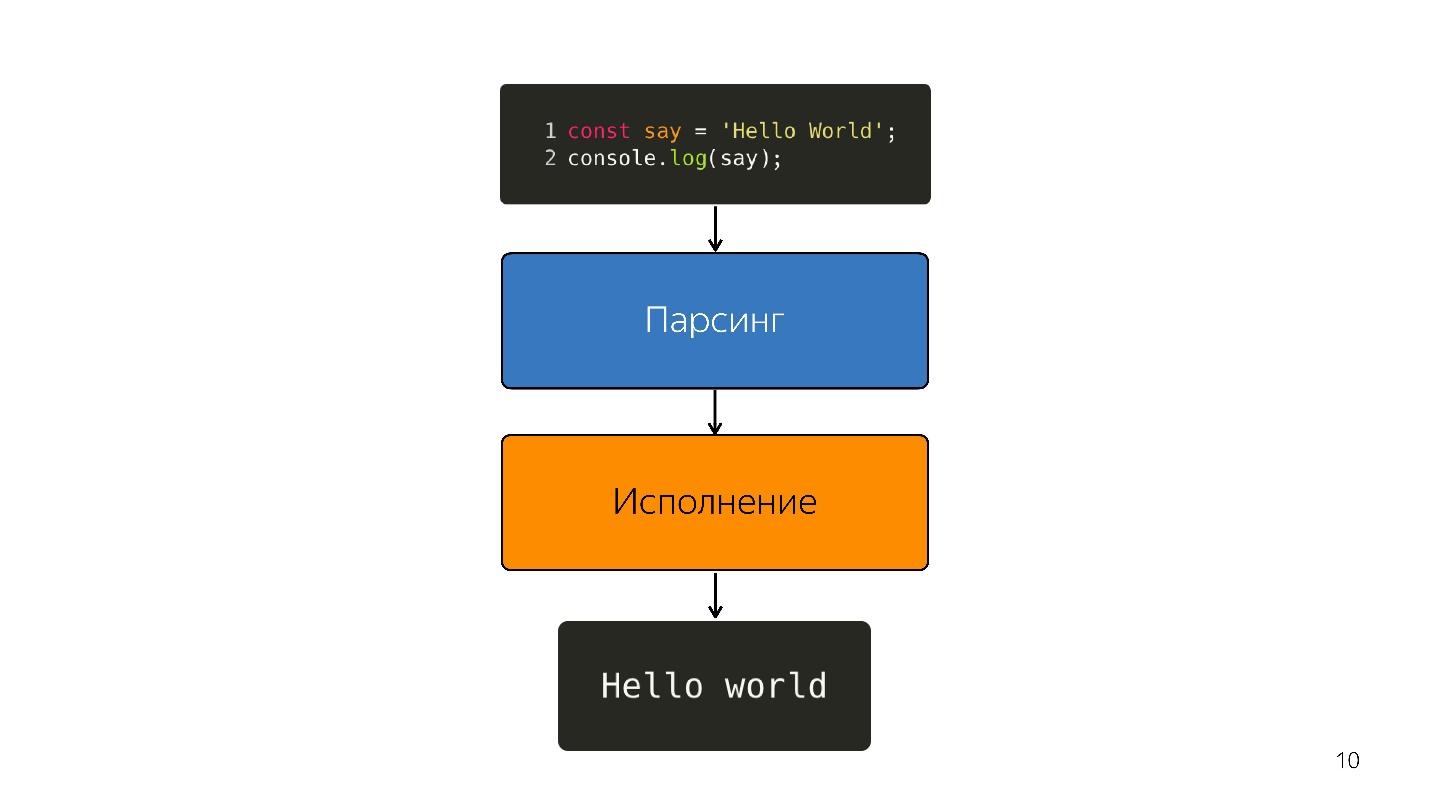
How is javascript executed?
- There is a code written in javascript that is being delivered.
- he parses;
- performed;
- the result is obtained.
Parsing turns the code into an abstract syntax tree . AST is a display of the syntactic structure of a code in the form of a tree. In fact, it is convenient for the program, although it is hard to read.
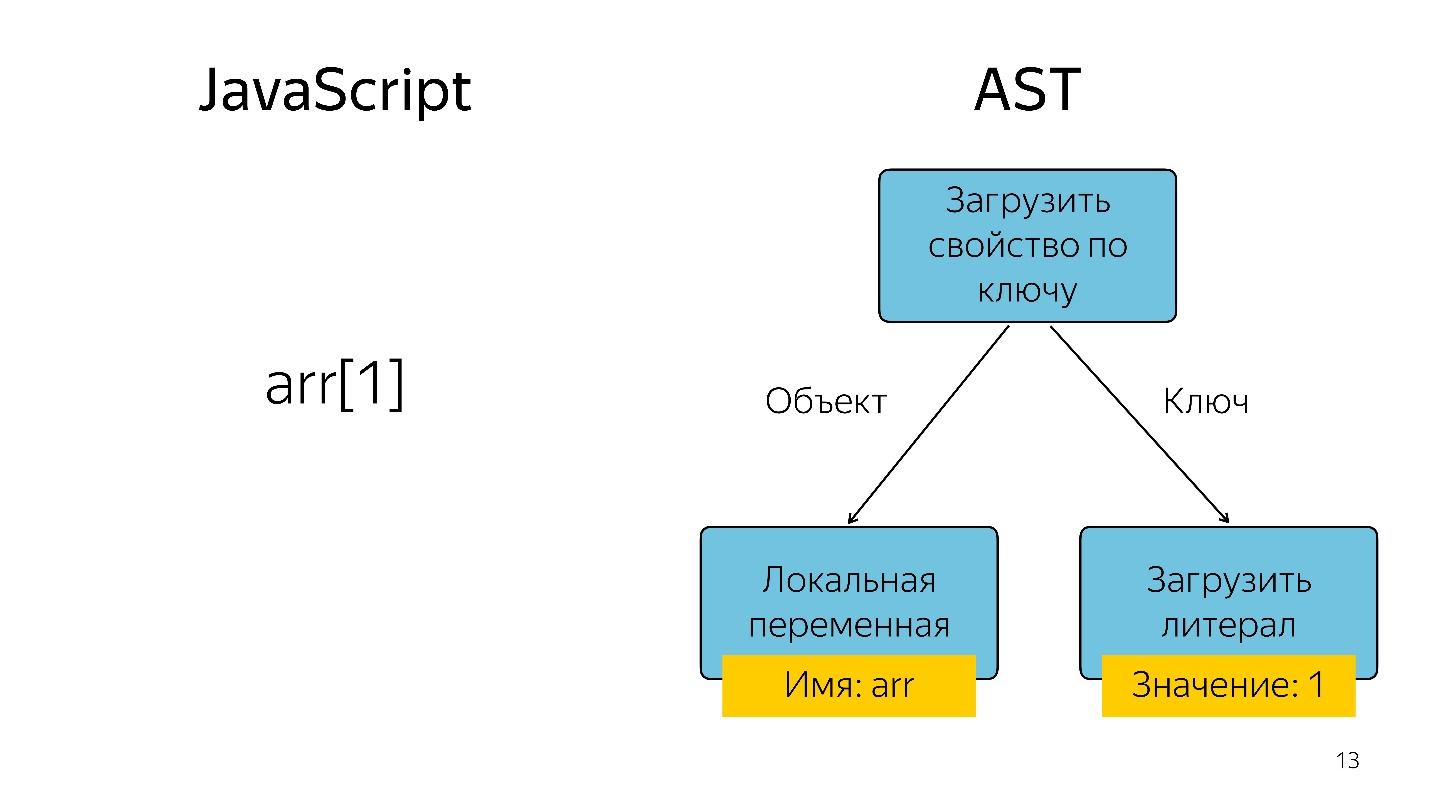
Obtaining an element of an array with index 1 in the form of a tree is represented as an operator and two operands: load the property by key and these keys.
Where is AST used
AST is not only in engines. Using AST, extensions are written in many utilities, including:
- ESLint;
- Babel;
- Prettier;
- Jscodeshift
For example, the cool thing Jscodeshift, about which not everyone knows, allows you to write transformations. If you change the API of a function, you can set these transformations on it and make changes in the whole project.
Moving on. The processor does not understand the abstract syntax tree, it needs machine code . Therefore, further transformation occurs through the interpreter, because the language is interpretable.
So it was, while browsers had a little javascript - highlight the line, open something, close. But now we have applications - SPA, Node.js, and the interpreter becomes a bottleneck .
JIT optimizer compiler
Instead of the interpreter, an optimizing JIT compiler appears, that is, a Just-in-time compiler. Ahead-of-time compilers work before the application is executed, and JIT - during. In the optimization question, the JIT compiler tries to guess how the code will be executed, what types will be used, and optimize the code so that it works better.
Such optimization is called speculative , because it speculates on knowledge of what happened to the code before. That is, if something with the number type was called 10 times, the compiler thinks that it will be this way all the time and optimizes for this type.
Naturally, if Boolean gets to the input, deoptimization occurs. Consider a function that adds numbers.
const foo=(a, b) => a + b;
foo (1, 2);
foo (2, 3);Folded once, the second time. The compiler builds a prediction: “These are numbers, I have a cool solution for adding numbers!” And you write
foo('WTF', 'JS')and pass strings to the function - we have JavaScript, we can also add a string with a number. At this point, de-optimization occurs.
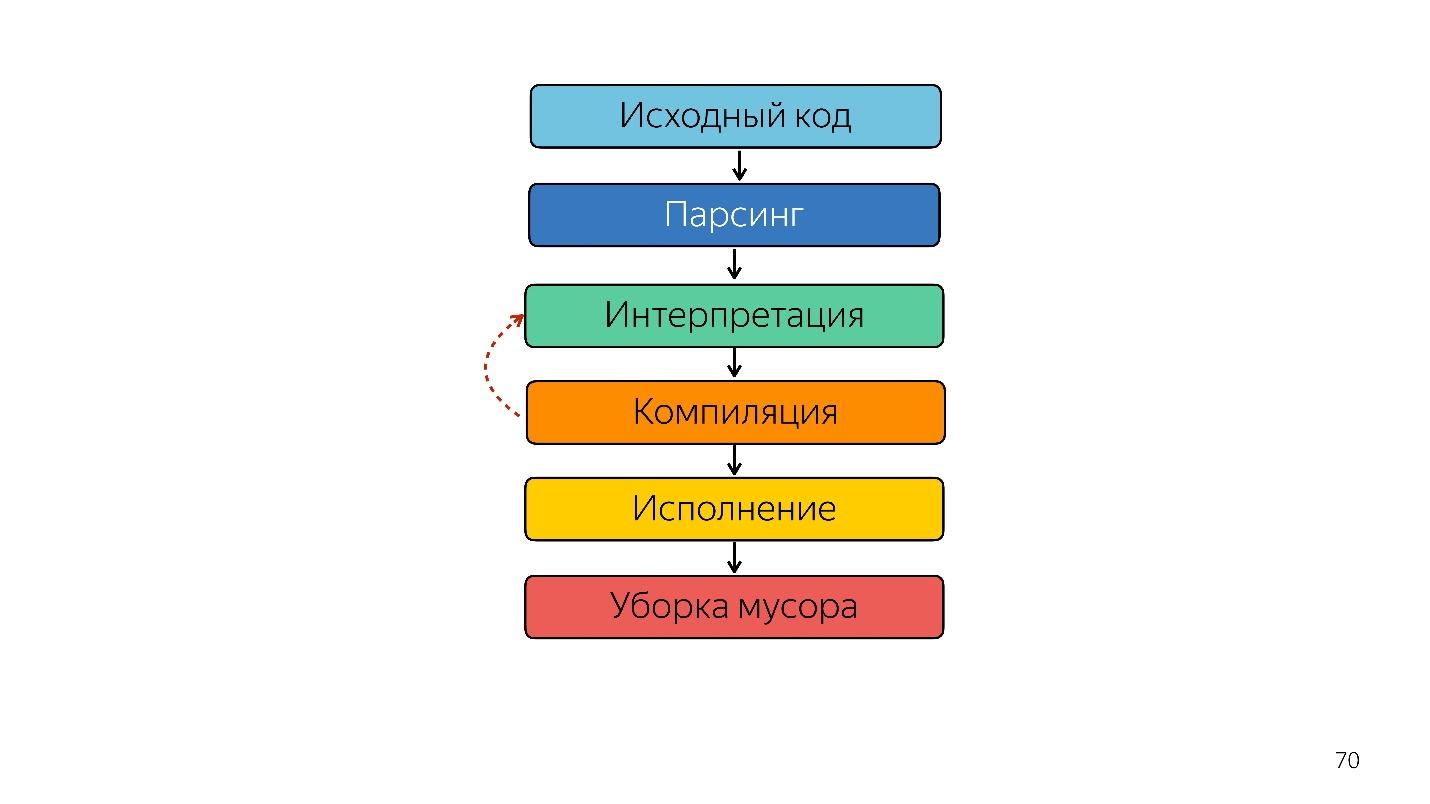
So, the interpreter was replaced by the compiler. It seems that the diagram above is a very simple pipeline. In reality, everything is a little different.
That was until last year. Last year you could hear a lot of reports from Google that they launched a new pipeline with TurboFan and now the scheme looks simpler.
Interestingly, an interpreter appeared here.
An interpreter is needed to turn an abstract syntax tree into bytecode, and turn the bytecode into a compiler. In case of de-optimization, he again goes to the interpreter.
Interpreter Ignition
Previously, the Ignition interpreter scheme was not. Google initially said that the interpreter is not needed - JavaScript is already quite compact and interpretable - we won’t win anything.
But the team that worked on mobile apps faced the following problem.
In 2013-2014, people began to use mobile devices more often to access the Internet than desktop. Basically, this is not an iPhone, but from devices simpler - they have little memory and a weak processor.
Above is the primary analysis graph of 1 MB of code before the interpreter runs. It can be seen that the desktop wins very much. The iPhone is also good, but it has a different engine, and now we are talking about the V8, which works in Chrome.
Did you know that if you put Chrome on the iPhone, will it still work on JavaScriptCore?
Thus, time is wasted - and this is only analysis, not execution - your file has been loaded, and it is trying to understand what is written in it.
When de-optimization occurs, you need to take the source code again, i.e. it must be stored somewhere. It took a lot of memory.
Thus, the interpreter had two tasks:
- reduce the overhead of parsing;
- reduce memory consumption.
The tasks were solved by switching to the bytecode interpreter.
Bytecode in Chrome is a register machine with a battery . In SpiderMonkey, the stack machine, there all the data are on the stack, but there are no registers. Here they are.
We will not fully understand how this works, just look at the code snippet.
It says: take the value that lies in the battery, and add to the value that lies in the register a0 , that is, in the variable a . There is still no information about types. If this were a real assembly code, then it would be written with an understanding of what shifts in memory are, what is in it. Here is just an instruction - take what lies in the register a0 and add to the value lying in the battery.
Of course, the interpreter does not just take an abstract syntax tree and translate it into bytecode.
There are also optimizations, for example, dead code elimination.
If a piece of code is not called, it is discarded and no longer stored. If Ignition sees the addition of two numbers, he will add them up and leave them in such a way as not to store excess information. Only after that it turns out baytkod.
Optimization and deoptimization
Cold and hot functions
This is the simplest topic.
Cold functions are those that were called once or not called at all, hot functions are those that were called several times. How many times, it is impossible to say - at any time it can be remade. But at some point the function becomes hot, and the engine understands that it needs to be optimized.
Scheme of work.
- Ignition (interpreter) collects information. It not only transforms JavaScript into bytecode, but also understands which types came to the input, which functions became hot, and tells the compiler about all this.
- Optimization occurs.
- The compiler executes the code. Everything works well, but a type arrives here that he did not expect, he does not have code to work with this type.
- Deoptimization occurs. The compiler refers to the interpreter Ignition for this code.
This is a normal cycle that happens all the time, but it is not infinite. At some point, the engine says: “No, it’s impossible to optimize,” and starts performing without optimization. It is important to understand that it is necessary to observe monomorphism.
Monomorphism is when the same types always come to the input of your function. That is, if you have a string all the time, you do not need to pass a boolean there.
But what to do with objects? Objects are all object. We have classes, but they are not real - it’s just sugar over the prototype model. But inside the engine there are so-called hidden classes.
Hidden classes
Hidden classes are in all engines, not only in V8. Everywhere they are called differently, in terms of V8 is Map.
All objects you create have hidden classes. If you
look at the memory profiler, you will see that there are elements where the list of elements is stored, properties where the property is stored, and map (usually the first parameter), where the link to its hidden class is indicated.
Map describes the structure of objects, because, in principle, in JavaScript, typing is possible only structural, not nominal. We can describe how our object looks like, what is behind it.
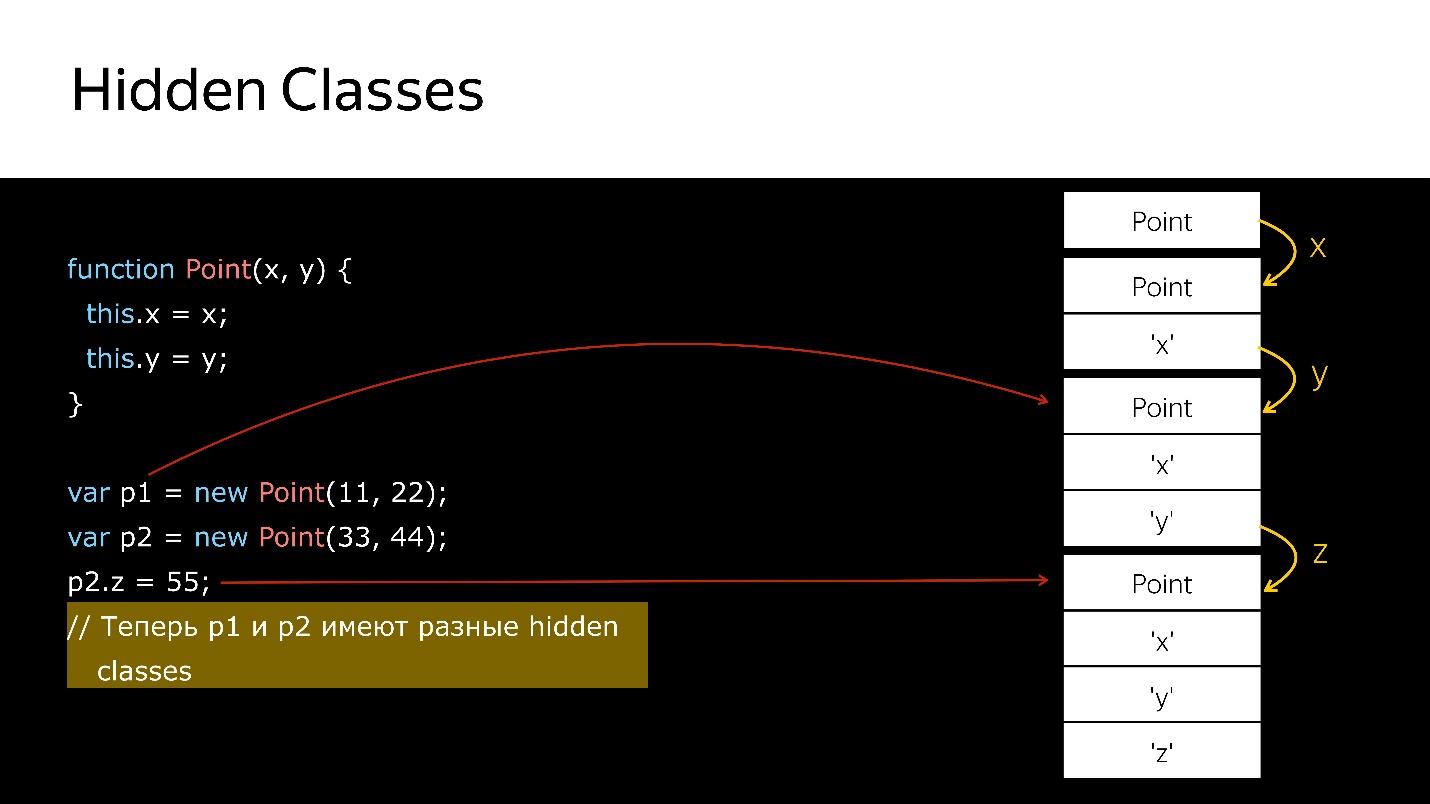
When deleting / adding properties of Hidden classes objects, the object is changed, a new one is assigned. Let's look at the code.
We have a constructor that creates a new object of type Point.
- Create an object.
- We bind to it a hidden class that says that it is an object of type Point.
- Added field x - a new hidden class, which says that it is an object of type Point, in which the first is the value of x.
- Added y - new Hidden classes, in which x, and then y.
- Created another object - the same thing happens. That is, it also binds what has already been created. At this moment, these two objects are of the same type (via Hidden classes).
- When a new field is added to the second object, the object has a new Hidden classes. Now for the p1 and p2 engine, these are objects of different classes, because they have different structures
- If you pass the first object somewhere, then when you pass the second object there, deoptimization will occur. The first refers to one hidden class, the second to the other.
How can I check Hidden classes?
In Node.js, you can run node —allow-natives-syntax. Then you will be able to write commands in a special syntax, which, of course, cannot be used in production. It looks like this:
%HaveSameMap({'a':1}, {'b':1})No one guarantees that tomorrow these commands will work, they are not in the ECMAScript specification, this is all for debugging.
What do you think will be the result of calling the% HaveSameMap function for two objects? The correct answer is false, because one has a field called a , and the second one has b . These are different objects. This knowledge can be used for Inline Caches.
Inline caches
Call a very simple function that returns a field from an object. It seems to return the unit is very simple. But if you look at the ECMAScript specification, you will see that there is a huge list of what needs to be done to get the field from the object. Because if the field is not in the object, it may be in its prototype. Maybe it's setter, getter, and so on. All this needs to be checked.
In this case, the object has a link to the map, which says: to get the field x , you need to make an offset by one, and we get x . No need to climb anywhere, in any prototypes, everything is close by. Inline Caches uses this.
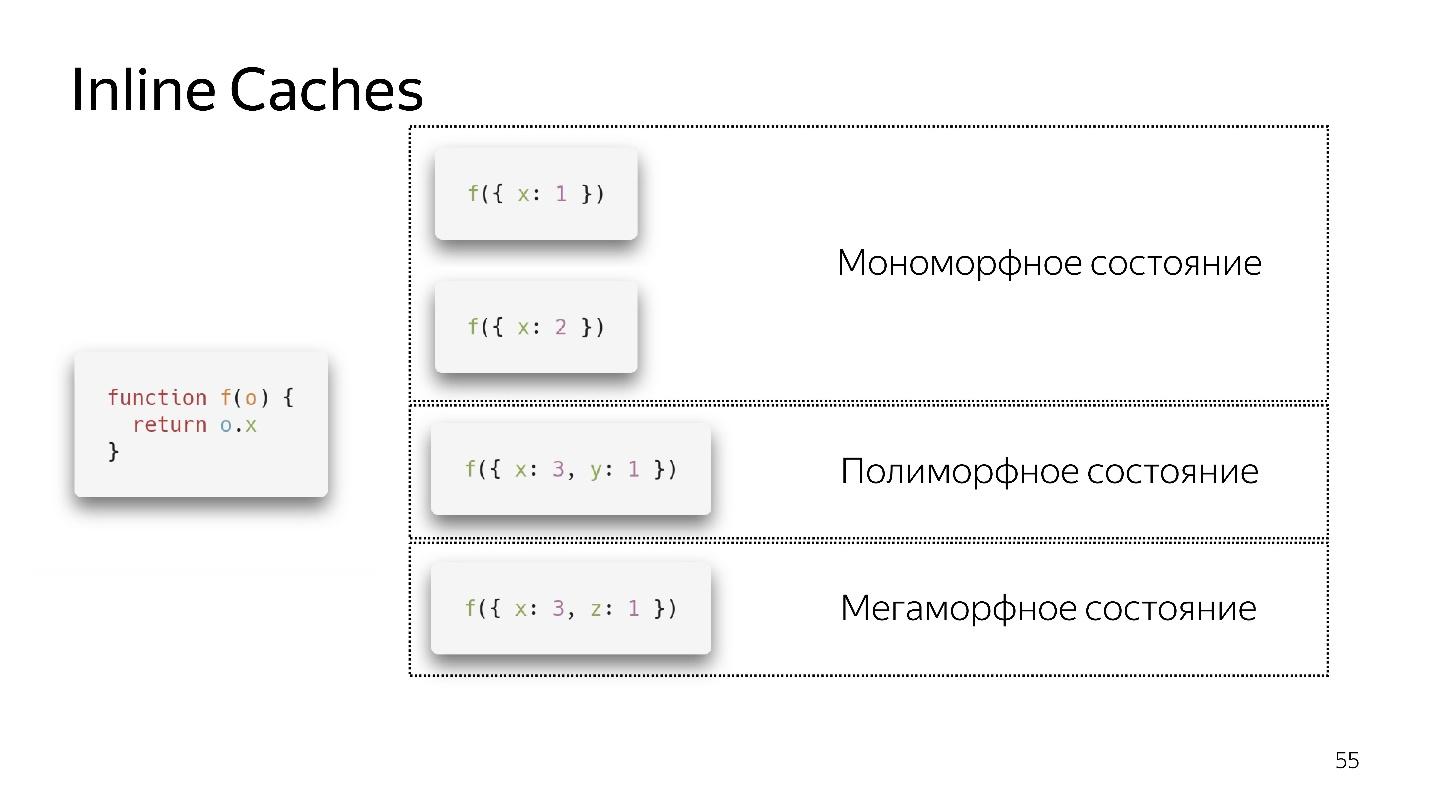
- If we call the function the first time, everything is fine, the interpreter did the optimization
- For the second call, the monomorphic state is preserved.
- I call the function a third time, passing a slightly different object {x: 3, y: 1}. De-optimization occurs, if appears, we move to the polymorphic state. Now the code that performs this function knows that two different types of objects can fly to it.
- If we transfer different objects several times, it remains in a polymorphic state, adding new if. But at some point it gives up and passes into the megamorphic state, i.e. when: “There are too many different types of arrivals at the entrance - I don’t know how to optimize it!”
It seems that 4 polymorphic states are now allowed, but tomorrow there may be eight of them. This is decided by the developers of the engine. We'd better stay in monomorphic, in extreme cases, in a polymorphic state. The transition between monomorphic and polymorphic states is expensive, because you will need to go to the interpreter, get the code again and optimize it again.
Arrays
In JavaScript, aside from the specific Typed Arrays, there is one type of
array. In the V8 engine, they are 6:
1. [1, 2, 3, 4] // PACKED_SMI_ELEMENTS is simply a packed small integer array. For him there is optimization.
2. [1.2, 2.3, 3.4, 4.6] // PACKED_DOUBLE_ELEMENTS is a packed array of double elements, for it there are also optimizations, but slower ones.
3. [1, 2, 3, 4, 'X'] // PACKED_ELEMENTS - packed array in which there are objects, strings and everything else. For him, too, there is optimization.
The following three types are arrays of the same type as the first three, but with holes:
4. [1, / * hole * /, 2, / * hole * /, 3, 4] // HOLEY_SMI_ELEMENT
5. [1.2, / * hole * /, 2, / * hole * /, 3, 4] // HOLEY_DOUBLE_ELEMENTS
6. [1, / * hole * /, 'X'] // HOLEY_ELEMENTS
When holes appear in your arrays, optimizations become less efficient. They start to work badly, because it is impossible to go through this array in a row, sorting through its iterations. Each subsequent type is worse optimized.
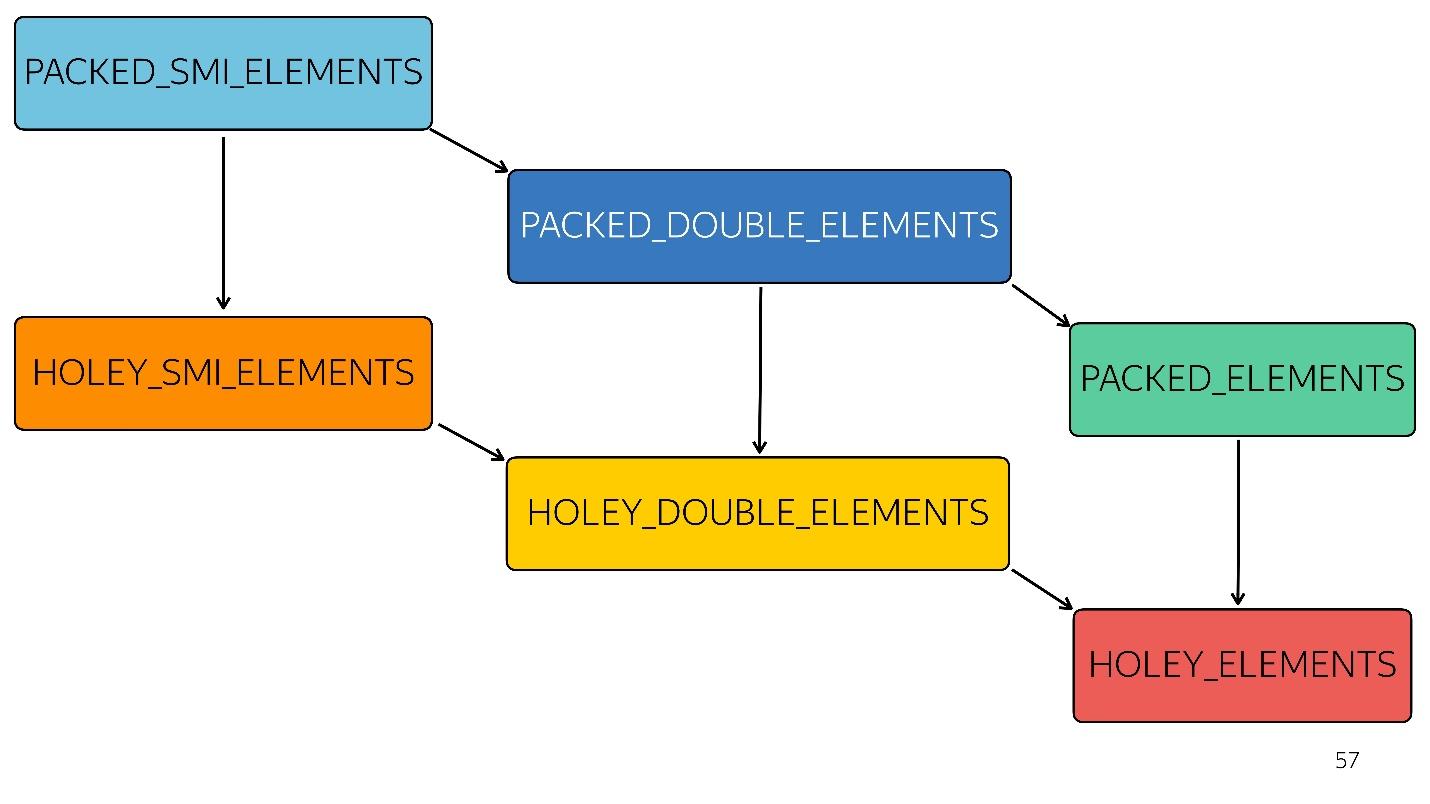
In the diagram, everything above is faster optimized. That is, all your native methods — map, reduce, sort — are well optimized inside. But with each type of optimization it gets worse.
For example, a simple array arrived at the input [ 1 , 2 , 3] (type - packed small integer). Slightly changed this array by adding a double to it - switched to the PACKED_DOUBLE_ELEMENTS state. Add an object to it - moved to the next state, the green rectangle PACKED_ELEMENTS. Add holes to it - go to the HOLEY_ELEMENTS state. We want to restore it to its previous state, so that it becomes “good” again - we delete everything that we have written, and we remain in the same condition ... with holes! That is, HOLEY_ELEMENTS at the bottom right in the diagram. Back it doesn't work. Your arrays can only get worse, but not vice versa.
Array-Like Object
We often encounter Array-Like Object - these are objects that look like arrays, because they have a sign of length. In fact, they are like a pirate cat, that is, they seem to be similar, but in the efficiency of rum consumption, the cat will be worse than the pirate. Similarly, an Array-Like Object is similar to an array, but not efficient.
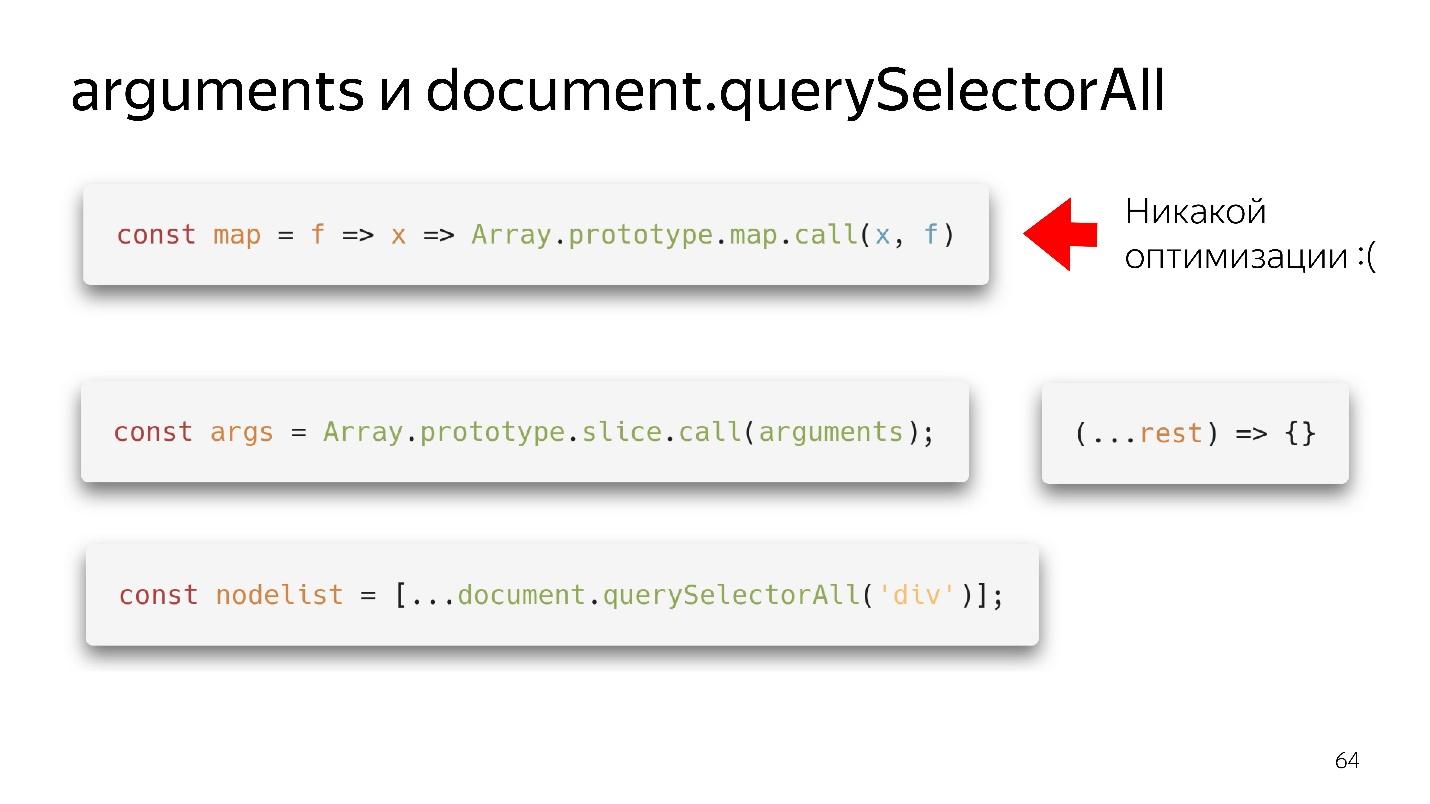
Our two favorite Array-Like Objects are arguments and document.querySelectorAII. There are such beautiful functional pieces.
We have a map - we tore it from the prototype and we can seem to use it. But if the array did not come to its input, there will be no optimization. Our engine does not know how to optimize objects.
What should be done?
- Old school version - through slice.call () to turn into a real array.
- The modern version is even better: write (... rest), get a clean array — not arguments — everything is fine!
With querySelectorAll, the same thing - due to the spread, we can turn it into a full-fledged array and work with all the optimizations.
Large arrays
Riddle: new Array (1000) vs array = []
Which option is better: create a large array at once and fill it with 1000 objects in a loop, or create an empty one and fill it gradually?
The correct answer: depends on.
What's the Difference?
- When we create an array in the first way and fill 1000 elements, we create 1000 holes. This array will not be optimized. But it will quickly write.
- Creating an array according to the second variant, a little memory is allocated, we write, for example, 60 elements, a little more memory is allocated, etc.
That is, in the first case we write quickly — we are slowly working; in the second we write slowly - we work quickly.
Garbage collector
The garbage collector also eats a little time and resources. Without plunging deeply, I will give the most common base.
In our generative model there is a space of young and old objects . The created object falls into the space of young objects. After some time, the cleaning starts. If the object cannot be reached by links from the root, then it can be collected in the trash. If the object is still in use, it moves to the space of old objects, which is cleaned less often. However, at some point old objects are also deleted.
This is how the automatic garbage collector works - it cleans up objects itself, based on the fact that there are no links to them. These are two different algorithms.
- Scavenge is fast, but not effective.
- Mark-Sweep is slow but effective.
If you start memory consumption profiling in Node.js, you’ll get something like this.
At first it grows abruptly - this is the work of the Scavenge algorithm. Then there is a sharp drop - this Mark-Sweep algorithm collected garbage in the space of old objects. At this point, everything starts to slow down a bit. You cannot control it because you do not know when it will happen. You can only customize the sizes.
Therefore, in the pipeline there is a stage of garbage collection, which consumes time.
Even faster?
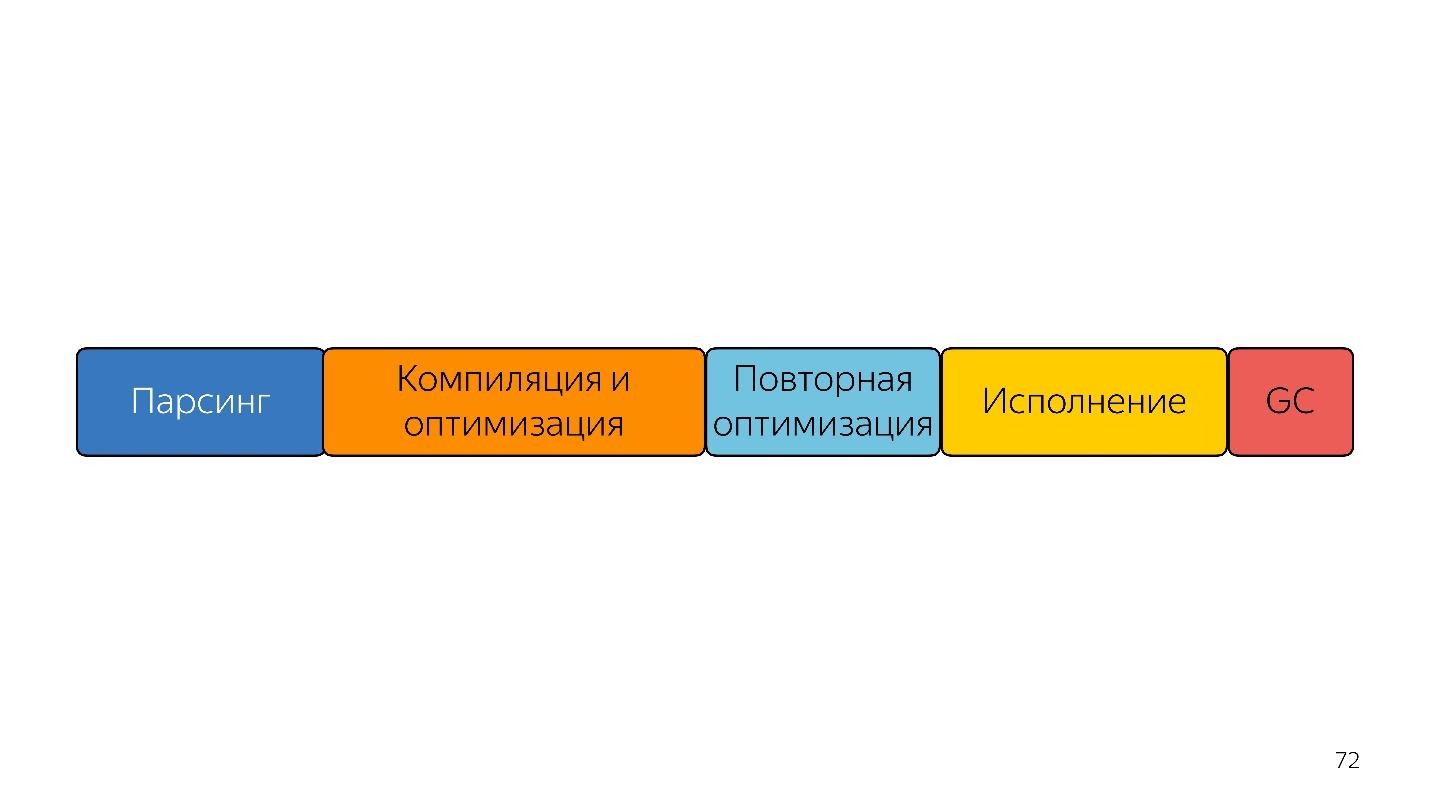
Let's look into the future. What to do next, how to be faster?
On this lineup, block sizes are roughly related to the time it takes.
The first thing that comes to mind to people who have heard about baytkod is to immediately feed baytkod to the input and decode it, and not to parse - it will be faster!
The problem is that the bytecode is different now. As I said: in Safari one, in FireFox the other, in Chrome the third. Nevertheless, developers from Mozilla, Bloomberg and Facebook have launched such a Proposal , but this is the future.
There is another problem - compilation, optimization, and re-optimization, if the compiler did not guess. Imagine that there is a statically typed input language that produces an efficient code, and therefore no re-optimization is needed, because what we have received is already effective. Such an input can only be compiled and optimized once. The resulting code will be more efficient and faster.
What else can you do? Imagine that there is manual memory management in this language. Then do not need a garbage collector. The line has become shorter and faster.
Guess what it looks like? WebAssembly about
and work: manual memory management, statically typed
languages and faster execution.
Is WebAssembly a silver bullet?
No, because it is behind JavaScript. WASM cannot do anything by itself. It does not have access to the DOM API. It is inside the engine for javascript - inside the same engine! It does everything through JavaScript, so WASM will not speed up your code . It can speed up individual computations, but your exchange between JavaScript and WASM will be a bottleneck.
Therefore, so far our language is JavaScript and only it, and some help from the black box.
Total
There are three types of optimization.
● Algorithmic optimizations
There is an article " Perhaps you do not need Rust to speed up your JS " by Vyacheslav Egorov, who once developed V8, and now develops Dart. Briefly retell her story.
There was a javascript library that didn't work very fast. Some guys copied it to Rust, compiled it and got WebAssembly, and the application started to work faster. Vyacheslav Egorov as an experienced JS-developer decided to answer them. He applied algorithmic optimizations, and the JavaScript solution became much faster than the Rust solution. In turn, those guys saw it, did the same optimizations, and won again, but not much - it depends on the engine: they won in Mozilla, in Chrome they did not.
Today we didn’t talk about algorithmic optimizations, and front-endiers usually don’t talk about them. This is very bad, because the algorithms also allow the code to run faster . You simply remove unnecessary cycles.
● Language-specific optimizations
This is what we talked about today: our language is interpreted dynamically typed. Understanding how arrays, objects work, monomorphism allows you to write efficient code . It is necessary to know and write correctly.
● Engine-specific optimizations
These are the most dangerous optimizations. If your very smart, but not very sociable, developer who applied a lot of such optimizations, and did not tell anyone about them, did not write the documentation, then if you open the code, you will see not JavaScript, but, for example, Crankshaft Script. That is, JavaScript, written with a deep understanding of how the Crankshaft engine worked two years ago. It all works, but now is no longer needed.
Therefore, such optimizations must be documented, covered with tests proving their effectiveness at the moment. They need to follow. You need to go to them only at the moment when you really slowed down somewhere - you just can’t do without the knowledge of such deep devices. Therefore, the famous phrase of Donald Knut seems logical.
No need to try to introduce some kind of tough optimization just because you have read positive reviews about them.
Such optimizations should be feared, be sure to document and leave the metrics. In general, always collect metrics. Metrics are important!
Useful links:
- Theses and presentation of the report
- What's up with monomorphism?
- What makes WebAssembly fast?
- Understanding the V8 bytecode
- Devshakhta: Hardcore
On Frontend Conf Moscow on October 4 and 5, we will analyze even more difficult cases and crawl into the insides of an even greater number of popular tools. Apply by August 15 , and see what is interesting in the list:
- Timofey Lavrenyuk (KeepSolid) plans to tell how to develop a fully offline Offline application using Persistent Storage.
- Anton Hlynovsky (TradingView) promises to acquaint listeners with the basics of WebGL and WebAssembly and show how to write on their basis a simple visual application using only the basic API .
- From the report Alexey Chernyshev Alexey learn how to implement multi-user text editing in real time like Google Docs.