Farewell microservices: from one hundred problem children to one superstar
- Transfer
If you do not live in a cave, you may know that microservices are the architecture of today. With the development of this trend, in the Segment product , it was adopted at an early stage as the best practice that served well in some cases, and, as you will soon see, not so well in others.
In short, microservices are a service-oriented software architecture in which server-side applications are built by combining multiple single-task, minimal network services. Benefits include improved modularity, simplified testing, better functional composition, isolation of the environment, and autonomy of development teams. The opposite is a monolithic architecture, where a large amount of functionality is located in one service, in which testing, deployment and scaling occur as a whole.
In early 2017, we reached a turning point with the main part of our Segment product.. It looked as if we were falling from the microservice tree, hitting each branch on the way down. Instead of developing faster, the small team is immersed in increasing complexity. The significant advantages of this architecture have become a burden. As our speed dropped, the number of defects increased.
As a result, the team was unable to succeed with three full-time engineers who spend most of their time simply maintaining the system. Something had to change. This post is a story about how we took a step back and adopted an approach that fit our requirements and needs of the team well.
Why microservices
Infrastructure Data Segment customer receives hundreds of thousands of events per second, and forwards them to the partner API, what we call the directions on the server side (server-side destinations). There are more than one hundred types of these directions, such as Google Analytics, Optimizely, or custom web hooks.
Years ago, when the product was originally launched, the architecture was simple. There was an API that received events and sent them to a queue of distributed messages. The event in this case was a JSON object generated by a web or mobile application containing information about users and their actions. An example of the payload was as follows:
When the event was received from the queue, a client-controlled setting was checked that determined which directions it was intended for. Then the event was sent to each recipient API, one by one, which was convenient, since developers had to send their event to a single endpoint - the Segment API, rather than creating potentially dozens of integrations. Segment handled the request for each destination endpoint.
If one of the requests to the recipient fails, sometimes we try to send this event later. Some failures are safe to resend, some are not. Errors that can be sent later are those that can potentially be accepted by the destination without changes. For example, HTTP 500, limits and timeouts. Errors that are not sent again are those in which we are sure that they will not be accepted by the destination points. For example, the request contains invalid data or missing required fields.
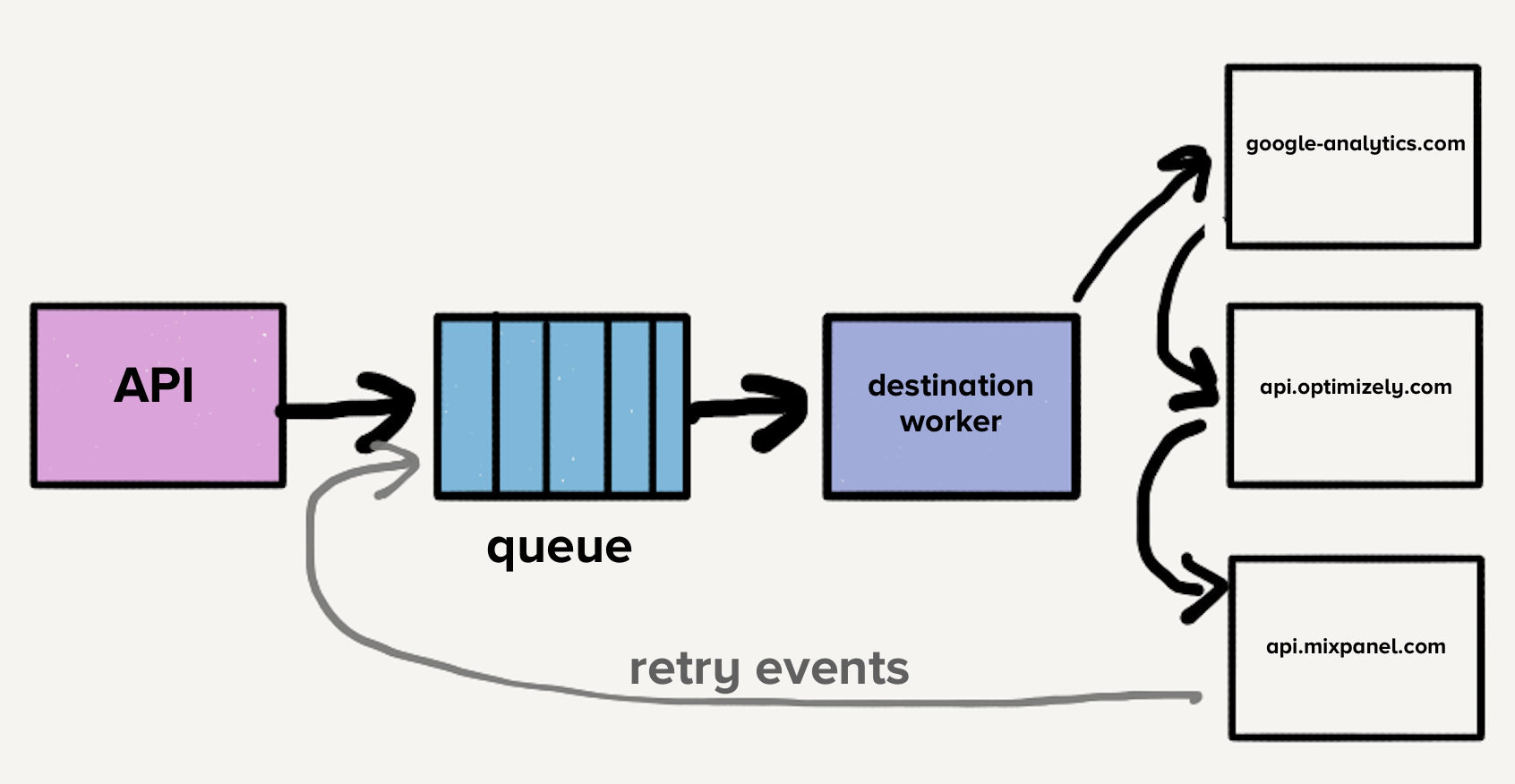
At this stage, the only queue contained both new events and those that may have had several retries in all directions, which led to blocking at the beginning of the queue. In this case, if one destination slowed down or fell, the queue will be filled with retries, which will lead to delays in all directions.
Imagine that direction X is experiencing temporary problems and each request ends with a timeout error. Now, this not only creates a large backlog of requests that have not yet reached X, but every unsuccessful event returns to be sent to the queue again. Although our systems automatically scale in response to an increase in load, a sudden increase in queue depth is ahead of our ability to scale, leading to delays for new events. Delivery time for all destinations will increase, since a brief failure has occurred on direction X. Customers rely on timely delivery, so we cannot afford to wait longer anywhere on our pipeline.

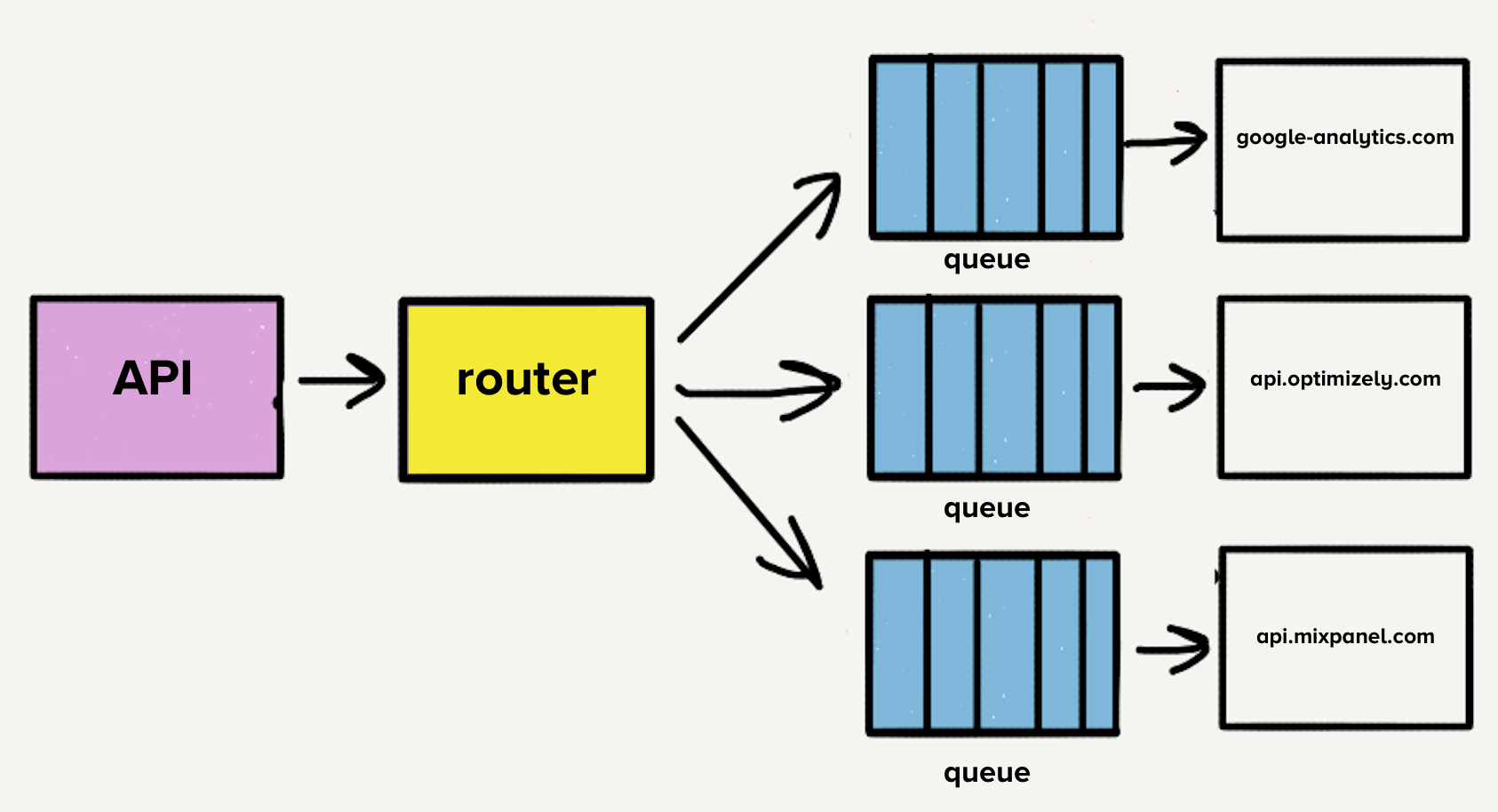
To solve the problem with blocking the start of the queue, the team created separate services and queues for each direction. The new architecture contained an additional process router that receives the incoming event and distributes its copy for each selected destination. Now, if one direction has problems, only its line will be stopped, and no other addressees will be affected. This microservice-style architecture isolated some directions from others, which is important when one destination experiences problems, as is often the case.
Each referral API uses a different request format, requiring additional code to translate the event according to this format. A simple example - assigning X requires sending a birth date as
Many modern endpoints have adopted the Segment query format, which makes some conversions relatively simple. However, these conversions can be very complex depending on the structure of the destination API. For example, for some of the oldest and most extensive destination points, we manually generate XML with values.
Initially, when assignments were divided into services, the entire code lived in one repository. A huge disappointment was that one broken test caused a drop in tests in all directions. When we wanted to deploy a change, it took time to correct a broken test, even if the changes had nothing to do with the original state. In response to this problem, it was decided to break the code for each assignment into their own repositories. All destinations were already broken into their own services, so the transition was natural.
The division into separate repositories allowed us to easily isolate the test directions. This isolation allowed the development team to quickly switch during support.
Over time, we added over 50 new destinations and this meant 50 new repositories. To ease the burden of developing and maintaining these code bases, we created libraries to do common transformations and functionality, such as processing HTTP requests, more uniformly in our areas.
For example, if we need a user name from an event, it
Shared libraries allow you to quickly create new directions. Familiarity with a single form of overall functionality made support less painful.
However, a new problem has arisen. Testing and deploying changes to these shared libraries has affected all of our areas. It began to require considerable time and effort for support. Making changes to improve our libraries, knowing that we would have to test and deploy dozens of services, was a risky proposition. With tight deadlines, engineers had to include updated versions of these libraries in the code base of one direction.
Over time, the versions of these shared libraries began to differ in directions codes. The great advantage that we once had from turning down the settings for each destination turned in the opposite direction. As a result, each of them had its own versions of shared libraries. We could create tools to automate the deployment of changes, but at this stage not only the productivity of the developers was suffering, but we also began to face other problems associated with the microservice architecture.
An additional problem is that each service experiences a different load. Some services processed several events per day, while others processed thousands of events per second. For destinations that have handled a small number of events, the operator would have to manually scale the service in the event of a sudden surge in load.
Although we had automatic scaling, each service had a clear combination of memory and processor resource requirements, which made the auto-scaling tincture more art than science.
The number of referrals continued to grow rapidly, with the team adding an average of three per month, which meant more repositories, more queues and more services. Thanks to the microservice architecture, our operating expenses increased linearly with each added direction. Therefore, we decided to take a step back and rethink our entire development process.
The first item on the list was the union of more than 140 services into one. Managing these services created a huge overhead for our team. We literally lost sleep when it became the norm for a support engineer to receive notifications about load peaks.
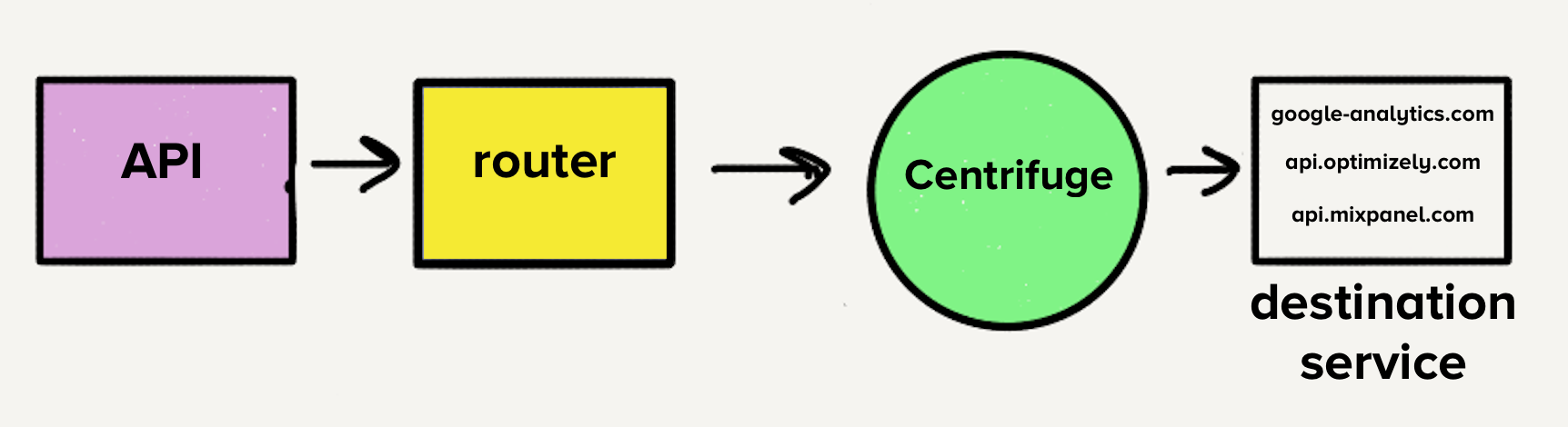
However, the architecture at that time would make the transfer to a single service a whole test. With separate queues for assignments, each handler would have to check all the queues for work, which would add complexity to assignment services with which we were uncomfortable. This was the main inspiration for Centrifuge . Centrifuge will replace all our individual queues and will be responsible for sending events to a single monolithic service.
Taking into account that there will be only one service, it makes sense to move the code of all directions into one repository, which means merging all the different dependencies and tests into one repository. We knew that there would be a mess.
For each of the 120 unique dependencies, we decided to take one version for all our destinations. When we transferred directions we checked their dependencies and updated to the latest versions. We also fixed everything that broke in them after updating to new versions.
With this transition, you no longer need to keep track of differences between dependency versions. All our directions used the same version, which significantly reduced the complexity of the entire code base. Supporting referrals has now become less time consuming and less risky.
We also needed a test suite that would allow all the direction tests to be run quickly and easily. Running all the tests was one of the main blocking factors in creating updates for libraries, which we discussed earlier.
Fortunately, all the test directions had a similar structure. They had basic unit tests to check the correctness of our transformation logic and to perform HTTP requests to partner endpoints to check that all events appear at destinations as expected.
Recall that the initial motivation for dividing the code base of each direction into separate repositories was test failures. However, it turned out that this is a false advantage. Tests that made HTTP requests still fell with some frequency. When the referrals were divided into their own repositories, there was little motivation for clearing off the falling tests. This poor hygiene has led to a constant source of frustration and technical debt. Often, a small change that should have taken an hour or two required from a few days to a week to complete.
Outgoing HTTP requests to destination endpoints during the test run were the main source of the crash. We also knew from experience that some endpoints were much slower than others. Some directions took up to 5 minutes to run their tests. With more than 140 tracks, our test suite could take up to an hour to complete.
To solve these problems, we created Traffic Recorder. Traffic Recorder compiled based on yakbak, and is responsible for recording and saving test recipient traffic. Whenever a test is performed for the first time, any requests and their corresponding responses are written to the file. On subsequent test runs, the request and response are reproduced from the file instead of executing the request for the intended purpose. These files are added to the repository so that the tests are consistent with each change. Now that the test suite no longer depends on HTTP requests over the Internet, our tests have become significantly more stable and mandatory for migration to a single repository.
I remember having passed tests for each destination for the first time after we integrated Traffic Recorder. It took milliseconds to complete the tests for all 140+ of our areas. Previously, only one item could take a couple of minutes.It was like magic.
When the code for all directions is in one repository, they can be combined into one service. Due to the fact that each direction is in the same service, the productivity of our developers has improved significantly. We no longer need to deploy 140+ services when changing one of the shared libraries. One engineer can deploy a service in minutes.
Proof was an increase in speed. In 2016, when our microservice architecture still existed, we made 32 improvements to shared libraries. This year alone we made 46. We have made more library improvements in the last 6 months than in all of 2016.
This change also benefited our operational history. With all the directions located in the same service, we have a good mix of memory and processor usage, which makes scaling much easier. A large pool of handlers can smooth load peaks, because we no longer have areas that handle small volumes.
The transfer of our microservice architecture to the monolith as a whole was a huge improvement, however, it came to compromise:
Our initial microservice architecture worked for some time, solving the direct performance problems of our working process by isolating directions from each other. However, we were not configured to scale. We lacked the right tools for testing and deploying microservices when a massive update was needed. As a result, the productivity of our developers has decreased dramatically.
The transition to the monolith allowed us to save the development process from operational problems, significantly increasing the productivity of developers. We did not make this transition frivolously, although we knew that there are things that need to be considered if this works.
When choosing between microservices or monolith, various factors should be considered. In some parts of our infrastructure, microservices work well, but our server directions are a great example of how a popular trend can hurt productivity and performance. It turns out the solution for us was a monolith.
In short, microservices are a service-oriented software architecture in which server-side applications are built by combining multiple single-task, minimal network services. Benefits include improved modularity, simplified testing, better functional composition, isolation of the environment, and autonomy of development teams. The opposite is a monolithic architecture, where a large amount of functionality is located in one service, in which testing, deployment and scaling occur as a whole.
In early 2017, we reached a turning point with the main part of our Segment product.. It looked as if we were falling from the microservice tree, hitting each branch on the way down. Instead of developing faster, the small team is immersed in increasing complexity. The significant advantages of this architecture have become a burden. As our speed dropped, the number of defects increased.
As a result, the team was unable to succeed with three full-time engineers who spend most of their time simply maintaining the system. Something had to change. This post is a story about how we took a step back and adopted an approach that fit our requirements and needs of the team well.
Why microservices worked worked
Infrastructure Data Segment customer receives hundreds of thousands of events per second, and forwards them to the partner API, what we call the directions on the server side (server-side destinations). There are more than one hundred types of these directions, such as Google Analytics, Optimizely, or custom web hooks.
Years ago, when the product was originally launched, the architecture was simple. There was an API that received events and sent them to a queue of distributed messages. The event in this case was a JSON object generated by a web or mobile application containing information about users and their actions. An example of the payload was as follows:
{
"type": "identify",
"traits": {
"name": "Alex Noonan",
"email": "anoonan@segment.com",
"company": "Segment",
"title": "Software Engineer"
},
"userId": "97980cfea0067"
}When the event was received from the queue, a client-controlled setting was checked that determined which directions it was intended for. Then the event was sent to each recipient API, one by one, which was convenient, since developers had to send their event to a single endpoint - the Segment API, rather than creating potentially dozens of integrations. Segment handled the request for each destination endpoint.
If one of the requests to the recipient fails, sometimes we try to send this event later. Some failures are safe to resend, some are not. Errors that can be sent later are those that can potentially be accepted by the destination without changes. For example, HTTP 500, limits and timeouts. Errors that are not sent again are those in which we are sure that they will not be accepted by the destination points. For example, the request contains invalid data or missing required fields.
At this stage, the only queue contained both new events and those that may have had several retries in all directions, which led to blocking at the beginning of the queue. In this case, if one destination slowed down or fell, the queue will be filled with retries, which will lead to delays in all directions.
Imagine that direction X is experiencing temporary problems and each request ends with a timeout error. Now, this not only creates a large backlog of requests that have not yet reached X, but every unsuccessful event returns to be sent to the queue again. Although our systems automatically scale in response to an increase in load, a sudden increase in queue depth is ahead of our ability to scale, leading to delays for new events. Delivery time for all destinations will increase, since a brief failure has occurred on direction X. Customers rely on timely delivery, so we cannot afford to wait longer anywhere on our pipeline.
To solve the problem with blocking the start of the queue, the team created separate services and queues for each direction. The new architecture contained an additional process router that receives the incoming event and distributes its copy for each selected destination. Now, if one direction has problems, only its line will be stopped, and no other addressees will be affected. This microservice-style architecture isolated some directions from others, which is important when one destination experiences problems, as is often the case.
The case of individual repositories
Each referral API uses a different request format, requiring additional code to translate the event according to this format. A simple example - assigning X requires sending a birth date as
traits.dob, while our API accepts traits.birthday. The conversion code for assignment X would look something like this:const traits = {}
traits.dob = segmentEvent.birthdayMany modern endpoints have adopted the Segment query format, which makes some conversions relatively simple. However, these conversions can be very complex depending on the structure of the destination API. For example, for some of the oldest and most extensive destination points, we manually generate XML with values.
Initially, when assignments were divided into services, the entire code lived in one repository. A huge disappointment was that one broken test caused a drop in tests in all directions. When we wanted to deploy a change, it took time to correct a broken test, even if the changes had nothing to do with the original state. In response to this problem, it was decided to break the code for each assignment into their own repositories. All destinations were already broken into their own services, so the transition was natural.
The division into separate repositories allowed us to easily isolate the test directions. This isolation allowed the development team to quickly switch during support.
Scaling microservices and repositories
Over time, we added over 50 new destinations and this meant 50 new repositories. To ease the burden of developing and maintaining these code bases, we created libraries to do common transformations and functionality, such as processing HTTP requests, more uniformly in our areas.
For example, if we need a user name from an event, it
event.name()can be called from a code in any direction. The shared library checks the event for the presence of properties nameand Name. If they do not exist, it checks the properties of firstName, first_nameand FirstName. It does the same for the last name, checking the cases and combining them to form the full name.Identify.prototype.name = function() {
var name = this.proxy('traits.name');
if (typeof name === 'string') {
return trim(name)
}
var firstName = this.firstName();
var lastName = this.lastName();
if (firstName && lastName) {
return trim(firstName + ' ' + lastName)
}
}Shared libraries allow you to quickly create new directions. Familiarity with a single form of overall functionality made support less painful.
However, a new problem has arisen. Testing and deploying changes to these shared libraries has affected all of our areas. It began to require considerable time and effort for support. Making changes to improve our libraries, knowing that we would have to test and deploy dozens of services, was a risky proposition. With tight deadlines, engineers had to include updated versions of these libraries in the code base of one direction.
Over time, the versions of these shared libraries began to differ in directions codes. The great advantage that we once had from turning down the settings for each destination turned in the opposite direction. As a result, each of them had its own versions of shared libraries. We could create tools to automate the deployment of changes, but at this stage not only the productivity of the developers was suffering, but we also began to face other problems associated with the microservice architecture.
An additional problem is that each service experiences a different load. Some services processed several events per day, while others processed thousands of events per second. For destinations that have handled a small number of events, the operator would have to manually scale the service in the event of a sudden surge in load.
Although we had automatic scaling, each service had a clear combination of memory and processor resource requirements, which made the auto-scaling tincture more art than science.
The number of referrals continued to grow rapidly, with the team adding an average of three per month, which meant more repositories, more queues and more services. Thanks to the microservice architecture, our operating expenses increased linearly with each added direction. Therefore, we decided to take a step back and rethink our entire development process.
Disposal of microservices and queues
The first item on the list was the union of more than 140 services into one. Managing these services created a huge overhead for our team. We literally lost sleep when it became the norm for a support engineer to receive notifications about load peaks.
However, the architecture at that time would make the transfer to a single service a whole test. With separate queues for assignments, each handler would have to check all the queues for work, which would add complexity to assignment services with which we were uncomfortable. This was the main inspiration for Centrifuge . Centrifuge will replace all our individual queues and will be responsible for sending events to a single monolithic service.
Moving to the mono-repository
Taking into account that there will be only one service, it makes sense to move the code of all directions into one repository, which means merging all the different dependencies and tests into one repository. We knew that there would be a mess.
For each of the 120 unique dependencies, we decided to take one version for all our destinations. When we transferred directions we checked their dependencies and updated to the latest versions. We also fixed everything that broke in them after updating to new versions.
With this transition, you no longer need to keep track of differences between dependency versions. All our directions used the same version, which significantly reduced the complexity of the entire code base. Supporting referrals has now become less time consuming and less risky.
We also needed a test suite that would allow all the direction tests to be run quickly and easily. Running all the tests was one of the main blocking factors in creating updates for libraries, which we discussed earlier.
Fortunately, all the test directions had a similar structure. They had basic unit tests to check the correctness of our transformation logic and to perform HTTP requests to partner endpoints to check that all events appear at destinations as expected.
Recall that the initial motivation for dividing the code base of each direction into separate repositories was test failures. However, it turned out that this is a false advantage. Tests that made HTTP requests still fell with some frequency. When the referrals were divided into their own repositories, there was little motivation for clearing off the falling tests. This poor hygiene has led to a constant source of frustration and technical debt. Often, a small change that should have taken an hour or two required from a few days to a week to complete.
Build Resilient Test Sets
Outgoing HTTP requests to destination endpoints during the test run were the main source of the crash. We also knew from experience that some endpoints were much slower than others. Some directions took up to 5 minutes to run their tests. With more than 140 tracks, our test suite could take up to an hour to complete.
To solve these problems, we created Traffic Recorder. Traffic Recorder compiled based on yakbak, and is responsible for recording and saving test recipient traffic. Whenever a test is performed for the first time, any requests and their corresponding responses are written to the file. On subsequent test runs, the request and response are reproduced from the file instead of executing the request for the intended purpose. These files are added to the repository so that the tests are consistent with each change. Now that the test suite no longer depends on HTTP requests over the Internet, our tests have become significantly more stable and mandatory for migration to a single repository.
I remember having passed tests for each destination for the first time after we integrated Traffic Recorder. It took milliseconds to complete the tests for all 140+ of our areas. Previously, only one item could take a couple of minutes.It was like magic.
Why does the monolith work
When the code for all directions is in one repository, they can be combined into one service. Due to the fact that each direction is in the same service, the productivity of our developers has improved significantly. We no longer need to deploy 140+ services when changing one of the shared libraries. One engineer can deploy a service in minutes.
Proof was an increase in speed. In 2016, when our microservice architecture still existed, we made 32 improvements to shared libraries. This year alone we made 46. We have made more library improvements in the last 6 months than in all of 2016.
This change also benefited our operational history. With all the directions located in the same service, we have a good mix of memory and processor usage, which makes scaling much easier. A large pool of handlers can smooth load peaks, because we no longer have areas that handle small volumes.
Compromises
The transfer of our microservice architecture to the monolith as a whole was a huge improvement, however, it came to compromise:
- Fault tolerance is difficult. When everything works in the monolith, if there is a bug in one direction, which leads to a drop in service, the service will fall in all directions. We have comprehensive automatic testing, but tests can still fail. We are currently working on a much more reliable way to prevent one destination from destroying the entire service, while keeping the remaining directions working in the monolith.
- Memory caching is less efficient. Previously, with a single service for routing low-traffic routes, there were only a few processes, which meant that their cache in memory remained hot. Now the cache is finely distributed between 3000+ processes, so the chances of getting into it are much less. We could use something like Redis to solve this problem, but it would add another scaling point. In the end, we took this loss of efficiency in the light of significant operational advantages.
Conclusion
Our initial microservice architecture worked for some time, solving the direct performance problems of our working process by isolating directions from each other. However, we were not configured to scale. We lacked the right tools for testing and deploying microservices when a massive update was needed. As a result, the productivity of our developers has decreased dramatically.
The transition to the monolith allowed us to save the development process from operational problems, significantly increasing the productivity of developers. We did not make this transition frivolously, although we knew that there are things that need to be considered if this works.
- We needed a comprehensive test package to put everything in just one repository. Without this, we would be in the same situation when we initially wanted to break them. Constant failing tests harmed our productivity in the past, and we didn’t want this to happen again.
- We accepted the compromises inherent in the monolithic architecture, and made sure that we had a good foundation associated with each. We had to make some sacrifices in connection with these changes.
When choosing between microservices or monolith, various factors should be considered. In some parts of our infrastructure, microservices work well, but our server directions are a great example of how a popular trend can hurt productivity and performance. It turns out the solution for us was a monolith.