About industrial systems for mass input, image processing and text recognition EMC Captiva InputAccel and Kofax Capture
In the realities of Russian legislation, due to the lack of legal rules for doing business electronically (paperless), accounting should create and store a very large number of paper documents (primary financial documents (invoices, invoices, invoices, etc.), transaction and transaction logs, personnel documents and other).
To reduce processing and storage costs, medium and large companies have resorted to the use of automated systems for mass input and processing. The products of the following software vendors are widely known and used in the market: EMC, Kofax, Abbyy, Cognitive Technologies.
Over the past year, I managed to fully understand many secrets of this interesting area of business automation using EMC Captiva and Kofax Capture systems, which I want to talk about in this article.
Both manufacturers promote their products under the definition of "Mass Input Systems" and not as text recognition systems, and this is no accident. The thing is that recognizing text as such is just a small task, of all that these systems can implement.
To begin with, the processing at Kofax and Captiva is the same principle: step by step. One processing step is to conditionally launch one separate .exe, which produces certain specified actions. To create the so-called "process" there are special designers in which you set the sequence of steps and routing rules.
In a general scenario, the recognition process looks something like this:

The figure shows that the document is being processed sequentially from its preparation (separating sheets, removing paper clips), then capturing (scanning), recognition and indexing (extracting certain parts of the text), then user verification (right there partial or full manual indexing), formation new output format (if necessary) and export from the processing system.
Since the source can be not only a scanner, but also a file system, facsimile systems, e-mail, web services and other systems, there can be other steps in processing (improving the image, rotations, smoothing, converting), checking the indexed values can be automatic and exports can take place both on the file system to any ERP, CRM and prochine system, sent by e-mail and other means, it is advisable to introduce the processing structure as follows:
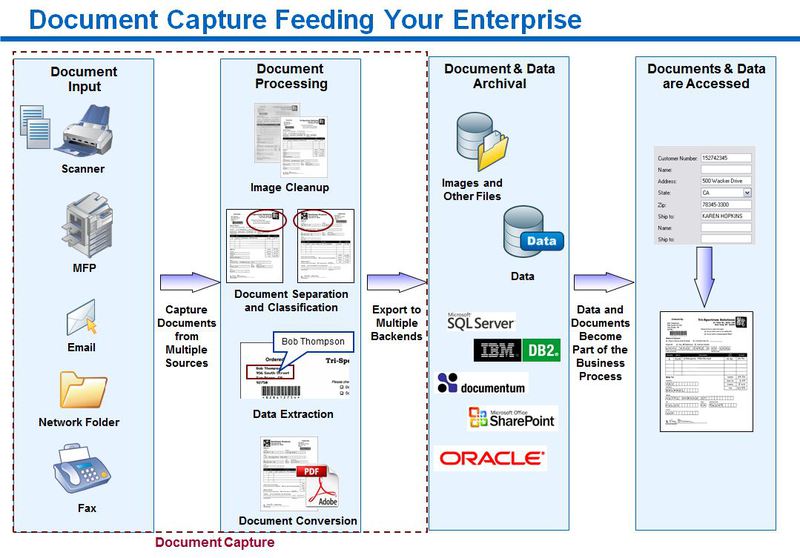
Logically arr system Botko appear as separate processes running, which interacts with the central server that is responsible for the pre-configured routing process:
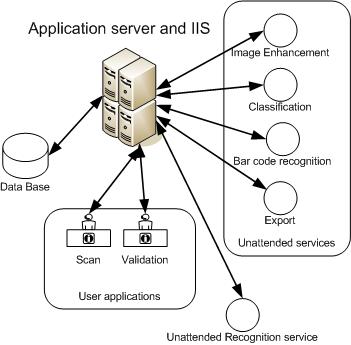
The system is built according to the modular architecture and consists of the following main components (For example, Kofax Capture):
A database consists of a relational database itself and a directory on a file system, usually expanded over a network that stores artifacts of step-by-step processing of documents.
The server routes documents by steps and modules.
Unmanaged modules work in the background without user intervention, for example, a recognition module.
Client modules such as 'Scan' or 'Indexing' are the main user interface of the system.
Administration is done in the Batch Administrator module for Kofax or the Administrative console for Captiva.
For both systems, there is scaling, both vertical and horizontal. Services can be launched on the same computer or distributed in different ways in order to increase productivity, run multiple times (within the framework of available licenses), which is why the Recognition service is separated from other services in this scheme, because most resources are required.
The quality of the input image can be low (the minimum typical requirement is 300dpi, 1 bit per pexel - black & white), contain artifacts, spots, blurring and other noises, therefore, preprocessing is usually used, which can significantly change image quality and improve recognition quality. EMC uses PixTools components, Kofax uses its VirtualReScan development.
Original image before processing

Image after processing
An important step - Classification (determining the type and form of a pre-configured document). A document can be determined either by graphic content, or by the presence of keywords or in a mixed way. It is also possible to classify “in code” - for example, when a document was received through a web service through an accounting system and its type is known in advance.
For recognition of the text, different recognition engines can be used, which are supplied with the basic set of products, however, most of them use the engine from Abbyy, as It gives high quality recognition of Russian printed text. Handwriting is difficult to recognize, so usually such documents, if any, are not recognized, and a limited number of fields are indexed by the operator on them.
It is important to note that the basic set of Captiva InputAccel, as well as Kofax Capture, allows indexing only strictly formal documents, for example, bank profiles, where the text fields are pre-set and when we extract, we will always know for sure where to look. For processing weakly and unstructured documents, it is necessary to use additional modules Captiva Dispatcher or Kofax Transformation Modules. In this case, full-page recognition of the text occurs and in most cases the principle of finding fields by regular expressions in conjunction with the position of the "anchor" sections is used (anchor words can also be detected by regular expressions or hard patterns). The same modules are necessary if you are going to process tabular parts of documents, which, by the way,
Comparison of system components
Licensing for products is about the same, all licenses are competing, i.e. for the number of active connections. You buy the volume of pages per year that you are going to process, such a license can be renewable (the counter is reset once a year) and non-renewable. It is also necessary to additionally purchase licenses for modules, for example, in the Captiva delivery only one scanner place and all the rest need to be purchased separately.
In Russia, the EMC Captiva system is most common, Kofax is rarely used.
If you are interested in continuing, then I can describe in detail the process of developing and setting up processes and recognition templates based on the EMC Captiva platform.
To reduce processing and storage costs, medium and large companies have resorted to the use of automated systems for mass input and processing. The products of the following software vendors are widely known and used in the market: EMC, Kofax, Abbyy, Cognitive Technologies.
Over the past year, I managed to fully understand many secrets of this interesting area of business automation using EMC Captiva and Kofax Capture systems, which I want to talk about in this article.
Both manufacturers promote their products under the definition of "Mass Input Systems" and not as text recognition systems, and this is no accident. The thing is that recognizing text as such is just a small task, of all that these systems can implement.
To begin with, the processing at Kofax and Captiva is the same principle: step by step. One processing step is to conditionally launch one separate .exe, which produces certain specified actions. To create the so-called "process" there are special designers in which you set the sequence of steps and routing rules.
In a general scenario, the recognition process looks something like this:
The figure shows that the document is being processed sequentially from its preparation (separating sheets, removing paper clips), then capturing (scanning), recognition and indexing (extracting certain parts of the text), then user verification (right there partial or full manual indexing), formation new output format (if necessary) and export from the processing system.
Since the source can be not only a scanner, but also a file system, facsimile systems, e-mail, web services and other systems, there can be other steps in processing (improving the image, rotations, smoothing, converting), checking the indexed values can be automatic and exports can take place both on the file system to any ERP, CRM and prochine system, sent by e-mail and other means, it is advisable to introduce the processing structure as follows:
Logically arr system Botko appear as separate processes running, which interacts with the central server that is responsible for the pre-configured routing process:
The system is built according to the modular architecture and consists of the following main components (For example, Kofax Capture):
- Database
- Kofax Capture Server
- Unmanaged Processing Modules
- Client Modules
A database consists of a relational database itself and a directory on a file system, usually expanded over a network that stores artifacts of step-by-step processing of documents.
The server routes documents by steps and modules.
Unmanaged modules work in the background without user intervention, for example, a recognition module.
Client modules such as 'Scan' or 'Indexing' are the main user interface of the system.
Administration is done in the Batch Administrator module for Kofax or the Administrative console for Captiva.
For both systems, there is scaling, both vertical and horizontal. Services can be launched on the same computer or distributed in different ways in order to increase productivity, run multiple times (within the framework of available licenses), which is why the Recognition service is separated from other services in this scheme, because most resources are required.
The quality of the input image can be low (the minimum typical requirement is 300dpi, 1 bit per pexel - black & white), contain artifacts, spots, blurring and other noises, therefore, preprocessing is usually used, which can significantly change image quality and improve recognition quality. EMC uses PixTools components, Kofax uses its VirtualReScan development.
Original image before processing
Image after processing
An important step - Classification (determining the type and form of a pre-configured document). A document can be determined either by graphic content, or by the presence of keywords or in a mixed way. It is also possible to classify “in code” - for example, when a document was received through a web service through an accounting system and its type is known in advance.
For recognition of the text, different recognition engines can be used, which are supplied with the basic set of products, however, most of them use the engine from Abbyy, as It gives high quality recognition of Russian printed text. Handwriting is difficult to recognize, so usually such documents, if any, are not recognized, and a limited number of fields are indexed by the operator on them.
It is important to note that the basic set of Captiva InputAccel, as well as Kofax Capture, allows indexing only strictly formal documents, for example, bank profiles, where the text fields are pre-set and when we extract, we will always know for sure where to look. For processing weakly and unstructured documents, it is necessary to use additional modules Captiva Dispatcher or Kofax Transformation Modules. In this case, full-page recognition of the text occurs and in most cases the principle of finding fields by regular expressions in conjunction with the position of the "anchor" sections is used (anchor words can also be detected by regular expressions or hard patterns). The same modules are necessary if you are going to process tabular parts of documents, which, by the way,
Comparison of system components
| Emc captiva | Kofax | What is he doing |
|---|---|---|
| InputAccel Server | Server process, controls the life cycle of the process (batch) | |
| KNS, not necessarily if the whole process will go on one machine, does not require IIS | Networking | |
| InputAccel | Kofax capture | Basic processes, the ability to recognize only strictly structured documents, i.e. strict forms, profiles, etc. |
| Dispatcher | KTM | Configuring recognition templates for semi-structured documents and non-template texts (all Russian Finnish primary) |
| Freeform designer | No, integrated in KTM | Designer to configure complex recognition rules |
| Administration Console, Web application, requires IIS | No, no such need, built into Capture | Application for server configuration, process and batch management, licensing, etc. |
| eInput | KFS | Ability to work through a browser |
Licensing for products is about the same, all licenses are competing, i.e. for the number of active connections. You buy the volume of pages per year that you are going to process, such a license can be renewable (the counter is reset once a year) and non-renewable. It is also necessary to additionally purchase licenses for modules, for example, in the Captiva delivery only one scanner place and all the rest need to be purchased separately.
In Russia, the EMC Captiva system is most common, Kofax is rarely used.
If you are interested in continuing, then I can describe in detail the process of developing and setting up processes and recognition templates based on the EMC Captiva platform.