Practical tips for dividing data into parts. Generating PartitionKey and RowKey for Azure Table Storage
Hello. Here is the final article from the series "Internal structure and architecture of the AtContent.com service". Here are the best practices from our experience with Azure Table Storage and the platform as a whole. This article can be a starting point for building typical data structures and allow you to more efficiently use the resources of Windows Azure.
Horizontal scaling relies heavily on data sharing, and Windows Azure is no exception. One of the components of the platform is the Azure Storage Table, a NoSQL database with unlimited growth. But many developers ignore it in favor of the familiar and familiar SQL. At the same time, tasks are often solved using the Azure Storage Table much more efficiently than using Azure SQL.
Here you will find practice and use case studies for Azure Storage Tables.
The most common use case is storing lists. It fits perfectly with the Azure Storage Tables architecture. Lists can be very different, but the most commonly used are records by date.
The first thing you should pay attention to when working is how the values are selected from the table. There are several features:
You should always remember about sampling in parts, because Table Storage can return any number of records and a continuation token. Although most often this happens when there are more than 1000 records. There is a mechanism in the SDK that allows you to process this automatically, so you should not worry very much about it. It is only necessary to remember that each request is an additional transaction. If you have a 2001 record in the sample, there will be at least 3 accesses to the repository.
You also need to remember PartitionKey. This is a very important key that is responsible for dividing data into sections. If you do not specify it in the request, then the cloud storage will have to poll all sections and then collect the data in one set. In this case, different sections can be located on different servers. And this will not add performance to your requests. In addition, it will increase the number of transactions to the repository.
And finally, the least obvious feature is the selection of records by condition. It was experimentally found that if you specify the condition "less" or "less than or equal to" for the RowKey, then the selected values will go from the minimum to one that will satisfy the condition. In this case, the order of the returned records will be from smaller to larger. That is, if you have 10,000 records in the table that satisfy the condition, and you only need the first 100, for which the RowKey is less than a certain value, then the store will select 100 records from the minimum RowKey value for you.
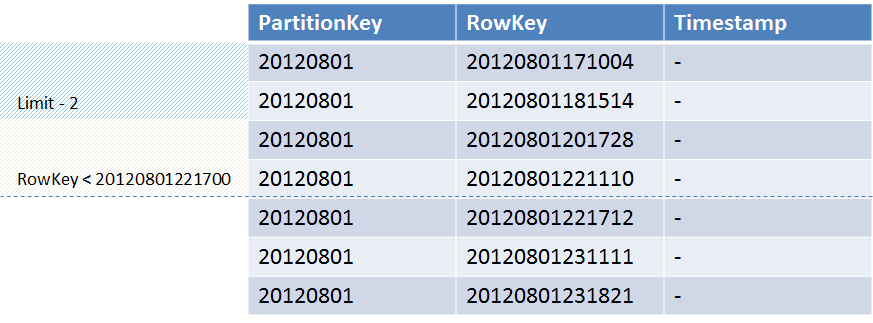
As an example, consider a table in which there are several records with the key RowKey from the date. And we need to select 2 records for which RowKey is less than 20120801221700. We expect the store to return records with the keys “20120801221110” and “20120801201728”. But in accordance with the sorting order, the store will return the values “20120801171004” and “20120801181514”.
You can overcome this by using an inverted key. So, in the case of date, this is DateTime.MaxValue - CurrentDateTime. Then, when sampling, the opposite condition will be used and it will work correctly.
When designing the application, you should focus on the recommendations that Microsoft gives regarding the Storage Table ( http://msdn.microsoft.com/en-us/library/windowsazure/hh508997.aspx ). The meaning of these recommendations is very simple. Design your applications so that there are not too many, and not too few, keys for partitions. And also, so that there are not too many entries in each section. It is advisable that they be distributed across sections evenly. If it is possible to predict the load on partitions, then partitions that will fit in with a higher load should be filled with fewer entries. Based on the Storage Tables architecture, partitions that are under heavy load are automatically replicated. And the smaller the partition size, the faster replication will occur.
During development, we faced the problem of selecting partition keys for a table in which data is stored for user identification and authentication. Since we identify the user primarily by email, it was necessary to choose a system by which they would be distributed among sections. After conducting a little experiment, it was found that a good uniform distribution gives the MD5 hash and the subsequent allocation of part of the bits from the hash to determine the partition number.
Here is such a simple code that will allow you to get the required number of bits from the MD5 hash and use from as the section number:
This method, like many others, is available as part of CPlaseEngine, a link to which can be found at the end of the article.
Subsequently, we expanded this practice to other parts of our system, and it showed itself from a very good side. Although in some cases it is more profitable to divide into sections by user ID. Or in terms of user ID. This allows you to build queries to select data for a specific user. At the same time, requests are effective in the sense that you have to choose from one section.
As you can see earlier, often the key for writing is associated with some date. Most often the date of creation. In our system, this is very common. And this is very effective for records, from which you later need to get a list starting from some date.
Naturally, the record key must be unique. This uniqueness should be for the pair “partition key” - “record key”. Therefore, when generating a key, it is safest to add a few random characters to it.
If you plan to choose records in the form of lists, then the general recommendation for generating a record key is to associate it with the parameter with respect to which you will build the list. So, for example, if you are building a list of values by dates, it is best to use the date when generating the key.
The practice of dividing by a hash of a key can be applied not only to Table Storage. It extends very well to the file system. When caching entities from Table Storage to the cache on an instance, we also use hash partitioning from the file path.
Horizontal scaling is closely related to data sharing, and the more efficiently you separate data, the more efficient the system as a whole will work. Windows Azure as a platform provides a very powerful infrastructure for building reliable, scalable, fault-tolerant services. But at the same time, do not forget that in order to build such services, the internal architecture must comply with the principles of building highly loaded systems.
I also want to report with pleasure that our OpenSource project CPlaseEngine has appeared in the public domain on CodePlex. It contains tools that will allow you to develop services on the Windows Azure platform more efficiently. You can download it at https://cplaseengine.codeplex.com/ .
Read in the series:
Horizontal scaling relies heavily on data sharing, and Windows Azure is no exception. One of the components of the platform is the Azure Storage Table, a NoSQL database with unlimited growth. But many developers ignore it in favor of the familiar and familiar SQL. At the same time, tasks are often solved using the Azure Storage Table much more efficiently than using Azure SQL.
Here you will find practice and use case studies for Azure Storage Tables.
In general about Azure Table Storage
The most common use case is storing lists. It fits perfectly with the Azure Storage Tables architecture. Lists can be very different, but the most commonly used are records by date.
The first thing you should pay attention to when working is how the values are selected from the table. There are several features:
- Values are selected in parts of no more than 1000 values;
- Partitioning without a partition key (PartitionKey) is very slow;
- When choosing a range of values by key, the condition "less than or equal to" is correctly triggered;
You should always remember about sampling in parts, because Table Storage can return any number of records and a continuation token. Although most often this happens when there are more than 1000 records. There is a mechanism in the SDK that allows you to process this automatically, so you should not worry very much about it. It is only necessary to remember that each request is an additional transaction. If you have a 2001 record in the sample, there will be at least 3 accesses to the repository.
You also need to remember PartitionKey. This is a very important key that is responsible for dividing data into sections. If you do not specify it in the request, then the cloud storage will have to poll all sections and then collect the data in one set. In this case, different sections can be located on different servers. And this will not add performance to your requests. In addition, it will increase the number of transactions to the repository.
And finally, the least obvious feature is the selection of records by condition. It was experimentally found that if you specify the condition "less" or "less than or equal to" for the RowKey, then the selected values will go from the minimum to one that will satisfy the condition. In this case, the order of the returned records will be from smaller to larger. That is, if you have 10,000 records in the table that satisfy the condition, and you only need the first 100, for which the RowKey is less than a certain value, then the store will select 100 records from the minimum RowKey value for you.
As an example, consider a table in which there are several records with the key RowKey from the date. And we need to select 2 records for which RowKey is less than 20120801221700. We expect the store to return records with the keys “20120801221110” and “20120801201728”. But in accordance with the sorting order, the store will return the values “20120801171004” and “20120801181514”.
You can overcome this by using an inverted key. So, in the case of date, this is DateTime.MaxValue - CurrentDateTime. Then, when sampling, the opposite condition will be used and it will work correctly.
Partition Key Selection Practice
When designing the application, you should focus on the recommendations that Microsoft gives regarding the Storage Table ( http://msdn.microsoft.com/en-us/library/windowsazure/hh508997.aspx ). The meaning of these recommendations is very simple. Design your applications so that there are not too many, and not too few, keys for partitions. And also, so that there are not too many entries in each section. It is advisable that they be distributed across sections evenly. If it is possible to predict the load on partitions, then partitions that will fit in with a higher load should be filled with fewer entries. Based on the Storage Tables architecture, partitions that are under heavy load are automatically replicated. And the smaller the partition size, the faster replication will occur.
During development, we faced the problem of selecting partition keys for a table in which data is stored for user identification and authentication. Since we identify the user primarily by email, it was necessary to choose a system by which they would be distributed among sections. After conducting a little experiment, it was found that a good uniform distribution gives the MD5 hash and the subsequent allocation of part of the bits from the hash to determine the partition number.
Here is such a simple code that will allow you to get the required number of bits from the MD5 hash and use from as the section number:
using System.Security.Cryptography;
using System.Text;
public static string GetHashMD5Binary(string Input, int BitCount = 128)
{
if (Input == null) return null;
byte[] MD5Bytes = MD5.Create().ComputeHash(
Encoding.Default.GetBytes(Input));
int Len = MD5Bytes.Length;
string Result = "";
int HasBits = 0;
for (int i = 0; i < Len; i++)
{
Result += Convert.ToString(MD5Bytes[i], 2).PadLeft(8, '0');
HasBits += 8;
if (HasBits >= BitCount) break;
}
if (BitCount < 1 || BitCount >= 128) return Result;
return Result.Substring(0, BitCount);
}
This method, like many others, is available as part of CPlaseEngine, a link to which can be found at the end of the article.
Subsequently, we expanded this practice to other parts of our system, and it showed itself from a very good side. Although in some cases it is more profitable to divide into sections by user ID. Or in terms of user ID. This allows you to build queries to select data for a specific user. At the same time, requests are effective in the sense that you have to choose from one section.
The practice of choosing keys for records
As you can see earlier, often the key for writing is associated with some date. Most often the date of creation. In our system, this is very common. And this is very effective for records, from which you later need to get a list starting from some date.
Naturally, the record key must be unique. This uniqueness should be for the pair “partition key” - “record key”. Therefore, when generating a key, it is safest to add a few random characters to it.
If you plan to choose records in the form of lists, then the general recommendation for generating a record key is to associate it with the parameter with respect to which you will build the list. So, for example, if you are building a list of values by dates, it is best to use the date when generating the key.
Distribution and generalization
The practice of dividing by a hash of a key can be applied not only to Table Storage. It extends very well to the file system. When caching entities from Table Storage to the cache on an instance, we also use hash partitioning from the file path.
Horizontal scaling is closely related to data sharing, and the more efficiently you separate data, the more efficient the system as a whole will work. Windows Azure as a platform provides a very powerful infrastructure for building reliable, scalable, fault-tolerant services. But at the same time, do not forget that in order to build such services, the internal architecture must comply with the principles of building highly loaded systems.
I also want to report with pleasure that our OpenSource project CPlaseEngine has appeared in the public domain on CodePlex. It contains tools that will allow you to develop services on the Windows Azure platform more efficiently. You can download it at https://cplaseengine.codeplex.com/ .
Read in the series:
- “ AtContent.com. Internal structure and architecture ”,
- " A mechanism for exchanging messages between roles and instances ",
- “ Caching data on an instance and managing caching ”,
- " Effective management of cloud-bursts (the Queue Azure) »,
- “ LINQ extensions for Azure Table Storage that implement Or and Contains operations .”