SolidFire - Storage for those who ** cking hate storage
There are more and more solutions that are moving away from the traditional approach of unified repositories. These are specialized storages, which are sharpened for the tasks of a specific business line. Earlier, I already talked about the Infinidat InfiniBox F2230 system. Today at the heart of my review of SolidFire.
 "Who f * cking hate storage" @Dave Hits, founder of NetApp
"Who f * cking hate storage" @Dave Hits, founder of NetApp
At the end of 2015, NetApp announced the purchase of a startup SolidFire, which was founded in 2010. Interest in these systems is due to their different approach to data warehouse management and predictable performance.
SolidFire solutions complemented the NetApp product line, which included All Flash FAS (AFF), EF and E series. It also enabled a year and a half to launch a new product on the market - NetApp HCI (Hyper Converged Infrastructure), which uses SolidFire as a storage subsystem.
Not so long ago, I already talked about the system Infinidat InfiniBox F2230which is great for service provider tasks. Today's contributor to our SolidFire review can also be attributed to this class of devices. SolidFire founder Dave Wright and his team came from RackSpace, where they developed an efficient storage system that would provide linear performance in a multi-user environment, while being simple, easily scalable, and with flexible automation capabilities. In an attempt to solve this problem, SolidFire was born.
Today, the SolidFire lineup consists of four models with different IOPS / TB ratios.

For data storage, 10 (MLC) SSDs are used, and the NVRAM is Radian RMS-200. True, there are already plans to switch to NVDIMM modules .

Here, interest is how SolidFire retrieves and stores data. We all know about the limited resource of SSD drives, so it is logical that for their maximum safety compression and deduplication should occur on the fly, before recording on the SSD. When SolidFire receives data from the host, it breaks it into 4K blocks, after which this block is compressed and stored in NVRAM. Then synchronous replication of this block in NVRAM to the “neighboring” cluster node occurs. After this, SolidFire obtains the hash of this compressed block and searches for this hash value in its index of stored data within the entire cluster. If a block with such a hash already exists, SolidFire updates only its metadata with a link to this block, if the block contains unique data, it is recorded on the SSD, and metadata is also written for it.
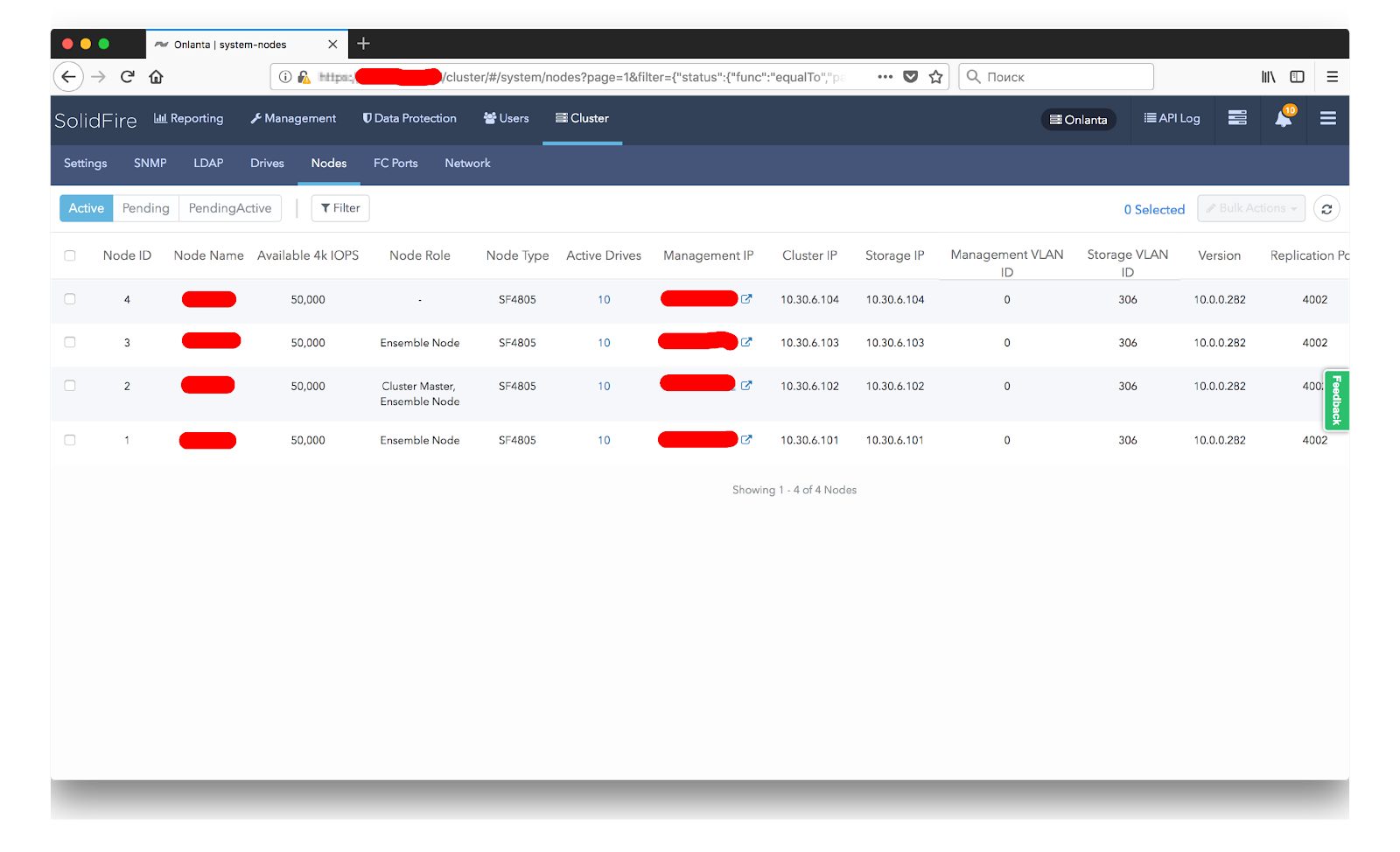 Our test cluster of four nodes
Our test cluster of four nodes
There are already rumors that this line will be updated soon. It is worth noting one very important thing - the SolidFire cluster is able to work with nodes both with different “IOPs / TB density” and unite nodes of different generations within one cluster. First, it makes the use of this system more predictable in terms of equipment support, and also facilitates the transition from old nodes to new ones when you simply add new ones and remove old ones from the cluster in real time (waiting only for the cluster to be rebuilt) without downtime. because There is support for both Scale Out and Scale Back.
SolidFire can come in three solutions:
As you can see from the table of characteristics, nodes support only an iSCSI connection, and for an FC connection there is a separate node type - Fabric Interconnect, which in turn contains four ports for FC data and four iSCSI ports for connection to the nodes, as well as 64GB of native system memory / cache for reading.

The performance table also indicates the performance of each node. This is one of those cases where you know the performance of your storage system at the buying stage. This performance is guaranteed (with a load profile of 4Kb, 80/20) per node.
Accordingly, buying a cluster of X nodes or expanding an existing solution, you understand how much and how much performance you will end up with. Of course, you can squeeze out more performance from each node under certain conditions, but this is not what this solution was designed for. If you want to get millions of IOPS in 2U on a single volume, you better turn your attention to other products, for example AFF. The greatest performance on SolidFire can be obtained with a large number of volumes and sessions.
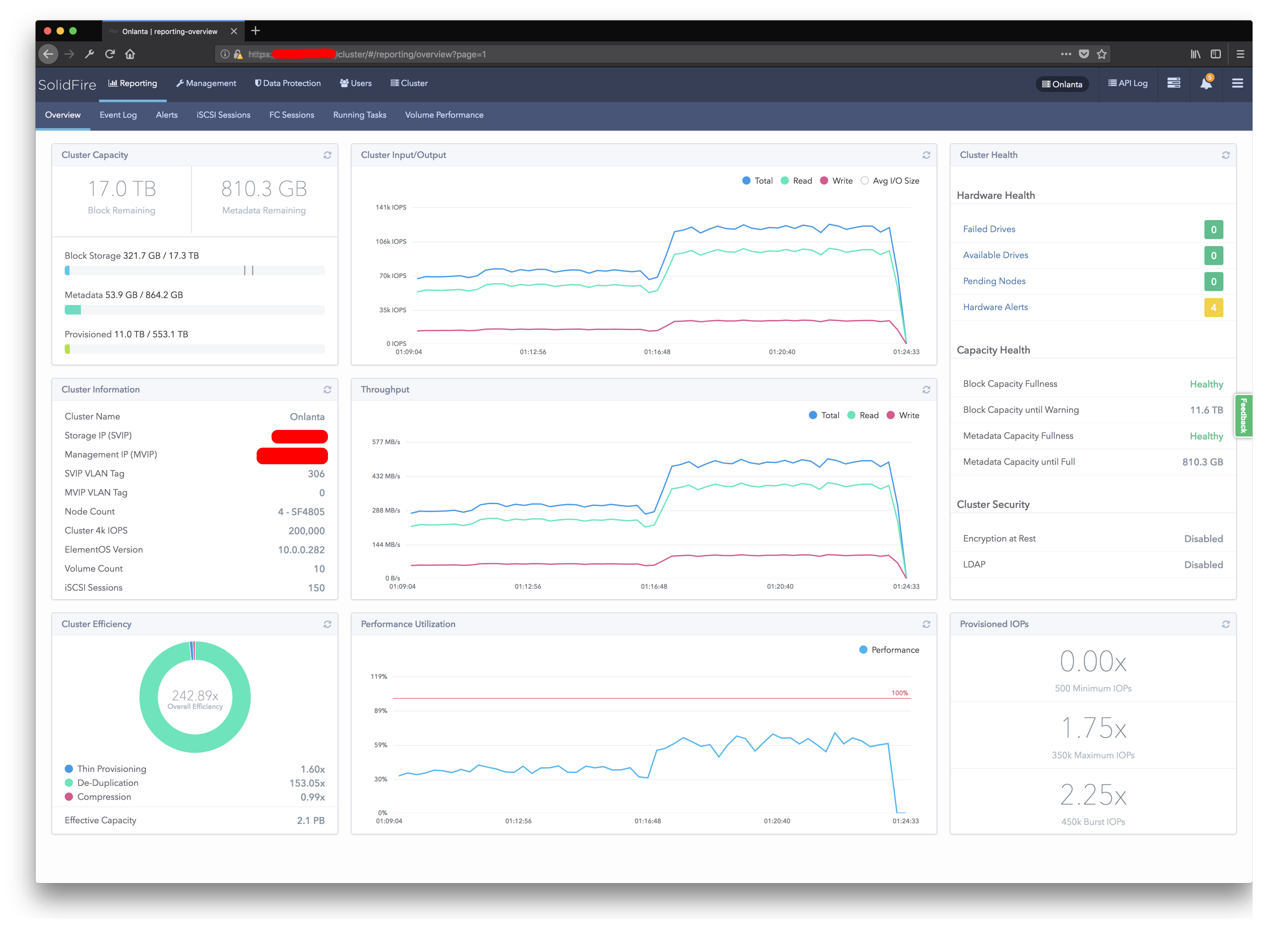 Main interface page
Main interface page
Managing storage is quite simple. In fact, we have two resource pools: volume and IOPS. Separating one of the types of resources and knowing their finite number, we clearly understand the other possibilities of our system. This again makes system expansion extremely easy. Need extra performance? We consider SF4805 or SF19210 with a “less dense” IOPS / TB ratio. Need volume? We look in the direction of SF9605 and SF38410, which provide less IOPS per Gb.
From the point of view of the storage system administrator, the system looks pretty boring. Things like deduplication and compression work by default.
Replication and snapshots are also available, and replication can be organized for the entire NetApp product line (except for the E-series). It is this simplicity, in my opinion, that is revealed for the quote of Dave Hits from the title of the article. Considering that this system assumes integration with various systems of dynamic resource allocation, without administrator participation and without additional labor costs, you will soon forget how the SolidFire interface looks. But we'll talk more about integration.
We are in "Onlanta"conducted load testing in order to verify the promised 200k IOPS. Not that we do not believe the vendor, but are accustomed to try everything yourself. We did not set ourselves the goal of squeezing out more from the system than was stated. We were also able to see for ourselves that the system gives a good result with a large number of threads. To do this, we organized 10 volumes of 1TB on SolidFire, on which we placed one test virtual machine. Already at the stage of preparation of the test environment, we were pleasantly surprised by the work of deduplication. Despite the fact that the scheme of his work is fairly standard, the quality of work within the cluster has proven to be extremely effective. The disks before the tests were filled with random data.
To make it faster, a block of 10 mb was generated, then it was filled. And on each virtual machine, this block was generated separately, i.e. In all machines, the pattern is different. From 10TB filled with data - the actual occupied space on the array was 4TB. The deduplication efficiency is 1: 2.5, with FAS using this approach, the inline deduplication efficiency tended to 0. We were able to get 190k IOPS with a response of ~ 1 ms on our test bench.
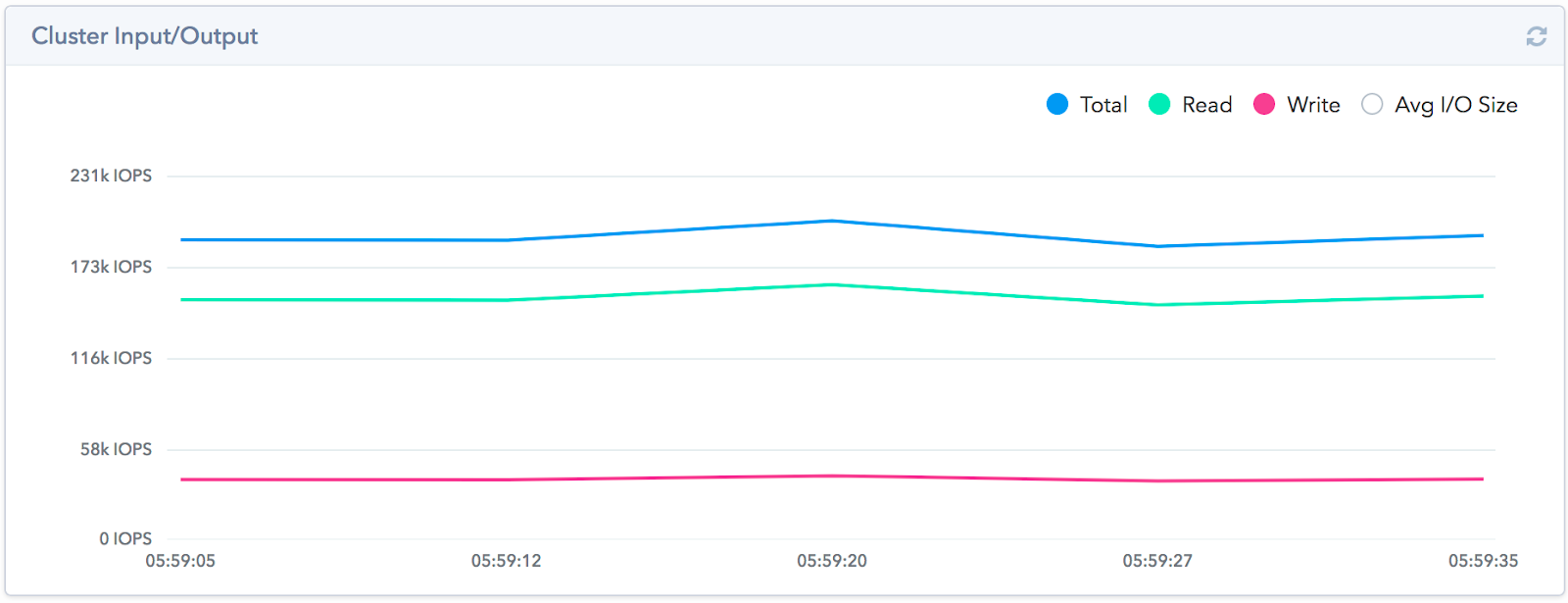
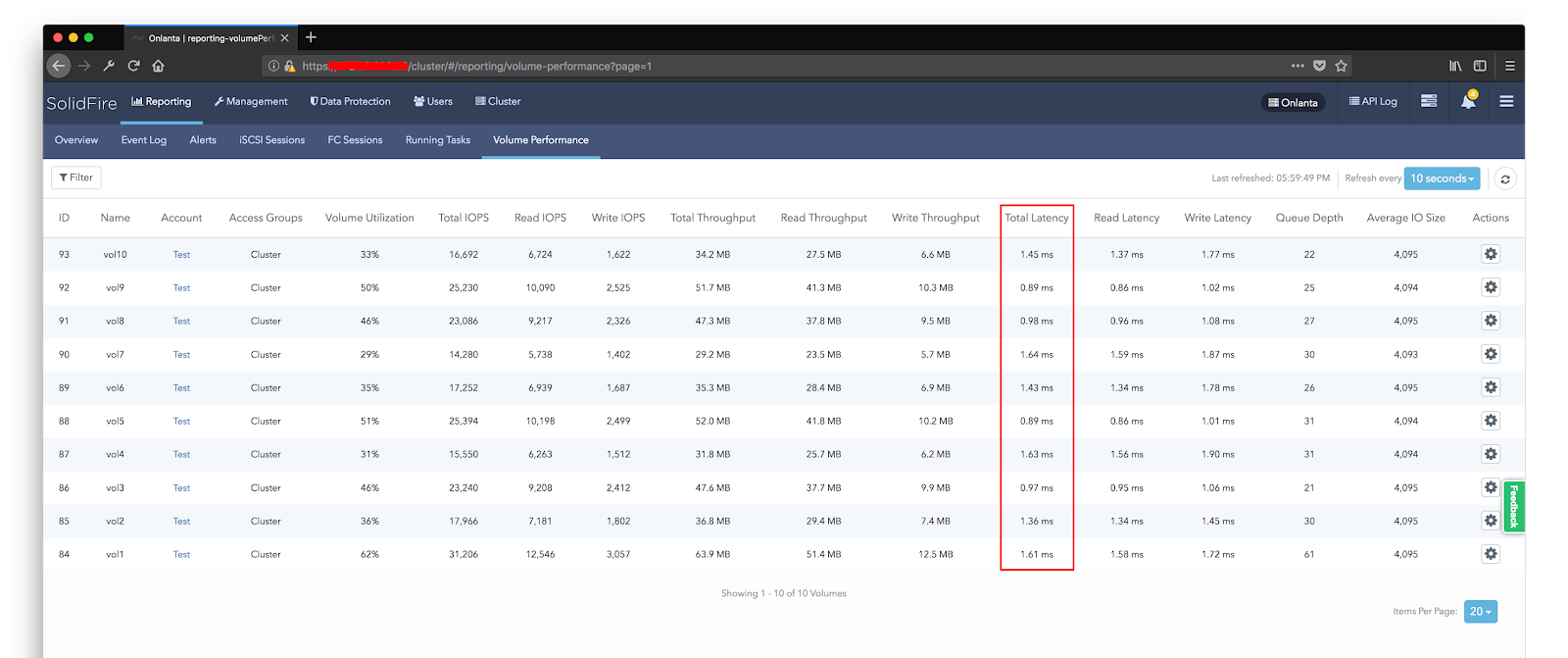
It should be noted that the architectural features of the solution do not allow to obtain a high level of performance on a small number of streams. One small moon or just one test virtual machine will not be able to show high results. We were able to get this amount of IOPS by using the entire capacity of the system and with a gradual increase in the number of virtual machines creating load using fio. We increased their number until the delays did not exceed 1.5 ms, after which we stopped and removed the performance indicators.
Performance is also affected by the fullness of the disk subsystem. As I said earlier, before running the tests, we filled the disks with random data. If you run the test without pre-filling the disk, the performance will be much higher with the same level of delays.
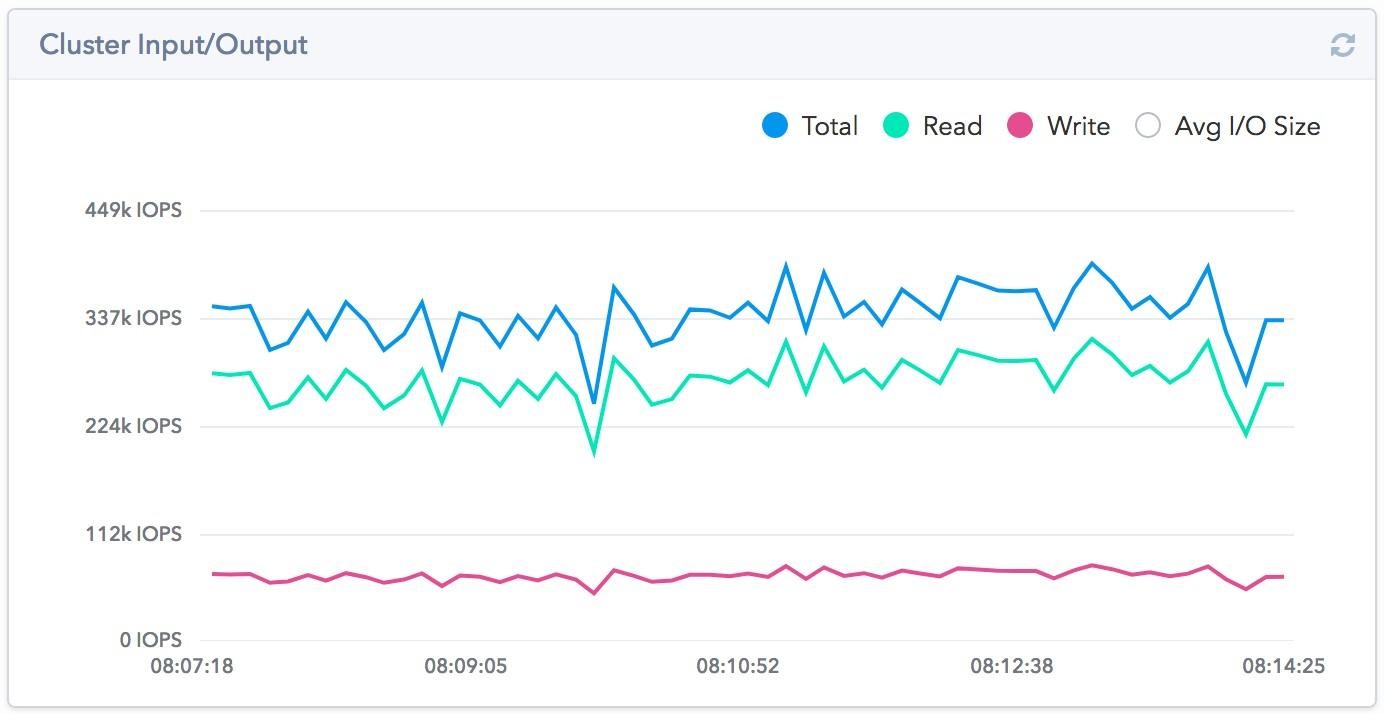
We also conducted our favorite fault tolerance test by shutting down one of the nodes. To get the best effect, the Master node was selected for shutdown. Since each client server establishes its own session with a cluster node, and not through a single point, when one node is disconnected, not all virtual machines degrade, but only those that work with this node. Accordingly, on the part of the storage system, we see only a partial drop in performance.

Of course, from the side of virtualization hosts on some data-stores, the performance drop was up to 0. But already within 30 seconds the working capacity was restored without loss of performance (it should be borne in mind that the load at the time of the fall was 120k iops, which can potentially give three The nodes of the four, respectively, the performance loss, we did not have to see).
 On the SolidFire side, the rebuilding of the array began. The timer is lying a little, and the process took about 55 minutes, which is within the promised hour of the vendor. At the same time, nobody removed the load from the storage system, and it remained at the same level at 120k IOPS.
On the SolidFire side, the rebuilding of the array began. The timer is lying a little, and the process took about 55 minutes, which is within the promised hour of the vendor. At the same time, nobody removed the load from the storage system, and it remained at the same level at 120k IOPS.
Fault tolerance is provided not only at the disk level, but also at the node level. The cluster supports simultaneous failure of one node, after which the cluster rebuild process is started. Considering the use of SSD and that all nodes are involved in the rebuild, the cluster is restored within an hour (it takes about 10 minutes if the drive fails). It should be borne in mind that when a node fails, you lose both in performance and in the amount of usable space. Accordingly, you always need to keep in reserve free space in the amount of one node. The minimum cluster size is four nodes. This configuration will allow you to avoid trouble if one of the nodes fails before you wait for a replacement.
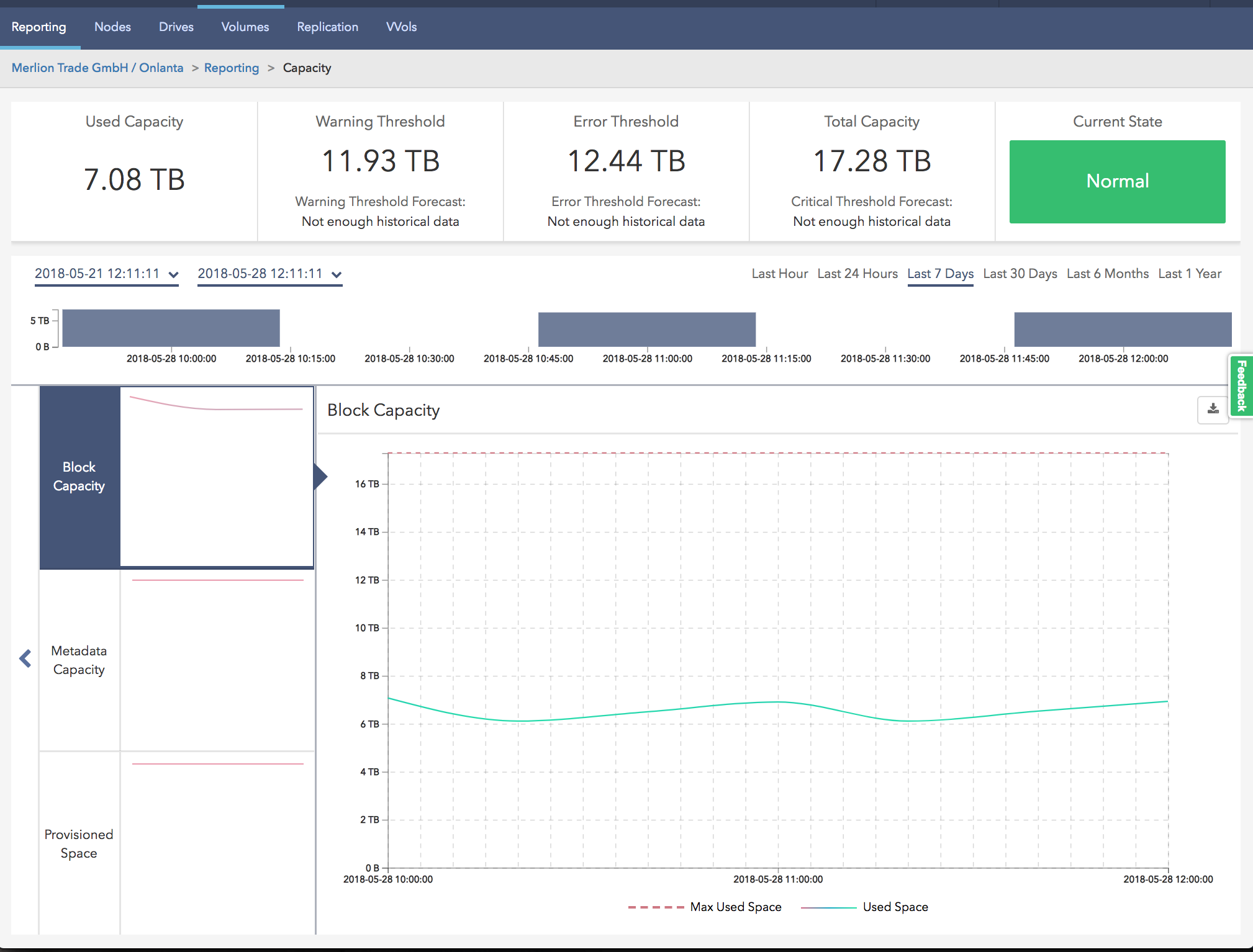
As with most storage systems, performance monitoring is displayed here only in real time. In order to have access to historical data, you need to deploy the so-called Management Node, which is committed to taking data on the API from SolidFire and pouring it into Active IQ. If you have already worked with NetApp systems, you probably already could have come across this portal. You have the opportunity to work with data on performance, efficiency, including growth forecasts. With that, you can access this data even from your mobile device, being anywhere in the world.


Since I mentioned the work of inline deduplication, I will say about the efficiency of storage in general. As with the AFF series, NetApp provides a guaranteed storage efficiency ratio based on the type of data stored.

As you can see, the data types and guaranteed coefficients are slightly different. For example, SolidFire has exactly our case - Virtual Infrastructure with a 4: 1 ratio. And this is without taking into account the use of snepshots.
The architecture of the solution is based on the Quality of Service (QoS), which actually allows us to achieve guaranteed performance for each of the volumes.
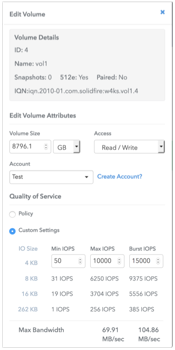
QoS is one of the critical functions for service providers and other enterprises who need to ensure a guaranteed level of storage performance. Someone will say that QoS is not something new and is implemented by many other vendors. Another question is how it works. While in traditional storage it’s more of a prioritization and speed limit, SolidFire, in turn, uses an integrated approach to achieve guaranteed performance.
In addition to the possibility of setting the maximum and minimum performance, it is possible to provide that performance beyond the maximum limit (Burst). Each volume has a certain conditional credit system. When his performance is below the maximum mark, he receives these loans, due to which, for a certain amount of time, he can overcome the maximum mark of performance. Such an approach allows placing a large number of applications requiring high performance in the storage and at the same time protecting them from negative influence on each other. The most interesting thing is that QoS is supported not only at the level of the volumes of the array, but also at the level of VMware VVol's, which allows granular allocation of resources for each virtual machine.
Speaking of integration, the solution from VMware is far from over.
SolidFire, perhaps, can be called the most automated storage system that can integrate with any modern systems, virtualization / containerization systems, supports configuration management systems, there are SDKs for various languages.
I, as always, watch the first thing SDK for Python, with which I automate my own workflows. And so we need to create 15 volumes with a volume of 1Tb, and at the output get them iqn, which we will transfer to VMware administrators to add datastores. We already have pre-acces groups in which our VMware hosts and a pre-created QoS policy are registered.
Or here is a more detailed video “Python SDK Demo” from SolidFire itself:
This approach to automation makes SolidFire convenient not only for cloud providers and similar tasks, but in accordance with the concept of continuous integration and delivery (CI / CD), it allows to optimize the development process.
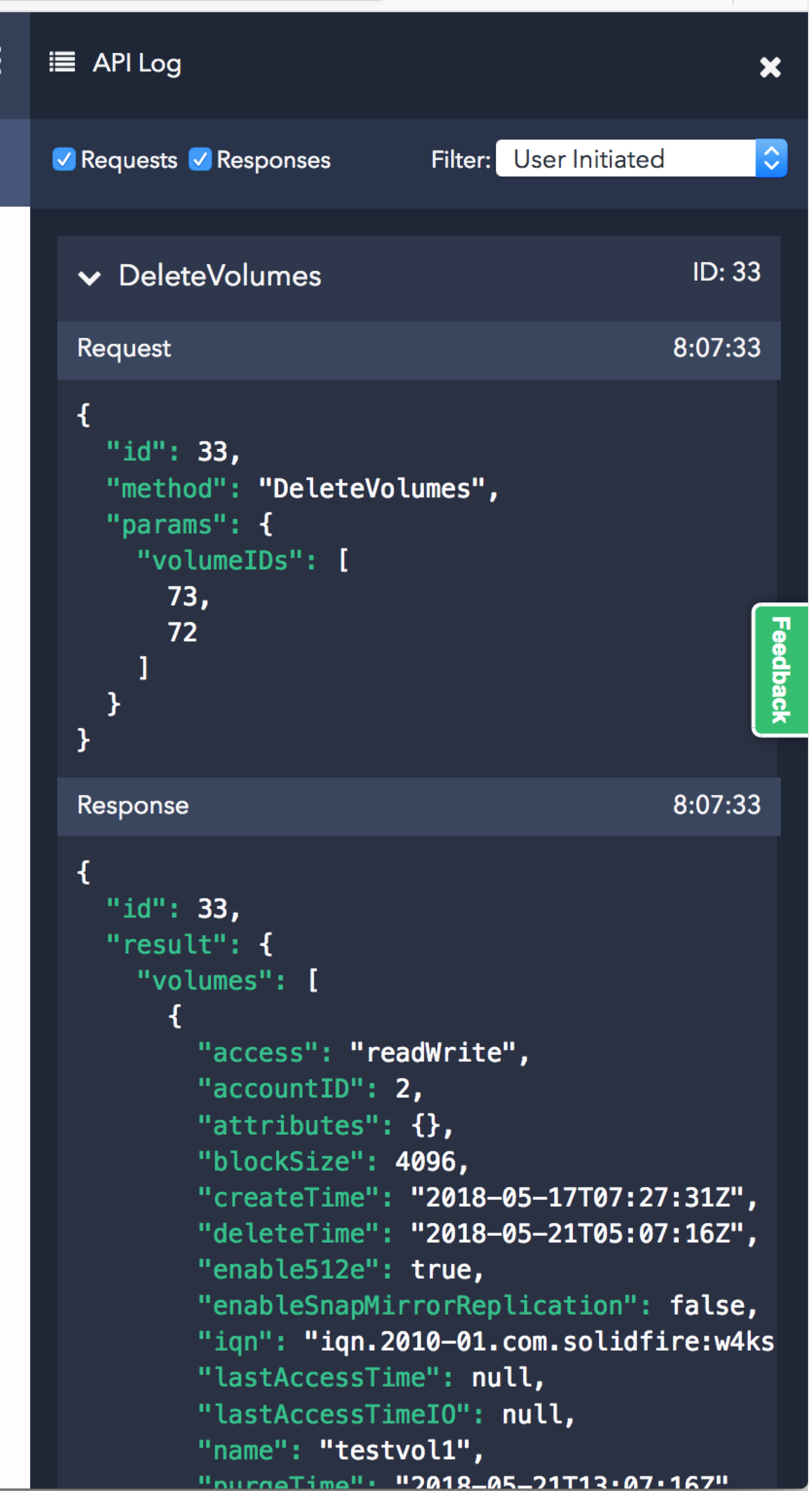
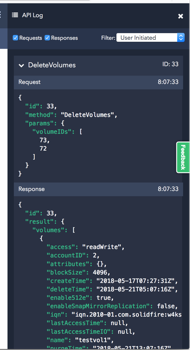 As I mentioned - WebUI works through the API, and you can view all requests and responses through the API Log.
As I mentioned - WebUI works through the API, and you can view all requests and responses through the API Log.
If you are interested in learning more about SolidFire, comparing it with competitors, working with the system, etc., I would like to recommend you YouTube channel , which has quite a large amount of useful video , from a useful one . For example, the cycle "Comparing Modern All-Flash Architectures".
Of the pleasant features of the system, you can call the built-in backup mechanism for snapshots in an external S3 compatible storage. This allows you to use snapshots as backups and store them in external repositories both on your site and on external resources, for example, in Amazon. Of course, such an approach can hardly be called flexible from the point of view of data recovery, but for some cases such a solution may be useful and quite applicable. There is another interesting point - you can upload data to the S3 storage in two versions:
In general, we were more than satisfied with our communication with SolidFire. We received the promised performance, the work of inline deduplication is beyond all praise, the possibilities of integration and automation also left a very positive impression. The impact of the failure of the node, or rather its minimal impact on the performance of the system as a whole, the load distribution and the lack of a single point of failure, which could greatly affect the performance make this system extremely attractive. Despite the fact that the cluster can work only on iSCSI, the presence of FC transport nodes makes this system more universal.
I would like to express special thanks to testing for Evgeny Krasikov from NetApp and Artur Alikulov from Merlion. By the way, Arthur, has a great Telegram channel.for everyone who wants to be aware of the news of storage-direction and NetApp in particular. You can find a huge amount of useful materials in it, and for whom it is not enough just to read, but you also want to talk, there is also a chat storagediscussions .
If you have any questions or suddenly new ones, I invite you to visit NetApp Directions 2018, which will be held on July 17, 2018 in Hyatt Regency Petrovsky Park, where Arthur and I will talk about SolidFire at one of the sessions. Registration for the event and all the details.
At the end of 2015, NetApp announced the purchase of a startup SolidFire, which was founded in 2010. Interest in these systems is due to their different approach to data warehouse management and predictable performance.
SolidFire solutions complemented the NetApp product line, which included All Flash FAS (AFF), EF and E series. It also enabled a year and a half to launch a new product on the market - NetApp HCI (Hyper Converged Infrastructure), which uses SolidFire as a storage subsystem.
“We are developing a new storage system designed for very large cloud computing data centers. The main idea is that many companies are transferring computing from their offices or their own data centers to these large cloud computing data centers, where they have tens of thousands of customers with all their information combined in one place. Therefore, we are creating a new storage system designed to service these large computer centers. ”Recently, more and more solutions are emerging that are moving away from the traditional approach of unified repositories, capable of solving any tasks, to specialized repositories, designed to solve problems of a particular business line.
Dave Wright, CEO of SolidFire, 2012
Not so long ago, I already talked about the system Infinidat InfiniBox F2230which is great for service provider tasks. Today's contributor to our SolidFire review can also be attributed to this class of devices. SolidFire founder Dave Wright and his team came from RackSpace, where they developed an efficient storage system that would provide linear performance in a multi-user environment, while being simple, easily scalable, and with flexible automation capabilities. In an attempt to solve this problem, SolidFire was born.
Today, the SolidFire lineup consists of four models with different IOPS / TB ratios.
For data storage, 10 (MLC) SSDs are used, and the NVRAM is Radian RMS-200. True, there are already plans to switch to NVDIMM modules .
Here, interest is how SolidFire retrieves and stores data. We all know about the limited resource of SSD drives, so it is logical that for their maximum safety compression and deduplication should occur on the fly, before recording on the SSD. When SolidFire receives data from the host, it breaks it into 4K blocks, after which this block is compressed and stored in NVRAM. Then synchronous replication of this block in NVRAM to the “neighboring” cluster node occurs. After this, SolidFire obtains the hash of this compressed block and searches for this hash value in its index of stored data within the entire cluster. If a block with such a hash already exists, SolidFire updates only its metadata with a link to this block, if the block contains unique data, it is recorded on the SSD, and metadata is also written for it.
There are already rumors that this line will be updated soon. It is worth noting one very important thing - the SolidFire cluster is able to work with nodes both with different “IOPs / TB density” and unite nodes of different generations within one cluster. First, it makes the use of this system more predictable in terms of equipment support, and also facilitates the transition from old nodes to new ones when you simply add new ones and remove old ones from the cluster in real time (waiting only for the cluster to be rebuilt) without downtime. because There is support for both Scale Out and Scale Back.
SolidFire can come in three solutions:
- SolidFire as a standalone product, based on Dell / EMC servers,
- as part of FlexPod SF on Cisco servers,
- as part of NetApp HCI on its platform.
As you can see from the table of characteristics, nodes support only an iSCSI connection, and for an FC connection there is a separate node type - Fabric Interconnect, which in turn contains four ports for FC data and four iSCSI ports for connection to the nodes, as well as 64GB of native system memory / cache for reading.
The performance table also indicates the performance of each node. This is one of those cases where you know the performance of your storage system at the buying stage. This performance is guaranteed (with a load profile of 4Kb, 80/20) per node.
Accordingly, buying a cluster of X nodes or expanding an existing solution, you understand how much and how much performance you will end up with. Of course, you can squeeze out more performance from each node under certain conditions, but this is not what this solution was designed for. If you want to get millions of IOPS in 2U on a single volume, you better turn your attention to other products, for example AFF. The greatest performance on SolidFire can be obtained with a large number of volumes and sessions.
Managing storage is quite simple. In fact, we have two resource pools: volume and IOPS. Separating one of the types of resources and knowing their finite number, we clearly understand the other possibilities of our system. This again makes system expansion extremely easy. Need extra performance? We consider SF4805 or SF19210 with a “less dense” IOPS / TB ratio. Need volume? We look in the direction of SF9605 and SF38410, which provide less IOPS per Gb.
From the point of view of the storage system administrator, the system looks pretty boring. Things like deduplication and compression work by default.
Replication and snapshots are also available, and replication can be organized for the entire NetApp product line (except for the E-series). It is this simplicity, in my opinion, that is revealed for the quote of Dave Hits from the title of the article. Considering that this system assumes integration with various systems of dynamic resource allocation, without administrator participation and without additional labor costs, you will soon forget how the SolidFire interface looks. But we'll talk more about integration.
We are in "Onlanta"conducted load testing in order to verify the promised 200k IOPS. Not that we do not believe the vendor, but are accustomed to try everything yourself. We did not set ourselves the goal of squeezing out more from the system than was stated. We were also able to see for ourselves that the system gives a good result with a large number of threads. To do this, we organized 10 volumes of 1TB on SolidFire, on which we placed one test virtual machine. Already at the stage of preparation of the test environment, we were pleasantly surprised by the work of deduplication. Despite the fact that the scheme of his work is fairly standard, the quality of work within the cluster has proven to be extremely effective. The disks before the tests were filled with random data.
To make it faster, a block of 10 mb was generated, then it was filled. And on each virtual machine, this block was generated separately, i.e. In all machines, the pattern is different. From 10TB filled with data - the actual occupied space on the array was 4TB. The deduplication efficiency is 1: 2.5, with FAS using this approach, the inline deduplication efficiency tended to 0. We were able to get 190k IOPS with a response of ~ 1 ms on our test bench.
It should be noted that the architectural features of the solution do not allow to obtain a high level of performance on a small number of streams. One small moon or just one test virtual machine will not be able to show high results. We were able to get this amount of IOPS by using the entire capacity of the system and with a gradual increase in the number of virtual machines creating load using fio. We increased their number until the delays did not exceed 1.5 ms, after which we stopped and removed the performance indicators.
Performance is also affected by the fullness of the disk subsystem. As I said earlier, before running the tests, we filled the disks with random data. If you run the test without pre-filling the disk, the performance will be much higher with the same level of delays.
We also conducted our favorite fault tolerance test by shutting down one of the nodes. To get the best effect, the Master node was selected for shutdown. Since each client server establishes its own session with a cluster node, and not through a single point, when one node is disconnected, not all virtual machines degrade, but only those that work with this node. Accordingly, on the part of the storage system, we see only a partial drop in performance.
Of course, from the side of virtualization hosts on some data-stores, the performance drop was up to 0. But already within 30 seconds the working capacity was restored without loss of performance (it should be borne in mind that the load at the time of the fall was 120k iops, which can potentially give three The nodes of the four, respectively, the performance loss, we did not have to see).
Fault tolerance is provided not only at the disk level, but also at the node level. The cluster supports simultaneous failure of one node, after which the cluster rebuild process is started. Considering the use of SSD and that all nodes are involved in the rebuild, the cluster is restored within an hour (it takes about 10 minutes if the drive fails). It should be borne in mind that when a node fails, you lose both in performance and in the amount of usable space. Accordingly, you always need to keep in reserve free space in the amount of one node. The minimum cluster size is four nodes. This configuration will allow you to avoid trouble if one of the nodes fails before you wait for a replacement.
As with most storage systems, performance monitoring is displayed here only in real time. In order to have access to historical data, you need to deploy the so-called Management Node, which is committed to taking data on the API from SolidFire and pouring it into Active IQ. If you have already worked with NetApp systems, you probably already could have come across this portal. You have the opportunity to work with data on performance, efficiency, including growth forecasts. With that, you can access this data even from your mobile device, being anywhere in the world.
Since I mentioned the work of inline deduplication, I will say about the efficiency of storage in general. As with the AFF series, NetApp provides a guaranteed storage efficiency ratio based on the type of data stored.
As you can see, the data types and guaranteed coefficients are slightly different. For example, SolidFire has exactly our case - Virtual Infrastructure with a 4: 1 ratio. And this is without taking into account the use of snepshots.
The architecture of the solution is based on the Quality of Service (QoS), which actually allows us to achieve guaranteed performance for each of the volumes.
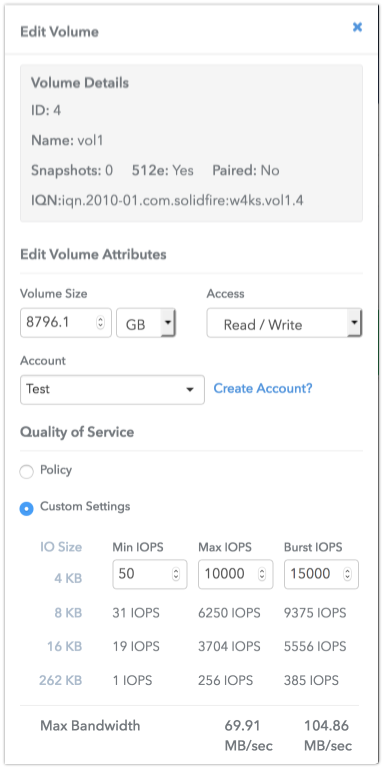
QoS is one of the critical functions for service providers and other enterprises who need to ensure a guaranteed level of storage performance. Someone will say that QoS is not something new and is implemented by many other vendors. Another question is how it works. While in traditional storage it’s more of a prioritization and speed limit, SolidFire, in turn, uses an integrated approach to achieve guaranteed performance.
- Using All-SSD allows for low I / O latency.
- Scale-out easily predicts performance.
- No classic RAID - predictable performance with
- equipment failures
- Balanced load distribution eliminates bottlenecks in the system.
- QoS helps to avoid "noisy neighbors."
In addition to the possibility of setting the maximum and minimum performance, it is possible to provide that performance beyond the maximum limit (Burst). Each volume has a certain conditional credit system. When his performance is below the maximum mark, he receives these loans, due to which, for a certain amount of time, he can overcome the maximum mark of performance. Such an approach allows placing a large number of applications requiring high performance in the storage and at the same time protecting them from negative influence on each other. The most interesting thing is that QoS is supported not only at the level of the volumes of the array, but also at the level of VMware VVol's, which allows granular allocation of resources for each virtual machine.
Speaking of integration, the solution from VMware is far from over.
SolidFire, perhaps, can be called the most automated storage system that can integrate with any modern systems, virtualization / containerization systems, supports configuration management systems, there are SDKs for various languages.
I, as always, watch the first thing SDK for Python, with which I automate my own workflows. And so we need to create 15 volumes with a volume of 1Tb, and at the output get them iqn, which we will transfer to VMware administrators to add datastores. We already have pre-acces groups in which our VMware hosts and a pre-created QoS policy are registered.
#!/usr/bin/env python# -*- coding:utf-8 -*-from solidfire.factory import ElementFactory
sfe = ElementFactory.create('ip', 'log', 'pass')
for i in range(1,51):
create_volume_result = sfe.create_volume(name='vol'+str(i), account_id=2, total_size=1099511627776, enable512e=True, qos_policy_id=1)
id = create_volume_result.volume_id
sfe.add_volumes_to_volume_access_group(volume_access_group_id=2, volumes=[id])
volumes = sfe.list_volumes(accounts=[2], limit=100).volumes
for volume in volumes:
print volume.iqn
Or here is a more detailed video “Python SDK Demo” from SolidFire itself:
This approach to automation makes SolidFire convenient not only for cloud providers and similar tasks, but in accordance with the concept of continuous integration and delivery (CI / CD), it allows to optimize the development process.
If you are interested in learning more about SolidFire, comparing it with competitors, working with the system, etc., I would like to recommend you YouTube channel , which has quite a large amount of useful video , from a useful one . For example, the cycle "Comparing Modern All-Flash Architectures".
Of the pleasant features of the system, you can call the built-in backup mechanism for snapshots in an external S3 compatible storage. This allows you to use snapshots as backups and store them in external repositories both on your site and on external resources, for example, in Amazon. Of course, such an approach can hardly be called flexible from the point of view of data recovery, but for some cases such a solution may be useful and quite applicable. There is another interesting point - you can upload data to the S3 storage in two versions:
- Native - in this case, the deduplicated data will be uploaded, but at the same time it will be possible to restore this volume only to the same system with which it is flooded.
- Uncompressed - a full set of blocks is already being poured in here, which makes it possible to restore this moon on any other SolidFire cluster.
In general, we were more than satisfied with our communication with SolidFire. We received the promised performance, the work of inline deduplication is beyond all praise, the possibilities of integration and automation also left a very positive impression. The impact of the failure of the node, or rather its minimal impact on the performance of the system as a whole, the load distribution and the lack of a single point of failure, which could greatly affect the performance make this system extremely attractive. Despite the fact that the cluster can work only on iSCSI, the presence of FC transport nodes makes this system more universal.
I would like to express special thanks to testing for Evgeny Krasikov from NetApp and Artur Alikulov from Merlion. By the way, Arthur, has a great Telegram channel.for everyone who wants to be aware of the news of storage-direction and NetApp in particular. You can find a huge amount of useful materials in it, and for whom it is not enough just to read, but you also want to talk, there is also a chat storagediscussions .
If you have any questions or suddenly new ones, I invite you to visit NetApp Directions 2018, which will be held on July 17, 2018 in Hyatt Regency Petrovsky Park, where Arthur and I will talk about SolidFire at one of the sessions. Registration for the event and all the details.
And in our company there is a vacancy.