Cloud opening for new customers
News in one line:
Key changes:
Actually, the announcement ends on this, then the lyrics begin.
What have we been doing these 3 months?
Or, more correctly, "what was wrong?"
The wonderful python language is famous as an excellent means of rapid development. Write a prototype of a working application on it, “proof of concept” - yes. To write on it an application that spends more time in library code than over math - yes.
But here you can write multithreaded applications on it with tens of thousands of transactions per second with reasonable CPU consumption ... Until a certain point, you can. Further, architectural problems begin, to struggle with which it begins to take more time than to program a new one.
This is exactly the situation that has happened here. At the same time, several components that were “written and forgotten” (that is, were not planned for further development in the near future) showed botneks. For some time we “had fun” with the optimization of the code, discussed the possibility of putting part of it into the library with binders on python ... Until we found out that problems accumulate faster than we solve them. And this is despite the fact that this fall we almost doubled the number of developers.
An additional problem was created by new users experimenting and playing with the functionality (we have nothing against it, but not at that moment when the system is already on the verge) - this gave additional stress. At the moment when some API requests began to execute for 10 s instead of the set 0.1-0.2 (someone could notice how slowly the contents of the control panel were displayed at that moment, and the delay was completely unpredictable), it was decided to stop creating new machines.
Firstly, this reduced the load from new customers, and secondly, when all the machines are created, users rarely go to the control panel and the number of calls to the control panel has dropped significantly.
At a time when the load stabilized, during the extremely bloody battles, the functionalists defeated the proceduralists. Or, in other words, we looked towards functional programming languages.
Namely, in the Haskell programming language.
Yes, that terrible and terrible language, in articles about which on page 5-10 the code ends and the higher mathematics begins.
Personally, I was a desperate opponent of adopting this language. However, the arguments from the supporters convinced me - strict typing, type inference, pattern matching (with control over the completeness thereof) ...
Add to this the consumer properties: a compiled language (read: to run, you only need an executable file without any environment), a long history of long-passed childhood diseases (20+ years), a lot of libraries for all occasions (this, by the way, defined “Haskell or okaml "). I was finally struck by the fact that the Haskell program went nose-to-nose in a simple IO test and math with a C program. Moreover, "nose-to-nose" is when gcc optimization is enabled.
Is haskell programming fast? Not. According to my observations, the program is written about three times slower than in python. However, the real difference comes after. Suffice it to say that if we rolled out an average of 3 to 10 bugfixes for products on python programs, then those programs that we now run on the Haskel practically do not contain bugfixes. Most of the changes are associated with the change in the ToR, and not a reaction to the next attribute has not method foobar in the logbook.
We used to write a lot of code in python, now we write a little code in Haskell.
Have we copied everything to Haskell? Alas, no, the process goes as needs arise and most of our code is still in python, but as the architecture changes, everything else is planned to be rewritten on it.
Moreover, as the final chord - our API server is still written in python - and it was the “fast python” that caused the two-week delay with the launch, since it was necessary to repeatedly and painfully recheck all the behaviors of the new functions that the python (like a language with dynamic typing ) I could not check.
...
However, while programmers honed the style, the system administration department did not sit still.
 One of our drawbacks was the use of nonclustered storage. The data was safe, but there was a chance of stumbling into problems with uptime. Not very big, but it was.
One of our drawbacks was the use of nonclustered storage. The data was safe, but there was a chance of stumbling into problems with uptime. Not very big, but it was.
The combination of drbd, flashcache and multipath, hopefully solved this problem. Data is stored on 10 raids, a full copy of all data is located on each node of the cluster. If the node dies, clients either do not notice anything or (in the worst case) receive a 5-10-second delay in disk operations, after which multipath finds an alternative path and further requests are processed without failures.
The second important change was the switch to LVM for system disks. This should greatly simplify the partition management process.
OS updated: OpenSUSE 12.1, CentOS 5.7, Debian Wheezy appeared. A template appeared with ClearOS (for those who want a web interface to a VPN server). Some more useful templates in development.

The most difficult and difficult task that we have solved with great success. About snapshots and the principles of their work, I will write a separate article, but for now “squeezing” snapshot features:
* Snapshots are made “on the fly” without stopping the machine
* Snapshots can form both a chronological list and a “tree”.
* Snapshots store only changed data (minimum size - 8Mb)
* Snapshots are paid as disk space (a separate line) at the price of regular disk space
* Snapshots of a disk can be connected in read only to existing machines without stopping the use of a "regular" disk.
In order to do this well and conveniently, we had to rewrite the usual snapshots very strongly in the Xen Cloud Platform, in particular, add support for tree relations between snapshots and the possibility of free kickbacks between any snapshots.
A lot of time was devoted to ergonomics. For example, fields such as password, IP address and other data that are often copied are made in such a way that a double click selects them and only them, without creeping into the neighbors. All controls in regular menus are static (that is, they do not jump back and forth and do not change the value depending on the context). This does not apply to “dangerous operations”, where our main task was not to create maximum amenities, but to make us think “I want or not”. By the way, if someone in some case has a clear feeling of “doing too much” - write to me (or in tickets). We do not promise a correction, but at least I’ll think about how to implement it and if we can come up with it, we’ll do it.
We will continue to maintain the old pool for a long time (I do not promise that it will always, but for a very long time, for sure), and all new machines will be created in the new pool — snapshots, “native kernels” will work there and new templates are located there .
Cloud launched
We again opened the opportunity to create virtual machines and are ready to accept new users in our cloud in a new pool. The tariffs are the same, there are more opportunities.Key changes:
- New cluster storage
- Updated LVM virtual machine templates to simplify disk resizing
- Snapshots
- Improved control panel performance
Actually, the announcement ends on this, then the lyrics begin.
What have we been doing these 3 months?
Or, more correctly, "what was wrong?"
The wonderful python language is famous as an excellent means of rapid development. Write a prototype of a working application on it, “proof of concept” - yes. To write on it an application that spends more time in library code than over math - yes.
But here you can write multithreaded applications on it with tens of thousands of transactions per second with reasonable CPU consumption ... Until a certain point, you can. Further, architectural problems begin, to struggle with which it begins to take more time than to program a new one.
This is exactly the situation that has happened here. At the same time, several components that were “written and forgotten” (that is, were not planned for further development in the near future) showed botneks. For some time we “had fun” with the optimization of the code, discussed the possibility of putting part of it into the library with binders on python ... Until we found out that problems accumulate faster than we solve them. And this is despite the fact that this fall we almost doubled the number of developers.
An additional problem was created by new users experimenting and playing with the functionality (we have nothing against it, but not at that moment when the system is already on the verge) - this gave additional stress. At the moment when some API requests began to execute for 10 s instead of the set 0.1-0.2 (someone could notice how slowly the contents of the control panel were displayed at that moment, and the delay was completely unpredictable), it was decided to stop creating new machines.
Firstly, this reduced the load from new customers, and secondly, when all the machines are created, users rarely go to the control panel and the number of calls to the control panel has dropped significantly.
At a time when the load stabilized, during the extremely bloody battles, the functionalists defeated the proceduralists. Or, in other words, we looked towards functional programming languages.
Namely, in the Haskell programming language.
Yes, that terrible and terrible language, in articles about which on page 5-10 the code ends and the higher mathematics begins.
Personally, I was a desperate opponent of adopting this language. However, the arguments from the supporters convinced me - strict typing, type inference, pattern matching (with control over the completeness thereof) ...
Add to this the consumer properties: a compiled language (read: to run, you only need an executable file without any environment), a long history of long-passed childhood diseases (20+ years), a lot of libraries for all occasions (this, by the way, defined “Haskell or okaml "). I was finally struck by the fact that the Haskell program went nose-to-nose in a simple IO test and math with a C program. Moreover, "nose-to-nose" is when gcc optimization is enabled.
Is haskell programming fast? Not. According to my observations, the program is written about three times slower than in python. However, the real difference comes after. Suffice it to say that if we rolled out an average of 3 to 10 bugfixes for products on python programs, then those programs that we now run on the Haskel practically do not contain bugfixes. Most of the changes are associated with the change in the ToR, and not a reaction to the next attribute has not method foobar in the logbook.
We used to write a lot of code in python, now we write a little code in Haskell.
Have we copied everything to Haskell? Alas, no, the process goes as needs arise and most of our code is still in python, but as the architecture changes, everything else is planned to be rewritten on it.
Moreover, as the final chord - our API server is still written in python - and it was the “fast python” that caused the two-week delay with the launch, since it was necessary to repeatedly and painfully recheck all the behaviors of the new functions that the python (like a language with dynamic typing ) I could not check.
...
However, while programmers honed the style, the system administration department did not sit still.
Cluster Storage
One of our drawbacks was the use of nonclustered storage. The data was safe, but there was a chance of stumbling into problems with uptime. Not very big, but it was. The combination of drbd, flashcache and multipath, hopefully solved this problem. Data is stored on 10 raids, a full copy of all data is located on each node of the cluster. If the node dies, clients either do not notice anything or (in the worst case) receive a 5-10-second delay in disk operations, after which multipath finds an alternative path and further requests are processed without failures.
Patterns
The key and fundamental was the transition to the 3.1-xen core (except for the centos, which is on its own mind). At the same time, reluctantly, we allowed users to load kernels from the machine, and not "ours." Why reluctantly? Because if the client puts the “wrong kernel”, then his machine will freeze or behave inappropriately. Poor, poor technical support department. But the convenience of the fact that the kernel is installed inside the virtual machine is still outweighed.The second important change was the switch to LVM for system disks. This should greatly simplify the partition management process.
OS updated: OpenSUSE 12.1, CentOS 5.7, Debian Wheezy appeared. A template appeared with ClearOS (for those who want a web interface to a VPN server). Some more useful templates in development.
Snapshots
The most difficult and difficult task that we have solved with great success. About snapshots and the principles of their work, I will write a separate article, but for now “squeezing” snapshot features:
* Snapshots are made “on the fly” without stopping the machine
* Snapshots can form both a chronological list and a “tree”.
* Snapshots store only changed data (minimum size - 8Mb)
* Snapshots are paid as disk space (a separate line) at the price of regular disk space
* Snapshots of a disk can be connected in read only to existing machines without stopping the use of a "regular" disk.
In order to do this well and conveniently, we had to rewrite the usual snapshots very strongly in the Xen Cloud Platform, in particular, add support for tree relations between snapshots and the possibility of free kickbacks between any snapshots.
Control Panel
We rolled out the design of the new control panel shortly before the service was suspended (silly, yes, but now everyone can see it). In addition, we rewrote the statistics, significantly reduced the load on the database in some types of queries. At the same time, to the noise, we added the upload of consumption data to CSV.A lot of time was devoted to ergonomics. For example, fields such as password, IP address and other data that are often copied are made in such a way that a double click selects them and only them, without creeping into the neighbors. All controls in regular menus are static (that is, they do not jump back and forth and do not change the value depending on the context). This does not apply to “dangerous operations”, where our main task was not to create maximum amenities, but to make us think “I want or not”. By the way, if someone in some case has a clear feeling of “doing too much” - write to me (or in tickets). We do not promise a correction, but at least I’ll think about how to implement it and if we can come up with it, we’ll do it.
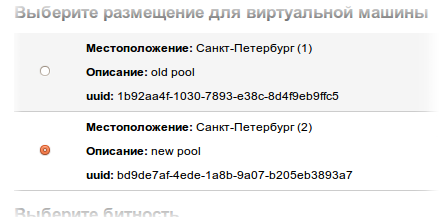
The fate of the old pool
Due to architectural changes, we were not able to implement new features in the old pool, they are implemented in the new pool (virtual machines will be created in it).- Help: pool (pool) - a group of servers that have a single administrative center (pool masters) that have a single configuration and shared storage. In the context of our cloud, it means the highest hierarchical unit of cloud segmentation. Pools do not interact with each other, although they obey a single API server.
We will continue to maintain the old pool for a long time (I do not promise that it will always, but for a very long time, for sure), and all new machines will be created in the new pool — snapshots, “native kernels” will work there and new templates are located there .