Innovate Cloud Technology: Disaster Protection Cloud
The cloud services market is growing rapidly both in the world and in Russia. More and more companies are moving their applications and data, including business-critical ones, to the cloud. According to marketers, this allows businesses to use the latest innovative cloud solutions, reducing capital costs (transferring CAPEX to OPEX), bringing new products to the market faster and launching new services. And such arguments do not leave indifferent potential customers. It is not by chance that the growth rates of the Russian cloud market significantly outpace the growth of the traditional, classic IT infrastructure market.

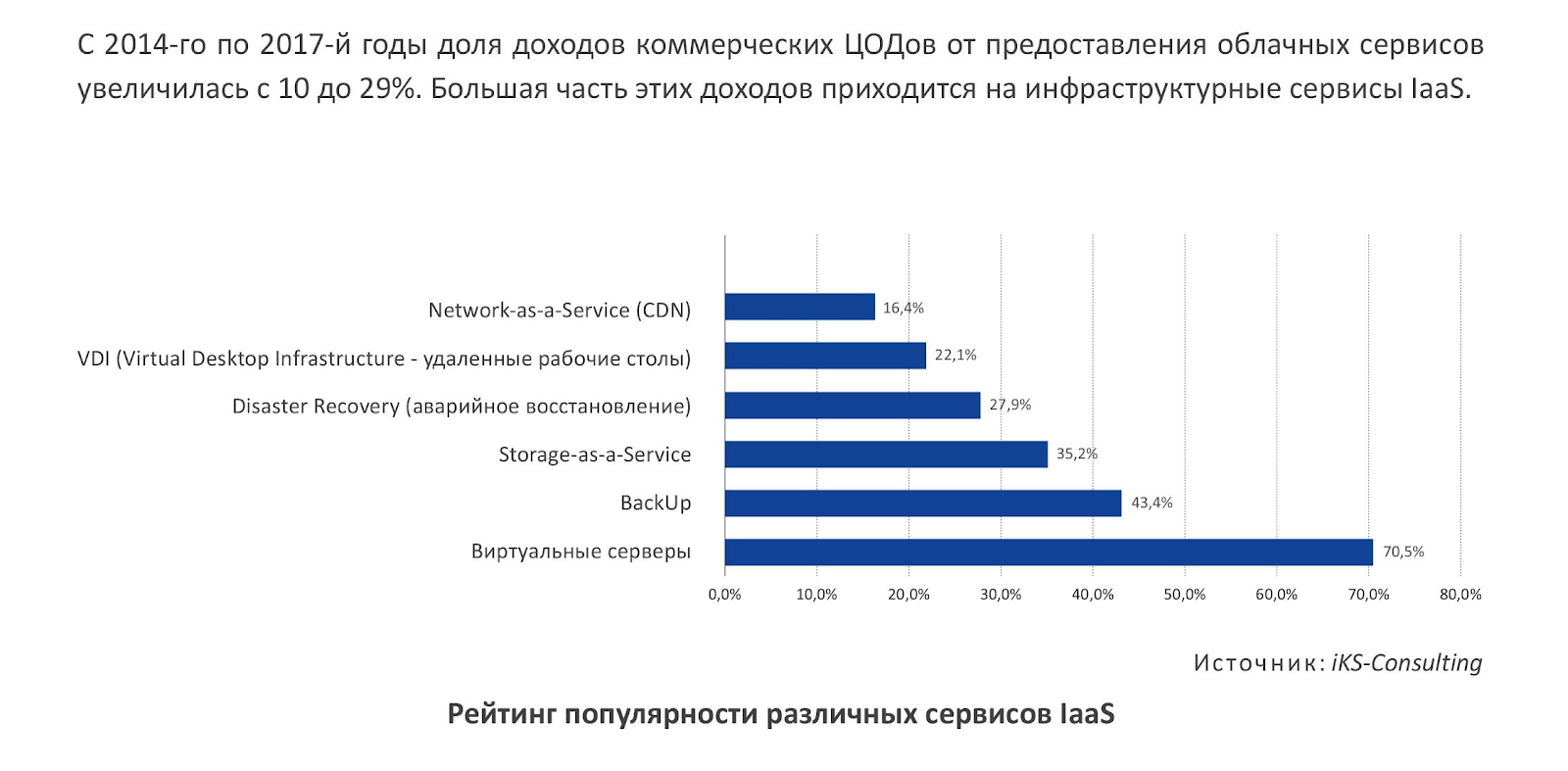
Gradually dispel doubts about the reliability and safety of clouds. As a recent study by iKS-Consulting has shown , almost 40% of the polled Russian companies see the use of public clouds as an opportunity to increase the security of their IT systems. The most popular infrastructure cloud service is the rental of virtual servers. In the second place in popularity is the cloud backup service (Backup-as-a-Service). About a third of respondents use cloud services to host storage and DR infrastructure.
Meanwhile, with the increasing dependence of business on IT requirements for the reliability of IT services, including cloud services, are growing. Moreover, it is often necessary to ensure not only hardware reliability, but also disaster recovery.
According to research , almost three-quarters of organizations in the world are not completely sure that they can restore their systems and data. Unplanned downtime and data loss cost organizations around the world more than $ 1.7 billion annually. According to Acronis researchIn Russia, only 2% of surveyed companies are absolutely sure that their IT infrastructure will pass any test. Half of Russian specialists expect long interruptions in its work in the event of a disaster or accident. According to world statistics, 93% of companies that have lost their data center for only 10 days are ruined during the year.
In any technically complex systems, accidents are unavoidable, but they can be made not critical for business. To prevent such situations, disaster-resistant cluster systems are created, virtually eliminating downtime in the event of accidents and failures.
Another important point that should not be forgotten when designing a disaster-proof IT infrastructure is the workplaces of users. You need to resume business processes, and not just switch to a backup server or raise the database. Disaster resistance begins at the client’s office. Even a backup office with employee jobs is not the best option. A good solution can be virtual desktops (VDI) or other forms of workplace in the cloud. Access to such a workplace in a virtual machine in the data center is easy to organize from any computer in the branch network.
The Russian telecommunications operator MasterTel and Lenovo have jointly prepared and implemented a disaster- resilient cloud project called Innovate Cloud Technology . Based on this cloud, highly reliable IaaS services are provided to a wide range of customers who would like to deploy critical IT infrastructure in the cloud environment. The basis of the cloud was the metro cluster, spaced between two sites - DataPro data centers and IXсellerate in Moscow.
When choosing a partner for this project, MasterTel was guided, first of all, by the vendor’s ability to promptly provide the most complete solution for reasonable money. To implement the cloud, launched in October 2018, a team of specialists from Lenovo Professional Services was involved. MasterTel acts as a cloud provider (Cloud Service Provider) and a telecommunications operator that organizes secure communication channels and provides direct fiber-optic lines, is responsible for the operation of the cloud and its support.
Innovate Cloud Technology is a private cloud for corporate clients, offering highly reliable and real-time scalable cloud services IaaS, BaaS, DRaaS, VDS, etc. What does the use of services Innovate Cloud Technology?
Currently, most cloud projects, in fact, provide power for rent. As a rule, this is the creation of virtual servers (the most common commercial data center service in Russia) and access to an already formed pool of resources. In the case of Innovate Cloud Technology, all settings can be made by the customer online, resources are allocated and released dynamically and pay-after-the-fact, exclusively for the resources used, as befits a classic cloud service.
But perhaps the most important feature of Innovate Cloud Technology is high reliability. Customers can use high-availability cloud infrastructure and store highly critical data in geographically dispersed DataPro and IXCellerate data centers. These sites by themselves guarantee reliability and a high level of physical and information security. A reliable high-speed communication channels and access to both data centers provides MasterTel.
Innovate Cloud Technology is a cloud resource with guaranteed availability of 99.99% for SLA. However, this cloud is distinguished not only by high reliability, but also by disaster recovery, since this is a geographically distributed virtualization cluster at two sites of the Tier III level.
This data center Tier III on the street. Aviamotornaya in Moscow is one of the few Russian commercial data centers that have been certified by Uptime Design and Facility. All technologies and solutions used in the data center are certified, which means maximum resiliency, guaranteed availability of resources and is an insurance against unexpected situations.

DataPro Data Center Control Center. International certification of Uptime Design and Facility means that it is designed and built in accordance with all applicable standards for the Tier III reliability category.
Security is responsible for the security of the data center and the surrounding area. Security system includes more than 350 network cameras. For uninterrupted and uninterrupted power supply, uninterruptible power supplies (UPS) are used, diesel generator sets (DGS) are used, which support the work of the data center during a prolonged power outage.
In the DataPro data center - two independent inputs of 10 kV from the Mosenergo substation, and the cables are laid in different collectors, provide the supply of the necessary electrical power to the object. The power supply of the data center is actually reserved under the 2N scheme.
IXcellerate's Moscow One data center also has a Tier III Uptime Institute certificate in the Design category. The facility also corresponds to the Level 3 reliability level in the categories “project”, “construction”, and “operation” according to the IBM Reliability Rating System methodology. IXcellerate Moscow One is technically implemented and guaranteed at the SLA level with an accessibility indicator of 99.999%. The total area of the IXcellerate Moscow One data center in Degunino is 15,741 sq. M. The design capacity of the facility reaches 13.7 MW. Data Center customers - about a hundred international and Russian companies.

Passing certification tests of the Uptime Institute proves that the IXcellerate computer complex is designed in accordance with modern world practices of building data processing centers.
Distribution over two sites requires the organization of reserved communication channels, replication of data between storages. We need a data synchronization mechanism to ensure their relevance in case of failure of one of the nodes and to support the work of those information systems that need such synchronization.
Often at the heart of disaster-resistant data center - geographically distributed cluster configuration of servers with connection to a common storage area network (SAN). The nodes of such a distributed cluster are located on the main and backup sites, forming a single system. This ensures continuous availability of services even in the event of the loss of one of the data center. Using clustering, you can automatically switch the load between the sites of the distributed data center in the event of an accident.
Data storage systems at the indicated sites can completely duplicate each other, and the sites themselves connect with redundant high-speed communication channels, which allows realizing projects with the highest demands on the reliability of data transfer and their availability, including synchronous data replication.

VMware vSphere based metro cluster example. it is based on duplication of storage systems at two geographically separated sites with data replication and possible load balancing at the data center network level. If one of the data centers is unavailable, the virtual machines will be automatically started on the second platform. The metrocluster is almost zero idle, work is interrupted only during the launch of virtual machines, when VMware High Availability (HA) restarts the VM on the remote site with the storage system that is in the cluster.
If you use load balancing mechanisms for DR (Global Server Load Balancing, GSLB), then you can automatically switch users to the backup site when the primary fails. For users, this process will be transparent.
Unlike DR with data replication, in the case of a metrocluster, only identical disk types are used for mirroring, an identical configuration is needed at both sites.
The cloud of Innovate Cloud Technology based on VMware is built according to this scheme. It provides continuous operation of critical applications and data in the cloud. All elements of the virtualization cluster are duplicated at two sites, located almost 30 km apart. Between them, data is mirrored at the storage system level. Due to this, data and services will be available in case of failures on one of the sites: power outage, partial failure of storage systems, controllers, communication channels between the data center, and even if one of the sites is completely inoperable.
When one of the data centers is unavailable, virtual machines are migrated to a backup site. Running a virtual machine on a backup site (Recovery Time Objective, RTO) will take about 3 minutes.
Customers are offered a detailed service level agreement (Service Level Agreement, SLA). Its main indicators: service availability at the level of 99.99%; idle time - no more than 4.38 minutes per month, guaranteed parameters of processor performance (MIPS / 1 vCPU), disk system (IOPS, GB / s), delays when accessing the storage system. For their compliance with the provider is financially responsible.
The cloud was built according to the classical architectural model, which involves the purchase of all the necessary hardware and software: servers with physical and logical access, storage, network components, virtualization software, security solutions.
In two data centers in Moscow, the allocated closed zones on four racks with computing and network nodes are organized. The solution is built on Lenovo-made components. The 1U Lenovo ThinkSystem SR530 / SR570 / SR630 servers with Emulex 16Gb Gen6 FC Dual-port HBA adapters are used as hardware computing systems, Lenovo Storage V3700 V2 XP arrays are used for data storage, and 10-Gbps 32-port rack switches are used for data storage with Lenovo ThinkSystem NE1032 RackSwitch. The package includes factory-installed VMware ESXi 6.5 software on servers. Sites are connected by two 8 Gb / s FC channels and two 10 Gb / s Ethernet channels.
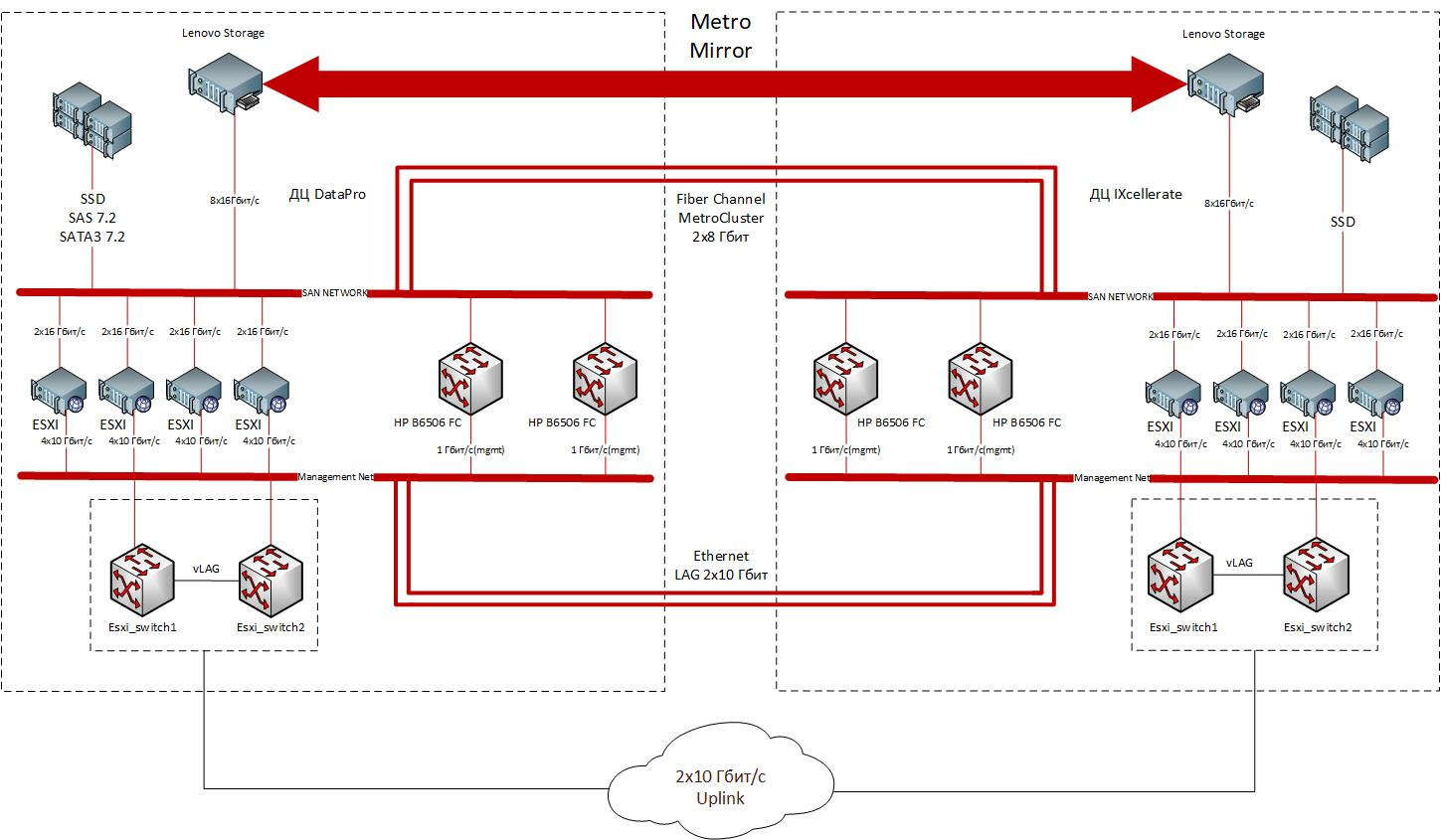
The structure of a geographically distributed cluster. The metro cluster located between two sites provides disaster recovery and makes it possible to provide reliable IaaS services to a wide range of customers. Sites are connected by redundant Ethernet (2x10 Gbit / s) and FC (2x8 Gbit / s) channels.
Due to the acquisition of infrastructure components from one supplier, the reliability and resiliency of the entire complex is increased, conflicts between elements, standards and protocols are eliminated.
The joint efforts of the two teams carried out work on the creation of the project, the preparation and elaboration of the TZ, the installation of equipment, the commissioning, the stress testing and the launch of the metrocluster into operation.
Lenovo Metrocluster provides full backup of all its elements: servers, storage, controllers, FC-adapters, optical switches. Synchronous data replication at the storage level provides a Recovery Point Objective (RPO) of zero.
High availability has always been achieved by ensuring redundancy - this is also true in the case of preparation for extreme situations, when the entire data center must be protected from power outages or natural disasters. If one of the sites fails, the geographically dispersed cluster automatically switches to the second data center without interrupting the workflows. In essence, a metrocluster is a local cluster with a mirrored storage system, spaced between two sites.
Geographically distributed clusters do not have critical points of failure. In the metrocluster, mutual synchronous data replication between sites is implemented. When a problem occurs, switching to another site is completely transparent and without administrator intervention. Automation of this process ensures continuous operation of all applications. Metro clusters also do not need to be stopped in order to upgrade their hardware or software.
For example, if the entire server fails, its responsibilities within a few seconds go to the second server located on the same site. Short-term data input / output interruption in this case will not affect the operation of the applications, since the data is synchronously mirrored to the second site. If there is a problem with the switch, cable or HBA-adapter Fiber Channel backup switching to the second data center is not required, and the end user will not feel any reduction in application performance.

In the event of a failure of the entire service node, a short-term (several seconds) interruption of the I / O flows occurs: services are first transferred to neighboring nodes, and the need to switch to a remotely located node occurs only if the site is completely disrupted.
In this situation, the geographically distributed cluster uses redundancy at the data center level to overcome the failure, and the systems located on the second site assume the support of all services. Thus, application servers retain access to all services, but with limited performance.
When the site on which the failure occurred re-enters the operating mode, it will be necessary to transfer to it only the data that was changed during the idle time, so after the elimination of local problems, the affected data center can return to normal operation very quickly.
In case of loss of VMware hosts, High Availability (HA) immediately restarts the VM on the remote site. If one of the storage systems fails, the storage system on the other site announces the paths to the disks to the remaining hosts. Lost VMs are restarted on them, everything happens automatically.
If the connection between the sites is lost, then everything continues to work in its place and, as soon as the connection is restored, the synchronization process begins.

The Lenovo ThinkSystem SR630 server, distinguished by the most capacious storage subsystem and the highest performance among all Lenovo servers with a height of 1U, copes with a variety of workloads. It allows the use of reference cloud building models.
The ThinkSystem SR630 server contains two high-performance Intel Xeon processors, up to four PCIe 3.0 slots for installing various I / O adapters. AnyBay technology provides support for hard drives and solid-state drives with SAS or SATA interfaces (12 SFF form factor devices or 4 LFF form factor devices). Four NVMe ports on the motherboard are designed for direct connection of NVMe drives.

Lenovo Storage V3700 V2 XP is a continuation of the IBM Storwize line. The XP version is characterized by high performance and configuration flexibility.
What is the result? The deployed “Mastertel” metro-cluster allows, due to the support of synchronous mirroring and clustering on the basis of arrays, to achieve permanent readiness and completely eliminate data loss. The software provides transparent failover, which ensures uninterrupted operation of mission-critical applications. Lenovo is not the first time participating in such projects. The company's product portfolio includes servers, storage systems and networking tools. And x86 servers act as aVMware virtualization platform .
Of course, a metrocluster is a difficult and expensive solution, but in those cases when it is necessary to ensure uninterrupted operation, when the cost of downtime or data damage is high, they usually prefer not to save.
Gradually dispel doubts about the reliability and safety of clouds. As a recent study by iKS-Consulting has shown , almost 40% of the polled Russian companies see the use of public clouds as an opportunity to increase the security of their IT systems. The most popular infrastructure cloud service is the rental of virtual servers. In the second place in popularity is the cloud backup service (Backup-as-a-Service). About a third of respondents use cloud services to host storage and DR infrastructure.
Meanwhile, with the increasing dependence of business on IT requirements for the reliability of IT services, including cloud services, are growing. Moreover, it is often necessary to ensure not only hardware reliability, but also disaster recovery.
According to research , almost three-quarters of organizations in the world are not completely sure that they can restore their systems and data. Unplanned downtime and data loss cost organizations around the world more than $ 1.7 billion annually. According to Acronis researchIn Russia, only 2% of surveyed companies are absolutely sure that their IT infrastructure will pass any test. Half of Russian specialists expect long interruptions in its work in the event of a disaster or accident. According to world statistics, 93% of companies that have lost their data center for only 10 days are ruined during the year.
In any technically complex systems, accidents are unavoidable, but they can be made not critical for business. To prevent such situations, disaster-resistant cluster systems are created, virtually eliminating downtime in the event of accidents and failures.
Another important point that should not be forgotten when designing a disaster-proof IT infrastructure is the workplaces of users. You need to resume business processes, and not just switch to a backup server or raise the database. Disaster resistance begins at the client’s office. Even a backup office with employee jobs is not the best option. A good solution can be virtual desktops (VDI) or other forms of workplace in the cloud. Access to such a workplace in a virtual machine in the data center is easy to organize from any computer in the branch network.
Innovation in the cloud
The Russian telecommunications operator MasterTel and Lenovo have jointly prepared and implemented a disaster- resilient cloud project called Innovate Cloud Technology . Based on this cloud, highly reliable IaaS services are provided to a wide range of customers who would like to deploy critical IT infrastructure in the cloud environment. The basis of the cloud was the metro cluster, spaced between two sites - DataPro data centers and IXсellerate in Moscow.
When choosing a partner for this project, MasterTel was guided, first of all, by the vendor’s ability to promptly provide the most complete solution for reasonable money. To implement the cloud, launched in October 2018, a team of specialists from Lenovo Professional Services was involved. MasterTel acts as a cloud provider (Cloud Service Provider) and a telecommunications operator that organizes secure communication channels and provides direct fiber-optic lines, is responsible for the operation of the cloud and its support.
Innovate Cloud Technology is a private cloud for corporate clients, offering highly reliable and real-time scalable cloud services IaaS, BaaS, DRaaS, VDS, etc. What does the use of services Innovate Cloud Technology?
High reliability
Currently, most cloud projects, in fact, provide power for rent. As a rule, this is the creation of virtual servers (the most common commercial data center service in Russia) and access to an already formed pool of resources. In the case of Innovate Cloud Technology, all settings can be made by the customer online, resources are allocated and released dynamically and pay-after-the-fact, exclusively for the resources used, as befits a classic cloud service.
But perhaps the most important feature of Innovate Cloud Technology is high reliability. Customers can use high-availability cloud infrastructure and store highly critical data in geographically dispersed DataPro and IXCellerate data centers. These sites by themselves guarantee reliability and a high level of physical and information security. A reliable high-speed communication channels and access to both data centers provides MasterTel.
Innovate Cloud Technology is a cloud resource with guaranteed availability of 99.99% for SLA. However, this cloud is distinguished not only by high reliability, but also by disaster recovery, since this is a geographically distributed virtualization cluster at two sites of the Tier III level.
DataPro Data Center
This data center Tier III on the street. Aviamotornaya in Moscow is one of the few Russian commercial data centers that have been certified by Uptime Design and Facility. All technologies and solutions used in the data center are certified, which means maximum resiliency, guaranteed availability of resources and is an insurance against unexpected situations.
DataPro Data Center Control Center. International certification of Uptime Design and Facility means that it is designed and built in accordance with all applicable standards for the Tier III reliability category.
Security is responsible for the security of the data center and the surrounding area. Security system includes more than 350 network cameras. For uninterrupted and uninterrupted power supply, uninterruptible power supplies (UPS) are used, diesel generator sets (DGS) are used, which support the work of the data center during a prolonged power outage.
In the DataPro data center - two independent inputs of 10 kV from the Mosenergo substation, and the cables are laid in different collectors, provide the supply of the necessary electrical power to the object. The power supply of the data center is actually reserved under the 2N scheme.
IXcellerate Moscow One
IXcellerate's Moscow One data center also has a Tier III Uptime Institute certificate in the Design category. The facility also corresponds to the Level 3 reliability level in the categories “project”, “construction”, and “operation” according to the IBM Reliability Rating System methodology. IXcellerate Moscow One is technically implemented and guaranteed at the SLA level with an accessibility indicator of 99.999%. The total area of the IXcellerate Moscow One data center in Degunino is 15,741 sq. M. The design capacity of the facility reaches 13.7 MW. Data Center customers - about a hundred international and Russian companies.
Passing certification tests of the Uptime Institute proves that the IXcellerate computer complex is designed in accordance with modern world practices of building data processing centers.
Disaster tolerance
Distribution over two sites requires the organization of reserved communication channels, replication of data between storages. We need a data synchronization mechanism to ensure their relevance in case of failure of one of the nodes and to support the work of those information systems that need such synchronization.
Often at the heart of disaster-resistant data center - geographically distributed cluster configuration of servers with connection to a common storage area network (SAN). The nodes of such a distributed cluster are located on the main and backup sites, forming a single system. This ensures continuous availability of services even in the event of the loss of one of the data center. Using clustering, you can automatically switch the load between the sites of the distributed data center in the event of an accident.
Data storage systems at the indicated sites can completely duplicate each other, and the sites themselves connect with redundant high-speed communication channels, which allows realizing projects with the highest demands on the reliability of data transfer and their availability, including synchronous data replication.
VMware vSphere based metro cluster example. it is based on duplication of storage systems at two geographically separated sites with data replication and possible load balancing at the data center network level. If one of the data centers is unavailable, the virtual machines will be automatically started on the second platform. The metrocluster is almost zero idle, work is interrupted only during the launch of virtual machines, when VMware High Availability (HA) restarts the VM on the remote site with the storage system that is in the cluster.
If you use load balancing mechanisms for DR (Global Server Load Balancing, GSLB), then you can automatically switch users to the backup site when the primary fails. For users, this process will be transparent.
Unlike DR with data replication, in the case of a metrocluster, only identical disk types are used for mirroring, an identical configuration is needed at both sites.
The cloud of Innovate Cloud Technology based on VMware is built according to this scheme. It provides continuous operation of critical applications and data in the cloud. All elements of the virtualization cluster are duplicated at two sites, located almost 30 km apart. Between them, data is mirrored at the storage system level. Due to this, data and services will be available in case of failures on one of the sites: power outage, partial failure of storage systems, controllers, communication channels between the data center, and even if one of the sites is completely inoperable.
When one of the data centers is unavailable, virtual machines are migrated to a backup site. Running a virtual machine on a backup site (Recovery Time Objective, RTO) will take about 3 minutes.
Customers are offered a detailed service level agreement (Service Level Agreement, SLA). Its main indicators: service availability at the level of 99.99%; idle time - no more than 4.38 minutes per month, guaranteed parameters of processor performance (MIPS / 1 vCPU), disk system (IOPS, GB / s), delays when accessing the storage system. For their compliance with the provider is financially responsible.
Anatomy of the metrocluster
The cloud was built according to the classical architectural model, which involves the purchase of all the necessary hardware and software: servers with physical and logical access, storage, network components, virtualization software, security solutions.
In two data centers in Moscow, the allocated closed zones on four racks with computing and network nodes are organized. The solution is built on Lenovo-made components. The 1U Lenovo ThinkSystem SR530 / SR570 / SR630 servers with Emulex 16Gb Gen6 FC Dual-port HBA adapters are used as hardware computing systems, Lenovo Storage V3700 V2 XP arrays are used for data storage, and 10-Gbps 32-port rack switches are used for data storage with Lenovo ThinkSystem NE1032 RackSwitch. The package includes factory-installed VMware ESXi 6.5 software on servers. Sites are connected by two 8 Gb / s FC channels and two 10 Gb / s Ethernet channels.
The structure of a geographically distributed cluster. The metro cluster located between two sites provides disaster recovery and makes it possible to provide reliable IaaS services to a wide range of customers. Sites are connected by redundant Ethernet (2x10 Gbit / s) and FC (2x8 Gbit / s) channels.
Due to the acquisition of infrastructure components from one supplier, the reliability and resiliency of the entire complex is increased, conflicts between elements, standards and protocols are eliminated.
The joint efforts of the two teams carried out work on the creation of the project, the preparation and elaboration of the TZ, the installation of equipment, the commissioning, the stress testing and the launch of the metrocluster into operation.
Lenovo Metrocluster provides full backup of all its elements: servers, storage, controllers, FC-adapters, optical switches. Synchronous data replication at the storage level provides a Recovery Point Objective (RPO) of zero.
High availability has always been achieved by ensuring redundancy - this is also true in the case of preparation for extreme situations, when the entire data center must be protected from power outages or natural disasters. If one of the sites fails, the geographically dispersed cluster automatically switches to the second data center without interrupting the workflows. In essence, a metrocluster is a local cluster with a mirrored storage system, spaced between two sites.
Geographically distributed clusters do not have critical points of failure. In the metrocluster, mutual synchronous data replication between sites is implemented. When a problem occurs, switching to another site is completely transparent and without administrator intervention. Automation of this process ensures continuous operation of all applications. Metro clusters also do not need to be stopped in order to upgrade their hardware or software.
For example, if the entire server fails, its responsibilities within a few seconds go to the second server located on the same site. Short-term data input / output interruption in this case will not affect the operation of the applications, since the data is synchronously mirrored to the second site. If there is a problem with the switch, cable or HBA-adapter Fiber Channel backup switching to the second data center is not required, and the end user will not feel any reduction in application performance.
In the event of a failure of the entire service node, a short-term (several seconds) interruption of the I / O flows occurs: services are first transferred to neighboring nodes, and the need to switch to a remotely located node occurs only if the site is completely disrupted.
In this situation, the geographically distributed cluster uses redundancy at the data center level to overcome the failure, and the systems located on the second site assume the support of all services. Thus, application servers retain access to all services, but with limited performance.
When the site on which the failure occurred re-enters the operating mode, it will be necessary to transfer to it only the data that was changed during the idle time, so after the elimination of local problems, the affected data center can return to normal operation very quickly.
In case of loss of VMware hosts, High Availability (HA) immediately restarts the VM on the remote site. If one of the storage systems fails, the storage system on the other site announces the paths to the disks to the remaining hosts. Lost VMs are restarted on them, everything happens automatically.
If the connection between the sites is lost, then everything continues to work in its place and, as soon as the connection is restored, the synchronization process begins.
The composition of the decision
| Eight Lenovo ThinkSystem SR630 servers with 2 Intel Xeon Gold 6132 14C 140W 2.6 GHz processors, 32 GB TruDDR4 2666 MHz memory (RDIMM), 10 bays for 2.5 "drives, M.2 32 GB SATA SSD and factory-installed VMware ESXi 6.5. | Dual-processor server in 1U form factor has the flexibility and performance due to the support of hard drives and solid-state drives (HDD and SSD) with SAS or SATA interfaces (12 SFF or 4 LFF). With the ability to connect NVMe drives, it provides high speed read and write. The Lenovo XClarity Administrator software simplifies infrastructure management and maintenance. This design solution is focused on the balance of performance and price to support a wide range of workloads, designed for continuous operation at a temperature of 45 ° C. |
| Two storage systems Lenovo Storage V3700 V2 XP with 1.92 TB 2.5 "SAS SSD and 1.2 TB 2.5" 10K HDD, with Easy Tier, FlashCopy and Remote Mirroring software. | A set of functional storage tools allows you to effectively solve problems with large amounts of data and with multi-threaded access to information resources. The V3700 V2 XP provides the ability to consolidate workloads, supports the formation of data storage systems capable of supporting multiple resource-intensive applications. The system on Intel processors is characterized by high performance and speed of data exchange through the SAS bus, functional tools that were previously available only in high-end devices. The storage system offers a Web-based interface with integrated management functions, ensures the formation of flexible working configurations and their rapid deployment using virtualization tools, and the execution of application backup using FlashCopy. Supports vertical scaling up to 240 2.5-inch drives or 120 drives in a 3.5-inch form factor. For scaling, you can use nine expansion units. |
| Storage Lenovo V3700 V2 with 20 disks 2 TB 2.5 "7.2K HDD | The system provides a set of tools that provide unified virtualization, scaling and management. It is a hybrid solution with virtualization capabilities. Storage Lenovo Storage V3700 V2 has two RAID-controller, allows you to use any storage formats - as a hard disk form factor 3.5 ", and HDD or SSD form factor 2.5". Storage comes standard with system software with Virtualization of Internal Storage, Thin Provisioning, One-way Data Migration, FlashCopy features (64 copies). Additional features - FlashCopy (2048 copies), Easy Tier, Remote Mirroring. |
| Four Lenovo ThinkSystem NE1032 32-Port 10 Gbps Ethernet Switches with SFP + SR Transceivers. | The switch is equipped with 24 10GBase-T ports and 8 10 Gbps SFP + ports for cascading. It uses the architecture of the Lenovo Cloud NOS, supports automation based on VM. The NE1032 system is optimized for data centers. It is distinguished by stable L2 / L3 performance and competitive routing by IP addresses, a fault-tolerant stack with BGP support, automation based on VMs, automatic provision of resources to speed up commissioning, and integration with Lenovo XClarity software. |
| Four Lenovo B6505 FC SAN Fiber Channel switches with 12 16 Gbps SFP ports. | These 5th generation Fiber Channel switches for storage area networks are designed to connect to high-performance data warehouses and are designed to support mission-critical business applications. They support flash and hybrid disk array technologies at 16 Gbps. |
The Lenovo ThinkSystem SR630 server, distinguished by the most capacious storage subsystem and the highest performance among all Lenovo servers with a height of 1U, copes with a variety of workloads. It allows the use of reference cloud building models.
The ThinkSystem SR630 server contains two high-performance Intel Xeon processors, up to four PCIe 3.0 slots for installing various I / O adapters. AnyBay technology provides support for hard drives and solid-state drives with SAS or SATA interfaces (12 SFF form factor devices or 4 LFF form factor devices). Four NVMe ports on the motherboard are designed for direct connection of NVMe drives.
Lenovo Storage V3700 V2 XP is a continuation of the IBM Storwize line. The XP version is characterized by high performance and configuration flexibility.
What is the result? The deployed “Mastertel” metro-cluster allows, due to the support of synchronous mirroring and clustering on the basis of arrays, to achieve permanent readiness and completely eliminate data loss. The software provides transparent failover, which ensures uninterrupted operation of mission-critical applications. Lenovo is not the first time participating in such projects. The company's product portfolio includes servers, storage systems and networking tools. And x86 servers act as aVMware virtualization platform .
Of course, a metrocluster is a difficult and expensive solution, but in those cases when it is necessary to ensure uninterrupted operation, when the cost of downtime or data damage is high, they usually prefer not to save.