Getting started with the Azure Machine Learning service
Today we look at our fifth iteration of creating a machine learning product. To approach this topic, we briefly recall previous products and their current status. Consider only fully integrated solutions that allow you to go from calculating the model to use in real cases in one full-fledged product.
I give the floor to the author, our MVP, Mikhail Komarov.
This article is on our news portal.
We do not consider HDInsight, DataScience virtual machine and other independent components related to machine learning, as well as cognitive services.
The current version of the Azure Machine Learning Service is available for paid use from December 2018, there is also a limited free version.
Microsoft splits the Azure Machine Learning Service into three big stages: data preparation, the experiment itself with model creation, deployment. On the diagram, it looks like this:

Next is a slightly more detailed diagram, especially pay attention to Python support and the lack of support R. It gives us information about how everything happens.

The final part is a taxonomy, in which three key building blocks are visible: the creation and calculation of the model (left), the collection of data on the model calculation process (center), the deployment and support of the expanded model. Let us dwell on each key block in more detail.

The work begins with the creation of an account in Azure, if it is not there - then with the help of simple combinations we create an account and go to portal.azure.com . There we select Create a resource, then click on the Azure Machine learning service workspace. Select a subscription, create a region and a new resource group.

After a few minutes of working with the cloud, we will get the following result on the Dashboard, and then move on to the Machine Learning service workspace.


We choose Azure Machine Learning service workspace, we open Microsoft Azure Notebooks, where we propose to clone an example, we agree, we choose a tutorial - it contains an example of image classification.

At startup, check if the Python 3.6 kernel is selected, and you can follow the example step by step. The description of the example steps is not included in the article.
The idea in general is that using a browser and standard Jupyter notebook with Python code, we can create, calculate and save a model. There is another way - using Visual Studio Code, we can connect to our area and see the properties of objects, also write code there, not forgetting to install the Azure ML plugin. In passing, we note that as soon as we began to use Visual Studio Code, we automatically received a normal IDE with version control.


At the end of the section we will pay attention to the possibility of choosing a place for the calculation and for the deployment of models.

Monitoring the process and deployment of the service
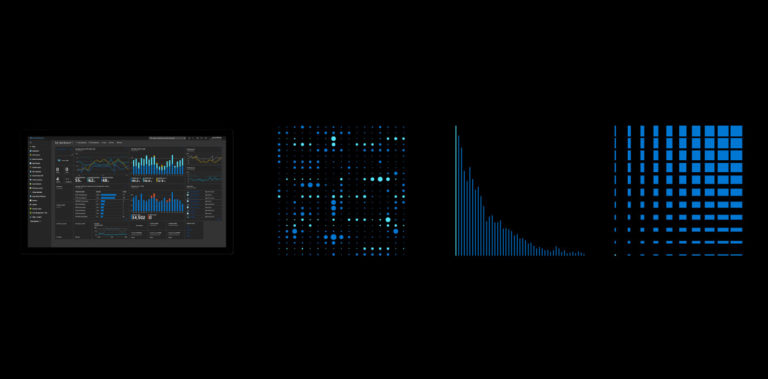
You can see the Experiments section, where the parameters of the calculated model are displayed.

We are interested in Image - Azure Container Instance, in other words, this is a
Docker-container with our model, which is located in the cloud.


The deployment process comes from Visual Studio Code or Microsoft Azure Notebooks. At the end of the service deployment, the core of which is our copy of the container with the model, we get the following picture:


After the experiment is completed, we will not forget to delete the service and all the allocated resources so that automatic debiting of your bank card does not occur. It's easier to delete the entire created resource group.

As a result, we have a solution of enterprise scale, with the possibility of automatic calculation of the model, deployment and automatic return to the previous model in case of unsatisfactory result of the metrics.
azure.microsoft.com/en-us/services/machine-learning-service
Mikhail Komarov, Microsoft MVP
More than 20 years in the IT field. Interests: virtualization, infrastructure, data analysis and machine learning. Engaged in supporting existing and implementing new systems aimed at improving the efficiency of work in the corporate segment. Previously, he worked as an information technology coach.
I give the floor to the author, our MVP, Mikhail Komarov.
This article is on our news portal.
We do not consider HDInsight, DataScience virtual machine and other independent components related to machine learning, as well as cognitive services.
- In SQL Server 2005, a data mining component has appeared, including the DMX language, as well as an extension for Excel. The last extension worked on Excel. Currently, the product is not developed, although it is in current versions of SQL Sever and exists for backward compatibility.
- It's been 10 years. In 2016, the Azure Machine Learning Studio project started. Last cosmetic update - October 2018, library R. At the moment, is not the mainstream. The main drawbacks are the impossibility of exporting and importing models, as well as issues with scalability. An example of use can be found at the link . Most likely, in 2-3 years he will quietly leave the stage.
- SQLServer 2016 (support only R), SQL 2017,2019 (support R and Python), as well as a dedicated server for machine learning. There is an active development of the product in terms of expanding machine learning opportunities in the corporate environment (clustering and other elements of the enterprise scale). There are cases with the analysis of a large amount of data in real time. Interesting for those who are not ready to share data with the cloud.
- In 2017, a preliminary version of the Azure Machine Learning Workbench appeared, was installed locally with Python, but required an account in Azure. For those who are interested, look here . At the moment the project is closed, but many ideas are transferred to the Azure Machine Learning Service.
The current version of the Azure Machine Learning Service is available for paid use from December 2018, there is also a limited free version.
Microsoft splits the Azure Machine Learning Service into three big stages: data preparation, the experiment itself with model creation, deployment. On the diagram, it looks like this:
Next is a slightly more detailed diagram, especially pay attention to Python support and the lack of support R. It gives us information about how everything happens.
The final part is a taxonomy, in which three key building blocks are visible: the creation and calculation of the model (left), the collection of data on the model calculation process (center), the deployment and support of the expanded model. Let us dwell on each key block in more detail.
The work begins with the creation of an account in Azure, if it is not there - then with the help of simple combinations we create an account and go to portal.azure.com . There we select Create a resource, then click on the Azure Machine learning service workspace. Select a subscription, create a region and a new resource group.
After a few minutes of working with the cloud, we will get the following result on the Dashboard, and then move on to the Machine Learning service workspace.
We choose Azure Machine Learning service workspace, we open Microsoft Azure Notebooks, where we propose to clone an example, we agree, we choose a tutorial - it contains an example of image classification.
At startup, check if the Python 3.6 kernel is selected, and you can follow the example step by step. The description of the example steps is not included in the article.
The idea in general is that using a browser and standard Jupyter notebook with Python code, we can create, calculate and save a model. There is another way - using Visual Studio Code, we can connect to our area and see the properties of objects, also write code there, not forgetting to install the Azure ML plugin. In passing, we note that as soon as we began to use Visual Studio Code, we automatically received a normal IDE with version control.
At the end of the section we will pay attention to the possibility of choosing a place for the calculation and for the deployment of models.
Monitoring the process and deployment of the service
You can see the Experiments section, where the parameters of the calculated model are displayed.
We are interested in Image - Azure Container Instance, in other words, this is a
Docker-container with our model, which is located in the cloud.
The deployment process comes from Visual Studio Code or Microsoft Azure Notebooks. At the end of the service deployment, the core of which is our copy of the container with the model, we get the following picture:
After the experiment is completed, we will not forget to delete the service and all the allocated resources so that automatic debiting of your bank card does not occur. It's easier to delete the entire created resource group.
As a result, we have a solution of enterprise scale, with the possibility of automatic calculation of the model, deployment and automatic return to the previous model in case of unsatisfactory result of the metrics.
Resources:
azure.microsoft.com/en-us/services/machine-learning-service
about the author
Mikhail Komarov, Microsoft MVP
More than 20 years in the IT field. Interests: virtualization, infrastructure, data analysis and machine learning. Engaged in supporting existing and implementing new systems aimed at improving the efficiency of work in the corporate segment. Previously, he worked as an information technology coach.