Once again about the architecture of network daemons
In many articles, including on the Habr, various ways of building the architecture of network services (daemons) are mentioned and even described. However, few authors have real experience in creating and optimizing daemons that work with tens of thousands of simultaneous connections and / or gigabit traffic.
Since most authors do not even bother to get into the documentation, usually in such articles all information is based on certain rumors and retelling of rumors. These rumors roam the web and hit Wikipedia, Habrahabr and other reputable resources. The result is opuses like, " You are probably joking, Mr. Dahl, or why Node.js"(the author’s punctuation is preserved): it is basically true in essence, but it is replete with inaccuracies, contains a number of factual errors and depicts an object from some incomprehensible angle.
It was difficult for me to go past an article full of phrases like" effective polling implementations to date, there are only * nix systems "(as if poll () is somewhere other than some * nix). This post began as a comment explaining the respected inikulin errors in his article. During the writing process, it turned out to be easier to state subject from the very beginning that I actually doing a separate post.
In my essay, there is no breakdown of the covers or some unknown tricks, it simply describes the advantages and disadvantages of different approaches by a person who checked how all this works in practice in different operating systems.
For those wishing to enlighten, welcome to cat.
First you need to understand what exactly network services should do and what, in general, is the problem.
Any daemon must accept and process network connections. Since the TCP / IP protocol stack has grown from UNIX, and this OS professes the dogma “everything is a file”, network connections are files of a special type that can be opened, closed, read and written by standard OS functions for working with files. Pay attention to the modal verb “can”, in conjunction with the word “theoretically” it very accurately describes reality.
So, first of all, any daemon calls the system functions socket (), then bind (), then listen () and as a result receives a file of the special type “listening socket”. The parameters of these functions and further actions of the daemon very much depend on the transport protocol used (TCP, UDP, ICMP, RPD ...), however, in most operating systems you can bind only the first two. In this article, we will look at the most popular TCP protocol as an example.
Although the listening socket is a file, all that can happen to it is periodically occurring events such as “incoming connection request”. The daemon can accept such a connection with the accept () function, which will create a new file, this time of the type “open TCP / IP network socket”. Presumably, the daemon should read the request from this connection, process it and send back the result.
At the same time, a network socket is already a more or less normal file: although it was not created in the most standard way, at least you can try to read and write data from it. But there are significant differences from ordinary files located on the file system:
* All events occur really asynchronously and with an unknown time duration. Any operation in the worst case may take tens of minutes. Generally any.
* Connections, unlike files, can be closed "by themselves" at any, most unexpected moment.
* The OS does not always report a closed connection, "dead" sockets can hang for half an hour.
* Connections on the client and on the server are closed at different times. If the client tries to create a new connection and "send" the data, duplication of data is possible, and if the client is incorrectly written, it may be lost. It is also possible that the server has several open connections from one client.
* Data is regarded as a stream of bytes and can literally come in portions of 1 byte. Therefore, it is impossible to consider them, for example, as UTF-8 strings.
* There are no buffers other than those provided by the daemon on the network. Therefore, writing to the socket even 1 byte can block the daemon for tens of minutes (see above). In addition, the memory on the server is “non-rubber”; the daemon must be able to limit the speed with which the results are generated.
* Any errors can happen anywhere, the daemon must correctly handle them all.
If you write a loop on all open connections “forehead”, then the first “hanging” connection will block all others. Yes, for tens of minutes. And here there are various options for organizing the interaction of various modules of the daemon. See the figure:

Disclaimer : The figure shows the pseudo-language code that does not correspond to reality. Many important system calls and all error handling code are omitted for clarity.
The simplest way to prevent connections from affecting each other is to start a separate process for each of them (that is, a separate copy of your program). The disadvantages of this method are obvious - starting a separate process is a very resource-intensive operation. But most of the articles do not explain why exactly this method is used in the same Apache.
And the thing is that the process in all OSs is the unit of accounting for system resources - memory, open files, access rights, quotas, and so on. If you create a remote access daemon for an operating system like Shell or FTP, you simply have to start a separate process on behalf of each logged-in user in order to correctly consider file permissions. Similarly, hundreds of sites of different users are spinning on a shared hosting server at the same time on one “physical” port - and processes need apache so that sites of some hosting users cannot get into the data of other users. Using processes does not really affect Apache's performance:
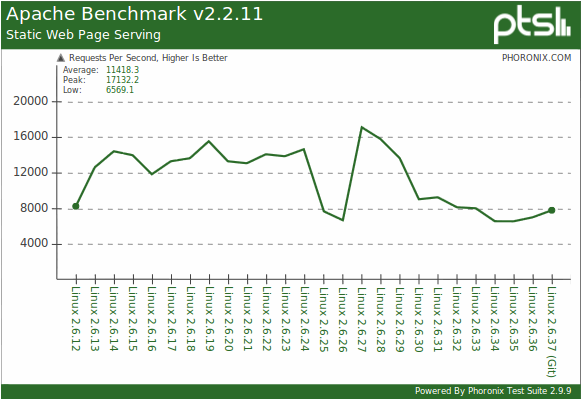
On the graph, the number of processed requests to a static file per second, depending on the version of the Linux kernel. More is better.
Test bench: Core i7 970, 3Gb DDR3, Nvidia GTX 460, 64GB OCZ Vertex SSD.
Source: Phoronix.
I wish your demons to give 17k files per second.
Even if the users of your daemon are not registered in the operating system, but increased security requirements are put forward for your service, allocating a separate process for each user is a very reasonable architectural solution. This will not allow bad users to gain or block access to the data of other users, even if they find a bug in your daemon that allows reading other people's data or simply destroying the daemon process.
Finally, each process has its own address space, and different processes do not interfere with each other's use of memory. Why this advantage is explained in part
Streams are the easiest “processes” that have shared memory, system resources and access rights, but different stacks. This means that threads have common dynamic, global and static variables, but different local ones. In multiprocessor and / or multicore systems, different threads of the same process can be performed physically simultaneously.
A multi-threaded architecture is similar to a multi-process architecture in which security and stability are sacrificed for performance and memory consumption.
The main advantage of multi-threaded architecture after performance is the sequence and synchronism of the open connection processing algorithm. This means that the algorithm looks and executes exactly as it is shown in the illustration in the first part. First, data is read from the socket, as much time as needed, then they are processed - again, as much time as this processing will require, then the results are sent to the client. At the same time, if you start sending results too quickly, the stream will automatically be blocked by the write () function. The processing algorithm is simple and straightforward at least at the highest level. This is a very, very big plus.
For a relatively small number of simultaneous connections, multi-threaded architecture is an excellent choice. But if there are really many connections, say ten thousand, switching between threads starts to take too much time. But even this is not the main drawback of multi-threaded architecture.
And the main thing is that the threads are not independent and can (and will) block each other. To understand how this happens, consider an example.
Suppose we need to calculate the value of an expression
, where a, b, and c are global variables.
In a normal, single-threaded situation, the compiler will generate something like this machine code:
In a multi-threaded version, this code cannot be used. Another thread can change the value of b between the first and second instructions, as a result of which we get the wrong value of a. If somewhere else it is considered that a is always equal to b + c, a very difficult to reproduce "floating" error will occur.
Therefore, in a multi-threaded version, a code is used like this: where lock and unlock are atomic operations of locking and unlocking access to a variable. They are arranged in such a way that if the variable is already locked by another thread, the lock () operation will wait for it to be released.
Thus, if two threads start simultaneously performing the operations a = b + c and b = c + a, they will block each other forever. This situation is called clinching, the search and resolution of clinches is a separate “sore subject” of parallel programming. But even without clinches, threads, if they do not release the lock quickly, can stop each other for quite long periods of time.
In addition, atomic operations are physically implemented through the exclusive capture of the RAM bus and the RAM itself. Working directly with memory, and not with the cache, is very slow in itself, and in this case also causes invalidation (reset) of the corresponding cache lines of all the cores of all other server processors. That is, even in the best case, in the absence of locks, each atomic operation is performed for a sufficiently long time and degrades the performance of other threads.
But, it would seem, since the connections in the demons are almost independent, where can they get the common variables?
And here's where:
* The general queue of new connections;
* The general queue for access to a database or similar resources;
* The general queue of requests for memory allocation (yes, malloc () and new () can cause blocking);
* General log (log-file) and general objects of statistics calculation.
These are only the most obvious.
In some cases, there are ways to dispense with shared variables. For example, you can refuse blocking the queue of new connections if you endow one of the streams with the function of a “dispatcher”, which will hand out tasks in a cunning way. Sometimes it is possible to apply special "non-blocking" data structures. But in general, the problem of deadlocks in multi-threaded architecture is not solved.
Ideally, the number of threads in the application should be approximately equal to the number of processor cores in order of magnitude. One mechanism to achieve this is non-blocking I / O.
Non-blocking I / O is just a file access mode that can be installed on most modern operating systems. If in the usual “blocking” mode the read function reads as many bytes from the file as the programmer ordered, and while this reading is in progress “lulls” the stream that caused it, then in non-blocking mode the same read function does not read from the file, but from it cache, as many bytes as there are in this cache, and after that it returns immediately, without streaming any traffic or blocking it. If the cache was empty, a non-blocking read () will read 0 bytes, set the system error code to EWOULDBLOCK, and return immediately. But still, this is a regular synchronous call to a regular synchronous function.
Asynchronous I / O is discussed in detail in the next part, but here we focus on the use of non-blocking read and write functions.
In real conditions, 95% of nonblocking read () calls will read 0 bytes each. To avoid these “idle” calls of the OS kernel, there is a select () function that allows you to ask the operating system to select from your list of connections those that can already be read and / or written. Some * nix operating systems have a variant of this function called poll ().
In any case, although select () has certain limitations (in particular, on the number of files in one request), using this function and non-blocking I / O mode is a way to transfer all work to the operating system in three dozen lines of code and simply process it your data. In most cases, the thread responsible for non-blocking I / O will consume only a couple of percent of the processing power of one core. Performing all calculations, the internal threads of the kernel of the operating system “eat up” dozens of times more.
Let's go back to reducing the number of threads.
So, in the daemon there are a large number of objects of the “connection” class, and there is a set of operations that need to be applied to each connection object, and in the right order.
In multi-threaded architecture, a separate thread is created for each connection object, and operations are naturally performed in blocking mode in the desired sequence.
In an architecture with non-blocking I / O, a stream is created for each operation, which is sequentially applied to different objects. This is a bit like SIMD instructions like MMX and SSE: one instruction is applied to several objects at once. To withstand the necessary sequence of operations (that is, first calculate the result, and then send it), job queues between threads are created in the general memory of the process. Typically, queues are created on the basis of ring buffers, which in this case can be implemented in a "non-blocking" way.
In a real network service, between reading the request and sending the result, there will be a rather complicated branched processing algorithm, possibly including calling the application server, DBMS or other “heavy” operations, as well as a full set of branches, loops, error handling at every step, etc. Break it all down into a previously unknown number of threads running simultaneously, and even so that the load on the processor cores is approximately the same - this is the highest level of developer skills that requires masterly mastery of all aspects of system programming. In most cases, they make it much simpler: they enclose everything that is between read () and write () in a separate stream, and start N = the number of cores of copies of this stream. And then crutches are invented for clinch members competing for resources, killing DBMSs, etc.
If you do not understand the difference between asynchronous and synchronous functions, then for simplicity you can assume that the asynchronous function is executed in parallel and simultaneously with the program that called it, for example, on the neighboring kernel. On the one hand, the calling program does not need to wait for the end of the calculations and it can do something useful. On the other hand, when the results of the asynchronous function are ready, you need to somehow inform the customer program about this. The way this message occurs is implemented in different OSs in very different ways.
Historically, one of the first operating systems to support asynchronous I / O was Windows 2000.
A typical use case was this: a single-threaded application (there were no multi-core processors then) downloads, for example, a large file for tens of seconds. Instead of freezing the interface and the “clock” that would have been observed with the synchronous call to read (), in the asynchronous version the main program flow does not “hang”, you can make a beautiful progress bar that displays the loading process, and the “cancel” button.
To implement the "progress bar", a special OVERLAPPED structure is passed to the asynchronous Windows I / O functions, in which the OS notes the current number of bytes transferred. The programmer can read the contents of this structure at any time convenient for him - in the main message processing cycle, by timer, etc. In the same structure, at the end of the operation, its final result will be recorded (total number of bytes transferred, error code if any, etc.).
In addition to this structure, you can transfer your own callback functions to asynchronous I / O functions that take a pointer to OVERLAPPED, which will be called by the operating system at the end of the operation.
A true, honest asynchronous launch of a callback function, through interrupting a program in any place wherever it is, is indistinguishable from starting a second thread of program execution on the same kernel. Accordingly, you need to either write callback functions very carefully, or apply all the “multithreaded” rules regarding blocking access to shared data, which, you see, is very strange in a single-threaded application. To avoid potential errors in single-threaded applications, Windows queues raw callsbacks, and the programmer must explicitly specify the places in his program where it can be interrupted to execute these callbacks (WaitFor * Object family of functions).
The asynchronous I / O scheme described above is “native” to the WindowsNT kernel, that is, all other operations are somehow implemented through it. Full name - IOCP (Input / Output Completion Port). It is believed that this scheme allows to achieve theoretically maximum performance from iron. Any daemons designed for serious work under Windows should be developed on the basis of IOCP. See the introduction to IOCP on MSDN for more details .
In Linux, instead of the normal OVERLAPPED structure, there is some weak similarity to aiocb, which allows determining only the fact of the operation completion, but not its current progress. Instead of user-defined callbacks, the kernel uses UNIX signals (yes, those that kill). Signals come completely asynchronously, with all the consequences, but if you don’t feel like a guru in writing reentrant functions, you can create a special type of file (signalfd) and read from it information about incoming signals with normal synchronous I / O functions, including non-blocking ones . See man aio.h for more details .
Using asynchronous I / O does not impose any restrictions on the architecture of the daemon, theoretically it can be any. But, as a rule, several workflows are used (by the number of processor cores) between which serviced connections are evenly distributed. A Finite State Machine (FSM) is built and programmed for each connection, the appearance of events (calls of callback functions and / or errors) transfers this automaton from one state to another.
As we can see, each method has its advantages, disadvantages and applications. If you need security - use processes, if speed is important under heavy load - non-blocking I / O, and if speed of development and code comprehensibility are important, then multi-threaded architecture is suitable. Asynchronous I / O is the main way in Windows. In any case, do not try to write code to work with I / O yourself. The network has free ready-made libraries for all architectures and operating systems, licked for decades almost to shine. Almost - because in your case you still have to twist, file and adjust to your conditions. The Internet is a complicated thing; there are no universal solutions for all occasions.
Be that as it may, daemons are not enough with one I / O, and much more complex “gags” happen during request processing. But this is a topic for another article, if anyone is interested.
1. The C10K problem (eng), thanks for the tip o_O_Tync
2. Help for the libev library , a tasty part with a description of the various mechanisms of mass input-output (eng), for the tip thanks saterenko
3. FAQ echo ru.unix.prog
4. Introduction to the libaio unix library (English)
5. Testing kernel performance from 2.6.12 to 2.6.37 .
Since most authors do not even bother to get into the documentation, usually in such articles all information is based on certain rumors and retelling of rumors. These rumors roam the web and hit Wikipedia, Habrahabr and other reputable resources. The result is opuses like, " You are probably joking, Mr. Dahl, or why Node.js"(the author’s punctuation is preserved): it is basically true in essence, but it is replete with inaccuracies, contains a number of factual errors and depicts an object from some incomprehensible angle.
It was difficult for me to go past an article full of phrases like" effective polling implementations to date, there are only * nix systems "(as if poll () is somewhere other than some * nix). This post began as a comment explaining the respected inikulin errors in his article. During the writing process, it turned out to be easier to state subject from the very beginning that I actually doing a separate post.
In my essay, there is no breakdown of the covers or some unknown tricks, it simply describes the advantages and disadvantages of different approaches by a person who checked how all this works in practice in different operating systems.
For those wishing to enlighten, welcome to cat.
TK for network daemon
First you need to understand what exactly network services should do and what, in general, is the problem.
Any daemon must accept and process network connections. Since the TCP / IP protocol stack has grown from UNIX, and this OS professes the dogma “everything is a file”, network connections are files of a special type that can be opened, closed, read and written by standard OS functions for working with files. Pay attention to the modal verb “can”, in conjunction with the word “theoretically” it very accurately describes reality.
So, first of all, any daemon calls the system functions socket (), then bind (), then listen () and as a result receives a file of the special type “listening socket”. The parameters of these functions and further actions of the daemon very much depend on the transport protocol used (TCP, UDP, ICMP, RPD ...), however, in most operating systems you can bind only the first two. In this article, we will look at the most popular TCP protocol as an example.
Although the listening socket is a file, all that can happen to it is periodically occurring events such as “incoming connection request”. The daemon can accept such a connection with the accept () function, which will create a new file, this time of the type “open TCP / IP network socket”. Presumably, the daemon should read the request from this connection, process it and send back the result.
At the same time, a network socket is already a more or less normal file: although it was not created in the most standard way, at least you can try to read and write data from it. But there are significant differences from ordinary files located on the file system:
* All events occur really asynchronously and with an unknown time duration. Any operation in the worst case may take tens of minutes. Generally any.
* Connections, unlike files, can be closed "by themselves" at any, most unexpected moment.
* The OS does not always report a closed connection, "dead" sockets can hang for half an hour.
* Connections on the client and on the server are closed at different times. If the client tries to create a new connection and "send" the data, duplication of data is possible, and if the client is incorrectly written, it may be lost. It is also possible that the server has several open connections from one client.
* Data is regarded as a stream of bytes and can literally come in portions of 1 byte. Therefore, it is impossible to consider them, for example, as UTF-8 strings.
* There are no buffers other than those provided by the daemon on the network. Therefore, writing to the socket even 1 byte can block the daemon for tens of minutes (see above). In addition, the memory on the server is “non-rubber”; the daemon must be able to limit the speed with which the results are generated.
* Any errors can happen anywhere, the daemon must correctly handle them all.
If you write a loop on all open connections “forehead”, then the first “hanging” connection will block all others. Yes, for tens of minutes. And here there are various options for organizing the interaction of various modules of the daemon. See the figure:
Disclaimer : The figure shows the pseudo-language code that does not correspond to reality. Many important system calls and all error handling code are omitted for clarity.
2. Multiprocess architecture
The simplest way to prevent connections from affecting each other is to start a separate process for each of them (that is, a separate copy of your program). The disadvantages of this method are obvious - starting a separate process is a very resource-intensive operation. But most of the articles do not explain why exactly this method is used in the same Apache.
And the thing is that the process in all OSs is the unit of accounting for system resources - memory, open files, access rights, quotas, and so on. If you create a remote access daemon for an operating system like Shell or FTP, you simply have to start a separate process on behalf of each logged-in user in order to correctly consider file permissions. Similarly, hundreds of sites of different users are spinning on a shared hosting server at the same time on one “physical” port - and processes need apache so that sites of some hosting users cannot get into the data of other users. Using processes does not really affect Apache's performance:
On the graph, the number of processed requests to a static file per second, depending on the version of the Linux kernel. More is better.
Test bench: Core i7 970, 3Gb DDR3, Nvidia GTX 460, 64GB OCZ Vertex SSD.
Source: Phoronix.
I wish your demons to give 17k files per second.
Even if the users of your daemon are not registered in the operating system, but increased security requirements are put forward for your service, allocating a separate process for each user is a very reasonable architectural solution. This will not allow bad users to gain or block access to the data of other users, even if they find a bug in your daemon that allows reading other people's data or simply destroying the daemon process.
Finally, each process has its own address space, and different processes do not interfere with each other's use of memory. Why this advantage is explained in part
3. Multithreaded architecture
Streams are the easiest “processes” that have shared memory, system resources and access rights, but different stacks. This means that threads have common dynamic, global and static variables, but different local ones. In multiprocessor and / or multicore systems, different threads of the same process can be performed physically simultaneously.
A multi-threaded architecture is similar to a multi-process architecture in which security and stability are sacrificed for performance and memory consumption.
The main advantage of multi-threaded architecture after performance is the sequence and synchronism of the open connection processing algorithm. This means that the algorithm looks and executes exactly as it is shown in the illustration in the first part. First, data is read from the socket, as much time as needed, then they are processed - again, as much time as this processing will require, then the results are sent to the client. At the same time, if you start sending results too quickly, the stream will automatically be blocked by the write () function. The processing algorithm is simple and straightforward at least at the highest level. This is a very, very big plus.
For a relatively small number of simultaneous connections, multi-threaded architecture is an excellent choice. But if there are really many connections, say ten thousand, switching between threads starts to take too much time. But even this is not the main drawback of multi-threaded architecture.
And the main thing is that the threads are not independent and can (and will) block each other. To understand how this happens, consider an example.
Suppose we need to calculate the value of an expression
a = b + c;, where a, b, and c are global variables.
In a normal, single-threaded situation, the compiler will generate something like this machine code:
a = b; // MOV A, B
a += c; // ADD A, C
In a multi-threaded version, this code cannot be used. Another thread can change the value of b between the first and second instructions, as a result of which we get the wrong value of a. If somewhere else it is considered that a is always equal to b + c, a very difficult to reproduce "floating" error will occur.
Therefore, in a multi-threaded version, a code is used like this: where lock and unlock are atomic operations of locking and unlocking access to a variable. They are arranged in such a way that if the variable is already locked by another thread, the lock () operation will wait for it to be released.
lock a;
lock b;
lock c;
a = b;
a += c;
unlock c;
unlock b;
unlock a;
Thus, if two threads start simultaneously performing the operations a = b + c and b = c + a, they will block each other forever. This situation is called clinching, the search and resolution of clinches is a separate “sore subject” of parallel programming. But even without clinches, threads, if they do not release the lock quickly, can stop each other for quite long periods of time.
In addition, atomic operations are physically implemented through the exclusive capture of the RAM bus and the RAM itself. Working directly with memory, and not with the cache, is very slow in itself, and in this case also causes invalidation (reset) of the corresponding cache lines of all the cores of all other server processors. That is, even in the best case, in the absence of locks, each atomic operation is performed for a sufficiently long time and degrades the performance of other threads.
But, it would seem, since the connections in the demons are almost independent, where can they get the common variables?
And here's where:
* The general queue of new connections;
* The general queue for access to a database or similar resources;
* The general queue of requests for memory allocation (yes, malloc () and new () can cause blocking);
* General log (log-file) and general objects of statistics calculation.
These are only the most obvious.
In some cases, there are ways to dispense with shared variables. For example, you can refuse blocking the queue of new connections if you endow one of the streams with the function of a “dispatcher”, which will hand out tasks in a cunning way. Sometimes it is possible to apply special "non-blocking" data structures. But in general, the problem of deadlocks in multi-threaded architecture is not solved.
4. Non-blocking architecture
Ideally, the number of threads in the application should be approximately equal to the number of processor cores in order of magnitude. One mechanism to achieve this is non-blocking I / O.
Non-blocking I / O is just a file access mode that can be installed on most modern operating systems. If in the usual “blocking” mode the read function reads as many bytes from the file as the programmer ordered, and while this reading is in progress “lulls” the stream that caused it, then in non-blocking mode the same read function does not read from the file, but from it cache, as many bytes as there are in this cache, and after that it returns immediately, without streaming any traffic or blocking it. If the cache was empty, a non-blocking read () will read 0 bytes, set the system error code to EWOULDBLOCK, and return immediately. But still, this is a regular synchronous call to a regular synchronous function.
Some confusion, in particular in the English-language Wikipedia, in which non-blocking synchronous input-output is called “asynchronous”, is caused, apparently, by not very curious apologists of the Linux OS. In this operating system for a long time, up to kernels 2.6.22-2.6.29, there simply were no asynchronous I / O functions at all (and even now there is not all the necessary set, in particular there is no asynchronous fnctl), and some programmers who wrote only under this OS, they mistakenly called non-blocking synchronous functions “asynchronous”, which can be traced in a number of old Linux manuals.
Asynchronous I / O is discussed in detail in the next part, but here we focus on the use of non-blocking read and write functions.
In real conditions, 95% of nonblocking read () calls will read 0 bytes each. To avoid these “idle” calls of the OS kernel, there is a select () function that allows you to ask the operating system to select from your list of connections those that can already be read and / or written. Some * nix operating systems have a variant of this function called poll ().
More about poll (): this feature appeared as a requirement of the next version of the POSIX standard. In the case of Linux, poll () was first implemented as a function of the standard C language library (libc> = 5.4.28) as a wrapper on top of the usual select (), and only after a while “moved” to the kernel. On Windows, for example, there is still no normal poll () function, but since Vista there is a certain palliative for simplifying application migration , also implemented as a wrapper around select () in C.
I can not help but share a graph showing what all these innovations lead to. On the graph - the time of pumping 10 GB of data through the loop interface, depending on the version of the kernel. Less is better. The source is the same, the test bench is the same.
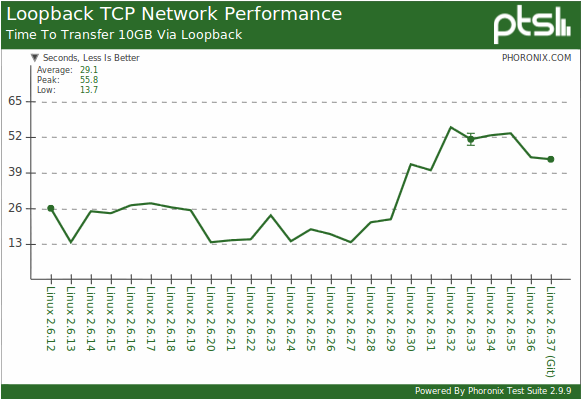
In any case, although select () has certain limitations (in particular, on the number of files in one request), using this function and non-blocking I / O mode is a way to transfer all work to the operating system in three dozen lines of code and simply process it your data. In most cases, the thread responsible for non-blocking I / O will consume only a couple of percent of the processing power of one core. Performing all calculations, the internal threads of the kernel of the operating system “eat up” dozens of times more.
Let's go back to reducing the number of threads.
So, in the daemon there are a large number of objects of the “connection” class, and there is a set of operations that need to be applied to each connection object, and in the right order.
In multi-threaded architecture, a separate thread is created for each connection object, and operations are naturally performed in blocking mode in the desired sequence.
In an architecture with non-blocking I / O, a stream is created for each operation, which is sequentially applied to different objects. This is a bit like SIMD instructions like MMX and SSE: one instruction is applied to several objects at once. To withstand the necessary sequence of operations (that is, first calculate the result, and then send it), job queues between threads are created in the general memory of the process. Typically, queues are created on the basis of ring buffers, which in this case can be implemented in a "non-blocking" way.
In a real network service, between reading the request and sending the result, there will be a rather complicated branched processing algorithm, possibly including calling the application server, DBMS or other “heavy” operations, as well as a full set of branches, loops, error handling at every step, etc. Break it all down into a previously unknown number of threads running simultaneously, and even so that the load on the processor cores is approximately the same - this is the highest level of developer skills that requires masterly mastery of all aspects of system programming. In most cases, they make it much simpler: they enclose everything that is between read () and write () in a separate stream, and start N = the number of cores of copies of this stream. And then crutches are invented for clinch members competing for resources, killing DBMSs, etc.
5. Asynchronous I / O
If you do not understand the difference between asynchronous and synchronous functions, then for simplicity you can assume that the asynchronous function is executed in parallel and simultaneously with the program that called it, for example, on the neighboring kernel. On the one hand, the calling program does not need to wait for the end of the calculations and it can do something useful. On the other hand, when the results of the asynchronous function are ready, you need to somehow inform the customer program about this. The way this message occurs is implemented in different OSs in very different ways.
Historically, one of the first operating systems to support asynchronous I / O was Windows 2000.
A typical use case was this: a single-threaded application (there were no multi-core processors then) downloads, for example, a large file for tens of seconds. Instead of freezing the interface and the “clock” that would have been observed with the synchronous call to read (), in the asynchronous version the main program flow does not “hang”, you can make a beautiful progress bar that displays the loading process, and the “cancel” button.
To implement the "progress bar", a special OVERLAPPED structure is passed to the asynchronous Windows I / O functions, in which the OS notes the current number of bytes transferred. The programmer can read the contents of this structure at any time convenient for him - in the main message processing cycle, by timer, etc. In the same structure, at the end of the operation, its final result will be recorded (total number of bytes transferred, error code if any, etc.).
In addition to this structure, you can transfer your own callback functions to asynchronous I / O functions that take a pointer to OVERLAPPED, which will be called by the operating system at the end of the operation.
A true, honest asynchronous launch of a callback function, through interrupting a program in any place wherever it is, is indistinguishable from starting a second thread of program execution on the same kernel. Accordingly, you need to either write callback functions very carefully, or apply all the “multithreaded” rules regarding blocking access to shared data, which, you see, is very strange in a single-threaded application. To avoid potential errors in single-threaded applications, Windows queues raw callsbacks, and the programmer must explicitly specify the places in his program where it can be interrupted to execute these callbacks (WaitFor * Object family of functions).
The asynchronous I / O scheme described above is “native” to the WindowsNT kernel, that is, all other operations are somehow implemented through it. Full name - IOCP (Input / Output Completion Port). It is believed that this scheme allows to achieve theoretically maximum performance from iron. Any daemons designed for serious work under Windows should be developed on the basis of IOCP. See the introduction to IOCP on MSDN for more details .
In Linux, instead of the normal OVERLAPPED structure, there is some weak similarity to aiocb, which allows determining only the fact of the operation completion, but not its current progress. Instead of user-defined callbacks, the kernel uses UNIX signals (yes, those that kill). Signals come completely asynchronously, with all the consequences, but if you don’t feel like a guru in writing reentrant functions, you can create a special type of file (signalfd) and read from it information about incoming signals with normal synchronous I / O functions, including non-blocking ones . See man aio.h for more details .
Using asynchronous I / O does not impose any restrictions on the architecture of the daemon, theoretically it can be any. But, as a rule, several workflows are used (by the number of processor cores) between which serviced connections are evenly distributed. A Finite State Machine (FSM) is built and programmed for each connection, the appearance of events (calls of callback functions and / or errors) transfers this automaton from one state to another.
Summary
As we can see, each method has its advantages, disadvantages and applications. If you need security - use processes, if speed is important under heavy load - non-blocking I / O, and if speed of development and code comprehensibility are important, then multi-threaded architecture is suitable. Asynchronous I / O is the main way in Windows. In any case, do not try to write code to work with I / O yourself. The network has free ready-made libraries for all architectures and operating systems, licked for decades almost to shine. Almost - because in your case you still have to twist, file and adjust to your conditions. The Internet is a complicated thing; there are no universal solutions for all occasions.
Be that as it may, daemons are not enough with one I / O, and much more complex “gags” happen during request processing. But this is a topic for another article, if anyone is interested.
References
1. The C10K problem (eng), thanks for the tip o_O_Tync
2. Help for the libev library , a tasty part with a description of the various mechanisms of mass input-output (eng), for the tip thanks saterenko
3. FAQ echo ru.unix.prog
4. Introduction to the libaio unix library (English)
5. Testing kernel performance from 2.6.12 to 2.6.37 .