Business cases using Data Mining. Part 1
Hi, Habr.
I am very glad that the topic of Data Mining is interesting to the community.
In this topic (and if you like it, in a series of topics) I’ll tell you what examples of using Data Mining are in Russian and not only business. Why am I writing about this? I work for a company that is closely connected with the Computing Center of the Russian Academy of Sciences (Computing Center of the Russian Academy of Sciences), which allows us to have an excellent research department and develop new projects, applying domestic achievements in mathematics. In this topic there will be more business than science, but if the latter still interests you, then you are here: mmro.ru or here: www.machinelearning.ru
So, let's go:
Today, in almost any big business, there is a huge cloud of data that has been collected and stored for many years. The main task of Data Mining is to find nontrivial dependencies in the raw data that will solve a specific business problem.
A large trading network, such as Kopeyka, Perkrestok, Pyaterochka, Auchan, has hundreds of stores throughout the Russian Federation, tens of thousands of active goods. Sales data for each product (SKU) in each particular store at each time point (day or hour) is stored in the company's accounting system.
A distribution network must order goods to their stores daily. Those. daily in the matrix, for example [5000 X 10 000] should be the value - how much to carry this product?
If the distribution network orders less than there will be real demand, it will receive LOSSES due to shortages (and lose the mark-up value), if the network will order more goods than there will be real demand, then it will LOSSES due to the cost of storing goods in the warehouse, frozen funds , damage to the goods after the expiration date. These two types of losses are called out-of-stock and over-stock, respectively.
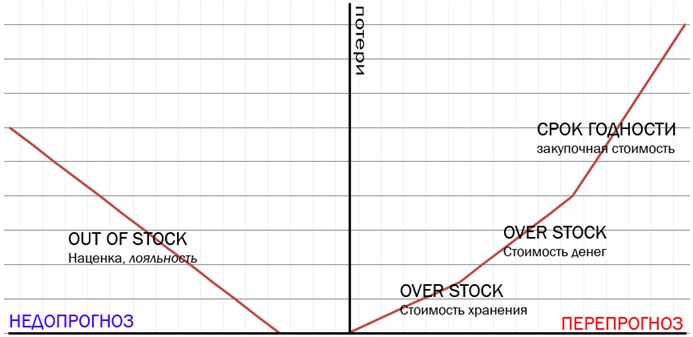
What to do? Based on the accumulated history of goods movements in each store and each product, you can learn from precedents and build a predictive model that will take into account:
1. Weekly seasonality (for example, vodka is sold starting on Thursday, energy is sold more on Fridays)
2. Annual seasonality (for example beer buy in the summer more)
3. Holidays (for example, Soviet champagne is sold 100 times more than the average on March 8, December 31, February 23)
4. Promotions (for example, a surge in sales of pescola in September is not the annual seasonality, but the effect of the promotion -action with Britney :))
In any data-mining task, it is important to correctly clear the data before working and building models. Therefore, in the case of sales, it is important to learn not from real sales, but from “restored demand”. What is it?
Suppose you sold sweets evenly during the month, but they weren’t delivered in the last week and sales were 0. This doesn’t mean that there was no demand (and there will be no demand either in the last week of the next month :)). Therefore, in this situation, it is important to restore demand in places of lack of sales.
And what if you have a new product (for which there is no history)? In this case, it is important to look at the history of the product group. For example, the appearance of “icetea lipton peach” tea can be predicted for the “cold teas” product group, while remembering to take into account the factor “how the appearance of a new product in history affected sales in the whole group”.
The same thing happens with new stores - how many products to order in the newly opened store? You need to find a “similar” store and first predict based on its history, and then gradually switch to the history of the new store.
All these are tasks of working with data in data minnig.
Daily forecasting systems in retail process gigabytes (and somewhere terabytes) of data to make a forecast and answer the question: How much of each particular product is ordered in each particular store in order to reduce financial costs and take into account (forecast) demand as much as possible.
If you have 1-2 stores and several thousand positions - a person predicts you better than any car, but when you have WallMart and hundreds of thousands of products on the shelves - no army of analysts and product experts can cope with solutions to this problem, which is why it is so close in retail chains pay attention to the automation of business processes.
FACT: improving the forecasting model can reduce the costs of the distribution network by 1-2 percent of the turnover. Now think about what kind of money it is, given the fact that the turnover of the largest Russian networks is from $ 1 billion.
I think that on this example1 about retail chains I will end. If interested - write questions, comments - I will answer. If I like it as a whole - next time I’ll tell you about telecom and how they solve the problem of “increasing customer loyalty”, given the volumes of tens and hundreds of millions of subscribers.
I am very glad that the topic of Data Mining is interesting to the community.
In this topic (and if you like it, in a series of topics) I’ll tell you what examples of using Data Mining are in Russian and not only business. Why am I writing about this? I work for a company that is closely connected with the Computing Center of the Russian Academy of Sciences (Computing Center of the Russian Academy of Sciences), which allows us to have an excellent research department and develop new projects, applying domestic achievements in mathematics. In this topic there will be more business than science, but if the latter still interests you, then you are here: mmro.ru or here: www.machinelearning.ru
So, let's go:
Today, in almost any big business, there is a huge cloud of data that has been collected and stored for many years. The main task of Data Mining is to find nontrivial dependencies in the raw data that will solve a specific business problem.
Example 1. Retail (retail chains).
A large trading network, such as Kopeyka, Perkrestok, Pyaterochka, Auchan, has hundreds of stores throughout the Russian Federation, tens of thousands of active goods. Sales data for each product (SKU) in each particular store at each time point (day or hour) is stored in the company's accounting system.
A distribution network must order goods to their stores daily. Those. daily in the matrix, for example [5000 X 10 000] should be the value - how much to carry this product?
If the distribution network orders less than there will be real demand, it will receive LOSSES due to shortages (and lose the mark-up value), if the network will order more goods than there will be real demand, then it will LOSSES due to the cost of storing goods in the warehouse, frozen funds , damage to the goods after the expiration date. These two types of losses are called out-of-stock and over-stock, respectively.
What to do? Based on the accumulated history of goods movements in each store and each product, you can learn from precedents and build a predictive model that will take into account:
1. Weekly seasonality (for example, vodka is sold starting on Thursday, energy is sold more on Fridays)
2. Annual seasonality (for example beer buy in the summer more)
3. Holidays (for example, Soviet champagne is sold 100 times more than the average on March 8, December 31, February 23)
4. Promotions (for example, a surge in sales of pescola in September is not the annual seasonality, but the effect of the promotion -action with Britney :))
In any data-mining task, it is important to correctly clear the data before working and building models. Therefore, in the case of sales, it is important to learn not from real sales, but from “restored demand”. What is it?
Suppose you sold sweets evenly during the month, but they weren’t delivered in the last week and sales were 0. This doesn’t mean that there was no demand (and there will be no demand either in the last week of the next month :)). Therefore, in this situation, it is important to restore demand in places of lack of sales.
And what if you have a new product (for which there is no history)? In this case, it is important to look at the history of the product group. For example, the appearance of “icetea lipton peach” tea can be predicted for the “cold teas” product group, while remembering to take into account the factor “how the appearance of a new product in history affected sales in the whole group”.
The same thing happens with new stores - how many products to order in the newly opened store? You need to find a “similar” store and first predict based on its history, and then gradually switch to the history of the new store.
All these are tasks of working with data in data minnig.
Daily forecasting systems in retail process gigabytes (and somewhere terabytes) of data to make a forecast and answer the question: How much of each particular product is ordered in each particular store in order to reduce financial costs and take into account (forecast) demand as much as possible.
If you have 1-2 stores and several thousand positions - a person predicts you better than any car, but when you have WallMart and hundreds of thousands of products on the shelves - no army of analysts and product experts can cope with solutions to this problem, which is why it is so close in retail chains pay attention to the automation of business processes.
FACT: improving the forecasting model can reduce the costs of the distribution network by 1-2 percent of the turnover. Now think about what kind of money it is, given the fact that the turnover of the largest Russian networks is from $ 1 billion.
I think that on this example1 about retail chains I will end. If interested - write questions, comments - I will answer. If I like it as a whole - next time I’ll tell you about telecom and how they solve the problem of “increasing customer loyalty”, given the volumes of tens and hundreds of millions of subscribers.