How cache affects multithreaded applications
The theoretical component.
It so happened, the bottleneck in many computers is the RAM - processor interface. This is due to the significant time it takes to form a request to memory and the fact that the memory frequency is lower than the processor frequency. In the general case, while the data is being received from memory, program execution is stopped. To improve the situation, a specialized high-speed memory is used - the cache.
If there is a cache, if the processor needs to access a specific byte in the RAM, then the memory area containing this byte (the size of the area depends on the processor) is selected in the cache, and then the processor reads the data from the cache. If the processor writes data to memory, then it first goes to the cache, and then to RAM.
In multi-core and multiprocessor systems, each core or processor has its own personal cache. If the data in the cache is modified by one processor, the changes must be synchronized with other processors that use the overlapping address space.
If changes occur frequently and data areas overlap, performance will decline.
I have a question how much things can be bad. In addition, it was interesting to see how the length of the data affects.
Experiment.
For verification, 2 multithreaded C ++ programs were written for two cases of intersection of workspaces:
There are 2 working threads, each, changing its words, goes through the entire array and, having reached the border, returns to the beginning and so on. Each of the threads makes 100 million changes.
UPD Thank you mikhanoid for the typo in the name of the CPU.
For testing, we used the HP xw4600 workstation, CPU Core 2 Quad (Q9300), OS Linux Slamd64 12.1, kernel 2.6.24.5, and gcc 4.2.3 compiler. The result was a 64-bit program, therefore, any arithmetic operation for words 1.4 and 8 bytes long was performed in 1 clock cycle.
The execution time was measured with the time (1) command, and averaged over 5 experiments.
At first, a program was written that simply increments the word and puts it back, but it turned out that in the case of an array on the stack, the -O2 optimization does something indecent. Therefore, a second program was written that does something more complex with the data.
Results.
UPD: Thnx for commenting on mt_ and Google Charts for api charts. The result is in graphical form.
Those who want to see the numbers can scroll further.
On the Y axis, the real time of program execution in seconds. On the X axis, the word length (in pairs).
Program 1.
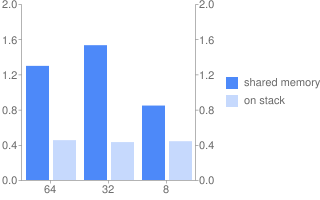
Program 2.
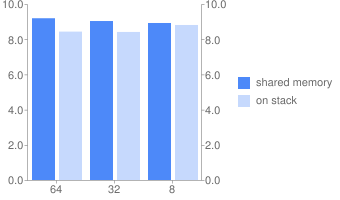
Program 2 + optimization -O2.

conclusions
We can say for sure that in the case of obviously non-overlapping areas it works faster, and significantly. Optimization somehow affects, but the trend continues.
But the dependence on the length of the word is somehow not very noticeable.
The idea of this opus is inspired by the article www.ddj.com/architect/208200273 .
UPD Trying to bring Perfect Code to my blog, it seems to me that this is the right place.
The results are in tabular form.
Results are presented in seconds.
Program 1 (shared memory).
Program 1 (stack)
Program 2 (shared memory).
Program 2 (stack)
Program 2 + optimization -O2 (shared memory).
Program 2 + optimization -O2 (stack)
Source.
Program 1. Program 2.
It so happened, the bottleneck in many computers is the RAM - processor interface. This is due to the significant time it takes to form a request to memory and the fact that the memory frequency is lower than the processor frequency. In the general case, while the data is being received from memory, program execution is stopped. To improve the situation, a specialized high-speed memory is used - the cache.
If there is a cache, if the processor needs to access a specific byte in the RAM, then the memory area containing this byte (the size of the area depends on the processor) is selected in the cache, and then the processor reads the data from the cache. If the processor writes data to memory, then it first goes to the cache, and then to RAM.
In multi-core and multiprocessor systems, each core or processor has its own personal cache. If the data in the cache is modified by one processor, the changes must be synchronized with other processors that use the overlapping address space.
If changes occur frequently and data areas overlap, performance will decline.
I have a question how much things can be bad. In addition, it was interesting to see how the length of the data affects.
Experiment.
For verification, 2 multithreaded C ++ programs were written for two cases of intersection of workspaces:
- The areas do not overlap and are on the stack of each thread;
- The workspace for threads is common, it is an array of 1, 4 and 8 byte words, with a total length of 1024 bytes, each of the threads modifies its words (for example, only even or only odd).
There are 2 working threads, each, changing its words, goes through the entire array and, having reached the border, returns to the beginning and so on. Each of the threads makes 100 million changes.
UPD Thank you mikhanoid for the typo in the name of the CPU.
For testing, we used the HP xw4600 workstation, CPU Core 2 Quad (Q9300), OS Linux Slamd64 12.1, kernel 2.6.24.5, and gcc 4.2.3 compiler. The result was a 64-bit program, therefore, any arithmetic operation for words 1.4 and 8 bytes long was performed in 1 clock cycle.
The execution time was measured with the time (1) command, and averaged over 5 experiments.
At first, a program was written that simply increments the word and puts it back, but it turned out that in the case of an array on the stack, the -O2 optimization does something indecent. Therefore, a second program was written that does something more complex with the data.
Results.
UPD: Thnx for commenting on mt_ and Google Charts for api charts. The result is in graphical form.
Those who want to see the numbers can scroll further.
On the Y axis, the real time of program execution in seconds. On the X axis, the word length (in pairs).
Program 1.
Program 2.
Program 2 + optimization -O2.
conclusions
We can say for sure that in the case of obviously non-overlapping areas it works faster, and significantly. Optimization somehow affects, but the trend continues.
But the dependence on the length of the word is somehow not very noticeable.
The idea of this opus is inspired by the article www.ddj.com/architect/208200273 .
UPD Trying to bring Perfect Code to my blog, it seems to me that this is the right place.
The results are in tabular form.
Results are presented in seconds.
Program 1 (shared memory).
| Word length | 64 | 32 | 8 |
|---|---|---|---|
| Real time | 1,297 | 1,532 | 0.846 |
| User Time regime | 2,461 | 3,049 | 1,664 |
Program 1 (stack)
| Word length | 64 | 32 | 8 |
|---|---|---|---|
| Real time | 0.453 | 0.431 | 0.441 |
| User Time regime | 0.851 | 0.842 | 0.866 |
Program 2 (shared memory).
| Word length | 64 | 32 | 8 |
|---|---|---|---|
| Real time | 9,191 | 9,033 | 8,921 |
| User Time regime | 18,365 | 18,039 | 17,824 |
Program 2 (stack)
| Word length | 64 | 32 | 8 |
|---|---|---|---|
| Real time with | 8,432 | 8,412 | 8,808 |
| User Time Mode c | 16,843 | 16,796 | 17,548 |
Program 2 + optimization -O2 (shared memory).
| Word length | 64 | 32 | 8 |
|---|---|---|---|
| Real time | 4,247 | 4,380 | 3,473 |
| User Time regime | 8,415 | 8,960 | 6,781 |
Program 2 + optimization -O2 (stack)
| Word length | 64 | 32 | 8 |
|---|---|---|---|
| Real time | 3,282 | 3,718 | 3,308 |
| User Time regime | 6,550 | 7,384 | 5,565 |
Source.
Program 1. Program 2.
#include
#include
#include
#include
#define TBYTES 1024
//
#define TOTAL 2
// определяет тип слова u_int8_t u_int32_t u_int64_t
#define MTYPE u_int8_t
//
#define MAXAR TBYTES/sizeof(MTYPE)
#define DOIT 100000000
MTYPE *array;
pthread_mutex_t mux = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
int workers = 2;
// Определяет используется ли общая память
//#define SHARED 1
void*
runner(void* args){
unsigned int which = *(unsigned int*)args; delete (unsigned int*)args;
unsigned int index = which;
MTYPE array1[MAXAR];
//
for ( unsigned int i = 0; i < DOIT; ++i){
if ( index >= MAXAR)
index = which;
//
#if defined(SHARED)
array[index] = array[index] + 1;
#else
array1[index] = array1[index] + 1;
#endif
//
index += TOTAL;
}
//
pthread_mutex_lock(&mux);
-- workers;
pthread_mutex_unlock(&mux);
pthread_cond_broadcast(&cond);
//
return 0;
};
int
main() {
//
array = (MTYPE*)calloc(MAXAR, sizeof(MTYPE));
//
unsigned int *which;
pthread_t t1;
pthread_attr_t attr;
//
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
//
which = new unsigned int(0);
pthread_create(&t1, &attr, runner, (void*)which);
//
which = new unsigned int(1);
pthread_create(&t1, &attr, runner, (void*)which);
//
pthread_mutex_lock(&mux);
while(!pthread_cond_wait(&cond, &mux)){
if ( !workers)
break;
};
pthread_mutex_unlock(&mux);
//
return 0;
};
//
* This source code was highlighted with Source Code Highlighter.
#include
#include
#include
#include
#define TBYTES 1024
//
#define TOTAL 2
// определяет тип слова u_int8_t u_int32_t u_int64_t
#define MTYPE u_int64_t
//
#define MAXAR TBYTES/sizeof(MTYPE)
//#define DOIT 100000000 * (sizeof(u_int64_t) / sizeof(MTYPE))
#define DOIT 100000000
MTYPE *array;
pthread_mutex_t mux = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
int workers = 2;
template
RTYPE scramble(u_int16_t *seed, RTYPE a){
int d;
//
for ( d = 0; d < 8; ++d){
u_int16_t mask;
//
mask = (*seed & 0x1) ^ ( (*seed >> 1) &0x1);
mask = mask & 0x1;
*seed = (mask << 15) | (*seed >> 1);
//
a = a ^ ((RTYPE)mask << d);
}
//
return a;
};
// Определяет используется ли общая память
//#define SHARED 1
void*
runner(void* args){
unsigned int which = *(unsigned int*)args; delete (unsigned int*)args;
unsigned int index = which;
u_int16_t seed = 0x4a80;
MTYPE array1[MAXAR];
//
for ( unsigned int i = 0; i < DOIT; ++i){
MTYPE data;
if ( index >= MAXAR)
index = which;
//
#if defined(SHARED)
data = array[index];
array[index] = scramble(&seed, data);
#else
data = array1[index];
array1[index] = scramble(&seed, data);
#endif
//
index += TOTAL;
}
//
pthread_mutex_lock(&mux);
-- workers;
pthread_mutex_unlock(&mux);
pthread_cond_broadcast(&cond);
//
return 0;
};
int
main() {
//
array = (MTYPE*)calloc(MAXAR, sizeof(MTYPE));
//
unsigned int *which;
pthread_t t1;
pthread_attr_t attr;
//
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
//
which = new unsigned int(0);
pthread_create(&t1, &attr, runner, (void*)which);
//
which = new unsigned int(1);
pthread_create(&t1, &attr, runner, (void*)which);
//
pthread_mutex_lock(&mux);
while(!pthread_cond_wait(&cond, &mux)){
if ( !workers)
break;
};
pthread_mutex_unlock(&mux);
//
return 0;
};
//
* This source code was highlighted with Source Code Highlighter.