Evolution of the approach to code deployment in Reddit
- Transfer

We, in the Wirex payment blockchain service team , are familiar with the need for constant refinement and improvement of the existing technological solution. The author of the material below tells the story of the evolution of the code deployment of the well-known social news platform Reddit.
"It is important to follow the direction of its development in order to be able to direct it to the useful direction in time."
The Reddit team is constantly deploying code. All members of the development team regularly write the code, which is checked by the author himself, is being tested by, in order to go to the "production". Every week we do at least 200 “deploevs”, each of which usually takes a total of less than 10 minutes.
The system that provides all of this has evolved over the years. Let's see what has changed in it for all this time, and what remains unchanged.
Beginning of history: stable and repetitive deployments (2007-2010)
All the system we have today has grown from a single seed - a Perl script called push. It was written long ago, in very different times for Reddit. Our entire technical team was then so small that it quietly fit into one small “negotiation” . We did not use AWS then. The site worked on a finite number of servers, and any additional capacity needed to be added manually. Everything worked on a single large, monolithic Python application called r2.
{kind=link}
One thing over all these years has remained unchanged. Requests were classified in the load balancer and distributed into “pools” containing more or less identical application servers. For example, the pages of lists of topics and comments are processed by different server pools. In fact, any r2 process can handle all types of requests, but splitting into pools allows you to protect each of them against sudden spikes in traffic in neighboring pools. Thus, in the case of traffic growth, failure threatens not the entire system, but its individual pools.
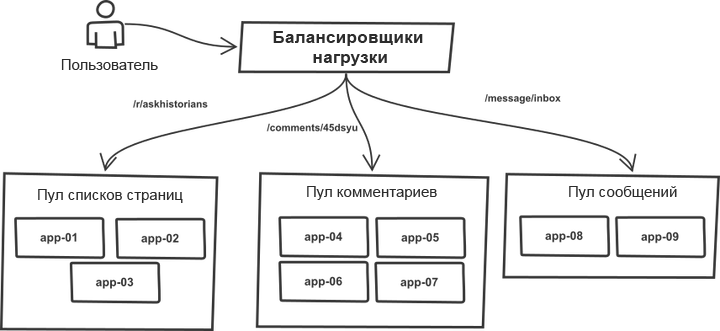
The list of target servers was registered manually in the push tool code, and the deployment process worked with a monolithic system. The tool ran through the server list, logged in via SSH, ran one of the predefined sequences of commands that updated the current copy of the code using git, and restarted all application processes. The essence of the process (the code is greatly simplified for a common understanding):
# создаем статические файлы и помещаем их на выделенные под статику серверы
`make -C /home/reddit/reddit static`
`rsync /home/reddit/reddit/staticpublic:/var/www/`
# проходим по всем app-серверам и обновляем на них текущие копии кода# как только все готово, перезагружаем ихforeach $h (@hostlist) {
`git push $h:/home/reddit/reddit master`
`ssh $h make -C /home/reddit/reddit`
`ssh $h /bin/restart-reddit.sh`
}Deployment took place sequentially, one server after another. For all its simplicity, the scheme had an important plus: it is very similar to the “ canary deploy ”. Having deployed code on several servers and noticing errors, you immediately understood that there were bugs, you could interrupt (Ctrl-C) the process and roll back before problems arise with all requests at once. Ease of deployment made it easy and without serious consequences to check things in production and roll back if they did not work. In addition, it was convenient to determine which kind of deployment caused the errors, where exactly and what should be rolled back.
Such a mechanism coped well with ensuring stability and control during deployment. The tool worked pretty fast. Things were going right.
In our regiment arrived (2011)
Then we hired more people, there were now six developers, and our new “negotiation” has become more spacious . We began to realize that the code deployment process now needed more coordination, especially when colleagues were working from home. The push utility has been updated: now it announced the start and end of the deployments using an IRC chat bot, which simply sat in the IRC and announced events. Performed during the Deploy process, there have been almost no changes, but now the system did everything for the developer and told everyone else about the modifications made.
From this point on, the use of chat in the deployment workflow began. At that time, talk about managing deployment from chat rooms was quite popular, however, since we used third-party IRC servers, we could not trust the chat to the utmost in production management environment, and therefore the process remained at the level of one-way information flow.
As the traffic on the site grows, so does the infrastructure supporting it. From time to time we now and then had to launch a new group of application servers and put them into operation. The process was still not automated. In particular, the list of hosts on push still needed to be updated manually.
Power pools are usually increased by adding to them several servers at a time. As a result, push running through the list consistently managed to roll changes to a whole group of servers in the same pool, without affecting the others, that is, there was no diversification across pools.

To manage the process, a worker used uWSGItherefore, when we gave the application a reboot command, it would kill all existing processes at once, replacing them with new ones. New processes took some time to prepare for the processing of requests. In the case of an unintended restart of a group of servers in one pool, the combination of these two circumstances seriously affected the ability of that pool to service requests. So we came up against the speed limit for the safe deployment of code on all servers. With the increase in the number of servers, the duration of the entire procedure has grown.
Recycling Deploy Tool (2012)
We have thoroughly reworked the deployment tool. And although its name, despite the complete rework, remained the same (push), this time it was written in Python. The new version had some major improvements.
First of all, he picked up the list of hosts from the DNS, and not from the sequence that was fixed in the code. This allowed updating only the list, without the need to update the push code. Appeared the beginnings of a service discovery system.
To solve the problem of successive restarts, we jumbled the list of hosts before deployments. Shuffling reduced risks and allowed speeding up the process.

The initial version mixed the list randomly each time, but this complicated the quick rollback, because each time the list of the first group of servers was different. Therefore, we corrected the mixing: it now generated a certain order that could be used during the re-deployment after a rollback.
Another small but important change was the constant deployment of some fixed version of the code. The previous version of the tool has always updated the master branch on the target host, but what happens if the master changes directly during deployment because someone mistakenly launches the code? Deploying some given git revision instead of referring to a branch name, made it possible to make sure that the same version of code was used on each production server.
And finally, the new tool distinguished its code (it worked mainly with the list of hosts and visited them via SSH) and the commands executed on the servers. It was still very dependent on the needs of r2, but it had something like an API prototype. This allowed r2 to follow its own deployment steps, which made it easier to roll out the changes and free the stream. The following is an example of commands executed on a separate server. The code, again, is not an exact code, but in general this sequence describes the workflow r2 well:
sudo /opt/reddit/deploy.py fetch reddit
sudo /opt/reddit/deploy.py deploy reddit f3bbbd66a6
sudo /opt/reddit/deploy.py fetch-names
sudo /opt/reddit/deploy.py restartallOf particular note is fetch-names: this instruction is unique to r2.
Autoscaling (2013)
Then we decided, finally, to switch to the cloud with automatic scaling (a topic for a whole separate post). This allowed us to save a whole bunch of money in those moments when the site was not loaded with traffic and to automatically increase capacity to cope with any sharp increase in requests.
Previous enhancements that automatically loaded DNS hosts list made this transition a matter of course. The list of hosts changed more often than before, but from the point of view of the deployment tool, this did not play any role. The change, which was originally introduced as a qualitative improvement, has become one of the key components required to run autoscaling.
However, autoscaling has led to some interesting borderline cases. There is a need to control the launches. What happens if the server starts right during deployment? We had to make sure that every new server that was running checked for the presence of a new code and took it, if there was one. We could not forget about the servers that go offline at the time of deployment. The tool needed to become smarter and learn to determine that the server went offline during the procedure, and not as a result of the error that occurred during the deployment. In the latter case, he should have loudly warned all colleagues involved in the problem.
At the same time, as if by the way, and for various reasons, we switched from uWSGI to Gunicorn. However, from the point of view of the topic of this post, such a transition did not lead to any significant changes.
So it worked for a while.
Too many servers (2014)
Over time, the number of servers required to service peak traffic grew. This led to the fact that deployments required more and more time. In the worst case scenario, one normal deployment took about an hour - a bad result.
We rewrote the tool so that it could support parallel work with hosts. The new version is called rollingpin . The old version took a lot of time to initialize ssh connections and wait for the completion of all commands, so paralleling within reasonable limits allowed speeding up the deployment. Deployment time again dropped to five minutes.

To reduce the impact of simultaneously rebooting multiple servers, the mixing component of the tool has become smarter. Instead of blindly shuffling the list, he sorted the server pools so that the hosts from one pool were as far from each other as possible .
The most important change in the new tool was that the API between the deployment tool and the tools on each of the servers were defined much clearer and separated from the needs of r2. Initially, this was done from the desire to make the code more open-source-oriented, but soon this approach turned out to be very useful in another respect. Next, an example of deployment with the allocation of remotely running API commands:

Too many people (2015)
Suddenly a moment came when, on r2, as it turned out, a lot of people were already working. It was great, and at the same time it meant that there were even more deployed. Complying with the rule of one deployment at a time became harder and harder. Developers had to agree with each other on how to release the code. To optimize the situation, we added another element to the chat bot, coordinating the deployment queue. The engineers requested a deployment reserve and either received it or their code “got up” in the queue. This helped streamline deployments, and those who wanted to complete them could quietly wait for their turn.
Another important addition as the team grew was tracking deployments in one place.. We changed the deployment tool to send metrics to Graphite. This made it easy to trace the correlation between deployments and changes in metrics.
Many (two) services (also 2015)
The moment of the release of the second online service also came suddenly. It was a mobile version of the website with its completely different stack, its own servers and the build process. This was the first real test of the shared API of the deployment tool. Adding the ability to work out all the assembly steps in different “locations” for each project allowed him to withstand the load and cope with the maintenance of two services within the same system.
25 services (2016)
Over the next year, we have witnessed a rapid expansion of the team. Instead of two services, two dozen appeared, instead of two development teams, fifteen. Most of the services were collected either on Baseplate , our backend framework, or on client applications by analogy with the mobile web. The infrastructure behind all the deposits is one for all. Soon, many other new services will be online, and all this is largely due to the versatility of rollingpin. It allows you to simplify the launch of new services with the help of tools familiar to people.
Airbag (2017)
As the number of servers in the monolith increased, deployment time grew. We wanted to significantly increase the number of parallel deployments, but this would have caused too many simultaneous reloads of application servers. Such things naturally lead to a drop in bandwidth and the loss of the ability to service incoming requests due to the overload of the remaining servers.
The main Gunicorn process used the same model as uWSGI, reloading all workers at the same time. New worker processes were unable to service requests until fully loaded. The launch time of our monolith ranged from 10 to 30 seconds. This meant that during this period of time we would not be able to process requests at all. To find a way out of this situation, we replaced the main gunicorn process with the Einhorn Workers Manager from Stripe, while retaining the Gunicorn HTTP stack and the WSGI container.. During the reboot, Einhorn creates a new worker, waits until he is ready, disposes of one old worker and repeats the process until the update is complete. This creates a safety cushion and allows us to keep bandwidth at a level during the deployment.
The new model has created another problem. As mentioned earlier, replacing the worker with a new and fully finished took up to 30 seconds. This meant that if there was a bug in the code, it didn’t pop up immediately and managed to turn around on a variety of servers before it was detected. To prevent this, we introduced a mechanism to block the transition of the deployment procedure to the new server, which was in effect until all the processes of the workers were restarted. It was implemented simply by surveying the state of einhorn and waiting for the readiness of all new workers. To keep the speed at the same level, we expanded the number of servers being processed in parallel, which was quite safe in the new conditions.
This mechanism allows us to carry out simultaneous deployment on a much larger number of machines, and the deployment time covering approximately 800 servers is reduced to 7 minutes, taking into account additional pauses to check for bugs.
Looking back
The deployment infrastructure described here is a product born as a result of many years of consistent improvements, rather than a one-time purposeful effort. The echoes of the decisions made once and the compromises reached at the early stages still make themselves felt in the current system, and this has always been the case at all stages. Such an evolutionary approach has its pros and cons: it requires a minimum of effort at any stage, but there is a risk, sooner or later, to come to a standstill. It is important to follow the direction of its development in order to be able to direct it to the useful course in time.
Future
Reddit infrastructure should be ready for the constant support of the team as it grows and new things are launched. The growth rate of the company is greater than ever, and we are working on even more interesting and large-scale projects than anything we have done before. The problems we face today are of a dual nature: on the one hand, it is the need to increase developer autonomy, on the other hand, to maintain the security of the production infrastructure and to improve the airbag that allows developers to quickly and confidently implement deployments.
