About expanding strings in .Net / C # and not only
Let's talk about strings, or rather about turning them over with .Net / C #. It just so happened that in the standard library the corresponding function is not observed. And as they tell me, writing a line-reversal function is a fairly popular question at job interviews. Let's see how you can effectively flip a line using this platform.
Under the cut is a comparative analysis of the performance of different methods of line reversal.
Khrr-rr ... - said the chainsaw.
Tyuyuyu ... - said the men.
© Old joke.
Well, let's get started. All implementations were tested for performance with a single line of 256 megabytes (128 × 1024 × 1024 characters) and 1024 × 1024 lines of 256 bytes (128 characters) in size. Before each measurement, garbage collection was accelerated (which is important with such a size of test data), the measurement was carried out 50 times, 20 extreme ones were discarded, the remaining values were averaged. Conditional parrots selected the number of ticks issued by an object of the Stopwatch class.
The test was conducted on two computers: Athlon64 x2 4200+, 2GB Dual-Channel DDR2 RAM and Pentium4 HT 3GHz, 3GB DDR RAM. The main difference between the configurations in this test is the speed of the memory-cache link - the second system is noticeably slower in this regard.
The technical formalities are over, now let's move on to the actual implementations. For clarity, unicode surrogate code points are not taken into account here . We will consider the approaches in the order of logic and “prettiness” of implementation in the context of the surrounding “ecosystem”.
Comparative measurements are in the last part of this note. In general, the ReverseUnsafeCopy function turned out to be optimal , if only safe code - ReverseArrayManual was limited . If you need safe code and huge lines, you will have to suffer with ReverseStringBuilder .
We will follow the recommendations and to build a "large" string we take a special tool - the StringBuilder class. The idea is simple to the point of horror: we create the builder of the right size and go along the line in the reverse order, adding characters to a new line.
We try, we launch, yes ... It all somehow somehow works slowly, we will dig further.
Ha! So this builder is equipped with checks to ensure thread safety from all sides, no, we don’t need this. But a string is an array of characters. So let's turn it over and convert the result back to a string:
Quite another matter, it turned out 3.5 times faster. Hmm, maybe even better?
So, we think. First, our data is copied twice: first from a string to an array, then inside the array. Secondly, Array.Reverse is a library method, which means it has input checks. Moreover, for atomic types it is explicitly implemented as a native method, and this is an additional switching of the execution context. Let's try to turn the string into an array manually:
Move on. In our case, the actions are symmetrical with respect to the middle of the line, which means that you can put two indexes in the opposite direction and halve the number of iterations:
Hmm ... Something went wrong, on a system with slow memory, the speed dropped one and a half times. Given the specifics of the configurations and implementations, we can assume that the memory speed and the processor cache are to blame: we used to work with two remote memory areas at the same time, now there are four of them, respectively, data capture is performed more often.
There is still a relatively beautiful and short way with LINQ, but it does not withstand any criticism in terms of performance - it works 3-3.5 times slower than the method based on StringBuilder. The reason for this is pumping data through IEnumerable and a virtual call for each iteration. For those who wish, the following is the implementation:
The problem is not so critical in most cases, but all the "fast" of the methods considered make an intermediate copy of the string in the form of an array of characters. On synthetic tests, this is manifested in the fact that only the first method was able to wrap a 512MB string, the rest fell on System.OutOfMemoryException. Also, we should not forget that unnecessary temporary objects increase the frequency of the GC, and although it is optimized to the point of horror, it eats up time anyway. In the next part, in addition to speed optimizations, we will also look for a solution to this problem.
Using unsafe code gives us one interesting advantage: lines that used to be immutable can now be changed, but you need to be extremely careful and only change copies of lines - the library minimizes the number of copies of one line, and together with interning lines this can lead to sad consequences for applications.
So, having created a new row of the right size, we can look at it as an array and fill it with the necessary data. Well, do not forget about the absence of checks on the validity of indexes, which will also speed up the code. However, due to the specifics of strings in .Net, we cannot just create a string of the desired length. You can either make a string from a repeating character (for example, space) using the String (char, int) constructor, or copy the original string using String.Copy (String).
Armed with this knowledge, we write the following two implementations.
Make a line of spaces and fill it in the reverse order:
Copy and flip the line:
As measurements showed, the second version works noticeably faster on slow memory and slightly slower on fast :) There are several reasons: operating with two remote memory areas instead of four and the difference in the speed of copying a memory block and its simple filling in a loop. Those who wish can try to make the ReverseUnsafeFill version with a full pass (this can reduce the number of data captures from memory to the cache) and test it on slow memory, however, I have reason to believe that it will still be slower than ReverseUnsafeCopy (although I could be wrong).
What's next? Rumor has it that exchanging with the XOR operator works faster than copying through a third variable (by the way, in the pros it also looks pretty nice: “a ^ = b ^ = a ^ = b;”, in C #, alas, this line will not work) . Well, let's check in practice.
As a result, it turns out 1.2-1.5 times slower than copying. The trick that worked for the quick exchange of values on registers did not work for variables (which is typical, in many C / C ++ compilers it also doesn’t work).
In search of an explanation of this fact, we climb inside the application and read the resulting CIL code.
For an answer to this question, it is worth looking at the CIL code generated for the two exchange methods. To make these instructions easier to understand, I ’ll explain their purpose: ldloc .N - loads the local variable number N on the stack , stloc .N - reads the top of the stack into local variable number N , xor - calculates the value of the XOR operation for two values at the top of the stack and loads the result onto the stack instead.
As you can easily see, the version with the XOR operator requires more virtual machine operations. Moreover, during subsequent compilation into native code, it is likely that there will be an optimization that will replace a typical exchange through a third variable with a more efficient exchange operation, taking into account the capabilities of the processor used. As a side effect of the analysis, we get a hypothetical “ideal” exchange for CIL, it would be interesting to check if its use will have any effect, but for this you need to mess with ilasm or reflection / emit, maybe I can still get together. However, the resulting code will be even less applicable than unsafe c #, therefore it is not of practical interest.
Well, while we look at the insides of assemblies with a reflector, it makes sense to look at the implementation of the library methods used in the first part. Array.Reverse stands out here, which relies on a certain function Array.TrySZReverse, implemented as a native method. So, download Shared Source Common Language Infrastructure 2.0 - the source .net 2.0 and see what kind of beast it is :) After a short search, in the file “sscli20 \ clr \ src \ vm \ comarrayhelpers.h” there is a Reverse template function (in this KIND case will correspond to UINT16), which (surprise!) is horribly similar to the ReverseUnsafeCopy implementation.
The analysis of the measurement results is presented in the first two parts, but only comparative diagrams showing the performance ratio of the above functions are shown here. The exact numbers in "ticks" are too configuration-dependent and are hardly of particular interest, everyone can measure their own performance using the provided pieces of code.
On fast memory On slow memory
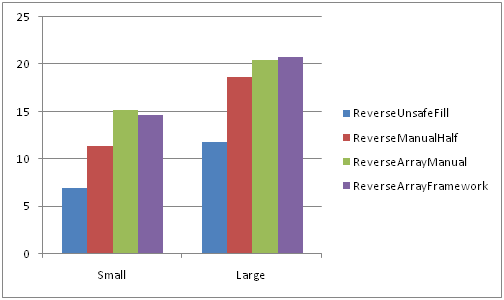

Big lines Short lines

Big lines Short lines

Under the cut is a comparative analysis of the performance of different methods of line reversal.
Khrr-rr ... - said the chainsaw.
Tyuyuyu ... - said the men.
© Old joke.
Well, let's get started. All implementations were tested for performance with a single line of 256 megabytes (128 × 1024 × 1024 characters) and 1024 × 1024 lines of 256 bytes (128 characters) in size. Before each measurement, garbage collection was accelerated (which is important with such a size of test data), the measurement was carried out 50 times, 20 extreme ones were discarded, the remaining values were averaged. Conditional parrots selected the number of ticks issued by an object of the Stopwatch class.
The test was conducted on two computers: Athlon64 x2 4200+, 2GB Dual-Channel DDR2 RAM and Pentium4 HT 3GHz, 3GB DDR RAM. The main difference between the configurations in this test is the speed of the memory-cache link - the second system is noticeably slower in this regard.
The technical formalities are over, now let's move on to the actual implementations. For clarity, unicode surrogate code points are not taken into account here . We will consider the approaches in the order of logic and “prettiness” of implementation in the context of the surrounding “ecosystem”.
Comparative measurements are in the last part of this note. In general, the ReverseUnsafeCopy function turned out to be optimal , if only safe code - ReverseArrayManual was limited . If you need safe code and huge lines, you will have to suffer with ReverseStringBuilder .
Part one: “normal” methods.
1. ReverseStringBuilder
We will follow the recommendations and to build a "large" string we take a special tool - the StringBuilder class. The idea is simple to the point of horror: we create the builder of the right size and go along the line in the reverse order, adding characters to a new line.
Copy Source | Copy HTML- static string ReverseStringBuilder(string str)
- {
- StringBuilder sb = new StringBuilder(str.Length);
- for (int i = str.Length; i-- != 0; )
- sb.Append(str[i]);
- return sb.ToString();
- }
We try, we launch, yes ... It all somehow somehow works slowly, we will dig further.
2. ReverseArrayFramework
Ha! So this builder is equipped with checks to ensure thread safety from all sides, no, we don’t need this. But a string is an array of characters. So let's turn it over and convert the result back to a string:
Copy Source | Copy HTML- static string ReverseArrayFramework(string str)
- {
- char[] arr = str.ToCharArray();
- Array.Reverse(arr);
- return new String(arr);
- }
Quite another matter, it turned out 3.5 times faster. Hmm, maybe even better?
3. ReverseArrayManual
So, we think. First, our data is copied twice: first from a string to an array, then inside the array. Secondly, Array.Reverse is a library method, which means it has input checks. Moreover, for atomic types it is explicitly implemented as a native method, and this is an additional switching of the execution context. Let's try to turn the string into an array manually:
Copy Source | Copy HTML- static string ReverseArrayManual(string originalString)
- {
- char[] reversedCharArray = new char[originalString.Length];
- for (int i = originalString.Length - 1; i > -1; i--)
- reversedCharArray[originalString.Length - i - 1] = originalString[i];
- return new string(reversedCharArray);
- }
4. ReverseManualHalf
Move on. In our case, the actions are symmetrical with respect to the middle of the line, which means that you can put two indexes in the opposite direction and halve the number of iterations:
Copy Source | Copy HTML- static string ReverseManualHalf(string originalString)
- {
- char[] reversedCharArray = new char[originalString.Length];
- int i = 0;
- int j = originalString.Length - 1;
- while (i <= j)
- {
- reversedCharArray[i] = originalString[j];
- reversedCharArray[j] = originalString[i];
- i++; j--;
- }
- return new string(reversedCharArray);
- }
Hmm ... Something went wrong, on a system with slow memory, the speed dropped one and a half times. Given the specifics of the configurations and implementations, we can assume that the memory speed and the processor cache are to blame: we used to work with two remote memory areas at the same time, now there are four of them, respectively, data capture is performed more often.
LINQ and Reverse Method
There is still a relatively beautiful and short way with LINQ, but it does not withstand any criticism in terms of performance - it works 3-3.5 times slower than the method based on StringBuilder. The reason for this is pumping data through IEnumerable and a virtual call for each iteration. For those who wish, the following is the implementation:
Copy Source | Copy HTML- static string ReverseStringLinq(string originalString)
- {
- return new string(originalString.Reverse().ToArray());
- }
Memory usage
The problem is not so critical in most cases, but all the "fast" of the methods considered make an intermediate copy of the string in the form of an array of characters. On synthetic tests, this is manifested in the fact that only the first method was able to wrap a 512MB string, the rest fell on System.OutOfMemoryException. Also, we should not forget that unnecessary temporary objects increase the frequency of the GC, and although it is optimized to the point of horror, it eats up time anyway. In the next part, in addition to speed optimizations, we will also look for a solution to this problem.
Part two: when you want faster and more efficiently, or unsafe code.
Using unsafe code gives us one interesting advantage: lines that used to be immutable can now be changed, but you need to be extremely careful and only change copies of lines - the library minimizes the number of copies of one line, and together with interning lines this can lead to sad consequences for applications.
So, having created a new row of the right size, we can look at it as an array and fill it with the necessary data. Well, do not forget about the absence of checks on the validity of indexes, which will also speed up the code. However, due to the specifics of strings in .Net, we cannot just create a string of the desired length. You can either make a string from a repeating character (for example, space) using the String (char, int) constructor, or copy the original string using String.Copy (String).
Armed with this knowledge, we write the following two implementations.
5. ReverseUnsafeFill
Make a line of spaces and fill it in the reverse order:
Copy Source | Copy HTML- static unsafe string ReverseUnsafeFill(string str)
- {
- if (str.Length <= 1) return str;
- String copy = new String(' ', str.Length);
- fixed (char* buf_copy = copy)
- {
- fixed (char* buf = str)
- {
- int i = 0;
- int j = str.Length - 1;
- while (i <= j)
- {
- buf_copy[i] = buf[j];
- buf_copy[j] = buf[i];
- i++; j--;
- }
- }
- }
- return copy;
- }
6. ReverseUnsafeCopy
Copy and flip the line:
Copy Source | Copy HTML- static unsafe string ReverseUnsafeCopy(string str)
- {
- if (str.Length <= 1) return str;
- char tmp;
- String copy = String.Copy(str);
- fixed (char* buf = copy)
- {
- char* p = buf;
- char* q = buf + str.Length - 1;
- while (p < q)
- {
- tmp = *p;
- *p = *q;
- *q = tmp;
- p++; q--;
- }
- }
- return copy;
- }
As measurements showed, the second version works noticeably faster on slow memory and slightly slower on fast :) There are several reasons: operating with two remote memory areas instead of four and the difference in the speed of copying a memory block and its simple filling in a loop. Those who wish can try to make the ReverseUnsafeFill version with a full pass (this can reduce the number of data captures from memory to the cache) and test it on slow memory, however, I have reason to believe that it will still be slower than ReverseUnsafeCopy (although I could be wrong).
7. ReverseUnsafeXorCopy
What's next? Rumor has it that exchanging with the XOR operator works faster than copying through a third variable (by the way, in the pros it also looks pretty nice: “a ^ = b ^ = a ^ = b;”, in C #, alas, this line will not work) . Well, let's check in practice.
Copy Source | Copy HTML- static unsafe string ReverseUnsafeXorCopy(string str)
- {
- if (str.Length <= 1) return str;
- String copy = String.Copy(str);
- fixed (char* buf = copy)
- {
- char* p = buf;
- char* q = buf + str.Length - 1;
- while (p < q)
- {
- *p ^= *q;
- *q ^= *p;
- *p ^= *q;
- p++; q--;
- }
- }
- return copy;
- }
As a result, it turns out 1.2-1.5 times slower than copying. The trick that worked for the quick exchange of values on registers did not work for variables (which is typical, in many C / C ++ compilers it also doesn’t work).
In search of an explanation of this fact, we climb inside the application and read the resulting CIL code.
Part Three: We climb into CIL and .Net library codes.
Why exchange through XOR turned out to be worse
For an answer to this question, it is worth looking at the CIL code generated for the two exchange methods. To make these instructions easier to understand, I ’ll explain their purpose: ldloc .N - loads the local variable number N on the stack , stloc .N - reads the top of the stack into local variable number N , xor - calculates the value of the XOR operation for two values at the top of the stack and loads the result onto the stack instead.
| Copy sharing | XOR-based Exchange | Perfect CIL exchange |
|---|---|---|
| | |
.locals init ( | .locals init ( | .locals init ( |
L_0004: ldloc.0 | L_0004: ldloc.0 | L_0004: ldloc.0 |
As you can easily see, the version with the XOR operator requires more virtual machine operations. Moreover, during subsequent compilation into native code, it is likely that there will be an optimization that will replace a typical exchange through a third variable with a more efficient exchange operation, taking into account the capabilities of the processor used. As a side effect of the analysis, we get a hypothetical “ideal” exchange for CIL, it would be interesting to check if its use will have any effect, but for this you need to mess with ilasm or reflection / emit, maybe I can still get together. However, the resulting code will be even less applicable than unsafe c #, therefore it is not of practical interest.
How does Array.Reverse work?
Well, while we look at the insides of assemblies with a reflector, it makes sense to look at the implementation of the library methods used in the first part. Array.Reverse stands out here, which relies on a certain function Array.TrySZReverse, implemented as a native method. So, download Shared Source Common Language Infrastructure 2.0 - the source .net 2.0 and see what kind of beast it is :) After a short search, in the file “sscli20 \ clr \ src \ vm \ comarrayhelpers.h” there is a Reverse template function (in this KIND case will correspond to UINT16), which (surprise!) is horribly similar to the ReverseUnsafeCopy implementation.
Copy Source | Copy HTML- static void Reverse(KIND array[], UNIT32 index, UNIT32 count) {
- LEAF_CONTRACT;
-
- _ASSERTE(array != NULL);
- if (count == 0) {
- return;
- }
- UNIT32 i = index;
- UNIT32 j = index + count - 1;
- while(i < j) {
- KIND temp = array[i];
- array[i] = array[j];
- array[j] = temp;
- i++;
- j--;
- }
- }
Part Four: The Results of the Binary Marathon.
The analysis of the measurement results is presented in the first two parts, but only comparative diagrams showing the performance ratio of the above functions are shown here. The exact numbers in "ticks" are too configuration-dependent and are hardly of particular interest, everyone can measure their own performance using the provided pieces of code.
Comparison of best practices from the first two parts
On fast memory On slow memory
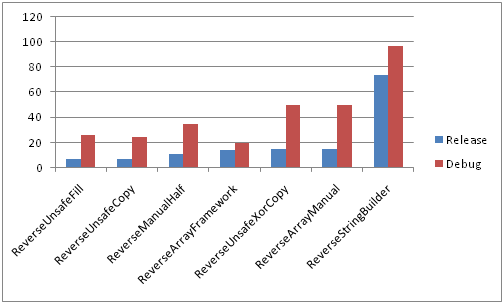
Comparison of all methods in Debug and Release configurations in fast memory
Big lines Short lines
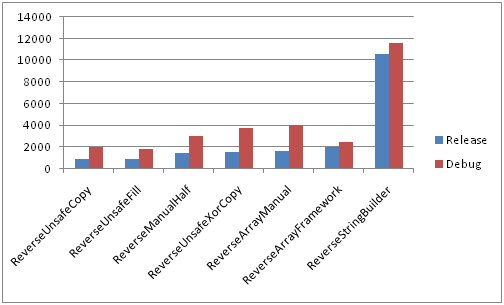
Comparison of all methods in Debug and Release configurations on slow memory
Big lines Short lines