Why we use GraphQL in 8base

Hello friends!
This article will first of all be interesting to front-end developers, especially those who are interested in GraphQL, but at the same time I hope that it will be useful for back-end developers and will help them understand the benefits of GraphQL through the front-fender.
A few words about myself: I am a VP of Technology company 8base. We develop tools that enable front-end and mobile developers to quickly build high-quality business applications.
We provide a platform in which it is sufficient to define a data model through our UI and get a ready-made GraphQL API for interacting with data. The user gets a customized server with roles, access rights, the ability to work with files, deploy serve functions, CI and much more. We also have an SDK and ready-made component libraries for React to speed development. We write backend on Node.js
And since the main users of our system are front-end and mobile developers, we decided to make a bet on GraphQL, which initially seemed to us more flexible than REST, and giving more options on the front. Well, now that we have received enough feedback from end users, we can say that in our case, it fits perfectly.
Why is GraphQL?
Unlike REST, each API in GraphQL provides a schema, which contains information about input and output data types, their fields, and relationships between types. This allows you to use a data model with links in the API, as well as make flexible queries (queries) and changes in data (mutations) that are independent of the presentation in a particular client application.
In addition, the GraphQL API allows client developers to explicitly define the returned data, including referring to related objects in each request, to avoid over-and under-fetching and reduce the number of API requests.
Compare GraphQL and REST
Let's compare GraphQL and REST with a simple example — creating an online blog. When displaying a separate article in a blog, we need to show the content of the article, the avatar and the name of the author, the list of comments, as well as the avatar and name of each commentator.
If you use REST, we will need the following API requests:
GET /articles/:id — получить содержание статьи;
GET /users/:id — получить URL аватара и имя автора;
GET /articles/:id/comments — получить список комментариев (а если бэкенд-разработчики не встроили в него имена и аватары комментаторов, придется выполнить еще и шаг 4);
GET /users/:id для каждого комментария — получить URL аватара и имя комментатора.
Pay attention to the problem of under-fetching (when a single request does not return all that is needed) and over-fetching (when, for example, the query / users /: id returns more data than will be displayed), as well as to a more complex code in the frontend Required to organize a series of API requests.
In GraphQL, all information can be obtained in one request, provided that the API developers have specified the relationships between articles, users, and comments in the GraphQL API schema. In addition, the response from the API will contain only the requested fields, which will reduce its volume.
Here is an example of a GraphQL query that will return all the information in one query to us at once:
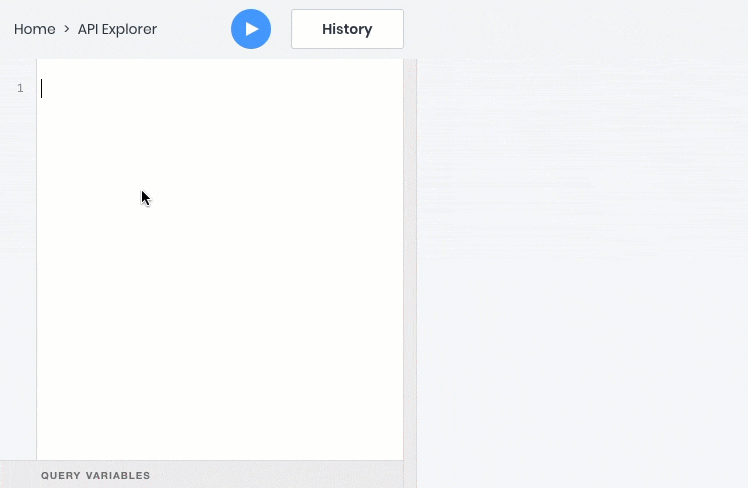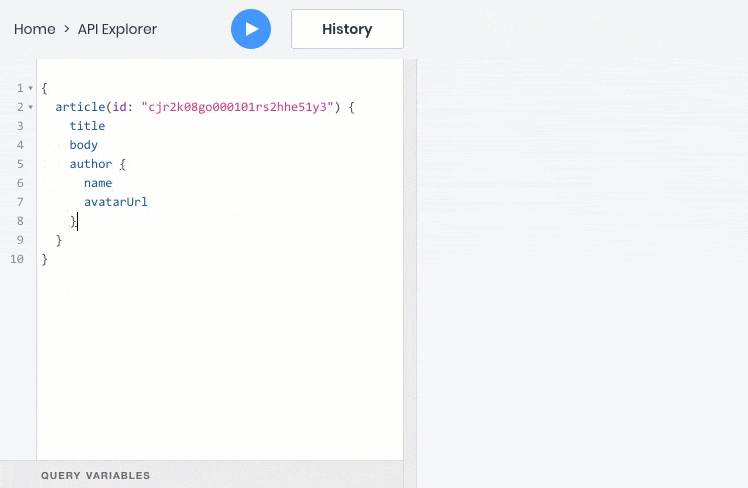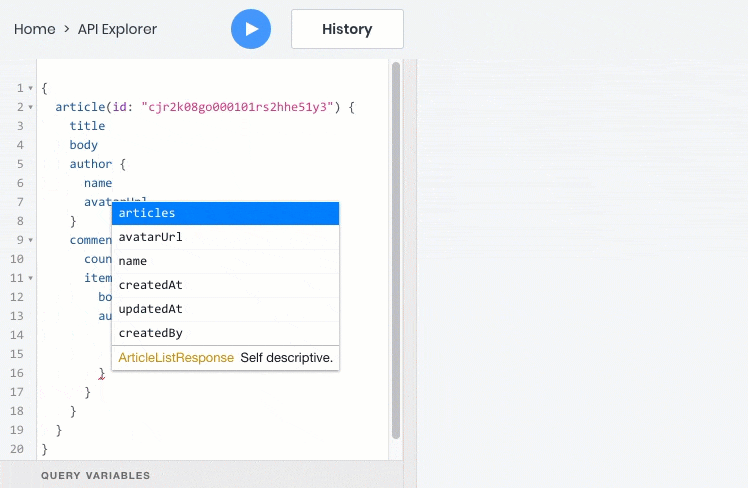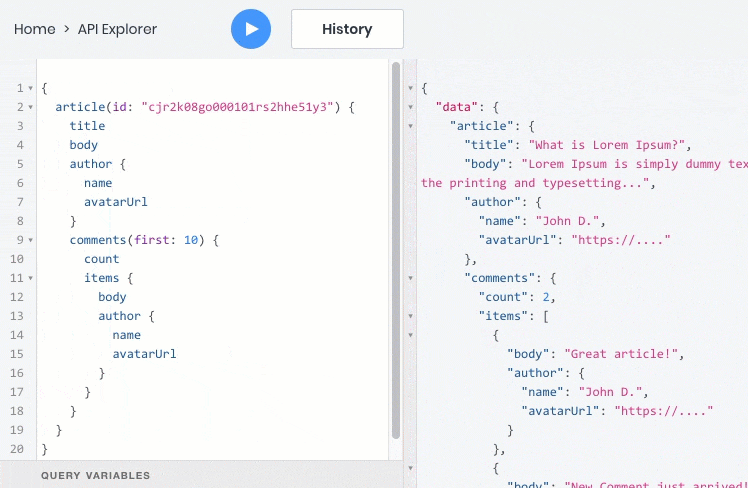
To implement this feature in REST, backend developers would need to create a special endpoint API that returns this information. However, the same thing would have to be done for each such case with the display of data from related tables, and at the same time to update the API, as soon as the frontend requires additional fields.
This example shows how GraphQL aligns the “balance of power” in favor of front-end developers, allowing them to request any necessary data, and gives backend developers the opportunity to implement the API to cover the entire subject area, rather than a specific presentation on the client.
All this combined with a set of libraries and tools brings the quality and usability of the front-end developer to a new level - that is why the popularity of GraphQL among development teams is growing all over the world.
How it looks in practice
One of the drawbacks of GraphQL is a more complex implementation than that of REST. To present the data in a convenient form for a variety of client applications, a large amount of work is needed on the back end. Implementing CRUD operations, relationships, filters, sorting, and pagination for each data type is quite tedious. Organizing such important features as data access rights and attaching files to data objects is also not so easy.
Now I’ll show you the possibilities using GraphQL using the example of our implementation:
- get one object by id or any unique field
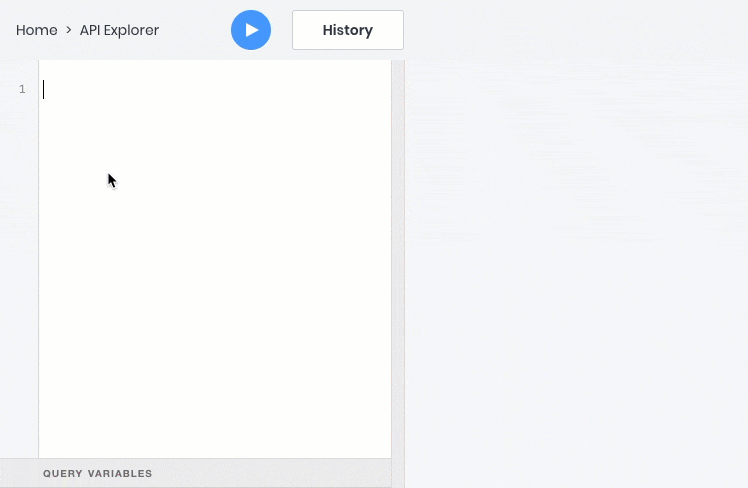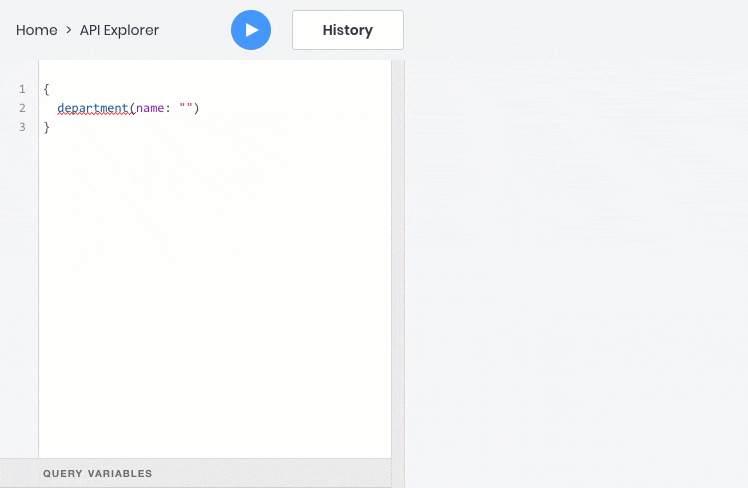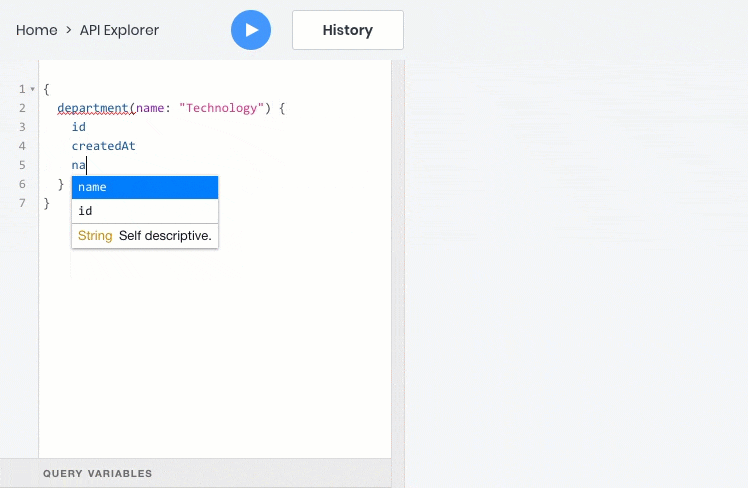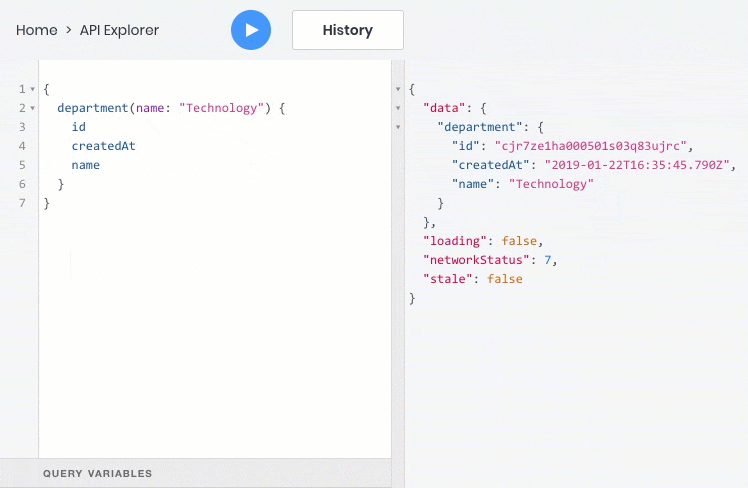
- get a list of objects based on filters, sorting, pagination and full-text search criteria

- create, update or delete an object

- subscribe to data events in real time via a web socket
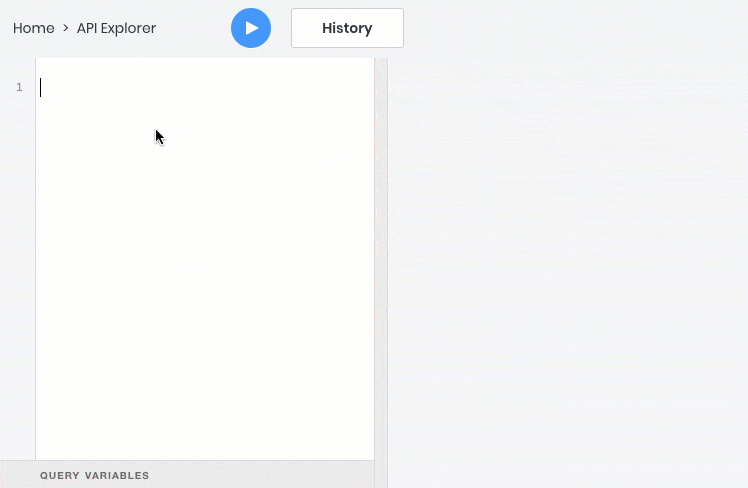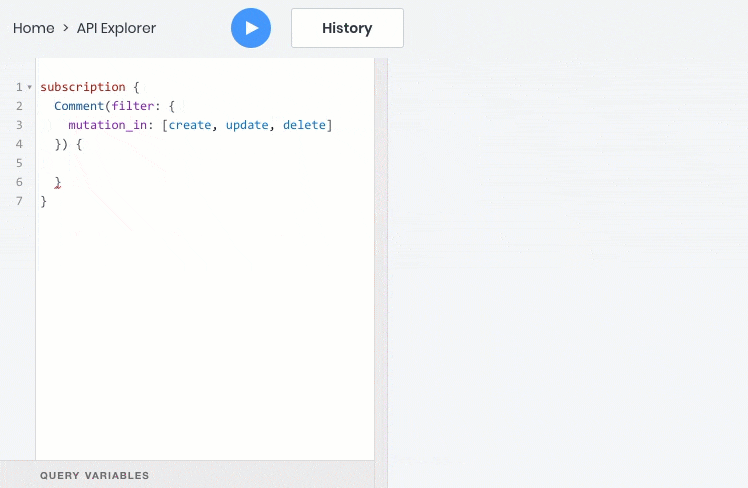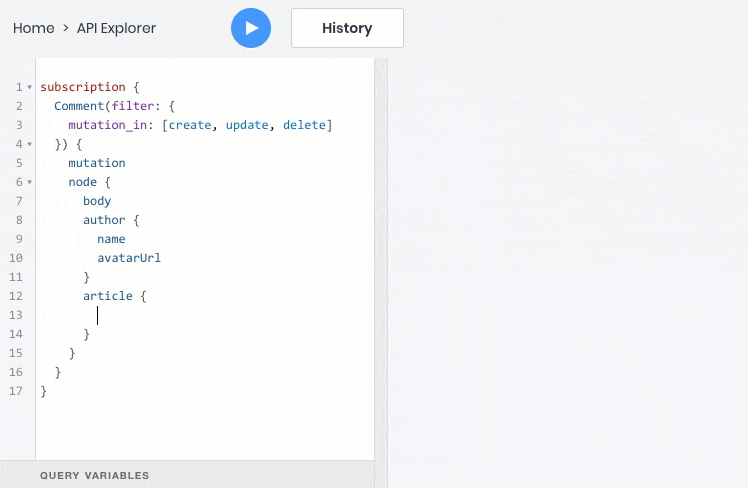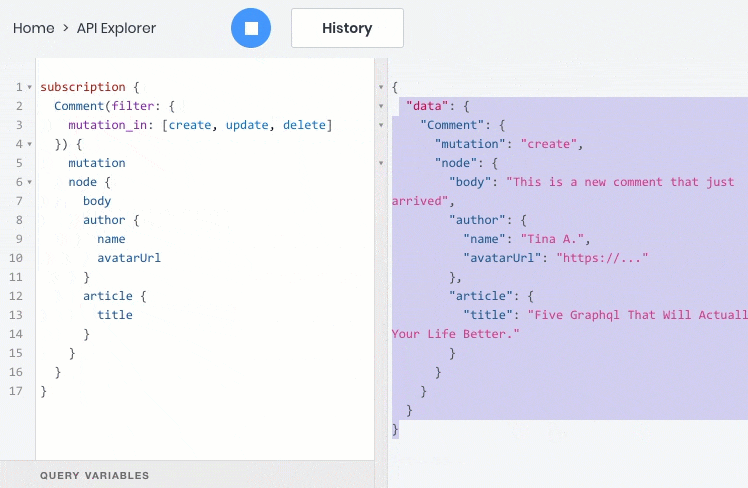
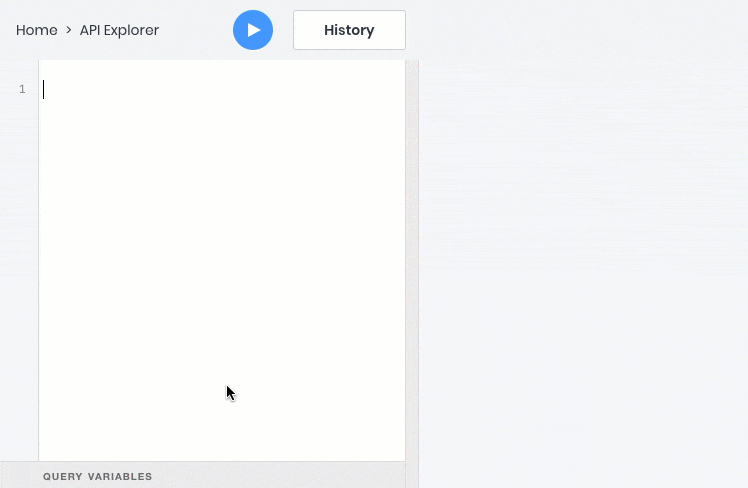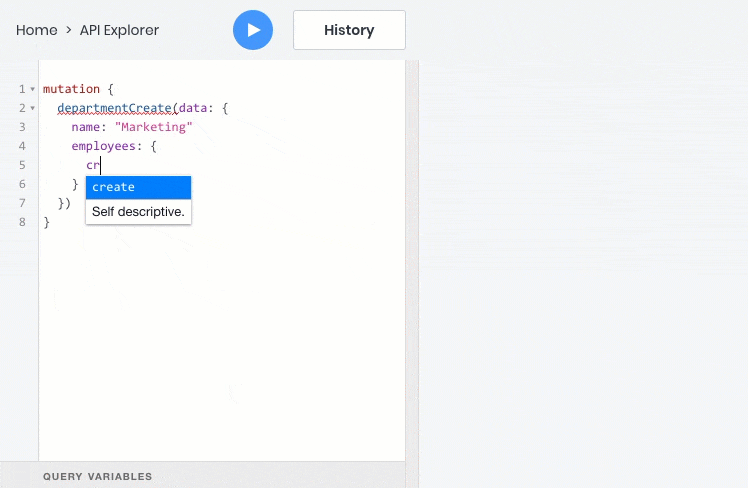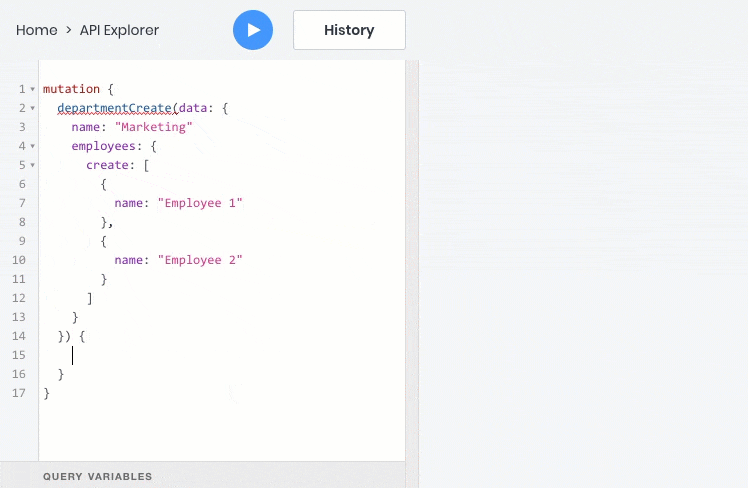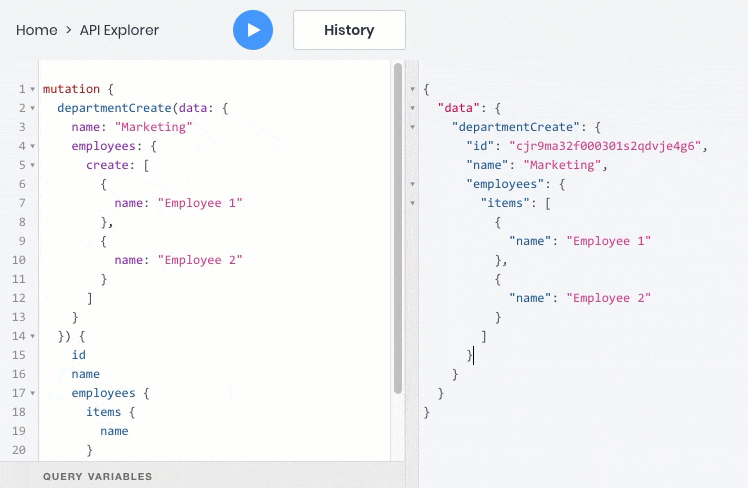
- All these operations work fine with relationships between objects, so you can query, create, and update child objects with the parent:
Summary
Thanks for attention! I would very much like to hear your opinion about GraphQL or about the experience of its use, its problems, and I will also be happy to answer questions.
Also, friends, maybe you would be interested to read a series of technical articles on our stack, or maybe something else?
PS A little more detail about the advantages of GraphQL for front-end developers and how we use GraphQL, can be seen in the video from the speech of our backend developer Andrei Gorin