AI generates realistic sounds on the video
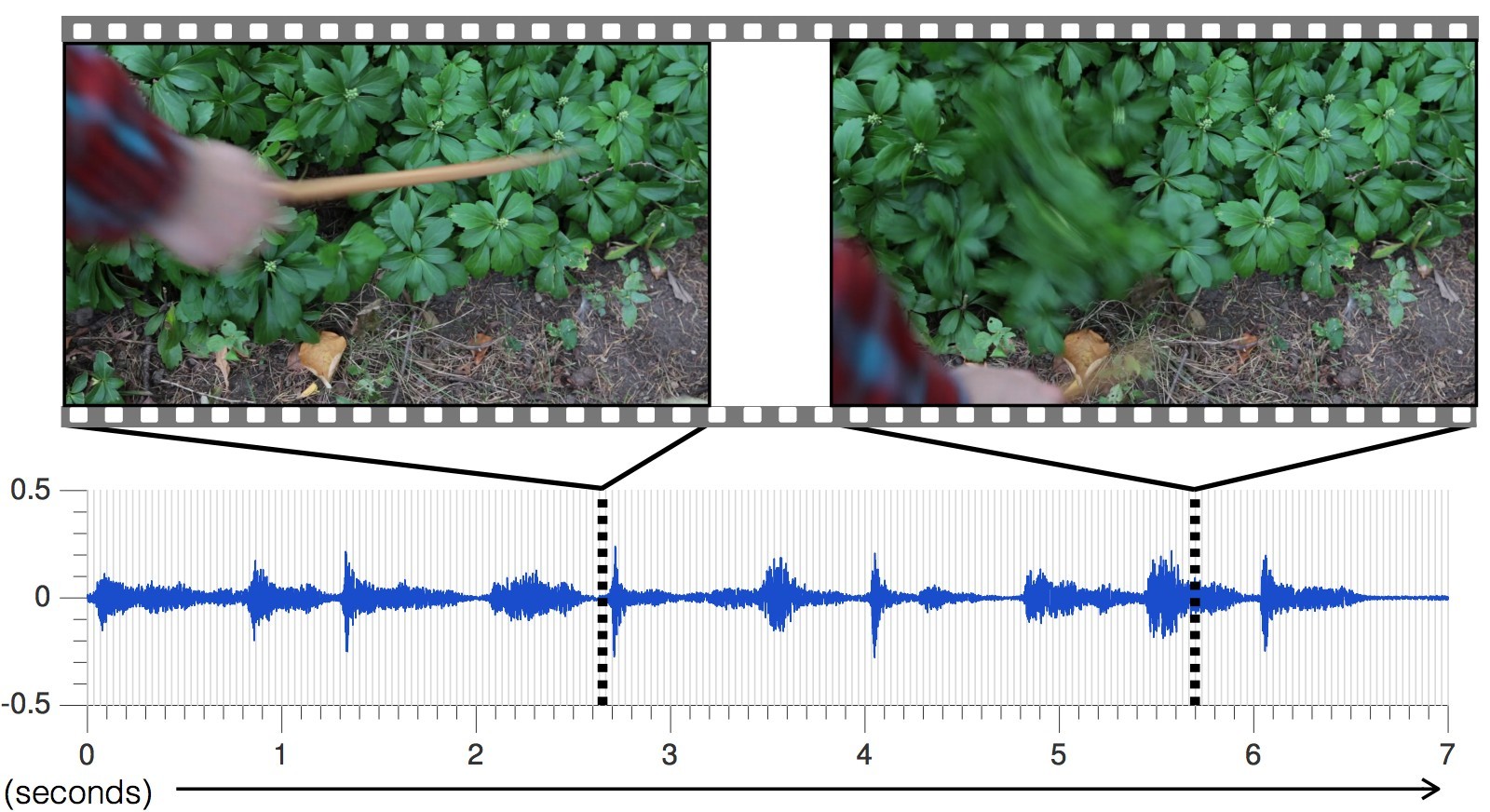
Employees of the Laboratory of Informatics and Artificial Intelligence (CSAIL) at the Massachusetts Institute of Technology and the Google Research division have designed a neural network that has learned to voice an arbitrary video series , generating realistic sounds and predicting the properties of objects. The program analyzes video, recognizes objects, their movement and the type of contact - impact, sliding, friction, and so on. Based on this information, it generates a sound that a person in 40% of cases considers more realistic than the real one.
Scientists assume that this development will find wide application in cinema and on television to generate sound effects in a video sequence without sound. In addition, it can be useful for learning robots to better understand the properties of the surrounding world.
The surrounding sounds say a lot about the properties of the surrounding objects, so in the process of self-study, future robots can act like children - touch objects, try them by touch, poke them with a stick, try to move, lift. In this case, the robot receives feedback, recognizing the properties of the object - its weight, elasticity, and so on.
The sound made by the object in contact also carries important information about the properties of the object. “When you run your finger over a glass of wine, the sound that is produced corresponds to the amount of liquid poured into the glass,” explains graduate student Andrew Owens , the lead author of a published scientific work that is not yet ready for a scientific journal, but only publishedin open access on the site arXiv.org. The presentation of the scientific work will take place at the annual conference on machine vision and image recognition (CVPR) in Las Vegas this month.
Scientists have picked up 977 videos in which people perform actions with surrounding objects consisting of various materials: they scratch, beat them with a stick, etc. In total, the videos contained 46,577 actions. CSAIL students manually marked all actions, specifying the type of material, the place of contact, the type of action (impact / scratching / other) and the type of reaction of the material or object (deformation, static shape, hard movement, etc.). Videos with sound were used to train the neural network, and manually placed tags - only for analyzing the learning outcome of the neural network, but not for teaching it.

The neural network analyzed the characteristics of sound that corresponds to each type of interaction with objects — loudness, pitch, and other characteristics. During the training, the system studied the video frame by frame, analyzed the sound in this frame and found the match with the most similar sound in the already accumulated database. The most important thing was to teach the neural network to stretch the sound into frames.
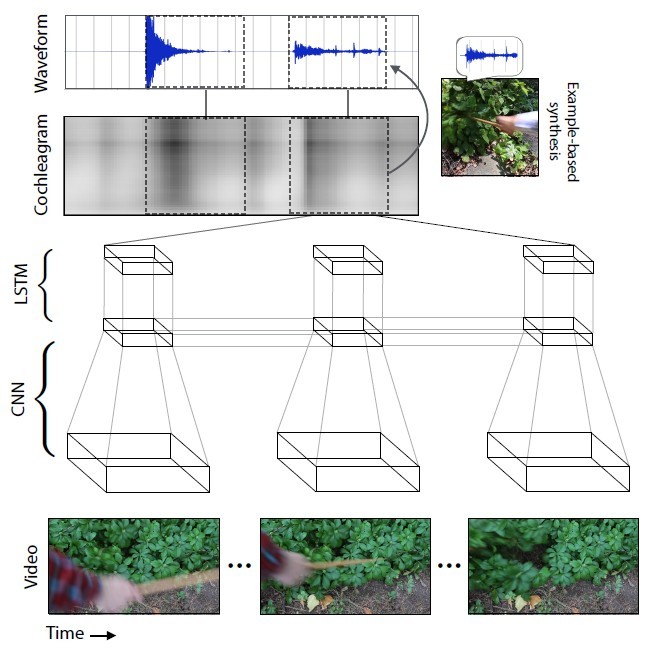
With each new video, the sound prediction accuracy increased.
The sound generated by the neural network for different scenes compared to the present.

As a result, the neural network learned to accurately predict the most diverse sounds with all the nuances: from knocking stones to rustling ivy.
“The current approaches of artificial intelligence researchers focus on only one of the five senses: machine vision specialists study visual images, speech recognition specialists study sound, and so on,” says Abhinav Gupta, an associate professor at the Carnegie University Robotics Department, Mellon. “The current research is a step in the right direction, which simulates the learning process in the same way that people do, that is, integrating sound and vision.”
To test the effectiveness of AI, scientists conducted an online study on Amazon Mechanical Turk, whose participants were asked to compare two options for the sound of a particular video and determine which sound is real and which is not.
As a result of the experiment, AI managed to deceive people in 40% of cases . However, according to some commentators on the forums , it is not so difficult to deceive a person, because a modern person gets much of the knowledge about the sound picture of the world from feature films and computer games. The sound range for movies and games is made up of specialists, using collections of standard samples. That is, we constantly hear about the same thing.
In an online experiment in two cases out of five, people thought that the program-generated sound was more realistic than the real sound from the video. This is a higher result than other methods of synthesizing realistic sounds.

Most often, the AI was misleading the participants in the experiment with the sounds of materials such as leaves and dirt, because these sounds are more complex and not so “pure” as emitting, for example, wood or metal.
Returning to the neural network training, as a side effect of the study, it was found that the algorithm can distinguish between soft and hard materials with an accuracy of 67%, simply predicting their sound. In other words, the robot can look at the asphalt path and grass in front of it - and conclude that the asphalt is hard and the grass is soft. The robot will know this from the predicted sound, even without stepping on the asphalt and grass. Then he can go wherever he wants - and check his feelings, checking with the database and, if necessary, making corrections in the library of sound samples. In this way, in the future, robots will study and explore the world around them.
However, researchers still have a lot of work to improve technology. The neural network is now often mistaken with the rapid movement of objects, not getting into the exact moment of contact. In addition, AI can only generate sound based on direct contact recorded on video, and there are so many sounds around us that are not based on visual contact: the noise of trees, the hum of a fan in a computer. “What would be really great is to somehow simulate a sound that is not so closely related to the video sequence,” says Andrew Owens.