Modeling experience from Computer Vision Mail.ru team

My name is Eduard Tyantov, I lead the Computer Vision team at Mail.ru Group. Over the several years of existence, our team has solved dozens of computer vision problems, and today I will tell you about the methods we use to successfully create machine learning models that work on a wide range of tasks. I will share tricks that can accelerate the model at all stages: setting a task, preparing data, training and deployment in production.
Computer Vision at Mail.ru
To begin with, what is Computer Vision in Mail.ru, and what projects we do. We provide solutions in our products, such as Mail, Mail.ru Cloud (an application for storing photos and videos), Vision (B2B solutions based on computer vision) and others. I will give a few examples.
The Cloud (this is our first and main client) holds 60 billion photos. We develop various features based on machine learning for their smart processing, for example, face recognition and sightseeing ( there is a separate post about this ). All user photos are run through recognition models, which allows you to organize a search and grouping by people, tags, visited cities and countries, and so on.
For Mail, we did OCR - recognition of text from a picture. Today I’ll tell you a little more about him.
For B2B products, we do recognition and counting people in queues. For example, there is a queue for the ski lift, and you need to calculate how many people are in it. To begin with, in order to test the technology and play, we deployed a prototype in the dining room in the office. There are several cash desks and, accordingly, several queues, and we, using several cameras (one for each of the queues), using the model, we calculate how many people are in the queues and how many approximately minutes are left in each of them. This way we can better balance the lines in the dining room.

Formulation of the problem
Let's start with the critical part of any task - its formulation. Almost any ML-development takes at least a month (this is at best when you know what to do), and in most cases several months. If the task is incorrect or inaccurate, then there is a great chance at the end of the work to hear from the product manager something in the spirit: “Everything is wrong. This is not good. I wanted something else. ” To prevent this from happening, you need to take some steps. What is special about ML based products? Unlike the task of developing a site, the task of machine learning cannot be formalized with text alone. Moreover, as a rule, it seems to an unprepared person that everything is already obvious, and it is simply required to do everything “beautifully”. And what small details are there, the task manager may not even know, he never thought about them and will not think about them,
Problems
Let’s understand by example what problems can be. Suppose you have a face recognition task. You receive it, rejoice and call your mother: “Hooray, an interesting task!” But is it possible to directly break down and start doing? If you do this, then at the end you may expect surprises:
- There are different nationalities. For example, there were no Asians or anyone else in the dataset. Your model, accordingly, does not know how to recognize them at all, and the product needs it. Or vice versa, you spent an extra three months on revision, and the product will only have Caucasians, and this was not necessary.
- There are children. For childless fathers like me, all children are on one face. I am absolutely in agreement with the model, when she sends all the children to one cluster - it’s really unclear how the majority of children differ! ;) But people who have children have a completely different opinion. Usually they are also your leaders. Or there are still funny recognition errors when the child’s head is successfully compared with the elbow or the head of a bald man (true story).
- What to do with painted characters is generally unclear. Do I need to recognize them or not?
Such aspects of the task are very important to identify at the beginning. Therefore, you need to work and communicate with the manager from the very beginning “on the data”. Oral explanations cannot be accepted. It is necessary to look at the data. It is desirable from the same distribution on which the model will work.
Ideally, in the process of this discussion, some test dataset will be obtained on which you can finally run the model and check whether it works as the manager wanted. It is advisable to give part of the test dataset to the manager himself, so that you do not have any access to it. Because you can easily retrain on this test set, you are an ML developer!
Setting a task in ML is a constant work between a product manager and a specialist in ML. Even if at first you set the task well, then as the model develops, more and more new problems will appear, new features that you will learn about your data. All this needs to be constantly discussed with the manager. Good managers always broadcast to their ML teams that they need to take responsibility and help the manager to set tasks.
Why is that? Machine learning is a fairly new area. Managers do not have (or have little) experience managing such tasks. How often do people learn to solve new problems? On the mistakes. If you do not want your favorite project to become a mistake, then you need to get involved and take responsibility, teach the product manager to set the task correctly, develop checklists and policies; all this helps a lot. Each time I pull myself off (or someone from my colleagues pulls me) when a new interesting task arrives, and we run to do it. Everything that I have just told you, I myself forget. Therefore, it is important to have some kind of checklist to check yourself.
Data
Data is super important in ML. For deep learning, the more data you feed models, the better. The blue graph shows that usually deep learning models improve greatly when data is added.

And the “old” (classical) algorithms from some point can no longer improve.
Usually in ML datasets are dirty. They were marked by people who always lie (s). Assessors are often inattentive and make a lot of mistakes. We use this technique: we take the data that we have, train the model on them, and then with the help of this model we clear the data and repeat the cycle again.
Let's take a closer look at the example of the same face recognition. Let's say we downloaded VKontakte user avatars. For example, we have a user profile with 4 avatars. We detect faces that are on all 4 images and run through the face recognition model. So we get embeddings of persons, with the help of which they can “glue” similar persons into groups (cluster). Next, we select the largest cluster, assuming that the user's avatars mainly contain his face. Accordingly, we can clean out all other faces (which are noise) in this way. After that, we can repeat the cycle again: on the cleaned data, train the model and use it to clean the data. You can repeat several times.
Almost always for such clustering we use CLink algorithms. This is a hierarchical clustering algorithm in which it is very convenient to set a threshold value for “gluing” similar objects (this is exactly what is required for cleaning). CLink generates spherical clusters. This is important, as we often learn the metric space of these embeds. The algorithm has a complexity of O (n 2 ), which, in principle, is approx.
Sometimes data is so hard to get or mark up that there is nothing left to do as soon as you start generating it. The generative approach allows you to produce a huge amount of data. But for this you need to program something. The simplest example is OCR, text recognition on images. The markup of the text for this task is wildly expensive and noisy: you need to highlight each line and each word, sign the text and so on. Assessors (markup people) will take up a hundred pages of text for an extremely long time, and much more is needed for training. Obviously, you can somehow generate the text and somehow “move” it so that the model learns from it.
Мы вывели для себя, что самый лучший и удобный инструментарий для этой задачи — это комбинация из PIL, OpenCV и Numpy. В них есть все для работы с текстом. Можно каким угодно образом усложнить изображение с текстом, чтобы сеть не переобучалась на простые примеры.

Иногда нам нужны какие-то объекты реального мира. Например, товары на полках магазинов. Одна их этих картинок автоматически сгенерирована. Как вы думаете, левая или правая?

На самом деле, обе сгенерированы. Если не присматриваться к мелким деталям, то отличия от реальности не заметить. Делаем мы это с помощью Blender (аналог 3dmax).
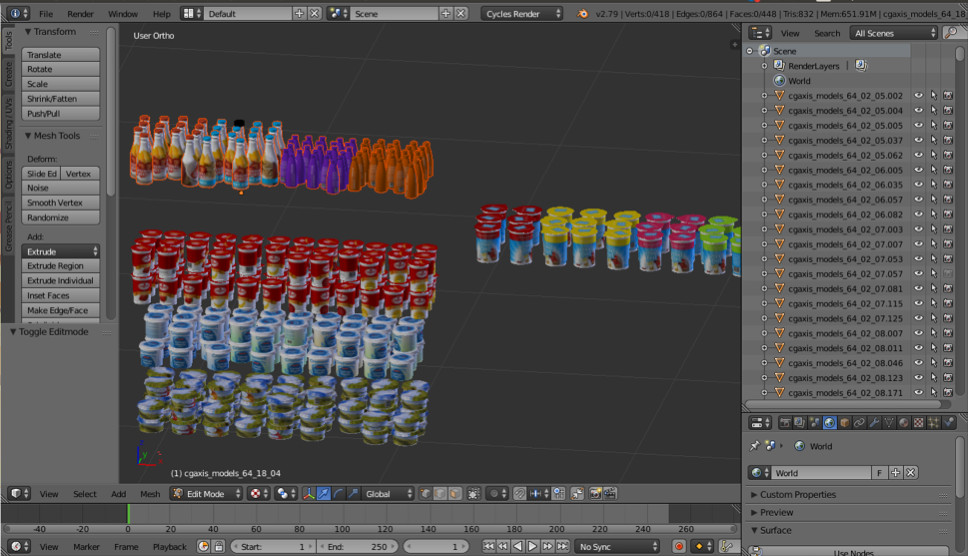
The main important advantage is that it is open source. It has an excellent Python API, which allows you to directly place objects in the code, configure and randomize the process and finally get a diverse dataset.
For rendering, ray tracing is used. This is a rather costly procedure, but it produces a result with excellent quality. The most important question: where to get models for objects? As a rule, they must be bought. But if you are a poor student and want to experiment with something, there are always torrents. It is clear that for production you need to purchase or order rendered models from someone.
That's all about the data. Let's move on to learning.
Metric learning
The goal of Metric learning is to train the network so that it translates similar objects into similar regions in the embedding metric space. I will again give an example with the sights, which is unusual in that in essence it is a classification task, but for tens of thousands of classes. It would seem, why here metric learning, which, as a rule, is appropriate in tasks such as face recognition? Let's try to figure it out.
If you use standard losses when training a classification problem, for example, Softmax, then the classes in the metric space are well separated, but in the embedding space, the points of different classes can be close to each other ...

This creates potential errors during generalization, as a slight difference in the source data may change the classification result. We would really like the points to be more compact. For this, various metric learning techniques are used. For example, Center loss, the idea of which is extremely simple: we simply pull together points to the learning center of each class, which eventually become more compact.
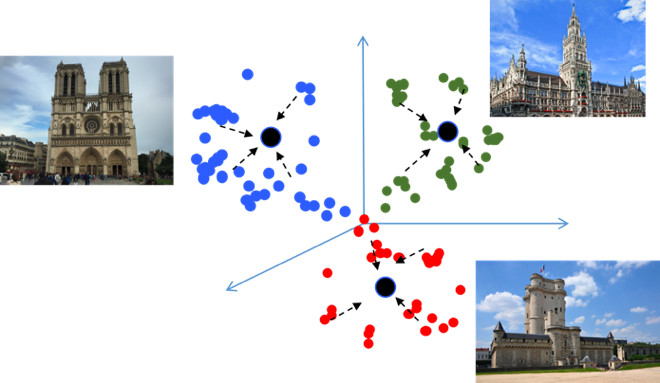
Center loss is programmed literally in 10 lines in Python, it works very quickly, and most importantly, it improves the quality of classification, because compactness leads to better generalizing ability.
Angular softmax
We tried many different metric learning methods and came to the conclusion that Angular Softmax produces the best results. Among the research community, he is also considered state of the art.
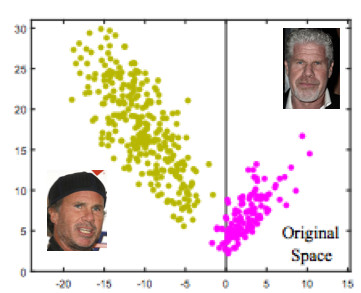
Let's look at an example of face recognition. Here we have two people. If you use the standard Softmax, then a dividing plane will be drawn between them - based on two weight vectors. If we make embedding norm 1, then the points will lie on the circle, i.e. on the sphere in the n-dimensional case (picture on the right).

Then you can see that the angle between them is already responsible for the separation of classes, and it can be optimized. But just that is not enough. If we just go on to optimize the angle, then the task will not change in fact, because we simply reformulated it in other terms. Our goal, I recall, is to make clusters more compact.
It is necessary in some way to demand a larger angle between the classes - to complicate the task of the neural network. For example, in such a way that she thinks that the angle between the points of one class is larger than in reality, so that she tries to compress them more and more. This is achieved by introducing the parameter m, which controls the difference in the cosines of the angles.
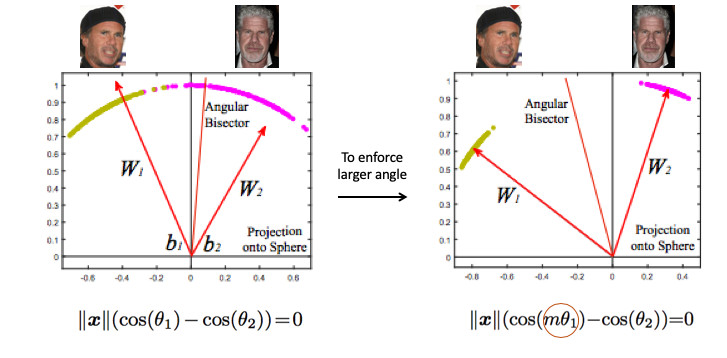
There are several options for Angular Softmax. They all play with the fact that multiply by m this angle or add, or multiply and add. State-of-the-art - ArcFace.
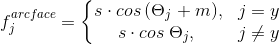
In fact, this one is quite easy to integrate into the pipeline classification.
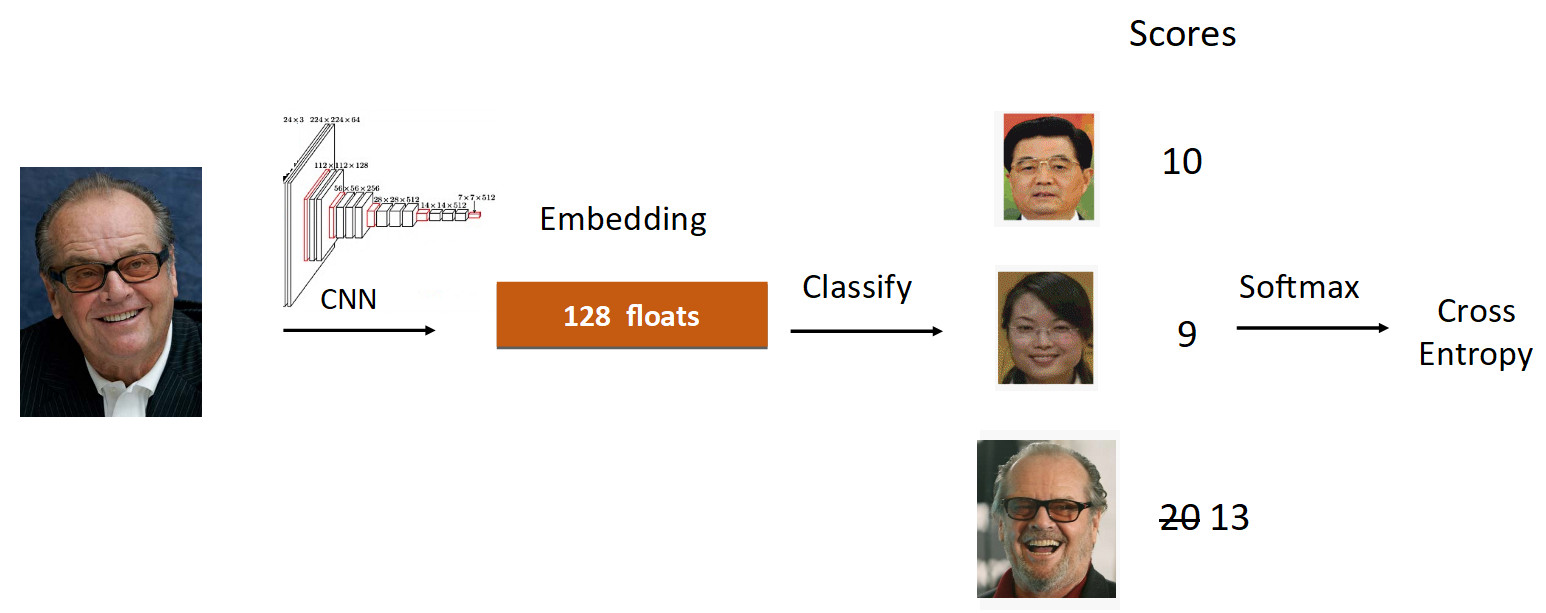
Let's look at the example of Jack Nicholson. We run his photo through the grid in the learning process. We get embedding, we run through the linear layer for classification and we get scores at the output, which reflect the degree of belonging to the class. In this case, Nicholson’s photograph has a speed of 20, the largest. Further, according to the formula from ArcFace, we reduce the speed from 20 to 13 (done only for the groundtruth class), complicating the task for the neural network. Then we do everything as usual: Softmax + Cross Entropy.
In total, the usual linear layer is replaced by the ArcFace layer, which is written not in 10, but in 20 lines, but gives excellent results and a minimum of overhead for implementation. As a result, ArcFace is better than most other methods for most tasks. It integrates perfectly with classification tasks and improves quality.
Transfer learning
The second thing I wanted to talk about is Transfer learning - using a pre-trained network on a similar task for retraining on a new task. Thus, knowledge is transferred from one task to another.
We did our search on images. The essence of the task is to produce semantically similar ones from the database in the image (query).

It is logical to take a network that has already studied on a large number of images - on ImageNet or OpenImages datasets, in which there are millions of pictures, and train on our data.
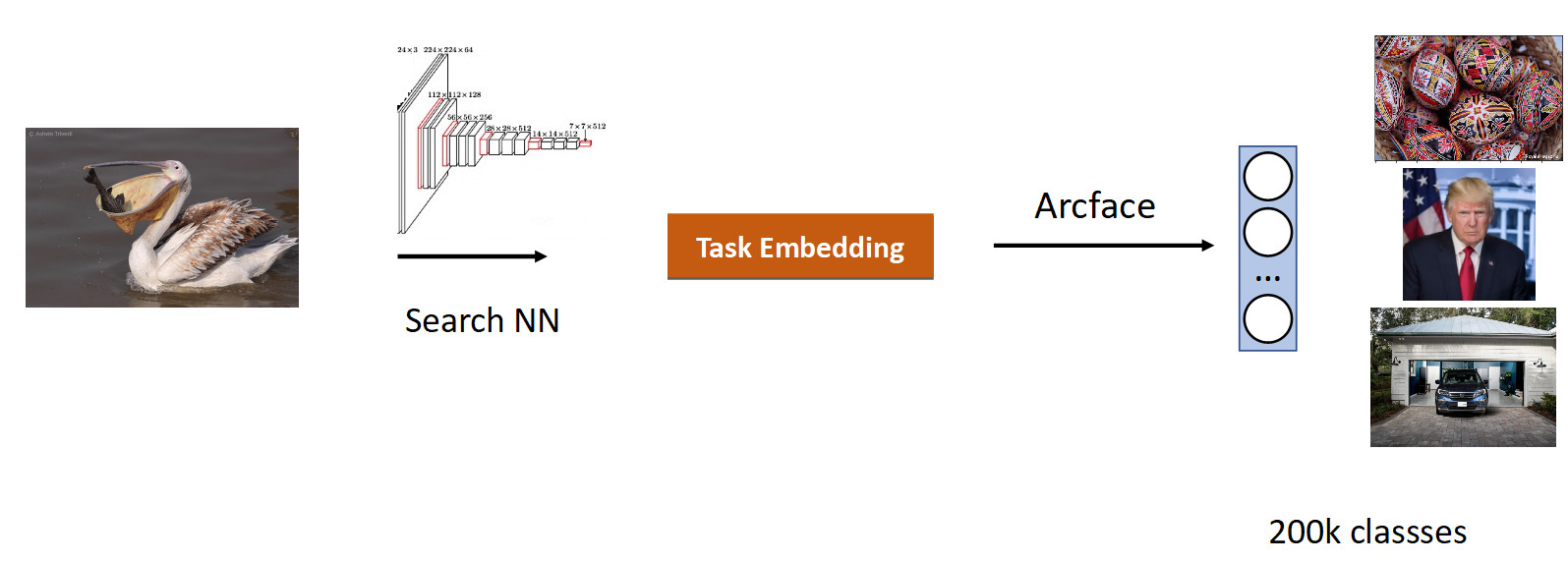
We collected data for this task based on the similarity of pictures and user clicks and got 200k classes. After training with ArсFace, we got the following result.

In the picture above, we see that for the requested pelican, sparrows also got into the issue. Those. embedding turned out semantically true - it is a bird, but racially unfaithful. The most annoying thing is that the original model with which we retrained knew these classes and distinguished them perfectly. Here we see the effect that is common to all neural networks, called catastrophic forgetting. That is, during retraining, the network forgets the previous task, sometimes even completely. This is exactly what prevents in this task to achieve better quality.
Knowledge distillation
This is treated using a technique called knowledge distillation, when one network teaches another and “transfers its knowledge to it”. How it looks (full training pipeline in the picture below).
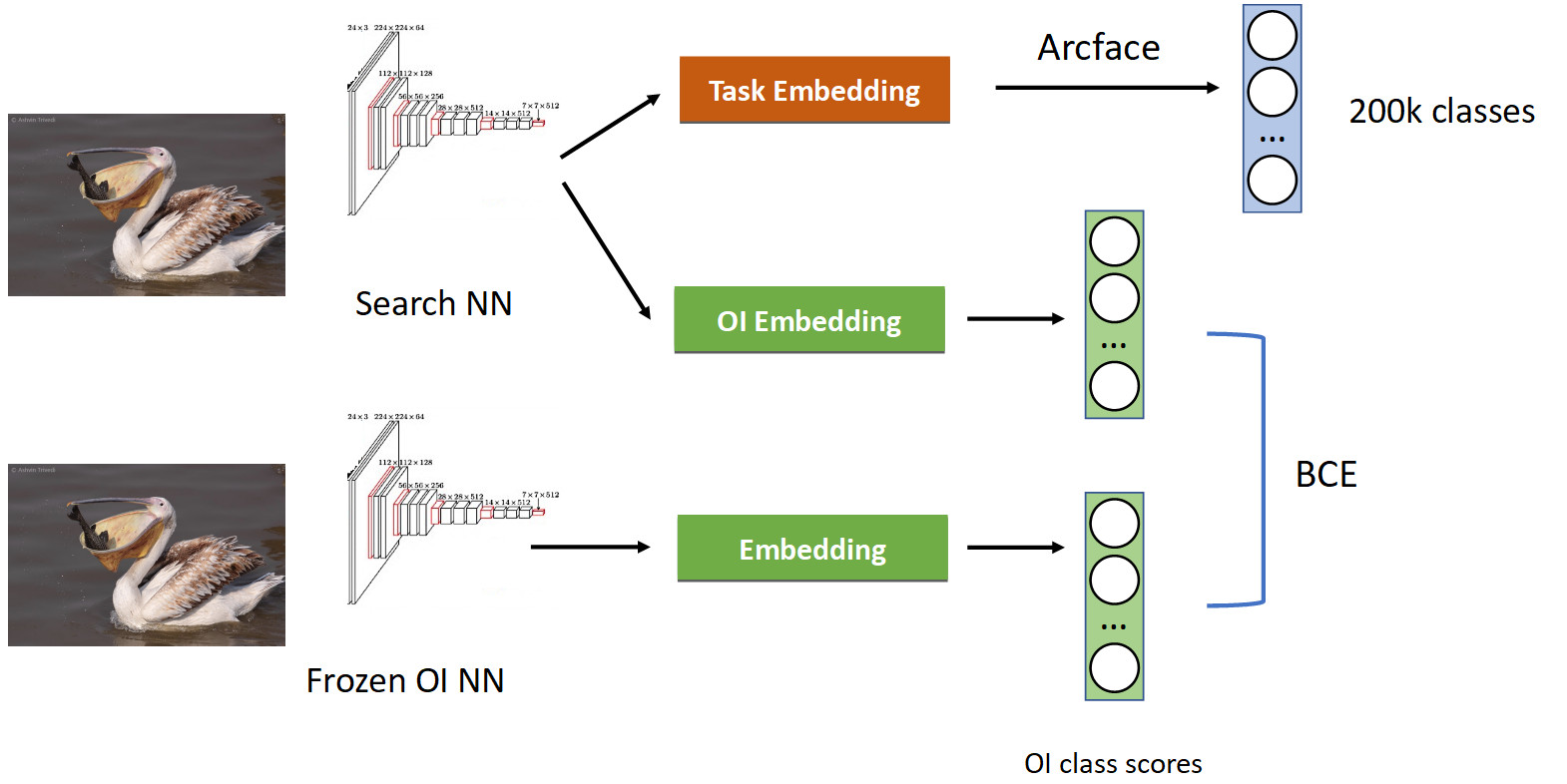
We already have a familiar classification pipeline with Arcface. Recall that we have a network with which we are pretended. We froze it and simply calculate its embeddings in all the photos in which we learn our network, and get the classes of the OpenImages classes: pelicans, sparrows, cars, people, etc. ... We budge from the original trained neural network and learn another embedding for the classes OpenImages, which produces similar scores. With BCE, we make the network produce a similar distribution of these scores. Thus, on the one hand, we are learning a new task (at the top of the picture), but we also make the network not forget its roots (at the bottom) - remember the classes that it used to know. If you correctly balance the gradients in a conditional proportion of 50/50, then this will leave all the pelicans in the top and throw out all the sparrows from there.

When we applied this, we got a full percentage in the mAP. This is quite a lot.
| Model | mAP |
|---|---|
| Arcface | 92.8 |
| + Knowledge distil | 93.8 (+1%) |
So if your network forgets the previous task, then treat using knowledge distillation - this works fine.
Extra heads
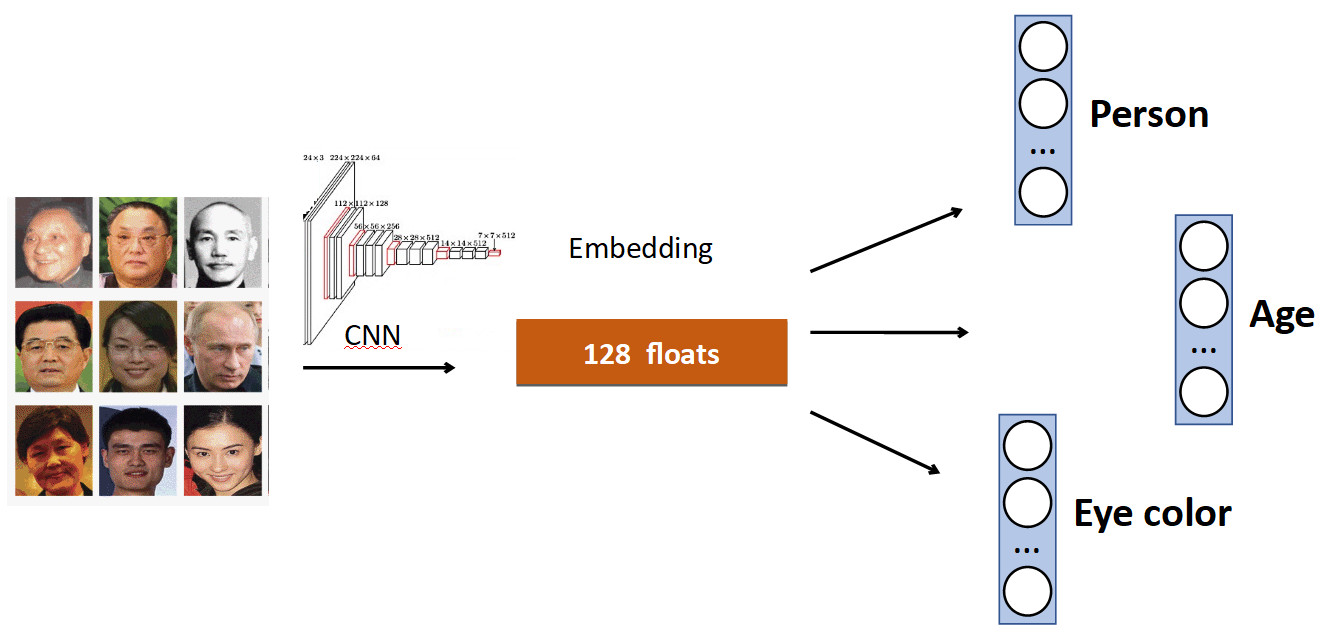
The basic idea is very simple. Again on the example of Face Recognition. We have a set of people in the dataset. But also often in datasets there are other characteristics of the face. For example, how old, what eye color, etc. All this can be added as one more add. signal: teach individual heads to predict this data. Thus, our network receives more diverse signal, and as a result, it may be better to learn the main task.
Another example: queue detection.

Often in datasets with people, in addition to the body, there is a separate marking of the position of the head, which, obviously, can be used. Therefore, we added to the network the prediction of the person’s bounding box and the prediction of the head’s bounding box, and we got an increase of 0.5% in accuracy (mAP), which is decent. And most importantly - free in terms of performance, because on production, the extra head is “disconnected”.

OCR
A more complex and interesting case is the OCR, already mentioned above. The standard pipeline is like that.
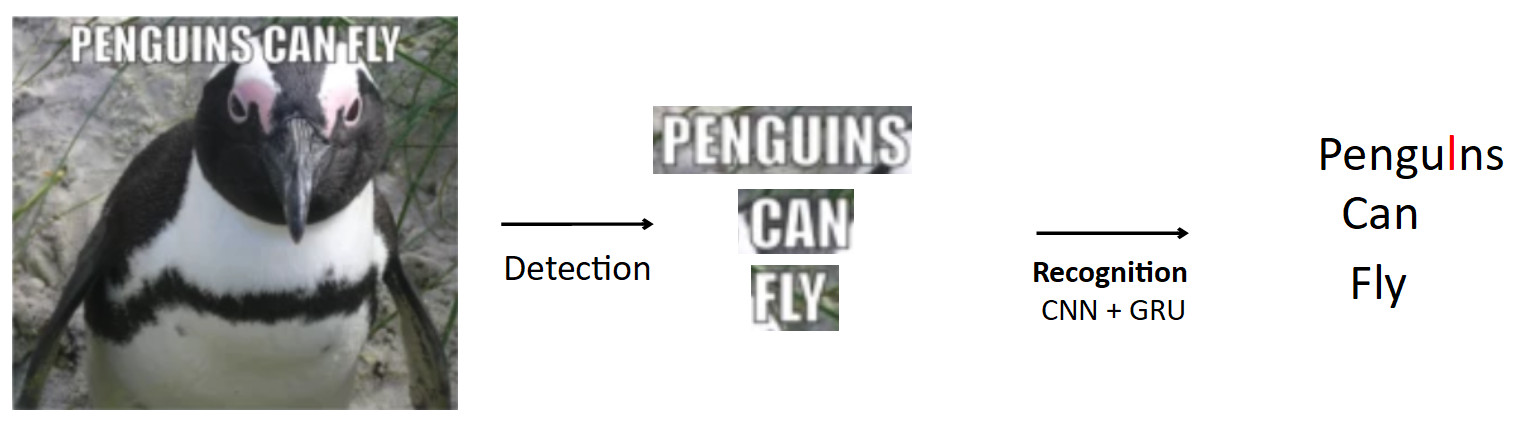
Let there be a poster with a penguin, the text is written on it. Using the detection model, we highlight this text. Further, we feed this text to the input of the recognition model, which produces the recognized text. Let's say our network is wrong and instead of “i” in the word penguins predicts “l”. This is actually a very common problem in OCR when the network confuses similar characters. The question is how to avoid this - translate pengulns into penguins? When a person looks at this example, it is obvious to him that this is a mistake, because he has knowledge of the structure of the language. Therefore, knowledge about the distribution of characters and words in the language should be embedded in the model.
We used a thing called BPE (byte-pair encoding) for this. This is a compression algorithm that was generally invented back in the 90s not for machine learning, but now it is very popular and is used in deep learning. The meaning of the algorithm is that frequently occurring subsequences in the text are replaced with new characters. Suppose we have the string "aaabdaaabac", and we want to get a BPE for it. We find that the pair of characters “aa” is the most frequent in our word. We replace it with a new character “Z”, we get the string “ZabdZabac”. We repeat the iteration: we see that ab is the most frequent subsequence, replace it with “Y”, we get the string “ZYdZYac”. Now “ZY” is the most frequent subsequence, we replace it with “X”, we get “XdXac”. Thus, we encode some statistical dependencies in the distribution of the text. If we meet a word,
aaabdaaabac
ZabdZabac Z=aa
ZYdZYac Y=ab
XdXac X=ZYHow it all fits into recognition.
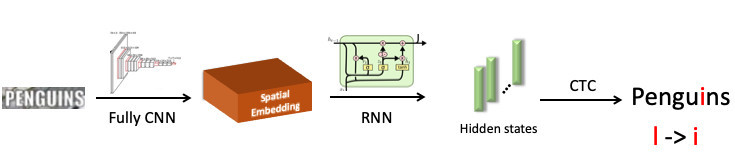
We highlighted the word “penguin”, sent it to the convolutional neural network, which produced spatial embedding (a fixed-length vector, for example 512). This vector encodes spatial symbol information. Next, we use a recurrence network (UPD: in fact, we already use the Transformer model), it gives out some hidden states (green bars), in each of which the probability distribution is sewn up - which, according to the model, the symbol is depicted at a specific position. Then, using CTC-Loss, we unwind these states and get our prediction for the whole word, but with an error: L in place of i.
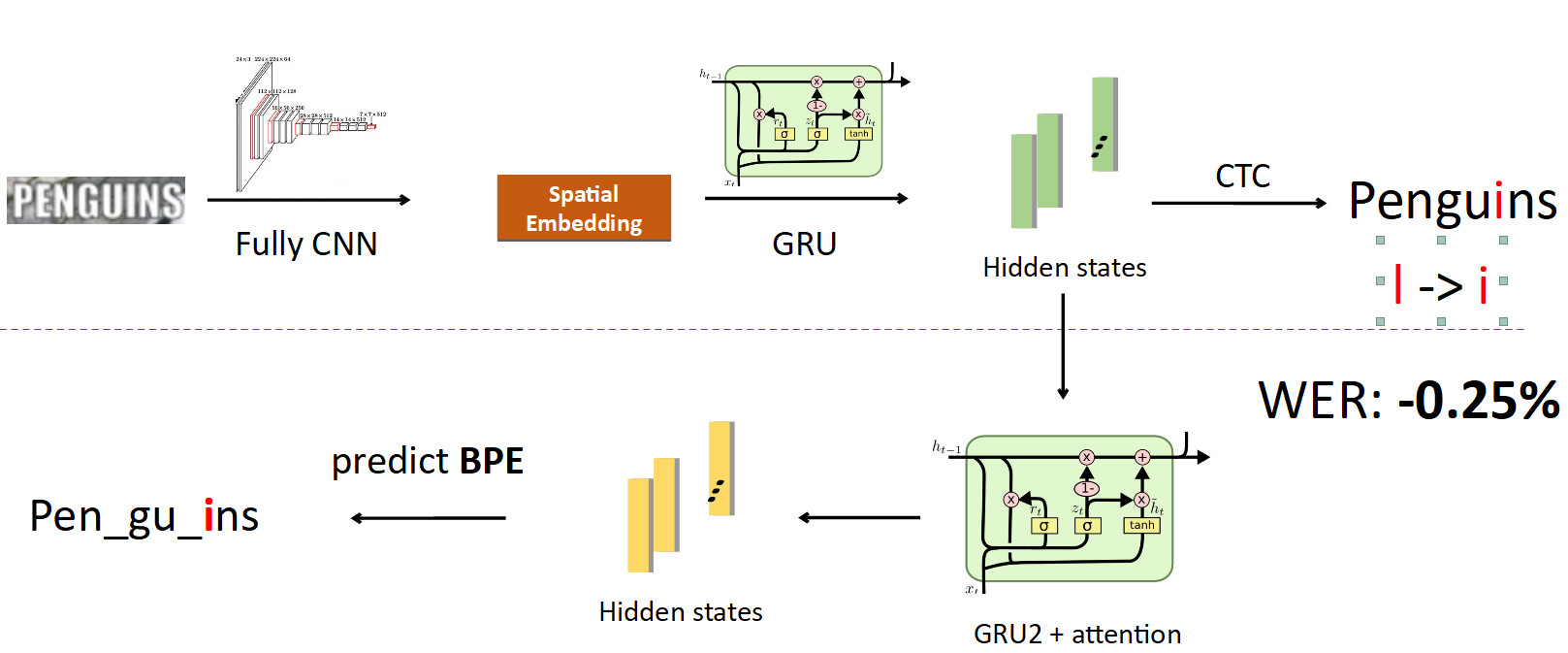
Now integrating BPE in the pipeline. We want to get away from predicting individual characters to words, so we branch off from the states in which information about the characters is sewn up and set another recursive network on them; she predicts BPE. In the case of the error described above, 3 BPEs are obtained: "peng", "ul", "ns". This differs significantly from the correct sequence for the word penguins, that is, pen, gu, ins. If you look at this from the point of view of model training, then, in a character-by-word prediction, the network made a mistake in only one letter out of eight (12.5% error); and in terms of BPE, she was 100% mistaken in predicting all 3 BPEs incorrectly. This is a much bigger signal for the network that something went wrong and you need to fix your behavior. When we implemented this, we were able to fix errors of this kind and reduced the Word Error Rate by 0.25% - that's a lot.
FP16
The last thing I wanted to say about training was FP16. It so happened historically that networks were trained on the GPU in unit accuracy, i.e. FP32. But this is redundant, especially for inference, where half accuracy (FP16) is enough without loss of quality. However, this is not the case with training.
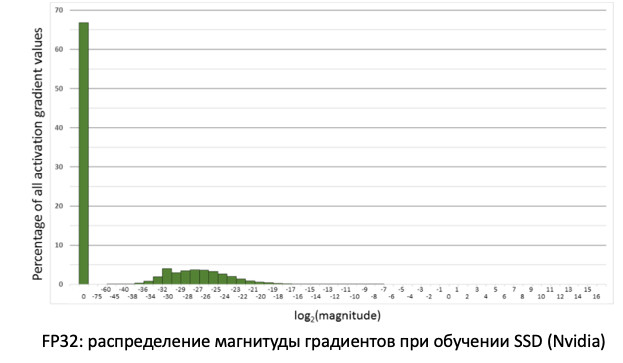
If we look at the distribution of gradients, information that updates our weights when propagating errors, we will see that there is a huge peak at zero. And in general, a lot of values are near zero. If we just transfer all the weights to FP16, it turns out that we cut off the left side in the region of zero (from the red line).
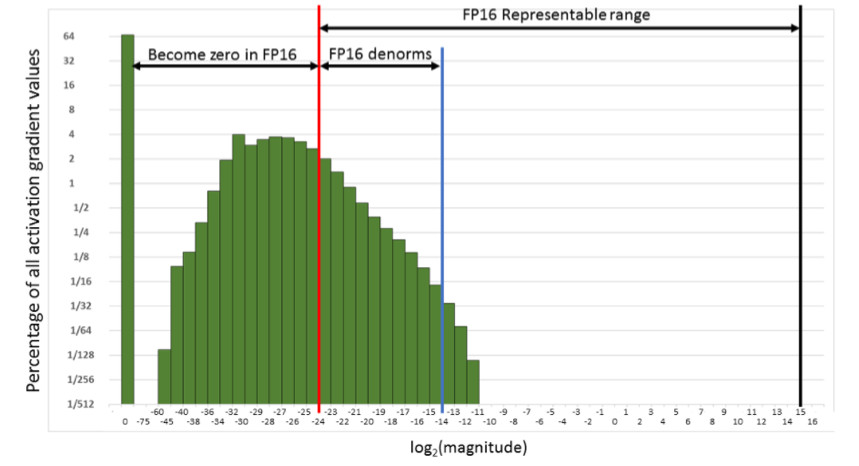
That is, we will reset a very large number of gradients. And the right part, in the FP16 working range, is not used at all. As a result, if you train forehead on FP16, then the process is likely to disperse (the gray graph in the picture below).
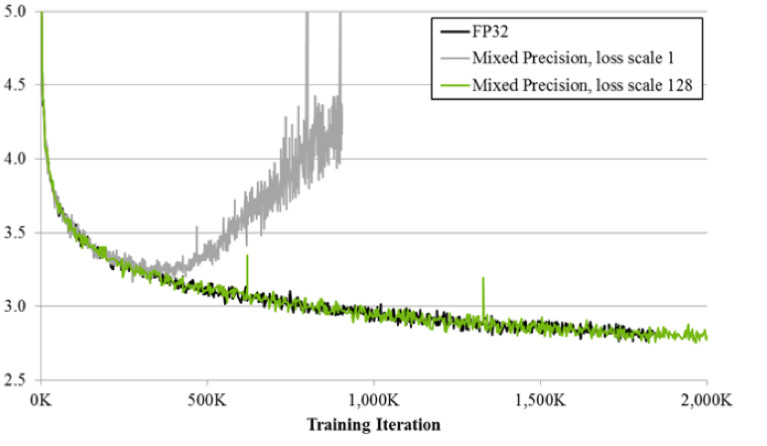
If you train using the mixed precision technique, the result is almost identical to FP32. Mixed precision implements two tricks.
First: we simply multiply loss by a constant, for example, 128. Thus, we scale all the gradients, and move their values from zero to the working range of FP16. Second: we store the master version of the FP32 balance, which is used only for updating, and in the operations of calculating forward and backward pass networks, only FP16 is used.
We use Pytorch to train networks. NVIDIA made a special assembly for it with the so-called APEX, which implements the logic described above. He has two modes. The first is Automatic mixed precision. See the code below to see how easy it is to use.

Literally two lines are added to the training code that wrap the loss and the initialization procedure of the model and optimizers. What does AMP do? He monkey patch'it all functions. What exactly is going on? For example, he sees that there is a convolution function, and she receives a profit from FP16. Then he replaces it with his own, which first casts to FP16, and then performs a convolution operation. So AMP does for all the functions that can be used on the network. For some, it doesn’t. there will be no acceleration. For most tasks, this method is suitable.
Second option: FP16 optimizer for fans of complete control. Suitable if you yourself want to specify which layers will be in FP16 and which in FP32. But it has a number of limitations and difficulties. It does not start with a half kick (at least we had to sweat to start it). Also FP_optimizer works only with Adam, and even then only with that Adam, which is in APEX (yes, they have their own Adam in the repository, which has a completely different interface than Paytorch).
We made a comparison when learning on Tesla T4 cards.
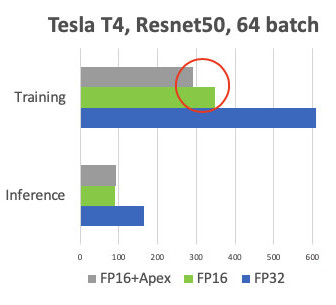
At Inference, we have the expected acceleration twice. In training, we see that the Apex framework provides 20% acceleration with relatively simple FP16. As a result, we get a workout that is twice as fast and consumes 2 times less memory, and the quality of training does not suffer in any way. Freebie.
Inference
Because Since we use PyTorch, the question is urgently how to deploy it in production.

There are 3 options for how to do it (and all of them we used (s).
- ONNX -> Caffe2
- ONNX -> TensorRT
- And more recently Pytorch C ++
Let's look at each of them.
ONNX and Caffe2
1,5 года назад появился ONNX. Это специальный фреймворк для конвертации моделей между различными фреймворками. А Caffe2 — фреймворк, смежный с Pytorch, оба разрабатывают в Facebook. Исторически Pytorch развивается гораздо быстрее, чем Caffe2. Caffe2 отстает по фичам от Pytorch, поэтому не каждую модель, которую вы обучили в Pytorch, можно конвертнуть в Caffe2. Часто приходится переучивать с другими слоями. К примеру, в Caffe2 нет такой стандартной операции как upsampling с nearest neighbor interpolation. В итоге мы пришли к тому, что под каждую модель завели специальный docker image, в котором мы прибиваем версии фреймворков гвоздями во избежания расхождений при их будущих обновлений, чтобы когда в очередной раз обновится какая-нибудь из версий, мы не тратили время на их совместимость. Все это не очень удобно и удлиняет процесс деплоя.
Tensor RT
There is also Tensor RT, an NVIDIA framework that optimizes network architecture to accelerate inference. We made our measurements (on the Tesla T4 map).
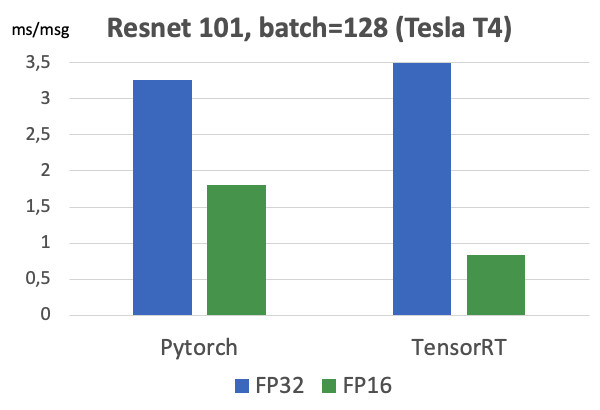
If you look at the graphs, you can see that the transition from FP32 to FP16 gives 2x acceleration on Pytorch, and TensorRT at the same time gives as much 4x. A very significant difference. We tested it on Tesla T4, which has tensor kernels that just very well utilize FP16 calculations, which is obviously excellent in TensorRT. Therefore, if there is a highly loaded model running on dozens of graphics cards, then there are all motivators to try Tensor RT.
However, when working with TensorRT there is even more pain than in Caffe2: layers are even less supported in it. Unfortunately, every time we use this framework, we have to suffer a little to convert the model. But for heavily loaded models, you have to do this. ;) I note that on maps without tensor kernels such a massive increase is not observed.
Pytorch C ++
And the last one is Pytorch C ++. Six months ago, Pytorch developers realized the pain of the people who use their framework and released the TorchScript tutorial , which allows you to trace and serialize the Python model into a static graph without unnecessary gestures (JIT). It was released in December 2018, we immediately started using it, immediately caught a few performance bugs and waited several months for fixation from Chintala. But now it is a fairly stable technology, and we are actively using it for all models. The only thing is the lack of documentation, which is being actively supplemented. Of course, you can always look at * .h files, but for people who don’t know the pluses, it’s hard. But then there is really identical work with Python. In C ++, j-code is run on a minimal Python interpreter, which practically guarantees the identity of C ++ with Python.
conclusions
- The statement of the problem is super important. You must communicate with product managers on data. Before you begin to do the task, it is advisable to have a ready-made test set on which we measure the final metrics before the implementation stage.
- We clean the data ourselves with the help of clustering. We get the model on the source data, clean the data using CLink clustering, and repeat the process until convergence.
- Metric learning: even classification helps. State-of-the-art - ArcFace, which is easy to integrate into the learning process.
- If you do transfer learning from a pre-trained network, then so that the network does not forget the old task, use knowledge distillation.
- It is also useful to use several network heads that will utilize different signals from the data to improve the main task.
- For FP16, you need to use the Apex assemblies from NVIDIA, Pytorch.
- And on inference it is convenient to use Pytorch C ++.