Sampling and calculation accuracy
A number of my colleagues are faced with the problem that in order to calculate some kind of metric, for example, conversion rate, you have to validate the entire database. Or you need to conduct a detailed study for each client, where there are millions of customers. This kind of kerry can work for quite some time, even in specially made repositories. It’s not very fun to wait 5-15-40 minutes until a simple metric is considered to find out that you need to calculate something else or add something else.
One solution to this problem is sampling: we are not trying to calculate our metric on the entire data array, but take a subset that representatively represents the metrics we need. This sample can be 1000 times smaller than our data array, but it’s good enough to show the numbers we need.
In this article, I decided to demonstrate how sampling sample sizes affect the final metric error.
Problem
The key question is: how well does the sample describe the “population”? Since we take a sample from a common array, the metrics we receive turn out to be random variables. Different samples will give us different metric results. Different, does not mean any. Probability theory tells us that the metric values obtained by sampling should be grouped around the true metric value (made over the entire sample) with a certain level of error. Moreover, we often have problems where a different error level can be dispensed with. It’s one thing to figure out whether we get a conversion of 50% or 10%, and it’s another thing to get a result with an accuracy of 50.01% vs 50.02%.
It is interesting that from the point of view of theory, the conversion coefficient observed by us over the entire sample is also a random variable, because The “theoretical” conversion rate can only be calculated on a sample of infinite size. This means that even all our observations in the database actually give a conversion estimate with their accuracy, although it seems to us that these calculated numbers are absolutely accurate. This also leads to the conclusion that even if today the conversion rate differs from yesterday, this does not mean that something has changed, but only means that the current sample (all observations in the database) is from the general population (all possible observations for this day, which occurred and did not occur) gave a slightly different result than yesterday.
Task statement
Let's say we have 1,000,000 records in a database of type 0/1, which tell us whether a conversion has occurred on an event. Then the conversion rate is simply the sum of 1 divided by 1 million.
Question: if we take a sample of size N, how much and with what probability will the conversion rate differ from that calculated over the entire sample?
Theoretical considerations
The task is reduced to calculating the confidence interval of the conversion coefficient for a sample of a given size for a binomial distribution.
From theory, the standard deviation for the binomial distribution is:
S = sqrt (p * (1 - p) / N)
Where
p - conversion rate
N - Sample size
S - standard deviation
I will not consider the direct confidence interval from the theory. There is a rather complicated and confusing matan, which ultimately relates the standard deviation and the final estimate of the confidence interval.
Let's develop an "intuition" about the standard deviation formula:
- The larger the sample size, the smaller the error. In this case, the error falls in the inverse quadratic dependence, i.e. increasing the sample by 4 times increases the accuracy by only 2 times. This means that at some point increasing the sample size will not give any particular advantages, and also means that a fairly high accuracy can be obtained with a fairly small sample.

- There is a dependence of the error on the value of the conversion rate. The relative error (that is, the ratio of the error to the value of the conversion rate) has a "vile" tendency to be the greater, the lower the conversion rate:
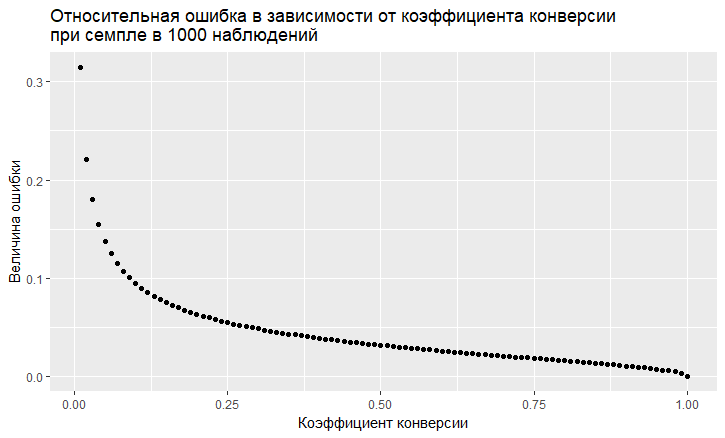
- As we see, the error "flies up" into the sky with a low conversion rate. This means that if you sample rare events, then you need large sample sizes, otherwise you will get a conversion estimate with a very big error.
Modeling
We can completely move away from the theoretical solution and solve the problem "head on." Thanks to the R language, this is now very easy to do. To answer the question, what error do we get when sampling, you can just do a thousand samples and see what error we get.
The approach is this:
- We take different conversion rates (from 0.01% to 50%).
- We take 1000 samples of 10, 100, 1000, 10000, 50,000, 100,000, 250,000, 500,000 elements in the sample
- We calculate the conversion rate for each group of samples (1000 coefficients)
- We construct a histogram for each group of samples and determine the extent to which 60%, 80% and 90% of the observed conversion rates lie.
R code generating data:
sample.size <- c(10, 100, 1000, 10000, 50000, 100000, 250000, 500000)
bootstrap = 1000
Error <- NULL
len = 1000000
for (prob in c(0.0001, 0.001, 0.01, 0.1, 0.5)){
CRsub <- data.table(sample_size = 0, CR = 0)
v1 = seq(1,len)
v2 = rbinom(len, 1, prob)
set = data.table(index = v1, conv = v2)
print(paste('probability is: ', prob))
for (j in 1:length(sample.size)){
for(i in 1:bootstrap){
ss <- sample.size[j]
subset <- set[round(runif(ss, min = 1, max = len),0),]
CRsample <- sum(subset$conv)/dim(subset)[1]
CRsub <- rbind(CRsub, data.table(sample_size = ss, CR = CRsample))
}
print(paste('sample size is:', sample.size[j]))
q <- quantile(CRsub[sample_size == ss, CR], probs = c(0.05,0.1, 0.2, 0.8, 0.9, 0.95))
Error <- rbind(Error, cbind(prob,ss,t(q)))
}As a result, we get the following table (there will be graphs later, but the details are better visible in the table).
| Conversion rate | Sample size | 5% | 10% | 20% | 80% | 90% | 95% |
|---|---|---|---|---|---|---|---|
| 0.0001 | 10 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.0001 | 100 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.0001 | 1000 | 0 | 0 | 0 | 0 | 0 | 0.001 |
| 0.0001 | 10,000 | 0 | 0 | 0 | 0.0002 | 0.0002 | 0.0003 |
| 0.0001 | 50,000 | 0.00004 | 0.00004 | 0.00006 | 0.00014 | 0.00016 | 0.00018 |
| 0.0001 | 100,000 | 0.00005 | 0.00006 | 0.00007 | 0.00013 | 0.00014 | 0.00016 |
| 0.0001 | 250000 | 0.000072 | 0.0000796 | 0.000088 | 0.00012 | 0.000128 | 0.000136 |
| 0.0001 | 500,000 | 0.00008 | 0.000084 | 0.000092 | 0.000114 | 0.000122 | 0.000128 |
| 0.001 | 10 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.001 | 100 | 0 | 0 | 0 | 0 | 0 | 0.01 |
| 0.001 | 1000 | 0 | 0 | 0 | 0.002 | 0.002 | 0.003 |
| 0.001 | 10,000 | 0.0005 | 0.0006 | 0.0007 | 0.0013 | 0.0014 | 0.0016 |
| 0.001 | 50,000 | 0.0008 | 0.000858 | 0.00092 | 0.00116 | 0.00122 | 0.00126 |
| 0.001 | 100,000 | 0.00087 | 0.00091 | 0.00095 | 0.00112 | 0.00116 | 0.0012105 |
| 0.001 | 250000 | 0.00092 | 0.000948 | 0.000972 | 0.001084 | 0.001116 | 0.0011362 |
| 0.001 | 500,000 | 0.000952 | 0.0009698 | 0.000988 | 0.001066 | 0.001086 | 0.0011041 |
| 0.01 | 10 | 0 | 0 | 0 | 0 | 0 | 0.1 |
| 0.01 | 100 | 0 | 0 | 0 | 0.02 | 0.02 | 0.03 |
| 0.01 | 1000 | 0.006 | 0.006 | 0.008 | 0.013 | 0.014 | 0.015 |
| 0.01 | 10,000 | 0.0086 | 0.0089 | 0.0092 | 0.0109 | 0.0114 | 0.0118 |
| 0.01 | 50,000 | 0.0093 | 0.0095 | 0.0097 | 0.0104 | 0.0106 | 0.0108 |
| 0.01 | 100,000 | 0.0095 | 0.0096 | 0.0098 | 0.0103 | 0.0104 | 0.0106 |
| 0.01 | 250000 | 0.0097 | 0.0098 | 0.0099 | 0.0102 | 0.0103 | 0.0104 |
| 0.01 | 500,000 | 0.0098 | 0.0099 | 0.0099 | 0.0102 | 0.0102 | 0.0103 |
| 0.1 | 10 | 0 | 0 | 0 | 0.2 | 0.2 | 0.3 |
| 0.1 | 100 | 0.05 | 0.06 | 0.07 | 0.13 | 0.14 | 0.15 |
| 0.1 | 1000 | 0.086 | 0.0889 | 0.093 | 0.108 | 0.1121 | 0.117 |
| 0.1 | 10,000 | 0.0954 | 0.0963 | 0.0979 | 0.1028 | 0.1041 | 0.1055 |
| 0.1 | 50,000 | 0.098 | 0.0986 | 0.0992 | 0.1014 | 0.1019 | 0.1024 |
| 0.1 | 100,000 | 0.0987 | 0.099 | 0.0994 | 0.1011 | 0.1014 | 0.1018 |
| 0.1 | 250000 | 0.0993 | 0.0995 | 0.0998 | 0.1008 | 0.1011 | 0.1013 |
| 0.1 | 500,000 | 0.0996 | 0.0998 | 0.1 | 0.1007 | 0.1009 | 0.101 |
| 0.5 | 10 | 0.2 | 0.3 | 0.4 | 0.6 | 0.7 | 0.8 |
| 0.5 | 100 | 0.42 | 0.44 | 0.46 | 0.54 | 0.56 | 0.58 |
| 0.5 | 1000 | 0.473 | 0.478 | 0.486 | 0.513 | 0.52 | 0.525 |
| 0.5 | 10,000 | 0.4922 | 0.4939 | 0.4959 | 0.5044 | 0.5061 | 0.5078 |
| 0.5 | 50,000 | 0.4962 | 0.4968 | 0.4978 | 0.5018 | 0.5028 | 0.5036 |
| 0.5 | 100,000 | 0.4974 | 0.4979 | 0.4986 | 0.5014 | 0.5021 | 0.5027 |
| 0.5 | 250000 | 0.4984 | 0.4987 | 0.4992 | 0.5008 | 0.5013 | 0.5017 |
| 0.5 | 500,000 | 0.4988 | 0.4991 | 0.4994 | 0.5006 | 0.5009 | 0.5011 |
Let's see the cases with 10% conversion and with a low 0.01% conversion, because all features of working with sampling are clearly visible on them.
At 10% conversion, the picture looks pretty simple:

Points are the edges of the 5-95% confidence interval, i.e. making a sample we will in 90% of cases get CR on the sample within this interval. Vertical scale - sample size (logarithmic scale), horizontal - conversion rate value. The vertical bar is a “true” CR.
We see the same thing that we saw from the theoretical model: accuracy increases as the size of the sample grows, and one converges quite quickly and the sample gets a result close to "true". In total for 1000 samples we have 8.6% - 11.7%, which will be enough for a number of tasks. And in 10 thousand already 9.5% - 10.55%.
Things are worse with rare events and this is consistent with the theory:

У низкого коэффициента конверсии в 0.01% принципе проблемы на статистике в 1 млн наблюдений, а с сэмплами ситуация оказывается еще хуже. Ошибка становится просто гигантской. На сэмплах до 10 000 метрика в принципе не валидна. Например, на сэмпле в 10 наблюдений мой генератор просто 1000 раз получил 0 конверсию, поэтому там только 1 точка. На 100 тысячах мы имеем разброс от 0.005% до 0.0016%, т.е мы можем ошибаться почти в половину коэффициента при таком сэмплировании.
Также стоит отметить, что когда вы наблюдаете конверсию такого маленького масштаба на 1 млн испытаний, то у вас просто большая натуральная ошибка. Из этого следует, что выводы по динамике таких редких событий надо делать на действительно больших выборках иначе вы просто гоняетесь за призраками, за случайными флуктуациями в данных.
Выводы:
- Сэмплирование рабочий метод для получения оценок
- Sample accuracy increases with increasing sample size and decreases with a decrease in conversion rate.
- The accuracy of the estimates can be modeled for your task and thus choose the optimal sampling for yourself.
- It’s important to remember that rare events do not sample well
- In general, rare events are difficult to analyze; they require large data samples without samples.