Introducing Airflow to manage Spark Jobs in ivi: hopes and crutches
The task of deploying machine learning models in production is always pain and suffering, because it is very uncomfortable to get out of a cozy jupyter notebook into the world of monitoring and fault tolerance.
We already wrote about the first iteration of refactoringonline cinema recommendation system ivi. Over the past year, we almost did not finalize the application architecture (from global - only moving from obsolete python 2.7 and python 3.4 to “fresh” python 3.6), but we added a few new ML models and immediately ran into the problem of rolling out new algorithms in production. In the article, I will talk about our experience in implementing such a task flow management tool like Apache Airflow: why the team had this need, what did not suit the existing solution, which crutches had to be cut along the way and what came of it.
→ The video version of the report can be watched on YouTube (starting from 03:00:00) here .

I’ll tell you a little about the project: ivi is several tens of thousands of units of content, we have one of the largest legal directories in RuNet. The main page of the ivi web version is a personalized cut from the catalog, which is designed to provide the user with the most rich, most relevant content based on his feedback (views, ratings, and so on).
The online part of the recommendation system is a Flask backend application with a load of up to 600 RPS. Offline, the model is trained on more than 250 million content views per month. The data preparation pipelines for training are implemented on Spark, which runs on top of the Hive repository.
The team now has 7 developers who are engaged in both creating models and rolling them out into production - this is a rather large team that requires convenient tools for managing task flows.
Below you see the data flow infrastructure diagram for the recommender system.
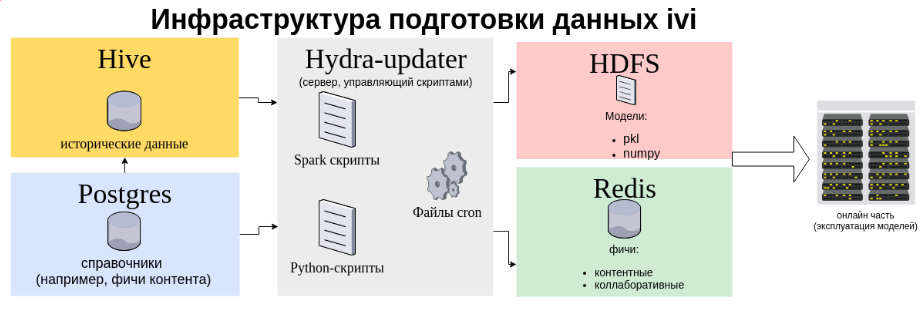
Two data storages are depicted here - Hive for user feedback (views, ratings) and Postgres for various business information (types of content monetization, etc.), while the transfer from Postgres to Hive is adjusted. A pack of Spark applications sucks data from Hive: and trains our models on this data (ALS for personal recommendations, various collaborative models of content similarity).
Spark applications have traditionally been managed from a dedicated virtual machine, which we call hydra-updater using a bunch of cron + shell scripts. This bundle was created in the ivi operations department in time immemorial and worked great. Shell-script was a single entry point for launching spark-applications - that is, each new model started spinning in the prod only after administrators finished this script.
Some of the artifacts of model training are stored in HDFS for eternal storage (and waiting for someone to download them from there and transfer to the server where the online part is spinning), and some are written directly from the Spark driver to the Redis fast storage, which we use as general memory for several dozen python processes of the online part.
Such an architecture has accumulated a number of disadvantages over time:

The diagram shows that data flows have a rather complicated and complicated structure - without a simple and clear tool for managing this good, development and operation will turn into horror, decay, and suffering.
In addition to managing spark applications, the admin script does a lot of useful things: restarting services in battle, a Redis dump, and other system things. Obviously, over a long period of operation, the script has overgrown with many functions, since each new model of ours generated a couple of dozen lines in it. The script began to look too overloaded in terms of functionality, therefore, as a team of the recommender system, we wanted to take out somewhere a part of the functionality that concerns launching and managing Spark applications. For these purposes, we decided to use Airflow.
In addition to solving all these problems, of course, on the way we created new ones for ourselves - deploying Airflow to launch and monitor Spark applications turned out to be difficult.
The main difficulty was that no one would remodel the entire infrastructure for us, because devops resource is a scarce thing. For this reason, we had to not only implement Airflow, but integrate it into the existing system, which is much more difficult to saw from scratch.
I want to talk about the pains that we encountered during the implementation process, and the crutches that we had to gash in order to get Airflow.
The first and main pain : how to integrate Airflow into a large shell script of the operations department.
Here the solution is the most obvious - we began to trigger graphs directly from the shell script using the airflow binary with the trigger_dag key. With this approach, we do not use the Airflow sheduler, and in fact the Spark application is launched with the same crown - this is religiously not very correct. But we got a seamless integration with an existing solution. Here's what the start looks like from the shell script of our main Spark application, which is historically called hydramatrices.
Pain: The shell script of the operations department must somehow determine the status of the Airflow graph in order to control its own execution flow.
Crutch: we extended the Airflow REST API with an endpoint for DAG monitoring right inside shell scripts. Now each graph has three states: RUNNING, SUCCEED, FAILED.
In fact, after starting the calculations in Airflow, we simply regularly poll the running graph: we bullet the GET request to determine if the DAG has completed or not. When the monitoring endpoint responds about the successful execution of the graph, the shell script continues to execute its flow.
I want to say that the Airflow REST API is just a fiery thing that allows you to flexibly configure your pipelines - for example, you can forward POST parameters to graphs.
The Airflow API extension is just a Python class that looks something like this:
We use the API in the shell script - we poll the endpoint every 10 minutes:
Pain : if you ever run a Spark job using spark-submit in cluster mode, then you know that the logs in STDOUT are an uninformative sheet with the lines “SPARK APPLICATION_ID IS RUNNING”. The logs of the Spark application itself could be viewed, for example, using the yarn logs command. In the shell script, this problem was solved simply: an SSH tunnel was opened to one of the cluster machines and spark-submit was executed in client mode for this machine. In this case, STDOUT will have readable and understandable logs. In Airflow, we decided to always use cluster-decide, and such a number will not work.
Crutch: after spark-submit has worked, we pull the driver logs from HDFS by application_id and display it in the Airflow interface simply through the Python print () operator. The only negative - in the Airflow interface, the logs appear only after the spark-submit has worked, you have to follow the realtime in other places - for example, the YARN web muzzle.
Pain : for testers and developers, it would be nice to have an Airflow test bench, but we are saving devops resources, so we have been thinking about how to deploy the test environment for a long time.
Crutch: we packed Airflow in a docker container, and Dockerfile put it right in the repository with spark jobs. Thus, each developer or tester can raise their own Airflow on a local machine. Due to the fact that applications run in cluster-mode, local resources for docker are almost not required.
A local installation of the spark was hidden inside the docker container and its entire configuration via environment variables - you no longer need to spend several hours setting up the environment. Below I gave an example with a docker file fragment for a container with Airflow, where you can see how Airflow is configured using environment variables:
As a result of the implementation of Airflow, we achieved the following results:
Where to go next? Now we have a huge number of data sources and sinks, the number of which will grow. Changes in any hydramatrices repository class can crash in another pipeline (or even in the online part):
In such a situation, we really need a stand for automatic testing of pipelines in data preparation. This will greatly reduce the cost of testing changes in the repository, accelerate the rolling out of new models in production and dramatically increase the level of endorphins in testers. But without Airflow, it would be impossible to deploy a stand for this kind of auto test!
I wrote this article to talk about our experience in implementing Airflow, which may be useful to other teams in a similar situation - you already have a large working system, and you want to try something new, fashionable and youthful. No need to be afraid of any updates to the working system, you need to try and experiment - such experiments usually open new horizons for further development.
We already wrote about the first iteration of refactoringonline cinema recommendation system ivi. Over the past year, we almost did not finalize the application architecture (from global - only moving from obsolete python 2.7 and python 3.4 to “fresh” python 3.6), but we added a few new ML models and immediately ran into the problem of rolling out new algorithms in production. In the article, I will talk about our experience in implementing such a task flow management tool like Apache Airflow: why the team had this need, what did not suit the existing solution, which crutches had to be cut along the way and what came of it.
→ The video version of the report can be watched on YouTube (starting from 03:00:00) here .
Hydra Team
I’ll tell you a little about the project: ivi is several tens of thousands of units of content, we have one of the largest legal directories in RuNet. The main page of the ivi web version is a personalized cut from the catalog, which is designed to provide the user with the most rich, most relevant content based on his feedback (views, ratings, and so on).
The online part of the recommendation system is a Flask backend application with a load of up to 600 RPS. Offline, the model is trained on more than 250 million content views per month. The data preparation pipelines for training are implemented on Spark, which runs on top of the Hive repository.
The team now has 7 developers who are engaged in both creating models and rolling them out into production - this is a rather large team that requires convenient tools for managing task flows.
Offline Architecture
Below you see the data flow infrastructure diagram for the recommender system.
Two data storages are depicted here - Hive for user feedback (views, ratings) and Postgres for various business information (types of content monetization, etc.), while the transfer from Postgres to Hive is adjusted. A pack of Spark applications sucks data from Hive: and trains our models on this data (ALS for personal recommendations, various collaborative models of content similarity).
Spark applications have traditionally been managed from a dedicated virtual machine, which we call hydra-updater using a bunch of cron + shell scripts. This bundle was created in the ivi operations department in time immemorial and worked great. Shell-script was a single entry point for launching spark-applications - that is, each new model started spinning in the prod only after administrators finished this script.
Some of the artifacts of model training are stored in HDFS for eternal storage (and waiting for someone to download them from there and transfer to the server where the online part is spinning), and some are written directly from the Spark driver to the Redis fast storage, which we use as general memory for several dozen python processes of the online part.
Such an architecture has accumulated a number of disadvantages over time:
The diagram shows that data flows have a rather complicated and complicated structure - without a simple and clear tool for managing this good, development and operation will turn into horror, decay, and suffering.
In addition to managing spark applications, the admin script does a lot of useful things: restarting services in battle, a Redis dump, and other system things. Obviously, over a long period of operation, the script has overgrown with many functions, since each new model of ours generated a couple of dozen lines in it. The script began to look too overloaded in terms of functionality, therefore, as a team of the recommender system, we wanted to take out somewhere a part of the functionality that concerns launching and managing Spark applications. For these purposes, we decided to use Airflow.
Crutches for Airflow
In addition to solving all these problems, of course, on the way we created new ones for ourselves - deploying Airflow to launch and monitor Spark applications turned out to be difficult.
The main difficulty was that no one would remodel the entire infrastructure for us, because devops resource is a scarce thing. For this reason, we had to not only implement Airflow, but integrate it into the existing system, which is much more difficult to saw from scratch.
I want to talk about the pains that we encountered during the implementation process, and the crutches that we had to gash in order to get Airflow.
The first and main pain : how to integrate Airflow into a large shell script of the operations department.
Here the solution is the most obvious - we began to trigger graphs directly from the shell script using the airflow binary with the trigger_dag key. With this approach, we do not use the Airflow sheduler, and in fact the Spark application is launched with the same crown - this is religiously not very correct. But we got a seamless integration with an existing solution. Here's what the start looks like from the shell script of our main Spark application, which is historically called hydramatrices.
log "$FUNCNAME started"
local RETVAL=0
export AIRFLOW_CONFIG=/opt/airflow/airflow.cfg
AIRFLOW_API=api/dag_last_run/hydramatrices/all
log "run /var/www/airflow/bin/airflow trigger_dag hydramatrices"
/var/www/airflow/bin/airflow trigger_dag hydramatrices 2>&1 | tee -a $LOGFILE
Pain: The shell script of the operations department must somehow determine the status of the Airflow graph in order to control its own execution flow.
Crutch: we extended the Airflow REST API with an endpoint for DAG monitoring right inside shell scripts. Now each graph has three states: RUNNING, SUCCEED, FAILED.
In fact, after starting the calculations in Airflow, we simply regularly poll the running graph: we bullet the GET request to determine if the DAG has completed or not. When the monitoring endpoint responds about the successful execution of the graph, the shell script continues to execute its flow.
I want to say that the Airflow REST API is just a fiery thing that allows you to flexibly configure your pipelines - for example, you can forward POST parameters to graphs.
The Airflow API extension is just a Python class that looks something like this:
import json
import os
from airflow import settings
from airflow.models import DagBag, DagRun
from flask import Blueprint, request, Response
airflow_api_blueprint = Blueprint('airflow_api', __name__, url_prefix='/api')
AIRFLOW_DAGS = '{}/dags'.format(
os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
)
class ApiResponse:
"""Класс обработки ответов на GET запросы"""
STATUS_OK = 200
STATUS_NOT_FOUND = 404
def __init__(self):
pass
@staticmethod
def standard_response(status: int, payload: dict) -> Response:
json_data = json.dumps(payload)
resp = Response(json_data, status=status, mimetype='application/json')
return resp
def success(self, payload: dict) -> Response:
return self.standard_response(self.STATUS_OK, payload)
def error(self, status: int, message: str) -> Response:
return self.standard_response(status, {'error': message})
def not_found(self, message: str = 'Resource not found') -> Response:
return self.error(self.STATUS_NOT_FOUND, message)
We use the API in the shell script - we poll the endpoint every 10 minutes:
TRIGGER=$?
[ "$TRIGGER" -eq "0" ] && log "trigger airflow DAG succeeded" || { log "trigger airflow DAG failed"; return 1; }
CMD="curl -s http://$HYDRA_SERVER/$AIRFLOW_API | jq .dag_last_run.state"
STATE=$(eval $CMD)
while [ $STATE == \"running\" ]; do
log "Generating matrices in progress..."
sleep 600
STATE=$(eval $CMD)
done
[ $STATE == \"success\" ] && RETVAL=0 || RETVAL=1
[ $RETVAL -eq 0 ] && log "$FUNCNAME succeeded" || log "$FUNCNAME failed"
return $RETVAL
Pain : if you ever run a Spark job using spark-submit in cluster mode, then you know that the logs in STDOUT are an uninformative sheet with the lines “SPARK APPLICATION_ID IS RUNNING”. The logs of the Spark application itself could be viewed, for example, using the yarn logs command. In the shell script, this problem was solved simply: an SSH tunnel was opened to one of the cluster machines and spark-submit was executed in client mode for this machine. In this case, STDOUT will have readable and understandable logs. In Airflow, we decided to always use cluster-decide, and such a number will not work.
Crutch: after spark-submit has worked, we pull the driver logs from HDFS by application_id and display it in the Airflow interface simply through the Python print () operator. The only negative - in the Airflow interface, the logs appear only after the spark-submit has worked, you have to follow the realtime in other places - for example, the YARN web muzzle.
def get_logs(config: BaseConfig, app_id: str) -> None:
"""Получить логи спарка
:param config:
:param app_id:
"""
hdfs = HDFSInteractor(config)
logs_path = '/tmp/logs/{username}/logs/{app_id}'.format(username=config.CURRENT_USERNAME, app_id=app_id)
logs_files = hdfs.files_in_folder(logs_path)
logs_files = [file for file in logs_files if file[-4:] != '.tmp']
for file in logs_files:
with hdfs.hdfs_client.read(os.path.join(logs_path, file), encoding='utf-8', delimiter='\n') as reader:
print_line = False
for line in reader:
if re.search('stdout', line) and len(line) > 30:
print_line = True
if re.search('stderr', line):
print_line = False
if print_line:
print(line)
Pain : for testers and developers, it would be nice to have an Airflow test bench, but we are saving devops resources, so we have been thinking about how to deploy the test environment for a long time.
Crutch: we packed Airflow in a docker container, and Dockerfile put it right in the repository with spark jobs. Thus, each developer or tester can raise their own Airflow on a local machine. Due to the fact that applications run in cluster-mode, local resources for docker are almost not required.
A local installation of the spark was hidden inside the docker container and its entire configuration via environment variables - you no longer need to spend several hours setting up the environment. Below I gave an example with a docker file fragment for a container with Airflow, where you can see how Airflow is configured using environment variables:
FROM ubuntu:16.04
ARG AIRFLOW_VERSION=1.9.0
ARG AIRFLOW_HOME
ARG USERNAME=airflow
ARG USER_ID
ARG GROUP_ID
ARG LOCALHOST
ARG AIRFLOW_PORT
ARG PIPENV_PATH
ARG PROJECT_HYDRAMATRICES_DOCKER_PATH
RUN apt-get update \
&& apt-get install -y \
python3.6 \
python3.6-dev \
&& update-alternatives --install /usr/bin/python3 python3.6 /usr/bin/python3.6 0 \
&& apt-get -y install python3-pip
RUN mv /root/.pydistutils.cf /root/.pydistutils.cfg
RUN pip3 install pandas==0.20.3 \
apache-airflow==$AIRFLOW_VERSION \
psycopg2==2.7.5 \
ldap3==2.5.1 \
cryptography
# Директория с проектом, которая используется в дальнейшем всеми скриптами
ENV PROJECT_HYDRAMATRICES_DOCKER_PATH=${PROJECT_HYDRAMATRICES_DOCKER_PATH}
ENV PIPENV_PATH=${PIPENV_PATH}
ENV SPARK_HOME=/usr/lib/spark2
ENV HADOOP_CONF_DIR=$PROJECT_HYDRAMATRICES_DOCKER_PATH/etc/hadoop-conf-preprod
ENV PYTHONPATH=${SPARK_HOME}/python/lib/py4j-0.10.4-src.zip:${SPARK_HOME}/python/lib/pyspark.zip:${SPARK_HOME}/python/lib
ENV PIP_NO_BINARY=numpy
ENV AIRFLOW_HOME=${AIRFLOW_HOME}
ENV AIRFLOW_DAGS=${AIRFLOW_HOME}/dags
ENV AIRFLOW_LOGS=${AIRFLOW_HOME}/logs
ENV AIRFLOW_PLUGINS=${AIRFLOW_HOME}/plugins
# Для корректного отображения логов в Airflow (log url)
BASE_URL="http://${AIRFLOW_CURRENT_HOST}:${AIRFLOW_PORT}" ;
# Настройка конфига Airflow
ENV AIRFLOW__WEBSERVER__BASE_URL=${BASE_URL}
ENV AIRFLOW__WEBSERVER__ENDPOINT_URL=${BASE_URL}
ENV AIRFLOW__CORE__AIRFLOW_HOME=${AIRFLOW_HOME}
ENV AIRFLOW__CORE__DAGS_FOLDER=${AIRFLOW_DAGS}
ENV AIRFLOW__CORE__BASE_LOG_FOLDER=${AIRFLOW_LOGS}
ENV AIRFLOW__CORE__PLUGINS_FOLDER=${AIRFLOW_PLUGINS}
ENV AIRFLOW__SCHEDULER__CHILD_PROCESS_LOG_DIRECTORY=${AIRFLOW_LOGS}/scheduler
As a result of the implementation of Airflow, we achieved the following results:
- Reduced the release cycle: rolling out a new model (or data preparation pipeline) now comes down to writing a new Airflow graph, the graphs themselves are stored in the repository and deployed with the code. This process is entirely in the hands of the developer. Admins are happy, we no longer pull them on trifles.
- Spark application logs that used to go straight to hell are now stored in Aiflow with a convenient access interface. You can see the logs for any day without picking in HDFS directories.
- The failed calculation can be restarted with one button in the interface, it is very convenient, even June can handle it.
- You can bullet spark jobs from the interface without having to run into Spark settings on the local machine. Testers are happy - all settings for spark-submit to work correctly are already made in Dockerfile
- Aiflow standard buns - schedules, restarting fallen jobs, beautiful graphs (for example, application execution time, statistics of successful and unsuccessful launches).
Where to go next? Now we have a huge number of data sources and sinks, the number of which will grow. Changes in any hydramatrices repository class can crash in another pipeline (or even in the online part):
- Clickhouse overflows → Hive
- data preprocessing: Hive → Hive
- deploy c2c models: Hive → Redis
- preparation of directories (like the type of content monetization): Postgres → Redis
- model preparation: Local FS → HDFS
In such a situation, we really need a stand for automatic testing of pipelines in data preparation. This will greatly reduce the cost of testing changes in the repository, accelerate the rolling out of new models in production and dramatically increase the level of endorphins in testers. But without Airflow, it would be impossible to deploy a stand for this kind of auto test!
I wrote this article to talk about our experience in implementing Airflow, which may be useful to other teams in a similar situation - you already have a large working system, and you want to try something new, fashionable and youthful. No need to be afraid of any updates to the working system, you need to try and experiment - such experiments usually open new horizons for further development.