AERODISK Engine: Catastrophic. Part 1

Hello readers of Habr! The topic of this article will be the implementation of disaster tolerance in AERODISK Engine storage systems. Initially, we wanted to write in one article about both means: replication and the metro cluster, but, unfortunately, the article turned out to be too large, so we divided the article into two parts. Let's go from simple to complex. In this article we will configure and test synchronous replication - drop one data center, and also cut off the communication channel between the data centers and see what happens.
Our customers often ask us different questions about replication, therefore, before moving on to setting up and testing replica implementation, we will tell you a little about what replication is in storage systems.
Bit of theory
Replication to storage is an ongoing process of ensuring data identity across multiple storage systems simultaneously. Technically, replication is performed by two methods.
Synchronous replication is the copying of data from the main storage system to the backup one, followed by the obligatory confirmation of both storage systems that the data is recorded and confirmed. It is after confirmation from both sides (on both storage systems) that the data is considered recorded, and you can work with them. This ensures guaranteed data identity on all storage systems participating in the replica.
The advantages of this method:
- Data is always identical on all storage systems.
Minuses:
- High cost of the solution (fast communication channels, expensive fiber, long-wave transceivers, etc.)
- Distance restrictions (within a few tens of kilometers)
- There is no protection against logical data corruption (if the data is corrupted (knowingly or accidentally) on the main storage system, then it will automatically and immediately become corrupted on the backup storage, since the data is always identical (this is a paradox)
Asynchronous replication is also copying data from the main storage to the backup, but with a certain delay and without the need to confirm the record on the other side. You can work with data immediately after recording to the main storage system, and on the backup storage system data will be available after a while. The identity of the data in this case, of course, is not provided at all. Data on backup storage is always a bit "in the past."
Advantages of Asynchronous Replication:
- Low solution cost (any communication channels, optics optional)
- No distance limit
- Data on the backup storage is not corrupted if it is corrupted on the main (at least for some time), if the data has become corrupted, you can always stop the replica in order to prevent damage to the data on the backup storage
Minuses:
- Data in different data centers is always not identical
Thus, the choice of replication mode depends on the tasks of the business. If it is critical for you that the backup data center has exactly the same data as the main data (i.e. the business requirement for RPO = 0), you will have to fork out and put up with the limitations of synchronous replica. And if the delay in the state of the data is acceptable or there is simply no money, then, definitely, you need to use the asynchronous method.
We also separately distinguish such a regime (more precisely, already a topology) as a metro cluster. Metro cluster mode uses synchronous replication, but, unlike a regular replica, the metro cluster allows both storage systems to work in active mode. Those. you do not have a separation of active-standby data centers. Applications work simultaneously with two storage systems that are physically located in different data centers. Accident downtimes in this topology are very small (RTO, usually minutes). In this article, we will not consider our implementation of the metro cluster, since this is a very large and capacious topic, so we will devote a separate, following article to it in continuation of this.
Also very often, when we talk about replication using storage systems, many have a reasonable question:> “Many applications have their own replication tools, why use replication on storage systems? Is it better or worse? ”
There is no single answer, so here are the pros and cons:
Arguments FOR storage replication:
- The simplicity of the solution. In one way, you can replicate an entire array of data, regardless of load type or application. If you use a replica of applications, then you will have to configure each application separately. If there are more than 2 of them, then it is extremely time-consuming and expensive (application replication requires, as a rule, a separate and not free license for each application. But more on that below).
- You can replicate anything - any applications, any data - and they will always be consistent. Many (most) applications do not have replication facilities, and replicas from the storage side are the only way to provide protection against disasters.
- No need to overpay for application replication functionality. As a rule, it costs a lot, just like licenses for a replica storage system. But you need to pay for the storage replication license once, and you need to buy the license for application replica for each application separately. If there are a lot of such applications, then it costs a pretty penny and the cost of licenses for replication of storage becomes a drop in the bucket.
Arguments AGAINST storage replication:
- A replica using application tools has more functionality from the point of view of the applications themselves, the application knows its data better (which is obvious), so there are more options for working with them.
- Manufacturers of some applications do not guarantee the consistency of their data if replication is done by third-party tools. *
* - a controversial thesis. For example, a well-known DBMS manufacturing company, for a very long time officially stated that their DBMS can normally be replicated only by their means, and the rest of the replication (including SHD-shnaya) is “not true”. But life has shown that this is not so. Most likely (but this is not accurate) this is simply not the most honest attempt to sell more licenses to customers.
As a result, in most cases, replication from the storage side is better, because This is a simpler and less expensive option, but there are complex cases when you need specific application functionality, and you need to work with application level replication.
With theory finished, now practice
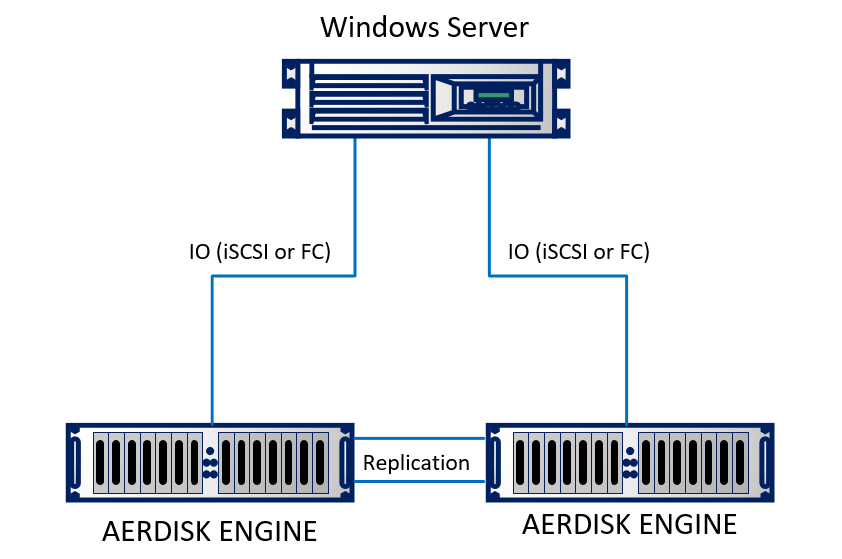
We will be setting up a replica in our lab. In the laboratory, we emulated two data centers (in fact, two stands next to each other, which seem to be in different buildings). The stand consists of two Engine N2 storage systems, which are interconnected by optical cables. A physical server running Windows Server 2016 using 10Gb Ethernet is connected to both storage systems. The stand is quite simple, but it does not change the essence.
Schematically, it looks like this:
Logically replication is organized as follows:
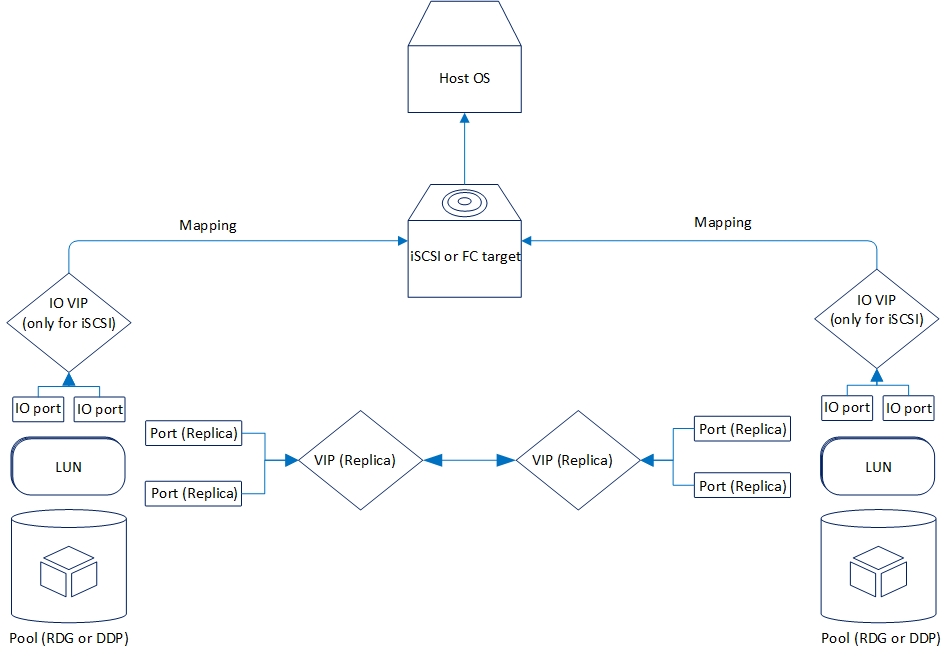
Now let's look at the replication functionality that we have now.
Two modes are supported: asynchronous and synchronous. It is logical that the synchronous mode is limited by the distance and the communication channel. In particular, synchronous mode requires the use of fiber as physics and 10 gigabit Ethernet (or higher).
The supported distance for synchronous replication is 40 kilometers, the delay of the optics channel between the data centers is up to 2 milliseconds. In general, it will work with large delays, but then there will be strong brakes when recording (which is also logical), so if you are considering synchronous replication between data centers, you should check the quality of the optics and delays.
Asynchronous replication requirements are not so serious. More precisely, they are not at all. Any working Ethernet connection is suitable.
At the moment, AERODISK ENGINE storage supports replication for block devices (LUNs) using the Ethernet protocol (copper or optics). For projects that necessarily require replication through the Fiber Channel SAN factory, we are now completing the appropriate solution, but so far it is not ready, so in our case only Ethernet.
Replication can work between any ENGINE series storage systems (N1, N2, N4) from lower systems to older and vice versa.
The functionality of both replication modes is completely identical. Below is more about what is:
- Replication "one to one" or "one to one", that is, the classic version with two data centers, the main and backup
- The replication is “one to many” or “one to many”, i.e. one LUN can be replicated to several storage systems at once
- Activation, deactivation and “reversal” of replication, respectively, to enable, disable or change the direction of replication
- Replication is available for both RDG (Raid Distributed Group) and DDP (Dynamic Disk Pool) pools. However, the RDG pool LUN can only be replicated to another RDG. C DDP is similar.
There are many more small features, but listing them does not make much sense, we will mention them during the setup.
Replication setup
The setup process is quite simple and consists of three stages.
- Network configuration
- Storage Setup
- Setting up rules (links) and mapping
An important point in configuring replication is that the first two stages should be repeated on a remote storage system, the third stage - only on the main one.
Network Resource Configuration
First of all, you need to configure the network ports through which replication traffic will be transmitted. To do this, you need to enable the ports and set IP addresses on them in the Front-end adapters section.
After that, we need to create a pool (in our case RDG) and a virtual IP for replication (VIP). VIP is a floating IP address that is tied to two “physical” addresses of storage controllers (the ports that we just configured). It will be the primary replication interface. You can also operate not with VIP, but with VLAN if you need to work with tagged traffic.
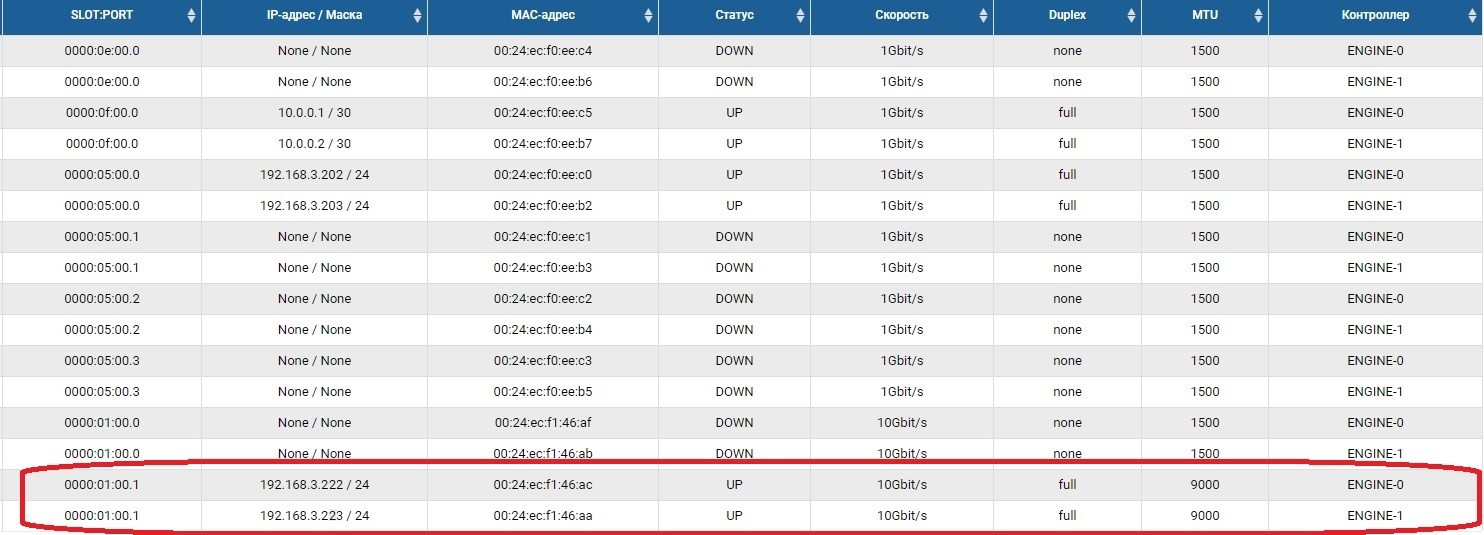
The process of creating a VIP for a replica is not much different from creating a VIP for I / O (NFS, SMB, iSCSI). In this case, we create a standard VIP (without VLAN), but we must indicate that it is for replication (without this pointer, we will not be able to add VIP to the rule in the next step).
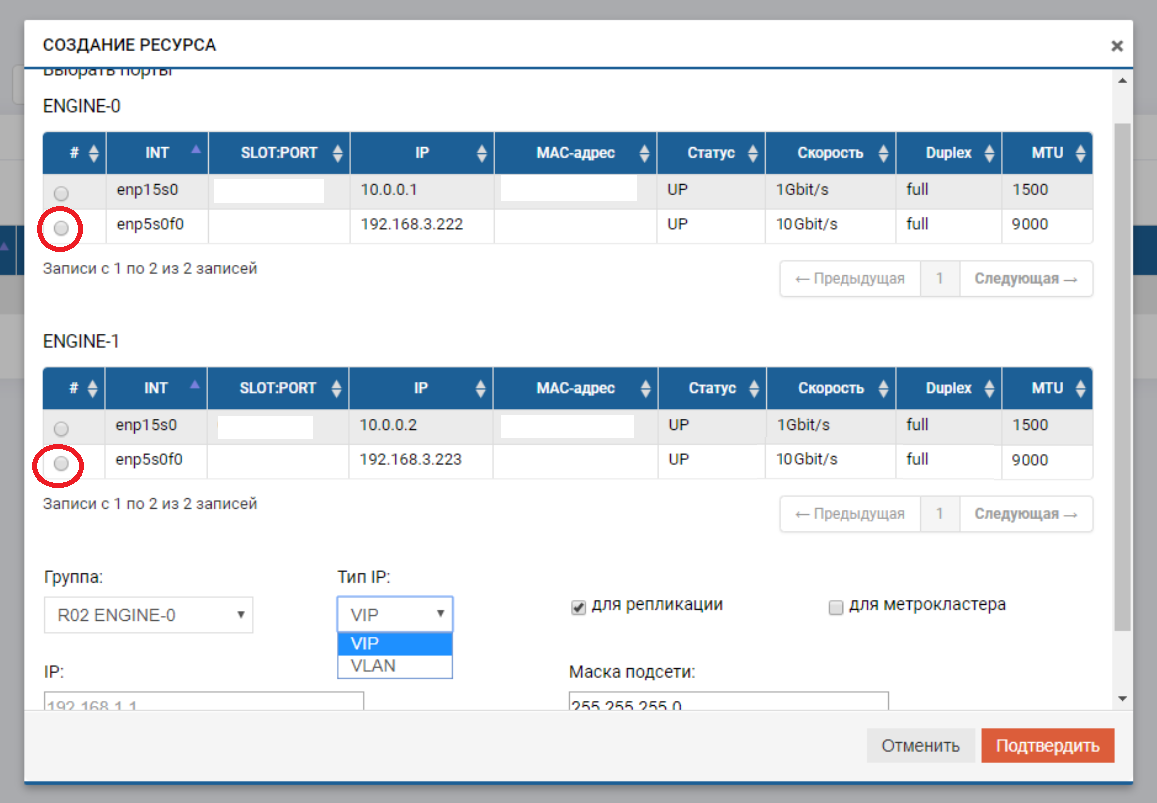
VIP must be on the same subnet as the IP ports between which it “floats”.

We repeat these settings on the remote storage system, with another IP-shnik, by itself.
VIPs from different storage systems can be in different subnets, the main thing is that there should be routing between them. In our case, this example is just shown (192.168.3.XX and 192.168.2.XX)

On this, the preparation of the network part is completed.
Configure storage
Configuring storage for a replica differs from the usual one only in that we do mapping through the special menu “Replication mapping”. Otherwise, everything is the same as with the usual setting. Now in order.
In the previously created R02 pool, you need to create a LUN. Create, call it LUN1.
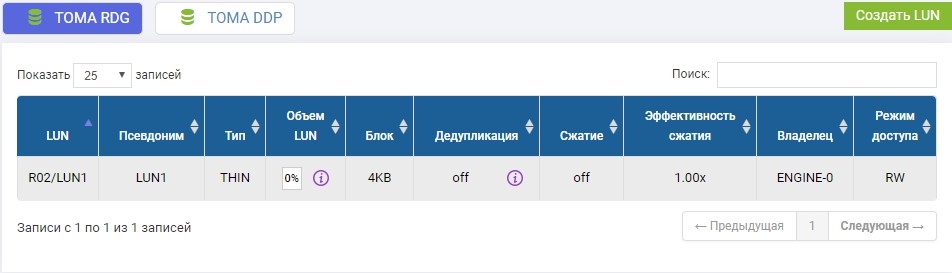
We also need to create the same LUN on a remote storage system of identical volume. We create. To avoid confusion, the remote LUN will be called LUN1R
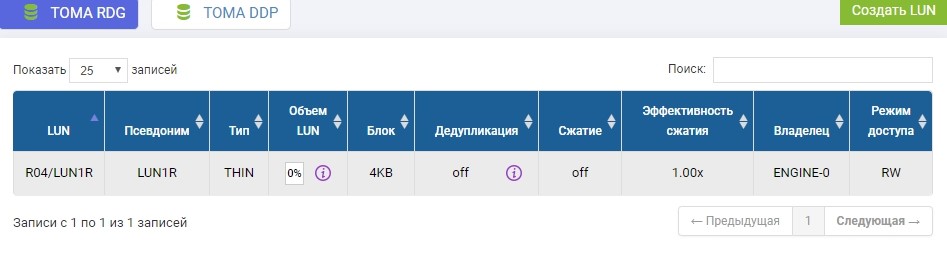
If we needed to take a LUN that already exists, then at the time of replica setup, this productive LUN would need to be unmounted from the host, and on the remote storage system simply create an empty LUN of identical size.
The storage setup is completed, we proceed to the creation of the replication rule.
Configure replication rules or replication links
After creating LUNs on the storage, which will be the primary one at the moment, we configure the replication rule LUN1 on SHD1 in LUN1R on SHD2.
Setup is done in the Remote Replication menu
Create a rule. To do this, specify the replica recipient. We also specify the name of the connection and the type of replication (synchronous or asynchronous).
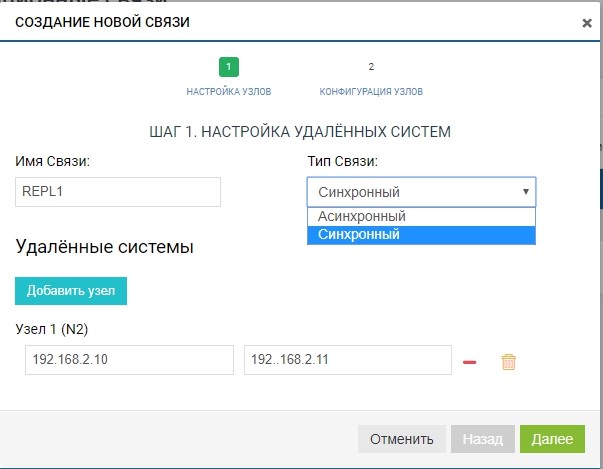
In the “remote systems” field, add our SHD2. To add, you need to use the managing IP storage (MGR) and the name of the remote LUN to which we will replicate (in our case, LUN1R). Managing IPs are needed only at the stage of adding communication; replication traffic through them will not be transmitted; for this, the previously configured VIP will be used.
Already at this stage, we can add more than one remote system for the “one to many” topology: click the “add node” button, as in the figure below.
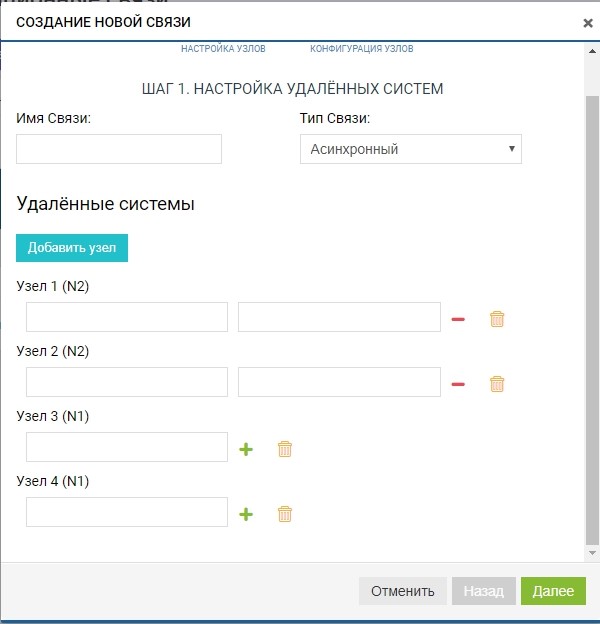
In our case, the remote system is one, so we are limited to this.
The rule is ready. Note that it is automatically added to all replication participants (in our case, there are two of them). You can create such rules as many as you like, for any number of LUNs and in any direction. For example, to balance the load, we can replicate part of the LUNs from SHD1 to SHD2, and the other part, on the contrary, from SHD2 to SHD1.
SHD1. Immediately after creation, synchronization began.
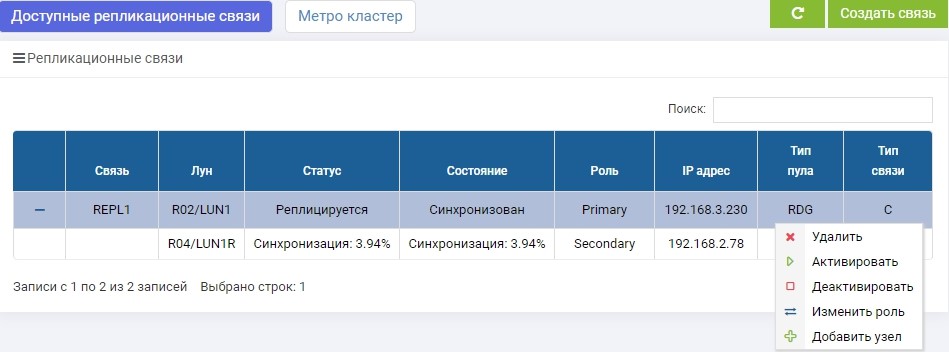
SHD2. We see the same rule, but the synchronization has already ended.
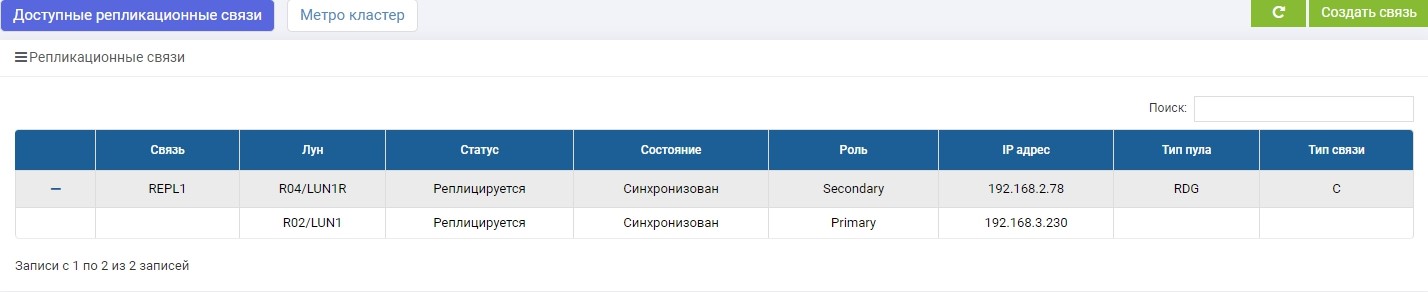
LUN1 on SHD1 is in the role of Primary, that is, it is active. LUN1R on SHD2 is in the role of Secondary, that is, it is on the hook in case of failure of SHD1.
Now we can connect our LUN to the host.
We will do the connection via iSCSI, although it can be done via FC. Configuring mapping via iSCSI LUN in the replica is practically no different from the usual scenario, so we will not consider this in detail here. If anything, this process is described in the Quick Setup article .
The only difference is that we create mapping in the “Replication mapping” menu.
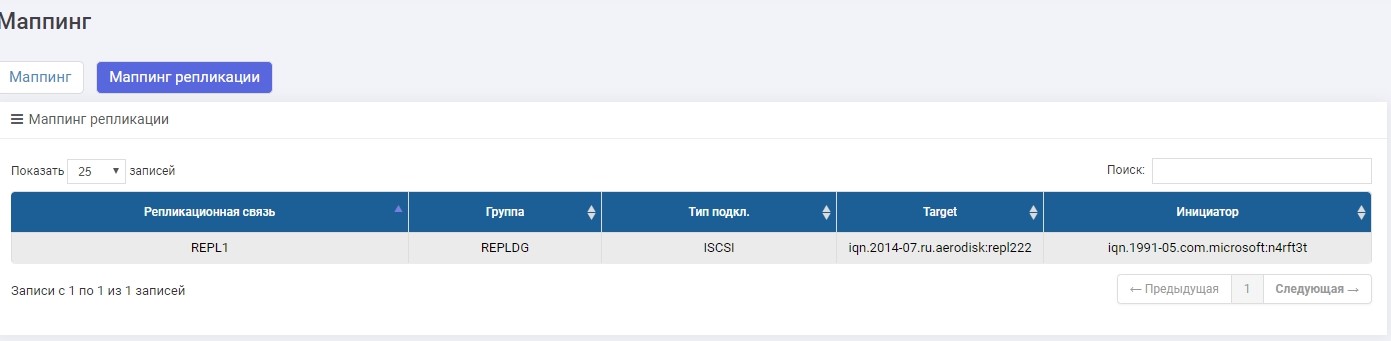
Set up mapping, give LUN to the host. The host saw a LUN.
Format it to the local file system.
That's it, the setup is complete. Next will go tests.
Testing
We will test three main scenarios.
- Staff Role Switching Secondary> Primary. A regular role switching is necessary in case, for example, we mainly need a data center to perform some preventive operations, and for this time, so that the data is available, we transfer the load to the backup data center.
- Failover of roles Secondary> Primary (data center failure). This is the main scenario for which there is replication, which can help to survive a complete data center failure without stopping the company for a long time.
- Broken communication channels between data centers. Checking the correct behavior of two storage systems under conditions when for some reason the communication channel between the data centers is unavailable (for example, the excavator dug in the wrong place and tore through the dark optics).
To begin with, we will begin to write data to our LUN (we write files with random data). We immediately see that the communication channel between the storage systems is being utilized. This is easy to understand if you open load monitoring of the ports that are responsible for replication.
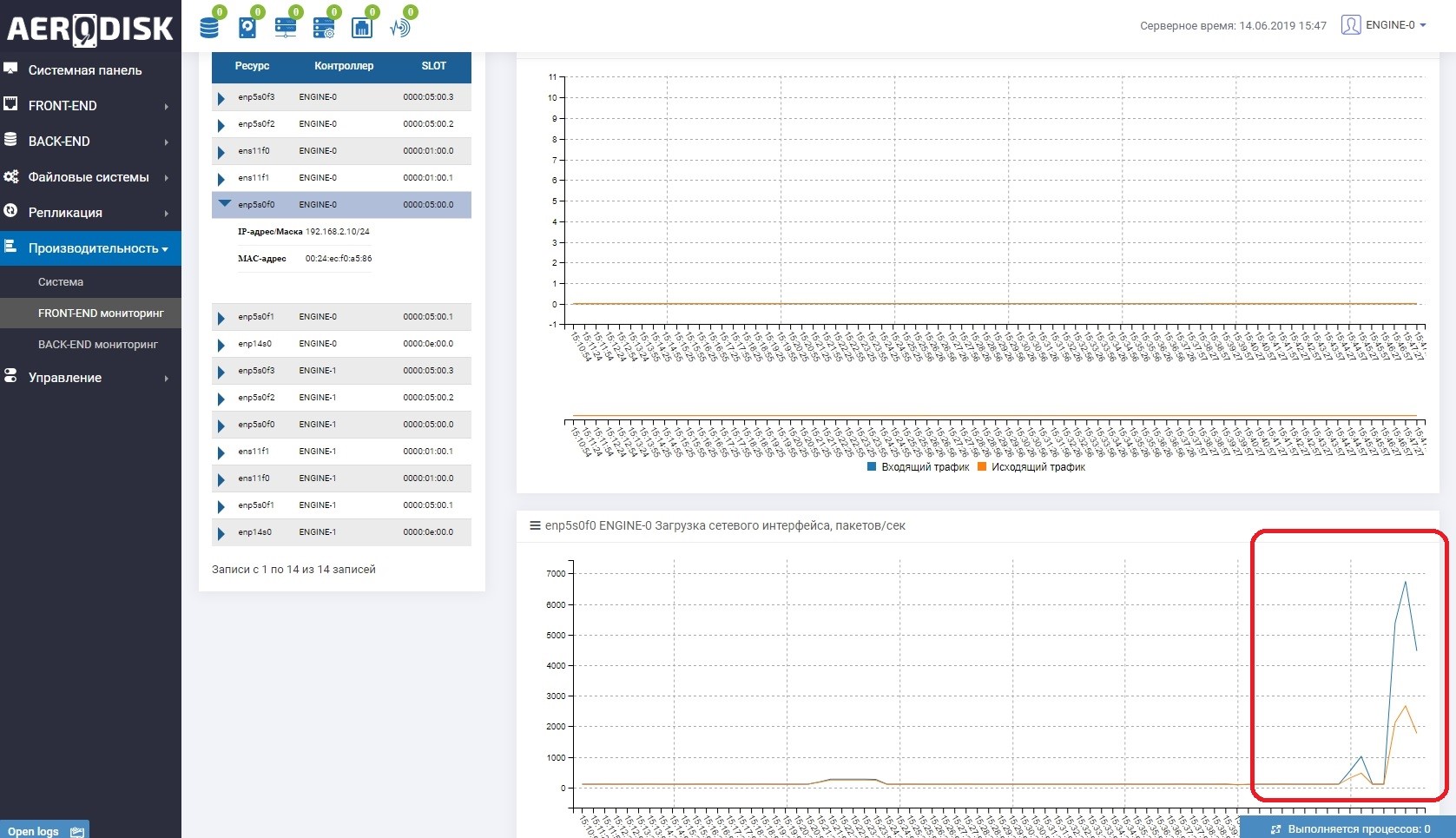
On both storage systems there is now “useful” data, we can start the test.
![]()
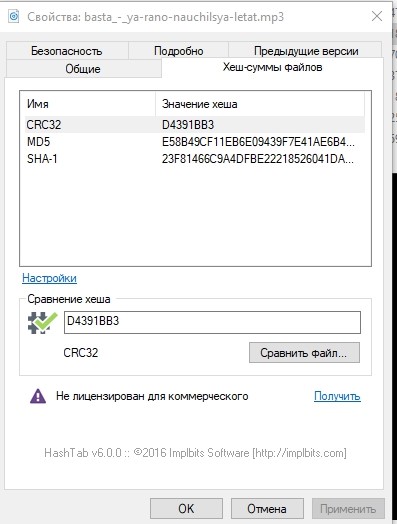
Just in case, let's look at the hash sums of one of the files and write it down.
Staff Role Switching
The operation of switching roles (changing the direction of replication) can be done from any storage system, but you still need to go to both, since you will need to disable mapping on Primary, and enable it on Secondary (which will become Primary).
Perhaps now a reasonable question arises: why not automate this? We answer: everything is simple, replication is a simple disaster tolerance tool based solely on manual operations. To automate these operations, there is a metro cluster mode, it is fully automated, but its configuration is much more complicated. We will write about setting up the metro cluster in the next article.
Disable mapping on the main storage to ensure that recording is stopped.
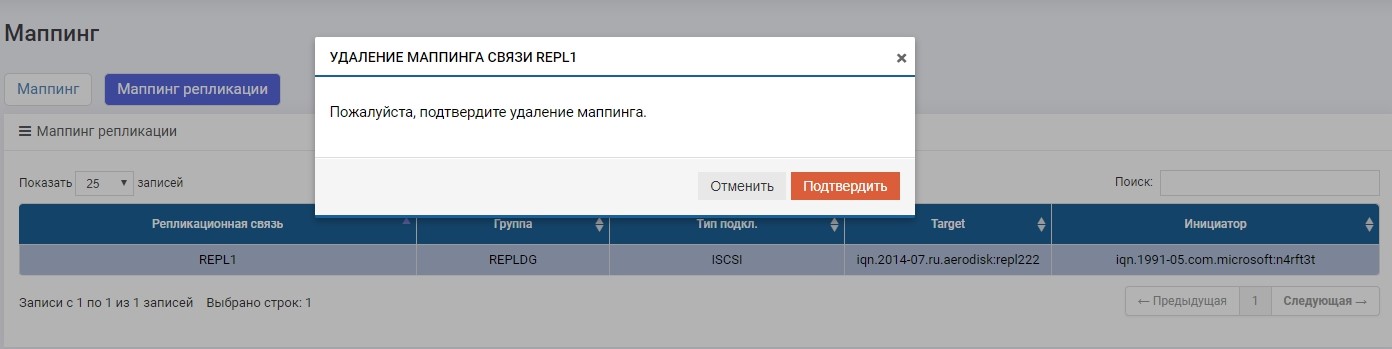
Then on one of the storage systems (it doesn’t matter, on the primary or backup) in the Remote Replication menu, select our REPL1 connection and click on “Change Role”.
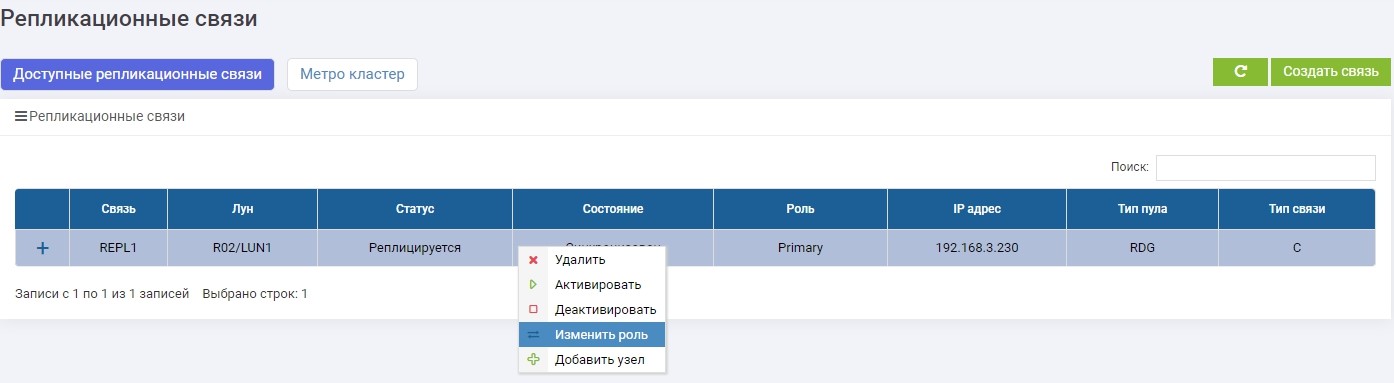
After a few seconds, LUN1R (backup storage) becomes Primary.
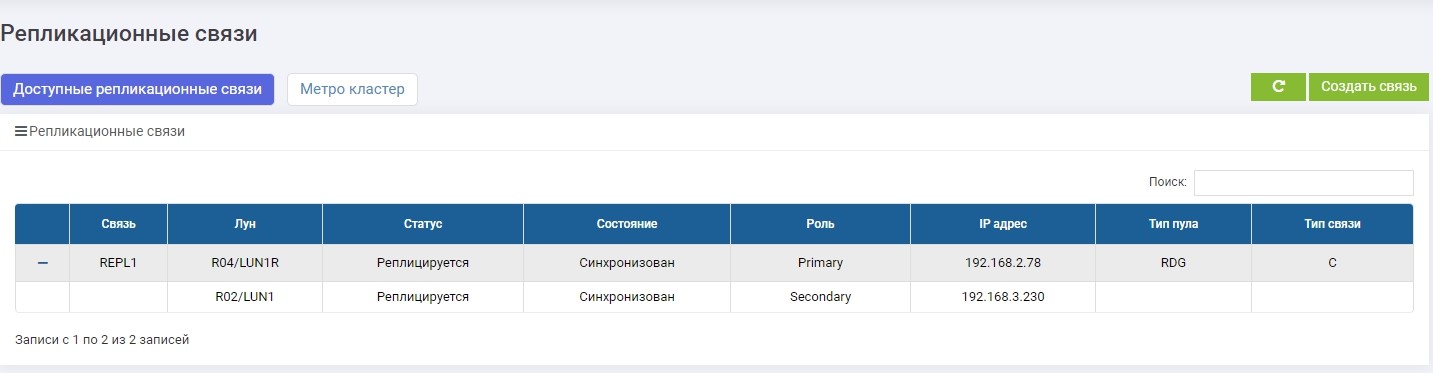
We make mapping LUN1R with SHD2.
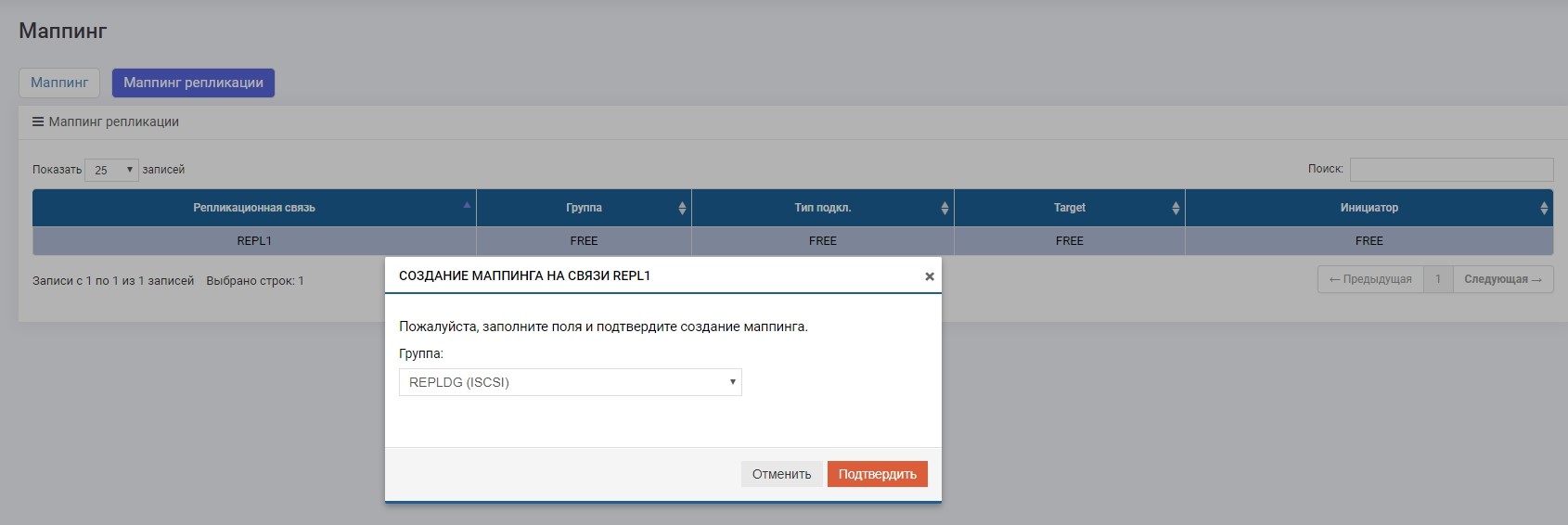
After that, our E: drive automatically clings to the host, only this time it “flew” with LUN1R.
Just in case, compare the hash amounts.
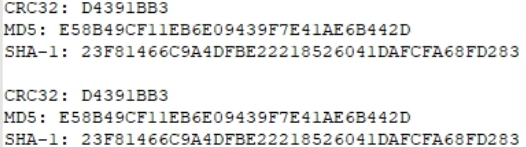
Identically. Test passed.
Failover Data Center Failure
At the moment, the main storage after regular switching is storage 2 and LUN1R, respectively. To simulate an accident, we turn off the power on both controllers SHD2.
Access to it is no more.
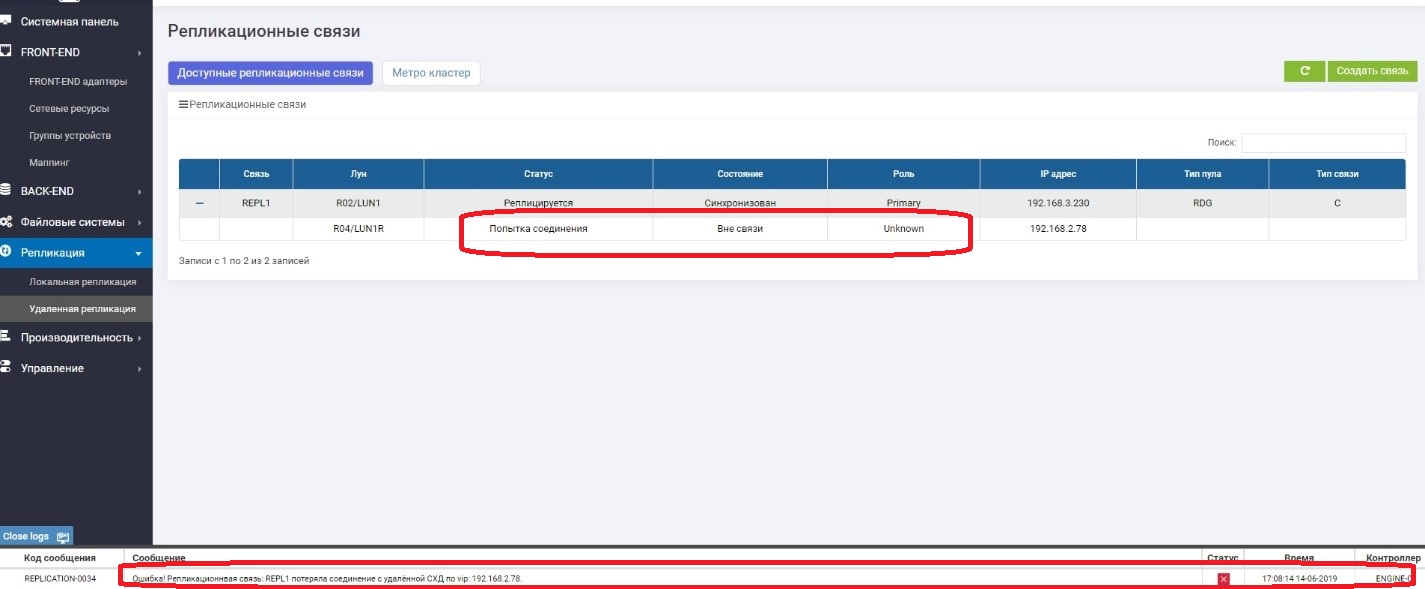
We look at what is happening on the storage 1 (backup at the moment).

We see that the Primary LUN (LUN1R) is not available. An error message appeared in the logs, in the information panel, as well as in the replication rule itself. Accordingly, data from the host is currently unavailable.
Change the role of LUN1 to Primary.
Affairs mapping to the host.

Make sure drive E appears on the host.
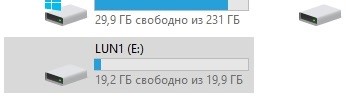
Check the hash.
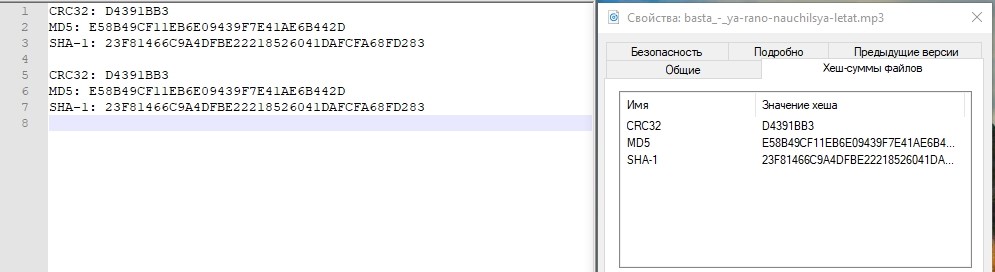
Everything is good. The storage center experienced a fall in the data center, which was active. The approximate time that we spent on connecting the “reversal” of replication and connecting the LUN from the backup data center was about 3 minutes. It is clear that in the real product everything is much more complicated, and in addition to actions with storage systems, you need to perform many more operations on the network, on hosts, in applications. And in life this period of time will be much longer.
Here I want to write that everything, the test was completed successfully, but let's not rush. The main storage "lies", we know that when she "fell", she was in the role of Primary. What happens if she suddenly turns on? There will be two Primary roles, which is equal to data corruption? We’ll check it now.
We are suddenly going to turn on the underlying storage.
It boots up for several minutes and after that it returns to operation after a short synchronization, but already in the role of Secondary.

All OK. Split brain didn’t happen. We thought about it, and always after the fall of the storage system rises in the role of Secondary, regardless of what role it was "in life". Now we can say for sure that the data center failure test was successful.
Failure of communication channels between data centers
The main task of this test is to make sure that the storage system will not start to freak out if it temporarily lost the communication channels between the two storage systems and then reappears.
So. We disconnect the wires between the storage systems (imagine that an excavator dug them).
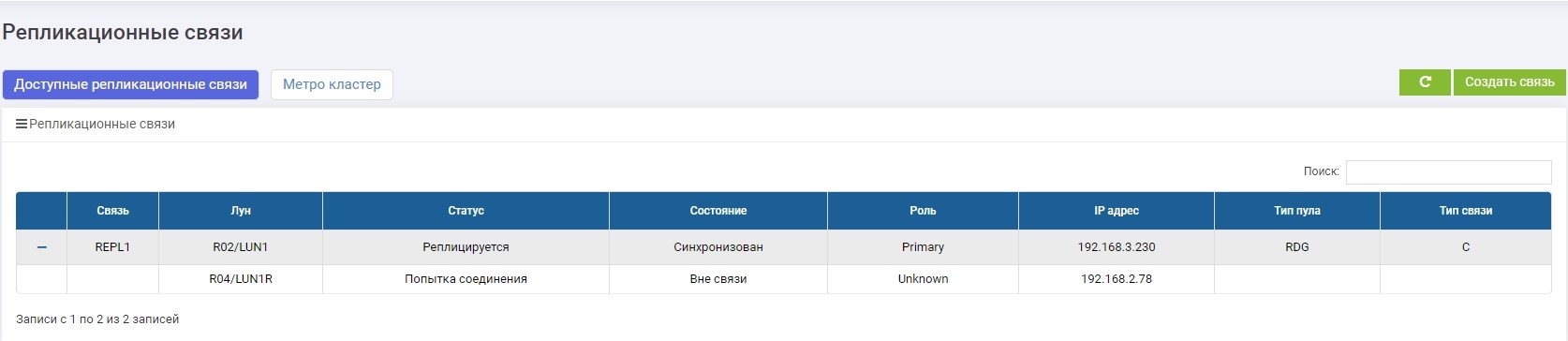
On Primary we see that there is no connection with Secondary.
On Secondary, we see that there is no connection with Primary.
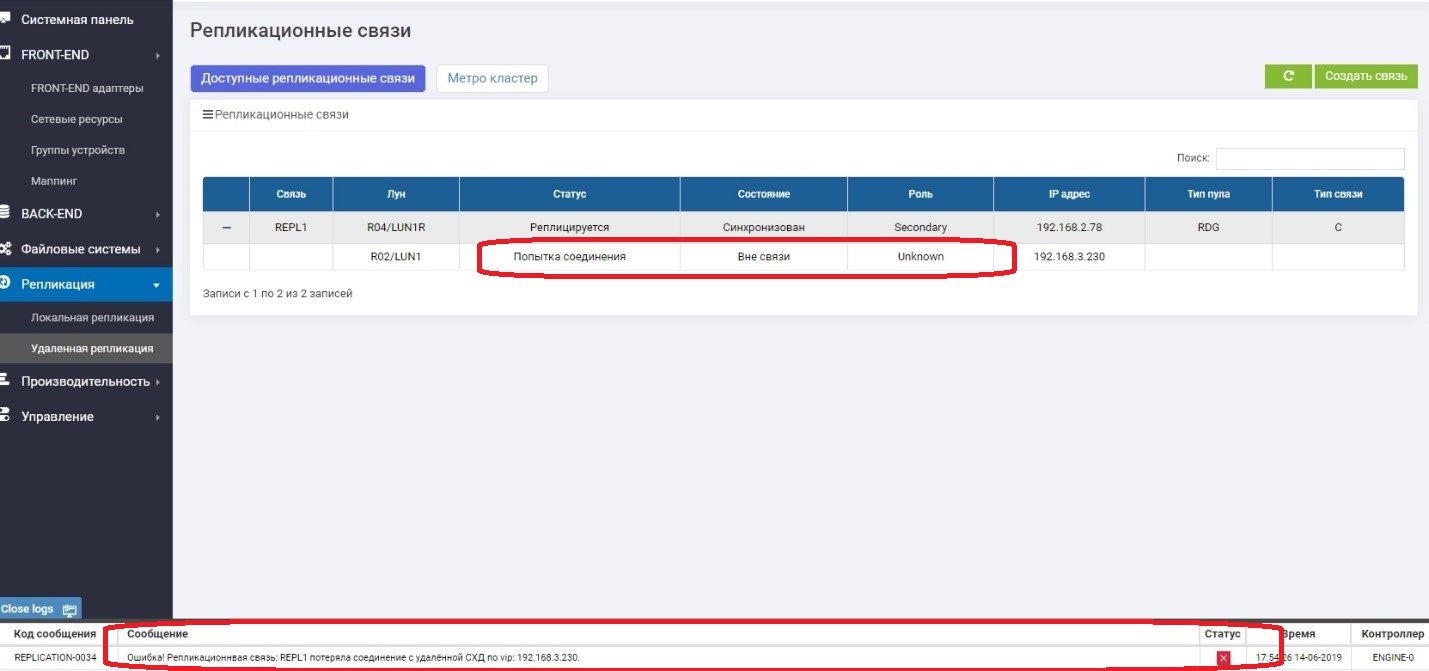
Everything works fine, and we continue to write data to the main storage system, that is, they are already guaranteed to differ from the backup one, that is, they have "left".
In a few minutes we’re fixing the communication channel. As soon as the storage systems have seen each other, data synchronization is automatically turned on. There is nothing required from the administrator.

After a while, the synchronization ends.
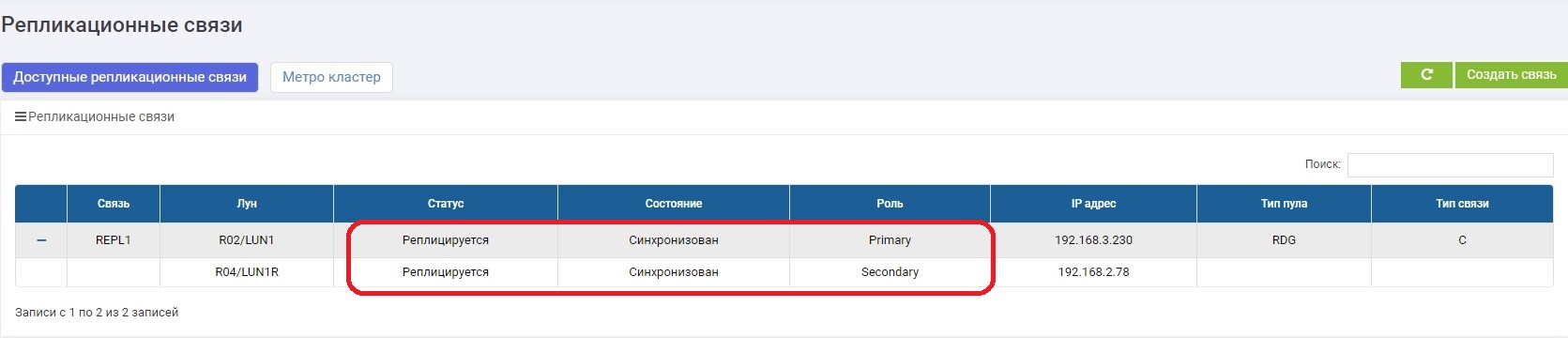
The connection was restored, the connection channels did not cause any emergency situations, and after switching on, synchronization automatically took place.
findings
We examined the theory - what and why is needed, where are the pros and cons. Then we set up synchronous replication between the two storage systems.
Then, the main tests were conducted for regular switching, data center failure and a break in communication channels. In all cases, storage worked well. There is no data loss, administrative operations are minimized for a manual scenario.
Next time we will complicate the situation and show how all this logic works in the automated metro cluster in active-active mode, that is, when both storage systems are the main ones, and the behavior in case of storage failure is fully automated.
Please write comments, we will be glad to sound criticism and practical advice.
Until we meet again.