Linux network application performance. Introduction
- Transfer
Web applications are now widely used, and HTTP is the lion's share of all transport protocols. Studying the nuances of developing web applications, most of them pay very little attention to the operating system where these applications actually run. The separation of development (Dev) and operation (Ops) only made matters worse. But with the spread of the DevOps culture, developers begin to take responsibility for launching their applications in the cloud, so it’s very useful for them to thoroughly get acquainted with the operating system backend. This is especially useful if you are trying to deploy a system for thousands or tens of thousands of concurrent connections.
Limitations in web services are very similar to limitations in other applications. Be it load balancers or database servers, all of these applications have similar problems in a high-performance environment. Understanding these fundamental limitations and how to overcome them in general will help you evaluate the performance and scalability of your web applications.
I am writing this series of articles in response to questions from young developers who want to become well-informed system architects. It is impossible to clearly understand the methods of optimizing Linux applications without diving into the basics of how they work at the operating system level. Although there are many types of applications, in this series I want to explore network applications, not desktop ones such as a browser or text editor. This material is intended for developers and architects who want to understand how Linux or Unix programs work and how to structure them for high performance.
Linux is serveroperating system, and most often your applications run on this particular OS. Although I say “Linux,” most of the time you can safely assume that all Unix-like operating systems in general are meant. However, I have not tested the accompanying code on other systems. So, if you are interested in FreeBSD or OpenBSD, the result may vary. When I try something Linux-specific, I point it out.
Although you can use this knowledge to create an application from scratch, and it will be perfectly optimized, it’s better not to. If you write a new web server in C or C ++ for your organization’s business application, this may be your last day at work. However, knowledge of the structure of these applications will help in the selection of existing programs. You can compare process-based systems with thread-based and event-based systems. You will understand and appreciate why Nginx works better than Apache httpd, why a Tornado-based Python application can serve more users than a Django-based Python application.
ZeroHTTPd is a web server that I wrote from scratch in C as a training tool. It has no external dependencies, including access to Redis. We run our own Redis routines. See below for more details.
Although we could discuss the theory for a long time, there is nothing better than writing code, running it, and comparing all server architectures together. This is the most obvious method. Therefore, we will write a simple ZeroHTTPd web server using each model: based on processes, threads and events. Let's check each of these servers and see how they work in comparison with each other. ZeroHTTPd is implemented in a single C file. Event-based server includes uthash, a great hash table implementation that comes in a single header file. In other cases, there are no dependencies, so as not to complicate the project.
There are a lot of comments in the code to help sort it out. Being a simple web server in a few lines of code, ZeroHTTPd is also a minimal web development framework. It has limited functionality, but it is able to produce static files and very simple “dynamic” pages. I must say that ZeroHTTPd is well suited for learning how to create high-performance Linux applications. By and large, most web services wait for requests, check them and process them. This is exactly what ZeroHTTPd will do. This is a learning tool, not a production tool. He is not good at handling errors and is unlikely to boast of the best security practices (oh yes, I used it
ZeroHTTPd homepage. It can produce different types of files, including images
Modern web applications are usually not limited to static files. They have complex interactions with various databases, caches, etc. Therefore, we will create a simple web application called “Guestbook”, where visitors leave entries under their names. The guestbook saves the entries left previously. There is also a visitor counter at the bottom of the page.
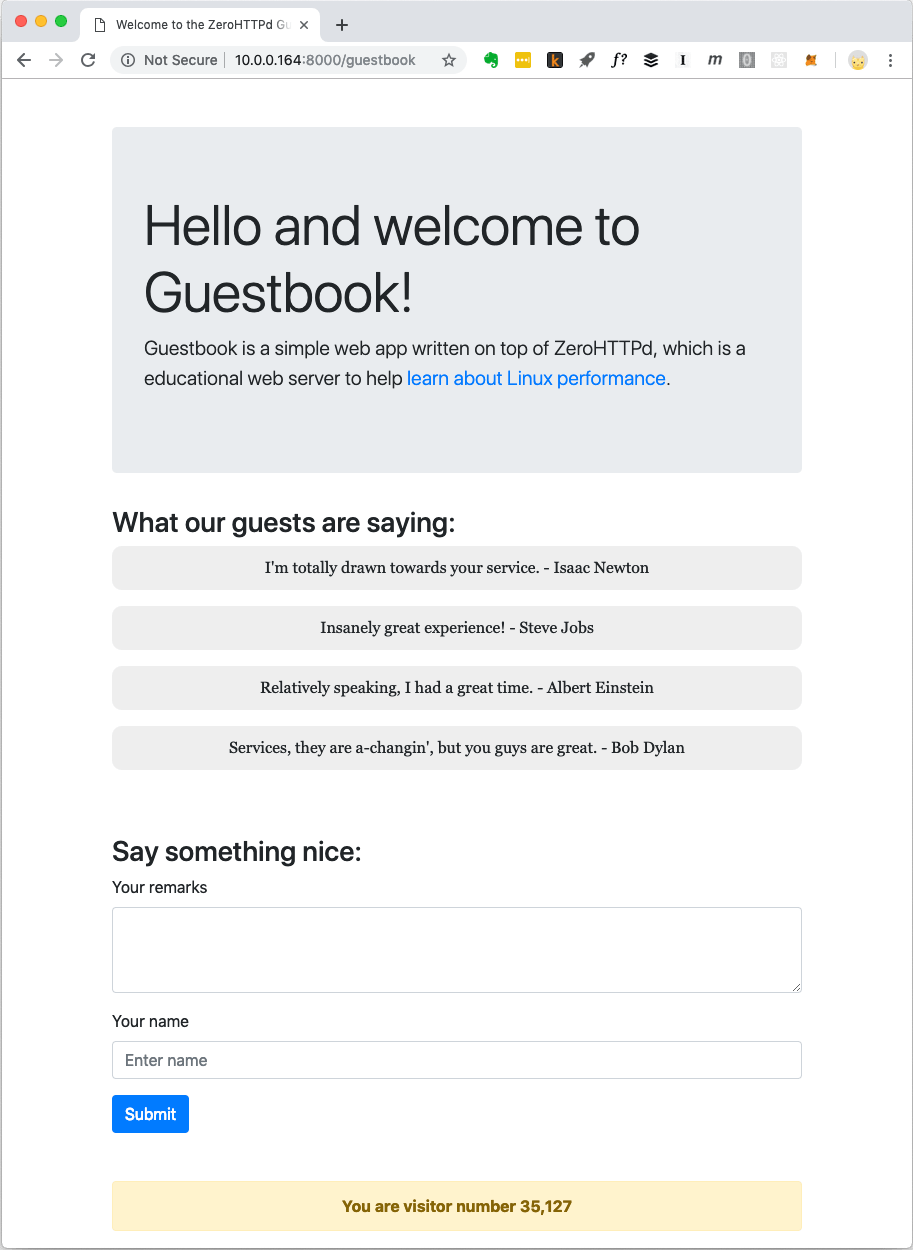
Guest Book Web Application ZeroHTTPd
The visitor counter and guest book entries are stored in Redis. For communication with Redis, own procedures are implemented; they are independent of an external library. I am not a big fan of rolling home-grown code when there are publicly available and well-tested solutions. But the goal of ZeroHTTPd is to study Linux performance and access to external services, while serving HTTP requests seriously affects performance. We must fully control communications with Redis in each of our server architectures. In one architecture, we use blocking calls, in others we use event-based procedures. Using an external Redis client library will not give such control. In addition, our little Redis client performs only a few functions (getting, setting, and increasing a key; getting and adding to an array). Also, Redis protocol is exceptionally elegant and simple. He does not even need to be specially taught. The fact that the protocol performs all the work in about a hundred lines of code indicates how well thought out it is.
The following figure shows the actions of the application when the client (browser) requests

The mechanism of the guestbook application
When you need to issue a guestbook page, there is one call to the file system to read the template into memory and three network calls to Redis. The template file contains most of the HTML content for the page in the screenshot above. There are also special placeholders for the dynamic part of the content: records and visitors counter. We get them from Redis, insert them on the page and give the client fully formed content. A third call to Redis can be avoided because Redis returns a new key value when incremented. However, for our server with an asynchronous event-based architecture, many network calls are a good test for training purposes. Thus, we discard the return value of Redis about the number of visitors and request it in a separate call.
We are building seven versions of ZeroHTTPd with the same functionality but different architectures:
We measure the performance of each architecture by loading the server with HTTP requests. But when comparing architectures with a high degree of parallelism, the number of requests increases. We test three times and consider the average.
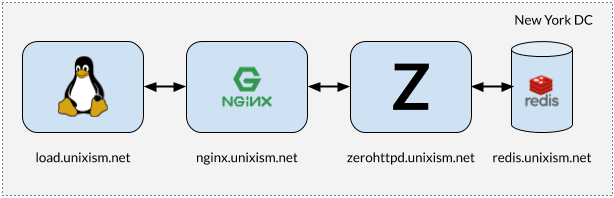
Installation for stress testing ZeroHTTPd
It is important that when testing all components do not work on the same machine. In this case, the OS carries additional planning overhead, since the components compete for the CPU. Measuring the operating system overhead from each of the selected server architectures is one of the most important goals of this exercise. Adding more variables will be detrimental to the process. Therefore, the setting in the figure above works best.
All servers run on a single processor core. The idea is to evaluate the maximum performance of each architecture. Since all server programs are tested on the same hardware, this is the basic level for comparing them. My test setup consists of virtual servers rented from Digital Ocean.
You can measure different indicators. We evaluate the performance of each architecture in this configuration, loading servers with requests at different levels of concurrency: the load grows from 20 to 15,000 concurrent users.
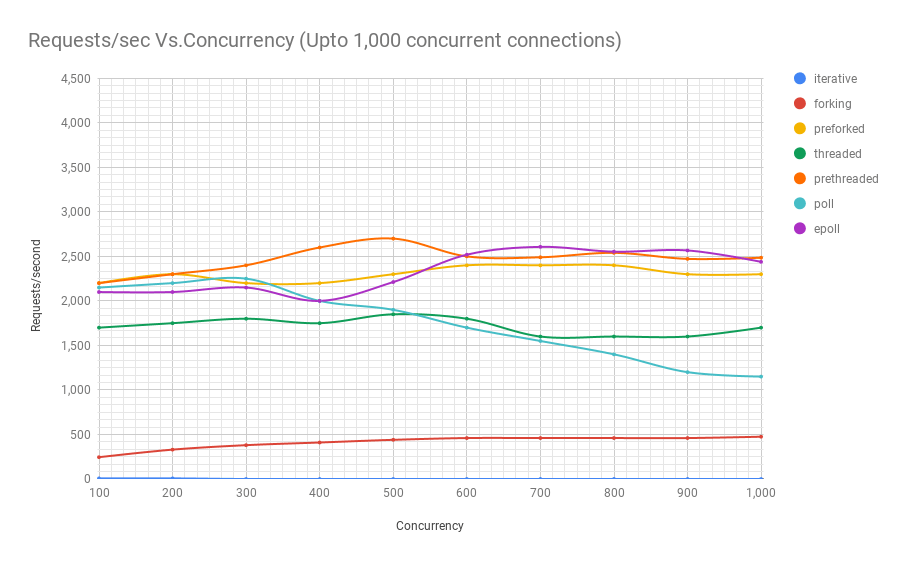
The following diagram shows the performance of servers on different architectures at different levels of concurrency. The y-axis is the number of requests per second, the x-axis is parallel connections.
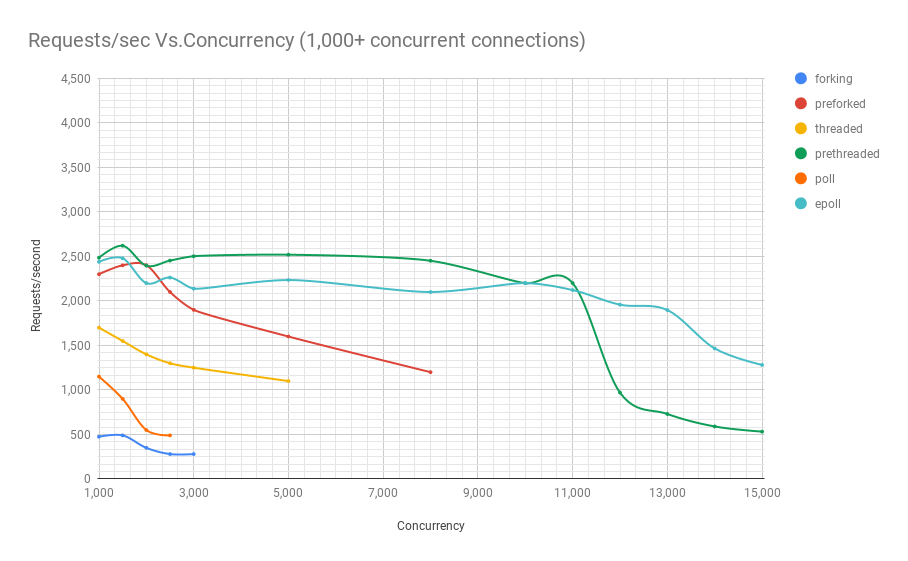
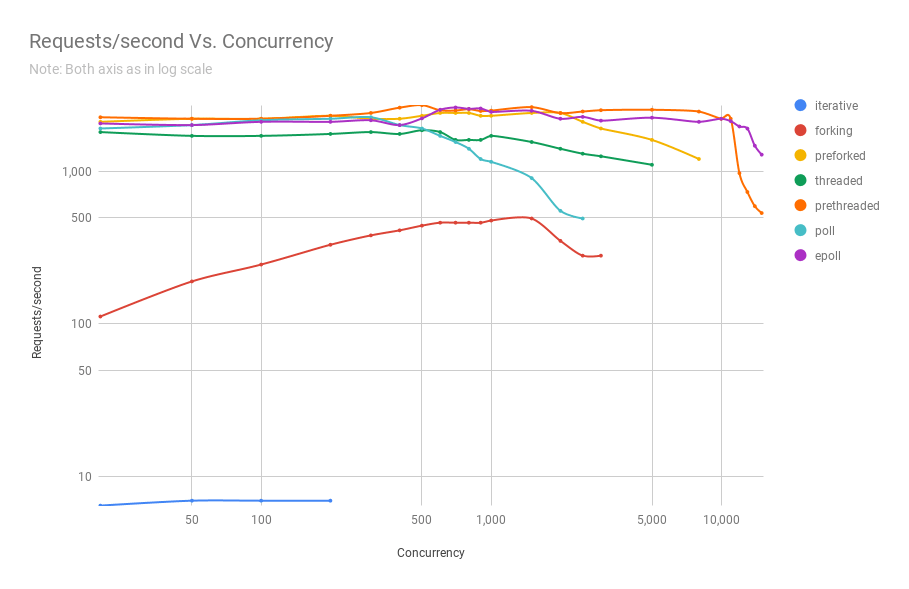
Below is a table with the results.
It can be seen from the graph and table that above 8000 simultaneous requests, we have only two players left: pre-fork and epoll. As the load grows, the poll-based server performs worse than streaming. Pre-threading architecture competes with epoll: this is evidence of how well the Linux kernel plans a large number of threads.
The source code for ZeroHTTPd is here . Each architecture has a separate directory.
In addition to seven directories for all architectures, there are two more in the top-level directory: public and templates. The first one contains the index.html file and the image from the first screenshot. Other files and folders can be placed there, and ZeroHTTPd should issue these static files without problems. If the path in the browser matches the path in the public folder, then ZeroHTTPd looks for the index.html file in this directory. Guestbook content is generated dynamically. It has only the main page, and its contents are based on the file 'templates / guestbook / index.html'. ZeroHTTPd easily adds dynamic pages for expansion. The idea is that users can add templates to this directory and extend ZeroHTTPd as needed.
To build all seven servers, run
To understand the information in this series of articles, it is not necessary to be well versed in the Linux API. However, I recommend reading more on this topic, there are a lot of reference resources on the Web. Although we will cover several categories of Linux APIs, our focus will be mainly on processes, threads, events, and the network stack. In addition to books and articles about the Linux API, I also recommend reading mana for system calls and library functions used.
One note on performance and scalability. Theoretically, there is no connection between them. You may have a web service that works very well, with a response time of a few milliseconds, but it does not scale at all. Similarly, there might be a poorly running web application that takes a few seconds to respond, but it scales to tens to handle tens of thousands of concurrent users. However, the combination of high performance and scalability is a very powerful combination. High-performance applications generally use resources economically and thus effectively serve more concurrent users on the server, reducing costs.
Finally, there are always two possible types of tasks in computing: for I / O and CPU. Receiving requests via the Internet (network I / O), file maintenance (network and disk I / O), communication with the database (network and disk I / O) are all I / O actions. Some database queries can load the CPU a bit (sorting, calculating the average of a million results, etc.). Most web applications are limited by the maximum possible I / O, and the processor is rarely used at full capacity. When you see that some CPU uses a lot of CPUs, this is most likely a sign of poor application architecture. This may mean that CPU resources are spent on process control and context switching - and this is not entirely useful. If you do something like image processing, converting audio files or machine learning, then the application requires powerful CPU resources. But for most applications this is not so.
Limitations in web services are very similar to limitations in other applications. Be it load balancers or database servers, all of these applications have similar problems in a high-performance environment. Understanding these fundamental limitations and how to overcome them in general will help you evaluate the performance and scalability of your web applications.
I am writing this series of articles in response to questions from young developers who want to become well-informed system architects. It is impossible to clearly understand the methods of optimizing Linux applications without diving into the basics of how they work at the operating system level. Although there are many types of applications, in this series I want to explore network applications, not desktop ones such as a browser or text editor. This material is intended for developers and architects who want to understand how Linux or Unix programs work and how to structure them for high performance.
Linux is serveroperating system, and most often your applications run on this particular OS. Although I say “Linux,” most of the time you can safely assume that all Unix-like operating systems in general are meant. However, I have not tested the accompanying code on other systems. So, if you are interested in FreeBSD or OpenBSD, the result may vary. When I try something Linux-specific, I point it out.
Although you can use this knowledge to create an application from scratch, and it will be perfectly optimized, it’s better not to. If you write a new web server in C or C ++ for your organization’s business application, this may be your last day at work. However, knowledge of the structure of these applications will help in the selection of existing programs. You can compare process-based systems with thread-based and event-based systems. You will understand and appreciate why Nginx works better than Apache httpd, why a Tornado-based Python application can serve more users than a Django-based Python application.
ZeroHTTPd: Learning Tool
ZeroHTTPd is a web server that I wrote from scratch in C as a training tool. It has no external dependencies, including access to Redis. We run our own Redis routines. See below for more details.
Although we could discuss the theory for a long time, there is nothing better than writing code, running it, and comparing all server architectures together. This is the most obvious method. Therefore, we will write a simple ZeroHTTPd web server using each model: based on processes, threads and events. Let's check each of these servers and see how they work in comparison with each other. ZeroHTTPd is implemented in a single C file. Event-based server includes uthash, a great hash table implementation that comes in a single header file. In other cases, there are no dependencies, so as not to complicate the project.
There are a lot of comments in the code to help sort it out. Being a simple web server in a few lines of code, ZeroHTTPd is also a minimal web development framework. It has limited functionality, but it is able to produce static files and very simple “dynamic” pages. I must say that ZeroHTTPd is well suited for learning how to create high-performance Linux applications. By and large, most web services wait for requests, check them and process them. This is exactly what ZeroHTTPd will do. This is a learning tool, not a production tool. He is not good at handling errors and is unlikely to boast of the best security practices (oh yes, I used it
strcpy) or C's abstruse tricks. But I hope he does his job well.ZeroHTTPd homepage. It can produce different types of files, including images
Guest Book Application
Modern web applications are usually not limited to static files. They have complex interactions with various databases, caches, etc. Therefore, we will create a simple web application called “Guestbook”, where visitors leave entries under their names. The guestbook saves the entries left previously. There is also a visitor counter at the bottom of the page.
Guest Book Web Application ZeroHTTPd
The visitor counter and guest book entries are stored in Redis. For communication with Redis, own procedures are implemented; they are independent of an external library. I am not a big fan of rolling home-grown code when there are publicly available and well-tested solutions. But the goal of ZeroHTTPd is to study Linux performance and access to external services, while serving HTTP requests seriously affects performance. We must fully control communications with Redis in each of our server architectures. In one architecture, we use blocking calls, in others we use event-based procedures. Using an external Redis client library will not give such control. In addition, our little Redis client performs only a few functions (getting, setting, and increasing a key; getting and adding to an array). Also, Redis protocol is exceptionally elegant and simple. He does not even need to be specially taught. The fact that the protocol performs all the work in about a hundred lines of code indicates how well thought out it is.
The following figure shows the actions of the application when the client (browser) requests
/guestbookURL. The mechanism of the guestbook application
When you need to issue a guestbook page, there is one call to the file system to read the template into memory and three network calls to Redis. The template file contains most of the HTML content for the page in the screenshot above. There are also special placeholders for the dynamic part of the content: records and visitors counter. We get them from Redis, insert them on the page and give the client fully formed content. A third call to Redis can be avoided because Redis returns a new key value when incremented. However, for our server with an asynchronous event-based architecture, many network calls are a good test for training purposes. Thus, we discard the return value of Redis about the number of visitors and request it in a separate call.
ZeroHTTPd Server Architectures
We are building seven versions of ZeroHTTPd with the same functionality but different architectures:
- Iterative
- Fork server (one child process per request)
- Pre-fork server (pre-forking processes)
- Server with threads (one thread per request)
- Server with pre-threading
- Based architecture
poll() - Based architecture
epoll
We measure the performance of each architecture by loading the server with HTTP requests. But when comparing architectures with a high degree of parallelism, the number of requests increases. We test three times and consider the average.
Test methodology
Installation for stress testing ZeroHTTPd
It is important that when testing all components do not work on the same machine. In this case, the OS carries additional planning overhead, since the components compete for the CPU. Measuring the operating system overhead from each of the selected server architectures is one of the most important goals of this exercise. Adding more variables will be detrimental to the process. Therefore, the setting in the figure above works best.
What each of these servers does
- load.unixism.net: here we run the
abApache Benchmark utility. It generates the load necessary to test our server architectures. - nginx.unixism.net: sometimes we want to run more than one instance of a server program. For this, the Nginx server with the appropriate settings works as a load balancer coming from ab to our server processes.
- zerohttpd.unixism.net: here we run our server programs on seven different architectures, one at a time.
- redis.unixism.net: the Redis daemon is running on this server, where entries are stored in the guest book and the counter of visitors.
All servers run on a single processor core. The idea is to evaluate the maximum performance of each architecture. Since all server programs are tested on the same hardware, this is the basic level for comparing them. My test setup consists of virtual servers rented from Digital Ocean.
What are we measuring?
You can measure different indicators. We evaluate the performance of each architecture in this configuration, loading servers with requests at different levels of concurrency: the load grows from 20 to 15,000 concurrent users.
Test results
The following diagram shows the performance of servers on different architectures at different levels of concurrency. The y-axis is the number of requests per second, the x-axis is parallel connections.
Below is a table with the results.
| requests per second | |||||||
| parallelism | iterative | fork | pre fork | streaming | pre-streaming | poll | epoll |
| 20 | 7 | 112 | 2100 | 1800 | 2250 | 1900 | 2050 |
| fifty | 7 | 190 | 2200 | 1700 | 2200 | 2000 | 2000 |
| 100 | 7 | 245 | 2200 | 1700 | 2200 | 2150 | 2100 |
| 200 | 7 | 330 | 2300 | 1750 | 2300 | 2200 | 2100 |
| 300 | - | 380 | 2200 | 1800 | 2400 | 2250 | 2150 |
| 400 | - | 410 | 2200 | 1750 | 2600 | 2000 | 2000 |
| 500 | - | 440 | 2300 | 1850 | 2700 | 1900 | 2212 |
| 600 | - | 460 | 2400 | 1800 | 2500 | 1700 | 2519 |
| 700 | - | 460 | 2400 | 1600 | 2490 | 1550 | 2607 |
| 800 | - | 460 | 2400 | 1600 | 2540 | 1400 | 2553 |
| 900 | - | 460 | 2300 | 1600 | 2472 | 1200 | 2567 |
| 1000 | - | 475 | 2300 | 1700 | 2485 | 1150 | 2439 |
| 1500 | - | 490 | 2400 | 1550 | 2620 | 900 | 2479 |
| 2000 | - | 350 | 2400 | 1400 | 2396 | 550 | 2200 |
| 2500 | - | 280 | 2100 | 1300 | 2453 | 490 | 2262 |
| 3000 | - | 280 | 1900 | 1250 | 2502 | wide spread | 2138 |
| 5000 | - | wide spread | 1600 | 1100 | 2519 | - | 2235 |
| 8000 | - | - | 1200 | wide spread | 2451 | - | 2100 |
| 10,000 | - | - | wide spread | - | 2200 | - | 2200 |
| 11,000 | - | - | - | - | 2200 | - | 2122 |
| 12,000 | - | - | - | - | 970 | - | 1958 |
| 13,000 | - | - | - | - | 730 | - | 1897 |
| 14,000 | - | - | - | - | 590 | - | 1466 |
| 15,000 | - | - | - | - | 532 | - | 1281 |
It can be seen from the graph and table that above 8000 simultaneous requests, we have only two players left: pre-fork and epoll. As the load grows, the poll-based server performs worse than streaming. Pre-threading architecture competes with epoll: this is evidence of how well the Linux kernel plans a large number of threads.
Source Code ZeroHTTPd
The source code for ZeroHTTPd is here . Each architecture has a separate directory.
ZeroHTTPd
│
├── 01_iterative
│ ├── main.c
├── 02_forking
│ ├── main.c
├── 03_preforking
│ ├── main.c
├── 04_threading
│ ├── main.c
├── 05_prethreading
│ ├── main.c
├── 06_poll
│ ├── main.c
├── 07_epoll
│ └── main.c
├── Makefile
├── public
│ ├── index.html
│ └── tux.png
└── templates
└── guestbook
└── index.htmlIn addition to seven directories for all architectures, there are two more in the top-level directory: public and templates. The first one contains the index.html file and the image from the first screenshot. Other files and folders can be placed there, and ZeroHTTPd should issue these static files without problems. If the path in the browser matches the path in the public folder, then ZeroHTTPd looks for the index.html file in this directory. Guestbook content is generated dynamically. It has only the main page, and its contents are based on the file 'templates / guestbook / index.html'. ZeroHTTPd easily adds dynamic pages for expansion. The idea is that users can add templates to this directory and extend ZeroHTTPd as needed.
To build all seven servers, run
make allfrom the top-level directory - and all builds will appear in this directory. The executables look for the public and templates directories in the directory from where they run.Linux API
To understand the information in this series of articles, it is not necessary to be well versed in the Linux API. However, I recommend reading more on this topic, there are a lot of reference resources on the Web. Although we will cover several categories of Linux APIs, our focus will be mainly on processes, threads, events, and the network stack. In addition to books and articles about the Linux API, I also recommend reading mana for system calls and library functions used.
Performance and scalability
One note on performance and scalability. Theoretically, there is no connection between them. You may have a web service that works very well, with a response time of a few milliseconds, but it does not scale at all. Similarly, there might be a poorly running web application that takes a few seconds to respond, but it scales to tens to handle tens of thousands of concurrent users. However, the combination of high performance and scalability is a very powerful combination. High-performance applications generally use resources economically and thus effectively serve more concurrent users on the server, reducing costs.
CPU and I / O Tasks
Finally, there are always two possible types of tasks in computing: for I / O and CPU. Receiving requests via the Internet (network I / O), file maintenance (network and disk I / O), communication with the database (network and disk I / O) are all I / O actions. Some database queries can load the CPU a bit (sorting, calculating the average of a million results, etc.). Most web applications are limited by the maximum possible I / O, and the processor is rarely used at full capacity. When you see that some CPU uses a lot of CPUs, this is most likely a sign of poor application architecture. This may mean that CPU resources are spent on process control and context switching - and this is not entirely useful. If you do something like image processing, converting audio files or machine learning, then the application requires powerful CPU resources. But for most applications this is not so.