How we moderate ads

Each service, whose users can create their own content (UGC - User-generated content), is forced not only to solve business problems, but also to put things in order in UGC. Poor or poor-quality moderation of content in the end can reduce the attractiveness of the service for users, until the termination of its work.
Today we will tell you about the synergy between Yula and Odnoklassniki, which helps us to effectively moderate ads in Yule.
Synergy in general is very useful, and in the modern world, when technology and trends change very quickly, it can turn into a lifesaver. Why spend scarce resources and time on the invention of what you have already been invented and brought to mind?
We thought the same way when we faced the challenge of moderating user-generated content — images, text, and links. Our users upload millions of units of content to Yula every day, and without automatic processing, manually moderating all this data is not realistic at all.
Therefore, we took advantage of the already prepared moderation platform, which by that time our colleagues from Odnoklassniki had dubbed to the state of “almost perfect”.
Why classmates?
Every day, tens of millions of users come to the social network to publish billions of units of content: from photos to videos and texts. Odnoklassniki's moderation platform helps to check very large amounts of data and counteract spammers and bots.
The OK moderation team has gained a lot of experience, as it has been improving its tool for 12 years. It is important that they not only could share their ready-made solutions, but also configure the architecture of their platform for our specific tasks.

Further for brevity we will call the moderation platform OK simply “platform”.
How it works
Between Yula and Odnoklassniki data exchange is established through Apache Kafka .
Why did we choose this tool:
- In Yulia, all ads are post-moderated, so initially a synchronous response was not required.
- If a fierce paragraph happens, and Yula or Odnoklassniki will be inaccessible, including due to some peak loads, then the data from Kafka will not disappear anywhere and can be read later.
- The platform has already been integrated with Kafka, so most security issues have been resolved.
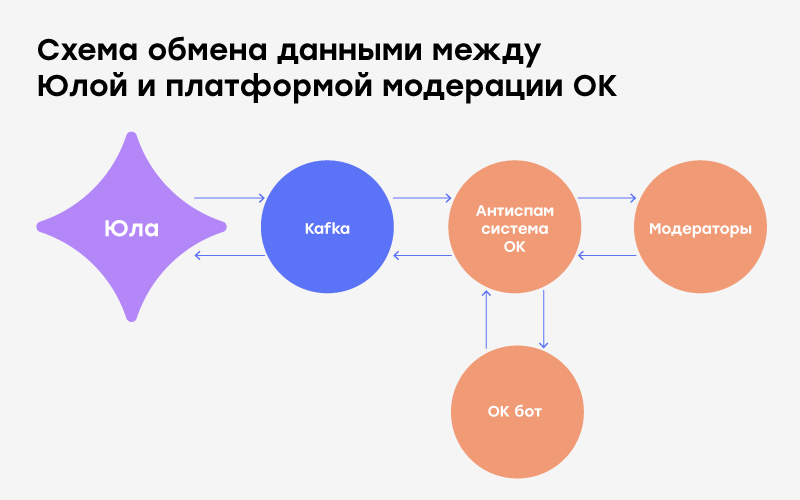
For each ad created or modified by the user in Yule, JSON is generated with data, which is put in Kafka for subsequent moderation. From Kafka, ads are uploaded to the platform, where decisions are made automatically or manually. Bad ads are blocked with a reason, and those in which the platform did not find violations are flagged as "good." Then all decisions are sent back to Yula and applied in the service.
As a result, for Yula, it all boils down to simple actions: send an ad to Odnoklassniki platform and back get the resolution “ok”, or why not “ok”.
Automatic processing
What happens to an ad after it hits the platform? Each ad is broken into several entities:
- title,
- description,
- Photo,
- user-selected category and subcategory of the ad,
- price.

Then, for each entity, the platform clusters to find duplicates. Moreover, the text and photos are clustered in different ways.
Texts before clustering are normalized to erase special characters, changed letters, and other garbage. The received data is divided into N-grams, each of which is hashed. The result is a lot of unique hashes. The similarity between the texts is considered as Jacquard between the two resulting sets. If the similarity is more than threshold, then the texts are glued together in one cluster. To speed up the search for similar clusters, MinHash and Locality-sensitive hashing are used.
Various options for gluing images were invented for photos, from comparing pHash images to finding duplicates using a neural network.
The latter method is the most "harsh". To train the model, such triples of images (N, A, P) were selected in which N does not look like A, and P - looks like A (is a half duplicate). Then, the neural network learned to make A and P as close as possible, and A and N as far as possible. This results in less false positives compared to simply embedding from a pre-trained network.
When a neural network receives images at the input, it generates an N (128) -dimensional vector for each of them and a request is made to assess the proximity of the image. Next, a threshold is calculated at which close images are considered duplicates.
The model can skillfully find spammers who specifically photograph the same product from different angles in order to circumvent the pHash comparison.


An example of spam photos glued by a neural network as duplicates.
At the final stage, duplicate ads are searched simultaneously in both text and image.
If two or more ads are stuck in a cluster, the system starts an automatic blocking, which, according to certain algorithms, selects which duplicates to remove and which to leave. For example, if two users have the same photos in an ad, then the system will block a more recent ad.
After creation, all clusters go through a series of automatic filters. Each filter gives the cluster a score: with what probability does it contain the threat this filter identifies.
For example, the system analyzes the description in the ad and selects potential categories for it. Then he takes the one with the highest probability and compares it with the category indicated by the creator of the ad. If they do not match, the ad is blocked for the wrong category. And since we are kind and honest, we directly tell the user which category he needs to choose so that the ad passes moderation.
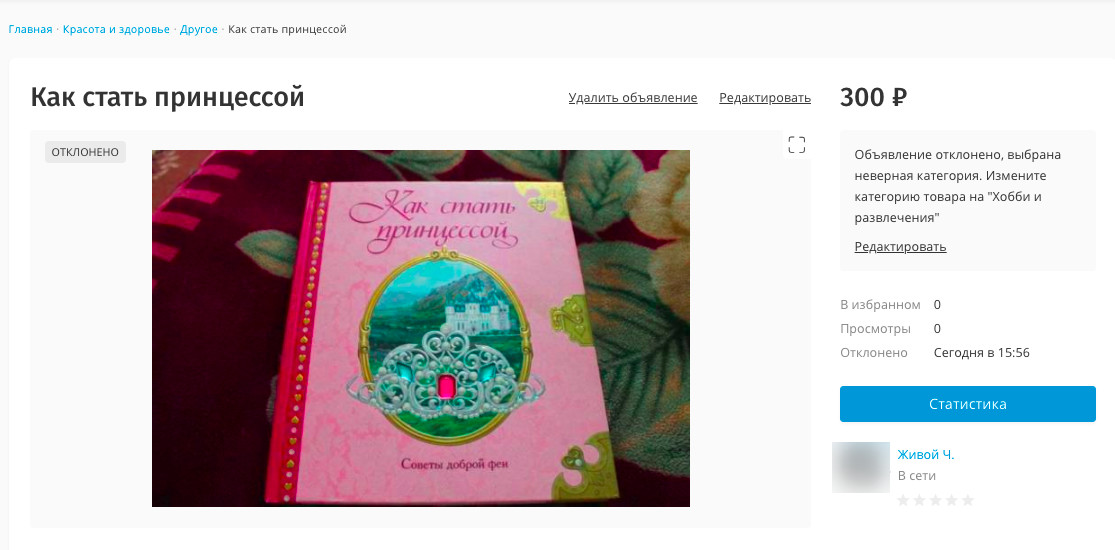
Block notification for the wrong category.
In our platform, machine learning feels right at home. For example, with its help we look for goods prohibited in the Russian Federation in names and descriptions. And models of neural networks meticulously “look at” images for URLs, spammer texts, phones, and the same “forbidden” ones.
For cases when they are trying to sell prohibited goods by disguising themselves as something legal, and at the same time there is no text in either the name or description, we use image tagging. For each image can be affixed up to 11 thousand different tags that describe what is on the image.
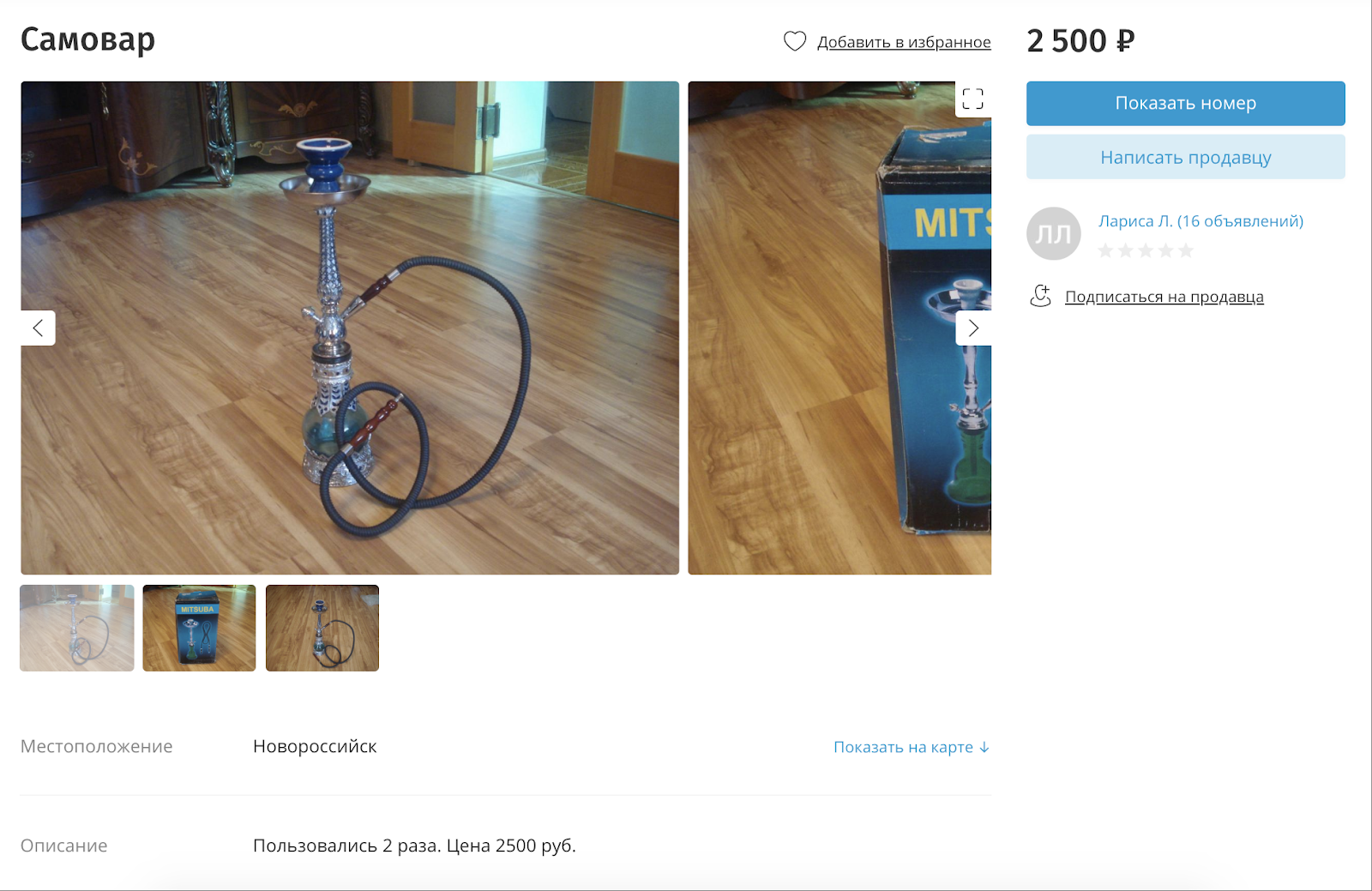
They are trying to sell a hookah, disguising it as a samovar.
In parallel with complex filters, simple, solving obvious tasks related to text work:
- antimat;
- URL and phone number detector;
- mention of instant messengers and other contacts;
- low price;
- ads that sell nothing, etc.
Today, each ad goes through a fine sieve of more than 50 automatic filters that try to find something bad in the ad.
If none of the detectors worked, then a response is sent to Yulu that the announcement is “most likely” complete. We use this answer at home, and users who subscribe to the seller receive a notification about the appearance of a new product.
Notification that the seller has a new product.
As a result, each ad “is overgrown” with metadata, some of which is generated when the ad is created (author’s IP address, user-agent, platform, geolocation, etc.), and the rest is the score given by each filter.
Ad queues
When an ad hits the platform, the system puts it in one of the queues. Each queue is formed using a mathematical formula that combines ad metadata in such a way as to detect some kind of bad pattern.
For example, you can create a queue of ads in the "Cell Phones" category from users of Yula supposedly from St. Petersburg, but at the same time their IP addresses from Moscow or other cities.
An example of ads posted by one user in different cities.
Or, you can create queues based on the points that the neural network assigns to ads, placing them in descending order.
Each line, according to its formula, assigns a final score to the ad. Then you can act in different ways:
- specify a threshold value at which the ad will receive a certain type of blocking;
- all ads in the queue should be sent to moderators for manual review;
- or combine the previous options: specify the threshold for automatic blocking and send to the moderators those ads that have not reached this threshold.

Why are these lines necessary? Let's say a user uploaded a photo of a firearm. The neural network assigns it a score from 95 to 100 and with 99 percent accuracy determines what the weapon is in the picture. But if the score value is below 95%, the accuracy of the model begins to decline (this is a feature of neural network models).
As a result, a queue is formed based on the score model, and those ads that received from 95 to 100 are automatically blocked as “Prohibited Goods”. Ads with points below 95 are sent to moderators for manual processing.

Chocolate Beretta with cartridges. Only for manual moderation! :)
Manual moderation
At the beginning of 2019, about 94% of all ads in Yule are moderated automatically.

If the platform cannot decide on any announcements, then sends them for manual moderation. Classmates developed their own tool: tasks for moderators immediately display all the necessary information for making a quick decision - the advertisement is suitable or should be blocked with an indication of the reason.
And so that with manual moderation the quality of service does not suffer, the work of people is constantly monitored. For example, in the stream of tasks the moderator shows “traps” - announcements for which there are already ready-made solutions. If the decision of the moderator does not coincide with the ready one, an error is counted to the moderator.
The average moderator spends 10 seconds to check one ad. Moreover, the number of errors is not more than 0.5% of all tested ads.
Folk moderation
Colleagues from Odnoklassniki went even further, took advantage of the "help of the hall": they wrote an application game for the social network in which you can quickly mark up a large amount of data, highlighting some bad sign, - Odnoklassnikov Moderator ( https://ok.ru/app/ moderator ). A good way to take advantage of the help of OK users who try to make content more enjoyable.
A game in which users mark photos that have a phone number.
Any queue of ads in the platform can be redirected to the game Odnoklassniki Moderator. Everything that users of the game mark up, then goes to internal moderators for verification. This scheme allows you to block ads for which filters have not yet been created, and simultaneously create training samples.
Storage of moderation results
We save all decisions made during moderation, so that later we don’t process those announcements that already made a decision.
Ads generate millions of clusters daily. Over time, each cluster receives a mark of "good" or "bad." Each new ad or its edition, falling into the cluster with a mark, automatically receives the resolution of the cluster itself. About 20 thousand of such automatic resolutions per day.
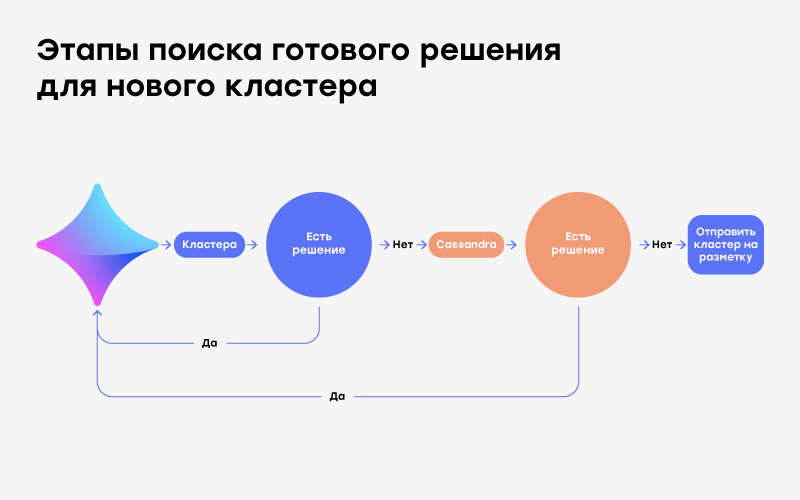
If the cluster does not receive new declarations, it is deleted from memory, and its hash and solution are written to Apache Cassandra.
When the platform receives a new announcement, it first tries to find a similar cluster among the already created ones and take a decision from it. If there is no such cluster, the platform goes to Cassandra and searches there. Found it? Great, applies the solution to the cluster and sends it to Yula. On average, 70,000 of these “repeated” decisions are recruited — 8% of the total.
Summarizing
We use the Odnoklassniki moderation platform for two and a half years. We like the results:
- We automatically moderate 94% of all ads per day.
- The moderation cost of one advertisement was reduced from 2 rubles to 7 kopecks.
- Thanks to the finished tool, they forgot about the problems of managing moderators.
- 2.5 times increased the number of manually processed ads with the same number of moderators and budget. The quality of manual moderation also increased due to automated control, and fluctuates around 0.5% of errors.
- Quickly filter new types of spam.
- Quickly connect new units of Yula Vertical to moderation . Since 2017, verticals of Real Estate, Jobs and Auto have appeared in Yule.