When is it worth checking the hypothesis of no less effectiveness?
- Transfer

An article from the Stitch Fix team suggests using a non-inferiority trials clinical research approach in marketing and product A / B tests. This approach is really applicable when we test a new solution that has advantages that are not measurable by tests.
The simplest example is bone loss. For example, we automate the process of assigning the first lesson, but we don’t want to drop the through conversion much. Or we test changes that are focused on one segment of users, while making sure that conversions across other segments do not sink much (when testing several hypotheses, do not forget about the corrections).
Choosing the right border of no less efficiency adds additional difficulties at the test design stage. The question of how to choose Δ in the article is not well disclosed. It seems that this choice is not completely transparent in clinical trials. A review of medical publications on non-inferiority reports that in only half of publications the choice of border is justified and often these justifications are ambiguous or not detailed.
In any case, this approach seems interesting, because by reducing the required sample size, it can increase the speed of testing, and, therefore, the speed of decision-making. - Daria Mukhina, product analyst for the Skyeng mobile app.
The Stitch Fix team loves to test different things. The whole technology community, in principle, likes to conduct tests. Which version of the site attracts more users - A or B? Does version A of the recommendation model bring more money than version B? Almost always, for testing hypotheses, we use the simplest approach from the basic course of statistics:
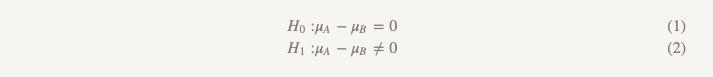
Although we rarely use this term, this form of testing is called "testing the hypothesis of superiority." With this approach, we assume that there is no difference between the two options. We adhere to this idea and refuse it only if the data obtained are convincing enough for this - that is, they demonstrate that one of the options (A or B) is better than the other.
Testing the superiority hypothesis is suitable for solving many problems. We release the B-version of the recommendation model only if it is obviously better than already used version A. But in some cases this approach does not work as well. Let's look at a few examples.
1) We use a third-party service that helps identify fake bank cards. We found another service that costs significantly less. If a cheaper service works as well as the one we use now, we will choose it. It does not have to be better than the service used.
2) We want to abandon the data sourceA and replace it with data source B. We could postpone the abandonment of A if B produces very poor results, but it is not possible to continue using A.
3) We would like to move from approach to modeling A to approach B not because we expect better results from B, but because it gives us great operational flexibility. We have no reason to believe that B will be worse, but we will not begin the transition if this is the case.
4) We made several qualitative changesinto the website design (version B) and we believe that this version is superior to version A. We do not expect changes in the conversion or any key performance indicators by which we usually evaluate the website. But we believe that there are advantages in parameters that are either immeasurable, or our technologies are not enough to measure.
In all of these cases, researching excellence is not the best solution. But most experts in these situations use it by default. We carefully conduct an experiment to correctly determine the magnitude of the effect. If it were true that versions A and B work very similarly, there is a chance that we will not be able to reject the null hypothesis. Do we conclude that A and B generally work the same? Not! The inability to reject the null hypothesis and the adoption of the null hypothesis are not the same thing.
Calculations of the sample size (which you, of course, performed) are usually carried out with stricter boundaries for the first kind error (probability of erroneous rejection of the null hypothesis, often called alpha), than for the second kind error (probability of failure to reject the null hypothesis, when assuming that the null hypothesis is wrong, often called beta). The typical value for alpha is 0.05, while the typical value for beta is 0.20, which corresponds to a statistical power of 0.80. This means that with we we can’t detect the true influence of the value that we indicated in our power calculations with a probability of 20% and this is a rather serious information gap. As an example, let's consider the following hypotheses:

H0: my backpack is NOT in my room (3)
H1: my backpack is in my room (4)
If I searched my room and found my backpack - fine, I can refuse the null hypothesis. But if I looked around the room and could not find my backpack (Figure 1), what conclusion should I draw? Am I sure he is not there? Have I searched thoroughly enough? What if I searched only 80% of the room? To conclude that the backpack is definitely not in the room will be a rash decision. Not surprisingly, we cannot "accept the null hypothesis."

The area we searched
We did not find a backpack - should we accept the null hypothesis?
Figure 1. Searching 80% of the room is about the same as conducting a study with a capacity of 80%. If you did not find a backpack, having examined 80% of the room, is it possible to conclude that it is not there?
So what does a data specialist do in this situation? You can greatly increase the research power, but then you will need a much larger sample, and the result will still be unsatisfactory.
Fortunately, such problems have long been studied in the world of clinical research. Drug B is cheaper than drug A; drug B is expected to cause fewer side effects than drug A; drug B is easier to transport because it does not need to be stored in the refrigerator, and drug A is needed. We test the hypothesis of no less efficiency. This is necessary to show that version B is as good as version A - at least within a certain predetermined limit of “no less efficiency”, Δ. A little later we will talk more about how to set this limit. But now suppose that this is the smallest difference that is practically significant (in the context of clinical trials, this is usually called clinical relevance).
Hypotheses of no less efficiency turn everything upside down:
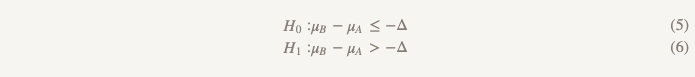
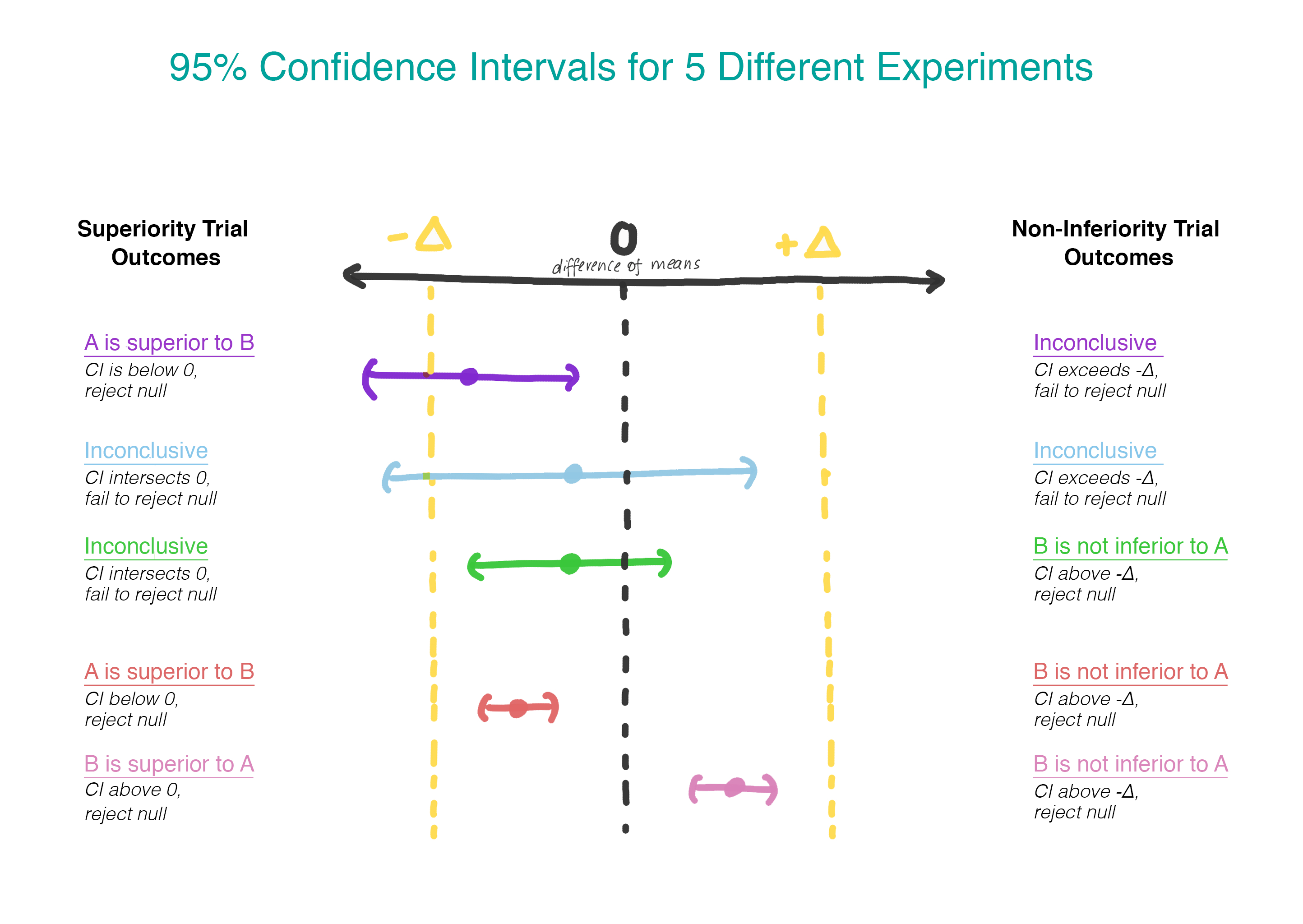
Now, instead of assuming that there is no difference, we assume that version B is worse than version A, and we will stick to this assumption until we demonstrate that it is not. This is exactly the moment when it makes sense to use testing a one-sided hypothesis! In practice, this can be done by constructing a confidence interval and determining whether the interval is really greater than Δ (Figure 2).
Δ selection
How to choose Δ? The selection process Δ includes a statistical justification and a subject evaluation. There are normative recommendations in the world of clinical trials, from which it follows that the delta should be the smallest clinically significant difference - one that will be relevant in practice. Here is a quote from the European leadership, with which you can check yourself: “If the difference was chosen correctly, a confidence interval that completely lies between –∆ and 0 ... is still sufficient to demonstrate no less efficiency. If this result does not seem acceptable, it means that ∆ was not chosen appropriately. ”
The delta should definitely not exceed the magnitude of the effect of version A in relation to true control (placebo / lack of treatment), since this leads us to believe that version B is worse than true control and at the same time demonstrates “no less efficiency”. Suppose that when version A was introduced, version 0 was in its place or the function did not exist at all (see Figure 3).
Based on the results of testing the hypothesis of superiority, the magnitude of the effect E was revealed (i.e., presumably μ ^ A − μ ^ 0 = E). Now A is our new standard, and we want to make sure that B is not inferior to A. Another way to write μB − μA≤ − Δ (null hypothesis) is μB≤μA − Δ. If we assume that doing is equal to or greater than E, then μB ≤ μA − E ≤ placebo. Now we see that our estimate for μB completely exceeds μA − E, which thereby completely refutes the null hypothesis and allows us to conclude that B is not inferior to A, but at the same time, μB may be ≤ μ placebo, but this is not what we need. (figure 3).
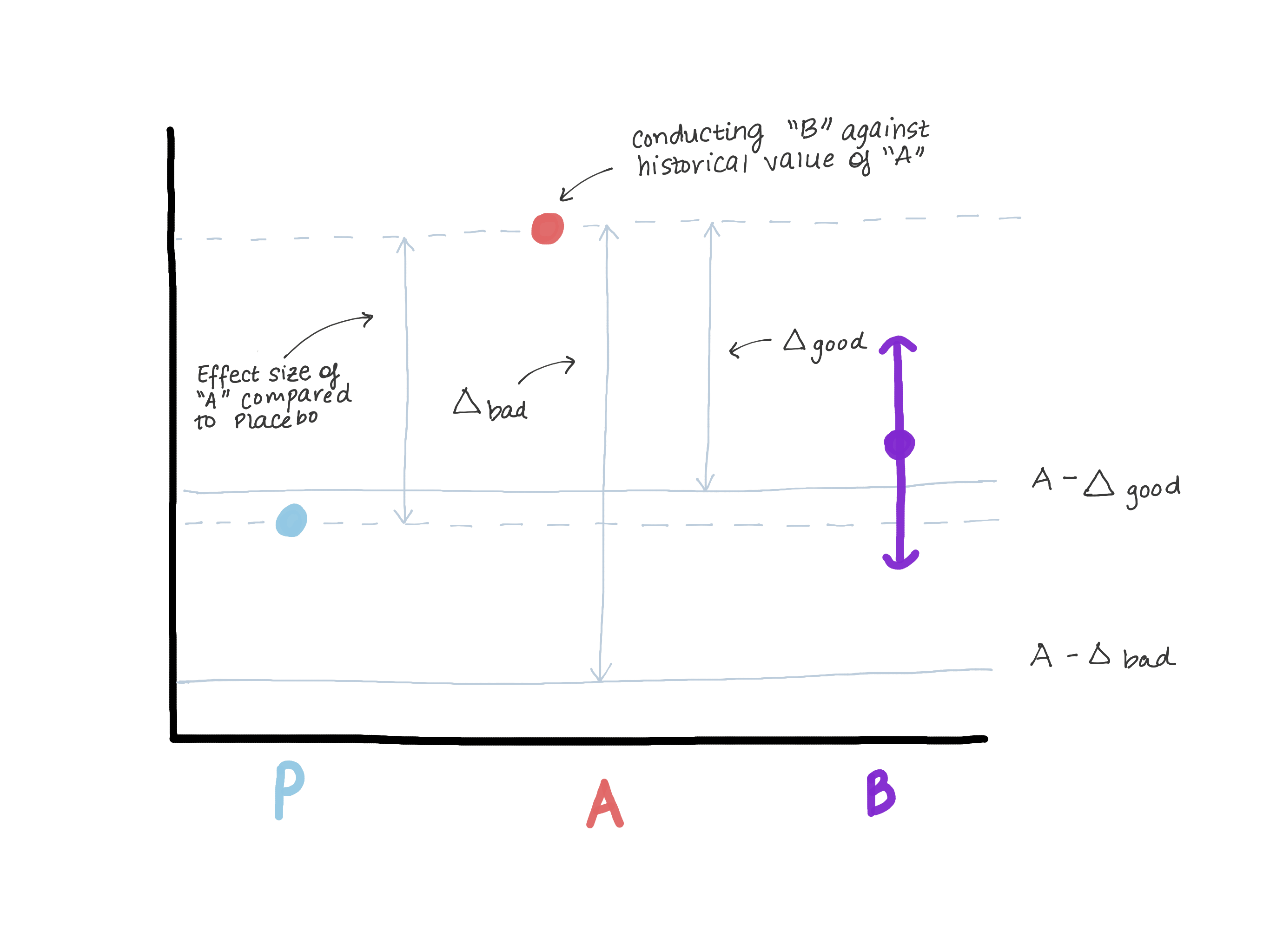
Figure 3. Demonstration of the risks of choosing a border of no less efficiency. If the limit is too large, we can conclude that B is not inferior to A, but at the same time indistinguishable from placebo. We will not change the drug, which is clearly more effective than placebo (A), on the drug, which has the same effectiveness as placebo.
Choosing α
We pass to the choice of α. You can use the standard value α = 0.05, but this is not entirely honest. Like, for example, when you buy something on the Internet and use several discount codes at once, although they should not be summarized, the developer just made a mistake and you got away with it. According to the rules, the value of α should be equal to half the value of α, which is used to test the hypothesis of superiority, i.e. 0.05 / 2 = 0.025.
Sample size
How to estimate the sample size? If you believe that the true average difference between A and B is 0, then the calculation of the sample size will be the same as when testing the hypothesis of superiority, except that you replace the effect size with a limit of no less efficiency, provided that you use α no less efficiency = 1/2 superiority (αnon-inferiority = 1/2 superior). If you have reason to believe that option B may be slightly worse than option A, but you want to prove that it is worse by no more than Δ, then you are in luck! In fact, this reduces the size of your sample, because it’s easier to demonstrate that B is worse than A if you really think that it is slightly worse and not equivalent.
Solution Example
Suppose you want to switch to version B, provided that it is worse than version A by no more than 0.1 points on a 5-point customer satisfaction scale ... We will approach this task using the superiority hypothesis.
To test the hypothesis of superiority, we would calculate the sample size as follows:

That is, if you have 2103 observations in your group, you can be 90% sure that you will find an effect of 0.10 or more. But if the value of 0.10 is too large for you, perhaps you should not test the hypothesis of superiority for it. Perhaps, for reliability, you decide to conduct a study for a smaller effect size, for example, 0.05. In this case, you will need 8407 observations, that is, the sample will increase almost 4 times. But what if we stick to our original sample size, but increase the power to 0.99 so that we don’t doubt if we get a positive result? In this case, n for one group will be 3676, which is better, but increases the sample size by more than 50%. And as a result, we all the same simply cannot refute the null hypothesis, and do not get the answer to our question.
What if, instead, we test the hypothesis of no less effectiveness?
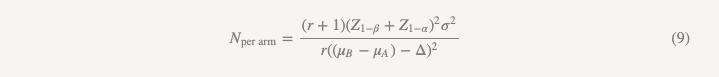
The sample size will be calculated using the same formula with the exception of the denominator.
The differences from the formula used to test the hypothesis of superiority are as follows:
- Z1 − α / 2 is replaced by Z1 − α, but if you do everything according to the rules, you replace α = 0.05 with α = 0.025, that is, this is the same number (1.96)
- appears in the denominator (μB − μA)
- θ (effect value) is replaced by Δ (limit of no less efficiency)
If we assume that µB = µA, then (µB - µA) = 0 and calculating the sample size for a limit of no less efficiency is exactly what we would get when calculating the superiority for the effect value of 0.1, great! We can conduct a study of the same scale with different hypotheses and a different approach to conclusions, and we will get an answer to the question that we really want to answer.
Now suppose that we don’t really think that µB = µA and
think that µB is a little worse, maybe 0.01 units. This increases our denominator, reducing the sample size per group to 1737.
What happens if version B is actually better than version A? We refute the null hypothesis that B is worse than A by more than Δ and accept the alternative hypothesis that B, if worse, is not worse than Δ, and could be better. Try putting this conclusion in a cross-functional presentation and see what comes of it (seriously, give it a try). In a situation where you need to focus on the future, no one wants to agree to "worse by no more than Δ and, possibly, better."
In this case, we can conduct a study, which is called very briefly "test the hypothesis that one of the options is superior to the other or inferior to it." It uses two sets of hypotheses:
The first set (the same as when testing a hypothesis of no less efficiency):
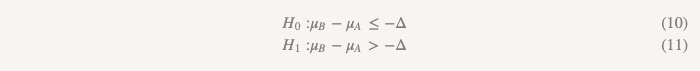
The second set (the same as when testing the hypothesis of superiority):

We test the second hypothesis only if the first is rejected. In sequential testing, we maintain the overall level of errors of the first kind (α). In practice, this can be achieved by creating a 95% confidence interval for the difference between the means and checking to determine if the entire interval exceeds -Δ. If the interval does not exceed -Δ, we cannot reject the zero value and stop. If the whole interval really exceeds −Δ, we continue and see if the interval contains 0.
There is another type of research that we have not discussed - equivalence studies.
Studies of this type can be replaced by studies to test the hypothesis of no less effectiveness and vice versa, but in fact they have an important difference. A test to test the hypothesis of no less efficiency is aimed at showing that option B is at least as good as A. And an equivalence study is aimed at showing that option B is at least as good as A, and option A is as good as B, which is more complicated. In essence, we are trying to determine whether the entire confidence interval lies for the difference in means between −Δ and Δ. Such studies require a larger sample size and are less frequent. Therefore, the next time you conduct a study in which your main task is to make sure that the new version is no worse, do not settle for "inability to refute the null hypothesis."