Automation for the smallest. Part zero. Planning
- Tutorial
SDSM is over, but the uncontrolled desire to write remains.
For many years, our brother suffered from the performance of routine work, crossed his fingers before committing, and lacked sleep due to night rollbacks.
But the dark times are coming to an end.
With this article, I will begin a series about how I see automation.
In the process, we will deal with the stages of automation, storing variables, formalizing the design, with RestAPI, NETCONF, YANG, YDK and we will program a lot. It means to me that a) this is not an objective truth, b) not unconditionally the best approach c) my opinion may change even during the movement from the first to the last article - to be honest, from the draft stage to the publication I completely rewrote everything twice.

I will try to keep the ADSM in a format slightly different from the SDSM. Large detailed numbered articles will continue to appear, and between them I will publish small notes from everyday experience. I’ll try to fight perfectionism here and not lick each of them.
We will try to take a medium-sized LAN DC data center and work out the entire automation scheme.
I will do some things almost the first time with you.
The LAN DC has 4 DCs, about 250 switches, half a dozen routers and a couple of firewalls.
Not facebook, but enough to think deeply about automation.
There is, however, the opinion that if you have more than 1 device, you already need automation.
In fact, it’s hard to imagine that someone can now live without at least a bunch of knee-high scripts.
Although I heard that there are such offices where IP addresses are kept in Excel, and each of the thousands of network devices is manually configured and has its own unique configuration. This, of course, can be passed off as contemporary art, but the feelings of the engineer will certainly be offended.
Now we will set the most abstract goals:
Later in this article we will analyze which means we will use, and in the following, goals and means in detail.
The defining phrase of the cycle, although at first glance it may not seem so significant: we will configure the network, not individual devices .
Over the past few years, we have seen a shift in emphasis on how to treat the network as a single entity, hence the software defined networking , intent driven networks and autonomous networks coming into our lives .
After all, what is globally needed by applications from the network: connectivity between points A and B (well, sometimes + B-Z) and isolation from other applications and users.

And so, our task in this series is to build a system that supports the current configuration of the entire network, which is already decomposed into the current configuration on each device in accordance with its role and location.
The network management system implies that to make changes we turn to it, and it, in turn, calculates the desired state for each device and configures it.
Thus, we minimize the use of CLI in our hands to almost zero — any changes in device settings or network design should be formalized and documented — and only then roll out to the necessary network elements.
It is known that 80% of problems happen during configuration changes - indirect evidence of this is that during the New Year holidays, everything is usually calm.
I personally witnessed dozens of global downtimes due to a human error: the wrong command, the configuration was executed in the wrong branch, the community forgot, demolished MPLS globally on the router, configured five pieces of iron, and did not notice the sixth error, committed the old changes made by another person . Scenarios darkness is dark.
Automation will allow us to make fewer mistakes, but on a larger scale. So you can brick up not one device, but the entire network at once.
From time immemorial, our grandfathers checked the correctness of the changes made with a sharp eye, steel eggs, and the efficiency of the network after rolling them out.
Those grandfathers, whose work led to downtime and catastrophic losses, left fewer offspring and should die out over time, but evolution is a slow process, and so still not everyone checks the changes in the laboratory beforehand.
However, at the forefront of those who automated the process of testing the configuration, and its further application to the network. In other words, I borrowed the CI / CD ( Continuous Integration, Continuous Deployment ) procedure from the developers.
In one part, we will look at how to implement this using a version control system, probably a github.
An organic continuation of the ideas about the network management system and CI / CD is the full versioning of the configuration.
We will assume that with any changes, even the most minor, even on one inconspicuous device, the entire network goes from one state to another.
And we always do not execute the command on the device, we change the state of the network.
Now let's get these states and call them versions?
Let's say the current version is 1.0.0.
Has the IP address of the Loopback interface changed on one of the ToRs? This is a minor version - get the number 1.0.1.
We reviewed the route import policies in BGP - a little more seriously - already 1.1.0
We decided to get rid of IGP and switch only to BGP - this is a radical design change - 2.0.0.
At the same time, different DCs may have different versions - the network is developing, new equipment is being installed, somewhere new spine levels are added, somewhere - no, etc.
We will talk about semantic versioning in a separate article.
I repeat - any change (except for debugging commands) is an update of the version. Administrators should be notified of any deviations from the current version.
The same applies to the rollback of changes - this is not the abolition of the last commands, this is not a rollback by the device’s operating system — this is bringing the entire network to a new (old) version.
This self-evident task in modern networks goes to a new level.
Often, large service providers practice the approach that a fallen service must be quickly finished off and a new one raised, instead of figuring out what happened.
“Very” means that from all sides it is necessary to smear profusely with monitoring, which within seconds will detect the slightest deviations from the norm.
And here are not enough familiar metrics, such as loading an interface or accessibility of a node. Not enough and manual tracking of the duty officer for them.
For many things, there should generally be Self-Healing - the controls lit up in red and went off the plantain themselves, where it hurts.
And here we also monitor not only individual devices, but also the health of the network as a whole, both whitebox, which is relatively clear, and blackbox, which is already more complicated.
What do we need to implement such ambitious plans?
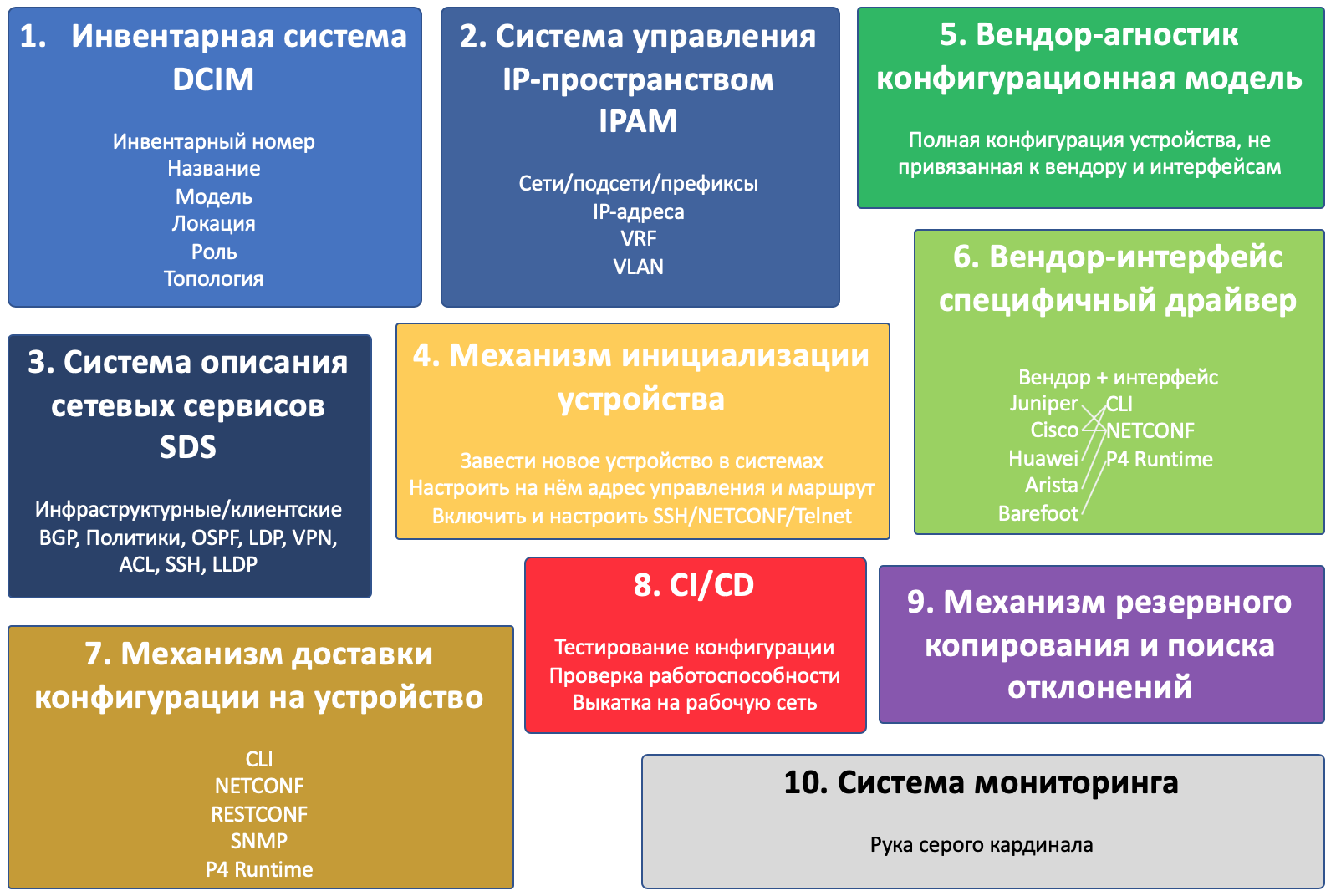
Sounds complicated enough to start decomposing a project into components.
And there will be ten of them:

In the illustration, I depicted all the components and the device itself.
Intersecting components interact with each other.
The larger the block, the more attention you need to pay to this component.
Obviously, we want to know what equipment, where it stands, what it is connected to.
Inventory system is an integral part of any enterprise.
Most often, for network devices, the enterprise has a separate inventory system that solves more specific tasks.
As part of a series of articles, we will call it DCIM - Data Center Infrastructure Management. Although the term DCIM itself, strictly speaking, includes much more.
For our tasks, we will store the following information about the device in it:

It is perfectly clear that we ourselves want to know all this.
But will it help for automation?
Of course.
For example, we know that in this data center on Leaf switches, if it is Huawei, ACLs for filtering certain traffic should be applied on the VLAN, and if it is Juniper, then on unit 0 of the physical interface.
Or you need to roll out a new Syslog server to all the boarders in the region.
In it, we will store virtual network devices, such as virtual routers or root-reflectors. We can add a DNS server, NTP, Syslog, and generally everything that somehow relates to the network.
Yes, and in our time there are teams of people who keep track of prefixes and IP addresses in an Excel file. But the modern approach is still a database, with a frontend on nginx / apache, an API and extensive functions for taking into account IP addresses and networks with separation into VRF.
IPAM - IP Address Management.
For our tasks, we will store the following information in it:

Again, it is clear that we want to be sure that by allocating a new IP address for the ToR loopback, we will not stumble on the fact that it has already been assigned to someone. Or that we used the same prefix twice at different ends of the network.
But how does this help in automation?
Easy.
We request a prefix in the system with the Loopbacks role, in which there are IP addresses available for allocation - if it is, select the address, if not, we request the creation of a new prefix.
Or, when creating a device configuration, we from the same system can find out which VRF the interface should be in.
And when you start a new server, the script goes into the system, finds out in which server the switch, in which port and which subnet is assigned to the interface - it will select the server address from it.
It begs the desire of DCIM and IPAM to combine into one system so as not to duplicate functions and not serve two similar entities.
So we will do.
If the first two systems store variables that still need to be used somehow, then the third describes for each device role how it should be configured.
It is worth highlighting two different types of network services:
The former are designed to provide basic connectivity and device management. These include VTY, SNMP, NTP, Syslog, AAA, routing protocols, CoPP, etc.
The second ones organize the service for the client: MPLS L2 / L3VPN, GRE, VXLAN, VLAN, L2TP, etc.
Of course, there are also borderline cases - where to include MPLS LDP, BGP? Yes, and routing protocols can be used for clients. But this is not important.
Both types of services are decomposed into configuration primitives:
How exactly we will do this, I will not put my mind to it yet. We will deal in a separate article.

If a little closer to life, then we could describe that the
Leaf switch should have BGP sessions with all the connected Spine switches, import the connected networks into the process, and accept only networks from a specific prefix from the Spine switches. Limit CoPP IPv6 ND to 10 pps, etc.
In turn, spins hold sessions with all connected bodices, acting as root-reflectors, and receive from them only routes of a certain length and with a certain community.
Under this heading, I combine the many actions that must occur in order for the device to appear on radars and be accessed remotely.
There are three approaches:
We will talk about all three in a separate article.

Until now, all systems have been scattered rags giving variables and a declarative description of what we would like to see on the network. But sooner or later, you have to deal with specifics.
At this stage, for each particular device, primitives, services, and variables are combined into a configuration model that actually describes the complete configuration of a particular device, only in a vendor-independent manner.
What gives this step? Why not immediately configure the device, which you can simply fill in?
In fact, this allows us to solve three problems:

As a result of this stage, we get a vendor-independent configuration.
Do not console yourself with hopes that once you can configure a tsiska it will be possible in the same way as a jumper, just sending them exactly the same calls. Despite the growing popularity of whiteboxes and the emergence of support for NETCONF, RESTCONF, OpenConfig, the specific content that these protocols deliver is different from the vendor to the vendor, and this is one of their competitive differences that they simply won’t give up.
This is about the same as OpenContrail and OpenStack, which have RestAPI as their NorthBound interface, expect completely different calls.
So, at the fifth step, the vendor-independent model should take the form in which it will go to the iron.
And here, all means are good (no): CLI, NETCONF, RESTCONF, SNMP in a simple fall.
Therefore, we need a driver that translates the result of the previous step into the desired format for a particular vendor: a set of CLI commands, an XML structure.

We generated the configuration, but it still needs to be delivered to the devices - and, obviously, not by hand.
Firstly , we are faced with the question, what kind of transport will we use? And the choice today is no longer small:
Let’s dot here with e. CLI is Legacy. SNMP ... hehe.
RESTCONF is still an unknown animal; the REST API is supported by almost no one. Therefore, we will focus on NETCONF in a loop.
In fact, as the reader already understood, we had already decided on the interface at this point - the result of the previous step was already presented in the format of the interface that was selected.
Secondly , with what tools will we do this?
Here the choice is also large:
There is still no favorite chosen - we will stomp.
What else is important here? The consequences of applying the configuration.
Successfully or not. Remained access to the piece of hardware or not.
It seems that commit will help here with confirmation and validation of what was downloaded to the device.
This, combined with the correct implementation of NETCONF, significantly narrows the range of suitable devices - not many manufacturers support normal commits. But this is just one of the prerequisites in RFP . In the end, no one is worried that not a single Russian vendor will pass under the condition of 32 * 100GE interface. Or worries?

At this point, we are already ready for all network devices.
I write “for everything” because we are talking about versioning the state of the network. And even if you need to change the settings of just one switch, the changes for the entire network are calculated. Obviously, they can be zero for most nodes.
But, as already mentioned, above, we are not some barbarians in order to roll everything at once into the prod.
The generated configuration must first go through the Pipeline CI / CD.
To do this, we have a version control system that monitors configuration changes, a laboratory where we check whether the customer service is breaking, a monitoring system that checks this fact, and the last step is to roll out the changes to the production network.
With the exception of debugging teams, absolutely all changes on the network should go through CI / CD Pipeline - this is our guarantee of a quiet life and a long happy career.

Well, I don’t have to talk about backups again.
We will simply add them according to the crown or upon the fact of a configuration change in the git.
But the second part is more interesting - someone should keep an eye on these backups. And in some cases, this someone has to go and rotate everything as it was, and in others, meow someone, that the disorder.
For example, if there is a new user who is not registered in the variables, you need to remove him from the hack. And if it’s better not to touch the new firewall rule, maybe someone just turned on debugging, or maybe a new service, a mess, didn’t register according to the rules, but people already went to it.
We still won’t get away from a certain small delta on the scale of the entire network, despite any automation systems and a steel hand of management. To debug problems anyway, no one will bring configuration to the system. Moreover, they may not even be provided for by the configuration model.

At first, I was not going to cover the monitoring topic - still a voluminous, controversial and complex topic. But along the way, it turned out that this is an integral part of automation. And you can’t get around it even without practice.
Developing thought is an organic part of the CI / CD process. After rolling out the configuration to the network, we need to be able to determine whether everything is okay with it now.
And it’s not only and not so much about the graphs of using interfaces or host availability, but about more subtle things - the availability of the necessary routes, attributes on them, the number of BGP sessions, OSPF neighbors, End-to-End uptime services.
But did the syslogs on the external server stop folding, did the SFlow agent break down, did the drops in the queues begin to grow, and did the connection between any pair of prefixes break?
In a separate article, we reflect on this.

As a basis, I chose one of the modern data center network designs - L3 Clos Fabric with BGP as the routing protocol.
This time we will build a network on Juniper, because now the JunOs interface is a vanlav.
Let's complicate our lives using only Open Source tools and a multi-vendor network - therefore, apart from the Juniper, along the way I will choose another lucky guy.
The plan for upcoming publications is something like this:
First I will talk about virtual networks. First of all, because I want to, and secondly, because without this, the design of the infrastructure network will not be very clear.
Then about the network design itself: topology, routing, policies.
Let's assemble the laboratory stand.
Let's ponder and maybe practice initializing the device on the network.
And then about each component in intimate details.
And yes, I do not promise to elegantly end this cycle with a ready-made solution. :)
Roman Gorge. For comments and edits.
Artyom Chernobay. For KDPV.

Content
- Goals
- The network is like a single organism
- Configuration testing
- Versioning
- Monitoring and self-healing services
- Facilities
- Inventory system
- IP Space Management System
- Network Services Description System
- Device initialization mechanism
- Vendor agnostic configuration model
- Vendor-specific driver
- The mechanism for delivering configuration to the device
- CI / CD
- Backup and deviation mechanism
- Monitoring system
- Conclusion
I will try to keep the ADSM in a format slightly different from the SDSM. Large detailed numbered articles will continue to appear, and between them I will publish small notes from everyday experience. I’ll try to fight perfectionism here and not lick each of them.
How funny that the second time you have to go the same way.
First, I had to write articles about the network itself due to the fact that they were not in RuNet.
Now I could not find a comprehensive document that would systematize approaches to automation and use simple practical examples to analyze the above technologies.
Perhaps I am mistaken, therefore, throw links to suitable resources. However, this will not change my determination to write, because the main goal is still to learn something myself, and to make life easier for my neighbor is a pleasant bonus that caresses the gene for the dissemination of experience.
We will try to take a medium-sized LAN DC data center and work out the entire automation scheme.
I will do some things almost the first time with you.
In the ideas and tools described here, I will not be original. Dmitry Figol has an excellent channel with streams on this topic .
Articles in many aspects will overlap with them.
The LAN DC has 4 DCs, about 250 switches, half a dozen routers and a couple of firewalls.
Not facebook, but enough to think deeply about automation.
There is, however, the opinion that if you have more than 1 device, you already need automation.
In fact, it’s hard to imagine that someone can now live without at least a bunch of knee-high scripts.
Although I heard that there are such offices where IP addresses are kept in Excel, and each of the thousands of network devices is manually configured and has its own unique configuration. This, of course, can be passed off as contemporary art, but the feelings of the engineer will certainly be offended.
Goals
Now we will set the most abstract goals:
- The network is like a single organism
- Configuration testing
- Network Status Versioning
- Monitoring and self-healing services
Later in this article we will analyze which means we will use, and in the following, goals and means in detail.
The network is like a single organism
The defining phrase of the cycle, although at first glance it may not seem so significant: we will configure the network, not individual devices .
Over the past few years, we have seen a shift in emphasis on how to treat the network as a single entity, hence the software defined networking , intent driven networks and autonomous networks coming into our lives .
After all, what is globally needed by applications from the network: connectivity between points A and B (well, sometimes + B-Z) and isolation from other applications and users.
And so, our task in this series is to build a system that supports the current configuration of the entire network, which is already decomposed into the current configuration on each device in accordance with its role and location.
The network management system implies that to make changes we turn to it, and it, in turn, calculates the desired state for each device and configures it.
Thus, we minimize the use of CLI in our hands to almost zero — any changes in device settings or network design should be formalized and documented — and only then roll out to the necessary network elements.
That is, for example, if we decided that from now on the rack-mount switches in Kazan should announce two networks instead of one, we
- First we document the changes in the systems
- We generate the target configuration of all network devices
- We start the network configuration update program, which calculates what needs to be removed on each node, what to add, and brings the nodes to the desired state.
At the same time, with our hands we make changes only at the first step.
Configuration testing
It is known that 80% of problems happen during configuration changes - indirect evidence of this is that during the New Year holidays, everything is usually calm.
I personally witnessed dozens of global downtimes due to a human error: the wrong command, the configuration was executed in the wrong branch, the community forgot, demolished MPLS globally on the router, configured five pieces of iron, and did not notice the sixth error, committed the old changes made by another person . Scenarios darkness is dark.
Automation will allow us to make fewer mistakes, but on a larger scale. So you can brick up not one device, but the entire network at once.
From time immemorial, our grandfathers checked the correctness of the changes made with a sharp eye, steel eggs, and the efficiency of the network after rolling them out.
Those grandfathers, whose work led to downtime and catastrophic losses, left fewer offspring and should die out over time, but evolution is a slow process, and so still not everyone checks the changes in the laboratory beforehand.
However, at the forefront of those who automated the process of testing the configuration, and its further application to the network. In other words, I borrowed the CI / CD ( Continuous Integration, Continuous Deployment ) procedure from the developers.
{kind=link}
In one part, we will look at how to implement this using a version control system, probably a github.
As soon as you get used to the idea of network CI / CD, overnight the method of checking the configuration by applying it to the working network will seem to you an early medieval ignorance. About how to hammer a warhead with a hammer.
An organic continuation of the ideas about the network management system and CI / CD is the full versioning of the configuration.
Versioning
We will assume that with any changes, even the most minor, even on one inconspicuous device, the entire network goes from one state to another.
And we always do not execute the command on the device, we change the state of the network.
Now let's get these states and call them versions?
Let's say the current version is 1.0.0.
Has the IP address of the Loopback interface changed on one of the ToRs? This is a minor version - get the number 1.0.1.
We reviewed the route import policies in BGP - a little more seriously - already 1.1.0
We decided to get rid of IGP and switch only to BGP - this is a radical design change - 2.0.0.
At the same time, different DCs may have different versions - the network is developing, new equipment is being installed, somewhere new spine levels are added, somewhere - no, etc.
We will talk about semantic versioning in a separate article.
I repeat - any change (except for debugging commands) is an update of the version. Administrators should be notified of any deviations from the current version.
The same applies to the rollback of changes - this is not the abolition of the last commands, this is not a rollback by the device’s operating system — this is bringing the entire network to a new (old) version.
Monitoring and self-healing services
This self-evident task in modern networks goes to a new level.
Often, large service providers practice the approach that a fallen service must be quickly finished off and a new one raised, instead of figuring out what happened.
“Very” means that from all sides it is necessary to smear profusely with monitoring, which within seconds will detect the slightest deviations from the norm.
And here are not enough familiar metrics, such as loading an interface or accessibility of a node. Not enough and manual tracking of the duty officer for them.
For many things, there should generally be Self-Healing - the controls lit up in red and went off the plantain themselves, where it hurts.
And here we also monitor not only individual devices, but also the health of the network as a whole, both whitebox, which is relatively clear, and blackbox, which is already more complicated.
What do we need to implement such ambitious plans?
- Have a list of all devices on the network, their location, roles, models, software versions.
kazan-leaf-1.lmu.net, Kazan, leaf, Juniper QFX 5120, R18.3. - Have a system for describing network services.
IGP, BGP, L2 / 3VPN, Policy, ACL, NTP, SSH. - Be able to initialize the device.
Hostname, Mgmt IP, Mgmt Route, Users, RSA-Keys, LLDP, NETCONF - Configure the device and bring the configuration to the desired (including the old) version.
- Test configuration
- Periodically check the status of all devices for deviations from the current one and tell who should.
At night, someone quietly added a rule to the ACL . - Monitor performance.
Facilities
Sounds complicated enough to start decomposing a project into components.
And there will be ten of them:
- Inventory system
- IP Space Management System
- Network Services Description System
- Device initialization mechanism
- Vendor agnostic configuration model
- Vendor-specific driver
- The mechanism for delivering configuration to the device
- CI / CD
- Backup and deviation mechanism
- Monitoring system
This, by the way, is an example of how the view on the goals of the cycle changed - there were 4 components in the draft components.
In the illustration, I depicted all the components and the device itself.
Intersecting components interact with each other.
The larger the block, the more attention you need to pay to this component.
Component 1. Inventory system
Obviously, we want to know what equipment, where it stands, what it is connected to.
Inventory system is an integral part of any enterprise.
Most often, for network devices, the enterprise has a separate inventory system that solves more specific tasks.
As part of a series of articles, we will call it DCIM - Data Center Infrastructure Management. Although the term DCIM itself, strictly speaking, includes much more.
For our tasks, we will store the following information about the device in it:
- Inventory number
- Title / Description
- Model ( Huawei CE12800, Juniper QFX5120, etc. )
- Typical parameters ( boards, interfaces, etc. )
- Role ( Leaf, Spine, Border Router, etc. )
- Location ( region, city, data center, rack, unit )
- Interconnects between devices
- Network topology
It is perfectly clear that we ourselves want to know all this.
But will it help for automation?
Of course.
For example, we know that in this data center on Leaf switches, if it is Huawei, ACLs for filtering certain traffic should be applied on the VLAN, and if it is Juniper, then on unit 0 of the physical interface.
Or you need to roll out a new Syslog server to all the boarders in the region.
In it, we will store virtual network devices, such as virtual routers or root-reflectors. We can add a DNS server, NTP, Syslog, and generally everything that somehow relates to the network.
Component 2. IP Space Management System
Yes, and in our time there are teams of people who keep track of prefixes and IP addresses in an Excel file. But the modern approach is still a database, with a frontend on nginx / apache, an API and extensive functions for taking into account IP addresses and networks with separation into VRF.
IPAM - IP Address Management.
For our tasks, we will store the following information in it:
- VLAN
- VRF
- Networks / Subnets
- IP addresses
- Binding addresses to devices, networks to locations and VLAN numbers
Again, it is clear that we want to be sure that by allocating a new IP address for the ToR loopback, we will not stumble on the fact that it has already been assigned to someone. Or that we used the same prefix twice at different ends of the network.
But how does this help in automation?
Easy.
We request a prefix in the system with the Loopbacks role, in which there are IP addresses available for allocation - if it is, select the address, if not, we request the creation of a new prefix.
Or, when creating a device configuration, we from the same system can find out which VRF the interface should be in.
And when you start a new server, the script goes into the system, finds out in which server the switch, in which port and which subnet is assigned to the interface - it will select the server address from it.
It begs the desire of DCIM and IPAM to combine into one system so as not to duplicate functions and not serve two similar entities.
So we will do.
Component 3. Network Services Description System
If the first two systems store variables that still need to be used somehow, then the third describes for each device role how it should be configured.
It is worth highlighting two different types of network services:
- Infrastructure
- Client
The former are designed to provide basic connectivity and device management. These include VTY, SNMP, NTP, Syslog, AAA, routing protocols, CoPP, etc.
The second ones organize the service for the client: MPLS L2 / L3VPN, GRE, VXLAN, VLAN, L2TP, etc.
Of course, there are also borderline cases - where to include MPLS LDP, BGP? Yes, and routing protocols can be used for clients. But this is not important.
Both types of services are decomposed into configuration primitives:
- physical and logical interfaces (tag / anteg, mtu)
- IP Addresses and VRF (IP, IPv6, VRF)
- ACLs and traffic handling policies
- Protocols (IGP, BGP, MPLS)
- Routing policies (prefix lists, community, ASN filters).
- Service services (SSH, NTP, LLDP, Syslog ...)
- Etc.
How exactly we will do this, I will not put my mind to it yet. We will deal in a separate article.
If a little closer to life, then we could describe that the
Leaf switch should have BGP sessions with all the connected Spine switches, import the connected networks into the process, and accept only networks from a specific prefix from the Spine switches. Limit CoPP IPv6 ND to 10 pps, etc.
In turn, spins hold sessions with all connected bodices, acting as root-reflectors, and receive from them only routes of a certain length and with a certain community.
Component 4. Device initialization mechanism
Under this heading, I combine the many actions that must occur in order for the device to appear on radars and be accessed remotely.
- Start the device in the inventory system.
- Highlight management IP address.
- Configure basic access to it:
Hostname, management IP address, route to the management network, users, SSH keys, protocols - telnet / SSH / NETCONF
There are three approaches:
- Everything is completely manual. The device is brought to a stand where an ordinary organic person will lead him into the system, connect to the console and configure. May work on small static networks.
- ZTP - Zero Touch Provisioning. Iron came, stood up, received an address via DHCP, went to a special server, and configured itself.
- The infrastructure of console servers, where the initial configuration occurs through the console port in automatic mode.
We will talk about all three in a separate article.
Component 5. Vendor-agnostic configuration model
Until now, all systems have been scattered rags giving variables and a declarative description of what we would like to see on the network. But sooner or later, you have to deal with specifics.
At this stage, for each particular device, primitives, services, and variables are combined into a configuration model that actually describes the complete configuration of a particular device, only in a vendor-independent manner.
What gives this step? Why not immediately configure the device, which you can simply fill in?
In fact, this allows us to solve three problems:
- Do not adapt to a specific interface for interacting with the device. Whether it is CLI, NETCONF, RESTCONF, SNMP - the model will be the same.
- Do not keep the number of templates / scripts by the number of vendors on the network, and in case of a design change, change the same in several places.
- Download the configuration from the device (backup), lay it out in the exact same model and directly compare the target configuration and the one available for calculating the delta and preparing the configuration patch, which will change only those parts that are necessary or to detect deviations.
As a result of this stage, we get a vendor-independent configuration.
Component 6. Vendor interface specific driver
Do not console yourself with hopes that once you can configure a tsiska it will be possible in the same way as a jumper, just sending them exactly the same calls. Despite the growing popularity of whiteboxes and the emergence of support for NETCONF, RESTCONF, OpenConfig, the specific content that these protocols deliver is different from the vendor to the vendor, and this is one of their competitive differences that they simply won’t give up.
This is about the same as OpenContrail and OpenStack, which have RestAPI as their NorthBound interface, expect completely different calls.
So, at the fifth step, the vendor-independent model should take the form in which it will go to the iron.
And here, all means are good (no): CLI, NETCONF, RESTCONF, SNMP in a simple fall.
Therefore, we need a driver that translates the result of the previous step into the desired format for a particular vendor: a set of CLI commands, an XML structure.
Component 7. The mechanism for delivering configuration to the device
We generated the configuration, but it still needs to be delivered to the devices - and, obviously, not by hand.
Firstly , we are faced with the question, what kind of transport will we use? And the choice today is no longer small:
- CLI (telnet, ssh)
SNMP- NETCONF
- RESTCONF
- REST API
- OpenFlow (although it is knocked out of the list, since this is a way to deliver FIB, not settings)
Let’s dot here with e. CLI is Legacy. SNMP ... hehe.
RESTCONF is still an unknown animal; the REST API is supported by almost no one. Therefore, we will focus on NETCONF in a loop.
In fact, as the reader already understood, we had already decided on the interface at this point - the result of the previous step was already presented in the format of the interface that was selected.
Secondly , with what tools will we do this?
Here the choice is also large:
- Self-written script or platform. We arm ourselves with ncclient and asyncIO and do everything ourselves. What does it cost us to build a deployment system from scratch?
- Ansible with its rich library of network modules.
- Salt with his meager network work and bundle with Napalm.
- Actually Napalm, who knows a couple of vendors and that's all, bye.
- Nornir is another beast that we are preparing for the future.
There is still no favorite chosen - we will stomp.
What else is important here? The consequences of applying the configuration.
Successfully or not. Remained access to the piece of hardware or not.
It seems that commit will help here with confirmation and validation of what was downloaded to the device.
This, combined with the correct implementation of NETCONF, significantly narrows the range of suitable devices - not many manufacturers support normal commits. But this is just one of the prerequisites in RFP . In the end, no one is worried that not a single Russian vendor will pass under the condition of 32 * 100GE interface. Or worries?
Component 8. CI / CD
At this point, we are already ready for all network devices.
I write “for everything” because we are talking about versioning the state of the network. And even if you need to change the settings of just one switch, the changes for the entire network are calculated. Obviously, they can be zero for most nodes.
But, as already mentioned, above, we are not some barbarians in order to roll everything at once into the prod.
The generated configuration must first go through the Pipeline CI / CD.
CI / CD stands for Continuous Integration, Continuous Deployment. This is an approach in which the team publishes a major major release more than once every six months, completely replacing the old one, and regularly Deploment introduces new functionality in small batches, each of which comprehensively tests for compatibility, security and performance (Integration).
To do this, we have a version control system that monitors configuration changes, a laboratory where we check whether the customer service is breaking, a monitoring system that checks this fact, and the last step is to roll out the changes to the production network.
With the exception of debugging teams, absolutely all changes on the network should go through CI / CD Pipeline - this is our guarantee of a quiet life and a long happy career.
Component 9. Backup and rejection system
Well, I don’t have to talk about backups again.
We will simply add them according to the crown or upon the fact of a configuration change in the git.
But the second part is more interesting - someone should keep an eye on these backups. And in some cases, this someone has to go and rotate everything as it was, and in others, meow someone, that the disorder.
For example, if there is a new user who is not registered in the variables, you need to remove him from the hack. And if it’s better not to touch the new firewall rule, maybe someone just turned on debugging, or maybe a new service, a mess, didn’t register according to the rules, but people already went to it.
We still won’t get away from a certain small delta on the scale of the entire network, despite any automation systems and a steel hand of management. To debug problems anyway, no one will bring configuration to the system. Moreover, they may not even be provided for by the configuration model.
For example, a firewall rule for counting the number of packets on a specific IP, for localization of the problem - a completely ordinary temporary configuration.
Component 10. Monitoring System
At first, I was not going to cover the monitoring topic - still a voluminous, controversial and complex topic. But along the way, it turned out that this is an integral part of automation. And you can’t get around it even without practice.
Developing thought is an organic part of the CI / CD process. After rolling out the configuration to the network, we need to be able to determine whether everything is okay with it now.
And it’s not only and not so much about the graphs of using interfaces or host availability, but about more subtle things - the availability of the necessary routes, attributes on them, the number of BGP sessions, OSPF neighbors, End-to-End uptime services.
But did the syslogs on the external server stop folding, did the SFlow agent break down, did the drops in the queues begin to grow, and did the connection between any pair of prefixes break?
In a separate article, we reflect on this.
Conclusion
As a basis, I chose one of the modern data center network designs - L3 Clos Fabric with BGP as the routing protocol.
This time we will build a network on Juniper, because now the JunOs interface is a vanlav.
Let's complicate our lives using only Open Source tools and a multi-vendor network - therefore, apart from the Juniper, along the way I will choose another lucky guy.
The plan for upcoming publications is something like this:
First I will talk about virtual networks. First of all, because I want to, and secondly, because without this, the design of the infrastructure network will not be very clear.
Then about the network design itself: topology, routing, policies.
Let's assemble the laboratory stand.
Let's ponder and maybe practice initializing the device on the network.
And then about each component in intimate details.
And yes, I do not promise to elegantly end this cycle with a ready-made solution. :)
useful links
- Before delving into the series, you should read the book by Natasha Samoilenko Python for network engineers . And, perhaps, take a course .
- It will also be useful to read the RFC about the design of data center factories from Facebook for the authorship of Peter Lapukhov.
- The Tungsten Fabric architecture documentation (formerly Open Contrail) will give you an idea of how the Overlay SDN works .
Thanks
Roman Gorge. For comments and edits.
Artyom Chernobay. For KDPV.