Face Anti-Spoofing or technologically recognize a cheater out of a thousand by face
Biometric identification of a person is one of the oldest ideas for recognizing people, which they generally tried to technically implement. Passwords can be stolen, spied, forgotten, keys can be faked. But the unique characteristics of the person himself is much more difficult to fake and lose. This can be fingerprints, voice, drawing of the vessels of the retina, gait, and more.

Of course, biometrics systems are trying to fool! That's what we’ll talk about today. How attackers try to circumvent facial recognition systems by impersonating another person and how this can be detected.
According to the ideas of Hollywood directors and science fiction writers, it’s quite easy to deceive biometric identification. All that is needed is to present to the system the “required parts” of the real user, either individually or by taking him as a hostage. Or you can “put on the mask” of another person on yourself, for example, using a physical transplant mask or in general, presenting fake genetic traits
In real life, attackers also try to introduce themselves as someone else. For example, rob a bank by wearing a black man's mask, as in the picture below.

Face recognition seems to be a very promising area for use in the mobile sector. If everyone has long been accustomed to using fingerprints, and voice technology is gradually and fairly predictably developing, then with identifying by face the situation is quite unusual and worthy of a little digression into the history of the issue.
How it all began or from fiction to reality
Today's recognition systems demonstrate tremendous accuracy. With the advent of large data sets and complex architectures, it has become possible to achieve face recognition accuracy of up to 0.000001 (one error per million!) And they are now suitable for transfer to mobile platforms. The bottleneck was their vulnerability.
In order to impersonate another person in our technical reality, and not in a film, masks are most often used. They also try to fool the computer system by presenting someone else instead of their face. Masks can be of completely different quality, from the photo of another person printed in the face that they hold in front of the face to very complex three-dimensional masks with heating. Masks can be presented separately in the form of a sheet or screen, and worn on the head.
A lot of attention was drawn to the topic by a successful attempt to deceive the Face ID system on the iPhone X with a rather complicated mask of stone powder with special inserts around the eyes that imitate the warmth of a living face using infrared radiation.
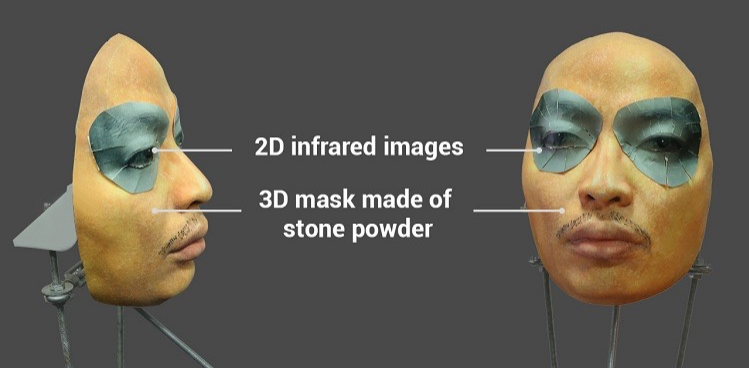
It is alleged that using such a mask it was possible to deceive Face ID on the iPhone X. Video and some text can be found here
The presence of such vulnerabilities is very dangerous for banking or state systems for authenticating a user by face, where the penetration of an attacker entails significant losses.
Terminology
The field of research of face anti-spoofing is quite new and so far cannot even boast even established terminology.
Let us agree to call an attempt to deceive the identification system by presenting it with a fake biometric parameter (in this case, a person) spoofing attack .
Accordingly, a set of protective measures to counter such deception will be called anti-spoofing . It can be implemented in the form of a variety of technologies and algorithms that are built into the conveyor of an identification system.
The ISO offers a slightly expanded set of terminology, with terms such as presentation attack - attempts to force the system to incorrectly identify the user or to enable him to avoid identification by demonstrating a picture, a recorded video, and so on. Normal (Bona Fide) - corresponds to the normal algorithm of the system, that is, everything that is NOT an attack. Presentation attack instrument means a means of attack, for example, an artificial part of the body. And finally, Presentation attack detection- automated means of detecting such attacks. However, the standards themselves are still under development, so it’s impossible to talk about any established concepts. The terminology in Russian is almost completely absent.
To determine the quality of work, systems often use the HTER metric (Half-Total Error Rate - half the total error), which is calculated as the sum of the coefficients of erroneously allowed identifications (FAR - False Acceptance Rate) and erroneously forbidden identifications (FRR - False Rejection Rate), divided in half.
HTER = (FAR + FRR) / 2
It is worth saying that in biometric systems, FAR is usually given the greatest attention, in order to do everything possible to prevent an attacker from entering the system. And they are making good progress in this (remember the one millionth from the beginning of the article?) The flip side is the inevitable increase in FRR - the number of ordinary users mistakenly classified as intruders. If this can be sacrificed for state, defense, and other similar systems, then mobile technologies that work with their enormous scale, a variety of subscriber devices and, in general, user-perspective-oriented ones are very sensitive to any factors that can cause users to refuse services. If you want to reduce the number of phones smashed against the wall after the tenth consecutive refusal of identification, you should pay attention to FRR!
Types of attacks. Cheat system

Let us finally find out exactly how the attackers cheat the recognition system, as well as how this can be opposed.
The most popular means of cheating are masks. There is nothing more obvious than putting on another person’s mask and presenting your face to an identification system (often referred to as a Mask attack).
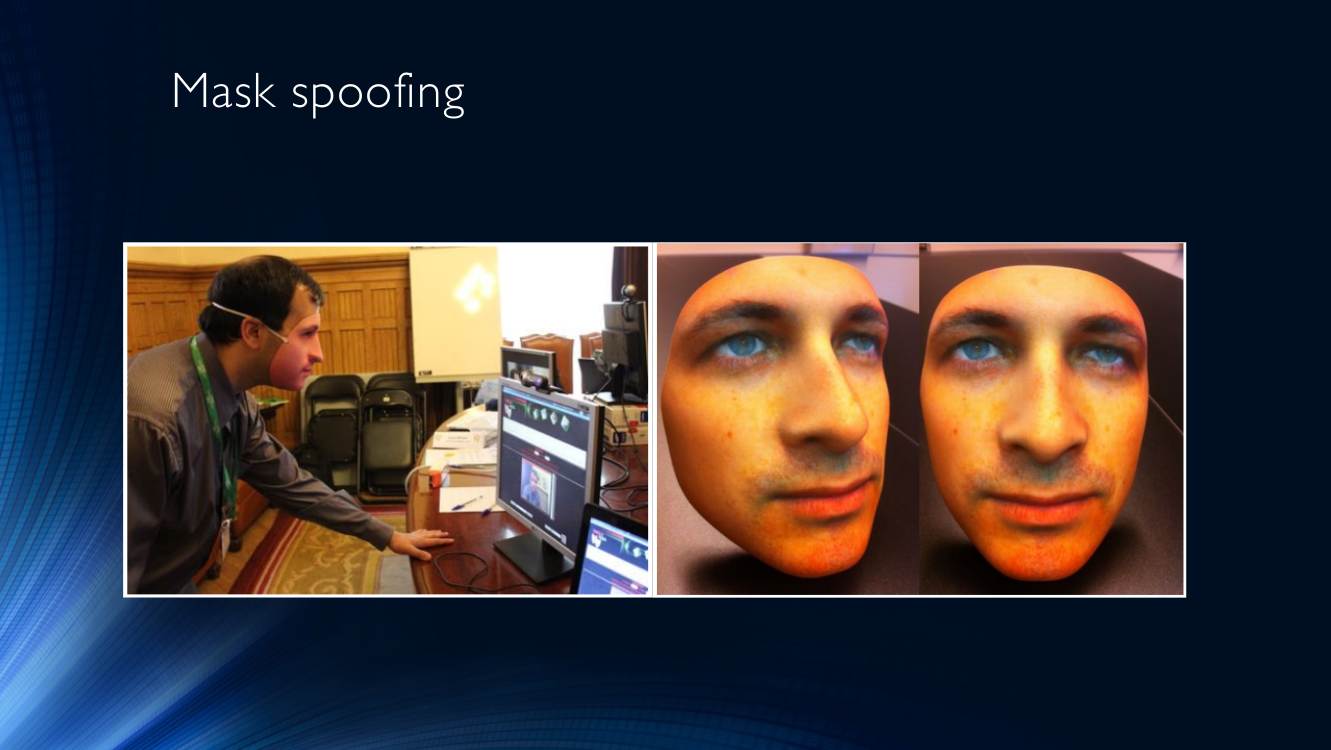
You can also print a photo of yourself or someone else on a piece of paper and bring it to the camera (let's agree to call this type of attack Printed attack).

A little more complicated is the Replay attack, when the system is presented with the screen of another device, on which a previously recorded video with another person is played. The complexity of the execution is compensated by the high efficiency of such an attack, since control systems often use signs based on the analysis of time sequences, for example, tracking blinking, micromotion of the head, the presence of facial expressions, breathing, and so on. All this can be easily reproduced on video.

Both types of attacks have a number of characteristic features that make it possible to detect them, and thus distinguish between a tablet screen or a sheet of paper from a real person.
We summarize the characteristic features that allow us to determine these two types of attacks in a table:
| Printed attack | Replay attack |
|---|---|
| Decrease in quality of the image texture when printing | Moire |
| Artifacts of halftone transmission when printing on a printer | Reflections (highlights) |
| Mechanical print artifacts (horizontal lines) | Flat picture (lack of depth) |
| Lack of local movements (e.g. blinking) | Image borders may be visible. |
| Image borders may be visible. |
Attack Detection Algorithms. Good old classic

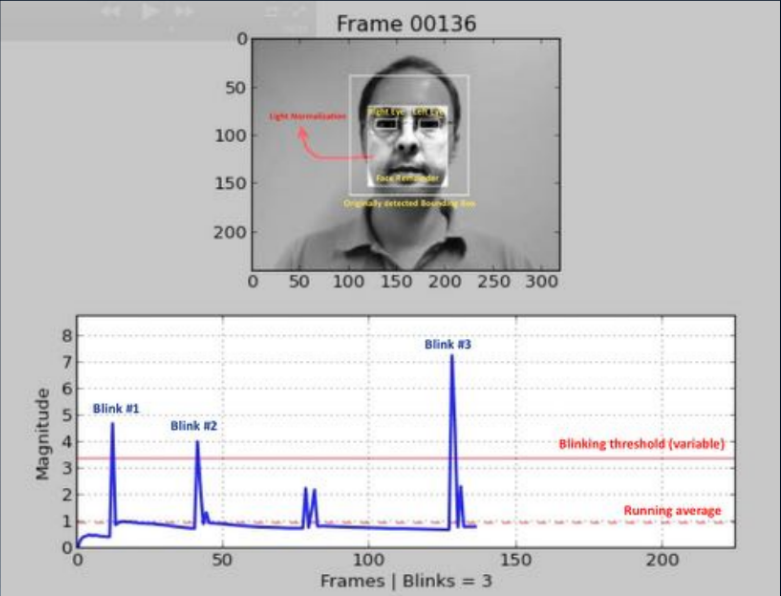
One of the oldest approaches (2007, 2008) is based on the detection of human blinks by analyzing the image using a mask. The point is to build some kind of binary classifier that allows you to select images with open and closed eyes in a sequence of frames. This can be an analysis of the video stream using the identification of parts of the face (landmark detection), or the use of some simple neural network. And today, this method is most often used; the user is prompted to perform some sequence of actions: turn your head, wink, smile, and more. If the sequence is random, it is not easy for an attacker to prepare for it in advance. Unfortunately, for an honest user, this quest is also not always surmountable, and engagement drops sharply.
You can also use the features of deterioration in picture quality when printing or playing on the screen. Most likely, even some local patterns, even elusive by the eye, will be detected in the image. This can be done, for example, by counting local binary patterns (LBP, local binary pattern) for different areas of the face after selecting it from the frame ( PDF) The described system can be considered the founder of the entire direction of face anti-spoofing algorithms based on image analysis. In a nutshell, when calculating the LBP, each pixel in the image, eight of its neighbors are sequentially taken and their intensity is compared. If the intensity is greater than on the central pixel, one is assigned, if less, zero. Thus, for each pixel an 8-bit sequence is obtained. Based on the obtained sequences, a per-pixel histogram is constructed, which is fed to the input of the SVM classifier.
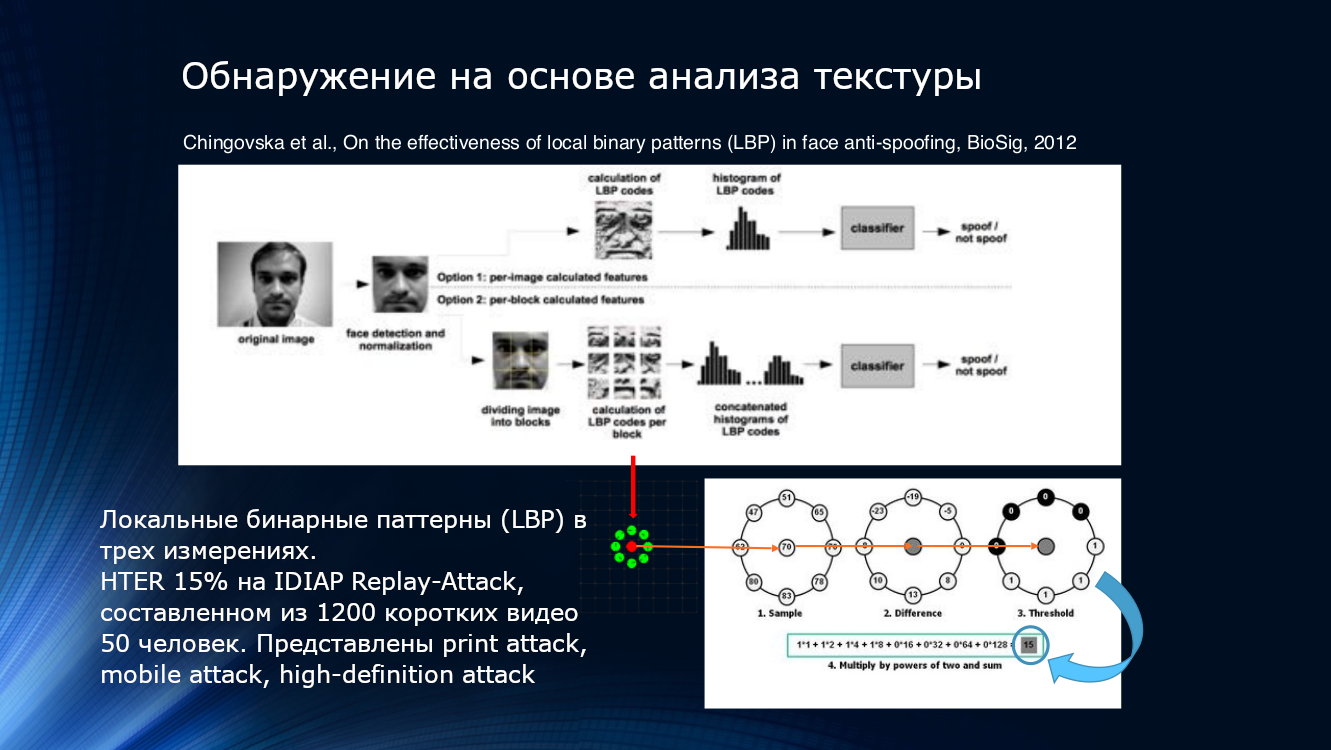
Local binary patterns, histogram and SVM. You can join the timeless classics here
The HTER efficiency indicator is “as much as” 15%, and means that a significant part of attackers overcome protection without much effort, although it should be recognized that a lot is eliminated. The algorithm was tested on the IDIAP Replay-Attack dataset, which is composed of 1200 short videos of 50 respondents and three types of attacks - printed attack, mobile attack, high-definition attack.
Ideas for analyzing image texture have been continued. In 2015, Bukinafit developed an algorithm for alternatively dividing the image into channels, in addition to traditional RGB, for the results of which local binary patterns were again calculated, which, as in the previous method, were fed to the input of the SVN classifier. HTER accuracy calculated on CASIA and Replay-Attack datasets was impressive at that time 3%.
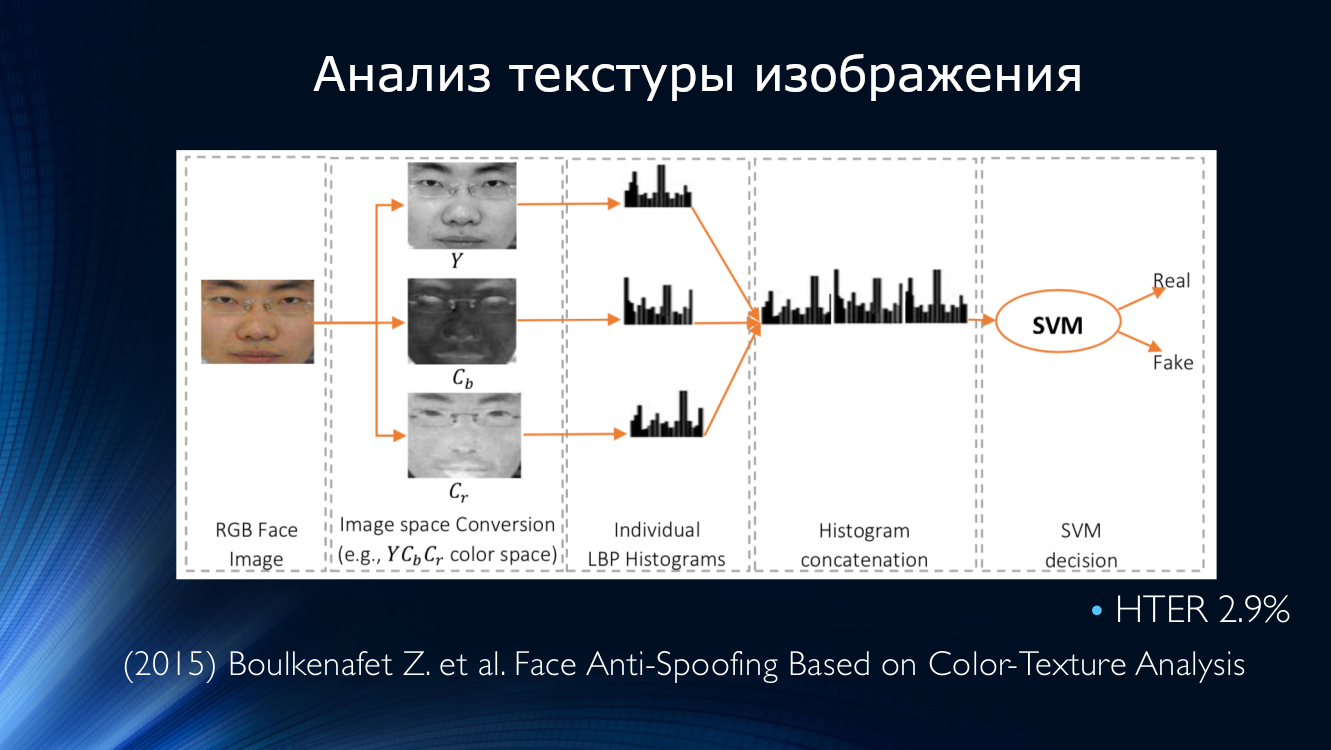
At the same time, work appeared to detect moire. Patel published an article where he suggested looking for image artifacts in the form of a periodic pattern caused by the overlap of two scans. The approach turned out to be workable, showing HTER about 6% on the IDIAP, CASIA and RAFS datasets. It was also the first attempt to compare the performance of an algorithm on different data sets.

Periodic pattern in the image caused by overlay sweeps
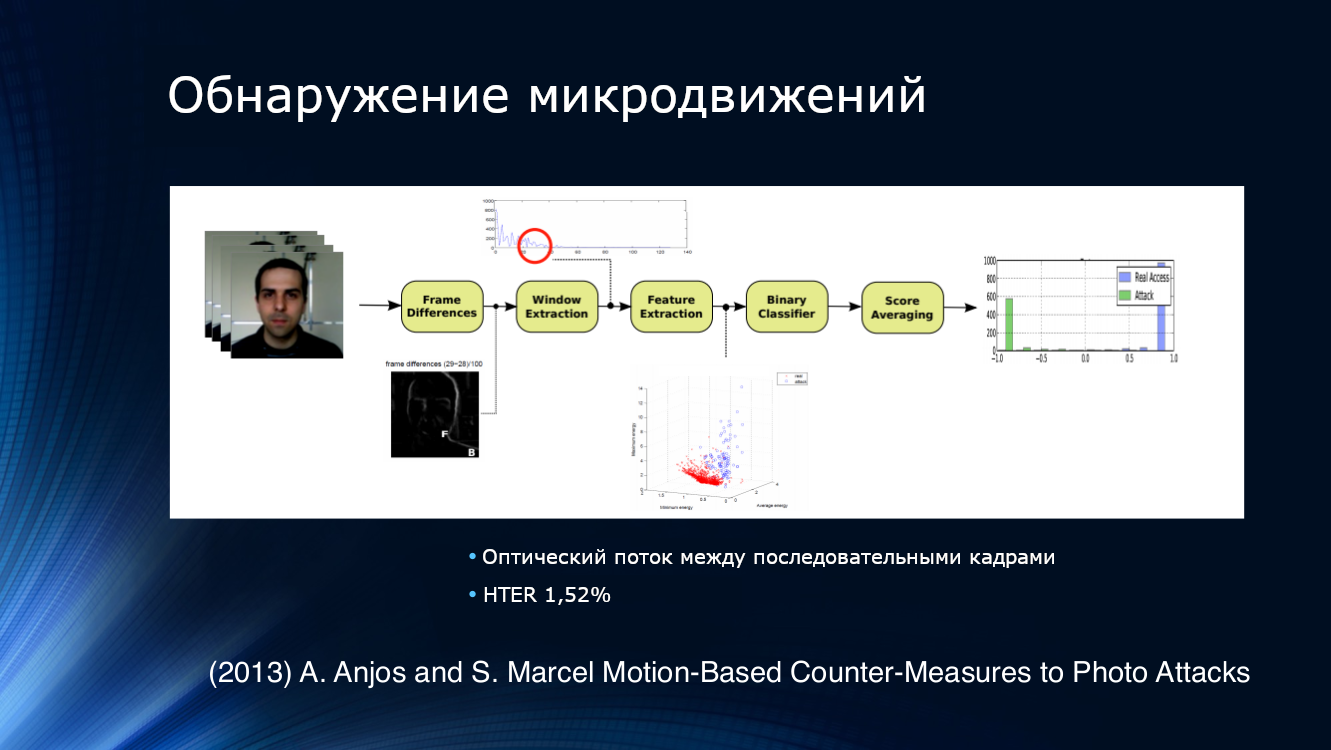
To detect attempts to present a photo, the logical solution was to try to analyze not one image, but their sequence taken from the video stream. For example, Anjos and colleagues suggested isolating features from the optical stream in adjacent pairs of frames, feeding the binary classifier to the input, and averaging the results. The approach turned out to be quite effective, demonstrating a HTER of 1.52% on their own data set.
An interesting method for tracking movements, which is somewhat aloof from conventional approaches. Since in 2013 the principle “applying a raw image to the input of the convolutional network and adjusting the grid layers to obtain the result” was not usual for modern deep learning projects, Bharadjw consistently applied more complex preliminary transformations. In particular, he applied the Eulerian video magnification algorithm known for the work of scientists from MIT, which was successfully used to analyze color changes in the skin depending on the pulse. I replaced LBP with HOOF (histograms of optical flow directions), having correctly noticed that since we want to track movements, we need the appropriate signs, and not just texture analysis. All the same SVM, traditional at that time, was used as a classifier. The algorithm showed extremely impressive results on Print Attack (0%) and Replay Attack (1.25%) datasets.

Let's already learn the grid!

From some point it became obvious that the transition to deep learning had matured. The notorious “deep learning revolution” overtook face anti-spoofing.
The “first swallow” can be considered a method of analyzing depth maps in individual sections (“patches”) of an image. Obviously, a depth map is a very good sign for determining the plane in which the image is located. If only because the image on the sheet of paper has no “depth” by definition. In the work of AtaumIn 2017, many individual small sections were extracted from the image; depth maps were calculated for them, which then merged with the depth map of the main image. It was pointed out that ten random face image patches are enough to reliably identify Printed Attack. In addition, the authors poured together the results of two convolutional neural networks, the first of which calculated depth maps for patches, and the second for the image as a whole. When training on data sets, the Printed Attack class was associated with a depth map of zero, and with a three-dimensional model of the face, a series of randomly selected sections. By and large, the depth map itself was not so important, only a certain indicator function was used from it, which characterizes the “depth of the section”. The algorithm showed a HTER value of 3.78%.

Unfortunately, the availability of a large number of excellent frameworks for deep learning has led to the emergence of a huge number of developers who are trying “head-on” to solve the problem of face anti-spoofing in a well-known way of assembling neural networks. Usually it looks like a stack of feature cards at the outputs of several networks pre-trained on some widespread dataset that is fed to a binary classifier.
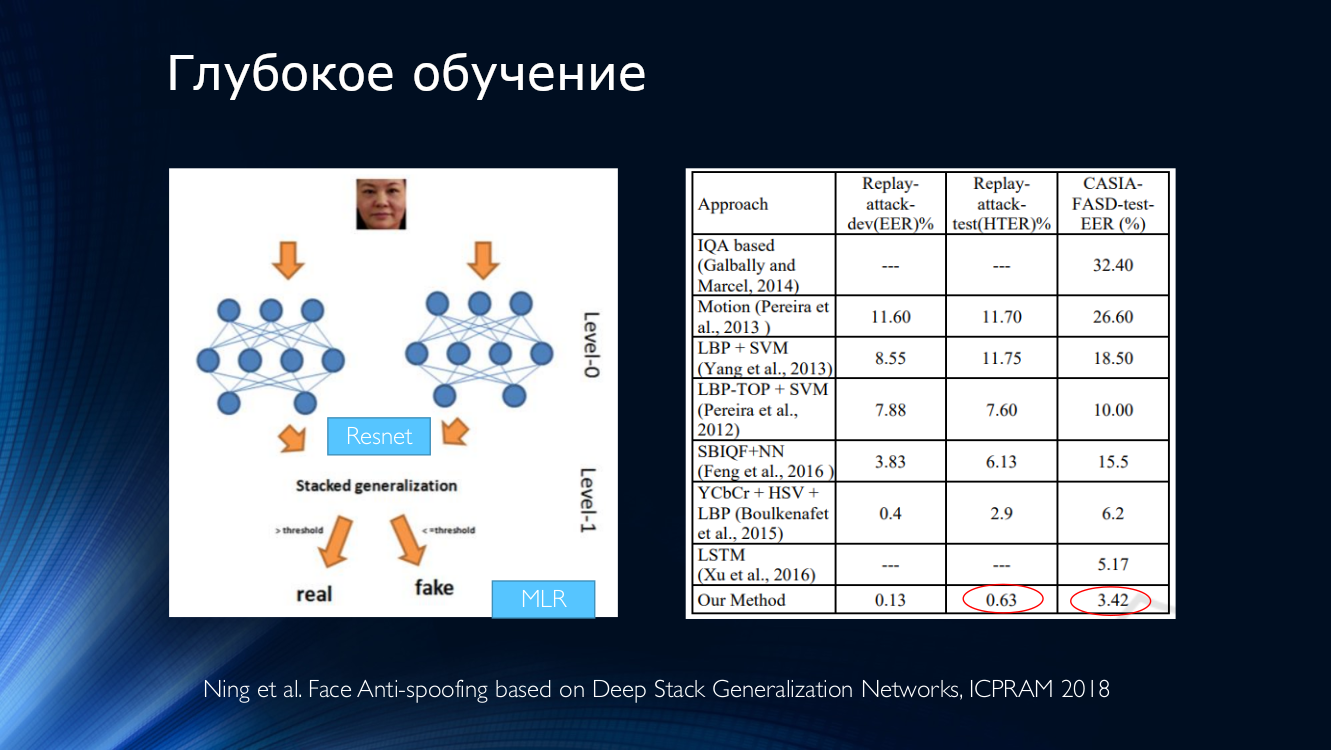
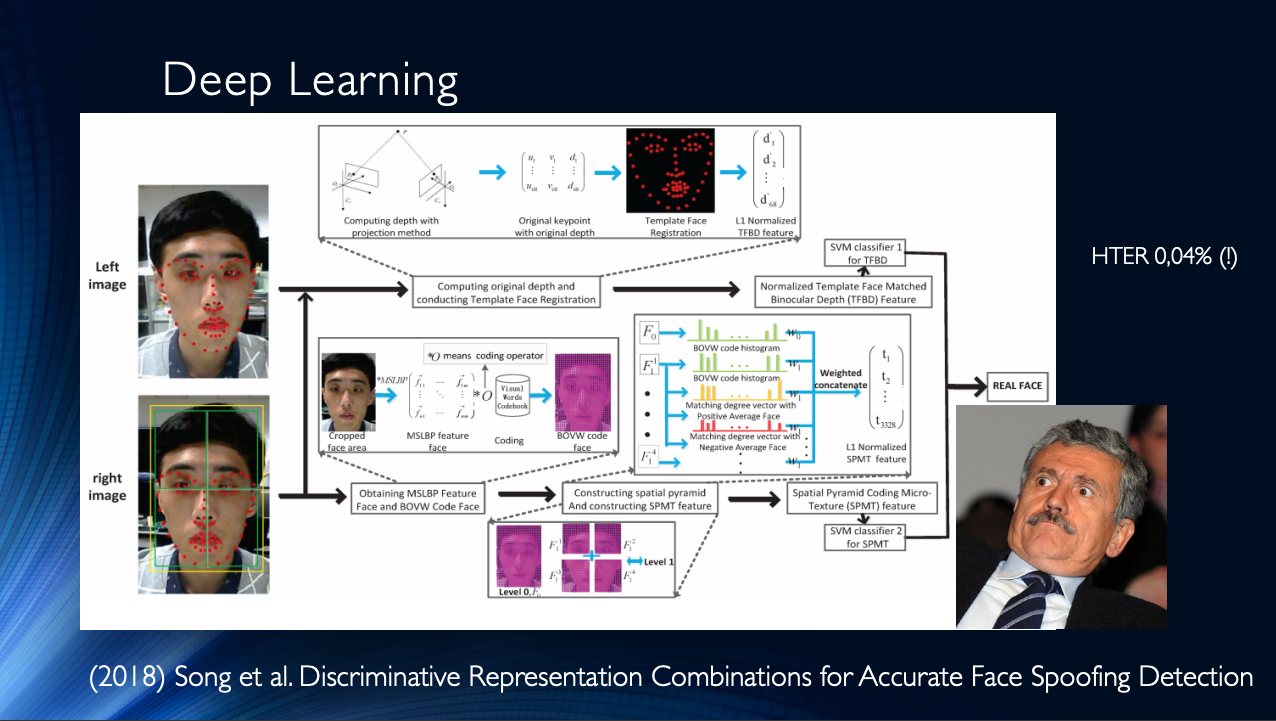
In general, it is worth concluding that to date, quite a few works have been published, which generally show good results, and which are united by only one small “but”. All these results are demonstrated in one specific dataset! The situation is aggravated by the limited availability of data sets, and, for example, at the notorious Replay-Attack it is no surprise to HTER 0%. All this leads to the emergence of very complex architectures, such as these , using various ingenious features, auxiliary algorithms stacked, with several classifiers, the results of which are averaged, and so on ... The authors get HTER = 0.04% at the output!
This suggests that the face anti-spoofing problem has been solved within a specific dataset. We bring to the table various modern methods based on neural networks. It is easy to see that the "reference results" were achieved by a variety of methods that only arose in the inquisitive minds of developers.
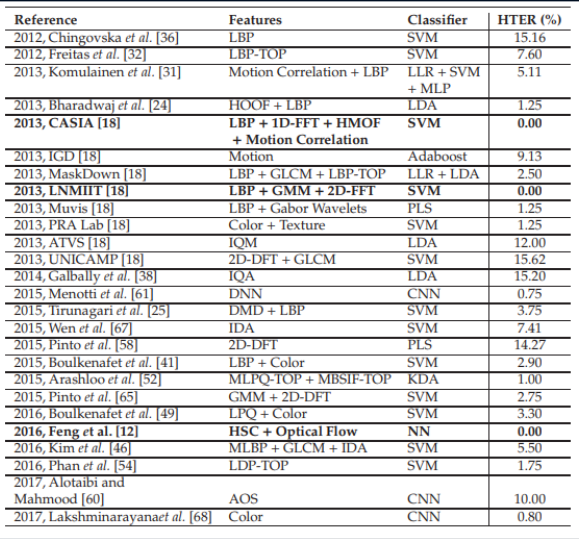
Comparative results of various algorithms. The table is taken from here .
Unfortunately, the same “small” factor violates the good picture of the struggle for tenths of a percent. If you try to train the neural network on one data set and apply it on another, then the results will be ... not so optimistic. Worse, attempts to apply classifiers in real life leave no hope at all.
As an example, we take the data from 2015, where a metric of its quality was used to determine the authenticity of the presented image. Take a look for yourself:
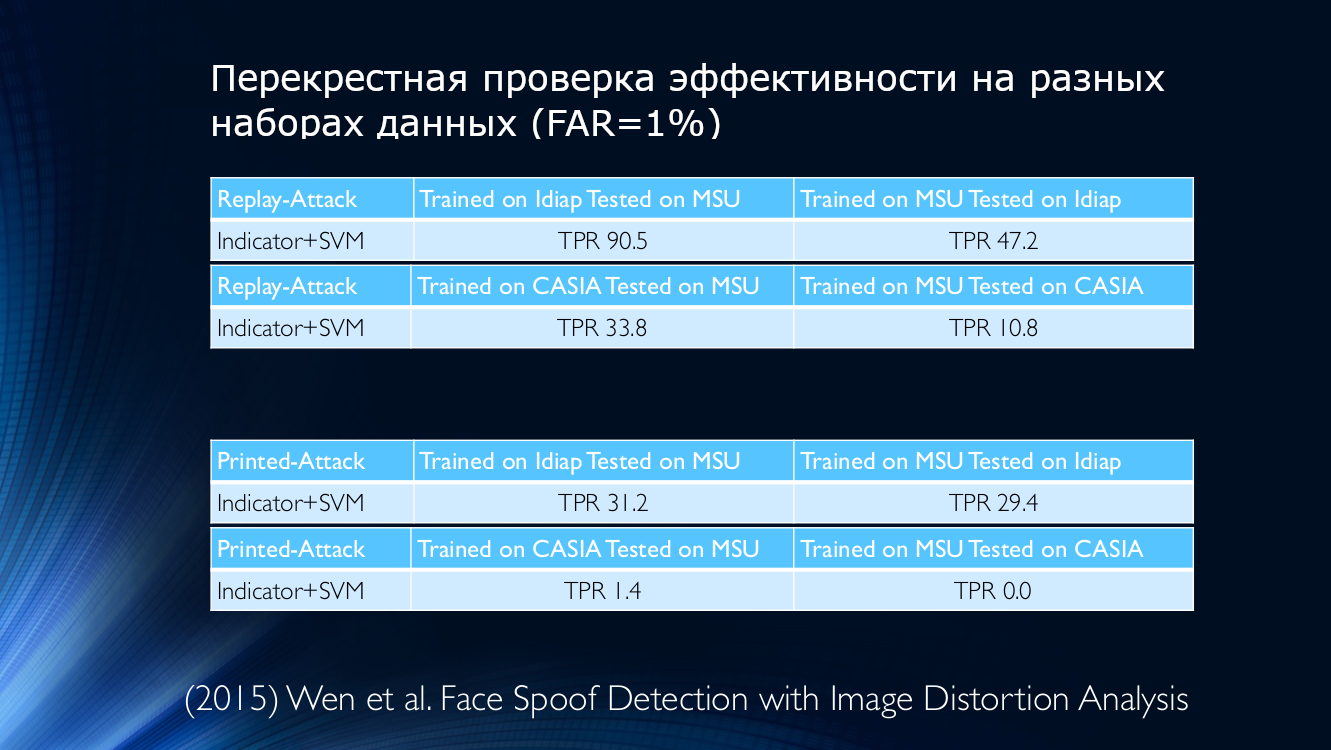
In other words, an algorithm trained on Idiap data, but applied on MSU, will give a true positive detection rate of 90.5%, and if you do the opposite (train on MSU and test on Idiap), then only 47.2 can be determined correctly % (!) For other combinations, the situation worsens even more, and, for example, if you train the algorithm on MSU and check it on CASIA, then TPR will be 10.8%! This means that a huge number of honest users were mistakenly assigned to the attackers, which cannot but be depressing. Even cross-database training was unable to reverse the situation, which seems to be a perfectly reasonable way out.
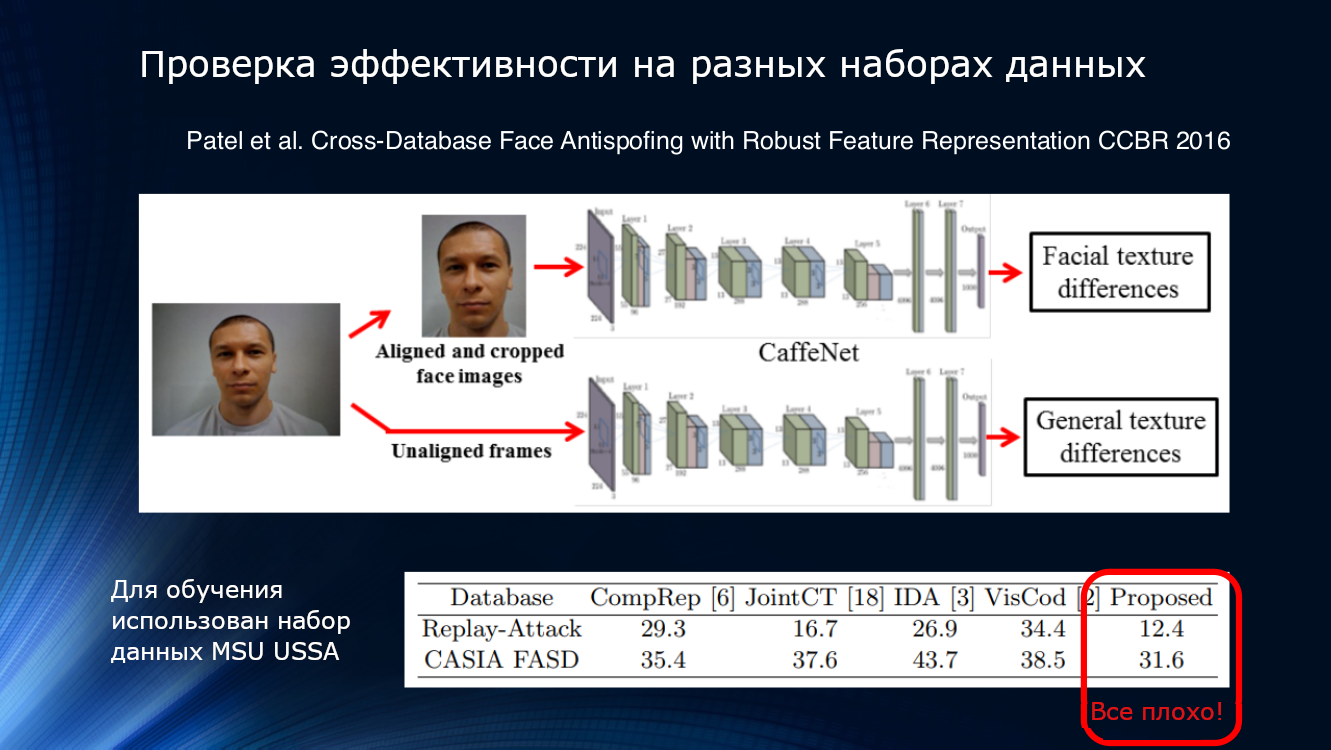
Let's see more. The results presented in Patel's 2016 article show that even with fairly complex processing pipelines and the selection of reliable features such as blinking and texture, results on unfamiliar data sets cannot be considered satisfactory. So, at some point it became quite obvious that the proposed methods are desperately not enough to summarize the results.
And if you arrange a competition ...
Of course, in the field of face anti-spoofing was not without competition. In 2017, a competition was held at the University of Oulu in Finland on its own new data set with quite interesting protocols, oriented specifically to use in the field of mobile applications.
Protocol 1: There is a difference in lighting and background. Datasets are recorded in various places and differ in background and lighting.
-Protocol 2: Various models of printers and screens were used for attacks. So, in the verification data set, a technique is used that is not found in the training set
Protocol 3: Interchangeability of sensors. Real user videos and attacks are recorded on five different smartphones and used in a training dataset. To test the algorithm, video is used from another smartphone, which is not included in the training set.
Protocol 4: includes all of the above factors.
The results were quite unexpected. As in any competition, there was no time to come up with brilliant ideas, so almost all participants took familiar architectures and refined them with fine-tuning, working with signs and trying to somehow use other data sets for training. The prize decision showed an error on the fourth, most complex protocol, about 10%. A brief description of the winning algorithms in the table below:
GRADIENT
- Characteristics are merged by color (using HSV and YCbCr color spaces), texture, and movement.
- Dynamics information is extracted from a given video sequence and time-change maps in a separate frame.
- This sequence is separately applied across all channels in the HSV and YCbCr color spaces, giving together a pair of three-channel images. For each image, the ROI (region-of-interest) is cropped based on the position of the eyes in the sequence of frames and is scaled to 160 × 160 pixels.
- Each ROI is divided into 3 × 3 and 5 × 5 rectangular areas, along which uniform LBP histograms of features are extracted, which are combined into two feature vectors of dimension 6018.
- By using the Recursive Feature Elimination, the dimension is reduced from 6018 to 1000.
- For each feature vector, SVM-based classification is performed, followed by averaging.
Szcvi
- A frame sample is extracted from each video, every sixth is taken
- Scaling frames to 216 × 384
- Five VGG-like layers
- The results of individual frames within the sample are averaged
Recod
- SqueezeNet is studying at Imagenet
- Transfer learning on two data sets: CASIA and UVAD
- First, the face is detected and scaled to 224 × 224 pixels. About every seventh frame, which is sent to ten CNNs, is extracted from each video of the training dataset.
- To obtain the final result, the indicators of individual frames are averaged.
- To improve efficiency, the obtained indicators are summarized in the generalized result of the basic method
CPqD
- ImageNet trained Inception-v3 network
- Sigmoid activation function
- Based on the determination of the position of the eyes, image sections containing the face are cropped, which are then scaled to 224 × 224 RGB |
It is clearly seen that there are not many new ideas. All the same LBP, pre-trained grids, texture and color analysis, pairwise frame analysis, etc. GRADIANT looks the most competently designed from a system point of view, it mixes various characters, is working in different color spaces, signs are being cleaned. He won the competition.
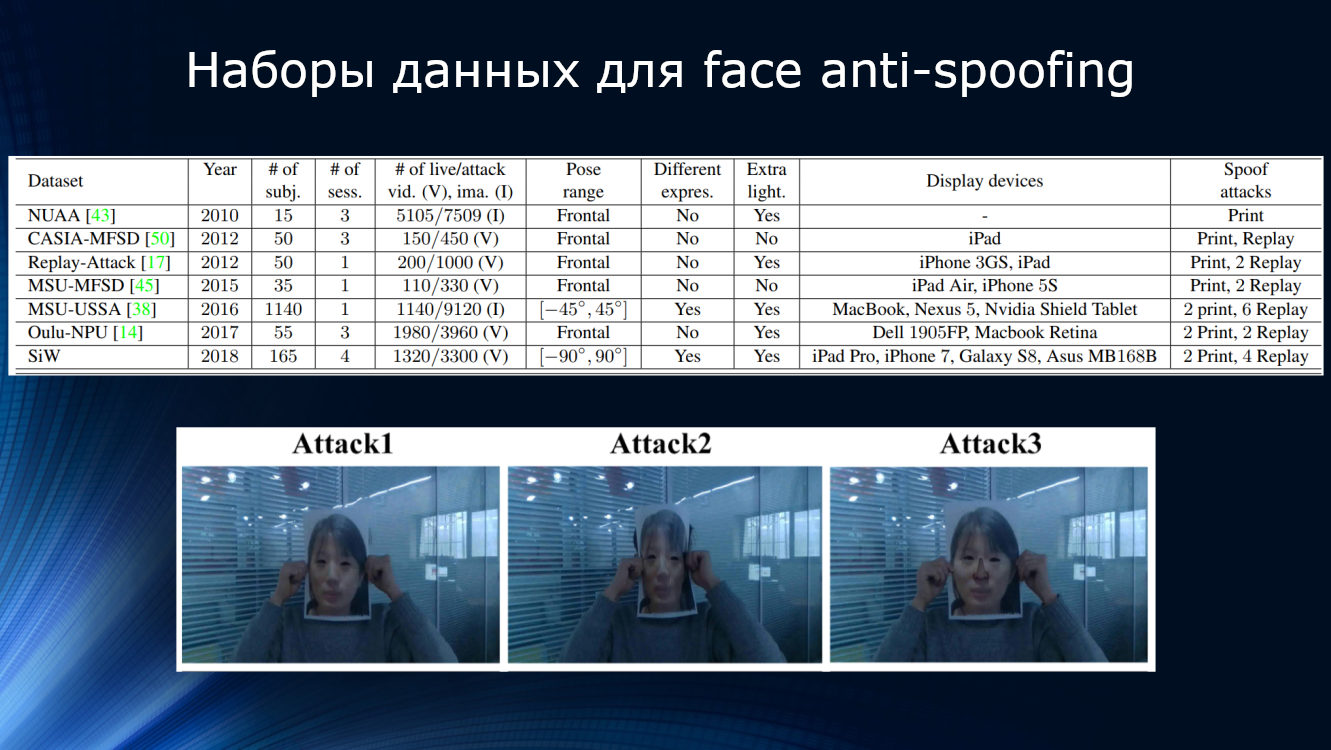
The competition very clearly showed the existing limitations. First of all, it is the limited and unbalanced existing training datasets. Firstly, they represent a fairly limited number of people (from 15 people in the NUAA to 1140 in the MSU-USSA) and sessions, the difference in ambient light, facial expressions, recording devices used, shooting angles and types of attacks. Moreover, in real conditions, the camera model, the quality of the matrix, shooting conditions, focal length and shutter speed, background and environment are often crucial for image analysis. Secondly, the analysis methods themselves are much more focused on the analysis of individual parts of the image without significant processing of the scene itself. For example, in the CASIA kit, many examples of attacks are presented as an image of a person holding a photograph in front of him. Obviously
Recently, another promising competition was proposed on a new 30 GB in-house dataset. According to the terms of the competition, the detection of a mask worn on the face, the fact of shooting a printed photograph and presenting a video on the screen instead of a real person, must be performed. It is likely that according to its results we will see a conceptually new solution.
Of course, there are solutions based on "non-standard approaches." We turn to them with the hope of improving the current state of affairs. For example, it was suggesteduse the method of remote photoplethysmography (rPPG - remote photoplethysmography), which allows you to detect the heartbeat of a person in a video image. The idea is that when light enters a person’s live face, part of the light will be reflected, part will be scattered, and part will be absorbed by the skin and tissues of the face. In this case, the picture will be different depending on the degree of tissue fullness with blood. Thus, it is possible to track the pulsation of blood in the vessels of the face and, accordingly, detect the pulse. Of course, if you cover your face with a mask or show the phone screen, you will not be able to detect any ripple. On this principle, Liu et al proposed to split the face image into sections, to detect the pulse by remote photoplethysmography,


The work showed a HTER value of about 10%, confirming the principal applicability of the method. There are several other works confirming the promise of this approach
(CVPR 2018) by JH-Ortega et al. Time Analysis of Pulsebased Face Anti-Spoofing in Visible and NIR
(2016) X. Li. et al. Generalized face anti-spoofing by detecting pulse from face videos
(2016) J. Chen et al. Realsense = real heart rate: Illumination invariant heart rate estimation from videos
(2014) HE Tasli et al. Remote PPG based vital sign measurement using adaptive facial regions
In 2018, Liu and colleagues at the University of Michigan proposed abandoning the binary classification in favor of the approach they called “binary supervision” —that is, using a more complex estimate based on depth maps and distance photoplethysmography. For each of these facial images, a three-dimensional model was reconstructed using a neural network.and called her with a depth map. Fake images were assigned a depth map consisting of zeros, in the end it's just a piece of paper or a device screen! These characteristics were taken as “truth”; neural networks were trained on their own SiW dataset. Then, a three-dimensional face mask was superimposed on the input image, a depth map and a pulse were calculated for it, and all this was tied together in a rather complicated conveyor. As a result, the method showed an accuracy of about 10 percent on the OULU competitive dataset. It is interesting that the winner of the competition organized by the University of Oulu built the algorithm on binary classification patterns, blinking tracking and other “designed by hand” signs, and its solution also had an accuracy of about 10%. The gain was only about half a percent! The new combined technology is supported by the fact that the algorithm was trained on its own data set and tested on OULU, improving the winner's result. This indicates a certain portability of the results from the dataset to the dataset, and what the hell is not joking, it is possible for real life. However, when trying to perform training on other datasets - CASIA and ReplayAttack, the result was again about 28%. Of course, this exceeds the performance of other algorithms when training on different data sets, but with such accuracy values, there can be no talk of any industrial use! while trying to perform training on other datasets - CASIA and ReplayAttack, again the result was about 28%. Of course, this exceeds the performance of other algorithms when training on different data sets, but with such accuracy values, there can be no talk of any industrial use! while trying to perform training on other datasets - CASIA and ReplayAttack, again the result was about 28%. Of course, this exceeds the performance of other algorithms when training on different data sets, but with such accuracy values, there can be no talk of any industrial use!
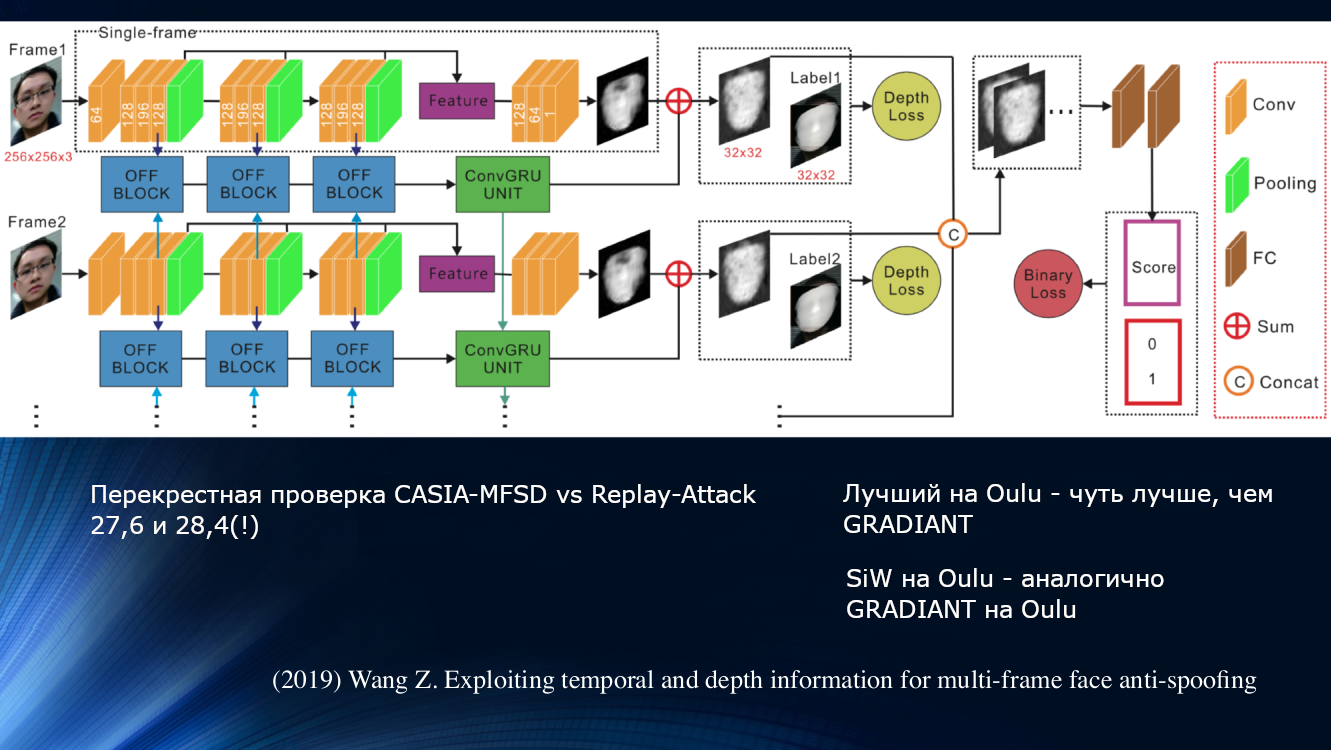
A different approach was proposed by Wang and colleagues in a recent work of 2019. It was noted that in the analysis of micromotion of the face, rotations and displacements of the head are noticeable, leading to a characteristic change in the angles and relative distances between the signs on the face. So when the face is shifted horizontally, the angle between the nose and ear increases. But, if you shift a sheet of paper with a picture in the same way, the angle will decrease! For illustration, it is worth quoting a drawing from the work.
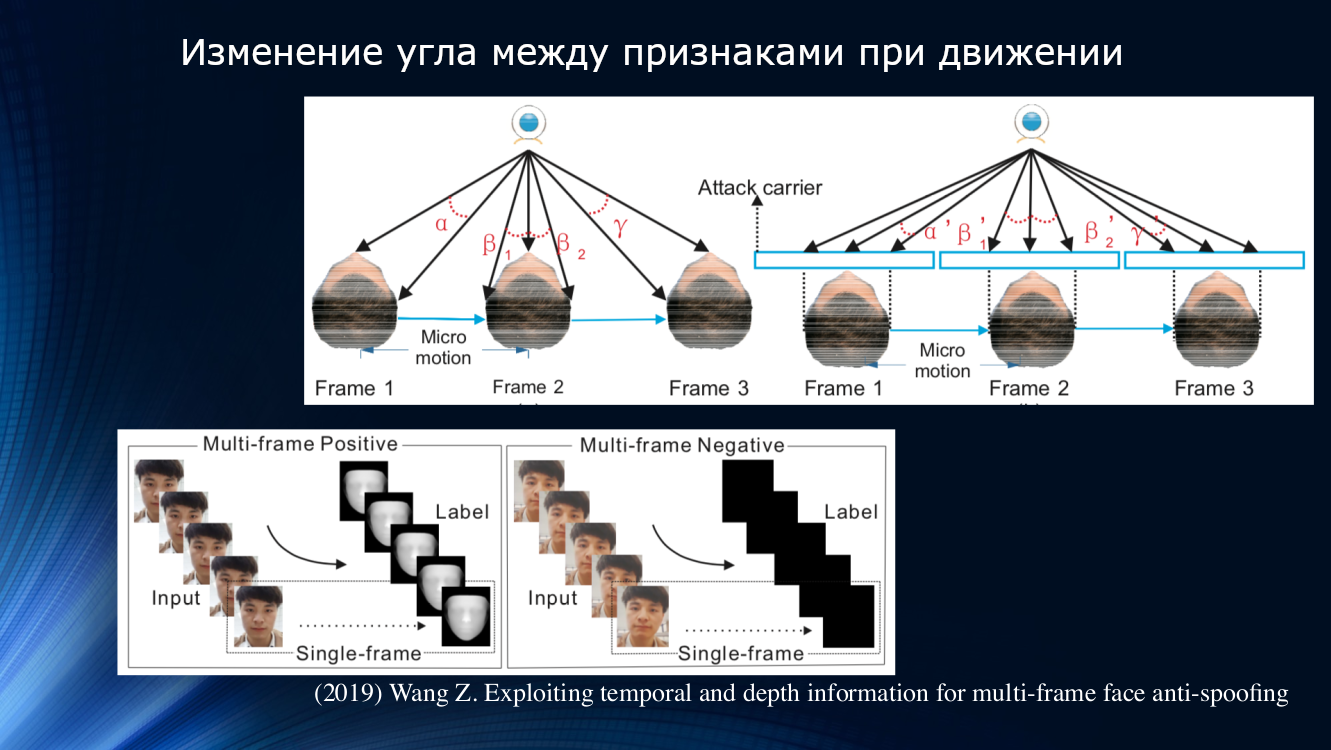
On this principle, the authors built a whole learning unit for transferring data between layers of a neural network. It took into account “incorrect offsets” for each frame in a sequence of two frames, and this allowed the results to be used in the next block of long-term dependency analysis based on the GRU Gated Recurrent Unit . Then all the signs were concatenated, the loss function was calculated, and the final classification was performed. This allowed us to slightly improve the result on the OULU dataset, but the problem of dependence on the training data remained, since for the CASIA-MFSD and Replay-Attack pair, the indicators were 17.5 and 24 percent, respectively.
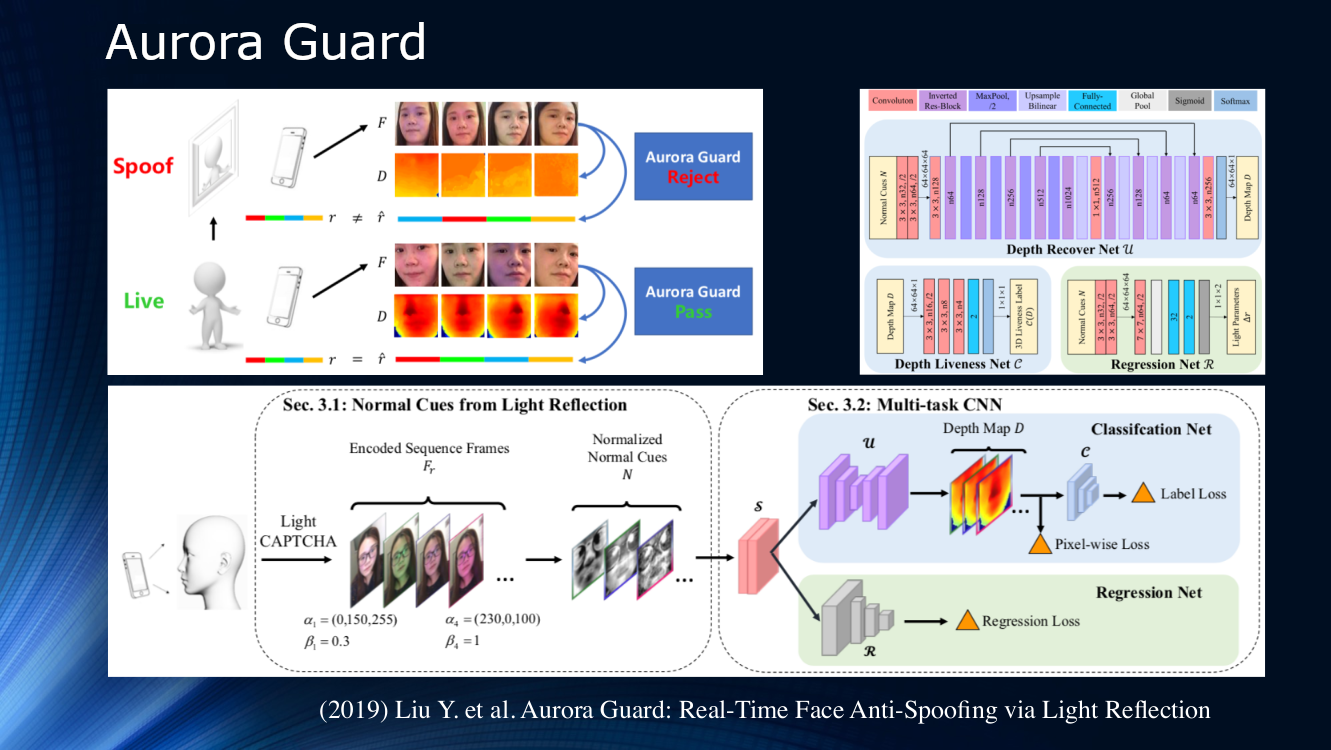
Toward the curtain it’s worth noting the workTencent experts who proposed changing the way the original video image was received. Instead of passively observing the scene, they suggested dynamically lighting up the face and reading reflections. The principle of active irradiation of an object has long been used in location systems of various kinds, therefore, its use to study the face looks very logical. Obviously, for reliable identification in the image itself there are not enough signs, and lighting the screen of a phone or tablet with a sequence of light symbols (light CAPTCHA according to the terminology of the authors) can greatly help. Next, the difference in scattering and reflection over a pair of frames is determined, and the results are fed to a multitask neural network for further processing using a depth map and calculating various loss functions. At the end, a regression of normalized light frames is performed. The authors did not analyze the generalizing ability of their algorithm on other data sets and trained it on their own private dataset. The result is about 1% and it is reported that the model has already been deployed for real use.
Until 2017, the face anti-spoofing area was not very active. But 2019 has already presented a whole series of works, which is associated with the aggressive promotion of mobile facial identification technologies, primarily by Apple. In addition, banks are interested in facial recognition technologies. Many new people have come to the industry, which allows us to hope for quick progress. But so far, despite the beautiful titles of publications, the generalizing ability of the algorithms remains very weak and does not allow us to talk about any suitability for practical use.
Conclusion And finally, I’ll say that ...
- Local binary patterns, tracking blinking, breathing, movements and other manually designed signs have not lost their significance at all. This is primarily due to the fact that deep training in the field of face anti-spoofing is still very naive.
- It is clear that in the “same” solution, several methods will be merged. Analysis of reflection, scattering, depth maps should be used together. Most likely, the addition of an additional data channel will help, for example, voice recording and some system approaches that will allow you to collect several technologies into a single system
- Almost all the technologies used for face recognition find application in face anti-spoofing (cap!) Everything that was developed for face recognition, in one form or another, has found application for attack analysis
- Existing datasets have reached saturation. Out of ten basic data sets in five, zero error was achieved. This already speaks, for example, of the efficiency of methods based on depth maps, but does not allow improving the generalizing ability. We need new data and new experiments on them
- There is a clear imbalance between the degree of facial recognition and face anti-spoofing. Recognition technologies are significantly ahead of protection systems. Moreover, it is the lack of reliable protection systems that inhibits the practical use of face recognition systems. It so happened that the main focus was on face recognition, and the attack detection systems remained somewhat aloof
- There is a strong need for a systematic approach in the field of face anti-spoofing. The past competition of the University of Oulu showed that when using a non-representative data set, it is quite possible to defeat with a simple competent adjustment of the established solutions, without developing new ones. Perhaps a new competition can turn the tide
- With increasing interest in the subject and the introduction of facial recognition technologies by large players, “windows of opportunity” appeared for new ambitious teams, since there is a serious need for a new solution at the architectural level