Introduction to Genomics for Programmers
- Transfer
About the author. Andy Thomason is a leading Genomics PLC programmer . Since the 70s he has been engaged in graphic systems, games and compilers; specialization - code performance.
The human genome consists of two copies of approximately 3 billion base pairs of DNA, the letters A, C, G, and T are used for coding. These are about two bits for each base pair:
3,000,000,000 × 2 × 2/8 = 1,500,000 000 or about 1.5 GB of data.
In fact, these copies are very similar, and the DNA of all people is almost the same: from Wall Street traders to Australian Aborigines.
There are a number of “reference genomes,” such as Ensembl Fasta files . Reference genomes help build a map with specific characteristics that are present in human DNA, but are not unique to specific people.
For example, we can determine the “location” of a gene that encodes a BRCA2 protein, which is responsible for DNA repair in breast cancer:this gene .
It is located on chromosome 13, starting from position 32315474 to 32400266.
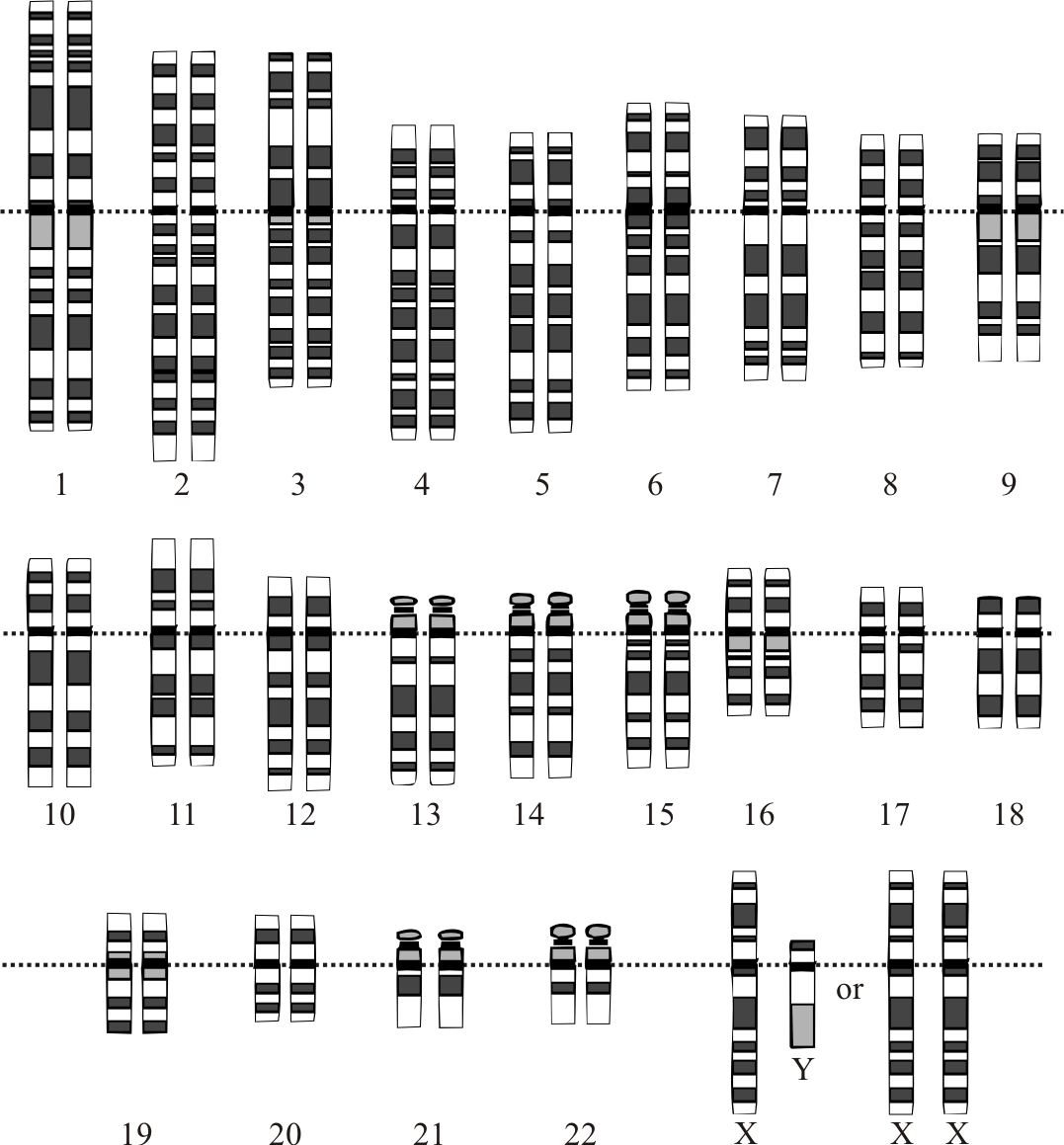
People are so similar that it’s usually enough to store a small set of “variations” to represent a person.
Over time, our DNA is damaged by cosmic rays and copying errors, so the DNA that parents pass on to their children is slightly different from their own.
Recombination mixes the genes even more, so the child’s DNA inherits from each parent a mixture of DNA from grandparents on this side.
Therefore, for every change in our DNA, it is enough to save only the differences from the reference genome. Usually they are saved in a VCF (Variant Call Format) file.
Like almost all files in bioinformatics, it is a TSV file type (text format with tab separation).
You can get your own VCF file from companies like 23 and Me andAncestry.com : pay relatively little money and send a sample that is sequenced on a DNA microchip. It highlights fragments where the DNA matches the expected sequences.
A shortened example from the VCF specifications :
Here we have three people with the names NA00001, NA00002 and NA00003 (we in the genetics world take security of personal data very seriously), who have certain differences in position 14370 of chromosome 20
There are two numbers per person, since we all have two copies of chromosome 20 (one from each parent; the only exception is sex chromosomes). I’m not lucky that I have only one X chromosome, so I inherited color blindness from my grandfather through my mother).
The following options are possible:
VCF files are considered “phased” if you can find out on which particular chromosome the variant is located, or at least where it is located relative to its neighbors. In practice, it’s hard to say which chromosome DNA came from, so you have to guess!
Thus, we have a bit vector
Using this bit vector, we can try to find out which parts of the genome affect diseases or other individual properties, such as hair color or growth. For each variant, we construct a haplotype for the measured traits ( phenotype ).
GWAS (Genome wide association study) is the basis for genetic analysis of variants. It compares variations with observational data.
For instance:
Note that each has two haplotypes, because we have pairs of chromosomes.
Here we see that options 1 are associated with higher growth, and the values correspond to linear regression:
In practice, there is really a lot of noise in the data, and the error is usually greater than
The easiest way to perform a regression is to apply the Moore - Penrose inversion .
We compose a 2 × 2 covariance matrix with the scalar product of two vectors, and we solve the problem by the least squares method.
We have trillions of data points, so it’s important to do this efficiently.
Since we inherit large fragments of the genome from our parents, certain areas of DNA look very similar: they are much more similar than what the case dictates.
This is good for us, because genes continue to work just like their ancestors, but bad for genomics researchers. This means that the differences are not enough to determine the variations that caused the phenotype to change.
Non-equilibrium linkage (LD) determines how similar two vectors are to variations.
It calculates a value between -1 and 1, where
To determine the similarity of variations, we create large square LD matrices for specific places in the genome. In practice, many of the variations around this place are almost identical to the middle variant.
The matrix looks something like this, with large squares of similarity.
Actual values are not 0 or 1, but very similar.
Between v7 and v8, recombination occurred. Because of this, v0..v7 is different from v8..vg.
The problem of similarity is that we know that one of the options in the group caused something, but we don’t know which one.
This limits the resolution of our genomic microscope , and additional methods, such as functional genomics, will have to be used to solve the problem.
In the end, one can never be 100% sure which particular part of the genome caused a specific individual feature, this is the essence of genetics. Biology is not an exact machine with ideal factory-made parts. This is a boiling mass of accidents that somehow create what we call life. That is why statistics, or “machine learning,” as it is now fashionable to call it, is so important.
Genes: A Brief Introduction
The human genome consists of two copies of approximately 3 billion base pairs of DNA, the letters A, C, G, and T are used for coding. These are about two bits for each base pair:
3,000,000,000 × 2 × 2/8 = 1,500,000 000 or about 1.5 GB of data.
In fact, these copies are very similar, and the DNA of all people is almost the same: from Wall Street traders to Australian Aborigines.
There are a number of “reference genomes,” such as Ensembl Fasta files . Reference genomes help build a map with specific characteristics that are present in human DNA, but are not unique to specific people.
For example, we can determine the “location” of a gene that encodes a BRCA2 protein, which is responsible for DNA repair in breast cancer:this gene .
It is located on chromosome 13, starting from position 32315474 to 32400266.
Genetic variations
People are so similar that it’s usually enough to store a small set of “variations” to represent a person.
Over time, our DNA is damaged by cosmic rays and copying errors, so the DNA that parents pass on to their children is slightly different from their own.
Recombination mixes the genes even more, so the child’s DNA inherits from each parent a mixture of DNA from grandparents on this side.
Therefore, for every change in our DNA, it is enough to save only the differences from the reference genome. Usually they are saved in a VCF (Variant Call Format) file.
Like almost all files in bioinformatics, it is a TSV file type (text format with tab separation).
You can get your own VCF file from companies like 23 and Me andAncestry.com : pay relatively little money and send a sample that is sequenced on a DNA microchip. It highlights fragments where the DNA matches the expected sequences.
A shortened example from the VCF specifications :
## fileDate = 20090805 ## source = myImputationProgramV3.1 ## reference = 1000GenomesPilot-NCBI36 ## phasing = partial #CHROM POS ID REF ALT QUAL FILTER INFO FORMAT NA00001 NA00002 NA00003 20 14370 rs6054257 GA 29 PASS NS = 3; DP = 14; AF = 0.5; DB; H2 GT: GQ: DP: HQ 0 | 0: 48: 1: 51.51 1 | 0: 48: 8: 51.51 1/1: 43: 5:.,.
Here we have three people with the names NA00001, NA00002 and NA00003 (we in the genetics world take security of personal data very seriously), who have certain differences in position 14370 of chromosome 20
0|0, 1|0and 1|1from G to A. There are two numbers per person, since we all have two copies of chromosome 20 (one from each parent; the only exception is sex chromosomes). I’m not lucky that I have only one X chromosome, so I inherited color blindness from my grandfather through my mother).
The following options are possible:
0 | 0 both chromosomes correspond to the reference sample 1 | 0 and 0 | 1 only one chromosome is different from the standard 1 | 1 both chromosomes differ from the standard
VCF files are considered “phased” if you can find out on which particular chromosome the variant is located, or at least where it is located relative to its neighbors. In practice, it’s hard to say which chromosome DNA came from, so you have to guess!
Thus, we have a bit vector
001011, which is enough to classify three people in this variation. These are haplotypes or variations of individual chromosomes.GWAS Research
Using this bit vector, we can try to find out which parts of the genome affect diseases or other individual properties, such as hair color or growth. For each variant, we construct a haplotype for the measured traits ( phenotype ).
GWAS (Genome wide association study) is the basis for genetic analysis of variants. It compares variations with observational data.
For instance:
Haplotype Height Person 0 1.5m NA00001 0 1.5m 1 1.75m NA00002 0 1.75m 1 1.95m NA00003 1 1.95m
Note that each has two haplotypes, because we have pairs of chromosomes.
Here we see that options 1 are associated with higher growth, and the values correspond to linear regression:
beta Change in growth with change in variation. standard error Error indicator.
In practice, there is really a lot of noise in the data, and the error is usually greater than
beta, but often we have several options where the betaerror is much higher. This ratio — the Z-score and the p-value associated with it — shows which options are most likely to affect growth. The easiest way to perform a regression is to apply the Moore - Penrose inversion .
We compose a 2 × 2 covariance matrix with the scalar product of two vectors, and we solve the problem by the least squares method.
We have trillions of data points, so it’s important to do this efficiently.
The Curse of Nonequilibrium Coupling
Since we inherit large fragments of the genome from our parents, certain areas of DNA look very similar: they are much more similar than what the case dictates.
This is good for us, because genes continue to work just like their ancestors, but bad for genomics researchers. This means that the differences are not enough to determine the variations that caused the phenotype to change.
Non-equilibrium linkage (LD) determines how similar two vectors are to variations.
It calculates a value between -1 and 1, where
-1 The exact opposite variation. 0 Variations are not similar. 1 Variations are exactly the same.
To determine the similarity of variations, we create large square LD matrices for specific places in the genome. In practice, many of the variations around this place are almost identical to the middle variant.
The matrix looks something like this, with large squares of similarity.
v0 v2 v4 v6 v8 va vc ve vg
v1 v3 v5 v7 v9 vb vd vf
v0 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0
v1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0
v2 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0
v3 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0
v4 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0
v5 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0
v6 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0
v7 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0
v8 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
v9 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
va 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
vb 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
vc 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
vd 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
ve 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
vf 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
vg 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1Actual values are not 0 or 1, but very similar.
Between v7 and v8, recombination occurred. Because of this, v0..v7 is different from v8..vg.
The problem of similarity is that we know that one of the options in the group caused something, but we don’t know which one.
This limits the resolution of our genomic microscope , and additional methods, such as functional genomics, will have to be used to solve the problem.
Conclusion
In the end, one can never be 100% sure which particular part of the genome caused a specific individual feature, this is the essence of genetics. Biology is not an exact machine with ideal factory-made parts. This is a boiling mass of accidents that somehow create what we call life. That is why statistics, or “machine learning,” as it is now fashionable to call it, is so important.