A brief and peppy overview of compiler architecture
- Transfer

Most compilers have the following architecture:

In this article, I am going to dissect this architecture in detail, element by element.
We can say that this article is an addition to the huge amount of existing resources on the topic of compilers. It is an autonomous source that will allow you to understand the basics of design and implementation of programming languages.
The target audience of the article is people whose idea of the work of compilers is extremely limited (the maximum is that they are involved in compiling). However, I expect the reader to understand data structures and algorithms.
The article is by no means devoted to modern production compilers with millions of lines of code - no, this is a short course “compilers for dummies” that helps to understand what a compiler is.
Introduction
I am currently working on the Krug system language inspired by Rust and Go. In the article I will refer to Krug as an example to illustrate my thoughts. Krug is under development, but is already available at https://github.com/krug-lang in the caasper and krug repositories . The language is not quite typical compared to the usual compiler architecture, which partly inspired me to write an article - but more on that later.
I hasten to inform you that I am in no way a specialist in compilers! I do not have a doctorate, and I did not go through any formal training - I studied everything described in the article on my own in my free time. I must also say that I am not describing the actual, only true approach to creating a compiler, but rather, I present the basic methods suitable for creating a small “toy” compiler.
Frontend
Let us return to the diagram above: the arrows on the left directed to the frontend field are well-known and beloved languages like C. The frontend looks something like this: lexical analysis -> parser.
Lexical analysis
When I started studying compilers and language design, I was told that lexical analysis is the same as tokenization. We will use this description. The analyzer takes input data in the form of strings or a stream of characters and recognizes patterns in them, which it cuts into tokens.
In the case of a compiler, it receives a written program at the input. It is read into a string from a file, and the analyzer tokenizes its source code.
enum TokenType {
Identifier,
Number,
};
struct Token {
std::string Lexeme;
TokenType type;
// ...
// It's also handy to store things in here
// like the position of the token (start to end row:col)
};In this fragment, written in a C-shaped language, you can see the structure containing the aforementioned lexeme, as well as TokenType, which serves to recognize this token.
Note: this article is not an instruction for creating a language with examples - but for a better understanding, I will insert code snippets from time to time.
Analyzers are usually the simplest compiler components. The whole frontend, in fact, is quite simple compared to the rest of the puzzle pieces. Although this largely depends on your work.
Take the following piece of C code:
int main() {
printf("Hello world!\n");
return 0;
}After reading it from a file to a line and performing a linear scan, you may be able to slice tokens. We identify tokens in a natural way - seeing that int is a "word", and 0 in the return statement is a "number". The lexical analyzer performs the same procedure as we do - later we will examine this process in more detail. For example, analyze the numbers:
0xdeadbeef — HexNumber (шестнадцатеричное число)
1231234234 — WholeNumber (целое число)
3.1412 — FloatingNumber (число с плавающей запятой)
55.5555 — FloatingNumber (число с плавающей запятой)
0b0001 — BinaryNumber (двоичное число)Defining words can be difficult. Most languages define a word as a sequence of letters and numbers, and an identifier should usually begin with a letter or underscore. For instance:
123foobar := 3
person-age := 5
fmt.Println(123foobar)In Go, this code will not be considered correct and will be parsed into the following tokens:
Number(123), Identifier(foobar), Symbol(:=), Number(3) ...Most of the identifiers encountered look like this:
foo_bar
__uint8_t
fooBar123Analyzers will have to solve other problems, for example, with spaces, multiline and single-line comments, identifiers, numbers, number systems and number formatting (for example, 1_000_000) and encodings (for example, support for UTF8 instead of ASCII).
And if you think you can resort to regular expressions - better not worth it. It is much easier to write an analyzer from scratch, but I highly recommend reading this article from our king and god Rob Pike. The reasons why Regex is not suitable for us are described in many other articles, so I’ll omit this point. In addition, writing an analyzer is much more interesting than tormenting yourself with long verbose expressions uploaded to regex101.com at 5:24 a.m. In my first language I used tokenization function
split(str) - and far from advanced.Parsing
Parsing is somewhat more complicated than lexical analysis. There are many parsers and parsers-generators - here the game begins in a big way.
Parsers in compilers usually take input in the form of tokens and build a specific tree - an abstract syntax tree or a parsing tree. By their nature, they are similar, but have some differences.
These stages can be represented as functions:
fn lex(string input) []Token {...}
fn parse(tokens []Token) AST {...}
let input = "int main() { return 0; }";
let tokens = lex(input);
let parse_tree = parse(tokens);
// ....Typically, compilers are built from many small components that take input, change it, or convert them to different output. This is one of the reasons why functional languages are well suited for creating compilers. Other reasons are excellent benchmarking and fairly extensive standard libraries. Fun fact: the first Rust compiler implementation was on Ocaml.
I advise you to keep these components as simple and autonomous as possible - modularity will greatly facilitate the process. In my opinion, the same can be said about many other aspects of software development.
Trees
Parsing tree
What the hell is this? Also known as a parse tree, this thick tree serves to visualize the source program. They contain all information (or most of it) about the input program, usually the same as that described in the grammar of your language. Each tree node will be trailing or non-trailing, for example, NumberConstant or StringConstant.
Abstract syntax tree
As the name implies, the ASD is an abstract syntax tree. The parsing tree contains a lot of (often redundant) information about your program, and in the case of an ASD, it is not required. ASD does not need useless information about the structure and grammar, which does not affect the semantics of the program.
Suppose your tree has an expression like ((5 + 5) -3) +2. In the parsing tree, you would store it completely, along with brackets, operators, and values 5, 5, 3, and 2. But you can simply associate with the ASD — we only need to know the values, operators, and their order.
The picture below shows the tree for the expression a + b / c.
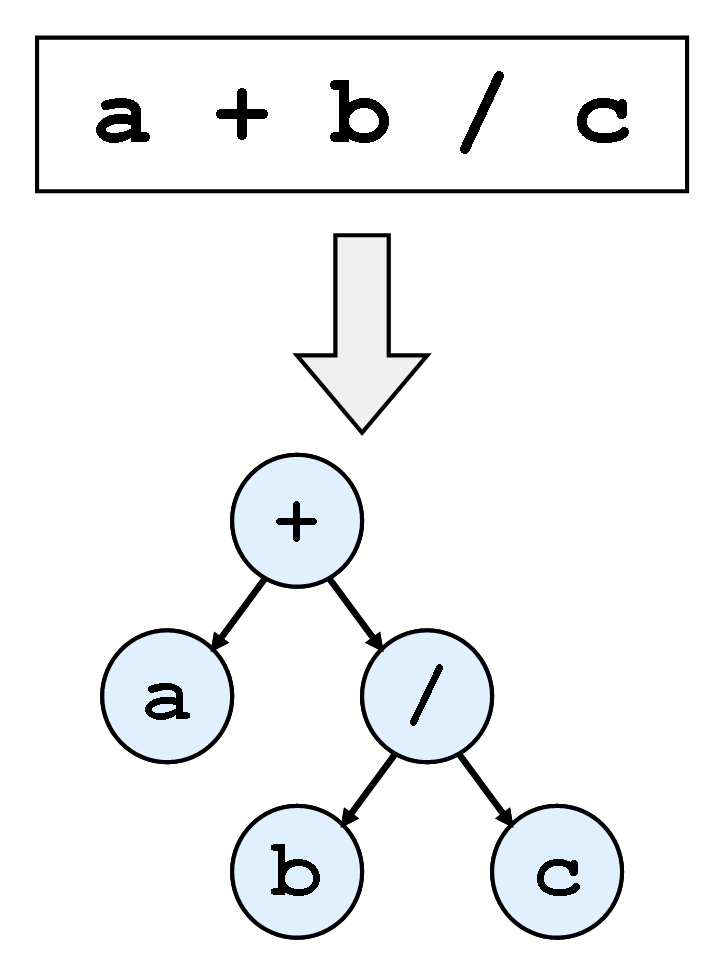
ASD can be represented as follows:
interface Expression { ... };
struct UnaryExpression {
Expression value;
char op;
};
struct BinaryExpression {
Expression lhand, rhand;
string op; // string because the op could be more than 1 char.
};
interface Node { ... };
// or for something like a variable
struct Variable : Node {
Token identifier;
Expression value;
};This view is quite limited, but I hope you can see how your nodes will be structured. For parsing, you can resort to the following procedure:
Node parseNode() {
Token current = consume();
switch (current.lexeme) {
case "var":
return parseVariableNode();
// ...
}
panic("unrecognized input!");
}
Node n = parseNode();
if (n != null) {
// append to some list of top level nodes?
// or append to a block of nodes!
}I hope that you get the gist of how the step-by-step parsing of the remaining nodes will proceed, starting with high-level language constructs. How exactly a parser with a recursive descent is implemented, you need to study yourself.
Grammar
Parsing an ADS from a set of tokens can be difficult. Usually you should start by grammar of your language. In essence, grammar determines the structure of your language. There are several languages for defining languages that can describe (or parse) themselves.
An example of a language for determining languages is an extended form of Backus-Naur (RBNF). It is a variation of BNF with fewer angle brackets. Here is an RBNF example from a Wikipedia article:
digit excluding zero = "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" ;
digit = "0" | digit excluding zero ;Production rules are defined: they indicate which terminal template is “non-terminal”. Terminals are part of the alphabet, for example, the if token or 0 and 1 in the example above are terminals. Non-terminals are their opposite, they are on the left side of the production rules, and they can be considered as variables or “named pointers” to groups of terminals and non-terminals.
Many languages have specifications that contain grammar. For example, for Go , Rust , and D .
Recursive Descent Analyzers
Recursive descent is the easiest of many parsing approaches.
Recursive descent analyzers - descending, based on recursive procedures. It is much easier to write a parser, because your grammar does not have left recursion . In most "toy" languages, this technique is sufficient for parsing. GCC uses a manually written down parser, although YACC was used before.
However, parsing these languages can cause problems. In particular, C, where
foo * barcan be interpreted as
int foo = 3;
int bar = 4;
foo * bar; // unused expressionor how
typedef struct {
int b;
} foo;
foo* bar;
bar.b = 3;The Clang implementation also uses a recursive descent analyzer:
Since this is regular C ++ code, recursive descent allows beginners to easily understand it. It supports custom rules and other weird things that C / C ++ requires and helps you easily diagnose and fix errors.
It is also worth paying attention to other approaches:
- descending LL, recursive descent
- ascending LR, shift, ascending descent
Parser generators
Another good way. Of course, there are also disadvantages - but this can be said about any other choice that programmers make when creating software.
Parser generators work very briskly. Using them is easier than writing your own analyzer and getting a high-quality result - although they are not very user friendly and do not always display error messages. In addition, you will have to learn to use a parser generator, and when promoting the compiler, you probably have to unwind the parser generator.
An example of a parser generator is ANTLR , there are many others.
I think this tool is suitable for those who do not want to spend time writing the frontend, and who would prefer to write the middle and backend of the compiler / interpreter and analyze anything.
Parsing application
If you still do not understand yourself. Even the compiler frontend (lex / parse) can be used to solve other problems:
- syntax highlighting
- HTML / CSS parsing for rendering engine
- transpilers: TypeScript, CoffeeScript
- linkers
- REGEX
- interface data analysis
- URL parsing
- formatting tools like gofmt
- SQL parsing and more.
Mid
Semantic analysis! Analysis of the semantics of the language is one of the most difficult tasks when creating a compiler.
You need to make sure that all input programs work correctly. So far, aspects related to semantic analysis have not been included in my Krug language, and without it the programmer will always be required to write the correct code. In reality, this is impossible - and we always write, compile, sometimes run, correct errors. This spiral is endless.
In addition, compilation of programs is impossible without analysis of the correctness of semantics at the appropriate stage of compilation.
Once upon a time I came across a chart devoted to the percentage of front-end, mid -land and backend. Then it looked like
F: 20% M: 20%: B: 60%Today it is something like
F: 5% M: 60% B: 35%The frontend is mainly concerned with the generator, and in contextless languages that do not have the duality of grammar, they can be completed quite quickly - a recursive descent will help here.
With LLVM technology, most of the optimization work can be loaded into the framework, which presents a number of ready-made optimizations.
The next step is semantic analysis, an essential part of the compilation phase.
For example, in Rust, with its memory management model, the compiler acts as a large, powerful machine that performs various types of static analysis on introductory forms. Part of this task is to convert the input data into a more convenient form for analysis.
For this reason, semantic analysis plays an important role in the architecture of the compiler, and exhausting preparatory work, such as optimizing the generated assembly or reading the input data in the ASD, is done for you.
Semantic Passages
In the course of semantic analysis, most compilers conduct a large number of "semantic passes" on the SDA or other abstract form of code expression. This article provides details about most of the passes made in the .NET C # compiler.
I will not consider each passage, especially since they vary depending on the language, but several steps are described below in Krug.
Top Level Ad
The compiler will go through all the “top-level” announcements in the modules and be aware of their existence. He will not go deeper into blocks - he will simply declare which structures, functions, etc. are available in one or another module.
Name / Symbol Resolution
The compiler goes through all the blocks of code in functions, etc. and resolves them - that is, finds characters that require permission. This is a common pass, and it is from here that the No such symbol XYZ error usually comes when compiling Go code.
Performing this pass can be very difficult, especially if there are circular dependencies in your dependency diagram. Some languages do not allow them, for example, Go will throw an error if one of your packages forms a loop, like my Krug language. Cyclic dependencies can be considered a side effect of poor architecture.
Loops can be determined by modifying DFS in the dependency diagram, or by using the Tarjan algorithm (as done by Krug) to define (multiple) loops.
Type Inference
The compiler goes through all the variables and displays their types. Type inference in Krug is very weak, it simply outputs variables based on their values. It is by no means a bizarre system, like the ones you can find in functional languages like Haskell.
Types can be derived using the “unification” process, or “type unification”. For simpler type systems, a very simple implementation can be used.
Types are implemented in Krug like this:
interface Type {};
struct IntegerType : Type {
int width;
bool signed;
};
struct FloatingType : Type {
int width;
};
struct ArrayType : Type {
Type base_type;
uint64 length;
};You can also have simple type inference, in which you will assign a type to expression nodes, for example, it
IntegerConstantNodecan be of type IntegerType (64). And then you may have a function unify(t1, t2)that selects the widest type that you can use to infer the type of more complex expressions, say, binary ones. So it’s a matter of assigning a variable on the left to the values of the given types on the right. I once wrote a simple type cast on Go, which became a prototype implementation for Krug.
Mutability Pass
Krug (like Rust) is by default an immutable language, that is, variables remain unchanged unless otherwise specified:
let x = 3;
x = 4; // BAD!
mut y = 5;
y = 6; // OK!The compiler goes through all the blocks and functions and checks that their “variables are correct”, that is, we do not change what does not follow, and that all variables passed to certain functions are constant or changeable where required.
This is done with the help of symbolic information that has been collected over previous passes. A symbol table based on the results of the semantic pass contains token names and signs of variable variability. It may contain other data, for example, in C ++ a table can store information about whether a symbol is external or static.
Character tables
A character table, or “stab,” is a table for finding the characters that are used in your program. For each scope, one table is created, and all of them contain information about the characters present in a particular scope.
This information includes such properties as the symbol name, type, sign of mutability, the presence of external communication, the location in static memory, and so on.
Area of visibility
This is an important concept in programming languages. Of course, your language does not have to make it possible to create nested scopes, everything can be placed in one common namespace!
Although representing the scope is an interesting task for the compiler architecture, in most C-like languages, the scope behaves (or is) like a stack data structure.
Usually we create and destroy scopes, and they are usually used to manage names, that is, they allow us to hide (shadowing) variables:
{ // push scope
let x = 3;
{ // push scope
let x = 4; // OK!
} // pop scope
} // pop scopeIt can be represented differently:
struct Scope {
Scope* outer;
SymbolTable symbols;
}A small offtopic, but I recommend reading about the spaghetti stack . This is a data structure that is used to store visibility areas in the ASD nodes of opposite blocks.
Type systems
Many of the following sections can be developed into separate articles, but it seems to me that this title deserves this most. Today a lot of information is available about type systems, as well as varieties of the systems themselves, around which many copies break. I will not delve deeply into this topic, just leave a link to the excellent article by Steve Klabnik .
A type system is what is provided and semantically defined in the compiler using compiler representations and analysis of these representations.
Possession
This concept is used in programming more and more. The principles of semantics of ownership and movement are embedded in the Rust language , and I hope they will appear in other languages. Rust performs many different types of static analysis, which checks to see if the input satisfies a set of rules regarding memory: who owns which memory, when the memory is destroyed, and how many references (or borrowings) exist to these values or memory.
The beauty of Rust lies in the fact that all this is done during compilation, inside the compiler, so that the programmer does not have to deal with garbage collection or link counting. All these semantics are assigned to the type system and can be provided even before the program is presented as a complete binary file.
I can’t say how it all works under the hood, but all this is the result of static analysis and wonderful research by the Mozilla team and the Cyclone project participants .
Control Flow Graphs
To represent program flows, we use control flow graphs (CFGs), which contain all the paths that program execution can follow. This is used in semantic analysis to exclude non-working sections of code, that is, blocks, functions, and even modules that will never be achieved during program execution. Graphs can also be used to identify cycles that cannot be interrupted. Or to search for inaccessible code, for example, when you cause a “panic” (call a panic), or return in a loop, and the code outside the loop does not execute. Data flow analysis plays an important role during the semantic phase of the compiler, so I recommend reading about the types of analysis that you can perform, how they work and what optimizations can do.
Backend

The final part of our architecture scheme.
We have done most of the work of generating executable binaries. This can be done in various ways, which we will discuss below.
It is not necessary to significantly change the phase of semantic analysis due to the information contained in the tree. Perhaps it’s better not to change it at all to avoid the occurrence of “spaghetti”.
A few words about transpilers
This is a type of compiler that converts code in one language to source code in another. For example, you can write code that compiles to source in C. In my opinion, a thing is pretty pointless, unless your language is much inferior to the language into which it is compiled. Usually, transplication makes sense for relatively high-level languages, or for languages with disabilities.
However, in the history of compilers, conversion to C code is very common. In fact, the first C ++ compiler - Cfront - transformed into C code.
A good example is JavaScript. TypeScript and many other languages transpose into its code in order to bring more features and, more importantly, a sensitive type system with a different number of types of static analysis for catching bugs and errors before we encounter them at runtime.
This is one of the “goals” of the compiler, and most often the simplest, because you do not need to think in terms of lower-level concepts about assigning variables, working with optimization, and so on, because you just “fall on the tail” of another language. However, this approach has an obvious drawback - a lot of overhead, and besides, you are usually limited by the capabilities of the language into which you translate your code.
LLVM
Many modern compilers usually use LLVM as their backend: Rust, Swift, C / C ++ (clang), D, Haskell.
This can be considered the “easy way”, because most of the work has been done for you to support a wide range of architectures, and top-level optimizations are available to you. Compared to the aforementioned transpilation, LLVM also provides great management capabilities. It’s certainly more than if you compiled in C. For example, you can decide how large the types should be, say, 1, 4, 8 or 16-bit. In C, this is not so simple, sometimes impossible, and for some platforms it is not even possible to define.
Generating Assembler Code
Generating code for a specific architecture - that is, generating machine code - is technically the most popular way that is used in many programming languages.
Go is an example of a modern language that does not take advantage of the LLVM framework (at the time of this writing). Go generates code for several platforms, including Windows, Linux, and MacOS. It's funny that the Krug prototype used to generate assembler code too.
This approach has many advantages and disadvantages. However, today, when technologies like LLVM are available, it is not wise to generate assembler yourself, because it is unlikely that a toy compiler with its own backend will surpass LLVM in optimization level for one platform, not to mention several.
However, a significant advantage of self-assembler generation is that your compiler is likely to be much faster than if you used a framework like LLVM, which must first assemble your IR, optimize, and so on, and then finally be able to produce assembler (or whatever you choose).
But trying is still nice. And besides, it will be interesting if you want to learn more about assembly language programming, or how programming languages work at lower levels. The easiest way is to open the ASD or the generated IR (if you have one) and “issue” the assembler instructions to a file using fprintf or another utility. This is how 8cc works .
Bytecode Generation
You can also generate bytecode for a certain type of virtual machine or bytecode interpreter. A striking example is Java: in fact, the JVM spawned a whole family of bytecode-generating languages for it, for example, Kotlin.
Bytecode generation has many advantages, and portability was the main thing for Java. If you can run your virtual machine anywhere, then any code executed on it will also work anywhere. In addition, it is much easier to run an abstract set of bytecode instructions on machines than to generate code in a few computer architectures.
As far as I know, JVM using JIT turns frequently used code into native functions, and also applies other JIT tricks to squeeze out even more performance.
Optimizations
They are an integral part of the compiler, no one needs slow-running code! Typically, optimizations make up the majority of the backend, and developers put a lot of effort into improving performance. If you ever compile a C code and run it with all the optimizations, you will be surprised how crazy it is. Godbolt is a great tool for understanding how modern compilers generate code and what instructions relate to which source code. You can also set the desired level of optimizations, goals, versions of compilers, and so on.
If you've ever written a compiler, you can start by creating a simple C program, turn off all optimizations and strip the debug symbols, and see what GCC generates. You can then use it as a reminder if you ever have difficulty.
When tuning optimizations, you can find a compromise between the accuracy and speed of the program. However, finding the right balance is not so simple. Some optimizations are very specific, and in some cases can lead to an erroneous result. For obvious reasons, they are not included in production compilers.
In the commentsto this article on another resource, the user rwmj noticed that only 8 optimizing passes are enough to get 80% of the maximum performance of your compiler. And all these optimizations were described in 1971! We are talking about the publication of Graydon Hoar, the mastermind of Rust.
IR
An intermediate representation (IR) is not necessary, but useful. You can generate code from the ASD, although it can be quite tedious and messy, and the result will be difficult to optimize.
You can think of IR as a higher level representation of the generated code. It should very accurately reflect what it represents and contain all the information necessary to generate the code.
There are specific types of IR, or “forms,” which you can create using IR to simplify optimizations. For example, SSA is Static Single Assignment, the only static assignment in which each variable is assigned only once.
In Go, SSA-based IR is built before generating the code. The LLVM IR is based on SSA to provide its optimization.
Initially, SSA provides several optimizations, for example, constant propagation, exclusion of non-working code, and (very important) register allocation.
Register allocation
This is not a requirement for generating code, but optimization. One abstraction that we consider a given is that we can define as many variables as our programs need. However, in assembler, we have a finite number of registers (usually from 16 to 32) that we need to keep in mind, or we can use the stack (spill to the stack).
Register allocation is an attempt to select a particular register for a particular variable at a particular point in time (without overwriting other values). This is much more efficient than using the stack, although it can incur additional costs, and the computer can not always calculate the ideal distribution scheme.
There are several register allocation algorithms:
- Graph coloring (graph coloring) is computationally complex (NP-complete problem). It is required to present the code in the form of a graph in order to calculate the range of lives of the variables.
- Line scan - scans variables and determines their life ranges.
Things to Remember
A lot has been written about compilers. So much that does not fit in any article. I want to remind, or at least mention a few important points that you need to remember in the course of your future projects.
Distortion of names ( Name Mangling )
If you generate assembler code in which there really are no scopes or namespaces, then you will often encounter character conflicts. Especially if your language supports overriding functions or classes, and the like.
fn main() int {
let x = 0;
{
let x = 0;
{
let x = 0;
}
}
return 0;
}For example, in this code (if the variables are not optimized in any way :)) you will have to distort the names of these characters so that they do not conflict in assembler. Also, distortion is usually used to indicate the type of information, or it may contain namespace information.
Debug information
Tools like LLDB usually use standards like DWARF . One of the great things about LLVM is that with DWARF you get a relatively simple integration with your existing GNU debugging toolkit. Your language may need a debugging tool, and it is always easier to use a ready-made tool than writing your own.
Foreign Function Interface ( FFI )
Usually, libc can’t go anywhere; you need to read about this library and think about how to embed it in your language. How do you connect to C code, or how do you open your code for C?
Linker
Writing a linker is a separate task. When your compiler generates code, does it generate machine instructions (in a .s / .asm file)? Does it write code directly to the object file? For example, in the Jai programming language, all code is supposedly written to a single object file. There are various options for which compromises are characteristic.
Compiler as a Service (CaaS)
Here, all of the compiler phases discussed above are distributed by API routes. This means that the text editor can access the Krug server tokenize the file and return tokens in response. In addition, all static analysis paths are open, making tooling easier.
Of course, this approach has disadvantages, for example, a delay in sending and receiving files. In addition, many aspects of the compiler architecture need to be rethought in order to work in the context of API routes.
Few production compilers use the CaaS approach. Microsofts Roslyn comes to mind, although I know little about this compiler, so study it yourself. And I can be wrong, but it seems that many compilers implement this approach, but their authors write API routes that connect to existing compilers, for example, Rust has RLS .
In my Krug language - which is still being actively developed and is unstable - the Caasper compiler uses the CaaS architecture.
Caasper runs locally on your machine (or, if you want, on the server), and then the frontends or clients, for example, krug, interact with this service. The plus is that you can have many frontend implementations, and the only frontend can be loaded (bootstrap) in the language itself before you rewrite the entire compiler.
The frontend for Krug is implemented in JavaScript, although there will be alternative implementations in Go *, as well as, I hope, in Krug itself. JavaScript was chosen for its availability, it can be downloaded with the very popular yarn / npm package managers.
* Initially, the frontend was written in Go and turned out to be (expected) much faster than the JS version.
The source code for the Caasper compiler lies here . In my personalGithub is the prototype of Krug, it is written in D and compiled in LLVM. You can also watch the demo on my YouTube channel .
The Krug manual (intermediate) is here .
useful links
- Jack Crenshaw is my personal door to the world of programming languages.
- Crafting interpreters
- An Introduction to LLVM (with Go) - Me!
- PL / 0
- The Dragon Book is a classic book that has it all.
- 8cc