Another monitoring system
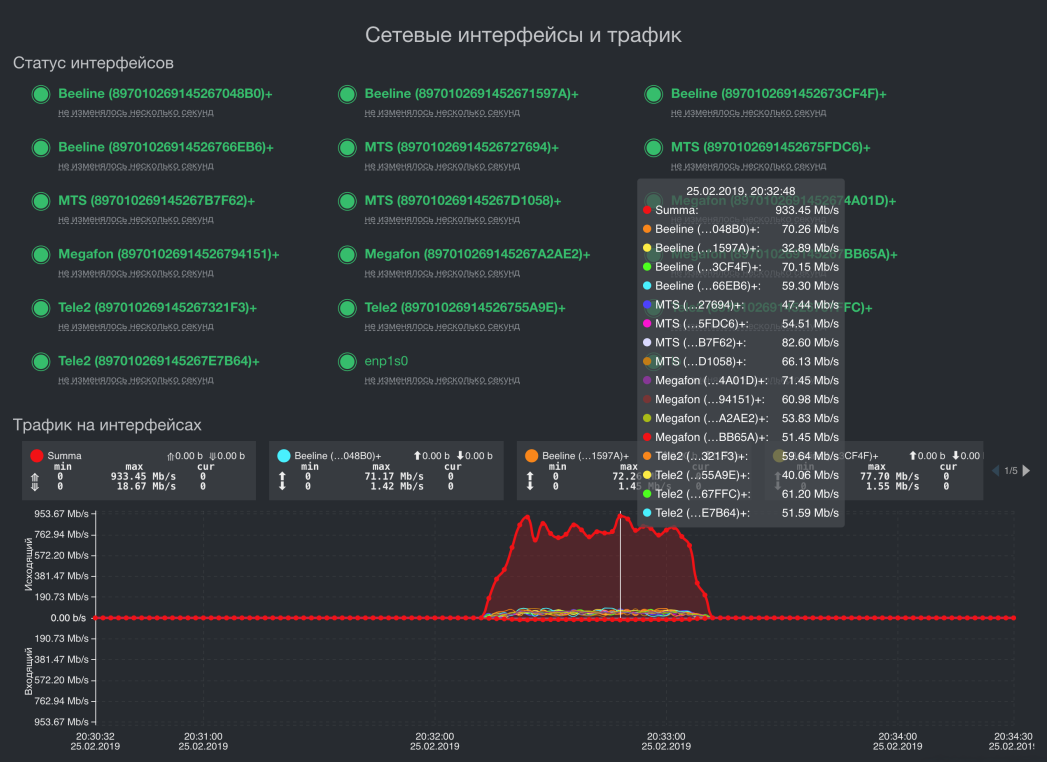
Speed summation on 16 modems of 4 mobile operators. Outgoing speed in one stream - 933.45 Mbps
Introduction
Hello! This article is about how we wrote a new monitoring system for ourselves. It differs from the existing ones by the possibility of high-frequency synchronous acquisition of metrics and very low resource consumption. The polling frequency can reach 0.1 milliseconds with an accuracy of synchronization between metrics of 10 nanoseconds. All binary files occupy 6 megabytes.
about the project
We have a rather specific product. We produce a comprehensive solution to summarize the throughput and fault tolerance of data channels. This is when there are several channels, for example, Operator1 (40Mbit / s) + Operator2 (30Mbit / s) + Something else (5 Mbit / s), the result is one stable and fast channel, the speed of which will be something like this: (40+ 30 + 5) x0.92 = 75x0.92 = 69 Mbps.
Such solutions are in demand where the capacity of any one channel is insufficient. For example, transport, real-time video surveillance and video streaming systems, live television and radio broadcasts, any out-of-town objects where telecom operators have only representatives of the Big Four, and speed on one modem / channel is not enough.
For each of these areas, we produce a separate line of devices, however, their software part is almost the same and a high-quality monitoring system is one of its main modules, without the correct implementation of which the product would be impossible.
For several years, we have managed to create a multi-level fast, cross-platform and lightweight monitoring system. What we want to share with a reputable community.
Formulation of the problem
The monitoring system provides metrics for two fundamentally different classes: real-time metrics and all the rest. The monitoring system had the following requirements:
- High-frequency synchronous acquisition of real-time metrics and their transfer to the communication control system without delay.
The high frequency and synchronization of different metrics is not just important, it is vital for the analysis of the entropy of data transmission channels. If there is an average delay of 30 milliseconds in one data channel, then an error in synchronization between the remaining metrics by only one millisecond will lead to degradation of the speed of the resulting channel by about 5%. If we make a mistake in synchronization for 1 millisecond in 4 channels, speed degradation can easily fall to 30%. In addition, the entropy in the channels changes very quickly, so if we measure it less than once every 0.5 milliseconds, on fast channels with a small delay we will get a high speed degradation. Of course, such accuracy is not needed for all metrics and not in all conditions. When the delay in the channel is 500 milliseconds, and we work with such then an error of 1 millisecond will hardly be noticeable. Also, for the metrics of life support systems, the polling and synchronization frequencies of 2 seconds are enough for us, however, the monitoring system itself should be able to work with ultra-high polling frequencies and ultra-precise metric synchronization. - Minimal resource consumption and a single stack.
The final device can be a powerful on-board complex that can analyze the situation on the road or record biometrics of people, or a single-board palm-sized computer that is worn by a special forces soldier under body armor to transmit real-time video in poor communication conditions. Despite such a variety of architectures and computing power, we would like to have the same software stack. - Umbrella architecture
Metrics should be assembled and aggregated on the final device, have a local storage system and visualization in real time and retrospectively. If communication is available, transfer data to the central monitoring system. When there is no connection, the sending queue should accumulate and not consume RAM. - An API for integration into a customer’s monitoring system, because no one needs a lot of monitoring systems. The customer must collect data from any devices and networks in a single monitoring.
What happened
In order to load the already impressive longrid, I will not give examples and measurements of all monitoring systems. This will pull another article. I’ll just say that we were not able to find a monitoring system that is capable of taking two metrics at the same time with an error of less than 1 millisecond and which works equally efficiently on both an ARM architecture with 64 MB of RAM and x86_64 architecture with 32 GB of RAM. Therefore, we decided to write our own, which can do just that. Here's what we got:
Summing the throughput of three channels for different network topologies
Visualization of some key metrics
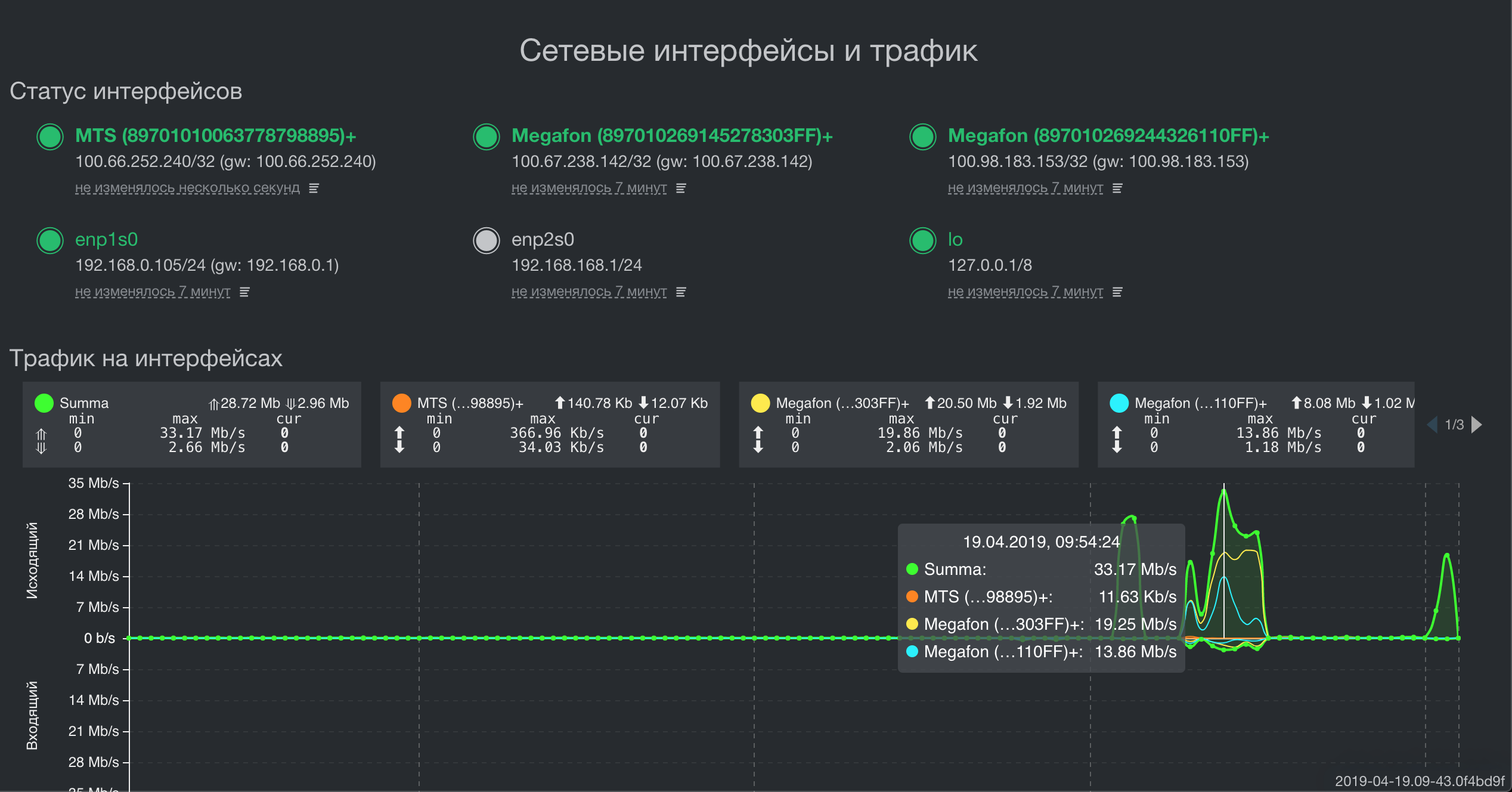
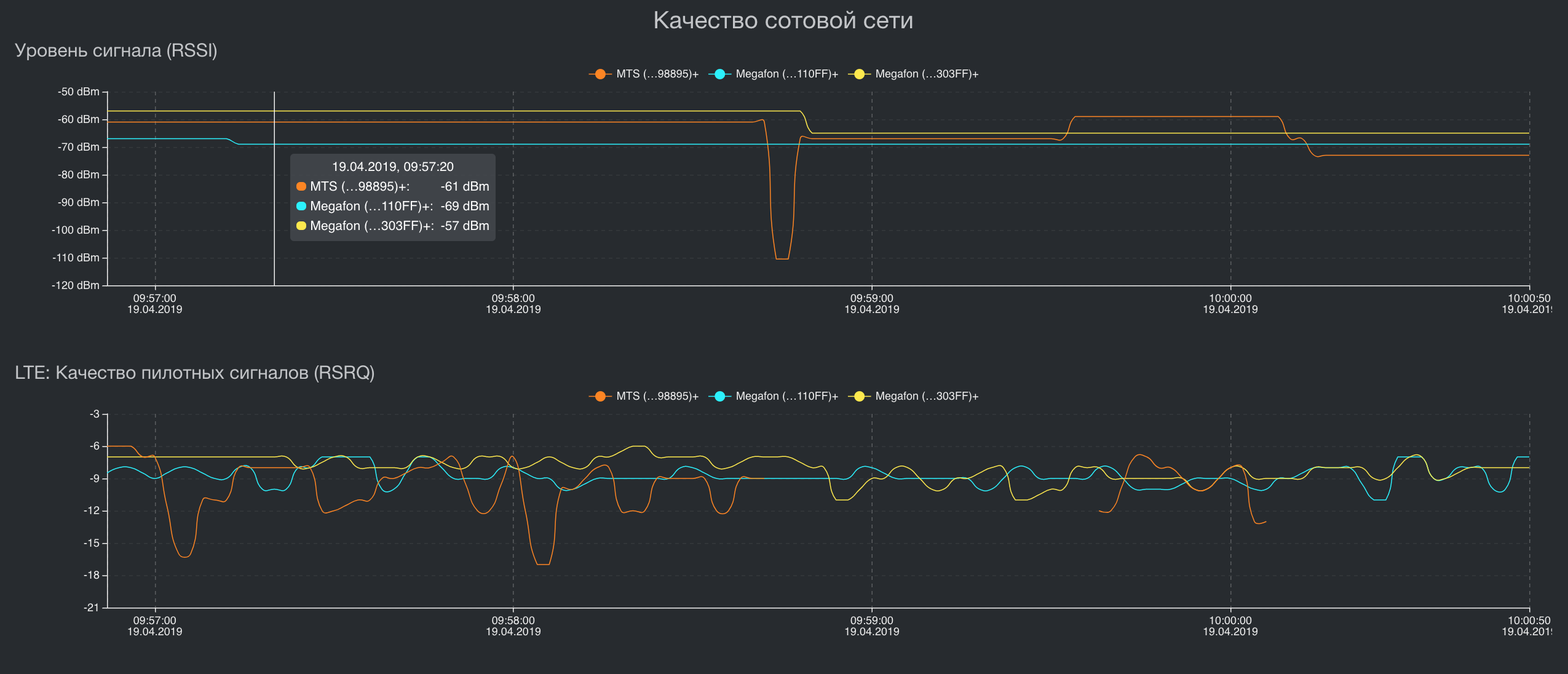
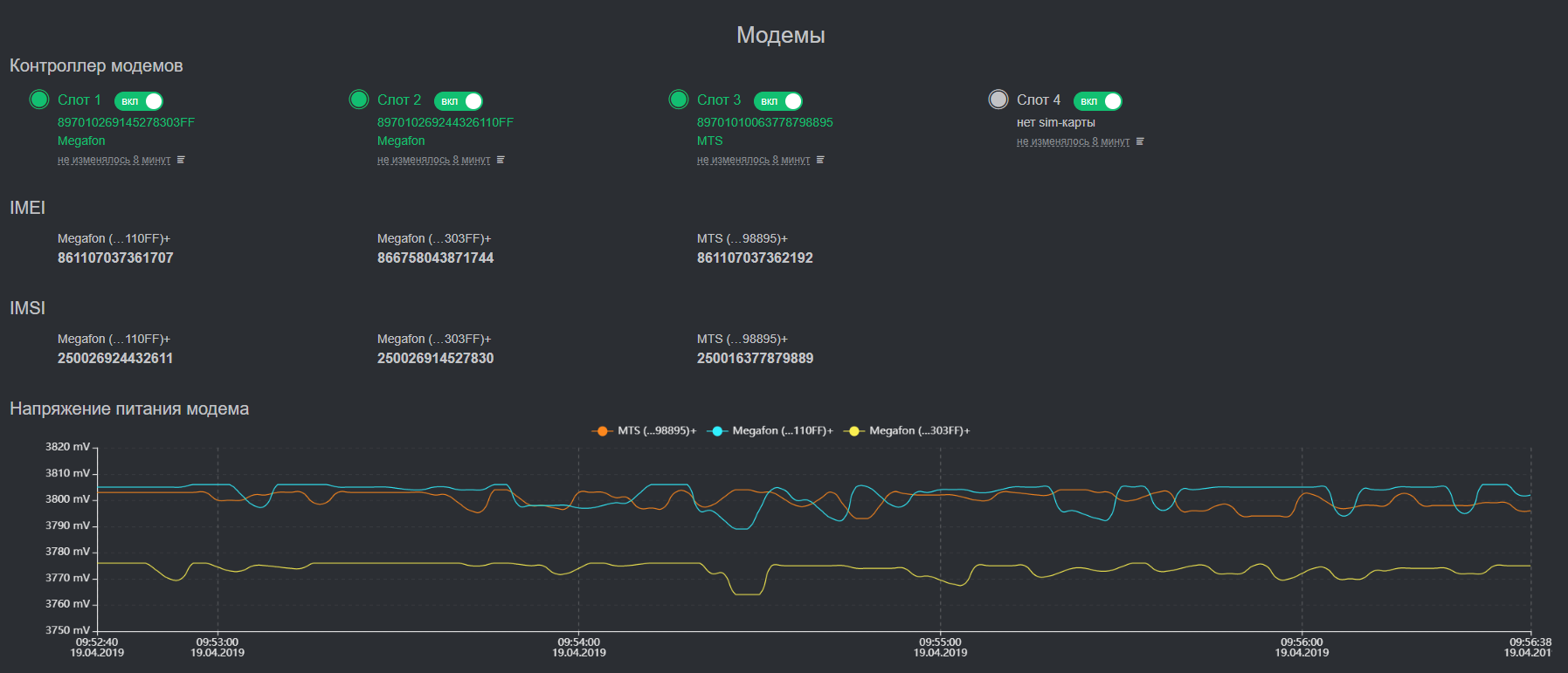
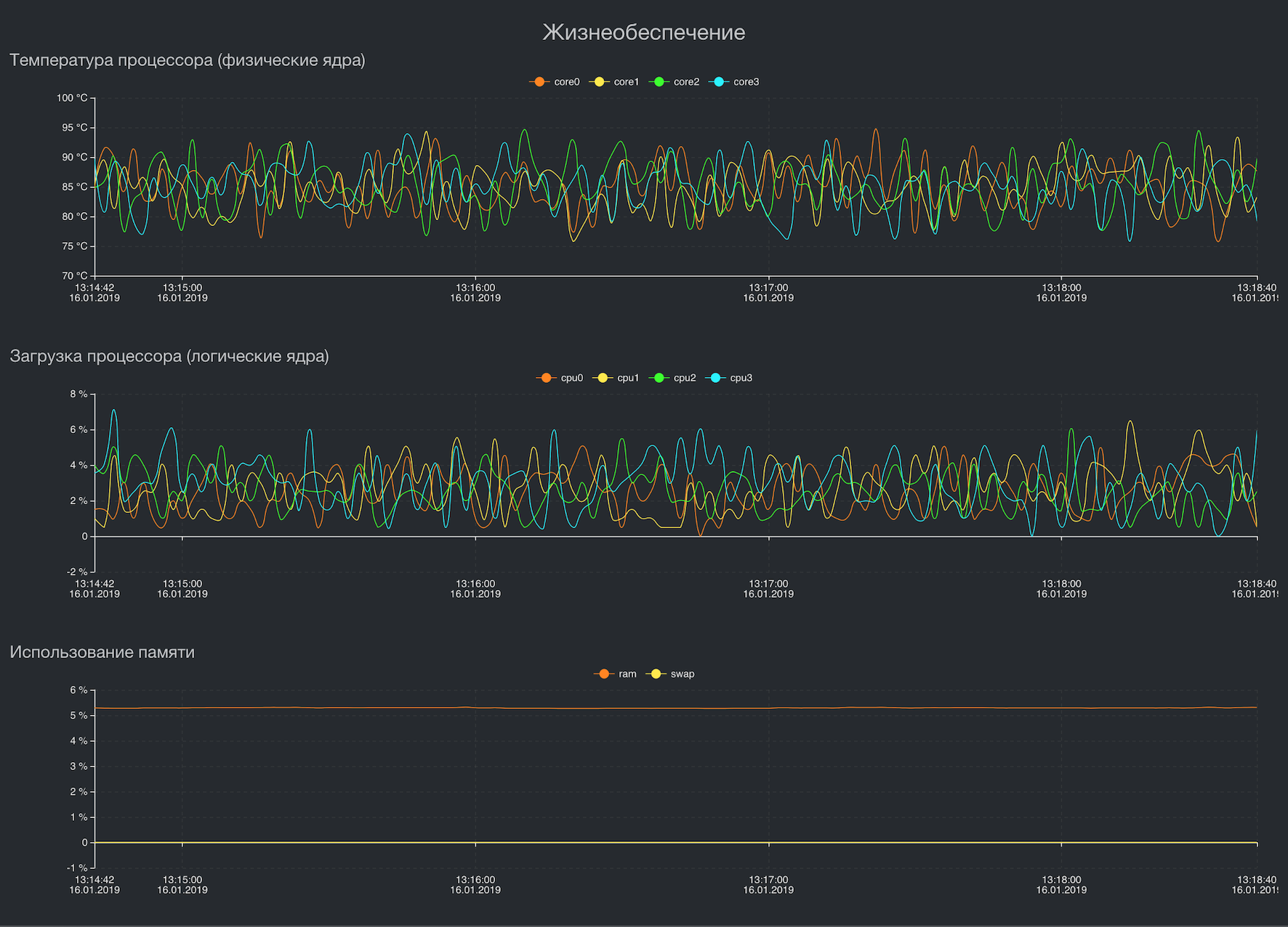
Architecture
As the main programming language, both on the device and in the data center, we use Golang. He greatly simplified his life by implementing multitasking and the ability to get one statically linked executable binary for each service. As a result, we significantly save in resources, methods and traffic of service deployment to end devices, development time and code debugging.
The system is implemented according to the classical modular principle and contains several subsystems:
- Registration of metrics.
Each metric is served by its own stream and synchronized through channels. We managed to get a synchronization accuracy of up to 10 nanoseconds. - Metric storage
We chose between writing our repository for time series or using one of the available ones. The database is needed for retrospective data, which is subject to subsequent visualization. That is, it does not have data on delays in the channel every 0.5 milliseconds or error indications in the transport network, but there is a speed on each interface every 500 milliseconds. In addition to the high requirements for cross-platform and low resource consumption, it is extremely important for us to be able to process. data in the same place where it is stored. This tremendously saves computing resources. Since 2016, we have been using Tarantool DBMS in this project and so far we are not seeing a replacement for it in the horizon. Flexible, with optimal consumption of resources, more than adequate technical support. Tarantool also has a GIS module. It is certainly not as powerful as PostGIS, - Visualization of metrics
Everything is relatively simple here. We take the data from the storage and show it either in real time or retrospectively. - Data synchronization with a central monitoring system.
The central monitoring system receives data from all devices, stores it with a given retrospective, and sends it via the API to the Customer’s monitoring system. Unlike classical monitoring systems, in which the "head" walks and collects data - we have the opposite scheme. Devices themselves send data when there is a connection. This is a very important point, since it allows you to receive data from the device for those periods of time at which it was not available and not load channels and resources while the device is unavailable. As a central monitoring system, we use the Influx monitoring server. Unlike analogs, it can import retrospective data (that is, with a time stamp different from the moment the metric was received) The collected metrics are visualized by a modified Grafana file. - Data synchronization with a central device management system.
The device management system implements Zero Touch Provisioning (updating firmware, configuration, etc.) and, unlike the monitoring system, receives only device problems. These are the triggers of the onboard hardware watchdog services and all the metrics of life support systems: CPU and SSD temperature, CPU load, free space and SMART health on disks. The subsystem storage is also built on Tarantool. This gives us significant speed in the aggregation of time series across thousands of devices, and also completely solves the issue of data synchronization with these devices. Tarantool has an excellent queuing system and guaranteed delivery. We got this important feature out of the box, great!
Network management system
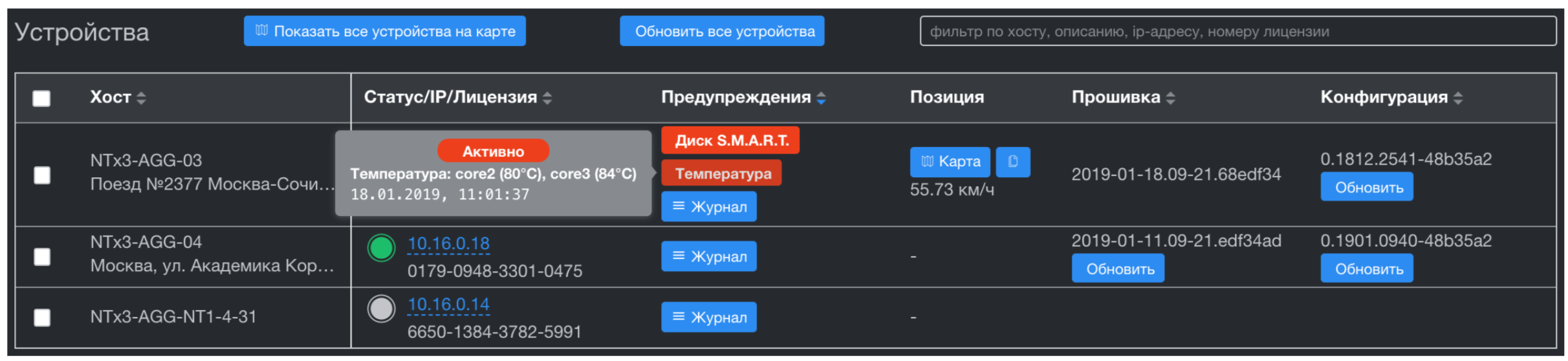
What's next
So far, the weakest link in our country is the central monitoring system. It is implemented at 99.9% on the standard stack and it has a number of disadvantages:
- InfluxDB loses data when power is turned off. As a rule, the Customer promptly takes everything that comes from the devices and there is no data older than 5 minutes in the database itself, but in the future this can be a pain.
- Grafana has a number of problems with data aggregation and synchronization of their display. The most common problem is when the database contains a time series with an interval of 2 seconds starting from 00:00:00, and Grafana starts showing aggregation data from +1 second. As a result, the user sees a dancing chart.
- Excess code for API integration with third-party monitoring systems. Can be made much more compact and of course rewrite to Go)
I suppose all of you perfectly saw what Grafana looks like and without me you know her problems, therefore I will not overload the post with pictures.
Conclusion
I deliberately did not describe technical details, but described only the supporting design of this system. Firstly, in order to technically fully describe the system, one more article is required. Secondly, not everyone will be interested. Write in the comments what technical details you would like to know.
If anyone has questions outside of this article, I can write to a.rodin @ qedr.com