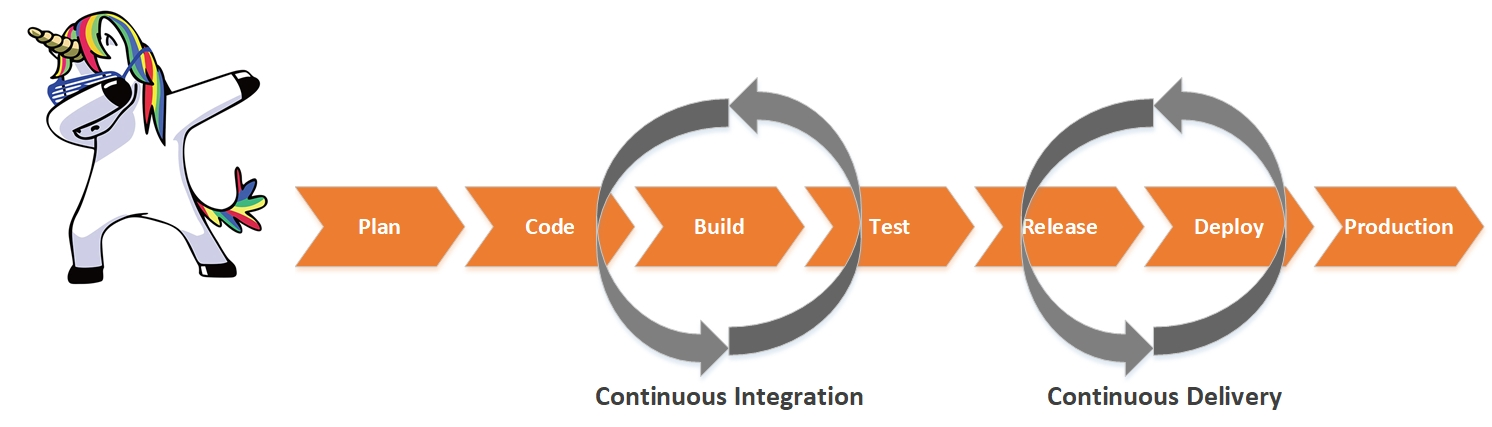
Continuous Monitoring - automation of software quality checks in CI / CD Pipeline
The hype theme is DevOps. The conveyor of continuous integration and delivery of CI / CD is implemented by everyone who feels like it. But most do not always pay due attention to ensuring the reliability of information systems at various stages of the CI / CD Pipeline. In this article, I would like to talk about my experience in automating software quality checks and implementing possible scenarios for its "self-healing".
 A source
A source
I work as an engineer in the IT services management department at LANIT-Integration. My core area is the implementation of various systems for monitoring the performance and availability of applications. I often communicate with IT customers from different market segments on topical issues of monitoring the quality of their IT services. The main task is to minimize the release cycle time and increase the frequency of their release. This, of course, is all good: more releases - more new features - more satisfied users - more profit. But in reality, not always everything turns out well. At very high deployment rates, the question immediately arises about the quality of our releases. Even with a fully automated pipeline, one of the biggest problems is the transfer of services from testing to production, without affecting uptime and user interaction with the application.
Based on the results of numerous conversations with customers, I can say that quality control of releases, the problem of application reliability and the possibility of its "self-healing" (for example, rollback to a stable version) at various stages of the CI / CD pipeline are among the most exciting and relevant topics.
Recently, I myself worked on the customer side - in the online banking application support service. The architecture of our application used a large number of self-written microservices. The saddest thing is that not all developers coped with the high development pace, the quality of some microservices suffered, which gave rise to ridiculous nicknames for them and their creators. There were stories about what materials these products are made of.

The high frequency of releases and a large number of microservices make it difficult to understand the application as a whole, both at the testing stage and at the operational stage. Changes occur constantly and it is very difficult to control them without good monitoring tools. Often after a nightly release in the morning, developers sit on a powder keg and wait for nothing to break, although at the testing stage all the checks were successful.
There is one more point. At the testing stage, the operability of the software is checked: the implementation of the main functions of the application and the absence of errors. Qualitative estimates of performance are either absent or do not take into account all aspects of the application and the integration layer. Some metrics may not be checked at all. As a result, if a breakdown occurs in a productive environment, the technical support department only finds out when real users begin to complain. I would like to minimize the impact of low-quality software on end users.
One of the solutions is to implement software quality control processes at various stages of CI / CD Pipeline, add various scripts to restore the system in the event of an accident. Also remember that we have DevOps. Business expects to receive a new product as quickly as possible. Therefore, all our checks and scripts must be automated.
The task is divided into two components:
In order to realize the tasks set, a monitoring system is required that can detect problems and transfer them to automation systems at various stages of the CI / CD pipeline. Also, a positive point will be if this system provides useful metrics for various teams: development, testing, operation. And quite wonderful, if for business.
To collect metrics, you can use a combination of different systems (Prometheus, ELK Stack, Zabbix, etc.), but, in my opinion, APM ( Application Performance Monitoring ) solutions are best suited for these tasks , which can greatly simplify your life.
As part of my work in the escort service, I started to do a similar project using the APM class solution from Dynatrace. Now, working as an integrator, I know the market of monitoring systems quite well. My subjective opinion: Dynatrace is best suited for such tasks.
The Dynatrace solution provides a horizontal display of each user operation with a deep degree of detail down to the level of code execution. You can track the entire chain of interaction between various information services: from front-end levels of web and mobile applications, back-end application servers, integration bus to a specific call to the database.
 Source . Automatic construction of all dependencies between system components
Source . Automatic construction of all dependencies between system components
 Source . Automatic determination and construction of a path for a service operation
Source . Automatic determination and construction of a path for a service operation
We also remember that we need to integrate with various automation tools. Here the solution has a convenient API that allows you to send and receive various metrics and events.
Next, we move on to a more detailed discussion of how to solve tasks using the Dynatrace system.
The first task is to find problems as early as possible at the stages of the application delivery pipeline. Only “good” builds of code should reach the prod environment. For this, additional monitors should be included in your pipeline at the testing stage to verify the quality of your services.

Let's look at the steps how to implement this and automate this process:
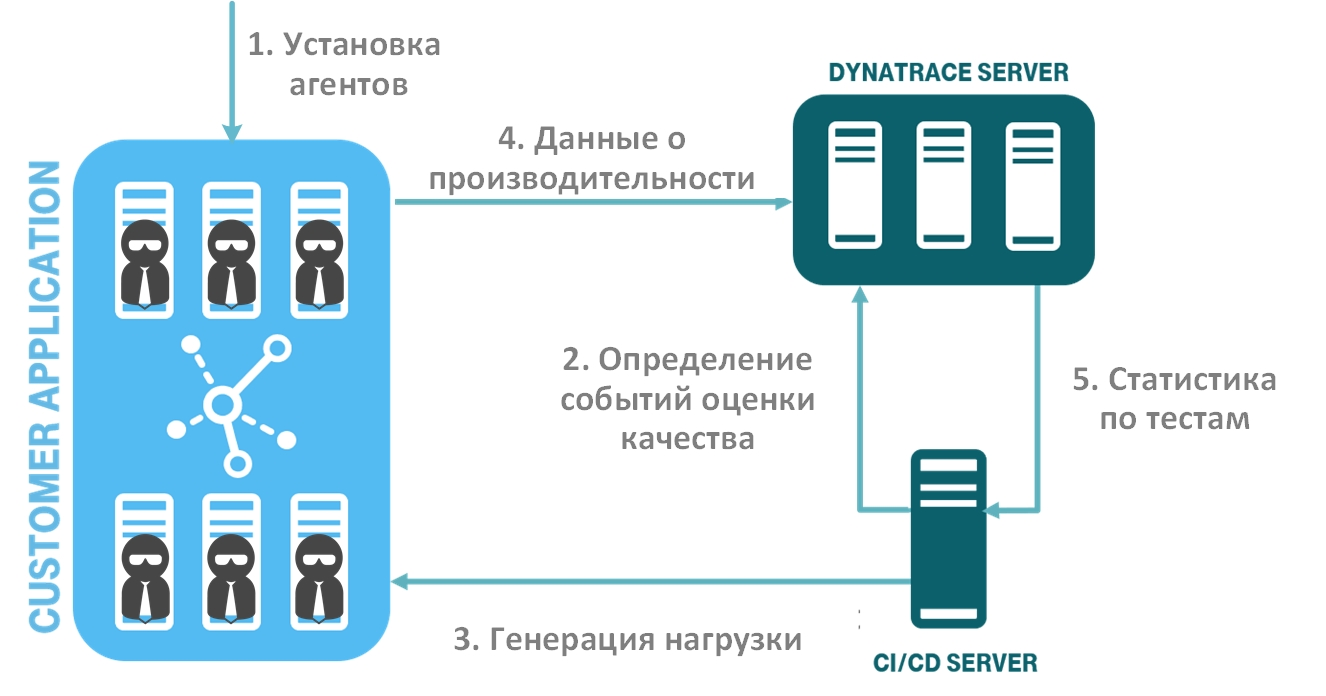 Source
Source
The figure shows the flow of automated steps for checking the quality of software:
Step 1. Deploying the monitoring system
First you need to install the agents in your test environment. At the same time, the Dynatrace solution has a nice feature - it uses the OneAgent universal agent, which is installed on the OS instance (Windows, Linux, AIX), automatically detects your services and starts collecting monitoring data on them. You do not need to configure an agent separately for each process. A similar situation will be for cloud and container platforms. At the same time, you can also automate the installation of agents. Dynatrace fits perfectly into the concept of "infrastructure as code" ( Infrastructure as code or IaC): There are ready-made scripts and instructions for all popular platforms. Embed the agent in the configuration of your service, and when you deploy it, you immediately get a new service with an already running agent.
Step 2. Determining the events of assessing the quality of your software
Now you need to determine the list of services and business operations. It is important to consider exactly those user operations that are business critical for your service. Here I recommend consulting with business and system analysts.
Next, you need to determine which metrics you want to include in the verification for each of the levels. For example, it can be runtime (with separation by average, median, percentile, etc.), errors (logical, service, infrastructure, etc.) and various infrastructure metrics (memory heap, garbage collector, thread count, etc.).
For automation and ease of use, the DevOps team introduces the concept of “Monitoring as code”. What I mean by this is that a developer / tester can write a simple JSON file that defines the indicators of software quality control.
Let's look at an example of such a JSON file. Objects from the Dynatrace API are used as a key / value pair (see the Dynatrace API description of the API ).
The file is an array of timeseries definitions:
The following figure shows an example of the use of such trasholds.
 Source
Source
Step 3. Load generation
After we have determined the quality levels of our service, it is necessary to generate a test load. You can use any of the testing tools that are convenient for you, for example, Jmeter, Selenium, Neotys, Gatling, etc.
The Dynatrace monitoring system allows you to capture various metadata from your tests and recognize which test relates to which release cycle and which service. It is recommended that you add additional headers to the test HTTP requests.
The following figure shows an example where, using the optional X-Dynatrace-Test header, we mark that this test refers to testing the operation of adding an item to the basket.
 Source
Source
When you run each load test, you send additional contextual information to Dynatrace using the event API from the CI / CD server. Thus, the system can distinguish between different tests among themselves.
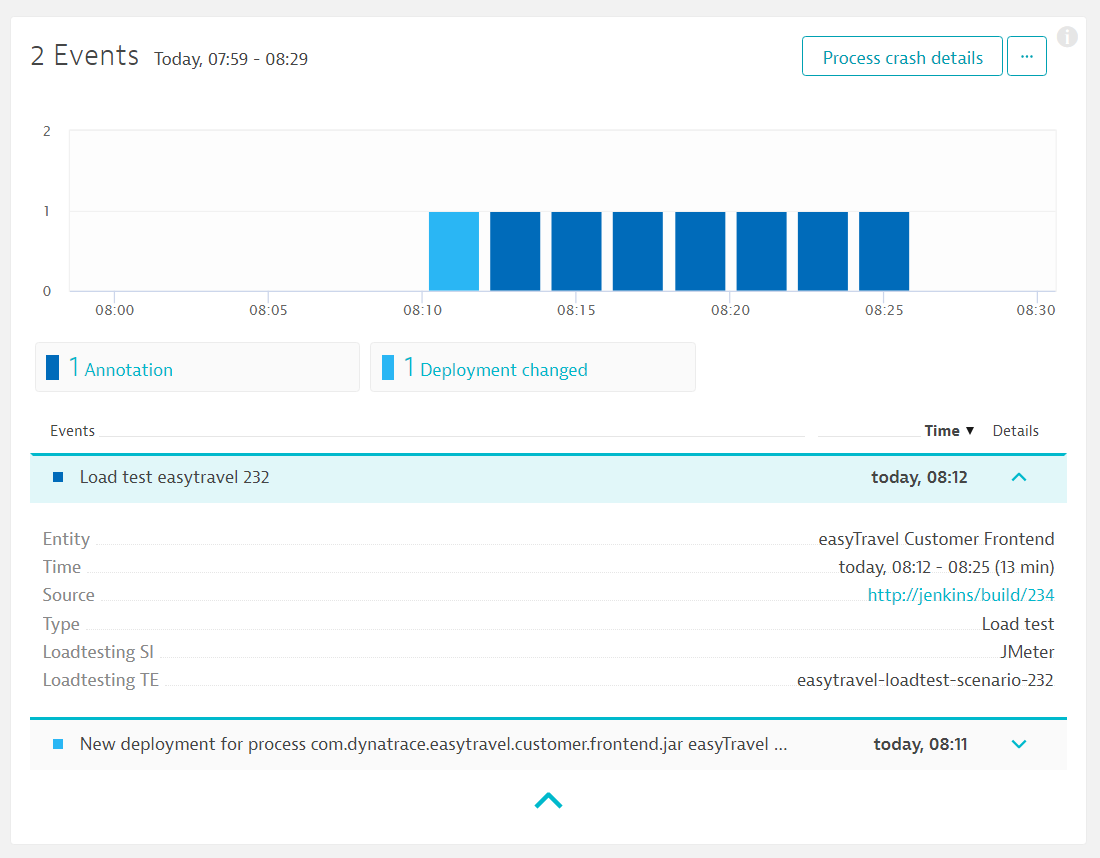 Source . Event in the monitoring system about the launch of load testing
Source . Event in the monitoring system about the launch of load testing
Step 4-5. Collecting performance data and transferring data to the CI / CD system
Together with the generated test, an event is transmitted to the monitoring system about the need to collect data on checking service quality indicators. Our JSON file is also indicated, in which key metrics are defined.
 Event on the need for software quality control generated on the CI / CD server for sending to the monitoring system
Event on the need for software quality control generated on the CI / CD server for sending to the monitoring system
In our example, the quality control event is called perfSigDynatraceReport (Performance_Signature ) - this is a ready - made plug - in for integration with Jenkins, which was developed by the guys from T-Systems Multimedia Solutions. Each event about the launch of the test contains information about the service, build number, and test time. The plugin collects performance values during assembly, evaluates them and compares the result with previous assemblies and non-functional requirements.
 Event in the monitoring system about the start of assembly quality control. Source
Event in the monitoring system about the start of assembly quality control. Source
After the test is completed, all software quality assessment metrics are transferred back to the continuous integration system, for example, Jenkins, which generates a report on the results.
 The result of assembly statistics on the CI / CD server. Source
The result of assembly statistics on the CI / CD server. Source
For each individual assembly, we see statistics for each metric we set during the entire test. We also see if there were violations at certain threshold values (warning and severe thrasholds). Based on the aggregate metrics, the entire assembly is marked as stable, unstable, or failed. Also, for convenience, you can add indicators for comparing the current assembly with the previous one in the report.
 View detailed assembly statistics on the CI / CD server. Source A
View detailed assembly statistics on the CI / CD server. Source A
detailed comparison of two assemblies
If necessary, you can go to the Dynatrace interface and there look in more detail at the statistics for each of your assemblies and compare them with each other.
 Comparison of assembly statistics in Dynatrace. Source
Comparison of assembly statistics in Dynatrace. Source
Conclusions
As a result, we get the service “monitoring as a service”, automated in the pipeline of continuous integration. The developer or tester only needs to determine the list of metrics in the JSON file, and everything else happens automatically. We get transparent quality control of releases: all notifications of performance, resource consumption, or architectural regressions.
So, we have solved the problem of how to automate the monitoring process at the testing stage in Pipeline. Thus, we minimize the percentage of low-quality assemblies that reach the production environment.
But what to do if bad software still got to the point of sale, well, or just something breaks. For utopia, we wanted the mechanisms to automatically detect problems to be present and, if possible, the system itself would recover, even at night.
To do this, we, by analogy with the previous section, provide automatic software quality checks in the production environment and lay scripts for self-healing of the system under them.

Autocorrection as a code
Most companies already have an accumulated knowledge base on various types of common problems and a list of actions to fix them, for example, restarting processes, cleaning resources, rolling back versions, restoring incorrect configuration changes, increasing or decreasing the number of components in a cluster, switching blue or green outline, etc.
Despite the fact that these use cases have been known for many years to many teams with which I communicate, only a few thought and invested Twa in their automation.
If you think about it, then in the implementation of processes for self-healing the application’s health there is nothing super complicated, you need to present the well-known work scenarios of your admins in the form of code scripts (the concept of “autocorrection as code”) that you wrote in advance for each specific case. Automatic repair scenarios should address the root cause of the problem. You set the right incident response actions yourself.
Any metric from your monitoring system can act as a trigger for running a script, the main thing is that these metrics accurately determine that everything is bad, since I would not want to get false positives in a productive environment.
You can use any system or set of systems: Prometheus, ELK Stack, Zabbix, etc. But I will give some examples based on the APM solution (Dynatrace will again be an example), which will also help make your life easier.
Firstly, there is everything that relates to operability from the point of view of the application. The solution provides hundreds of metrics at various levels that you can use as triggers:
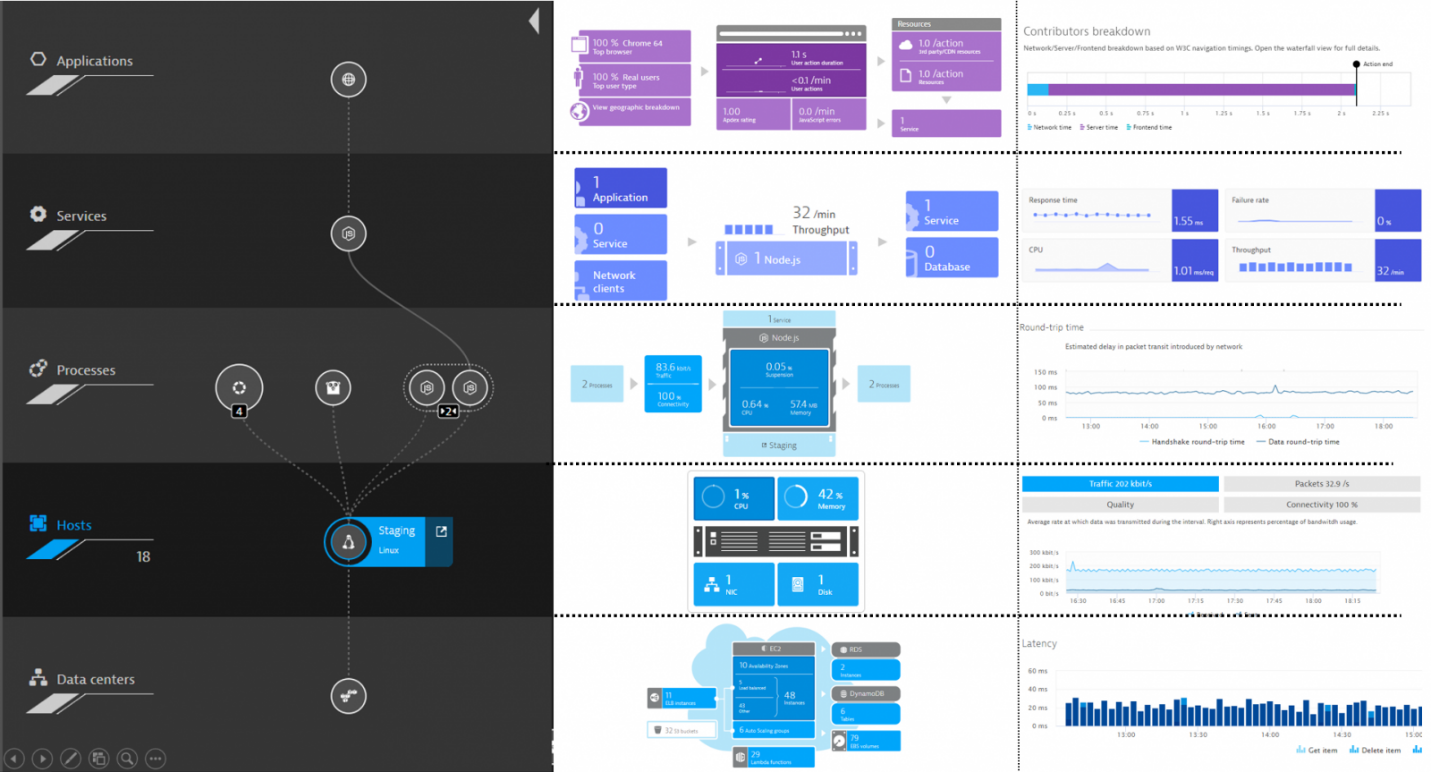 Monitoring levels in Dynatrace. Source
Monitoring levels in Dynatrace. Source
Secondly, as I said earlier, Dynatrace has an open API, which makes it very convenient to integrate it with various third-party systems. For example, sending a notification to the automation system when control parameters are exceeded.
Below is an example for interacting with Ansible.
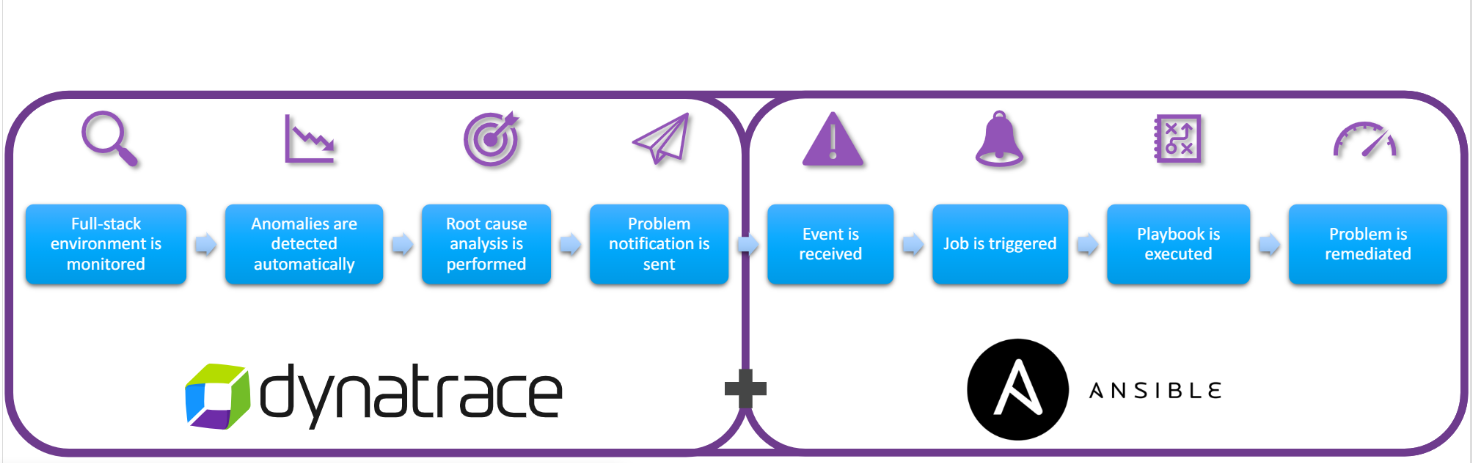 Source
Source
Next, I will give some examples of exactly which automation can be done. This is only part of the cases; listing them in your environment may be limited only by your imagination and the capabilities of your monitoring tools.
1. Bad deploy - version rollback
Even if we test everything very well in a test environment, there is still a chance that a new release may kill your application in the production environment. The same human factor has not been canceled.
In the next figure, we see that there is a sharp jump in the execution time of operations on the service. The beginning of this jump coincides with the deployment time to the application. We transfer all this information as events to the automation system. If the service’s serviceability does not normalize after the time specified by us expires, a script is automatically called that rolls back the version to the old one.
 Degradation of operational performance after deployment. Source
Degradation of operational performance after deployment. Source
2. Resource loading at 100% - add a node to the routing.
In the following example, the monitoring system determines that one of the components has 100% CPU utilization.
 CPU utilization 100%
CPU utilization 100%
Several different scenarios are possible for this event. For example, the monitoring system additionally checks whether the lack of resources is associated with an increase in the load on the service. If, yes, then a script is executed that automatically adds the node to the routing, thereby restoring the system as a whole.
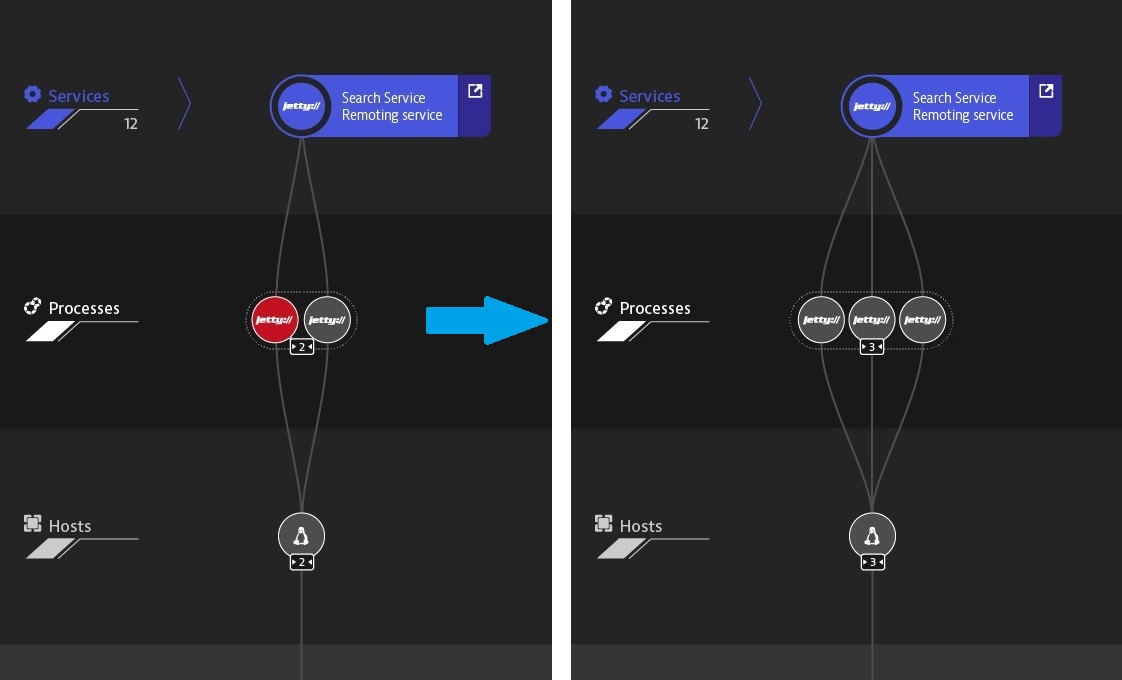 Scaling the nodes after the incident
Scaling the nodes after the incident
3. Lack of space on the hard disk - cleaning the disk
I think that many of these processes are already automated. Using APM, you can also monitor the free space on the disk subsystem. If there is no space or the disk is slow, we call the script to clean or add space.

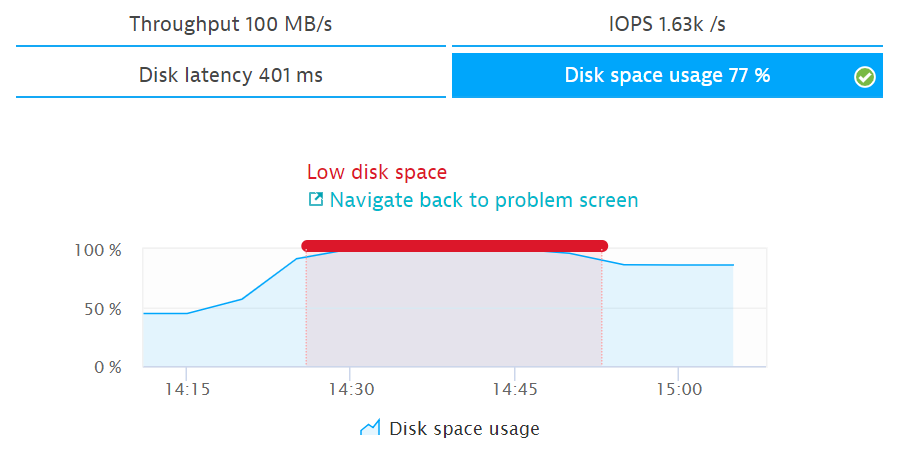 Disk loading 100%
Disk loading 100%
4. Low user activity or low conversion - switching between the blue and green branches
I often meet customers who use two circuits (blue-green deploy) for applications in the production environment. This allows you to quickly switch between branches when delivering new releases. Often after the deployment, cardinal changes can occur that are not immediately noticeable. However, degradation in performance and availability may not be observed. For quick response to such changes, it is better to use various metrics that reflect user behavior (the number of sessions and user actions, conversion, bounce rate). The following figure shows an example in which when the conversion drops, switching between software branches takes place.
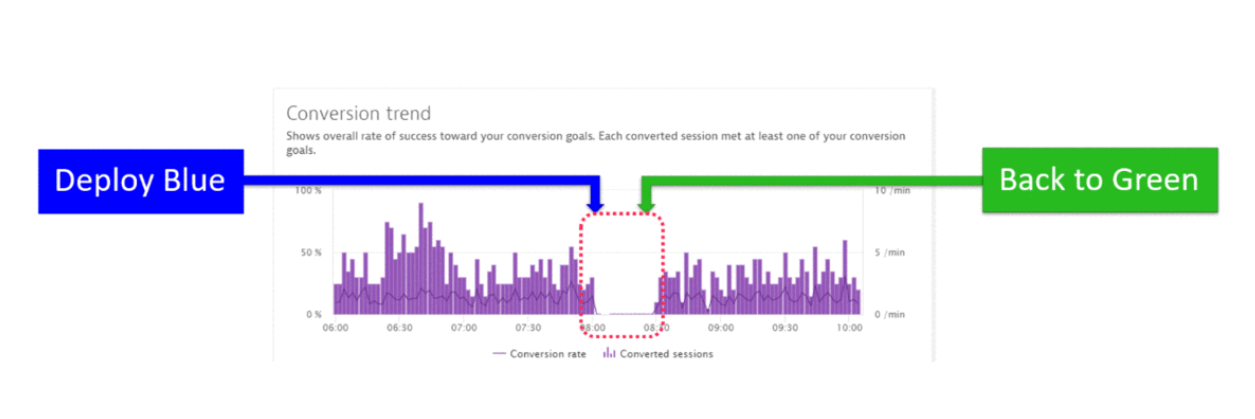 Conversion drop after switching between software branches. Source
Conversion drop after switching between software branches. Source
Mechanisms for automatic problem determination
In the end, I will give another example, for which I like Dynatrace the most.
In part of my story about the automation of assembly quality control in a test environment, we determined all threshold values in manual mode. This is normal for a test environment, the tester himself determines the indicators before each test, depending on the load. In the production environment, it is desirable that problems are detected automatically, taking into account the various baseline mechanisms.
Dynatrace has interesting built-in artificial intelligence tools that, based on the mechanisms for determining anomalous metrics (baselining) and constructing a map of interaction between all components, comparing and correlating events among themselves, determine anomalies in the work of your service and provide detailed information on each problem and root cause.
By automatically analyzing dependencies between components, Dynatrace determines not only whether the problematic service is the main cause, but also its dependence on other services. In the example below, Dynatrace automatically monitors and evaluates the health of each service as part of a transaction, identifies the Golang service as the main reason.
 An example of determining the root cause of a failure. Source
An example of determining the root cause of a failure. Source
The following figure shows the process of monitoring problems with your application from the start of an incident.
 Visualization of the emerging problem with the display of all components and events on them.
Visualization of the emerging problem with the display of all components and events on them.
The monitoring system has compiled a complete chronology of events on the emerging problem. In the window under the timeline, we see all the key events on each of the components. Based on these events, you can set procedures for automatic correction in the form of code scripts.
Additionally, I advise you to integrate the monitoring system with Service Desk or a bug tracker. If a problem arises, developers quickly receive complete information for its analysis at the code level in the production environment.
As a result, we ended up with a CI / CD pipeline with built-in automated software quality checks in Pipeline. We minimize the number of poor-quality assemblies, increase the reliability of the system as a whole, and if we still disrupt the system’s performance, we launch mechanisms to restore it.

It’s definitely worth the effort to automate software quality monitoring, it is not always a fast process, but over time it will bear fruit. I recommend that after solving a new incident in the production environment, immediately think about which monitors to add for checks in the test environment in order to avoid getting a bad build in the production, as well as create a script to automatically fix these problems.
I hope my examples will help you in your endeavors. It will also be interesting to me to see your examples of used metrics for the implementation of self-healing systems.
 A source
A source
{kind=link}
I work as an engineer in the IT services management department at LANIT-Integration. My core area is the implementation of various systems for monitoring the performance and availability of applications. I often communicate with IT customers from different market segments on topical issues of monitoring the quality of their IT services. The main task is to minimize the release cycle time and increase the frequency of their release. This, of course, is all good: more releases - more new features - more satisfied users - more profit. But in reality, not always everything turns out well. At very high deployment rates, the question immediately arises about the quality of our releases. Even with a fully automated pipeline, one of the biggest problems is the transfer of services from testing to production, without affecting uptime and user interaction with the application.
Based on the results of numerous conversations with customers, I can say that quality control of releases, the problem of application reliability and the possibility of its "self-healing" (for example, rollback to a stable version) at various stages of the CI / CD pipeline are among the most exciting and relevant topics.
Recently, I myself worked on the customer side - in the online banking application support service. The architecture of our application used a large number of self-written microservices. The saddest thing is that not all developers coped with the high development pace, the quality of some microservices suffered, which gave rise to ridiculous nicknames for them and their creators. There were stories about what materials these products are made of.
"Formulation of the problem"
The high frequency of releases and a large number of microservices make it difficult to understand the application as a whole, both at the testing stage and at the operational stage. Changes occur constantly and it is very difficult to control them without good monitoring tools. Often after a nightly release in the morning, developers sit on a powder keg and wait for nothing to break, although at the testing stage all the checks were successful.
There is one more point. At the testing stage, the operability of the software is checked: the implementation of the main functions of the application and the absence of errors. Qualitative estimates of performance are either absent or do not take into account all aspects of the application and the integration layer. Some metrics may not be checked at all. As a result, if a breakdown occurs in a productive environment, the technical support department only finds out when real users begin to complain. I would like to minimize the impact of low-quality software on end users.
One of the solutions is to implement software quality control processes at various stages of CI / CD Pipeline, add various scripts to restore the system in the event of an accident. Also remember that we have DevOps. Business expects to receive a new product as quickly as possible. Therefore, all our checks and scripts must be automated.
The task is divided into two components:
- quality control of assemblies at the testing stage (to automate the process of catching substandard assemblies);
- software quality control in the production environment (automatic problem detection mechanisms and possible scenarios for self-healing).
Tool for monitoring and collecting metrics
In order to realize the tasks set, a monitoring system is required that can detect problems and transfer them to automation systems at various stages of the CI / CD pipeline. Also, a positive point will be if this system provides useful metrics for various teams: development, testing, operation. And quite wonderful, if for business.
To collect metrics, you can use a combination of different systems (Prometheus, ELK Stack, Zabbix, etc.), but, in my opinion, APM ( Application Performance Monitoring ) solutions are best suited for these tasks , which can greatly simplify your life.
As part of my work in the escort service, I started to do a similar project using the APM class solution from Dynatrace. Now, working as an integrator, I know the market of monitoring systems quite well. My subjective opinion: Dynatrace is best suited for such tasks.
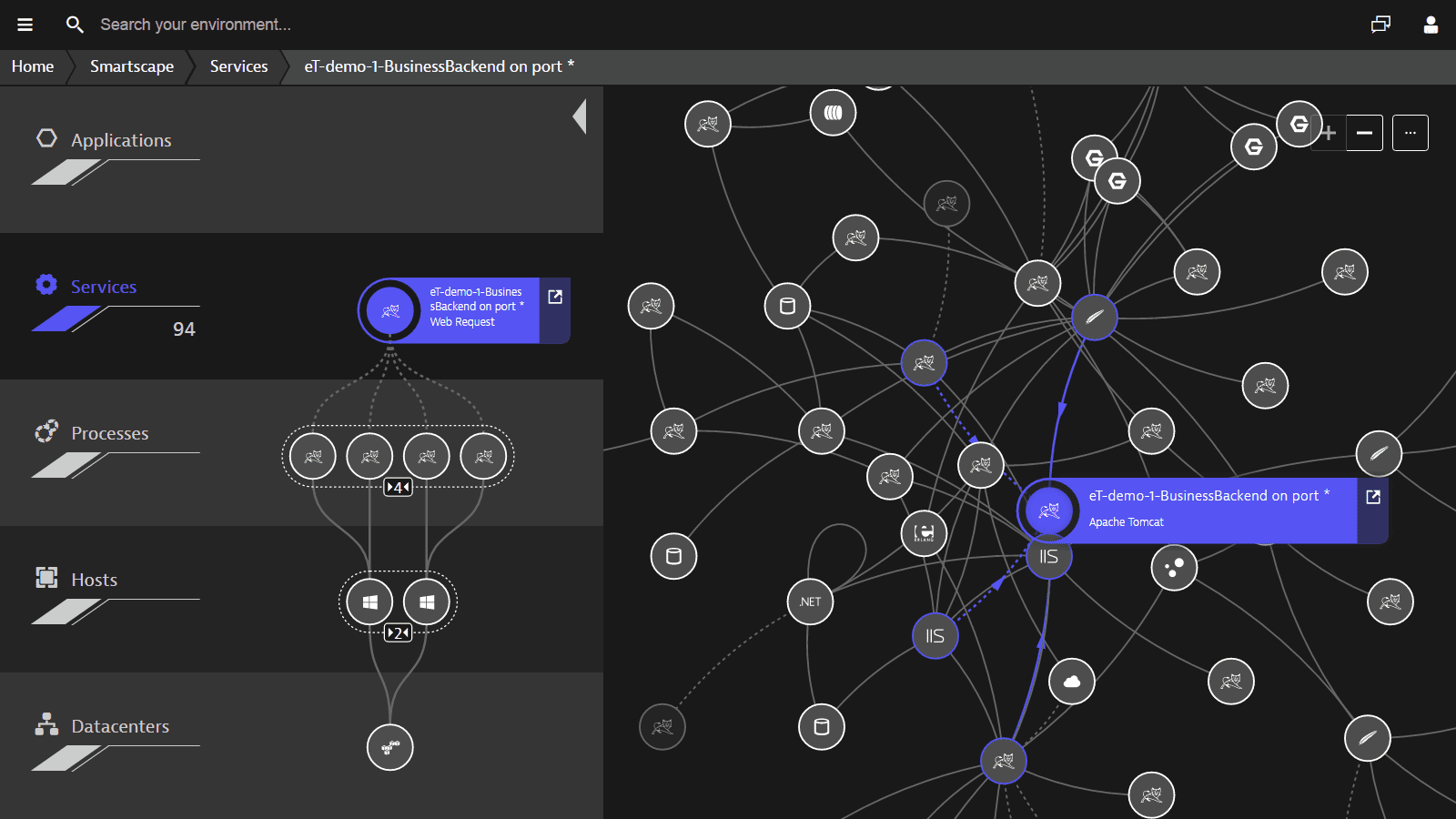
The Dynatrace solution provides a horizontal display of each user operation with a deep degree of detail down to the level of code execution. You can track the entire chain of interaction between various information services: from front-end levels of web and mobile applications, back-end application servers, integration bus to a specific call to the database.
{kind=link}
{kind=link}
We also remember that we need to integrate with various automation tools. Here the solution has a convenient API that allows you to send and receive various metrics and events.
Next, we move on to a more detailed discussion of how to solve tasks using the Dynatrace system.
Task 1. Automation of quality control of assemblies at the testing stage.
The first task is to find problems as early as possible at the stages of the application delivery pipeline. Only “good” builds of code should reach the prod environment. For this, additional monitors should be included in your pipeline at the testing stage to verify the quality of your services.
Let's look at the steps how to implement this and automate this process:
{kind=link}
The figure shows the flow of automated steps for checking the quality of software:
- deployment of a monitoring system (installation of agents);
- definition of events of your software quality assessment (metrics and threshold values) and their transfer to the monitoring system;
- load generation and performance tests;
- collecting performance and availability data in a monitoring system;
- transfer of test data based on software quality assessment events from the monitoring system to the CI / CD system. Automatic assembly analysis.
Step 1. Deploying the monitoring system
First you need to install the agents in your test environment. At the same time, the Dynatrace solution has a nice feature - it uses the OneAgent universal agent, which is installed on the OS instance (Windows, Linux, AIX), automatically detects your services and starts collecting monitoring data on them. You do not need to configure an agent separately for each process. A similar situation will be for cloud and container platforms. At the same time, you can also automate the installation of agents. Dynatrace fits perfectly into the concept of "infrastructure as code" ( Infrastructure as code or IaC): There are ready-made scripts and instructions for all popular platforms. Embed the agent in the configuration of your service, and when you deploy it, you immediately get a new service with an already running agent.
Step 2. Determining the events of assessing the quality of your software
Now you need to determine the list of services and business operations. It is important to consider exactly those user operations that are business critical for your service. Here I recommend consulting with business and system analysts.
Next, you need to determine which metrics you want to include in the verification for each of the levels. For example, it can be runtime (with separation by average, median, percentile, etc.), errors (logical, service, infrastructure, etc.) and various infrastructure metrics (memory heap, garbage collector, thread count, etc.).
For automation and ease of use, the DevOps team introduces the concept of “Monitoring as code”. What I mean by this is that a developer / tester can write a simple JSON file that defines the indicators of software quality control.
Let's look at an example of such a JSON file. Objects from the Dynatrace API are used as a key / value pair (see the Dynatrace API description of the API ).
{
"timeseries": [
{
"timeseriesId": "service.ResponseTime",
"aggregation": "avg",
"tags": "Frontend",
"severe": 250000,
"warning": 1000000
},
{
"timeseriesId": "service.ResponseTime ",
"aggregation": "avg",
"tags": "Backend",
"severe": 4000000,
"warning": 8000000
},
{
"timeseriesId": "docker.Container.Cpu",
"aggregation": "avg",
"severe": 50,
"warning": 70
}
]
}The file is an array of timeseries definitions:
- timeseriesId - metric checked, for example, Response Time, Error count, Memory used, etc .;
- aggregation - the level of aggregation of metrics, in our case avg, but you can use whatever you need (avg, min, max, sum, count, percentile);
- tags - an object tag in the monitoring system, or you can specify a specific object identifier;
- severe and warning - these indicators regulate the threshold values of our metrics, if the value of the tests exceeds the severe threshold, then our assembly is marked as unsuccessful.
The following figure shows an example of the use of such trasholds.
{kind=link}
Step 3. Load generation
After we have determined the quality levels of our service, it is necessary to generate a test load. You can use any of the testing tools that are convenient for you, for example, Jmeter, Selenium, Neotys, Gatling, etc.
The Dynatrace monitoring system allows you to capture various metadata from your tests and recognize which test relates to which release cycle and which service. It is recommended that you add additional headers to the test HTTP requests.
The following figure shows an example where, using the optional X-Dynatrace-Test header, we mark that this test refers to testing the operation of adding an item to the basket.
{kind=link}
When you run each load test, you send additional contextual information to Dynatrace using the event API from the CI / CD server. Thus, the system can distinguish between different tests among themselves.
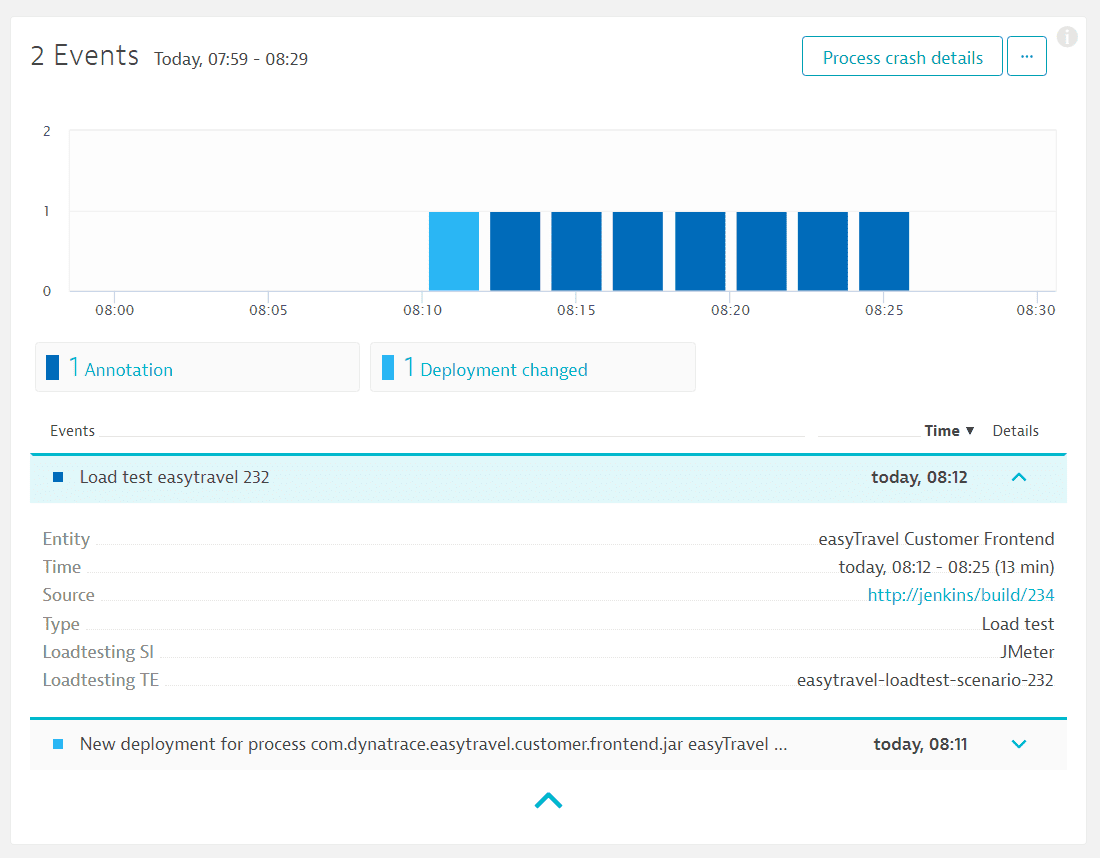{kind=link}
Step 4-5. Collecting performance data and transferring data to the CI / CD system
Together with the generated test, an event is transmitted to the monitoring system about the need to collect data on checking service quality indicators. Our JSON file is also indicated, in which key metrics are defined.
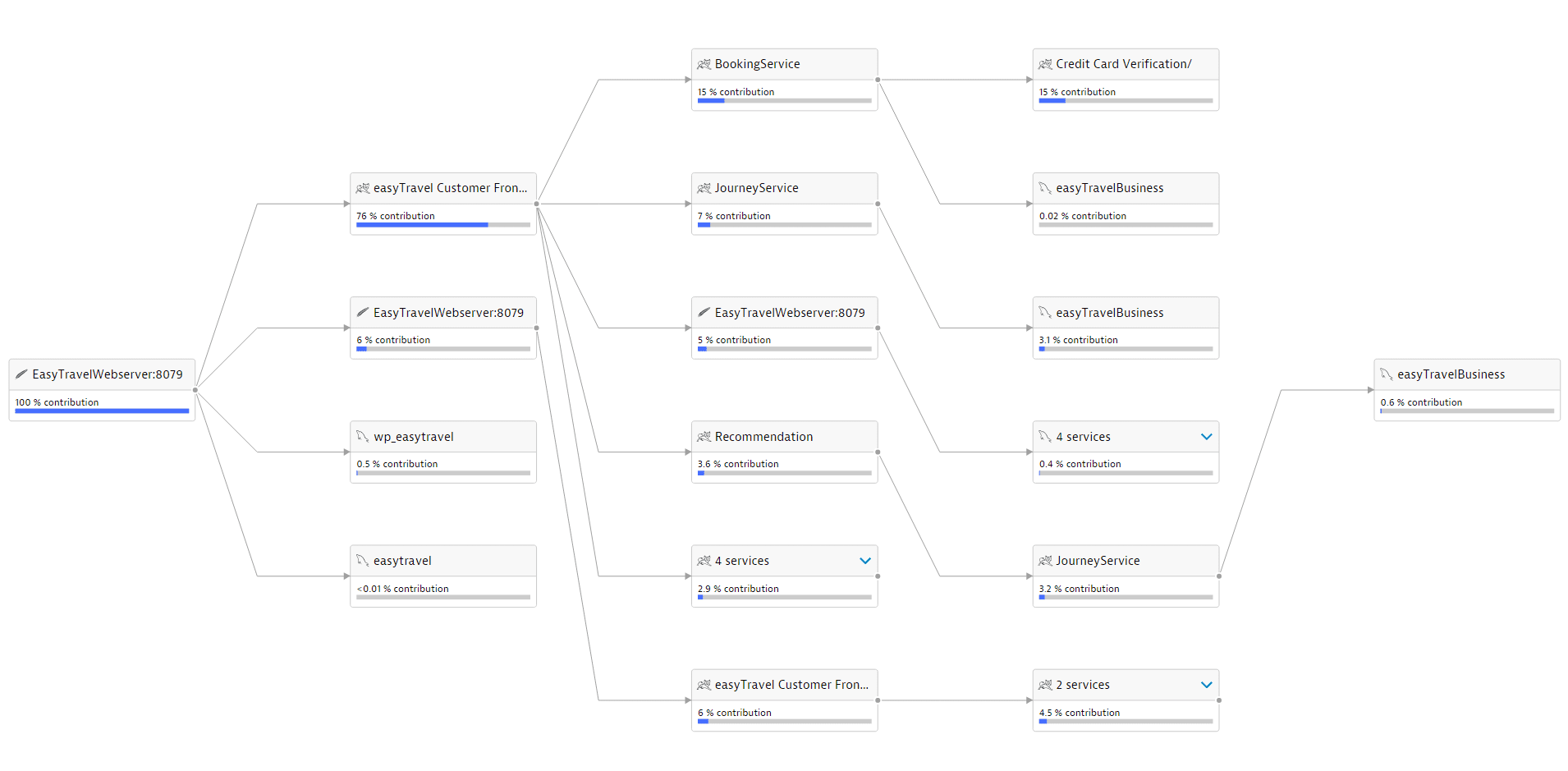
In our example, the quality control event is called perfSigDynatraceReport (Performance_Signature ) - this is a ready - made plug - in for integration with Jenkins, which was developed by the guys from T-Systems Multimedia Solutions. Each event about the launch of the test contains information about the service, build number, and test time. The plugin collects performance values during assembly, evaluates them and compares the result with previous assemblies and non-functional requirements.
{kind=link}
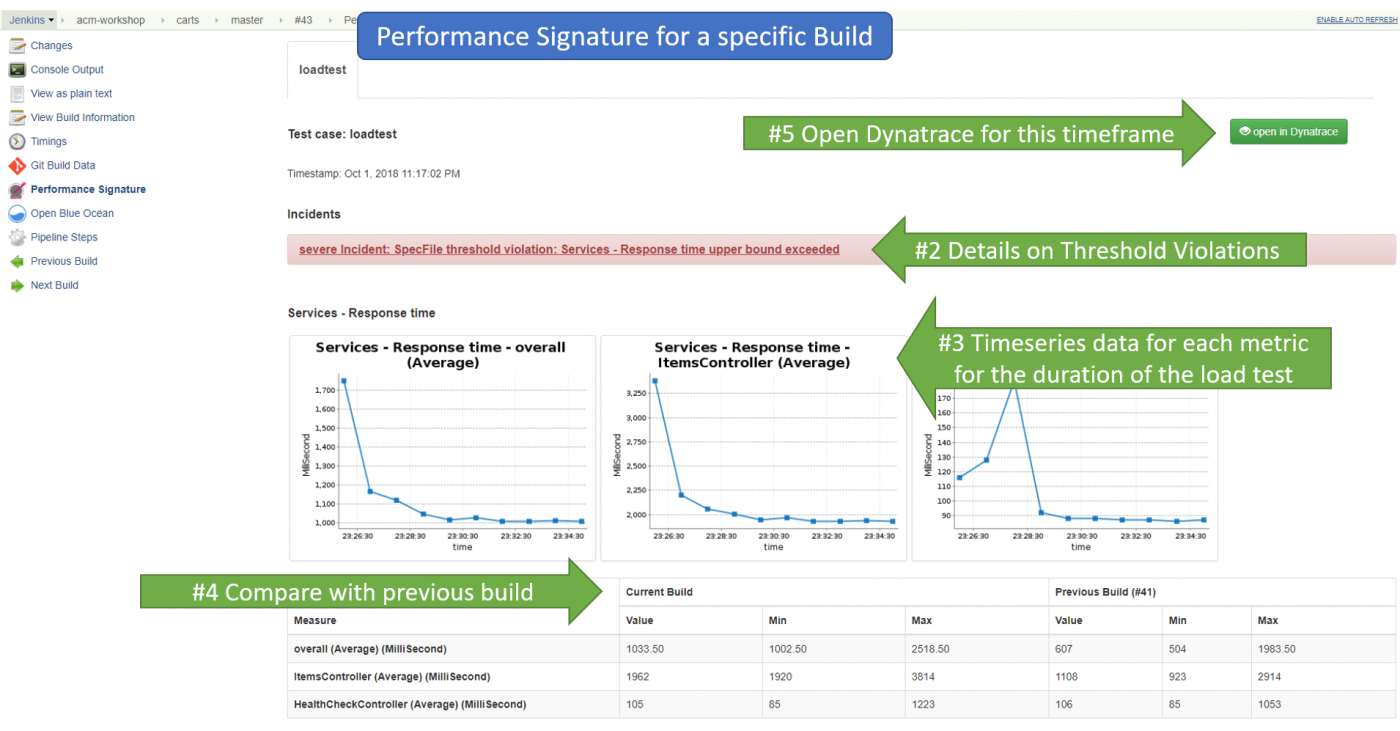
After the test is completed, all software quality assessment metrics are transferred back to the continuous integration system, for example, Jenkins, which generates a report on the results.
For each individual assembly, we see statistics for each metric we set during the entire test. We also see if there were violations at certain threshold values (warning and severe thrasholds). Based on the aggregate metrics, the entire assembly is marked as stable, unstable, or failed. Also, for convenience, you can add indicators for comparing the current assembly with the previous one in the report.
{kind=link}
detailed comparison of two assemblies
If necessary, you can go to the Dynatrace interface and there look in more detail at the statistics for each of your assemblies and compare them with each other.
Conclusions
As a result, we get the service “monitoring as a service”, automated in the pipeline of continuous integration. The developer or tester only needs to determine the list of metrics in the JSON file, and everything else happens automatically. We get transparent quality control of releases: all notifications of performance, resource consumption, or architectural regressions.
Task 2. Automation of software quality control in a production environment
So, we have solved the problem of how to automate the monitoring process at the testing stage in Pipeline. Thus, we minimize the percentage of low-quality assemblies that reach the production environment.
But what to do if bad software still got to the point of sale, well, or just something breaks. For utopia, we wanted the mechanisms to automatically detect problems to be present and, if possible, the system itself would recover, even at night.
To do this, we, by analogy with the previous section, provide automatic software quality checks in the production environment and lay scripts for self-healing of the system under them.
Autocorrection as a code
Most companies already have an accumulated knowledge base on various types of common problems and a list of actions to fix them, for example, restarting processes, cleaning resources, rolling back versions, restoring incorrect configuration changes, increasing or decreasing the number of components in a cluster, switching blue or green outline, etc.
Despite the fact that these use cases have been known for many years to many teams with which I communicate, only a few thought and invested Twa in their automation.
If you think about it, then in the implementation of processes for self-healing the application’s health there is nothing super complicated, you need to present the well-known work scenarios of your admins in the form of code scripts (the concept of “autocorrection as code”) that you wrote in advance for each specific case. Automatic repair scenarios should address the root cause of the problem. You set the right incident response actions yourself.
Any metric from your monitoring system can act as a trigger for running a script, the main thing is that these metrics accurately determine that everything is bad, since I would not want to get false positives in a productive environment.
You can use any system or set of systems: Prometheus, ELK Stack, Zabbix, etc. But I will give some examples based on the APM solution (Dynatrace will again be an example), which will also help make your life easier.
Firstly, there is everything that relates to operability from the point of view of the application. The solution provides hundreds of metrics at various levels that you can use as triggers:
- user level (browsers, mobile applications, IoT devices, user behavior, conversion, etc.);
- level of service and operations (performance, availability, errors, etc.);
- application infrastructure level (host OS metrics, JMX, MQ, web-server, etc.);
- platform level (virtualization, cloud, container, etc.).
{kind=link}
Secondly, as I said earlier, Dynatrace has an open API, which makes it very convenient to integrate it with various third-party systems. For example, sending a notification to the automation system when control parameters are exceeded.
Below is an example for interacting with Ansible.
Next, I will give some examples of exactly which automation can be done. This is only part of the cases; listing them in your environment may be limited only by your imagination and the capabilities of your monitoring tools.
1. Bad deploy - version rollback
Even if we test everything very well in a test environment, there is still a chance that a new release may kill your application in the production environment. The same human factor has not been canceled.
In the next figure, we see that there is a sharp jump in the execution time of operations on the service. The beginning of this jump coincides with the deployment time to the application. We transfer all this information as events to the automation system. If the service’s serviceability does not normalize after the time specified by us expires, a script is automatically called that rolls back the version to the old one.
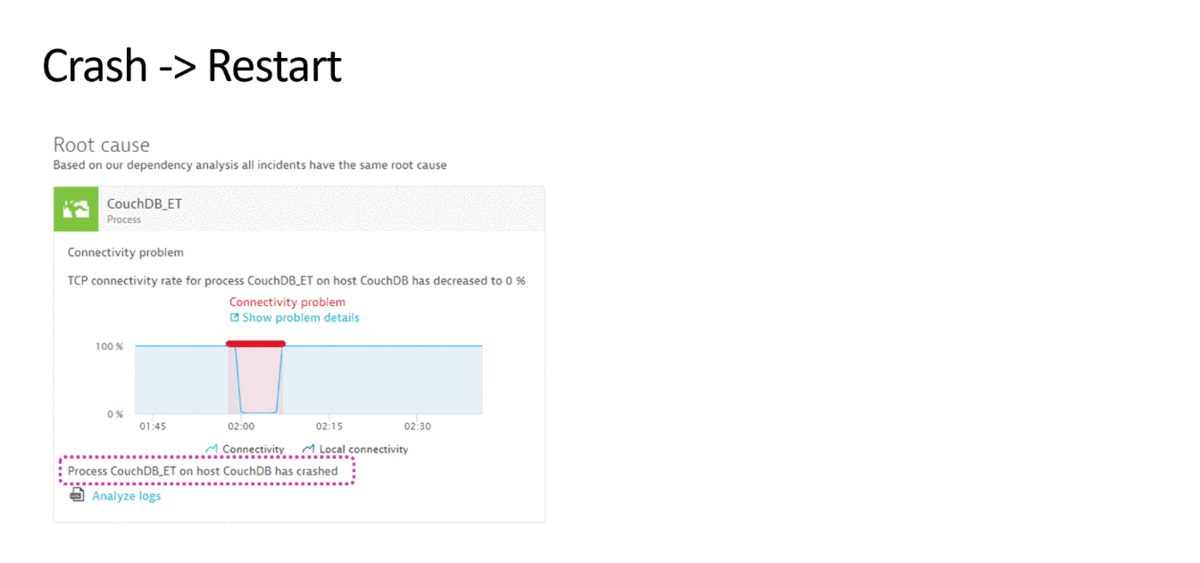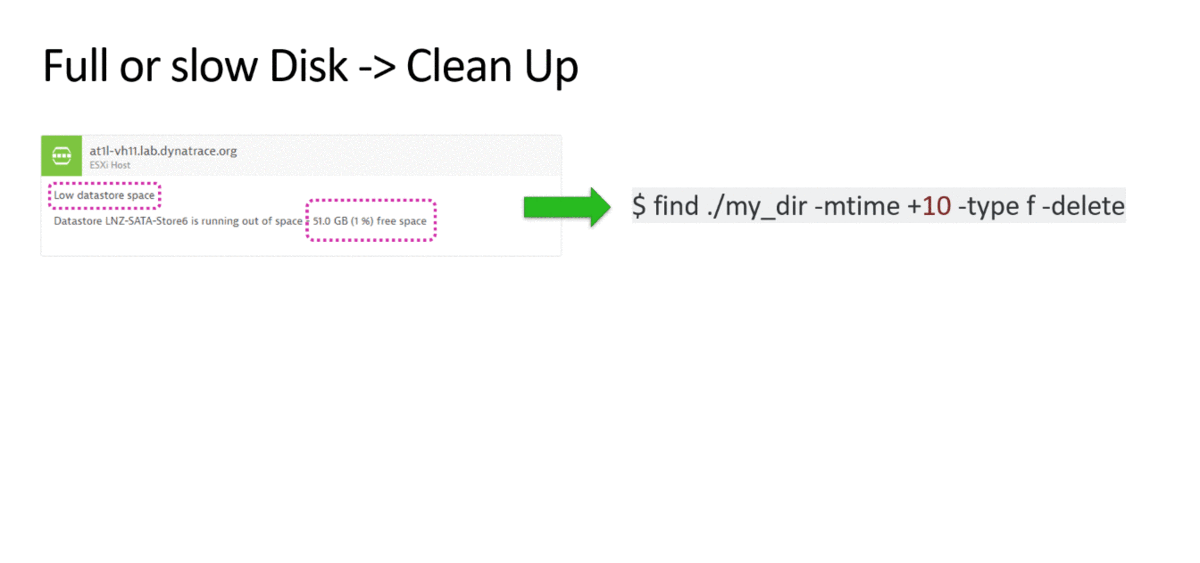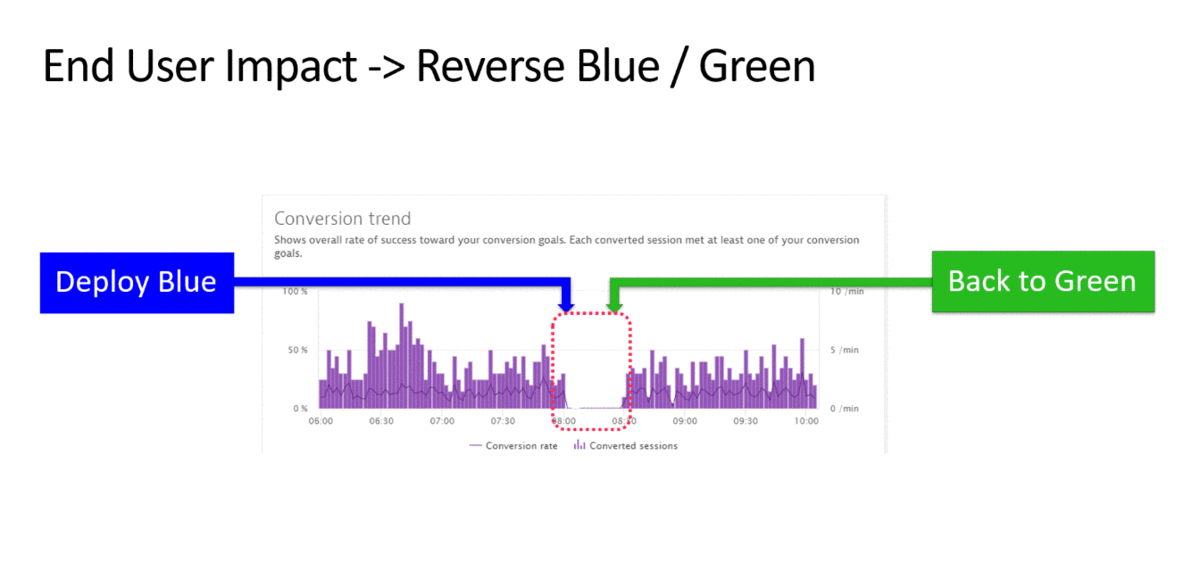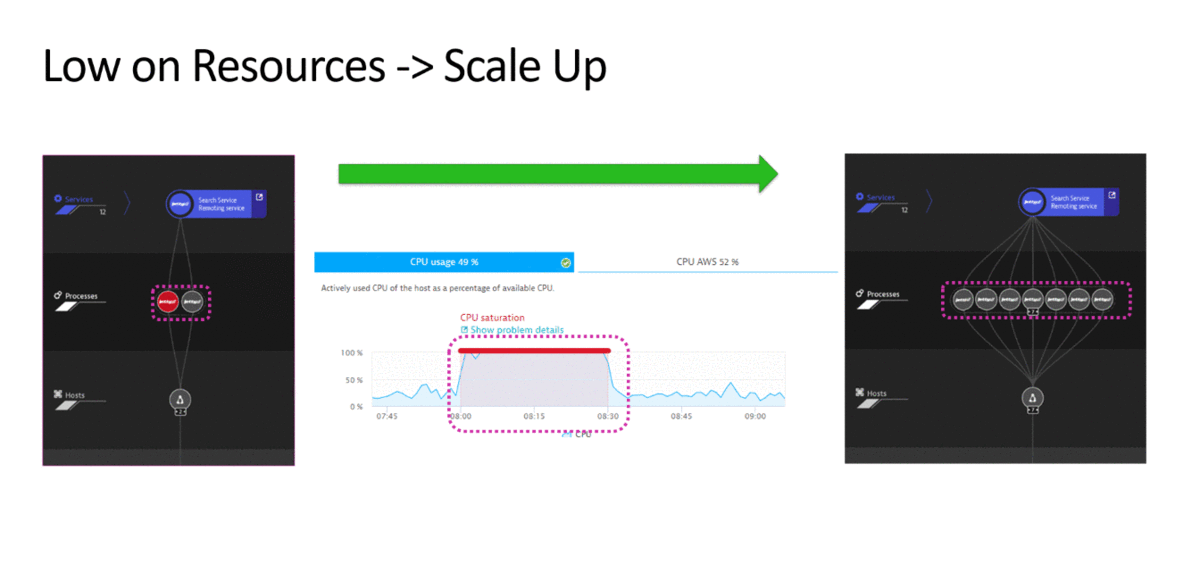{kind=link}
2. Resource loading at 100% - add a node to the routing.
In the following example, the monitoring system determines that one of the components has 100% CPU utilization.
Several different scenarios are possible for this event. For example, the monitoring system additionally checks whether the lack of resources is associated with an increase in the load on the service. If, yes, then a script is executed that automatically adds the node to the routing, thereby restoring the system as a whole.
3. Lack of space on the hard disk - cleaning the disk
I think that many of these processes are already automated. Using APM, you can also monitor the free space on the disk subsystem. If there is no space or the disk is slow, we call the script to clean or add space.
4. Low user activity or low conversion - switching between the blue and green branches
I often meet customers who use two circuits (blue-green deploy) for applications in the production environment. This allows you to quickly switch between branches when delivering new releases. Often after the deployment, cardinal changes can occur that are not immediately noticeable. However, degradation in performance and availability may not be observed. For quick response to such changes, it is better to use various metrics that reflect user behavior (the number of sessions and user actions, conversion, bounce rate). The following figure shows an example in which when the conversion drops, switching between software branches takes place.
Mechanisms for automatic problem determination
In the end, I will give another example, for which I like Dynatrace the most.
In part of my story about the automation of assembly quality control in a test environment, we determined all threshold values in manual mode. This is normal for a test environment, the tester himself determines the indicators before each test, depending on the load. In the production environment, it is desirable that problems are detected automatically, taking into account the various baseline mechanisms.
Dynatrace has interesting built-in artificial intelligence tools that, based on the mechanisms for determining anomalous metrics (baselining) and constructing a map of interaction between all components, comparing and correlating events among themselves, determine anomalies in the work of your service and provide detailed information on each problem and root cause.
By automatically analyzing dependencies between components, Dynatrace determines not only whether the problematic service is the main cause, but also its dependence on other services. In the example below, Dynatrace automatically monitors and evaluates the health of each service as part of a transaction, identifies the Golang service as the main reason.
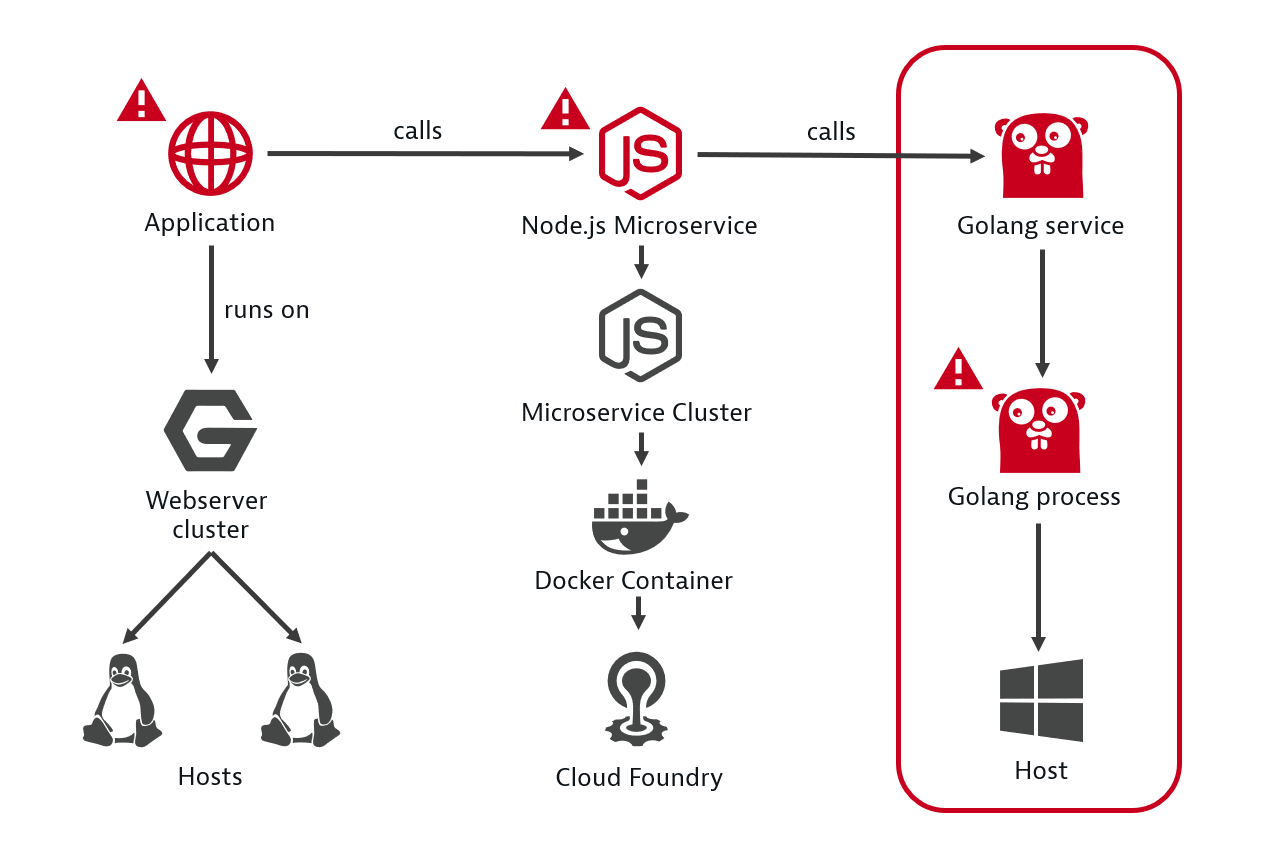{kind=link}
The following figure shows the process of monitoring problems with your application from the start of an incident.
The monitoring system has compiled a complete chronology of events on the emerging problem. In the window under the timeline, we see all the key events on each of the components. Based on these events, you can set procedures for automatic correction in the form of code scripts.
Additionally, I advise you to integrate the monitoring system with Service Desk or a bug tracker. If a problem arises, developers quickly receive complete information for its analysis at the code level in the production environment.
Conclusion
As a result, we ended up with a CI / CD pipeline with built-in automated software quality checks in Pipeline. We minimize the number of poor-quality assemblies, increase the reliability of the system as a whole, and if we still disrupt the system’s performance, we launch mechanisms to restore it.
It’s definitely worth the effort to automate software quality monitoring, it is not always a fast process, but over time it will bear fruit. I recommend that after solving a new incident in the production environment, immediately think about which monitors to add for checks in the test environment in order to avoid getting a bad build in the production, as well as create a script to automatically fix these problems.
I hope my examples will help you in your endeavors. It will also be interesting to me to see your examples of used metrics for the implementation of self-healing systems.
{kind=link}