Fundamentals of modern artificial intelligence: how does it work, and will it destroy our society this year?
- Transfer
Today's AI is technically “weak” - however, it is complex and can significantly affect society

You don’t need to be Cyrus Dully to know how frightening an intelligent intelligence can become [an American actor who played the role of astronaut Dave Bowman in the film "Space Odyssey 2001" / approx. transl.]
AI, or artificial intelligence, is now one of the most important areas of knowledge. “Unsolvable” problems are being solved, billions of dollars are being invested, and Microsoft even hires Common to tell us in poetic calm, what a wonderful thing this is - AI. That's right.
And, as with any new technology, it can be difficult to get through all this hype. I have been doing research in the field of drones and AI for years, but even it can be difficult for me to keep up with all this. In recent years, I spent a lot of time looking for answers to even the simplest questions like:
- What do people mean by saying “AI”?
- What is the difference between AI, machine learning, and deep learning?
- What is so great about deep learning?
- Which former difficult tasks are now easy to solve, and what is still difficult?
I know that not one is interested in such things. Therefore, if you are interested in what all these enthusiasms about AI are connected at the simplest level, it's time to look behind the scenes. If you are an AI expert and read reports from a conference on neurological information processing (NIPS) for fun, the article will not be anything new for you - however, we expect clarifications and corrections from you in the comments.
What is AI?
There is such an old joke in computer science: what is the difference between AI and automation? Automation is something that can be done using a computer, and AI is something we would like to be able to do. As soon as we learn how to do something, it moves from the field of AI to the category of automation.
This joke is valid today, since AI is not defined clearly enough. Artificial Intelligence is simply not a technical term. If you climb into Wikipedia, it says that AI is "the intelligence demonstrated by machines, in contrast to the natural intelligence demonstrated by people and other animals." You can’t say less clearly.
In general, there are two types of AI: strong and weak. Most people imagine a strong AI when they hear about AI - it's some kind of god-like omniscient intellect like Skynet or Hal 9000, capable of reasoning and comparable to human, while exceeding its capabilities.
Weak AIs are highly specialized algorithms designed to answer specific useful questions in narrowly defined areas. For example, a very good chess program falls into this category. The same can be said about software that very accurately adjusts insurance payments. In their field, such AIs achieve impressive results, but in general they are very limited.
With the exception of Hollywood opuses, today we have not even come close to a strong AI. So far, any AI is weak, and most researchers in this area agree that the techniques we invented to create great weak AIs are not likely to bring us closer to creating a strong AI.
So today's AI is more a marketing term than a technical one. The reason companies advertise their AI instead of automation is because they want to introduce Hollywood AI into the public mind. However, this is not so bad. If this is not taken too strictly, the companies only want to say that, although we are still very far from a strong AI, today's weak AI is much more capable than existed several years ago.
And if you distract from marketing, then so it is. In certain areas, the capabilities of machines have increased dramatically, and mainly thanks to two more phrases that are now fashionable: machine learning and deep learning.
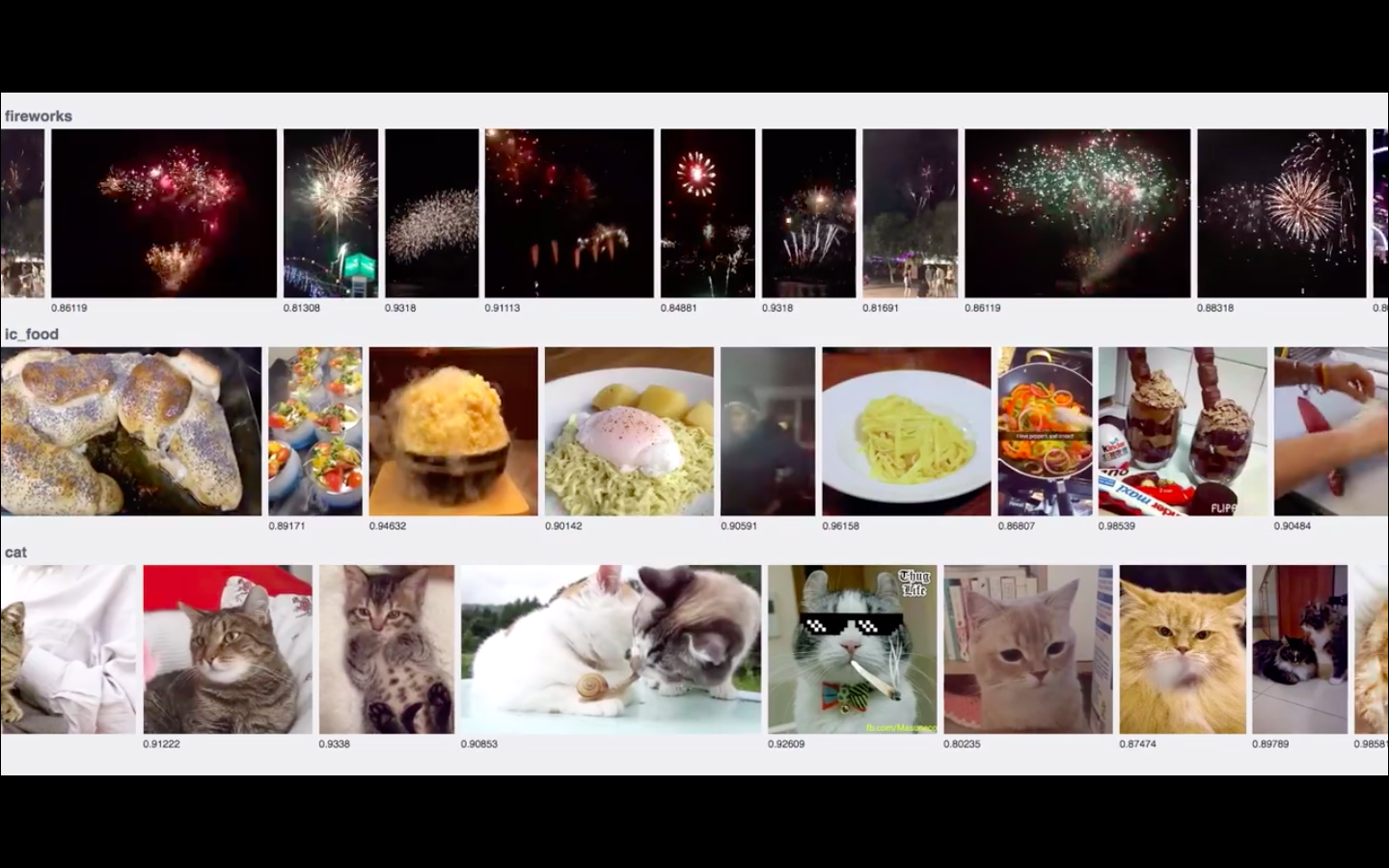
Shot from a short video from Facebook engineers showing how real-time AI recognizes cats (a task also known as the holy grail of the Internet)
Machine learning
MO is a special way to create machine intelligence. Suppose you want to launch a rocket, and predict where it will go. In general, it’s not so difficult: gravity is pretty well studied, you can write down the equations and calculate where it will go, based on several variables - such as speed and initial position.
However, this approach becomes awkward if we turn to an area whose rules are not so well known and clear. Suppose you want the computer to tell you if there are any cats on some images. How will you write down the rules that describe the view in all possible points of view on all possible combinations of mustache and ears?
Today, the MO approach is well known: instead of trying to write down all the rules, you create a system that can independently derive a set of internal rules after studying a huge number of examples. Instead of describing cats, you simply show your AI a bunch of photos of cats, and let him understand on his own what is a cat and what is not.
And today it’s the perfect approach. A self-learning system based on data can be improved simply by adding data. And if our species is able to do something very well, it is to generate, store and manage data. Want to learn how to better recognize cats? The Internet is generating millions of examples right this minute.
The ever-increasing flow of data is one of the reasons for the explosive growth of MO algorithms in recent times. Other reasons are related to the use of this data.
In addition to the data, there are two more issues related to this for the Moscow Region:
- How do I remember what I’ve learned? How to store and present on the computer the communications and rules that I deduced from the data?
- How do i learn? How to change the stored representation in response to new examples, and improve?
In other words, what exactly is being trained on the basis of all this data?
In MO, the computational representation of the training we store is a model. The type of model used is very important: it determines how your AI learns, what data it can learn from, and what questions you can ask it.
Let's look at a very simple example. Suppose we buy figs at a grocery store and want to make an AI with the MO that would tell us if it is ripe. This should be easy to do, because in the case of figs, the softer the sweeter.
We can take several samples of ripe and unripe figs, see how sweet they are, and then place them on the chart and adjust the straight line for it. This line will be our model.

Embryo AI in the form of “the softer the sweeter”

With the addition of new data, the task becomes more complicated.
Look! The straight line implicitly follows the idea that "the softer they are, the sweeter", and we did not even have to write anything down. Our AI fetus does not know anything about sugar content or ripening fruit, but can predict the sweetness of a fruit by squeezing it.
How to train a model to make it better? We can collect even more samples and draw another straight line to get more accurate predictions (as in the second picture above). However, the problems immediately become apparent. So far, we have been training our fig AI on quality berries - what if we take data from the orchard? Suddenly, we have not only ripe, but also rotten fruits. They are very soft, but definitely not suitable for eating.
What should we do? Well, since this is a MO model, we can just feed her more data, right?
As the first picture below shows, in this case we will get completely meaningless results. The line is simply not suitable for describing what happens when the fruit becomes too ripe. Our model no longer fits into the data structure.
Instead, we have to change it, and use a better and more complex model - perhaps a parabola, or something similar. This change complicates learning because drawing curves requires more sophisticated mathematics than drawing a straight line.
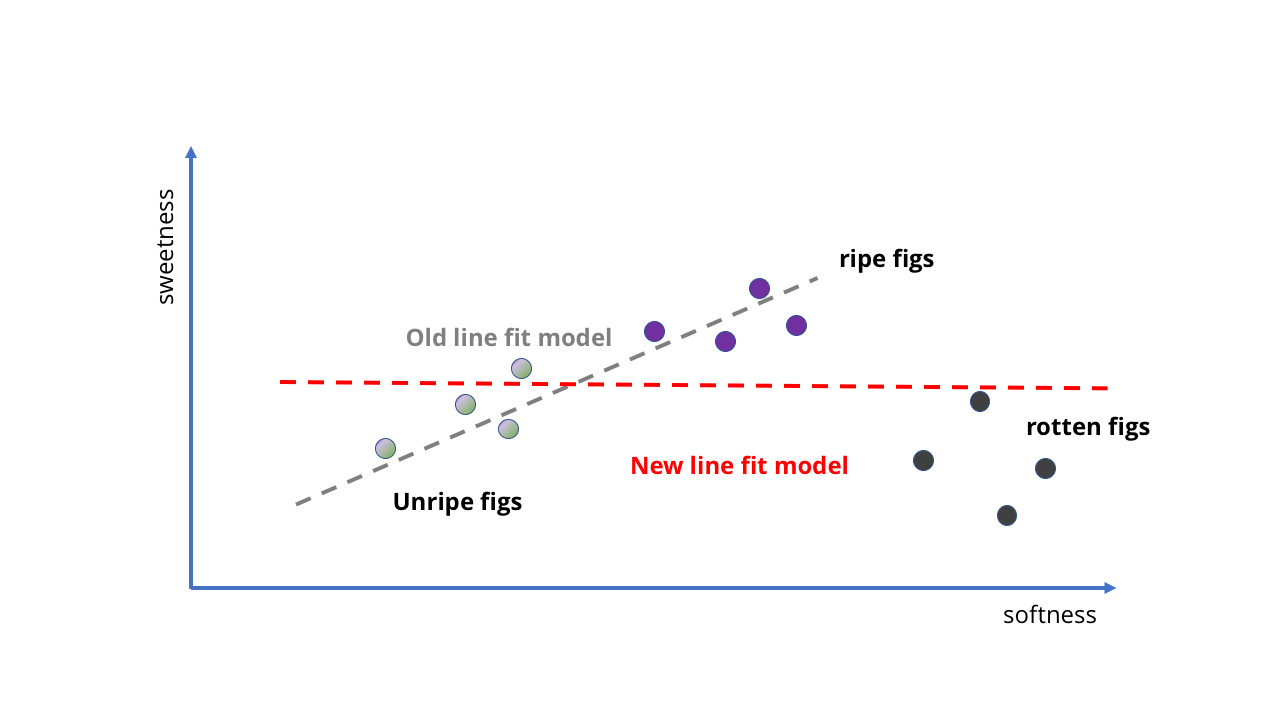
Okay, probably, the idea of using the straight line for complex AI was not very successful.
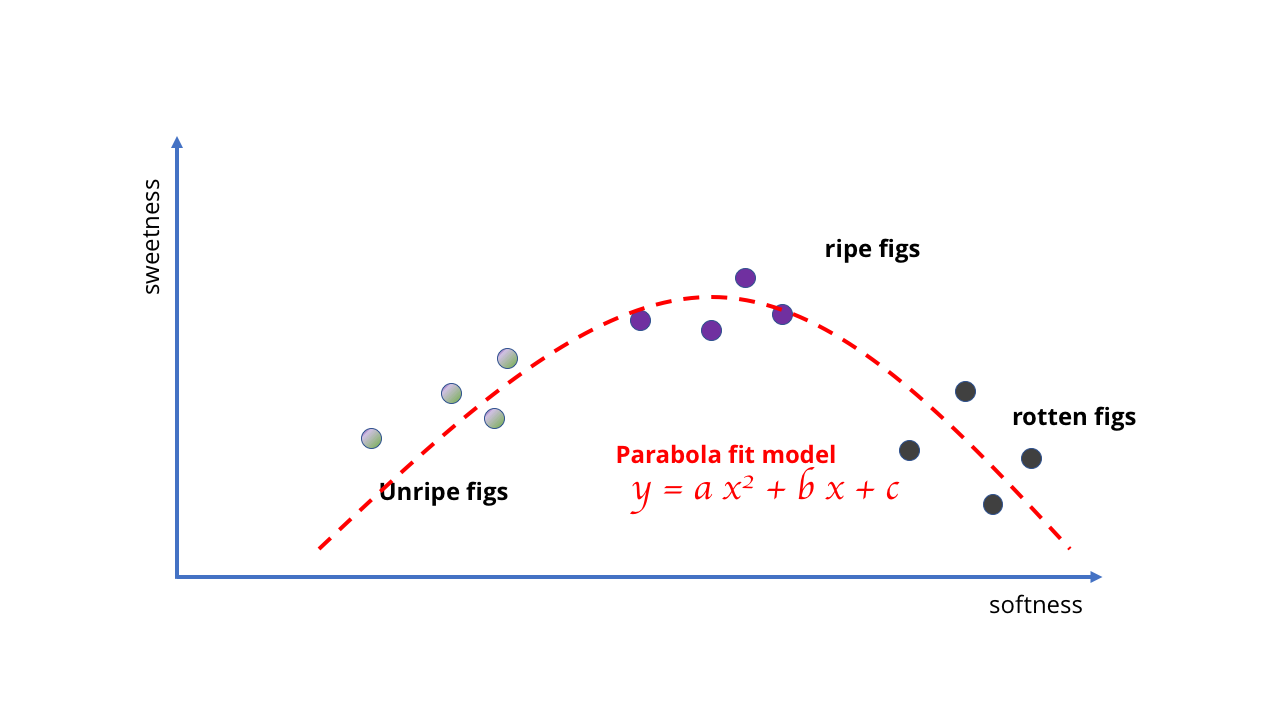
It requires more complicated mathematics.
The example is rather stupid, but it shows that the choice of model determines the possibilities of learning. In the case of figs, the data is simple, and the models can be simple. But if you are trying to learn something more complex, more complex models are required. Just as no amount of data makes a linear model reflect the behavior of rotten berries, it is impossible to select a simple curve corresponding to a bunch of pictures to create a computer vision algorithm.
Therefore, the difficulty for the MO is to create and select the right models for the corresponding tasks. We need a model that is complex enough to describe the really complex relationships and structures, but simple enough so that you can work with it and train it. So, although the Internet, smartphones, and so on have created incredible mountains of data to learn from, we still need the right models to take advantage of this data.
This is where deep learning comes into play.

Deep learning
Deep learning is machine learning that uses a certain type of model: deep neural networks.
Neural networks are a type of MO model that uses a structure resembling neurons in the brain for calculations and predictions. Neurons in neural networks are organized in layers: each layer performs a set of simple calculations and passes the answer to the next.
The layered model allows for more complex calculations. A simple network with a small number of neuron layers is enough to reproduce the straight line or parabola that we used above. Deep neural networks are neural networks with a large number of layers, with dozens, or even hundreds; hence their name. With so many layers, you can create incredibly powerful models.
This opportunity is one of the main reasons for the huge popularity of deep neural networks in recent times. They can learn various complex things without forcing a human researcher to define any rules, and this allowed us to create algorithms that can solve a variety of problems that computers could not approach before.
However, another aspect contributed to the success of neural networks: training.
A model’s “memory” is a set of numerical parameters that determines how it provides answers to questions asked. To train a model means to fine-tune these parameters so that the model gives the best answers possible.
In our model with figs, we searched for the equation of the line. This is a simple regression task, and there are formulas that will give you the answer in one step.

Simple neural network and deep neural network.
With more complex models, everything is not so simple. A straight line and a parabola can easily be represented by several numbers, but a deep neural network can have millions of parameters, and the data set for its training can also consist of millions of examples. An analytical solution in one step does not exist.
Fortunately, there is one strange trick: you can start with a bad neural network, and then improve it with gradual tweaks.
Learning the MO model in this way is similar to testing a student using tests. Each time we get an assessment by comparing what answers should be in the opinion of the model with the “correct” answers in the training data. Then we make an improvement and run the test again.
How do we know which parameters to adjust, and how much? Neural networks have such a cool feature when for many types of training you can not only get an assessment in the test, but also calculate how much it will change in response to a change in each parameter. In mathematical terms, an estimate is a function of value, and for most of these functions we can easily calculate the gradient of this function with respect to the parameter space.
Now we know exactly which way we need to adjust the parameters to increase the score, and we can adjust the network by successive steps in all the best and best “directions” until you reach a point where nothing can be improved. This is often referred to as climbing a hill, because it really is like moving up a hill: if you constantly move up, you will end up on top.

Have you seen? Vertex!
Thanks to this, it is easy to improve the neural network. If your network has a good structure, having received new data, you do not need to start from scratch. You can start with the available parameters, and re-learn from the new data. Your network will gradually improve. The most prominent of today's AIs - from cat recognition on Facebook to technologies that Amazon (probably) uses in stores without sellers - are built on this simple fact.
This is the key to one more reason why GO has spread so quickly and so widely: climbing a hill allows you to take one neural network trained to some task and retrain it to perform another, but similar one. If you have trained AI to recognize cats well, this network can be used to train AI that recognizes dogs or giraffes without having to start from scratch. Start with the AI for cats, evaluate it by the quality of dog recognition, and then climb the hill, improving the network!
Therefore, in the last 5-6 years, there has been a sharp improvement in the capabilities of AI. Several pieces of the puzzle came together in a synergistic way: the Internet generated a huge amount of data to learn from. Computations, especially parallel computations on GPUs, made it possible to process these huge sets. Finally, deep neural networks made it possible to take advantage of these kits and create incredibly powerful MO models.
And all this means that some things that were previously extremely difficult are now very easy to do.
And what can we do now? Pattern recognition
Perhaps the deepest (sorry for the pun) and the earliest impact deep learning had on the field of computer vision - in particular, on the recognition of objects in photographs. A few years ago, this xkcd comic perfectly described the cutting edge of computer science:

Today, recognizing birds and even certain types of birds is a trivial task that a correctly motivated high school student can solve. What has changed?
The idea of visual recognition of objects is easy to describe, but difficult to implement: complex objects consist of sets of simpler ones, which in turn consist of simpler shapes and lines. Faces consist of eyes, noses and mouths, and those consist of circles and lines, and so on.
Therefore, face recognition becomes a matter of recognizing patterns in which the eyes and mouths are located, which may require recognition of the shape of the eye and mouth from lines and circles.
These patterns are called features, and before deep learning for recognition, it was necessary to describe all the features manually and program the computer to find them. For example, there is the famous Viola-Jones method of face recognition based on the fact that the eyebrows and nose are usually lighter than the eye sockets, so they form a bright T-shape with two dark points. The algorithm, in fact, is looking for similar T-shapes.
The Viola-Jones method works well and is surprisingly fast, and serves as the basis for face recognition in cheap cameras, etc. But, obviously, not every object that you need to recognize lends itself to such a simplification, and people came up with increasingly complex and low-level patterns. For the algorithms to work correctly, a team of doctors of sciences was required, they were very sensitive and prone to failure.
The big breakthrough came about thanks to civil defense, and in particular to a certain type of neural network called convolutional neural network. Convolutional neural networks, SNS are deep networks with a certain structure, inspired by the structure of the visual cortex of the mammalian brain. This structure allows the SNA to independently learn the hierarchy of lines and patterns for recognizing objects, rather than waiting for doctors of science to spend years researching which features are best suited for this. For example, the SNA, trained on faces, will learn its own internal representation of lines and circles that form in the eyes, ears and noses, and so on.
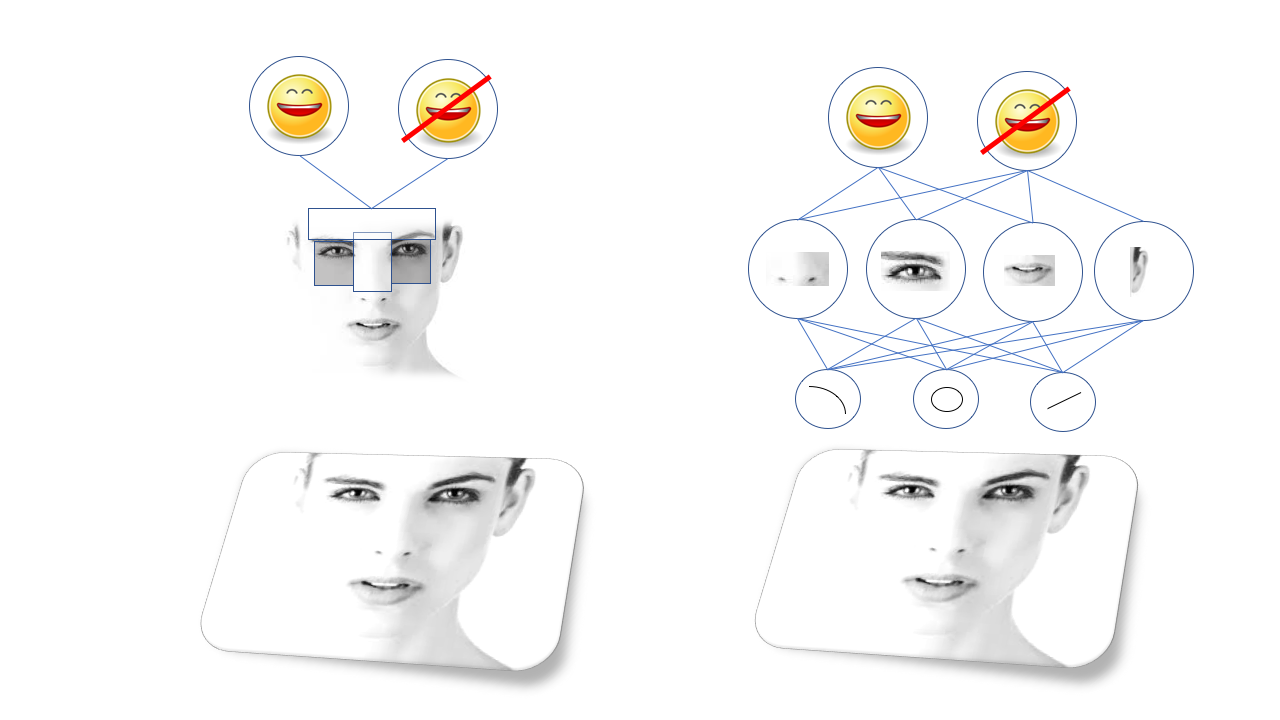
Old visual algorithms (Viola-Jones method, on the left) rely on manually selected features, and deep neural networks (on the right) on their own hierarchy of more complex features made up of simpler
SNAs were amazingly good for computer vision, and soon the researchers were able to train them to perform all sorts of tasks for visual recognition, from finding cats in the photo to identifying pedestrians caught in the camera of a robomobile.
This is all wonderful, but there is another reason for such a fast and widespread spread of the SNA - this is how easily they adapt. Remember climbing a hill? If our high school student wants to recognize a specific bird, he can take any of the many visual networks with open source code and train it on his own data set, without even understanding how the mathematics underlying it work.
Naturally, this can be expanded even further.
Who's there? (face recognition)
Suppose you want to train a network that recognizes not just faces, but one specific face. You could train the network to recognize a specific person, then another person, and so on. However, it takes time to train networks, and that would mean that for every new person, it would be necessary to retrain the network. No, really.
Instead, we can start with a network trained to recognize faces in general. Her neurons are configured to recognize all facial structures: eyes, ears, mouths, and so on. Then you just change the output: instead of forcing her to recognize certain faces, you command her to give out a face description in the form of hundreds of numbers describing the curvature of the nose or the shape of the eyes, and so on. The network can do this because it already “knows” what components the face consists of.
Of course, you do not define all this directly. Instead, you train the network by showing it a set of faces, and then comparing the output. You also teach her so that she gives descriptions similar to each other of the same person, and very different from each other descriptions of different persons. Mathematically speaking, you train a network to build a correspondence to the images of faces of a point in a space of features, where the Cartesian distance between points can be used to determine their similarity.

Changing the neural network from face recognition (on the left) to the description of faces (on the right) requires only changing the format of the output data, without changing its basis.

Now you can recognize faces by comparing the descriptions of each of the faces created by the neural network
Having trained the network, you can easily recognize faces. You take the original person and get his description. Then take a new face and compare the description provided by the network with your original. If they are close enough, you say that it is one and the same person. And now you have moved from a network capable of recognizing one face to what can be used to recognize any face!
This structural flexibility is another reason for the usefulness of deep neural networks. A huge number of various MO models for computer vision have already been developed, and although they are developing in very different directions, the basic structure of many of them is based on such early SNAs as Alexnet and Resnet.
I even heard stories about people using visual neural networks to work with time series data or sensor measurements. Instead of creating a special network for analyzing data flow, they trained an open-source neural network designed for computer vision to literally look at the shapes of line graphs.
Such flexibility is a good thing, but not infinite. To solve some other problems, you need to use other types of networks.

And even to this point, virtual assistants took a very long time
What you said? (Speech recognition)
Image cataloging and computer vision are not the only areas of AI resurgence. Another area in which computers have come very far is speech recognition, especially in translating speech to writing.
The basic idea in speech recognition is quite similar to the principle of computer vision: to recognize complex things in the form of sets of simpler ones. In the case of speech, the recognition of sentences and phrases is based on the recognition of words, which is based on the recognition of syllables, or, to be more precise, phonemes. So when someone says “Bond, James Bond,” we actually hear BON + DUH + JAY + MMS + BON + DUH.
In vision, features are spatially organized, and the SNA processes this structure. In rumor, these features are organized in time. People can speak quickly or slowly, without a clear beginning and end of speech. We need a model that is able to perceive sounds as it arrives, as a person, instead of waiting and looking for complete sentences in them. We cannot, as in physics, say that space and time are one and the same.
Recognizing individual syllables is fairly easy, but they are difficult to isolate. For example, “Hello there” may sound like “hell no they're” ... So for any sequence of sounds there are usually several combinations of syllables actually spoken.
To understand all this, we need the opportunity to study the sequence in a certain context. If I hear a sound, it’s more likely that the person said “hello there dear” or “hell no they're deer?” Machine learning comes to the rescue here again. With a sufficiently large set of patterns of spoken words, you can learn the most likely phrases. And the more examples you have, the better it will turn out.
For this, people use recurrent neural networks, RNS. In most types of neural networks, such as the SNA involved in computer vision, connections between neurons work in one direction, from input to output (mathematically speaking, these are directed acyclic graphs). In RNS, the output of neurons can be redirected back to neurons of the same level, to themselves or even further. This allows the RNS to have its own memory (if you are familiar with binary logic, then this situation is similar to the operation of triggers).
SNA works for one approach: we feed her an image, and she gives out some description. The RNS maintains the internal memory of what was given to her earlier, and gives answers based on what she has already seen, plus what she sees now.
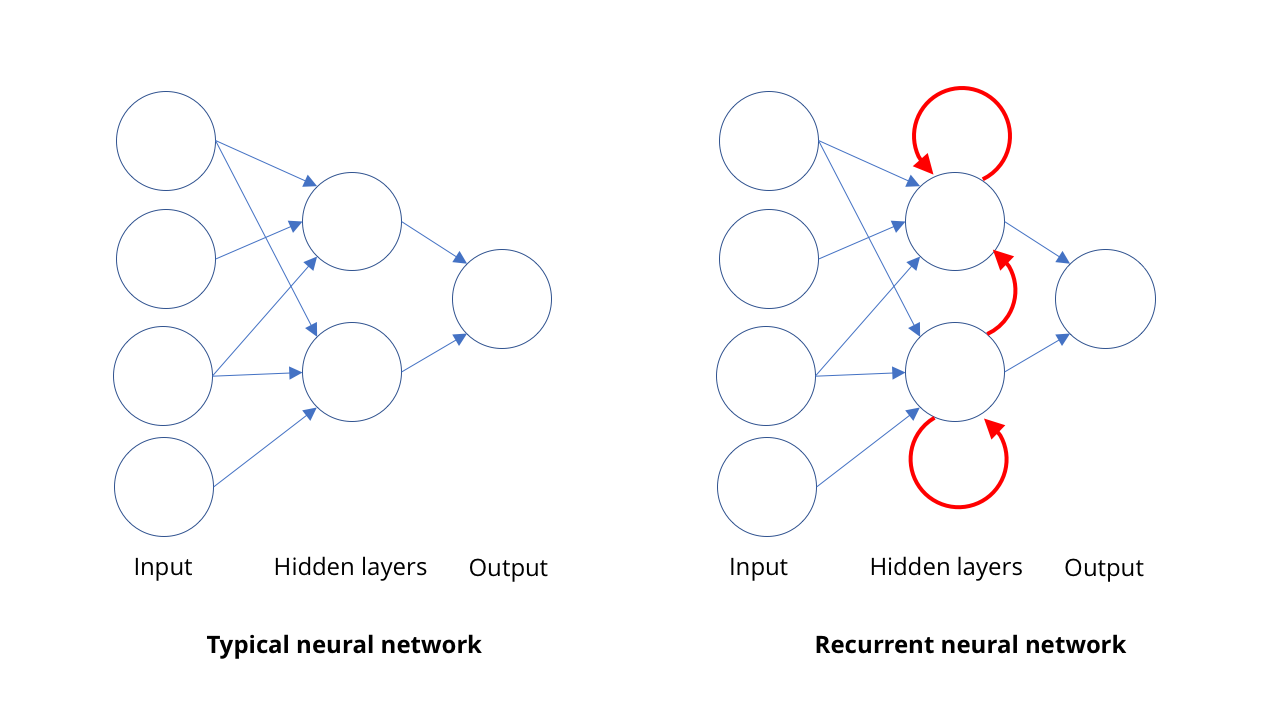
This property of memory in the RNS allows them not only to “listen” to the syllables that come to it one by one. This allows the network to learn which syllables go together to form a word, and how likely certain sequences are.
Using RNS, it is possible to obtain very good transcription of human speech - to such an extent that computers can now outperform humans in some measurements of transcription accuracy. Of course, sounds are not the only area where sequences appear. Today, RNS is also used to determine sequences of movements for recognizing actions on video.
Show me how you can move (deep fakes and generative networks)
So far, we have been talking about MO models designed for recognition: tell me what is shown in the picture, tell me what the person said. But these models are capable of more - today's GO models can also be used to create content.
This is when people talk about deepfake - incredibly realistic fake videos and images created using GO. Some time ago, an employee of German television provoked an extensive political discussion by creating a fake video in which the Greek finance minister showed Germany the middle finger. To create this video, we needed a team of editors who worked to create a TV show, but in the modern world, it can be done in a few minutes by anyone with access to a medium-sized gaming computer.
All this is rather sad, but not so gloomy in this area - my favorite video on the topic of this technology is shown at the top.
This team created a model capable of processing a video with the dancing movements of one person and creating a video with another person repeating these movements, magically performing them at the expert level. It is also interesting to read the accompanying scientific work .
One can imagine that, using all the techniques discussed by us, it is possible to train a network that receives the image of a dancer and tells where his arms and legs are. And in this case, obviously, at some level, the network learned how to connect the pixels in the image with the location of the human limbs. Given that a neural network is just data stored on a computer, not a biological brain, it should be possible to take this data and go in the opposite direction - to get pixels corresponding to the location of the limbs.
Start with a network that extracts poses from images of people.
MO models that can do this are called generative models. generate - generate, produce, create / approx. transl.]. All the previous models we have considered are called discriminatory [eng. discriminate - to distinguish / approx. transl.]. The difference between them can be imagined as follows: a discriminatory model for cats looks at photos and distinguishes between photos containing cats and photos where they are not. The generative model creates images of cats based on, say, a description of what a cat should be like.

Generative models that “draw” images of objects are created using the same SNA structures as the models used to recognize these objects. And these models can be trained in much the same way as other MO models.
However, the trick is to come up with an “assessment” for their training. When training a discriminatory model, there is a simple way to evaluate the correctness and incorrectness of the answer - such as whether the network correctly distinguished the dog from the cat. However, how to evaluate the quality of the resulting cat picture, or its accuracy?
And here for a person who loves conspiracy theories and believes that we are all doomed, the situation becomes a little scary. You see, the best way we invented for learning generative networks is not to do it yourself. For this, we simply use a different neural network.
This technology is called a generative adversarial network, or GSS. You force two neural networks to compete with each other: one network is trying to create fakes, for example, by drawing a new dancer based on the old postures. Another network is trained to find the difference between real and fake examples using a bunch of real dancer examples.
And these two networks play a competitive game. Hence the word "adversarial" in the title. The generative network tries to make convincing fakes, and the discriminatory network tries to understand where the fake is and where the real thing is.
In the case of a video with a dancer, a separate discriminatory network was created during the training process, giving simple yes / no answers. She looked at the image of the person and the description of the position of his limbs, and decided whether the image was a real photograph or a picture drawn by a generative model.

GSS force two networks to compete with each other: one produces fakes, and the other tries to distinguish fake from the original.
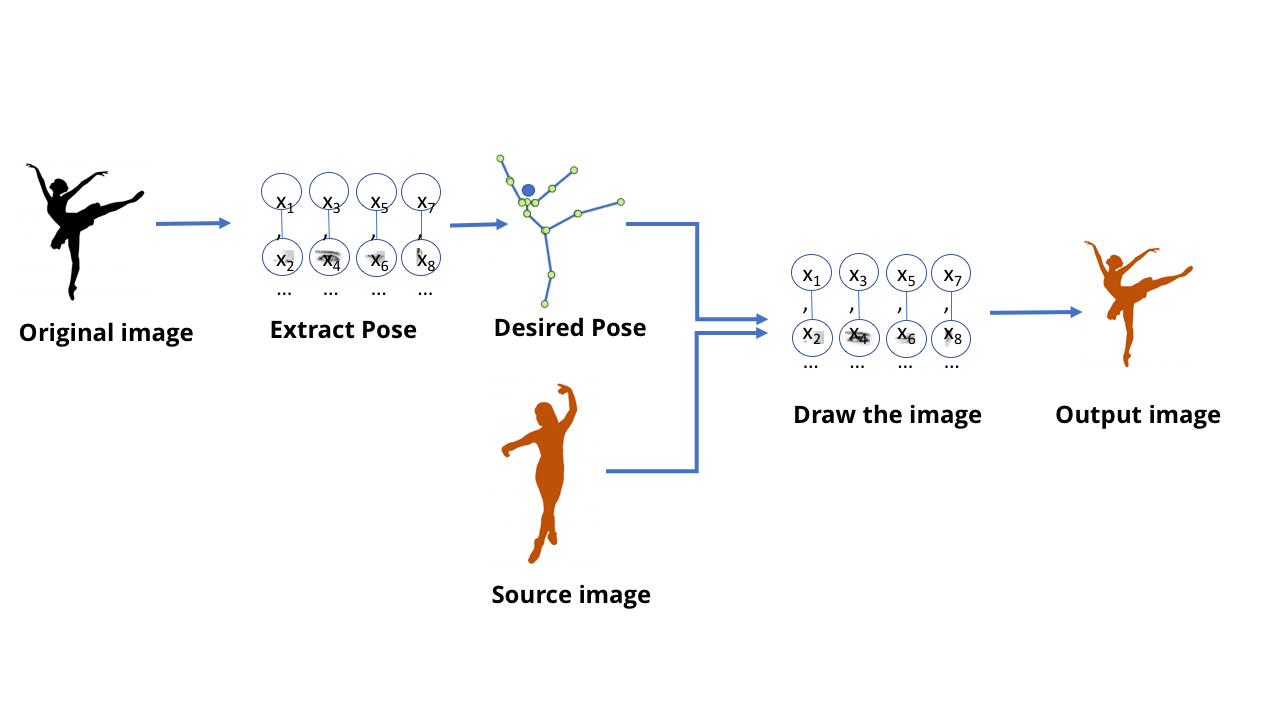
In the final workflow, only a generative model is used that creates the necessary images
During the repeated rounds of training, the models got better and better. This is similar to a competition between a jewelry expert and an expert in valuation - competing with a strong opponent, each of them becomes stronger and smarter. Finally, when the models work well enough, you can take a generative model and use it separately.
Post-training generative models can be very useful for creating content. For example, they can generate images of faces (which can be used to train face recognition programs), or backgrounds for video games.
For all this to work correctly, a lot of work on adjustments and corrections is required, but in essence the person here acts as an arbiter. It is AI that works against each other, making major improvements.
So, should we expect the appearance of Skynet and Hal 9000 in the near future?
In every documentary about nature at the end there is an episode where the authors talk about how all this grandiose beauty will soon disappear due to how terrible people are. I think that in the same spirit, each responsible discussion regarding AI should include a section on its limitations and social consequences.
First, let's emphasize once again the current limitations of AI: the main idea that I hope you have learned from reading this article is that the success of the MO or AI is extremely dependent on the training models we have chosen. If people do not organize the network well or use unsuitable materials for training, then these distortions can be very obvious to everyone.
Deep neural networks are incredibly flexible and powerful, but do not have magical properties. Despite the fact that you use deep neural networks for RNS and SNA, their structure is very different, and therefore, people should determine it anyway. So even if you can take the SNA for cars and retrain it for bird recognition, you cannot take this model and retrain it for speech recognition.
If we describe it in human terms, then it looks as if we understood how the visual cortex and the auditory cortex work, but we have no idea how the cerebral cortex works, and where we can begin to approach it.
This means that in the near future, we probably will not see the Hollywood god-like AI. But this does not mean that in its current form, AI cannot have a serious impact on society.
We often imagine how AI “replaces” us, that is, how robots literally do our work, but in reality this will not happen. Take a look at radiology, for example: sometimes people, looking at the success of computer vision, say that AI will replace radiologists. Perhaps we will not reach the point where we will not have a single human radiologist at all. But a future is quite possible in which, for a hundred of today's radiologists, AI will allow five to ten of them to do the work of everyone else. If such a scenario is realized, where will the remaining 90 doctors go?
Even if the modern generation of AI does not live up to the hopes of its most optimistic supporters, it will still lead to very extensive consequences. And we will have to solve these problems, so a good start will probably be to master the basics of this area.