CI evolution in the mobile development team
Today, most software products are developed in teams. Success conditions for team development can be presented in the form of a simple scheme.
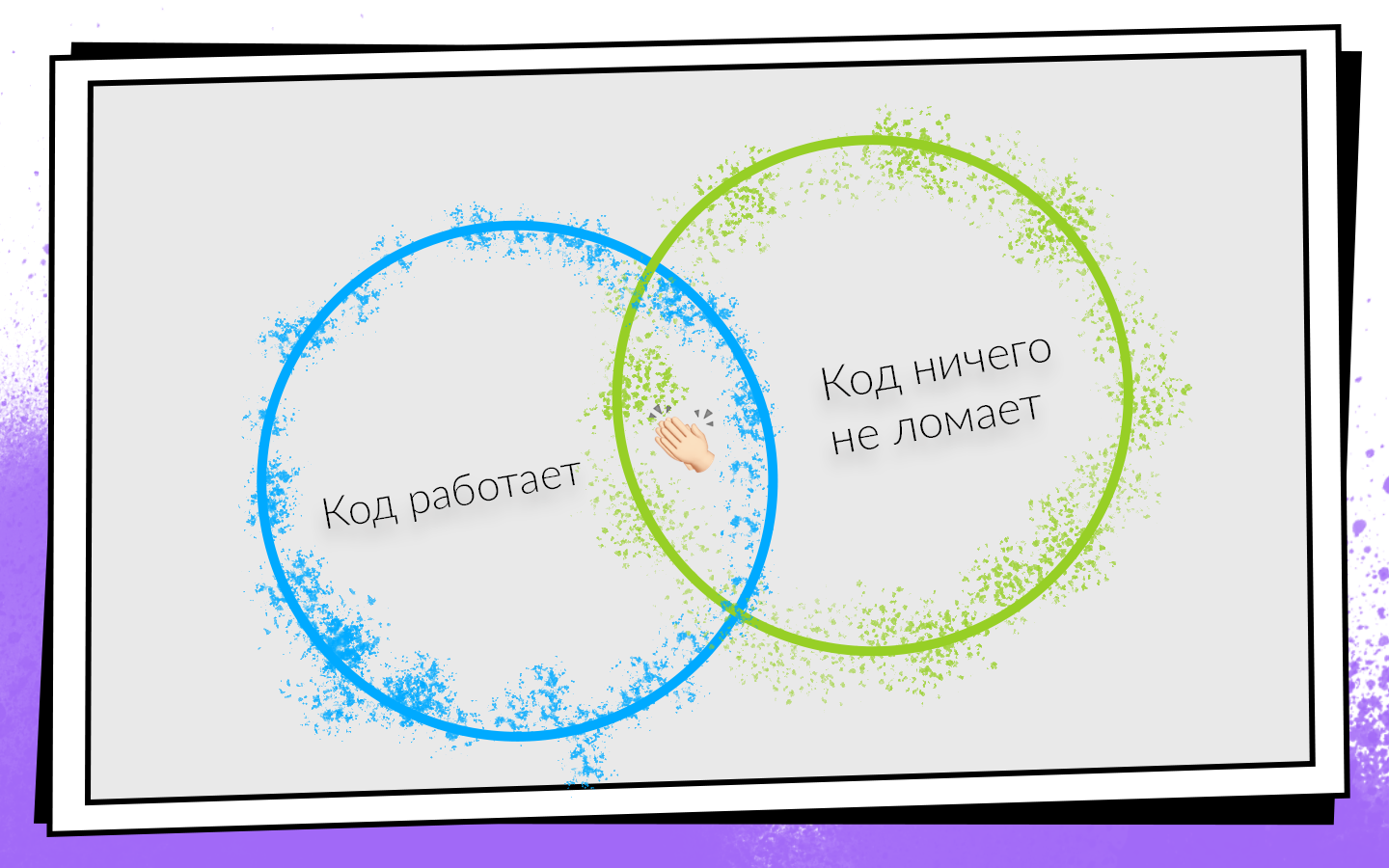
After writing the code, you must make sure that it:
If both conditions are met, then you are on the path to success. In order to easily check these conditions and not turn off a profitable path, they came up with Continuous Integration.
CI is a workflow in which you integrate your code into the general product code as often as possible. And not just integrate, but also constantly check that everything works. Since you need to check a lot and often, you should think about automation. You can check everything on manual traction, but not worth it, and that's why.
How Continuous Integration was introduced and developed in the Avito mobile development team, how they reached 0 to 450 assemblies per day, and that build machines collect 200 hours a day, says Nikolai Nesterov ( nnesterov ) - participant in all evolutionary changes of the CI / CD Android application .
The story is built on the example of the Android team, but most approaches apply on iOS as well.
Once upon a time, one person worked in the Avito Android team. By definition, he did not need anything from Continuous Integration: there was no one to integrate with.
But the application grew, more and more new tasks appeared, respectively, the team grew. At some point, it was time to more formally establish the process of integrating code. It was decided to use Git flow.

The concept of Git flow is known: there is one common develop branch in the project, and for each new feature, developers cut a separate branch, commit it, push it, and when they want to inject their code into the develop branch, open pull request. To share knowledge and discuss approaches, we introduced a code review, that is, colleagues must check and confirm each other's code.
Watching the code with your eyes is cool, but not enough. Therefore, automatic checks are introduced.
To understand how these checks should be run, let's look at the development process in Avito.
Schematically, it can be represented as follows:
Nobody liked running tests on their laptop. When the developer has finished the feature, he wants to quickly launch it and open the pull request. If at that moment some long checks are launched, this is not only not very pleasant, but also slows down the development: while the laptop is checking something, it is impossible to work normally on it.
We really liked to run checks at night, because there are a lot of time and servers, you can take a walk. But, unfortunately, when the feature code got into develop, the developer already has much less motivation to repair the errors that CI found. I periodically caught myself thinking when I looked in the morning report on all the errors found that I would fix them sometime later, because now in Jira lies a cool new task that I just want to start doing.
If the checks block the pull request, then motivation is enough, because until the builds turn green, the code does not get into develop, which means that the task will not be completed.
As a result, we chose this strategy: at night we drive the maximum possible set of checks, and the most critical of them and, most importantly fast, run on a pull request. But we do not stop there - in parallel, we optimize the speed of passing checks so that they switch from night mode to checks on pull request.
At that time, all of our builds were fast enough, so we just included the ARC assembly, Junit tests and code coverage calculation with the pull request blocker. They turned it on, thought it over, and abandoned code coverage because they thought we didn't need it.
It took us two days to complete the basic CI setup (hereinafter, a temporary estimate is approximate, needed for scale).
After that, they began to think further - are we checking it correctly? Do we run builds on pull request correctly?
We started the build on the last commit of the branch with which pull request is open. But checks of this commit can only show that the code that the developer wrote works. But they do not prove that he did not break anything. In fact, you need to check the status of the develop branch after the feature has been poured into it.
To do this, we wrote a simple bash script premerge.sh:
Here, all the latest changes from develop are simply pulled up and merged into the current branch. We added the premerge.sh script as the first step of all builds and began to check exactly what we want, that is, integration .
It took three days to localize the problem, find a solution, and write this script.
The application developed, more and more tasks appeared, the team grew, and premerge.sh sometimes started to let us down. In develop penetrated conflicting changes that broke the assembly.
An example of how this happens:

Two developers simultaneously start sawing features A and B. The developer of feature A discovers an unused function in the project
Developers finish work and at the same time open pull request. Builds start, premerge.sh checks both pull request for a fresh develop state - all checks are green. After that pull request features A is merged, pull request features B is merged ... Boom! Develop breaks because in develop code there is a call to a nonexistent function.
When not going to develop, this is a local disaster . The whole team can not collect and give anything for testing.
It so happened that I was most often involved in infrastructure tasks: analytics, network, databases. That is, I wrote the functions and classes that other developers use. Because of this, I very often got into such situations. I even had such a picture at one time.

Since this did not suit us, we began to work out options on how to prevent this.
First option: rebuild all pull request when upgrade develop. If in our example the pull request with feature A first gets into develop, the pull request of feature B will be rebuilt, and, accordingly, the checks will fail because of a compilation error.
To understand how long it will take, consider an example with two PRs. We open two PRs: two builds, two test launches. After the first PR is poured into develop, the second must be rebuilt. In total, two PR launches of three checks start: 2 + 1 = 3.
In principle, it’s normal. But we looked at the statistics, and a typical situation in our team was 10 open PRs, and then the number of checks is the sum of the progression: 10 + 9 + ... + 1 = 55. That is, in order to accept 10 PRs, you need to rebuild 55 times. And this is in an ideal situation, when all checks pass the first time, when no one opens an additional pull request, while this ten is being processed.
Imagine yourself a developer who needs to have time to press the “merge” button first, because if this is done by a neighbor, you will have to wait until all the assemblies go through again ... No, that won’t work, it will seriously slow down the development.
The second possible way: to collect pull request after code review.That is, open the pull request, collect the necessary number of updates from colleagues, fix what you need, then run the builds. If they are successful, pull request merges with develop. In this case, there are no additional restarts, but the feedback slows down a lot. As a developer, when I open a pull request, I immediately want to see if he is going to. For example, if a test crashes, you need to fix it quickly. In the case of a delayed build, feedback slows down, which means the whole development. This did not suit us either.
As a result, only the third option remained - to cycle . All our code, all our sources are stored in the repository in the Bitbucket server. Accordingly, we had to develop a plugin for Bitbucket.

This plugin overrides the pull request merge mechanism. The beginning is standard: PR opens, all assemblies start, code review passes. But after the code review is passed, and the developer decides to click on “merge”, the plugin checks to see what state the develop checks were run against. If develop has managed to update after builds, the plugin will not allow you to merge such a pull request into the main branch. It will simply restart the builds relative to the fresh develop.

In our example with conflicting changes, such builds will fail because of a compilation error. Accordingly, the developer of feature B will have to correct the code, restart the checks, then the plugin will automatically apply the pull request.
Prior to implementing this plugin, we had an average of 2.7 test runs per pull request. With the plugin there were 3.6 launches. It suited us.
It is worth noting that this plugin has a drawback: it restarts the build only once. That is, all the same, a small window remains through which conflicting changes can get into develop. But the probability of this is not high, and we made this compromise between the number of starts and the probability of failure. For two years, it shot only once, therefore, probably not in vain.
It took us two weeks to write the first version of the plugin for Bitbucket.
Meanwhile, our team continued to grow. New checks were added.
We thought: why repair mistakes if they can be prevented? And so they introduced static code analysis . We started with lint, which is included in the Android SDK. But at that time he did not know how to work with Kotlin code at all, and we already have 75% of the application written in Kotlin. Therefore, built-in Android Studio checks were added to lint .
To do this, I had to be very perverted: take Android Studio, pack it in Docker and run it on CI with a virtual monitor so that it thought that it was running on a real laptop. But it worked.
Also at this time, we began to write a lot of instrumentation tests and implemented screenshot testing. This is when a reference screenshot is generated for a separate small view, and the test is that a screenshot is taken from the view and compared directly with the reference pixel by pixel. If there is a discrepancy, it means that a layout has gone somewhere or something is wrong in the styles.
But instrumentation tests and screenshot tests need to be run on devices: on emulators or on real devices. Given that there are many tests and they often chase, you need a whole farm. To start your own farm is too laborious, so we found a ready-made option - Firebase Test Lab.
It was chosen because Firebase is a Google product, that is, it must be reliable and is unlikely to ever die. The prices are affordable: $ 5 per hour of operation of a real device, $ 1 per hour of operation of the emulator.
It took about three weeks to implement the Firebase Test Lab in our CI.
But the team continued to grow, and Firebase, unfortunately, began to let us down. At that time, he had no SLA. Sometimes Firebase made us wait until the required number of devices for tests became free, and did not start to execute them right away, as we wanted it to. Waiting in line took up to half an hour, and this is a very long time. Instrumentation tests ran at every PR, delays slowed development very much, and then a monthly bill came with a round sum. In general, it was decided to abandon Firebase and saw in-house, since the team has grown enough.
They took docker, stuffed emulators into it, wrote a simple Python program that at the right time raises the right number of emulators in the right version and stops them when necessary. And, of course, a couple of bash scripts - where without them?
It took five weeks to create our own test environment.
As a result, for each pull request, there was an extensive, blocking merge list of checks:
This prevented many possible breakdowns. Technically, everything worked, but the developers complained that the wait for the results was too long.
Too long is how much? We uploaded data from Bitbucket and TeamCity to the analysis system and realized that the average wait time is 45 minutes . That is, a developer, opening a pull request, on average expects build results of 45 minutes. In my opinion, this is a lot, and you can’t work like that.
Of course, we decided to speed up all our builds.
Seeing that often builds are in line, the first thing we bought was iron - extensive development is the simplest. Builds stopped standing in line, but the waiting time decreased only a little, because some checks by themselves were chasing for a very long time.
Our Continuous Integration could catch these types of errors and problems.
Looking at this list, we realized that only the first two points are critical. We want to catch such problems first of all. Bugs in the layout are detected at the design-review stage and then easily fixed. Working with technical debt requires a separate process and planning, so we decided not to check it for pull request.
Based on this classification, we shook up the entire list of checks. Crossed out Lint and postponed its launch for the night: just so that it gives out a report of how many problems are in the project. We agreed to work separately with the technical debt, but completely refused Android Studio checks. Docker’s Android Studio for launching inspections sounds interesting, but it brings a lot of trouble in support. Any update to Android Studio versions is a fight against obscure bugs. It was also difficult to maintain screenshot tests, because the library did not work very stably, there were false positives. Screenshot tests were removed from the list of checks .
As a result, we have left:
Without heavy checks, things got better. But there is no limit to perfection!
Our application has already been broken into approximately 150 gradle modules. Usually, in this case, the Gradle remote cache works well, and we decided to try it.
Gradle remote cache is a service that can cache build artifacts for individual tasks in separate modules. Gradle, instead of actually compiling the code, knocks over the remote cache via HTTP and asks if someone has already performed this task. If so, just download the result.
Starting Gradle remote cache is easy because Gradle provides a Docker image. We managed to do this in three hours.
All that was needed was to launch Docker and register one line in the project. But although you can start it quickly so that everything works well, it will take a lot of time.
Below is a graph of cache misses.

At the very beginning, the percentage of misses past the cache was about 65. Three weeks later, we managed to bring this value to 20%. It turned out that the tasks that the Android application collects have strange transitive dependencies, due to which Gradle missed the cache.
By connecting the cache, we greatly accelerated the assembly. But apart from the assembly, instrumentation tests are still chasing, and they are chasing for a long time. Perhaps not all tests need to be chased for every pull request. To find out, we use impact analysis.
On pull request, we build git diff and find the modified Gradle modules.

It makes sense to run only those instrumentation tests that test modified modules and all modules that depend on them. There is no point in running tests for neighboring modules: the code has not changed there, and nothing can break.
Instrumentation tests are not so simple, because they must be located in the top-level Application module. We applied a bytecode analysis heuristic to understand which module each test belongs to.
It took about eight weeks to upgrade instrumentation tests to test only the modules involved.
Verification acceleration measures have worked successfully. From 45 minutes we reached approximately 15. A quarter of an hour to wait for the build is already normal.
But now the developers have begun to complain that it is not clear to them which builds are being launched, where the log will look, why the build is red, which test fell, etc.
Feedback problems slow down development, so we tried to provide the most understandable and detailed information about each PR and build. We started with comments on Bitbucket for PR, indicating which build fell and why, wrote targeted messages in Slack. In the end, they made a dashboard for the PR page with a list of all the builds that are currently running and their status: in line, starts, crashes or ends. You can click on the build and get to its log.
Six weeks were spent on detailed feedback.
We pass to the latest history. Having solved the question of feedback, we reached a new level - we decided to build our own farm of emulators. When there are many tests and emulators, they are difficult to manage. As a result, all of our emulators moved to a k8s cluster with flexible resource management.
In addition, there are other plans.
So, we traced the history of the development of Continuous Integration in Avito. Now I want to give some advice from the point of view of the experienced.
If I could give only one piece of advice, this would be this:
Bash is a very flexible and powerful tool, it is very convenient and fast to write scripts on it. But you can fall into a trap with him, and we, unfortunately, fell into it.
It all started with simple scripts that ran on our build machines:
But, as you know, everything develops and gets complicated over time - let's run one script from another, let's pass some parameters there - in the end I had to write a function that determines what level of bash nesting we are at now to substitute the necessary quotes, so that it all starts.

You can imagine the labor involved in developing such scripts. I advise you not to fall into this trap.
What can be replaced?
We decided to choose the second option, and now we are systematically deleting all bash scripts and writing a lot of custom gradle shuffles.
Tip # 2: keep your infrastructure in code.
It is convenient when the Continuous Integration configuration is not stored in the Jenkins or TeamCity UI-interface, etc., but as text files directly in the project repository. This gives versionability. It will not be difficult to roll back or collect code on another branch.
Scripts can be stored in the project. And what to do with the environment?
Tip # 3: Docker can help with the environment.
It will definitely help Android developers, there is no iOS yet, unfortunately.
This is an example of a simple docker file that contains jdk and android-sdk:
Having written this docker-file (I’ll tell you a secret, you can not write it, but pull it ready from GitHub) and collect the image, you get a virtual machine on which you can build the application and run Junit tests.
The two main arguments why this makes sense are scalability and repeatability. Using docker, you can quickly raise a dozen build agents that will have exactly the same environment as the old one. This makes life easier for CI engineers. Pushing android-sdk into docker is quite simple, with emulators a little more complicated: you have to work out a bit (well, or download the finished one again from GitHub).
Tip number 4: do not forget that checks are not done for the sake of checks, but for people.
Quick and, most importantly, clear feedback is very important for developers: what they broke, which test fell, where the build log is.
Tip # 5: Be pragmatic with Continuous Integration.
Understand clearly what types of errors you want to prevent, how much you are willing to spend resources, time, computer time. Checks that are too long can, for example, be rescheduled overnight. And those who catch not very important mistakes should be completely abandoned.
Tip number 6: use ready-made tools.
Now there are many companies that provide cloud CI.

For small teams, this is a good way out. You don’t need to maintain anything, just pay some money, collect your application and even drive instrumentation tests.
Tip # 7: in a large team, in-house solutions are more profitable.
But sooner or later, with the growth of the team will become more profitable in-house solutions. There is one point with these decisions. In economics, there is a law of diminishing returns: in any project, each subsequent improvement is made more difficult, requires more and more investment.
The economy has been describing our whole life, including Continuous Integration. I built a work schedule for each stage of our Continuous Integration development.

It can be seen that any improvement is given more and more difficult. Looking at this graph, you can understand that the development of Continuous Integration must be consistent with the growth of team size. For a two-person team, spending 50 days developing an internal emulator farm is an so-so idea. But at the same time, for a large team not to do Continuous Integration at all is also a bad idea, because of integration problems, fixing communications, etc. it will take even more time.
We started with the fact that automation is needed because people are expensive, they are mistaken and lazy. But people also automate. Therefore, all these same problems apply to automation.
But I have statistics: in 20% of assemblies errors are caught. And this is not because our developers write code poorly. This is because the developers are sure that if they make a mistake, it will not get into develop, it will be caught by automated checks. Accordingly, developers can spend more time writing code and interesting things, rather than locally chasing and checking something.
Get involved in Continuous Integration. But in moderation.
After writing the code, you must make sure that it:
- Works.
- It doesn’t break anything, including the code that your colleagues wrote.
If both conditions are met, then you are on the path to success. In order to easily check these conditions and not turn off a profitable path, they came up with Continuous Integration.
CI is a workflow in which you integrate your code into the general product code as often as possible. And not just integrate, but also constantly check that everything works. Since you need to check a lot and often, you should think about automation. You can check everything on manual traction, but not worth it, and that's why.
- People are expensive . An hour of work of any programmer is more expensive than an hour of work of any server.
- People are wrong . Therefore, situations may arise when they launched tests on the wrong branch or collected the wrong commit for testers.
- People are lazy . Periodically, when I finish a task, I have the thought: “But what is there to check? I wrote two lines - stopudovo, everything works! ”I think some of you also sometimes think of such thoughts. But you need to check always.
How Continuous Integration was introduced and developed in the Avito mobile development team, how they reached 0 to 450 assemblies per day, and that build machines collect 200 hours a day, says Nikolai Nesterov ( nnesterov ) - participant in all evolutionary changes of the CI / CD Android application .
The story is built on the example of the Android team, but most approaches apply on iOS as well.
Once upon a time, one person worked in the Avito Android team. By definition, he did not need anything from Continuous Integration: there was no one to integrate with.
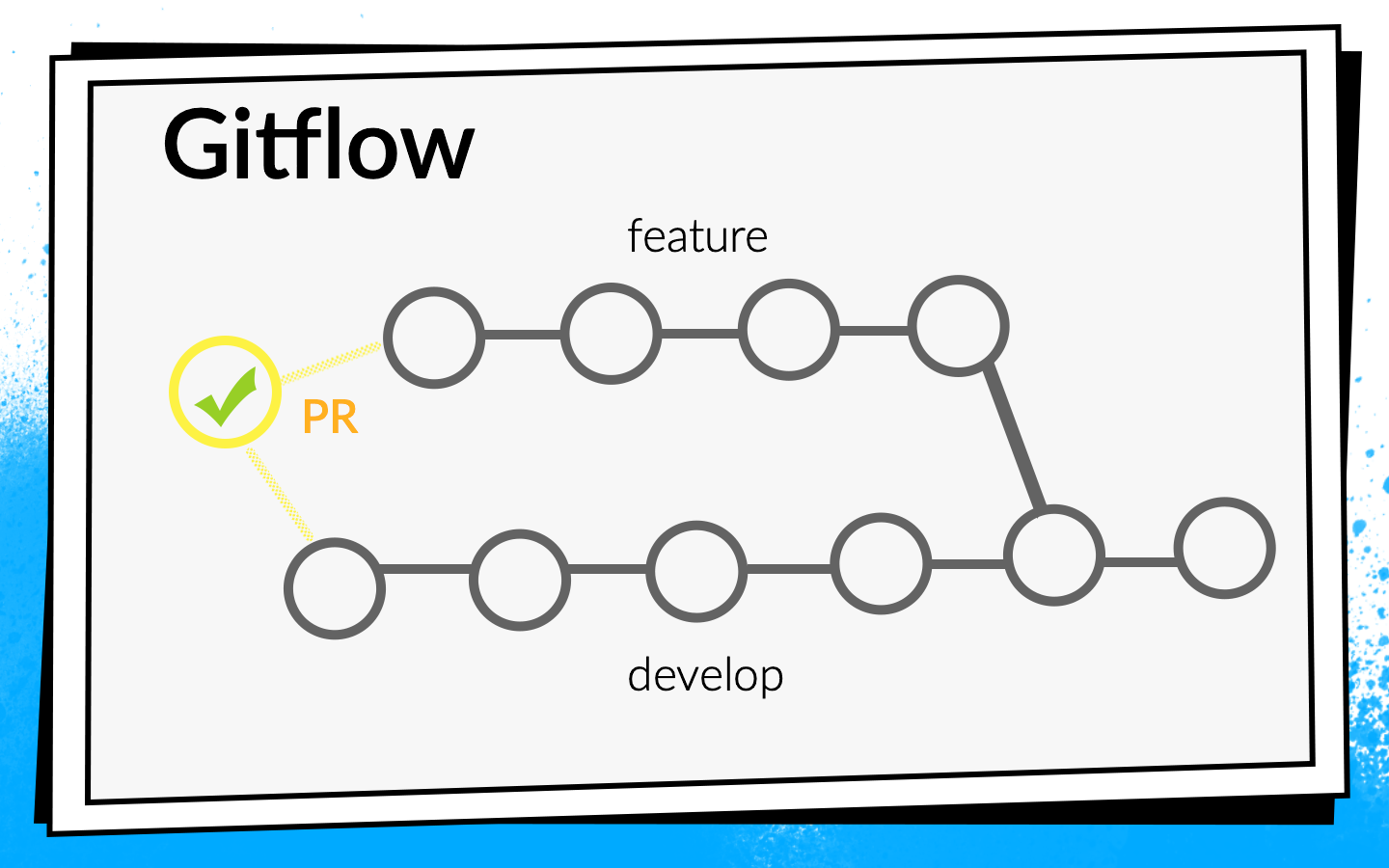
But the application grew, more and more new tasks appeared, respectively, the team grew. At some point, it was time to more formally establish the process of integrating code. It was decided to use Git flow.
The concept of Git flow is known: there is one common develop branch in the project, and for each new feature, developers cut a separate branch, commit it, push it, and when they want to inject their code into the develop branch, open pull request. To share knowledge and discuss approaches, we introduced a code review, that is, colleagues must check and confirm each other's code.
Checks
Watching the code with your eyes is cool, but not enough. Therefore, automatic checks are introduced.
- First of all, we check the assembly of the ARC .
- Lots of Junit tests .
- We consider code coverage , since we run the tests.
To understand how these checks should be run, let's look at the development process in Avito.
Schematically, it can be represented as follows:
- The developer writes the code on his laptop. You can run integration checks right here - either with a commit hook, or just run checks in the background.
- After the developer has run the code, he opens the pull request. In order for his code to get into the develop branch, you must go through a code review and collect the required number of confirmations. You can enable checks and builds here: until all builds are successful, pull request cannot be merged.
- After the pull request is merged and the code is in develop, you can choose a convenient time: for example, at night, when all servers are free, and drive checks as you like.
Nobody liked running tests on their laptop. When the developer has finished the feature, he wants to quickly launch it and open the pull request. If at that moment some long checks are launched, this is not only not very pleasant, but also slows down the development: while the laptop is checking something, it is impossible to work normally on it.
We really liked to run checks at night, because there are a lot of time and servers, you can take a walk. But, unfortunately, when the feature code got into develop, the developer already has much less motivation to repair the errors that CI found. I periodically caught myself thinking when I looked in the morning report on all the errors found that I would fix them sometime later, because now in Jira lies a cool new task that I just want to start doing.
If the checks block the pull request, then motivation is enough, because until the builds turn green, the code does not get into develop, which means that the task will not be completed.
As a result, we chose this strategy: at night we drive the maximum possible set of checks, and the most critical of them and, most importantly fast, run on a pull request. But we do not stop there - in parallel, we optimize the speed of passing checks so that they switch from night mode to checks on pull request.
At that time, all of our builds were fast enough, so we just included the ARC assembly, Junit tests and code coverage calculation with the pull request blocker. They turned it on, thought it over, and abandoned code coverage because they thought we didn't need it.
It took us two days to complete the basic CI setup (hereinafter, a temporary estimate is approximate, needed for scale).
After that, they began to think further - are we checking it correctly? Do we run builds on pull request correctly?
We started the build on the last commit of the branch with which pull request is open. But checks of this commit can only show that the code that the developer wrote works. But they do not prove that he did not break anything. In fact, you need to check the status of the develop branch after the feature has been poured into it.
To do this, we wrote a simple bash script premerge.sh:
#!/usr/bin/env bash
set -e
git fetch origin develop
git merge origin/developHere, all the latest changes from develop are simply pulled up and merged into the current branch. We added the premerge.sh script as the first step of all builds and began to check exactly what we want, that is, integration .
It took three days to localize the problem, find a solution, and write this script.
The application developed, more and more tasks appeared, the team grew, and premerge.sh sometimes started to let us down. In develop penetrated conflicting changes that broke the assembly.
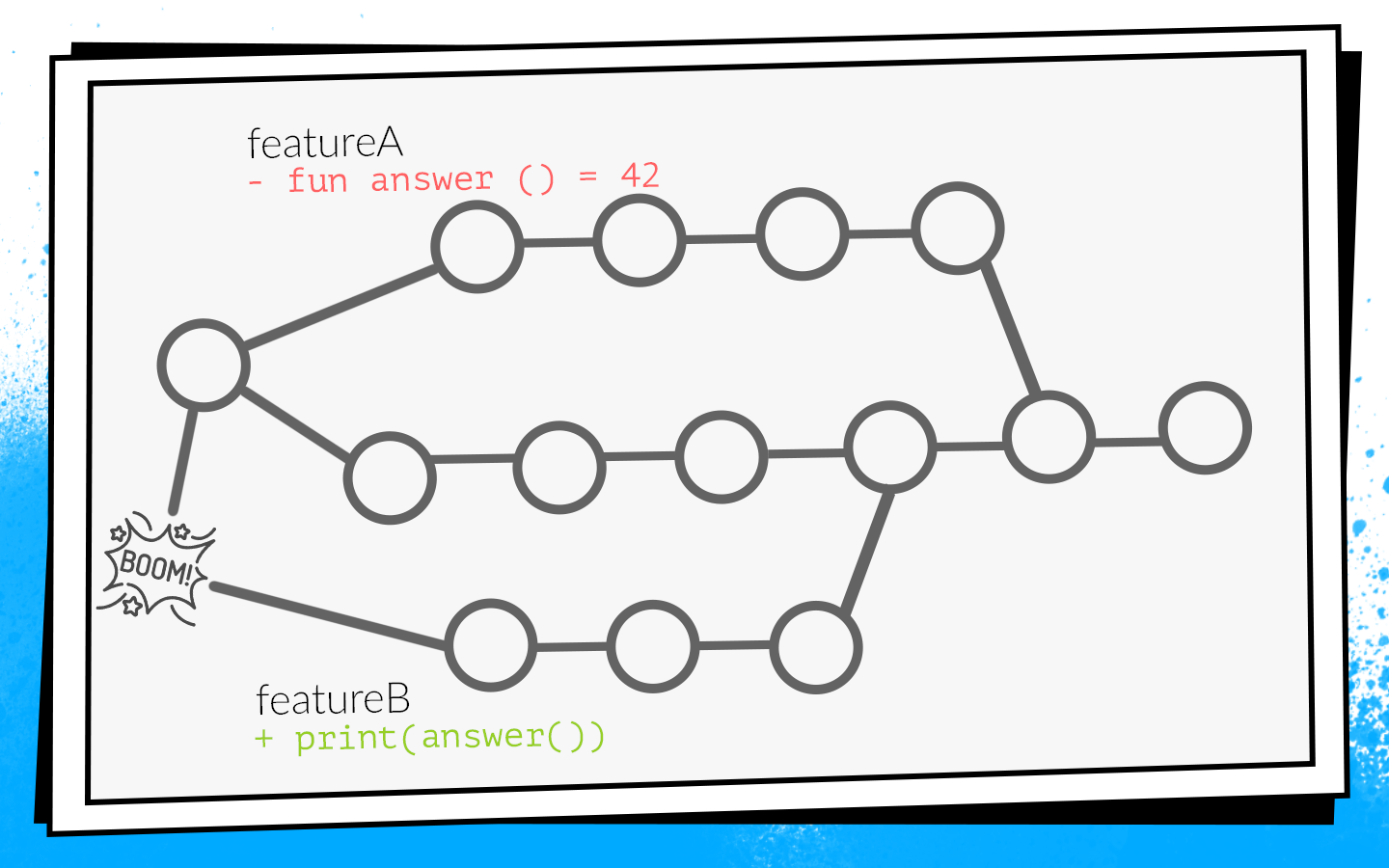
An example of how this happens:
Two developers simultaneously start sawing features A and B. The developer of feature A discovers an unused function in the project
answer()and, like a good scout, removes it. At the same time, the developer of feature B in his branch adds a new call to this function.Developers finish work and at the same time open pull request. Builds start, premerge.sh checks both pull request for a fresh develop state - all checks are green. After that pull request features A is merged, pull request features B is merged ... Boom! Develop breaks because in develop code there is a call to a nonexistent function.
When not going to develop, this is a local disaster . The whole team can not collect and give anything for testing.
It so happened that I was most often involved in infrastructure tasks: analytics, network, databases. That is, I wrote the functions and classes that other developers use. Because of this, I very often got into such situations. I even had such a picture at one time.
Since this did not suit us, we began to work out options on how to prevent this.
How not to break develop
First option: rebuild all pull request when upgrade develop. If in our example the pull request with feature A first gets into develop, the pull request of feature B will be rebuilt, and, accordingly, the checks will fail because of a compilation error.
To understand how long it will take, consider an example with two PRs. We open two PRs: two builds, two test launches. After the first PR is poured into develop, the second must be rebuilt. In total, two PR launches of three checks start: 2 + 1 = 3.
In principle, it’s normal. But we looked at the statistics, and a typical situation in our team was 10 open PRs, and then the number of checks is the sum of the progression: 10 + 9 + ... + 1 = 55. That is, in order to accept 10 PRs, you need to rebuild 55 times. And this is in an ideal situation, when all checks pass the first time, when no one opens an additional pull request, while this ten is being processed.
Imagine yourself a developer who needs to have time to press the “merge” button first, because if this is done by a neighbor, you will have to wait until all the assemblies go through again ... No, that won’t work, it will seriously slow down the development.
The second possible way: to collect pull request after code review.That is, open the pull request, collect the necessary number of updates from colleagues, fix what you need, then run the builds. If they are successful, pull request merges with develop. In this case, there are no additional restarts, but the feedback slows down a lot. As a developer, when I open a pull request, I immediately want to see if he is going to. For example, if a test crashes, you need to fix it quickly. In the case of a delayed build, feedback slows down, which means the whole development. This did not suit us either.
As a result, only the third option remained - to cycle . All our code, all our sources are stored in the repository in the Bitbucket server. Accordingly, we had to develop a plugin for Bitbucket.
This plugin overrides the pull request merge mechanism. The beginning is standard: PR opens, all assemblies start, code review passes. But after the code review is passed, and the developer decides to click on “merge”, the plugin checks to see what state the develop checks were run against. If develop has managed to update after builds, the plugin will not allow you to merge such a pull request into the main branch. It will simply restart the builds relative to the fresh develop.
In our example with conflicting changes, such builds will fail because of a compilation error. Accordingly, the developer of feature B will have to correct the code, restart the checks, then the plugin will automatically apply the pull request.
Prior to implementing this plugin, we had an average of 2.7 test runs per pull request. With the plugin there were 3.6 launches. It suited us.
It is worth noting that this plugin has a drawback: it restarts the build only once. That is, all the same, a small window remains through which conflicting changes can get into develop. But the probability of this is not high, and we made this compromise between the number of starts and the probability of failure. For two years, it shot only once, therefore, probably not in vain.
It took us two weeks to write the first version of the plugin for Bitbucket.
New Checks
Meanwhile, our team continued to grow. New checks were added.
We thought: why repair mistakes if they can be prevented? And so they introduced static code analysis . We started with lint, which is included in the Android SDK. But at that time he did not know how to work with Kotlin code at all, and we already have 75% of the application written in Kotlin. Therefore, built-in Android Studio checks were added to lint .
To do this, I had to be very perverted: take Android Studio, pack it in Docker and run it on CI with a virtual monitor so that it thought that it was running on a real laptop. But it worked.
Also at this time, we began to write a lot of instrumentation tests and implemented screenshot testing. This is when a reference screenshot is generated for a separate small view, and the test is that a screenshot is taken from the view and compared directly with the reference pixel by pixel. If there is a discrepancy, it means that a layout has gone somewhere or something is wrong in the styles.
But instrumentation tests and screenshot tests need to be run on devices: on emulators or on real devices. Given that there are many tests and they often chase, you need a whole farm. To start your own farm is too laborious, so we found a ready-made option - Firebase Test Lab.
Firebase test lab
It was chosen because Firebase is a Google product, that is, it must be reliable and is unlikely to ever die. The prices are affordable: $ 5 per hour of operation of a real device, $ 1 per hour of operation of the emulator.
It took about three weeks to implement the Firebase Test Lab in our CI.
But the team continued to grow, and Firebase, unfortunately, began to let us down. At that time, he had no SLA. Sometimes Firebase made us wait until the required number of devices for tests became free, and did not start to execute them right away, as we wanted it to. Waiting in line took up to half an hour, and this is a very long time. Instrumentation tests ran at every PR, delays slowed development very much, and then a monthly bill came with a round sum. In general, it was decided to abandon Firebase and saw in-house, since the team has grown enough.
Docker + python + bash
They took docker, stuffed emulators into it, wrote a simple Python program that at the right time raises the right number of emulators in the right version and stops them when necessary. And, of course, a couple of bash scripts - where without them?
It took five weeks to create our own test environment.
As a result, for each pull request, there was an extensive, blocking merge list of checks:
- Assembly of the ARC;
- Junit tests
- Lint;
- Android Studio checks;
- Instrumentation tests;
- Screenshot tests.
This prevented many possible breakdowns. Technically, everything worked, but the developers complained that the wait for the results was too long.
Too long is how much? We uploaded data from Bitbucket and TeamCity to the analysis system and realized that the average wait time is 45 minutes . That is, a developer, opening a pull request, on average expects build results of 45 minutes. In my opinion, this is a lot, and you can’t work like that.
Of course, we decided to speed up all our builds.
Speed up
Seeing that often builds are in line, the first thing we bought was iron - extensive development is the simplest. Builds stopped standing in line, but the waiting time decreased only a little, because some checks by themselves were chasing for a very long time.
We remove too long checks
Our Continuous Integration could catch these types of errors and problems.
- Not going to . CI can catch a compilation error when, due to conflicting changes, something is not going to. As I said, then no one can collect anything, the development rises, and everyone gets nervous.
- A bug in behavior . For example, when the application is assembled, but when you click on the button, it crashes, or the button is not pressed at all. This is bad because such a bug can reach the user.
- Bug in layout . For example, a button is pressed, but moved 10 pixels to the left.
- Increase in technical debt .
Looking at this list, we realized that only the first two points are critical. We want to catch such problems first of all. Bugs in the layout are detected at the design-review stage and then easily fixed. Working with technical debt requires a separate process and planning, so we decided not to check it for pull request.
Based on this classification, we shook up the entire list of checks. Crossed out Lint and postponed its launch for the night: just so that it gives out a report of how many problems are in the project. We agreed to work separately with the technical debt, but completely refused Android Studio checks. Docker’s Android Studio for launching inspections sounds interesting, but it brings a lot of trouble in support. Any update to Android Studio versions is a fight against obscure bugs. It was also difficult to maintain screenshot tests, because the library did not work very stably, there were false positives. Screenshot tests were removed from the list of checks .
As a result, we have left:
- Assembly of the ARC;
- Junit tests
- Instrumentation tests.
Gradle remote cache
Without heavy checks, things got better. But there is no limit to perfection!
Our application has already been broken into approximately 150 gradle modules. Usually, in this case, the Gradle remote cache works well, and we decided to try it.
Gradle remote cache is a service that can cache build artifacts for individual tasks in separate modules. Gradle, instead of actually compiling the code, knocks over the remote cache via HTTP and asks if someone has already performed this task. If so, just download the result.
Starting Gradle remote cache is easy because Gradle provides a Docker image. We managed to do this in three hours.
All that was needed was to launch Docker and register one line in the project. But although you can start it quickly so that everything works well, it will take a lot of time.
Below is a graph of cache misses.
At the very beginning, the percentage of misses past the cache was about 65. Three weeks later, we managed to bring this value to 20%. It turned out that the tasks that the Android application collects have strange transitive dependencies, due to which Gradle missed the cache.
By connecting the cache, we greatly accelerated the assembly. But apart from the assembly, instrumentation tests are still chasing, and they are chasing for a long time. Perhaps not all tests need to be chased for every pull request. To find out, we use impact analysis.
Impact analysis
On pull request, we build git diff and find the modified Gradle modules.
It makes sense to run only those instrumentation tests that test modified modules and all modules that depend on them. There is no point in running tests for neighboring modules: the code has not changed there, and nothing can break.
Instrumentation tests are not so simple, because they must be located in the top-level Application module. We applied a bytecode analysis heuristic to understand which module each test belongs to.
It took about eight weeks to upgrade instrumentation tests to test only the modules involved.
Verification acceleration measures have worked successfully. From 45 minutes we reached approximately 15. A quarter of an hour to wait for the build is already normal.
But now the developers have begun to complain that it is not clear to them which builds are being launched, where the log will look, why the build is red, which test fell, etc.
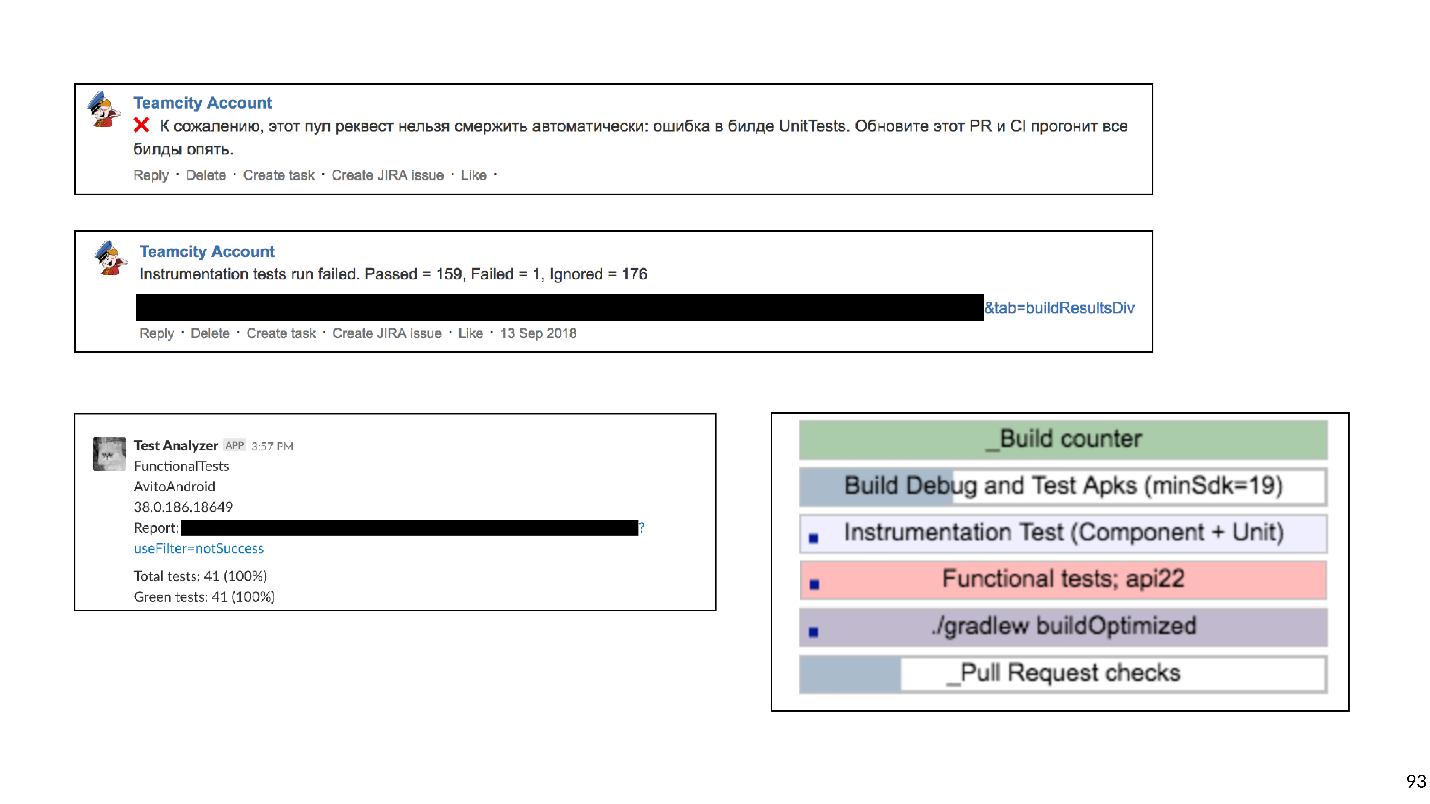
Feedback problems slow down development, so we tried to provide the most understandable and detailed information about each PR and build. We started with comments on Bitbucket for PR, indicating which build fell and why, wrote targeted messages in Slack. In the end, they made a dashboard for the PR page with a list of all the builds that are currently running and their status: in line, starts, crashes or ends. You can click on the build and get to its log.
Six weeks were spent on detailed feedback.
Plans
We pass to the latest history. Having solved the question of feedback, we reached a new level - we decided to build our own farm of emulators. When there are many tests and emulators, they are difficult to manage. As a result, all of our emulators moved to a k8s cluster with flexible resource management.
In addition, there are other plans.
- Return Lint (and other static analysis). We are already working in this direction.
- Run all end-to-end tests on the PR blocker on all versions of the SDK.
So, we traced the history of the development of Continuous Integration in Avito. Now I want to give some advice from the point of view of the experienced.
Advice
If I could give only one piece of advice, this would be this:
Please be careful with shell scripts!
Bash is a very flexible and powerful tool, it is very convenient and fast to write scripts on it. But you can fall into a trap with him, and we, unfortunately, fell into it.
It all started with simple scripts that ran on our build machines:
#!/usr/bin/env bash
./gradlew assembleDebugBut, as you know, everything develops and gets complicated over time - let's run one script from another, let's pass some parameters there - in the end I had to write a function that determines what level of bash nesting we are at now to substitute the necessary quotes, so that it all starts.
You can imagine the labor involved in developing such scripts. I advise you not to fall into this trap.
What can be replaced?
- Any scripting language. Writing in Python or Kotlin Script is more convenient because it is programming, not scripts.
- Or describe all the build logic in the form of Custom gradle tasks for your project.
We decided to choose the second option, and now we are systematically deleting all bash scripts and writing a lot of custom gradle shuffles.
Tip # 2: keep your infrastructure in code.
It is convenient when the Continuous Integration configuration is not stored in the Jenkins or TeamCity UI-interface, etc., but as text files directly in the project repository. This gives versionability. It will not be difficult to roll back or collect code on another branch.
Scripts can be stored in the project. And what to do with the environment?
Tip # 3: Docker can help with the environment.
It will definitely help Android developers, there is no iOS yet, unfortunately.
This is an example of a simple docker file that contains jdk and android-sdk:
FROM openjdk:8
ENV SDK_URL="https://dl.google.com/android/repository/sdk-tools-linux-3859397.zip" \
ANDROID_HOME="/usr/local/android-sdk" \
ANDROID_VERSION=26 \
ANDROID_BUILD_TOOLS_VERSION=26.0.2
# Download Android SDK
RUN mkdir "$ANDROID_HOME" .android \
&& cd "$ANDROID_HOME" \
&& curl -o sdk.zip $SDK_URL \
&& unzip sdk.zip \
&& rm sdk.zip \
&& yes | $ANDROID_HOME/tools/bin/sdkmanager --licenses
# Install Android Build Tool and Libraries
RUN $ANDROID_HOME/tools/bin/sdkmanager --update
RUN $ANDROID_HOME/tools/bin/sdkmanager "build-tools;${ANDROID_BUILD_TOOLS_VERSION}" \
"platforms;android-${ANDROID_VERSION}" \
"platform-tools"
RUN mkdir /application
WORKDIR /application
Having written this docker-file (I’ll tell you a secret, you can not write it, but pull it ready from GitHub) and collect the image, you get a virtual machine on which you can build the application and run Junit tests.
The two main arguments why this makes sense are scalability and repeatability. Using docker, you can quickly raise a dozen build agents that will have exactly the same environment as the old one. This makes life easier for CI engineers. Pushing android-sdk into docker is quite simple, with emulators a little more complicated: you have to work out a bit (well, or download the finished one again from GitHub).
Tip number 4: do not forget that checks are not done for the sake of checks, but for people.
Quick and, most importantly, clear feedback is very important for developers: what they broke, which test fell, where the build log is.
Tip # 5: Be pragmatic with Continuous Integration.
Understand clearly what types of errors you want to prevent, how much you are willing to spend resources, time, computer time. Checks that are too long can, for example, be rescheduled overnight. And those who catch not very important mistakes should be completely abandoned.
Tip number 6: use ready-made tools.
Now there are many companies that provide cloud CI.
For small teams, this is a good way out. You don’t need to maintain anything, just pay some money, collect your application and even drive instrumentation tests.
Tip # 7: in a large team, in-house solutions are more profitable.
But sooner or later, with the growth of the team will become more profitable in-house solutions. There is one point with these decisions. In economics, there is a law of diminishing returns: in any project, each subsequent improvement is made more difficult, requires more and more investment.
The economy has been describing our whole life, including Continuous Integration. I built a work schedule for each stage of our Continuous Integration development.
It can be seen that any improvement is given more and more difficult. Looking at this graph, you can understand that the development of Continuous Integration must be consistent with the growth of team size. For a two-person team, spending 50 days developing an internal emulator farm is an so-so idea. But at the same time, for a large team not to do Continuous Integration at all is also a bad idea, because of integration problems, fixing communications, etc. it will take even more time.
We started with the fact that automation is needed because people are expensive, they are mistaken and lazy. But people also automate. Therefore, all these same problems apply to automation.
- Automate is expensive. Remember the work schedule.
- In automation, people make mistakes.
- Automation is sometimes very lazy, because everything works like that. Why else improve, why all this Continuous Integration?
But I have statistics: in 20% of assemblies errors are caught. And this is not because our developers write code poorly. This is because the developers are sure that if they make a mistake, it will not get into develop, it will be caught by automated checks. Accordingly, developers can spend more time writing code and interesting things, rather than locally chasing and checking something.
Get involved in Continuous Integration. But in moderation.
By the way, Nikolai Nesterov not only makes cool presentations himself, but also enters into the AppsConf program committee and helps others prepare meaningful presentations for you. The completeness and usefulness of the program of the next conference can be estimated by the topics in the schedule . And for details, come April 22-23 to Infospace.