Operating Systems: Three Easy Pieces. Part 3: Process API (translation)
Introduction to Operating Systems
Hello, Habr! I want to bring to your attention a series of translation articles of one interesting literature in my opinion - OSTEP. This article discusses rather deeply the work of unix-like operating systems, namely, work with processes, various schedulers, memory, and other similar components that make up the modern OS. The original of all materials you can see here . Please note that the translation was done unprofessionally (quite freely), but I hope I retained the general meaning.
Laboratory work on this subject can be found here:
Other parts:
- Part 1: Intro
- Part 2: Abstraction: the process
- Part 3: Introduction to the Process API
- Part 4: Introduction to the Scheduler
- Part 5: MLFQ Scheduler
And you can look at my channel in telegram =)
Alarm! There is a lab for this lecture! watch github
Process API
Consider the example of creating a process on a UNIX system. It occurs through two system calls fork () and exec () .
Fork () call

Consider a program that makes a fork () call. The result of its implementation will be as follows.
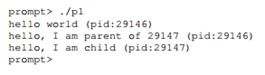
First of all, we enter the main () function and execute the output of the string to the screen. The line contains the identifier of the process which in the original is called PIDor process identifier. This identifier is used on UNIX to refer to a process. The next command will call fork (). At this point, an almost exact copy of the process is created. For the OS, it looks as if the system runs as if 2 copies of the same program, which in turn will exit the fork () function. The newly created child process (relative to the parent process that created it) will no longer be executed, starting with the main () function. It should be remembered that the child process is not an exact copy of the parent process, in particular, it has its own address space, its own registers, its own pointer to executable instructions, and the like. Thus, the value returned to the caller of the fork () function will be different. In particular, the parent process will receive the PID value of the child’s process as a return, and the child will receive a value equal to 0. Based on these return codes, it is already possible to separate processes and force each of them to do their job. Moreover, the execution of this program is not strictly defined. After dividing into 2 processes, the OS begins to follow them, as well, and plan their work. If executed on a single-core processor, one of the processes will continue to work, in this case the parent, and then the child process will receive control. When you restart, the situation may be different. After dividing into 2 processes, the OS begins to follow them, as well, and plan their work. If executed on a single-core processor, one of the processes will continue to work, in this case the parent, and then the child process will receive control. When you restart, the situation may be different. After dividing into 2 processes, the OS begins to follow them, as well, and plan their work. If executed on a single-core processor, one of the processes will continue to work, in this case the parent, and then the child process will receive control. When you restart, the situation may be different.
Call wait ()
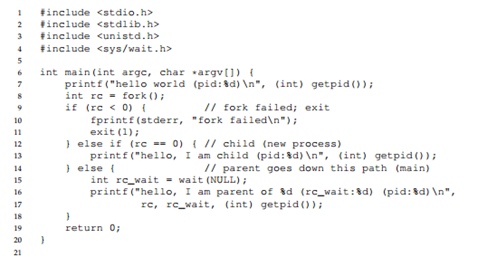
Consider the following program. In this program, due to the presence of the wait () call , the parent process will always wait for the child process to complete its work. In this case, we get a strictly defined text output to the screen.

Call exec ()

Consider the call to exec () . This system call is useful when we want to run a completely different program. Here we will call execvp ()to run the wc program, which is a word counting program. What happens when exec () is called? The name of the executable file and some parameters are passed to this call as arguments. After that, the code and static data from this executable file are downloaded and its own segment with the code is overwritten. The remaining sections of memory, such as the stack and heap, are reinitialized. After which the OS simply executes the program, passing it a set of arguments. Thus, we did not create a new process, we simply transformed the current running program into another running program. After exec () is executed, the descendant gives the impression that the original program seemed to not start in principle.
This complication of launching is absolutely normal for the Unix shell, and allows this shell to execute code after calling fork () , but before calling exec () . An example of such code can be tuning the environment of the shell to the needs of the program being launched, before it is launched directly.
Shell- just a user program. She shows you the prompt line and waits for you to write something to it. In most cases, if you write the name of the program there, the shell will find its location, call the fork () method, and then to create a new process, it will call some of the exec () types and wait for it to be executed using the wait () call. When the child process completes, the shell returns from the wait () call and displays the prompt again and waits for the next command to be entered.
Separating fork () & exec () allows the shell to do the following things, for example:
wc file> new_file.
In this example, the output from wc is redirected to a file. The way that the shell achieves this is quite simple - when creating a child process before calling exec (), the shell closes the standard output stream and opens the new_file file , so all the output from the further running wc program will be redirected to the file instead of the screen.
Unix pipes are implemented in a similar way, with the difference that they use the pipe () call. In this case, the output stream of the process will be connected to the pipe queue located in the kernel to which the input stream of another process will be attached.