Getting rid of duplicate packages in bundles
There are many webpack packages that find duplicates in the bundle, the most popular of them is duplicate-package-checker-webpack-plugin , but it requires reassembling the project, and since there was a task to automate the selection of the optimal version of packages, it turned out its own alternative solution.
Well, or my story is how it turned out to reduce the bundle by 15%, in a few seconds.
As in many large companies that have a huge code base, there is a lot of common logic, as a result we use common components published in our npm repository. They are published through lerna , respectively, before each installation or update of common components, the question arises of which version to install. lerna overrides all components that use the published component (if the version was previously the latest). Accordingly, there are always versions of several components that are better suited to each other, since they do not compete with dependencies.
From open source projects in this way nivo , here is their lerna config .
How do duplicate dependencies appear then? And how to eliminate them?
Suppose you have a simple project with the following package.json:
{
"name": "demo-project",
"version": "1.0.0",
"dependencies": {
"@nivo/bar": "0.54.0",
"@nivo/core": "0.53.0",
"@nivo/pie": "0.54.0",
"@nivo/stream": "0.54.0"
}
}Let's see where it is used @nivo/core:
npm list @nivo/core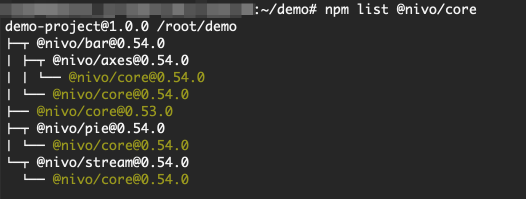
We see 4 copies @nivo/core(3 copies 0.54.0and 1 - 0.53.0). But if we change the minor version @nivo/coreto 0.54.0, duplicates will be eliminated.
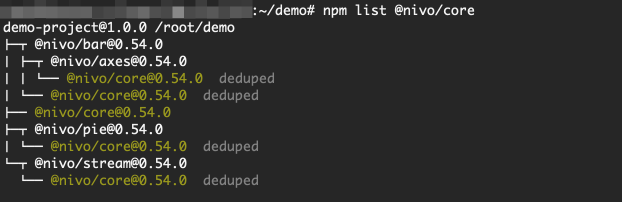
The current example is simple, but in practice, of course, each package has more dependencies, and you still need to consider the dependencies further, which increases the complexity of the task.
And once once again seeing the huge size of the bundle, I was tired of manually removing duplicate packets.
In general, it’s right to immediately upgrade packages to the latest version, but there is no time, as always, to change major versions, and it’s long and difficult to select the appropriate package blindly. After all, you need to update the dependency version in package.json, install new dependencies, and then check if duplicates have disappeared in the build, if not, repeat, for a long time, on average, 3-4 minutes per iteration.
All this is monotonous and requires attention, so I decided to automate.
I would like to know duplicates without reinstalling dependencies, and rebuilding the project, ideally cli application that displays optimization options in 10 seconds and all existing duplicates in the project.
The elimination of takes can be divided into several subtasks, we will consider them in order.
First task. You need to model the future bundle dependency tree only by package.json, given the standard dedupe, quickly, in no more than 100ms.
I decided to use package-json to get information on packages and semver to compare different versions.
The result was an npm package dependencies-tree-builder , smartly modeling the bundle dependency tree only by package.json.
Allocated to a separate component, because maybe someone will reuse it in combinatorial tasks with package.json.
The second task. A combinatorial task, an efficient enumeration of options for changing dependencies, and a comparison of several options for trees, and of course the choice of the optimal one.
It was necessary to somehow compare the resulting trees qualitatively, and we had to borrow the idea of entropy, as a quantitative measure of the disorder, took the sum of duplicate copies (from the example above it is 3).
It would be great to take package weights into account (in KB), but unfortunately I did not find a package that would work quickly with weights, and those that work work for about half a minute per package, for example package-size . Since they work according to the following principle: create a project with a single dependency, establish dependencies, after which the total weight of the folder is measured. As a result, I did not come up with another criterion, as the number of duplicate copies.
To understand which package needs to be changed, the reasons for duplicates, more specifically the source and effect, are considered. Enumeration eliminates duplicate effects as much as possible, and since the effects are eliminated, then duplicates later as well.
As a result , it has turned a small cli application ostap , recommending optimal version to reduce the number of copies doubles in bundles.
It starts just by pointing to package.json of your project.
ostap ./package.json
You can also use it to quickly view all future takes without rebuilding the project by changing only the versions in package.json.
ostap ./package.json -s
As a result, in my project the total weight of bundles decreased by 15%.
The repository has a quick start section.
If you use route-splitting, it might seem that some bundles have increased in weight, but the distribution of components may have changed. That is, instead of copies of dependencies on each page, the only version turned into a common bundle for all pages, so you need to evaluate the total weight of bundles for all pages.
Hope the article was helpful. And someone will save time information. Thanks.
References for convenience again:
- Package modeling the bundle dependency tree by package.json
GitHub ; - Dependency Optimizer for eliminating duplicates in the
GitHub bundle .
If you have interesting ideas, write to issue on github, we’ll discuss it.