Machine vision vs human intuition: algorithms for disrupting the operation of object recognition programs

The logic of the machines is impeccable, they do not make mistakes if their algorithm works correctly and the set parameters correspond to the necessary standards. Ask the car to choose a route from point A to point B, and it will build the most optimal, taking into account the distance, fuel consumption, the presence of gas stations, etc. This is a pure calculation. The car will not say: "Let's go along this road, I feel this route better." Maybe cars are better than us in the speed of calculations, but intuition is still one of our trump cards. Mankind has spent decades creating a machine similar to the human brain. But is there so much in common between them? Today we will consider a study in which scientists, doubting the unmatched machine "vision" on the basis of convolutional neural networks, conducted an experiment to fool an object recognition system using an algorithm, whose task was to create “fake” images. How successful was the sabotage activity of the algorithm, did people cope with recognition better than cars, and what will this study bring to the future of this technology? We will find answers in the report of scientists. Go.
Study basis
Object recognition technologies using convolutional neural networks (SNS) allow the machine, roughly speaking, to distinguish a swan from the number 9 or a cat from a bicycle. This technology is developing quite rapidly and is currently being applied in various fields, the most obvious of which is the production of unmanned vehicles. Many are of the opinion that the SNA of the system of recognition of objects can be considered as a model of human vision. However, this statement is too loud, due to the human factor. The thing is that fooling a car turned out to be easier than fooling a person (at least in matters of object recognition). SNA systems are very vulnerable to the effects of malicious algorithms (hostile, if you want), which will in every way prevent them from correctly performing their task, creating images,
Researchers divide such images into two categories: “fooling” (completely changing the target) and “embarrassing” (partially changing the target). The first ones are meaningless images that are recognized by the system as something familiar. For example, a set of lines can be classified as a “baseball,” and multi-colored digital noise as an “armadillo.” The second category of images (“embarrassing") are images that, under normal conditions, would be classified correctly, but the malicious algorithm slightly distorts them, exaggerating saying, in the eyes of the SNA system. For example, handwritten number 6 will be classified as number 5 due to a small complement of several pixels.
Just imagine what harm such algorithms can do. It is worth swapping the classification of road signs for autonomous transport and accidents will be inevitable.
Below are the “fake” images that fool the SNA system, trained to recognize objects, and how a similar system classified them.

Image No. 1
Explanation of the series:
- and - indirectly encoded "fraudulent" images;
- b - directly encoded "fraudulent" images;
- c - “embarrassing” images, forcing the system to classify one digit as another;
- d - LaVAN attack (localized and visible adversarial / malicious noise) can lead to incorrect classification, even when the “noise” is located only at one point (in the lower right corner).
- e - three-dimensional objects that are incorrectly classified from different angles.
The most curious thing about this is that a person may not succumb to fooling a malicious algorithm and classify images correctly, based on intuition. Previously, as scientists say, no one made a practical comparison of the abilities of a machine and a person in an experiment to counter malicious algorithms of fake images. That is what the researchers decided to do.
For this, several images made by malicious algorithms were prepared. The subjects were told that the machine classified these (front) images as familiar objects, i.e. the machine did not recognize them correctly. The task of the subjects was to determine exactly how the machine classified these images, i.e. what they think the machine saw in the images, is this classification true, etc.
A total of 8 experiments were carried out, in which 5 types of malicious images created without taking into account human vision were used. In other words, they are created by machine for machines. The results of these experiments turned out to be very entertaining, but we will not spoil them and consider everything in order.
Experiment Results
Experiment # 1: Fooling Images with Invalid Tags
In the first experiment, 48 fooled images were used, created by the algorithm to counter the recognition system based on the SNA called AlexNet. This system classified these images as “gear” and “donut” ( 2a ).
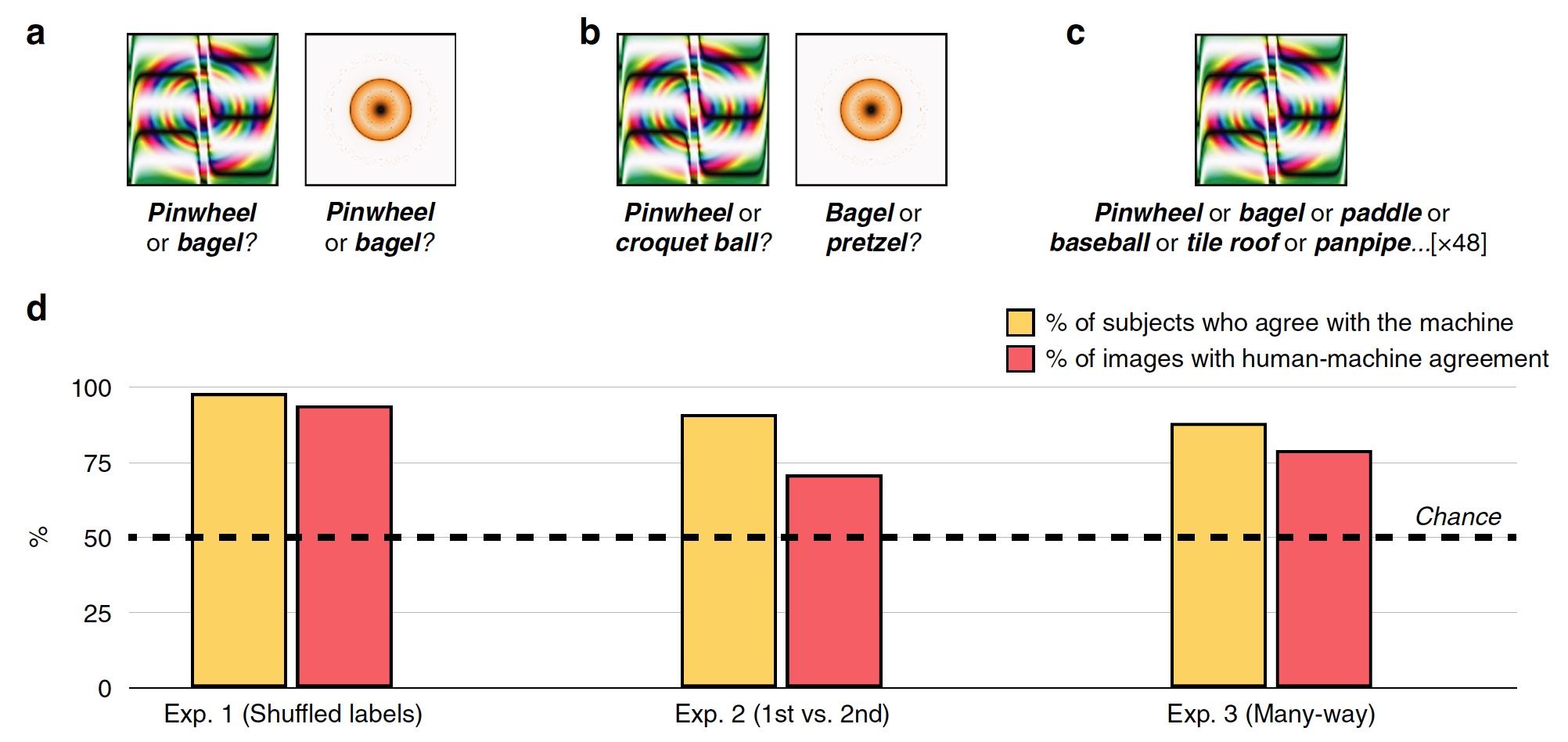
Image No. 2
During each attempt, the test person, of whom there were 200, saw one duping image and two labels, i.e. classification labels: system SNS label and random from the other 47 images. The subjects had to choose the label that was created by the machine.
As a result, most of the subjects chose to choose a label created by the machine, rather than a label of a malicious algorithm. Classification accuracy, i.e. the degree of consent of the subject with the machine was 74%. Statistically, 98% of the subjects chose machine tags at a level higher than statistical randomness ( 2d , “% of subjects agree with the machine”). 94% of the images showed a very high human-machine alignment, that is, out of 48, only 3 images were classified by people differently than a machine.
Thus, the subjects showed that a person is able to share a real image and a fool, that is, act according to a program based on the SNA.
Experiment No. 2: first choice versus second
Researchers asked the question - due to what subjects were able to recognize images so well and separate them from erroneous marks and duping images? Perhaps the subjects noted the orange-yellow ring as a “donut”, because in reality the donut is of exactly this shape and about the same color. In recognition, associations and intuitive choices based on experience and knowledge could help a person.
To verify this, the random label was replaced with the one that was selected by the machine as the second possible classification option. For example, AlexNet classified the orange-yellow ring as a “donut”, and the second option for this program was “pretzel”.
The subjects were faced with the task of choosing the first mark of the machine or the one that occupied the second place for all 48 images ( 2s ).
The graph in the center of image 2d shows the results of this test: 91% of the subjects chose the first version of the label, and the level of human-machine matching was 71%.
Experiment No. 3: multi-threaded classification
The experiments described above are quite simple in view of the fact that the subjects have a choice between two possible answers (machine tag and random tag). In fact, the machine in the process of image recognition iterates through hundreds and even thousands of options for labels before choosing the most suitable.
In this test, all the marks for 48 images were immediately in front of the subjects. They had to choose from this set the most suitable for each image.
As a result, 88% of the subjects chose exactly the same labels as the machine, and the degree of coordination was 79%. An interesting fact is that even when choosing the wrong label that the machine chose, subjects in 63% of such cases chose one of the top 5 labels. That is, all the marks on the car are arranged in a list from the most suitable to the most inappropriate (exaggerated example: “bagel”, “pretzel”, “rubber ring”, “tire”, etc. up to “hawk in the night sky” )
Experiment No. 3b: "what is it?"
In this test, scientists have slightly changed the rules. Instead of asking them to “guess” what label the machine will choose for a particular image, the subjects were simply asked what they see in front of them.
Recognition systems based on convolutional neural networks select the appropriate label for a particular image. This is a fairly clear and logical process. In this test, subjects exhibit intuitive thinking.
As a result, 90% of the subjects chose a label, which was also chosen by the machine. The human-machine alignment among the images was 81%.
Experiment 4: Television Static Noise
Scientists note that in previous experiments, images are unusual, but they have distinguishable features that may prompt subjects to make the right (or wrong) choice of label. For example, the image “baseball” is not a ball, but there are lines and colors on it that are present on a real baseball ball. This is a striking distinguishing feature. But if the image does not have such features, but is essentially static noise, can a person recognize at least something on it? That is what it was decided to check.

Image No. 3a
In this test, there were 8 images with statics in front of the subjects, which the SNS system recognizes as a specific object (for example, a bird-zaryanka). Also, in front of the subjects there was a label and normal images related to it (8 images of static, 1 label “zaryanka” and 5 photos of this bird). The test subject had to select 1 out of 8 images of static that best suits one or another label.
You can test yourself. Above you see an example of such a test. Which of the three images is best suited to the tag “zaryanka” and why?
81% of the subjects chose the label that the machine chose. At the same time, 75% of the images were labeled by the subjects with the most suitable label in the opinion of the machine (from a number of options, as we mentioned earlier).
For this particular test you may have questions, just like mine. The fact is that in the proposed statics (above), I personally see three pronounced features that distinguish them from each other. And only in one image, this feature strongly resembles the same zaryanka (I think you understand which image of the three). Therefore, my personal and very subjective opinion is that such a test is not particularly indicative. Although perhaps among other options for static images were really indistinguishable and unrecognizable.
Experiment No. 5: “doubtful" numbers
The tests described above were based on images that cannot immediately be fully and without a drop of doubt classified as one or another object. There is always a fraction of doubt. The fooling images are fairly straightforward in their work - to spoil the image beyond recognition. But there is a second type of malicious algorithms that add (or remove) only a small detail in the image, which can completely violate the recognition system by the SNA system. Add a few pixels, and the number 6 magically turns into the number 5 ( 1s ).
Scientists consider such algorithms to be one of the most dangerous. You can slightly change the image tag, and the unmanned vehicle incorrectly considers the speed limit sign (for example, 75 instead of 45), which can lead to sad consequences.

Image No. 3b
In this test, scientists suggested that the subjects choose the wrong answer, but rather the wrong one. In the test, 100 digital images changed by a malicious algorithm were used (the LeNet SNA changed their classification, that is, the malicious algorithm worked successfully). The subjects had to say what figure in their opinion the machine saw. As expected, 89% of the subjects successfully completed this test.
Experiment 6: photos and localized "distortion"
Scientists note that not only object recognition systems are developing, but also malicious algorithms that prevent them from doing this. Previously, for the image to be classified incorrectly, it was necessary to distort (change, delete, damage, etc.) 14% of all pixels in the target image. Now this figure has become much smaller. It is enough to add a small image inside the target and the classification will be violated.

Image No. 4
In this test, a fairly new malicious LaVAN algorithm was used, which places a small image localized at one point on the target photo. As a result, the object recognition system can recognize the metro train as a can of milk ( 4a) The most significant features of this algorithm are precisely the small proportion of damaged pixels (only 2%) of the target image and the absence of the need to distort it in its entirety or the main (most significant) part of it.
In the test, 22 images damaged by LaVAN were used (SNA recognition system Inception V3 was successfully hacked by this algorithm). The subjects were supposed to classify the malicious insert in the photo. 87% of the subjects were able to successfully do this.
Experiment 7: three-dimensional objects
The images that we saw earlier are two-dimensional, like any photo, picture or newspaper clipping. Most malicious algorithms successfully manipulate just such images. However, these pests can work only under certain conditions, that is, they have a number of limitations:
- complexity: only two-dimensional images;
- practical application: malicious changes are possible only on systems that read the received digital images, and not images from sensors and sensors;
- stability: a malicious attack loses its strength if you rotate a two-dimensional image (resize, crop, sharpen, etc.);
- people: we see the world and the objects around us in 3D at different angles, lighting, and not in the form of two-dimensional digital images taken from one angle.
But, as we know, progress has not spared malicious algorithms. Among them appeared one who is capable of not only distorting two-dimensional images, but also three-dimensional ones, which leads to incorrect classification by the object recognition system. When using software for three-dimensional graphics, such an algorithm misleads classifiers based on the SNA (in this case, the Inception V3 program) from different distances and viewing angles. The most surprising thing is that such fooling 3D images can be printed on an appropriate printer, i.e. create a real physical object, and the object recognition system will still incorrectly classify it (for example, an orange as an electric drill). And all thanks to minor changes in the texture on the target image ( 4b ).
For an object recognition system, such a malicious algorithm is a serious adversary. But man is not a machine; he sees and thinks differently. In this test, before the subjects there were images of three-dimensional objects in which there were the above-described texture changes from three angles. The subjects were also given the mark correct and erroneous. They had to determine which labels are correct, which are not, and why, i.e. whether test subjects see texture changes in images.
As a result, 83% of the subjects successfully completed the task.
For a more detailed acquaintance with the nuances of the study, I strongly recommend that you look into the report of scientists .
And at this link you will find the image, data and code files that were used in the study.
Epilogue
The work carried out gave scientists the opportunity to draw a simple and fairly obvious conclusion - human intuition can be a source of very important data and a tool in making the right decision and / or perception of information. A person is able to intuitively understand how the object recognition system will behave, what labels it will choose, and why.
The reasons why it is easier for a person to see a real image and correctly recognize it several. The most obvious is the method of obtaining information: the machine receives an image in digital form, and a person sees it with his own eyes. For a machine, a picture is a data set, making changes to which, you can distort its classification. For us, the image of a metro train will always be a metro train, not a can of milk, because we see it.
Scientists also stress that such tests are difficult to evaluate, because a person is not a machine, and a machine is not a person. For example, researchers are talking about the test with a “donut” and “wheel”. These images are similar to the “donut” and “wheel”, because the recognition system classifies them that way. A person sees that they look like a “donut” and “wheel”, but they are not. This is the fundamental difference in the perception of visual information between a person and a program.
Thank you for your attention, remain curious and have a good working week, guys.
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to your friends,30% discount for Habr users on a unique analogue of entry-level servers that was invented by us for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to divide the server correctly? (options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until the summer for free when paying for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to Build Infrastructure Bldg. class using Dell R730xd E5-2650 v4 servers costing 9,000 euros for a penny?