The book "Python. Express course. 3rd ed. "
 Hi, Habrozhiteli! This book is intended for people who already have experience in one or more programming languages and want to learn the basics of Python 3 as quickly and simply as possible. It is assumed that the reader is already familiar with control structures, OOP, file handling, exception handling, etc. The book is also useful to users of earlier versions of Python, who need a compact guide to Python 3.1.
Hi, Habrozhiteli! This book is intended for people who already have experience in one or more programming languages and want to learn the basics of Python 3 as quickly and simply as possible. It is assumed that the reader is already familiar with control structures, OOP, file handling, exception handling, etc. The book is also useful to users of earlier versions of Python, who need a compact guide to Python 3.1. We invite you to read the passage "Processing data files"
How to use the book
Part 1 provides general information about Python. You will learn how to download and install Python on your system. It also provides a general overview of the language, which will be useful primarily for experienced programmers who want to get a high-level view of Python.
Part 2 contains the main material of the book. It discusses the ingredients needed to gain practical skills in using Python as a general-purpose programming language. The material of the chapters was designed so that readers who are just starting to learn Python can move forward consistently, learning the key points of the language. In this part there are also more complex sections, so that you can then go back and find all the necessary information about a certain structure or topic in one place.
Part 3 introduces the advanced features of Python — elements of the language that are not absolutely necessary, but will certainly come in handy for any serious Python programmer.
Part 4 focuses on specialized topics that go beyond simple language syntax. You can read these chapters or skip them depending on your needs.
For beginners, Python programmers are encouraged to start with Chapter 3 in order to create a general impression, and then go on to the interesting chapters in part 2. Enter interactive examples to consolidate the concepts immediately. You can also go beyond the examples in the text and look for answers to any questions that remain unclear. Such an approach will increase the speed of learning and deepen understanding. If you are not familiar with OOP or it is not required for your application, you can skip most of chapter 15.
Readers who are already familiar with Python should also begin with chapter 3. It contains a good introductory overview and a description of the differences between Python 3 and more. familiar versions. It can also be used to evaluate whether you are ready to proceed to the more complex chapters in Parts 3 and 4 of this book.
Perhaps some readers who have no experience with Python but have sufficient experience in other programming languages will be able to get most of the necessary information by reading Chapter 3 and reviewing the modules of the standard Python library (Chapter 19) and the Python library reference manual in the Python documentation .
Excerpt Processing data files
Most of the data is distributed in text files. This can be either unstructured text (for example, a selection of messages or a collection of literary texts), or more structured data, in which each line is a record, and the fields are separated by a special separator character — a comma, tab, or a vertical bar (|). Text files can be huge; a data set can occupy tens and even hundreds of files, and the data contained in it can be incomplete or distorted. With such a variety, you almost inevitably run into the task of reading and using data from text files. This chapter presents the basic strategies for solving this problem in Python.
21.1. Introducing ETL
The need to extract data from files, parse them, convert to a convenient format, and then do something appeared almost simultaneously with data files. Moreover, there is even a standard term for this process: ETL (Extract-Transform-Load, i.e. “extract-transform-load”). By extraction is meant the process of reading a data source and parsing it if necessary. Conversion can involve cleaning and normalizing data, as well as merging, splitting and reorganizing the records contained in them. Finally, loading means saving the converted data in a new location (in a different file or database). This chapter covers the basics of implementing ETL in Python, starting with text data files and ending with saving the converted data to other files.
21.2. Reading text files
The first part of ETL, extraction, involves opening a file and reading its contents. At first glance it sounds simple, but even here problems may arise - for example, the file size. If the file is too large to fit in memory, the code needs to be structured so that it works with smaller segments of the file (perhaps one line at a time).
21.2.1. Text encoding: ASCII, Unicode, and others
Another possible problem is with the encoding. This chapter is about working with text files, and in fact a large proportion of data transmitted in the real world is stored in text files. However, the exact nature of the text may vary depending on the application, on the user and, of course, on the country.
Sometimes the text contains information in ASCII encoding, which includes 128 characters, only 95 of which belong to the category of printed characters. Fortunately, ASCII is the “least common multiple” of most data transfer situations. On the other hand, it cannot cope with the difficulties of numerous alphabets and writing systems existing in the world. Reading ASCII files will almost certainly lead to the fact that when reading unsupported characters, be it German ü, Portuguese ç, or almost any character from a language other than English, problems will start and errors will appear.
These errors occur because ASCII uses 7-bit values, while bytes in a typical file consist of 8 bits, which makes it possible to represent 256 possible values instead of 128 for 7-bit values. These additional codes are usually used to store additional values — from extended punctuation marks (such as the middle and short dashes) to various marks (trademark, copyright mark and degree sign) and versions of alphabetic characters with accents. There was always one problem: when reading a text file, you could run into a character that went beyond the ASCII range of 128 characters and could not be sure which character was encoded. Suppose you see a symbol with code 214. What is it? The division sign, the letter Ö or something else? Without the source code that created this file,
Unicode and UTF-8
To eliminate this ambiguity, you can use Unicode. The Unicode encoding, called UTF-8, supports basic ASCII characters without any changes, but it also allows for a virtually unlimited set of other characters and characters from the Unicode standard. Due to its flexibility, UTF-8 is used in more than 85% of the web pages that existed at the time of this writing. This means that when reading text files, it is best to use UTF-8. If the files contain only ASCII characters, they will be read correctly, but you also get insurance in case other characters are encoded in UTF-8. Fortunately, the Python 3 string data type is by default designed for Unicode support.
Even with Unicode, there are situations when there are values in the text that cannot be decoded successfully. The open function in Python receives an additional errors parameter that determines how to deal with encoding errors when reading or writing files. The default value is 'strict', with which an error is triggered whenever an encoding error is detected. Other useful values are 'ignore' (skip the character that caused the error); 'replace' (the character is replaced by a special marker - usually?); 'backslashreplace' (the character is replaced by the escape sequence with a \) and 'surrogateescape' (the offending character is converted to a private Unicode code point when read and back to the original byte sequence when writing).
Consider a short example of a file containing an invalid UTF-8 character, and see how this character is processed in different modes. First write the file using bytes and binary mode:
>>> open('test.txt', 'wb').write(bytes([65, 66, 67, 255, 192,193]))As a result of the command execution, a file is created from the characters “ABC”, followed by three non-ASCII characters, which can be displayed differently depending on the encoding method used. If you use vim to view the file, the result will look like this:
ABCÿÀÁ
~When the file is created, try to read it in the default error mode 'strict':
>>> x = open('test.txt').read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.6/codecs.py", line 321, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 3:
invalid start byteThe fourth byte with a value of 255 is not a valid UTF-8 character in this position, so an exception is thrown in the 'strict' mode. And now let's see how other error handling modes deal with the same file, without forgetting that the last three characters trigger an error:
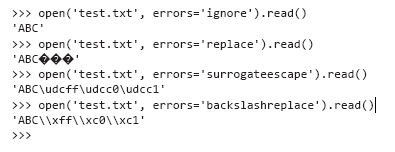
If you want the problematic characters to simply disappear, use the 'ignore' mode. The 'replace' mode only marks the positions of invalid characters, while other modes try to save invalid characters in different ways without interpretation.
21.2.2. Unstructured text
Unstructured text files are the easiest to read, but they also create the most problems with extracting information. The processing of unstructured text can vary in the widest limits, depending on both the nature of the text and what you are going to do with it, so any detailed discussion of text processing is beyond the scope of the book. However, a brief example will help demonstrate some basic problems and will lay the foundation for discussing files with structured text data.
One of the simplest problems is the selection of the basic logical unit in the file. If you use a compilation of thousands of Twitter messages, a Moby Dick text, or a news collection, they need to be broken down into blocks somehow. In the case of tweets, each block can fit on one line, and reading and processing each line of the file is organized quite simply.
In the case of Moby Dick and even a separate news item, the problem becomes more complicated. Of course, the text of the novel and even the text of the news is usually undesirable to consider as a single unit. In this case, you need to decide which blocks you need, and then work out a strategy for dividing the file into blocks. You may prefer to process the text in paragraphs. In this case, you should determine how the breakdown of the text into paragraphs in the file is organized, and write the code accordingly. If the paragraphs coincide with the lines of the text file, it will be easy to do. However, often a single paragraph of a text file may consist of several lines in a text file, and you will have to work hard.
Now consider a couple of examples.
Call me Ishmael. Years ago Some - never mind how long precisely--
having little or no money in my purse, and nothing particular
to interest me on shore, I thought I would sail about a little
and see the watery part of the world. It is a way to
control the circulation.
Whenever I find myself growing grim about the mouth;
whenever it is a damp, drizzly I meet
myself during the
funeral I meet;
I need you to get
me
Into the stepping deliberately street, and methodically knocking
people's hats off - the then, I of account IT high time to the get to sea
as with the soon's I of as with the CAN. This is my substitute for pistol and ball.
With a philosophical flourish of Cato throws himself upon his sword;
I quietly take to the ship. There is nothing surprising in this.
It was
clear that she was not feeling the same feelings
.
Is your now! Just There insular o city of the Manhattoes, belted round by wharves
as with the Indian isles by coral reefs - commerce surrounds with her IT of surf.
Right and left, the streets take you waterward. Its extreme downtown
It was the battery, where it was washed
out.
Look at the crowds of water-gazers there.
In this example (with the beginning of the “Moby Dick” text), the lines are broken down more or less as they would be paginated, and paragraphs are indicated by a single blank line. If you want to process each paragraph as a whole, you need to split the text into empty lines. Fortunately, this problem is easily solved by the split () method. Each newline character in the text is represented by the "\ n" combination. Naturally, the last line of the text of each paragraph ends with a newline, and if the next line of text is empty, then immediately followed by the second newline:

Splitting text into paragraphs is a very simple step in the process of unstructured text processing. It may also be necessary to perform additional text normalization before further processing. Suppose you want to calculate the frequency of occurrence of each word in a text file. If you just split the file by pass, you will get a list of words in the file, but it will not be so easy to count the entries, because This, this, this. and this will not be considered the same word. In order for this code to work correctly, you need to normalize the text by removing the punctuation marks and converting the entire text to one register before processing. In the above text example, the code for building a normalized word list might look like this:

21.2.3. Unstructured Delimited Files
Unstructured files are easy to read, but the lack of structure is also a disadvantage. It is often more convenient to define a certain structure for a file in order to simplify the selection of individual values. In the simplest version, the file is divided into lines, and one information element is stored in each line. For example, it may be a list of file names to process, a list of names of people, or a series of temperature readings from a remote sensor. In such cases, data analysis is organized very simply: you read the string and, if necessary, convert it to the desired type. This is all that is needed for the file to be ready for use.
However, the situation is not so simple. Often you want to group several interrelated data elements, and your code must read them together. Usually, for this, the interconnected data is placed in one line and separated by a special character. In this case, when reading each line of the file, special characters are used to split the data into fields and store the field values in variables for further processing.
The following file contains temperature data in a delimited format:
State|Month Day, Year Code|Avg Daily Max Air Temperature (F)|Record Count for
Daily Max Air Temp (F)
Illinois|1979/01/01|17.48|994
Illinois|1979/01/02|4.64|994
Illinois|1979/01/03|11.05|994
Illinois|1979/01/04|9.51|994
Illinois|1979/05/15|68.42|994
Illinois|1979/05/16|70.29|994
Illinois|1979/05/17|75.34|994
Illinois|1979/05/18|79.13|994
Illinois|1979/05/19|74.94|994The data in the file is separated by a vertical bar (|). In this example, they consist of four fields: state, date of observation, average maximum temperature, and number of stations supplying data. Other standard delimiters are tab and comma. Perhaps the comma is used most often, but the delimiter can be any character that will not occur in values (more on that later). Separating data with commas is so common that this format is often called CSV (Comma-Separated Values, that is, data separated by commas), and files of this type are provided with the .csv extension as an indication of the format.
Whatever character is used as a delimiter, if you know what kind of character it is, you can write your own Python code to split the string into fields and return them as a list. In the previous case, you can use the split () method to convert a string to a list of values:
>>> line = "Illinois|1979/01/01|17.48|994"
>>> print(line.split("|"))
['Illinois', '1979/01/01', '17.48', '994']This technique is very easy to implement, but all values are stored in string form, and this can be inconvenient for further processing.
21.2.4. Csv module
If you often have to process data files with delimiters, it is better to get acquainted with the csv module and its capabilities. When I was asked to name my favorite module from the standard Python library, I often called the csv module - not because it looks spectacular (this is not so), but because it probably saved me more time and saved me from my potential errors more often than any other module.
The csv module is a perfect example of a battery-included Python philosophy. Although you can perfectly write your own code for reading delimited files (moreover, it is not that difficult), it is much easier and more reliable to use the Python module. The csv module has been tested and optimized, and it provides a number of features that you would hardly have realized on your own, but which are nevertheless quite convenient and time-saving.
Take a look at the previous data and decide how you would read it with the csv module. The data parsing code should read each line and remove the trailing new line character, and then break the line into characters | and append the list of values to the general list of strings. The solution might look something like this:
>>> results = []
>>> for line in open("temp_data_pipes_00a.txt"):
... fields = line.strip().split("|")
... results.append(fields)
...
>>> results
[['State', 'Month Day, Year Code', 'Avg Daily Max Air Temperature (F)',
'Record Count for Daily Max Air Temp (F)'], ['Illinois', '1979/01/01',
'17.48', '994'], ['Illinois', '1979/01/02', '4.64', '994'], ['Illinois',
'1979/01/03', '11.05', '994'], ['Illinois', '1979/01/04', '9.51',
'994'], ['Illinois', '1979/05/15', '68.42', '994'], ['Illinois', '1979/
05/16', '70.29', '994'], ['Illinois', '1979/05/17', '75.34', '994'],
['Illinois', '1979/05/18', '79.13', '994'], ['Illinois', '1979/05/19',
'74.94', '994']]If you want to do the same with the csv module, the code might look something like this:
>>> import csv
>>> results = [fields for fields in
csv.reader(open("temp_data_pipes_00a.txt", newline=''), delimiter="|")]
>>> results
[['State', 'Month Day, Year Code', 'Avg Daily Max Air Temperature (F)',
'Record Count for Daily Max Air Temp (F)'], ['Illinois', '1979/01/01',
'17.48', '994'], ['Illinois', '1979/01/02', '4.64', '994'], ['Illinois',
'1979/01/03', '11.05', '994'], ['Illinois', '1979/01/04', '9.51',
'994'], ['Illinois', '1979/05/15', '68.42', '994'], ['Illinois', '1979/
05/16', '70.29', '994'], ['Illinois', '1979/05/17', '75.34', '994'],
['Illinois', '1979/05/18', '79.13', '994'], ['Illinois', '1979/05/19',
'74.94', '994']]In this simple case, the gain compared with the independent implementation of the solution is not so great. However, the code is two lines shorter and a little clearer, and you don’t need to worry about clipping new characters. The present advantage manifests itself when you are faced with more complex cases.
The data in this example is real, but in reality it has been simplified and cleaned up. The real data from the source will be more complex. Real data contains more fields, some fields will be enclosed in quotes, while others will not, and the first field may be empty. The original is separated by tabs, but for purposes of demonstration, I quote them separated by commas:
"Notes","State","State Code","Month Day, Year","Month Day, Year Code",Avg
Daily Max Air Temperature (F),Record Count for Daily Max Air Temp
(F),Min Temp for Daily Max Air Temp (F),Max Temp for Daily Max Air Temp
(F),Avg Daily Max Heat Index (F),Record Count for Daily Max Heat Index
(F),Min for Daily Max Heat Index (F),Max for Daily Max Heat Index
(F),Daily Max Heat Index (F) % Coverage
,"Illinois","17","Jan 01, 1979","1979/01/
01",17.48,994,6.00,30.50,Missing,0,Missing,Missing,0.00%
,"Illinois","17","Jan 02, 1979","1979/01/02",4.64,994,-
6.40,15.80,Missing,0,Missing,Missing,0.00%
,"Illinois","17","Jan 03, 1979","1979/01/03",11.05,994,-
0.70,24.70,Missing,0,Missing,Missing,0.00%
,"Illinois","17","Jan 04, 1979","1979/01/
04",9.51,994,0.20,27.60,Missing,0,Missing,Missing,0.00%
,"Illinois","17","May 15, 1979","1979/05/
15",68.42,994,61.00,75.10,Missing,0,Missing,Missing,0.00%
,"Illinois","17","May 16, 1979","1979/05/
16",70.29,994,63.40,73.50,Missing,0,Missing,Missing,0.00%
,"Illinois","17","May 17, 1979","1979/05/
17",75.34,994,64.00,80.50,82.60,2,82.40,82.80,0.20%
,"Illinois","17","May 18, 1979","1979/05/
18",79.13,994,75.50,82.10,81.42,349,80.20,83.40,35.11%
,"Illinois","17","May 19, 1979","1979/05/
19",74.94,994,66.90,83.10,82.87,78,81.60,85.20,7.85%Please note: some fields include commas. According to the rules in such cases, the field is enclosed in quotes to show that its contents are not intended for parsing and searching for delimiters. In practice (as in this case) often only part of the fields is quoted, first of all those whose values may contain a separator. However (as again in this example), some fields are quoted even when they are unlikely to contain a separator.
In such cases, homegrown solutions become too cumbersome. Now, just splitting a string by a delimiter character no longer works; you need to ensure that when searching used only those separators that are not inside the lines. In addition, you must remove the quotes, which can be in an arbitrary position or not located anywhere. With the csv module you don’t have to change your code at all. Moreover, since the comma is considered the default delimiter, it does not even need to be specified:
>>> results2 = [fields for fields in csv.reader(open("temp_data_01.csv",
newline=''))]
>>> results2
[['Notes', 'State', 'State Code', 'Month Day, Year', 'Month Day, Year Code',
'Avg Daily Max Air Temperature (F)', 'Record Count for Daily Max Air
Temp (F)', 'Min Temp for Daily Max Air Temp (F)', 'Max Temp for Daily
Max Air Temp (F)', 'Avg Daily Min Air Temperature (F)', 'Record Count
for Daily Min Air Temp (F)', 'Min Temp for Daily Min Air Temp (F)', 'Max
Temp for Daily Min Air Temp (F)', 'Avg Daily Max Heat Index (F)',
'Record Count for Daily Max Heat Index (F)', 'Min for Daily Max Heat
Index (F)', 'Max for Daily Max Heat Index (F)', 'Daily Max Heat Index
(F) % Coverage'], ['', 'Illinois', '17', 'Jan 01, 1979', '1979/01/01',
'17.48', '994', '6.00', '30.50', '2.89', '994', '-13.60', '15.80',
'Missing', '0', 'Missing', 'Missing', '0.00%'], ['', 'Illinois', '17',
'Jan 02, 1979', '1979/01/02', '4.64', '994', '-6.40', '15.80', '-9.03',
'994', '-23.60', '6.60', 'Missing', '0', 'Missing', 'Missing', '0.00%'],
['', 'Illinois', '17', 'Jan 03, 1979', '1979/01/03', '11.05', '994', '-
0.70', '24.70', '-2.17', '994', '-18.30', '12.90', 'Missing', '0',
'Missing', 'Missing', '0.00%'], ['', 'Illinois', '17', 'Jan 04, 1979',
'1979/01/04', '9.51', '994', '0.20', '27.60', '-0.43', '994', '-16.30',
'16.30', 'Missing', '0', 'Missing', 'Missing', '0.00%'], ['',
'Illinois', '17', 'May 15, 1979', '1979/05/15', '68.42', '994', '61.00',
'75.10', '51.30', '994', '43.30', '57.00', 'Missing', '0', 'Missing',
'Missing', '0.00%'], ['', 'Illinois', '17', 'May 16, 1979', '1979/05/
16', '70.29', '994', '63.40', '73.50', '48.09', '994', '41.10', '53.00',
'Missing', '0', 'Missing', 'Missing', '0.00%'], ['', 'Illinois', '17',
'May 17, 1979', '1979/05/17', '75.34', '994', '64.00', '80.50', '50.84',
'994', '44.30', '55.70', '82.60', '2', '82.40', '82.80', '0.20%'], ['',
'Illinois', '17', 'May 18, 1979', '1979/05/18', '79.13', '994', '75.50',
'82.10', '55.68', '994', '50.00', '61.10', '81.42', '349', '80.20',
'83.40', '35.11%'], ['', 'Illinois', '17', 'May 19, 1979', '1979/05/19',
'74.94', '994', '66.90', '83.10', '58.59', '994', '50.90', '63.20',
'82.87', '78', '81.60', '85.20', '7.85%']]»More information about the book is available on the publisher's website
» Table of contents
» Excerpt
For Habrozhiteley 20% discount coupon - Python