Formula for Korean, or recognize Hangul quickly, easily and without errors.
 To date, any student who has taken a course on neural networks can make recognition of Korean characters. Give him a sample and a computer with a video card, and after a while he will bring you a network that will recognize Korean characters with almost no errors.
To date, any student who has taken a course on neural networks can make recognition of Korean characters. Give him a sample and a computer with a video card, and after a while he will bring you a network that will recognize Korean characters with almost no errors. But such a solution will have several disadvantages:
Firstly , a large number of necessary calculations, which affects the operating time or the required energy (which is very important for mobile devices). Indeed, if we want to recognize at least 3000 characters, then this will be the size of the last layer of the network. And if the input of this layer is at least 512, then we get 512 * 3000 multiplications. Too much.
Secondly, the size. The same last layer from the previous example will weigh 512 * 3001 * 4 bytes, i.e. about 6 megabytes. This is only one layer, the entire network will weigh tens of megabytes. It’s clear that this is not a big problem for a desktop computer, but not everyone will be ready to store so much data on a smartphone to recognize one language.
Thirdly , such a network will give unpredictable results on images that are not Korean characters, but are nevertheless used in Korean texts. In laboratory conditions, this is not difficult, but for the practical application of technology, this issue will have to be somehow solved.
And fourthly, the problem is the number of characters: 3000 is most likely enough to, for example, distinguish a steak from a fried sea cucumber in the restaurant’s menu, but sometimes more complex texts are also found. It will be difficult to train the network for a larger number of characters: it will not only be slower, but there will also be a problem with the collection of the training sample, since the frequency of the characters decreases approximately exponentially. Of course, you can get images from fonts and augment them, but this is not enough to train a good network.
And today I will tell you how we managed to solve these problems.
How does Korean writing work?
Korean writing, Hangul, is a cross between Chinese and European writing. Outwardly, these are square characters resembling hieroglyphs, and on one page of the text you can count more than a hundred unique ones. On the other hand, it is phonetic writing, that is, based on the recording of sounds. There is an alphabet containing 24 letters (plus you can additionally count diffraphs and diphthongs). But, unlike the Latin or Cyrillic alphabet, sounds are not written in a line, but combined in blocks. For example, if we wrote in the same way, then the phrase “Hello, Habr” could be written in three blocks like this:

Each block can consist of two, three, or four letters. In this case, the consonant always comes first, then one or two vowels, and at the end there can be another consonant. There are several different ways to combine letters into blocks, that is, in different blocks the second letter, for example, will stand in different places.
The picture below shows two blocks that together form the word "Hangul". The first letter of each block is indicated in red, the vowels are highlighted in blue, and the final consonant is highlighted in green.

Image source: Wikipedia.
Modify Hangul block
That is, it turns out that one Hangul block can be described by the formula: Ci V [V] [Cf], where Ci is the initial consonant (possibly double), V is the vowel, and Cf is the final consonant (can also be double). Such a representation is inconvenient for recognition, so we change it.
First, combine both vowels. We get the formula Ci V '[Cf], where V' - all possible options for combining letters, considering the absence of the second letter. Since there are 10 vowels in the language, one would expect that as a result we get 10 * (10 + 1) options, but in practice not all of them are possible, we get only 21.
Further, the last letter may not be. Add to the many expected letters at the end an empty one. Then we obtain the formula Ci V 'Cf *. Thus, it turns out that now the Korean symbol always consists of three “letters”. You can learn the grid.
We construct a network
The idea is that instead of recognizing the whole character, we will recognize the individual letters in them. Thus, instead of one huge softmax at the end, we get three small ones, each about a few tens in size. They correspond to the first, second and third “letters” in the syllable. As a result, we got the following architecture:
clickable image We train, run on a separate sample. The quality is good, the grid is fast, and it weighs little. Let's try to take it out of the laboratory to the real world.
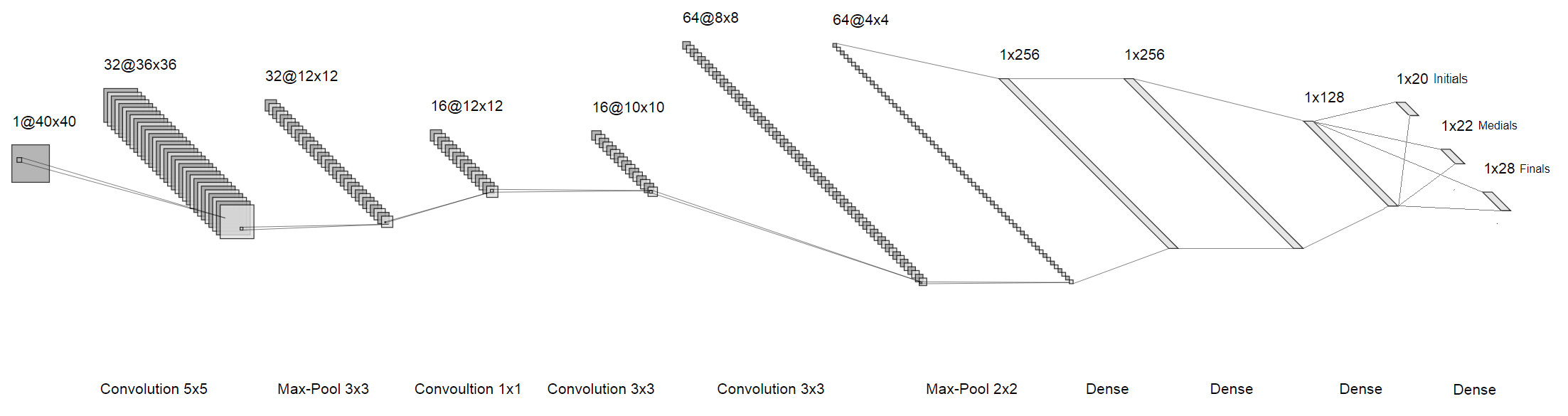
We solve problems
We’ll get the first problem right away: sometimes images that are not Korean characters at all get into the input, and the network on them behaves extremely unpredictably. You can, of course, train another network that will distinguish Korean blocks from everything else, but we will make it easier.
Let's do the same thing that we did with the third group of letters: add an output for the absence of a letter. Then the symbol formula will look like this: Ci * V '* Cf *. And in the training set, we’ll add all kinds of garbage — Chinese characters, incorrectly cut characters, European letters, and we will teach the network to mark three empty letters on it.
We train, test. It works, but the problems remain. It turns out that quite often, for example, such images fall into the grid:

This is the correct Korean block to which a single quote is stuck. And it is obvious that on them the network perfectly finds all three letters of which the block consists. That's just the image is not correct, and we need to signal about it. It is wrong to return empty letters here, as they are in the image. Let's try to apply what has already proved to be good: add two more outputs to recognize such sticky punctuators. In each of them there will be one additional output for a situation where there is nothing superfluous in the image, but in addition it is necessary to add one more output for the situation "there is a punctuator, but it is not recognized, probably garbage."
Trained It is bad at such a grid to recognize punctuators: it distinguishes a comma from a bracket, but it is already difficult from a point. You can increase the complexity of the grid, but do not want to. We will deal with the recognition of punctuators later, but for now we will simply give out whether there is something there or not. This grid learned well.
We figured out the glued punctuators, but what if, on the contrary, part of the key is missing in the image? There was such a two-character word, but we cut it into characters incorrectly:

The network here without any problems determines the central letter. This would be a very useful quality if our task was to recognize only a selection of characters, but in the real world it would be harmful: when we incorrectly cut the string into characters, we must pass this information above, because otherwise the remaining piece is then recognized as some kind of punctuation, and in the resulting text there will be an extra character.
To solve this problem, we will use what remains of some old experiments of many years ago. The idea of recognizing Korean characters by letters appeared a very long time ago, and the first attempts were made even before the era of neural networks, but they did not find practical application. But since then, interesting things have remained:
- Marking out where each block has a letter.
- High-quality, albeit quick, cutting out these letters from symbols.
Having brushed off the dust, with the help of this stuff we will generate a sufficient number of such problematic images without one of the letters and we will specially teach the network to answer that they are an empty letter.
That's all, there are no more problems with recognizing Korean characters, but life puts sticks into the wheels again.
The fact is that in addition to Hangeul characters, Korean texts also consist of a large number of other characters: punctuators, European characters (at least numbers) and Chinese characters. But they naturally occur much less frequently. We will divide them into two groups: hieroglyphs and everything else, and we will train our grid for each of them. And we will make a simple classifier, which according to the results of the network for recognizing Korean characters and for some other signs (geometric, in the first place) will answer whether at least one of them needs to be launched, and if so, which one. You need to recognize a bit of European characters, so the grid will be small, but for hieroglyphs ... It saves that they are rarely found in texts, so let's twist our classifier so that it very rarely suggests recognizing them.
In general, with these two grids, the problem of an adequate answer arises in images that are not symbols on which she was trained, but we will talk about how to solve this problem another time.
Carry out experiments
First one . There are two image bases, let's call them Real and Synthetic. Real consists of real images that are obtained from scanned documents, and Synthetic - images obtained from fonts. In the first base there are images for 2374 blocks (the rest are very rare), and from the fonts we got all the possible 11172 characters. Let's try to train the network on the blocks that are in Real (we will take the images from both bases), and test on those that are only in Synthetic. Results:

That is, in about 60% of cases, the network is able to recognize those blocks, examples of which it did not see at all during training. The quality could have been higher if not for one problem: among the final letters there are very rare ones, and during training the network saw very few images of blocks in them. This explains the low quality in the last column. If it were possible to choose the 2374 blocks on which we study, in a different way, then the quality would most likely be noticeably higher.
Second. Compare our network with a “normal” network, which has softmax at the end. I would like to make it 11172 in size, but we cannot find a sufficient number of real images for rare blocks, so we restrict ourselves to 2374. The quality and speed of this network depends on the size of the hidden layers. We will only teach on Real, test on it (on the other part, of course).

That is, even if we restrict ourselves to recognizing only 2374 blocks, our network is faster and at the same level in quality.
Third . Suppose that we were able to get somewhere a huge base of all 11172 Korean blocks. If we train a network with softmax on it, how long will it work on time? It’s expensive to conduct all experiments, so we’ll only consider a network with 256 hidden layer sizes:

We get the results

Without them, nothing would have happened
I express my gratitude to my colleague Jura Chulinin, the original author of the idea. It is patented in Russia, and, in addition, a similar application has been filed with the American Patent Office (USPTO). Many thanks to the developer Misha Zatsepin, who implemented all this and conducted all the experiments.
Yuri Vatlin,
Head of Complex Scripts group